
- 【參考文獻】Meng R, Mirchev M, B?hme M, et al. Large language model guided protocol fuzzing[C]//Proceedings of the 31st Annual Network and Distributed System Security Symposium (NDSS). 2024.(CCF A類會議)
- 【注】本文僅為作者個人學習筆記,如有冒犯,請聯系作者刪除。
目錄
摘要
1、Introduction
2、Background and Motivation
2.1、Protocol Fuzzing
2.2、Large Language Models
2.3、Motivation
3、Case Study: Testing the Capabilities of LLMs for Protocol Fuzzing
3.1、Lifting Message Grammars: Quality and Diversity
3.2、Enriching the Seed Corpus: Diversity and Validity
3.3、Inducing Interesting State Transitions
4、LLM-Guided Protocol Fuzzing
4.1、Grammar-guided Mutation
4.1.1、Grammar-guided Mutation
4.1.2、Mutation based on Grammar
4.2、Enriching Initial Seeds
4.3、Surpassing Coverage Plateau
4.4、Implementation
5、Experimental?Design
5.1、Configuration Parameters
5.2、Benchmark and baselines
5.3、Variables and Measures
5.4、Experimental Infrastructure
6、Experimental Results
6.1、State coverage
6.2、Code coverage
6.3、Ablation?Studies
6.4、Discovering New bugs
7、Related Work
8、Conclusion
摘要
- 如果沒有機器可讀的協議規范,如何發現協議實現中的安全漏洞?在一組記錄的消息序列上使用變異模糊測試作為種子輸入,可以緩解這一挑戰。然后,可用種子集合非常有限,并且難以覆蓋協議多樣性的狀態和輸入結構。
- 在本文中,我們探討了系統性地與預訓練的大型語言模型 (LLM)進行交互的機會,這些模型已經攝取了數百萬頁的人類可讀協議規范,以提取可用于協議模糊測試的機器可讀信息。我們利用LLM對知名協議的消息類型的知識。我們還檢查了LLM通過生成消息序列和預測響應碼來檢測有狀態協議實現中‘狀態’的能力。
- 基于這些觀察,我們開發了一種LLM引導的協議實現模糊測試引擎。我們的協議模糊測試器CHATAFL為協議中的每種消息類型構建語法,然后通過與LLM的交互變異消息或預測消息序列中的下一個消息。
- 對Profuzzbench中的各種實際協議進行的實驗顯示,在狀態和代碼覆蓋方面顯著有效。我們的LLM引導的有狀態fuzzers與最先進的模糊測試器AFLNET和NSFUZZ進行了比較。CHATAFL分別覆蓋了47.60%和42.69%更多的狀態轉換,29.55%和25.75%更多的狀態,以及5.81%和6.74%更多的代碼。除了增強的覆蓋率外,CHATAFL在廣泛使用和廣泛測試的協議實現中發現了九個不同且之前未知的漏洞,而AFLNET和NSFUZZ分別只發現了三個和四個。
1、Introduction
- 查找特定協議狀態中的漏洞需要以正確的順序發送正確的輸入。例如,某些協議在交換其他類型的消息之前需要初始化或握手消息。為了讓接收方正確解析該消息并進入下一個狀態,消息必須遵循特定的格式。然而,默認情況下,我們既不知道這些消息的正確結構,也不知道它們的正確順序。
- 基于變異的協議fuzzers減少了對所需消息結構或規范的依賴。簡單的突變通常會保留所需的協議,但仍然會損壞消息序列,從而暴露錯誤。然而,基于突變的協議fuzzers的有效性受到記錄的種子消息序列的質量和多樣性的限制,并且可用的簡單突變無助于有效覆蓋原本豐富的輸入或狀態空間。
- 在本文中,我們探討了利用LLM來指導協議模糊測試過程的實用性。LLM通過互聯網網站和文檔中的許多TB數據進行訓練,最近被證明能夠準確回答關于任何主題的特定問題。LLM的近期巨大成功為我們提供了開發一個系統的機會,該系統將協議fuzzers與LLM進行系統交互,其中fuzzers可以向LLM發布非常具體的任務。
- 我們稱這種方法為LLM引導的協議模糊測試,并提出了三個具體組件。
- 首先,模糊測試器使用LLM提取協議的機器可讀語法,以用于結構感知的變異。
- 其次,模糊測試器使用LLM增加記錄消息序列中的消息多樣性,這些消息序列用作初始種子。
- 最后,模糊測試器使用LLM打破覆蓋率的瓶頸,通過提示LLM生成消息以到達新狀態。
- 在我們的消融研究中,從基線開始,我們發現依次啟用語法提取 (the grammar extraction)、種子豐富 (the seed enrichment)和飽和處理器 (the saturation handler),使得CHATAFL分別比基線在24小時內實現相同代碼覆蓋的速度快2.0、4.6和6.1倍。CHATAFL在發現協議實現中的關鍵安全問題方面非常有效。在我們的實驗中,CHATAFL在廣泛使用和廣泛測試的協議實現中發現了九個不同且之前未知的漏洞。
- 本文貢獻如下:
- 我們構建了一個LLM引導的協議實現模糊測試引擎,以克服現有協議模糊測試器的挑戰。為了更深入地覆蓋這些協議的行為,需要進行即時狀態推斷——這通過詢問LLM(如ChatGPT)關于給定協議的狀態機和輸入結構來實現。
- 我們提出了將LLM集成到基于變異的協議fuzzers中的三種策略,每種策略都明確解決了協議模糊測試的一個已識別挑戰。我們開發了一種擴展的灰盒模糊測試算法,并將其作為原型CHATAFL實現。該工具公開可用,網址為:GitHub - ChatAFLndss/ChatAFL: Large Language Model guided Protocol Fuzzing (NDSS'24)
- 我們進行了實驗,結果表明,我們的LLM引導的有狀態模糊測試原型CHATAFL在協議狀態空間和協議實現代碼的覆蓋方面,明顯優于最先進的AFLNET和NSFUZZ。除了增強的覆蓋范圍外,CHATAFL在廣泛使用的協議實現中發現了九個之前未知的漏洞,其中大部分是AFLNET和NSFUZZ無法找到的。
2、Background and Motivation
2.1、Protocol Fuzzing
- 協議指定了要交換的消息的一般結構和順序。圖1顯示了RTSP消息結構的示例:除了指定消息類型(PLAY)、地址和協議版本的頭部外,消息還包括由回車和換行字符(CRLF;\r\n)分隔的鍵值對(key: value)。
- RTSP消息的順序要求如圖2所示:從INIT狀態開始,只有SETUP或ANNOUNCE類型的消息會導致進入新狀態(READY)。要從INIT狀態到達PLAY狀態,至少需要兩條特定類型和結構的消息。
- 作為一種最先進的(SOTA)方法,基于突變的協議模糊仍然面臨著幾個挑戰:
- 依賴初始種子:基于突變的協議模糊器的有效性受到所提供的初始種子輸入的嚴重限制。預先記錄的消息序列很難涵蓋協議規范中討論的協議狀態和輸入結構的多樣性。
- 未知消息結構:如果沒有關于消息結構的機器可讀信息,fuzzers就不能對種子消息進行結構上有趣的更改。例如,構造不可見類型的消息,或者刪除、替換或添加整個連貫的數據結構到種子消息。
- 未知狀態空間:如果沒有關于狀態空間的機器可讀信息,模糊器就不能識別當前狀態,也不能被引導去探索以前看不見的狀態。


2.2、Large Language Models
- 由于LLM預訓練于數十億的互聯網樣本,它們應該也能理解不同協議的規范。此外,LLM已經展示了強大的文本生成能力。考慮到消息是在服務器和客戶端之間傳輸的文本格式,為LLM生成消息應該是直截了當的。LLM的這些能力有可能解決基于變異的協議模糊測試的開放挑戰。此外,LLM固有的自動化和易用性與模糊測試的設計理念完美契合。
2.3、Motivation
- 在本文中,我們提出使用LLMs來引導協議模糊測試。為緩解對初始種子的依賴(C1),我們建議讓LLM向給定的種子消息序列添加隨機消息。但這是否真的增加了消息的多樣性和有效性?
- 為應對消息結構未知的問題(C2),我們建議讓LLM提供每種消息類型的機器可讀信息(即語法)。但這些語法與真實情況相比有多好?覆蓋了哪些消息類型?
- 為探索未知的狀態空間(C3),我們建議讓LLM在給定模糊測試器和協議實現之間最近的消息交換的情況下,返回一條可以引導到新狀態的消息。但這是否真的有助于我們過渡到新狀態?
3、Case Study: Testing the Capabilities of LLMs for Protocol Fuzzing
- 本研究選擇了RTSP,以及它在Profuzzbench中的實現live555,并且使用了最新的ChatGPT模型。
3.1、Lifting Message Grammars: Quality and Diversity
- 我們要求LLM提供關于消息結構的機器可讀信息(即語法),并評估生成語法的質量以及消息類型覆蓋的多樣性相對于真實情況的表現。
- 為了建立真實語法,兩位作者共花費8小時閱讀RFC 2326,并手動和單獨提取相應的語法,達成完全一致。最終,我們提取了10種特定于RTSP協議的客戶端請求的真實語法,每種請求包含大約2到5個頭字段。圖3顯示了PLAY消息的語法,對應于圖1中所示的PLAY客戶端請求的語法。PLAY語法包括4個基本頭字段:CSeq、User-Agent、Session和Range。
- 此外,某些請求類型具有特定的頭字段。例如,Transport字段特定于SETUP請求,Session字段適用于除SETUP和OPTIONS之外的所有類型,而Range字段特定于PLAY、PAUSE和RECORD請求。
- 為了獲取LLM的語法進行分析,我們隨機抽取了LLM關于RTSP協議的50個回答,并將它們整合成一個答案集。如圖4所示,LLM生成了我們預期的所有十種消息類型的語法,這些消息類型出現在超過40個LLM回答中。此外,LLM偶爾生成了2種隨機的客戶端請求類型,如‘SET DESCRIPTION’,但每種隨機類型在我們的答案集中只出現了一次。
- 此外,我們還檢查了LLM生成的語法的質量。對于10種消息類型中的9種,LLM生成的語法在所有回答中都與從RFC中提取的真實語法完全相同。唯一的例外是PLAY客戶端請求,其中LLM在一些回答中忽略了(可選的)‘Range’字段。進一步檢查整個答案集中PLAY語法后,我們發現LLM在35個回答中準確生成了包括‘Range’字段的PLAY語法,但在15個回答中省略了它。這些發現表明,LLM具有生成高度準確的消息語法的能力,這激勵我們利用語法來指導變異。
- LLM生成的所有類型RTSP客戶端請求的結構信息均為機器可讀,并與真實情況相匹配,盡管存在一些隨機性。



3.2、Enriching the Seed Corpus: Diversity and Validity
- 我們要求LLM向給定的種子消息序列添加一個隨機消息,并評估消息序列的多樣性和有效性。
- 在PROFUZZBENCH中,LIVE555的初始種子語料庫僅包含10種真實消息類型中的4種客戶端請求:DESCRIBE、SETUP、PLAY和TEARDOWN。缺少其余6種客戶端請求類型,導致RTSP狀態機的很大一部分未被探索,如圖2所示。盡管fuzzers有可能生成缺失的6種客戶端請求類型,但概率相對較低。為了驗證這一觀察結果,我們檢查了AFLNet和NSfuzz生成的種子,沒有生成這些缺失的消息類型。因此,增強初始種子是至關重要的。我們能否利用LLM生成客戶端請求并增強初始種子語料庫?
- 如果LLM不僅能夠生成準確的消息內容,還能將消息插入到客戶端請求序列的適當位置,這將是最優的。眾所周知,網絡協議的服務器通常是有狀態的反應系統。此特性決定了客戶端請求要被服務器接受,必須滿足兩個強制條件:(1)它出現在適當的狀態中,(2)消息內容是準確的。
- 為了調查LLM的這一能力,我們要求它生成10種類型客戶端請求中的每一種類型的10條消息,總共100條客戶端請求。隨后,我們驗證這些客戶端請求是否被放置在給定客戶端請求序列中的適當位置。為此,我們將它們與圖2所示的RTSP狀態機進行了比較,因為消息序列應該根據狀態機進行轉換。一旦我們確保客戶端請求的序列在狀態機上是準確的,我們將其發送到LIVE555服務器。通過檢查服務器返回的響應代碼,我們可以確定消息內容是否準確,從而雙重檢查消息的順序。
- 為了提升LLM在生成包含正確會話ID的消息時的能力,我們開發了兩種方法。當提供額外的上下文信息時,這些方法表現出了顯著效果。
- 首先,我們在提示中包含了服務器的響應,然后請求LLM生成相同類型的消息。這時,生成的客戶端請求被服務器直接接受。
- 此外,我們嘗試將會話ID包括到給定的客戶端請求序列中,LLM也準確地將相同的值插入到這些消息中,并生成了正確的結果。
- 由此可見,LLM能夠生成準確的消息,并且具備豐富初始種子的能力。
3.3、Inducing Interesting State Transitions
- 我們將fuzzers與協議實現之間的消息交換提供給LLM,并請求它返回一條能夠導致新狀態的消息。然后評估該消息誘發狀態轉換的可能性。具體來說,我們向LLM提供現有的通信歷史記錄,使服務器分別達到每個狀態(即INIT、READY、PLAY和RECORD)。然后,我們查詢LLM以確定可能影響服務器狀態的下一個客戶端請求。為了減輕LLM隨機行為的影響,我們對每個狀態提示LLM100次。
- 圖5展示了不同狀態的結果。每個餅狀圖的每個部分表示不同的客戶端請求類型。灰色的表示可以導致狀態改變的客戶端請求類型的百分比。橙色的表示在適當狀態中出現但不會觸發任何狀態轉換的消息類型(因此不會發生狀態變化)。藍色的表示在不適當狀態中出現并會被服務器直接拒絕的消息類型。
- 這些結果表明LLM具有推斷協議狀態的能力,盡管偶爾會出現錯誤。

4、LLM-Guided Protocol Fuzzing
- 基于上述證明的LLM的能力,本文提出LLM-guided protocol fuzzing (LLMPF)來解決現有的基于變異的協議模糊測試 (EMPF)的挑戰。
- 算法1,描述傳統EMPF方法的一般過程(非灰色區域)。
- 輸入為測試P0下的協議服務器,對應的協議p,初始種子池C和總模糊測試時間T。輸出包括最終的種子池C和觸發服務器崩潰的種子Cx。
- 每次迭代過程中(7~34行),EMPF會選擇一個前進的狀態s(7行)和執行到s的序列M(8行)來引導fuzzer探索更大的空間。為了確保選擇的狀態s被執行,M被劃分為了3部分(9行):
- M1:到達s的序列。
- M2:選擇進行變異的部分。
- M3:剩余的子序列。
- 隨后,EMPF為M(10行)分配能量來確定突變時間,將M變異為M’。M‘隨后將發送到服務器(23行)。如果M’導致了崩潰(24~25行)或增加了代碼或狀態覆蓋(27~28行),EMPF將保留該序列。如果是后者,它還會更新狀態機(29行)。這個過程會一直重復,直到分配的時間結束,之后將選擇下一個狀態。

- 對于LLMPF,我們通過合并灰色的組件來增強EMPF的基線邏輯。
- 通過提示LLM提取語法(2行),并使用語法來引導變異(12~14行)。
- 請求LLM豐富初始種子(3行)。
- 利用LLM的能力突破覆蓋限制(4,19~21,26,30,32行)。
4.1、Grammar-guided Mutation
- 本節介紹從LLM中提取語法,并使用語法來引導結構感知變異。
4.1.1、Grammar-guided Mutation
- 在從LLM中提取語法之前,我們遇到一個緊迫的挑戰:如何為fuzzer獲得機器可讀的語法?
- fuzzer在一臺機器上運行,僅限于解析預定的格式。但LLM生成的響應通常是一種相當靈活的自然語言結構。如果fuzzer要理解LLM的響應,那么LLM應該始終以預定的格式回答來自fuzzer的問題。另一種選擇包括手動將LLM的響應轉換為所需的格式。然而,這種方法會損害fuzzer高度自動化的性質,不太可取。因為,現在的問題是如何使LLM以所需的格式回答問題。
- 常見的方法是對模型進行微調,以實現對特定任務的熟練度。相似地,對于LLM就需要對提示進行微調。這是因為LLM可以通過簡單提供自然語言提示來執行特定的任務,而不需要指令。因此,fuzzer提示LLM生成被測協議的消息語法。然而,提示微調的范圍是廣泛的。
- 為了使LLM生成一個機器可讀的語法,我們最終在提示工程領域中使用了in-context few-shot learning。in-context few-shot learning是一種微調模型的有效方法。Few-shot learning被用來增強上下文,通過少量的期望輸入和輸出的例子。這使得LLM能夠識別輸入提示的語法和輸出模式。通過in-context few-shot learning,我們用幾個示例提示LLM以所需的格式提取協議語法。
- 圖6展示了提取RTSP語法的模型提示。在該提示中,模糊器以所需格式提供了兩種不同協議的兩種語法示例。在這種格式中,我們在語法中保留消息關鍵字,認為它是不可變的,并用“Value”替換可變異區域。請注意,為了指導大型語言模型(LLM)正確生成語法,我們使用了兩個示例,而不是僅僅依賴一個示例。這有助于防止LLM嚴格遵守給定的語法,并可能忽略重要的事實。
- 此外,我們的案例研究揭示了另一個問題:LLM可能偶爾會產生隨機答案,如“SET_DESCRIPTION。但這些情況很少見。為了解決這種隨機性,我們與LLM進行了多次對話,并將大多數一致的答案作為最終語法。
- 圖6中所示的Model Output展示了從LLM中派生出來的部分RTSP語法。在實踐中,LLM偶爾對這個提示中的單詞“all”不敏感,這導致它們只生成部分語法類型。為了解決這個問題,我們只需再次提示llm詢問剩余的語法。
- 在開始fuzzing之前,LLMPF與LLM進行對話,以獲得語法。隨后,該語法被保存到語法種子池G中,用于結構感知突變。該設計旨在最小化與LLM交互的開銷,同時確保最佳的模糊測試性能。

4.1.2、Mutation based on Grammar
- LLMPF利用從LLM中提取的語法種子池,對種子消息序列進行結構化感知變異。在之前的工作中,研究人員通過利用LLM的理解輸入語法能力來生成給定輸入的變體。但這種方法被與LLM頻繁互動的開銷所限制。LLMPF利用提取的語法來指導突變。fuzzer只提取一次語法,并在整個模糊測試活動中使用。
- 在算法1的第9行中,模糊器選擇消息部分M2進行突變。假設M2包含多個客戶端請求,其中一個是RTSP協議的PLAY客戶端請求。由語法指導的突變方法如圖7所示,展示了修改一個RTSP PALY客戶端請求的工作流程。具體來說,當出現PLAY客戶端請求時,LLMPF首先將其與相應的語法進行匹配。為了加快匹配過程,我們將語法語料庫保持為映射格式: G = {type → grammar}。使用消息類型,LLMPF將檢索相應的語法。隨后,我們使用正則表達式將消息中的每個標題字段與語法匹配,標記為“Value”可變區域。圖7中標記為藍色。在突變期間,LLMPF只選擇這些區域,以確保消息保留有效的格式。然而,如果沒有找到語法匹配,我們認為所有區域都是可變的。

4.2、Enriching Initial Seeds
- 由于LLM能夠生成新的消息并將它們插入到所提供的消息序列中的適當位置,我們建議豐富初始種子語料庫(算法1的第3行)。然而,我們的方法必須首先解決幾個挑戰:
- 如何生成攜帶正確上下文信息的新消息(例如,RTSP協議中正確的會話ID)?
- 如何最大化生成的序列的多樣性?
- 如何提示LLM從給定的種子消息序列生成全部修改后的消息序列?
- 對于挑戰1,我們發現,LLM可以自動從所提供的消息序列中學習所需的上下文信息。例如,在我們的實驗中,ProFuzzBench已經擁有了一些消息序列作為初始種子(盡管它們缺乏多樣性)。這些初始種子由被測服務器和客戶端之間的網絡流量組成。因此,這些初始種子包含了來自服務器的正確和充分的上下文信息。所以,在提示LLM時,我們包含了來自ProFuzzBench的初始種子,以方便獲取必要的上下文信息。
- 對于挑戰2,fuzzer決定了在初始種子中缺少哪些類型的客戶端請求,即LLM應該生成哪些類型的消息來豐富初始種子。回到圖6中所示的語法提示符。提示包括消息類型的名稱(即,PLAY和GET),相應地,消息名稱也包含在模型輸出中(例如,DESCRIBE和SETUP)。我們利用這些信息來維護一組消息類型:Alltypes={messageType},以及從語法到對應類型的一個映射:G2T={grammar→type}。在發現缺失的消息類型時,我們首先利用獲得的語法語料庫G和語法到類型的映射G2T來獲取現有的消息類型,并將它們維護到一個集合中(即存在的類型)。然后,我們指示LLM生成缺失的消息類型,并將它們插入到初始種子中;為了避免初始種子過長,我們均勻地向給定的消息序列中添加兩種缺失的類型。
- 對于挑戰3,為了確保生成的消息序列的有效性,我們將提示設計為延續格式(即“修改后的客戶端請求序列為:”)。在實際操作中,獲得的響應可以直接用作種子,除了去掉開頭的換行符 (\n) 或添加缺失的分隔符 (\r\n) 之外。圖 8 提供了一個說明性示例。在該示例中,我們指示大型語言模型(LLM)在給定序列中插入兩種類型的消息,“SET PARAMETER”和“TEARDOWN”。修改后的序列顯示在右側。
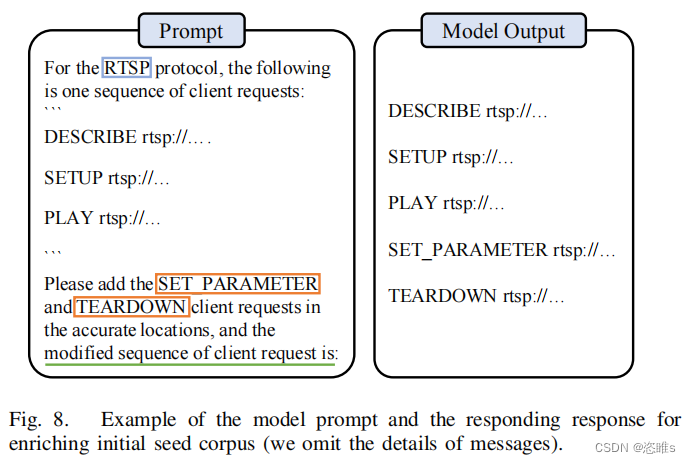
4.3、Surpassing Coverage Plateau
- 對于有狀態協議,探索未知的狀態是一種挑戰。回顧圖2所示的RTSP狀態機。
- 假設,服務器接收一客戶端請求序列后處于狀態READY。如果服務器想要轉變到不同的狀態(例如,PLAY或者RECORD),客戶端必須發送對應的PALY或RECORD請求。在模糊測試過程中,fuzzer扮演客戶端的角色。雖然模糊器具有生成誘導狀態轉換的消息的能力,但它需要探索相當數量的種子。fuzzer很有可能無法生成合適的消息順序來覆蓋所需的狀態轉換。因此,代碼空間的相當一部分仍未被探索。所以,為了徹底測試有狀態的服務器,探索其他狀態是很重要的。不幸的是,完成這個任務對于現有的有狀態模糊器來說確實具有挑戰性。
- 在本文中,當fuzzer無法探索新的覆蓋范圍時,我們將此場景稱為fuzzer進入覆蓋瓶頸 (coverage plateau)。當fuzzer在給定時間內不能生成有趣的種子時,我們使用LLM幫助fuzzer突破覆蓋瓶頸。我們根據fuzzer連續生成的無趣種子的數量來量化這個持續時間。具體來說,我們使用一個全局變量PlateauLen來跟蹤至今為止生成的無趣種子的數量。在模糊測試開始前,PlateauLen被初始化為0(算法1,4行)。在每次迭代過程中,如果遇到導致崩潰或者覆蓋率增加的種子,PlateauLen會重置為0。否則,每遇到一個無趣種子,PlateauLen加1。
- 如果PlateauLen沒有超過預先設定的閾值MaxPlateau,LLMPF就使用之前提到的變異策略。用戶可以自定義閾值。如果超過了MaxPlateau,LLMPF就會使用LLM來克服覆蓋瓶頸(19~21行)。為了實現這一點,我們使用LLM來生成下一個可能導致狀態向其他狀態轉換的合適的客戶端請求。提示如圖9所示。我們向LLM提供服務器和客戶機之間的通信記錄,即客戶端請求和相應的服務器響應。為了確保LLM生成的是真實的消息,而不是消息類型或描述,我們通過從初始種子語料庫中任意提取消息來演示所需的格式。隨后,LLM推斷當前狀態,并生成下一個客戶端請求M2‘。這個請求作為原始M2的突變,并被插入到消息序列M‘中,然后將其發送到服務器。
- 重新看向RTSP的例子。最初,服務器處于INIT狀態。在接收到消息序列M1 = {SETUP}時,它用R1 = {200-OK}響應,過渡到就緒狀態。隨后,模糊器遇到了一個覆蓋瓶頸,在那里它不能產生有趣的種子。在注意到這一點后,我們通過呈現通信歷史H = {SETUP,200-OK}來激活LLM。作為回應,LLM很有可能回復PLKAY或RECORD。這些消息導致服務器轉換到一個不同的狀態,克服了覆蓋瓶頸。


4.4、Implementation
- 本文在AFLNET的基礎上實現了LLM引導的協議模糊測試,稱為CHATAFL,來測試C/C++編寫的協議。AFLNET維護一個推斷的狀態機,并使用狀態和代碼反饋來指導模糊測試。當前狀態的標識涉及到從服務器的響應消息中解析響應代碼。如果種子增加了狀態或代碼覆蓋,它被認為是有趣的。CHATAFL繼續利用這種方法,同時將上述三種策略集成到AFLNET框架中。
5、Experimental?Design
- 對于LLM解決基于突變的fuzzers對有狀態協議進行測試的挑戰,為了評估其效用,我們試圖回答以下問題:
- State coverage:與baseline相比,CHATAFL實現了多少狀態覆蓋率?
- Code coverage:與baseline相比,CHATAFL實現了多少代碼覆蓋率?
- Ablation:每個組件對CHATAFL的性能有什么影響?
- New bugs:CHATAFL對于在廣泛使用和廣泛測試的協議實現中發現以前未知的錯誤是否有用?
5.1、Configuration Parameters
- MaxPlateau設置為512。在初步實驗中,我們發現512是MaxPlateau的一個合理設置,在大約10分鐘內實現。將值設置得太小會導致CHATAFL過度查詢LLM,而將其設置得過大將導致CHATAFL停留太久,對我們的優勢不利。為了限制LLM提示的成本,我們將MaxPlateau的四分之一設置為無效提示的最大數量。
- 我們使用的LLM為gpt-3.5- turbo,并且temperature設置為0.5來提取語法和豐富初始種子。為了生成新的信息,J. Qiang等人的發現,對于灰盒模糊,1.5的temperature是最佳的。因此,我們將temperature設置為1.5來突破覆蓋瓶頸。在提取語法時,對于self-consistency check,我們使用了5次重復,這足以過濾掉錯誤的情況。
- 【注】temperature參數決定了模型生成文本時的多樣性和創造性。
5.2、Benchmark and baselines
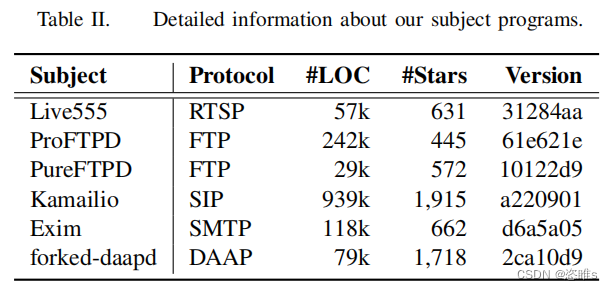
- 表2列出了在我們的評估中使用的目標程序,包括5個廣泛使用的網絡協議(即RTSP、FTP、SIP、SMTP和DAAP)。這些目標程序集成在ProFuzzBench中。這些協議涵蓋了廣泛的應用程序,包括流媒體、消息傳遞和文件傳輸。這些實現已經成熟,并在企業和個人用戶中廣泛使用。對于每個協議,我們都選擇了流行的、適合在現實應用程序中使用的實現。這些項目中的安全缺陷可能會產生廣泛的影響。
- 我們選擇了AFLNet工具和NSFuzz-v作為基線工具。由于ChatAFL是基于AFLNET實現的,觀察ChatAFL和AFLNet之間的差異,可以歸因于我們為實現LLM指導所做的改變。NSFUZZ-v擴展了AFLNET,以更好地處理協議狀態空間。它通過靜態分析來識別狀態變量,并使用狀態變量值作為模糊反饋,以最大化狀態空間的覆蓋范圍。
5.3、Variables and Measures
- 為了評估CHATAFL比對基線fuzzers的效率,我們測量了協議模糊器覆蓋協議的狀態空間和協議實現的代碼的程度。然而,覆蓋只是模糊的錯誤發現能力的代理度量。因此,我們用錯誤發現結果來補充覆蓋結果。
- Coverage
- 我們報告了代碼和狀態空間的覆蓋范圍。
- 為了評估代碼覆蓋率,我們使用基準平臺PeoFuzzBench提供的自動化工具來實現的分支覆蓋率。
- 為了評估狀態空間的覆蓋范圍,我們測量了:
- 不同狀態的數量(狀態覆蓋)和這些狀態之間的轉換數量(轉換覆蓋)。
- 為了減輕隨機性的影響,我們報告了在24小時內重復10次時所達到的平均覆蓋率。
- 我們報告了代碼和狀態空間的覆蓋范圍。
- Bugs
- 為了識別bug,我們在Address Sanitizer(ASAN)下執行被測試的程序。ChatAFL存儲崩潰的消息序列,然后我們使用AFLNET提供的AFLNet-replay來重現崩潰并調試潛在的原因。我們通過分析ASAN報告的堆棧跟蹤來區分不同的bug。最后,我們將這些錯誤報告給他們各自的開發人員,以供確認。
5.4、Experimental Infrastructure
- XXX
6、Experimental Results
6.1、State coverage
- Transition

- 表3顯示了狀態轉換的平均數量。A12(Vargha-Delaney)測量效應量是一種用于比較兩組獨立樣本的非參數效應量指標。它主要用于評估兩個獨立組之間的差異大小,特別是在應用于非正態分布數據或有秩次數據的情況下。
- States
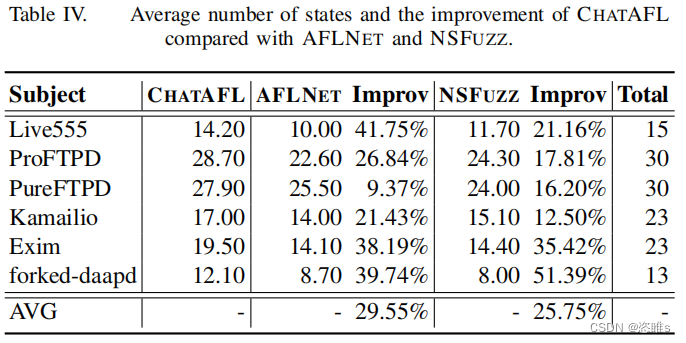
- 表4顯示了所覆蓋的平均狀態。
- 在狀態覆蓋范圍方面,ChatAFL提供的狀態轉換平均覆蓋率分別比AFLNET和NSFUZZ多48%和43%。與baseline相比,CHATAFL覆蓋的相同數量的狀態轉換分別快48倍和16倍。此外,ChatAFL還探索了比AFLNET和NSFUZZ更大的可達狀態空間的比例。
6.2、Code coverage

- 表5顯示了達到的平均分支數。
- 在代碼覆蓋率方面,ChatAFL的平均分支覆蓋率分別比AFLNET和NSFUZZ多5.8%和6.7%。此外,CHATAFL實現的分支數量分別比AFLNET和NSFUZZ快6倍和10倍。
6.3、Ablation?Studies
- ?CHATAFL實現了三種策略來與LLM交互,以克服協議模糊的挑戰:
- 語法引導的突變
- 豐富的初始種子
- 突破覆蓋瓶頸
- 為了評估每種策略對增加覆蓋率的貢獻,我們進行了一項消融研究。為此目的,我們開發了四種工具:
- AFLNET,即所有策略都被禁用。
- AFLNET + 語法引導突變(SA)。
- AFLNET+語法引導突變(SA)和豐富初始種子(SB)。
- AFLNET+所有策略(SA + SB + SC),即ChatAFL。
- 表6展示了它們的分支覆蓋率結果。
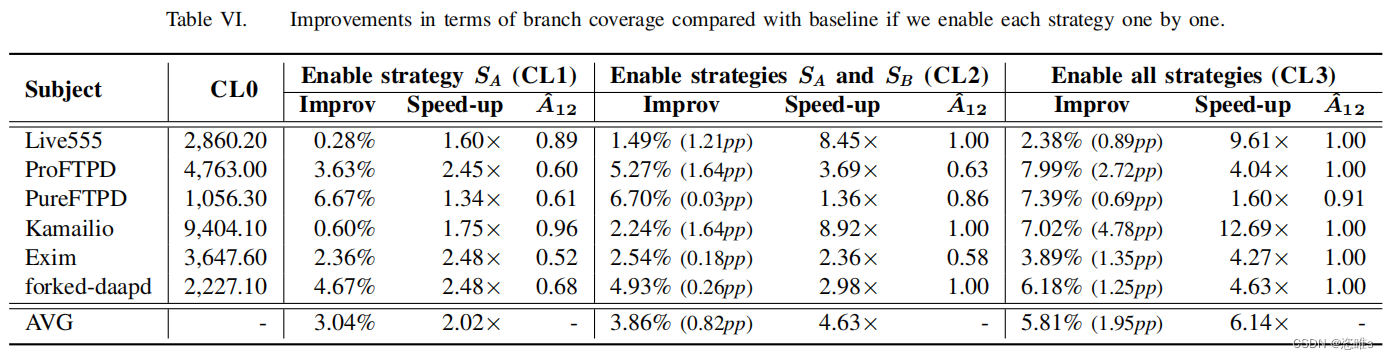
- 總的來說,每一種策略都有助于不同程度的提高分支覆蓋率。逐個啟用策略SA、SB和SC使我們能夠實現相同的分支覆蓋率,分別達到快2.0倍、快2.6倍、快4.6倍和6.1倍的速度。
6.4、Discovering New bugs
- 在這個實驗中,我們通過檢查CHATAFL是否能夠在我們的目標程序中發現zero-day錯誤來評估它的效用。結果如表7所示。

- CHATAFL發現了9個不同的、以前未知的bugs,而AFLNET和NSFUZZ分別只發現了其中的3個和4個。AFLNET和NSFUZZ也沒有發現任何額外的錯誤。9個bug中有7個(7/9)可能是潛在的安全問題。
7、Related Work
- Grammar-based fuzzing
- 基于生成的fuzzers基于手動構建的規范從頭開始生成消息。這些規范通常包括數據模型和狀態模型。數據模型描述了消息的語法,而狀態模型指定了服務器和客戶端之間的消息順序。然而,構建這些規范可能是一項費力的任務,并且需要大量的人力努力。相比之下,大型語言模型是在數十億個文檔上預先訓練的,并且擁有關于協議規范的廣泛知識。在CHATAFL中,我們直接利用llm來獲取規范信息,從而無需進行額外的手工工作。
- Dynamic Message Inference
- 為了減少模糊測試前對先驗知識和手動工作的依賴,幾個現有工作提出了動態推斷消息結構,包括黑盒和灰盒fuzzers。黑盒fuzzers如TreeFuzz,在種子池上使用機器學習技術來構建概率模型,隨后用于生成輸入。白盒fuzzers如Polyglot,通過對被測系統的動態分析技術來提取消息結構,例如符號執行和污點跟蹤。但是,這些方法只能根據觀察到的消息來推斷消息結構。因此,所推斷出的結構可能會明顯偏離實際的消息結構。
- Dynamic State Inference
- 基于變異的fuzzers是模糊測試協議實現的最主要方法之一。基于突變的模糊器通過隨機突變從種子池中選擇的現有種子,生成新的輸入,并利用覆蓋信息系統地進化該種子池。在分支覆蓋反饋的指導下,它們已經被證明模糊測試無狀態程序的有效性。
- 然而,當模糊有狀態的程序時,分支覆蓋本身是一個有用但不足的指標來指導模糊運動,正如在現有工作中闡明的。因此,采用狀態覆蓋反饋與分支機覆蓋一起指導模糊測試工作。然而,分辨狀態是一個重要的挑戰。一系列工作提出了各種狀態表示方案。AFLNET [36]將響應代碼作為狀態,在模糊活動中構建一個狀態機,并將其作為狀態覆蓋指導。StateAFL、SGFUZZ和NSFUZZ提出了基于程序變量的不同的狀態表示方案。在本文中,我們并不試圖回答狀態是什么。相反,我們將此任務委托給LLM,并允許它推斷狀態。這種方法已被證明是有效的。
- Fuzzing based on Large Language Models
- 隨著預先訓練好的大型語言模型在各種自然語言處理任務中取得的顯著成功,研究人員一直在探索它們在不同領域的潛力,包括模糊測試。例如,CodaMosa是第一個將llm應用于模糊測試的(即自動生成Python模塊的測試用例)。之后,TitanFuzz和FuzzGPT使用LLM自動生成深度學習軟件庫的測試用例。然而這些工作都是采用了生成的方法來進行模糊測試,ChatFuzz是通過要求LLM修改人類編寫的測試用例來進行變異。Ackerman等人利用模糊的格式規范,并使用LLM遞歸檢查自然語言格式規范,生成實例作為基于變異的fuzzers的強種子示例。與這些技術相比,CHATAFL將信息提取與模糊測試技術分離。CHATAFL首先以機器可讀的格式(即通過語法和狀態機)從LLM中提取關于輸入的結構和順序的信息,然后運行一個包含這些信息的高效fuzzer。為了提高效率,CHATAFL只在模糊過程中覆蓋范圍飽和時才使用LLM進行突變(類似于ChatFuzz)。
8、Conclusion
- 協議模糊測試是一個固有的難題。與文件處理應用程序相比,它的模糊輸入是文件,協議通常是響應系統,涉及系統和環境之間的持續交互。這就提出了兩個獨立但相關的挑戰:
- 為了探索導致崩潰的不常見的深層行為,我們可能需要生成復雜的有效事件序列。
- ?由于協議是有狀態的,這也隱式地涉及到模糊測試期間的動態狀態推斷(因為并不是所有的操作都可以在一個狀態中啟用)。此外,模糊測試的效率很大程度也取決于初始種子的質量,這是模糊測試的基礎。
- 在這項工作中,我們已經證明,對于具有公開獲得的RFCs的協議,LLMs被證明在豐富初始種子、實現結構感知突變和幫助狀態推斷方面是有效的。我們在ProFuzzBench提供的廣泛協議中評估了CHATAFL。結果表明:與基線工具(baseline tools)相比,CHATAFL覆蓋了更多的代碼,并在明顯更少的時間內探索了更大的狀態空間。此外,CHATAFL發現了9個零日(zero-day)漏洞,而基線工具只發現了其中的3到4個。



:Qt應用界面設計原則)



】運行配置找不到導入的自定義 makefile 項目)
)

)



應用程序)

(高級進階))

)
