針對高并發寫,分布式ID是其業務基礎,本文從一個面試題細細展開。
面試官: 1.對于Mysql的InnoDB引擎下,自增ID和UUID作為主鍵各自有什么優劣,對于一張表的主鍵你建議使用哪種ID? 2.除了UUID是否還了解其他類型的唯一ID? |
對于這兩個問題,我們需要深入了解的知識有兩個:
1.mysql的innodb引擎的數據組織結構是什么樣的
2.分布式ID都有幾種各自的優劣是什么
還有這里要關注一點,為什么強調了InnoDB 引擎,還有什么引擎(MyISAM這個后續再說)?
Mysql-InnoDB 引擎
通常InnoDB為mysq的默認引擎,此引擎也是我們最熟識的B+樹作為我們數據的基礎組織結構,B+樹作為一個“矮胖子”,通過4層高度就能組織千萬數據,極大的減少了磁盤IO次數提升了數據訪問效率,這也是它可以作為大多數公司數據持久化基石的原因。
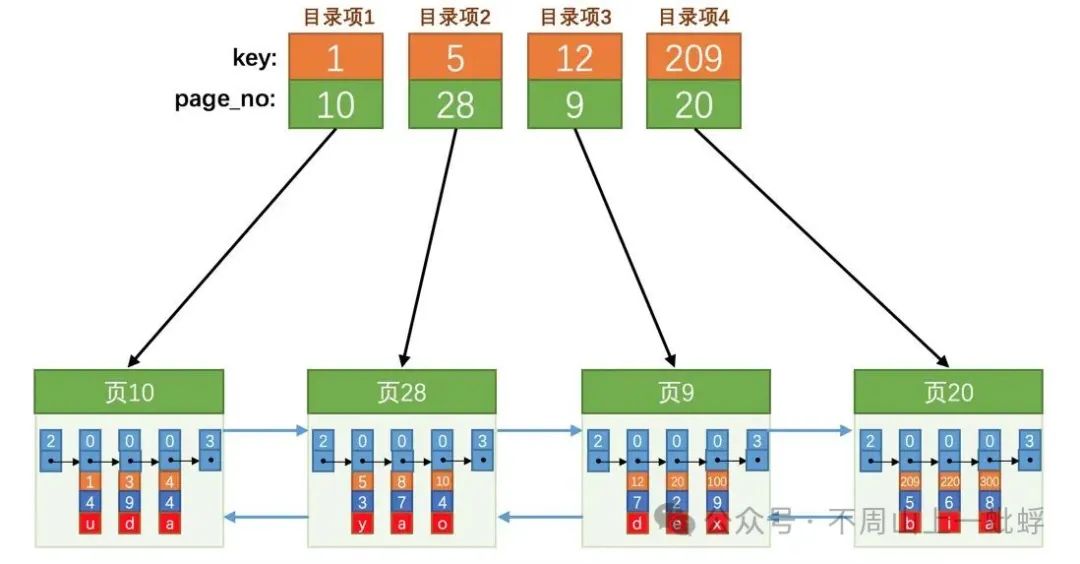
(此圖非原創-侵刪)
對于此B+樹結構,數據庫的數據新增,順序新增還是隨機新增對于它的執行效率有很大影響,如果新增數據是隨機的,那可能增加大量的IO,因為每次新增都可能頁分裂與頁合并,涉及數據挪移,而對于順序新增,每次都會在頁尾進行操作,這大大減小了磁盤IO,因此對于一個業務主鍵,它應該是單調遞增的,這樣可以大大提升數據插入效率。
自增ID和UUID作為主鍵對比
其實這個問題,面試官最主要就是要考察的UUID對于mysql 隨機寫入的影響,當然其他的了解越多越好。
特點對比 | 自增ID | UUID(v4) |
實現方式 | 數據庫支持 | 工具包支持 |
生成速率限制 | 取決于數據庫的TPS,比較低 | 無上限 |
寫入效率* | 順序寫入,性能很高 | 隨機寫入導致數據寫入性能急劇下降 |
查詢效率 | 數字查詢效率更高(數字比較) | 36位字符(32+4個‘-’)比較效率稍低 |
存儲空間 | BigInt 8字節 | Varchar(36) 1字節前綴+36字節=37字節 |
業務量推測 | 根據id相減可推測業務量 | 隨機無法推測 |
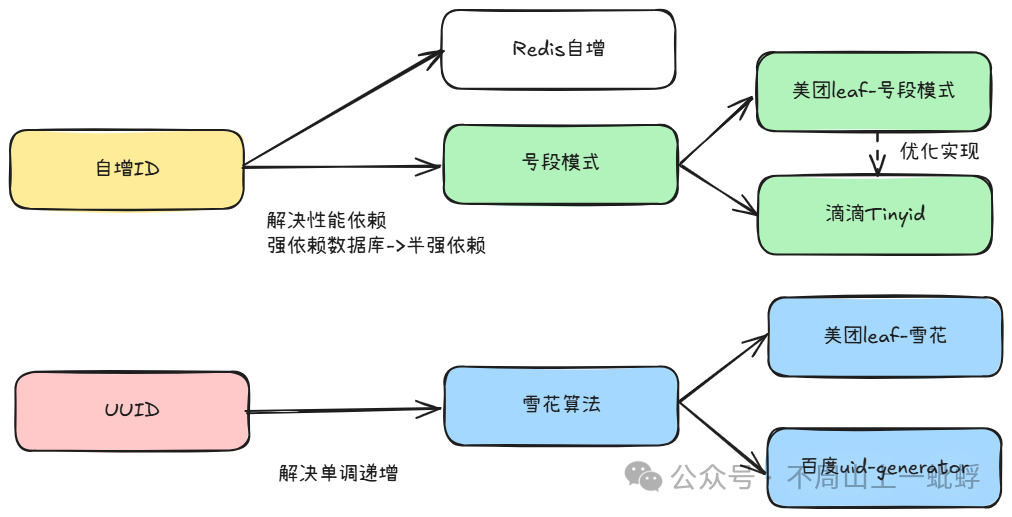
其實可以看出,這兩種方案都會存在一個致命性問題,自增id強依賴數據庫且生成效率低,UUID對于寫入效率又有很大問題。針對上面分析其實我們需要的分布式id 需要具有以下特性:全局唯一、單調遞增、高效生成。很多大家熟悉的方案都是針對上面兩種方案的優化產生,整理目前的解決方案如下:
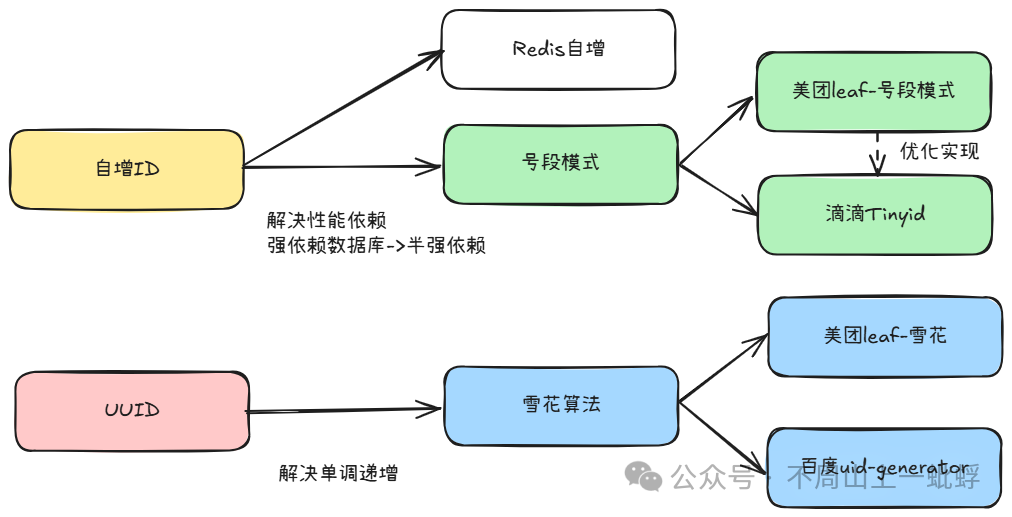
分布式ID-Snowflake
先說說名字(個人猜測)之所以取雪花這個名字,是威爾遜·奧爾溫·賓利(Wilson Bentley)他通過顯微鏡和顯微攝影技術拍攝了5382張雪花照片,證實了雪花形態的獨特性,因此產生觀點“世界上沒有兩片完全相同的雪花”,美團的leaf名字異曲同工。
直接上圖吧,原始snowflake 和mongo的objectId 原理相似。
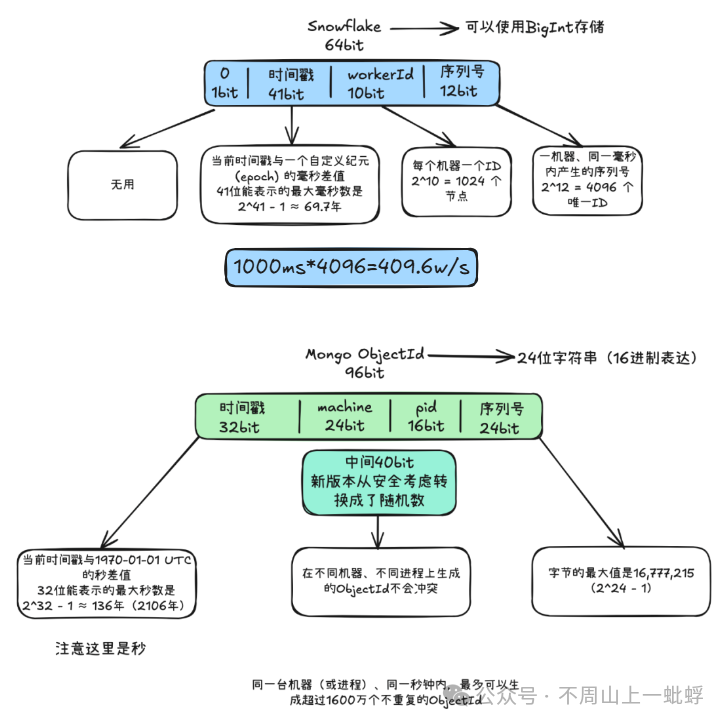
而經典的雪花算法和類雪花算法,由于整體ID的組成使用了時間戳,所以都會存在一個重要的bug情況“時鐘回撥”。
時鐘回撥:是指一臺機器的操作系統時鐘,突然跳變到了一個比當前系統記錄的時間更早的時刻。 |
一旦產生時鐘回撥就可能產生致命的問題,分布式ID不能保證全局唯一,這樣會對業務造成嚴重影響。
產生時鐘回撥的原因:
NTP時間同步:一般毫秒級別回撥,當 NTP 客戶端發現自己的本地時鐘比時間服務器快時,為了逐步糾正這個誤差,它可能會選擇逐步減慢時鐘(斯步進,slewing),但在某些配置或差異過大時,NTP 服務可能會認為時鐘發生了嚴重故障,從而采取直接跳轉(步進,stepping)的方式,將系統時間瞬間調回正確時間。硬件時鐘(RTC)問題:回撥時間很嚴重,這個由CMOS電池供電(想不到吧),如果電池沒電了會重置一個比較早的時間例如1970-01-01,如果這系統重啟了,系統會先讀取RTC時間,再NTP同步時間,在NTP同步之前時鐘都是錯誤的。
虛擬化環境:掛起后恢復,需要同步宿主機時間。
人為誤操作: 看修改情況了,誰腦子抽筋取修改系統時間或時區。
分布式ID-美團Leaf-Snowflake
美團leaf的雪花模式,針對于雪花算法做了兩處優化:
1.workerId 不手動分配使用zookeeper(弱依賴)獲取。
2.解決時鐘回撥問題(所有以雪花模式生成分布式ID都會去解決時鐘回撥)。
workerId 分配原理
對于workerId,當系統節點數過多的時候,很難手動維護,因此選擇啟動時通過zookeeper加載,在加載后會本地持久化一個workerId,當zooKeeper掛了了時則采用本地數據,提升SLA。
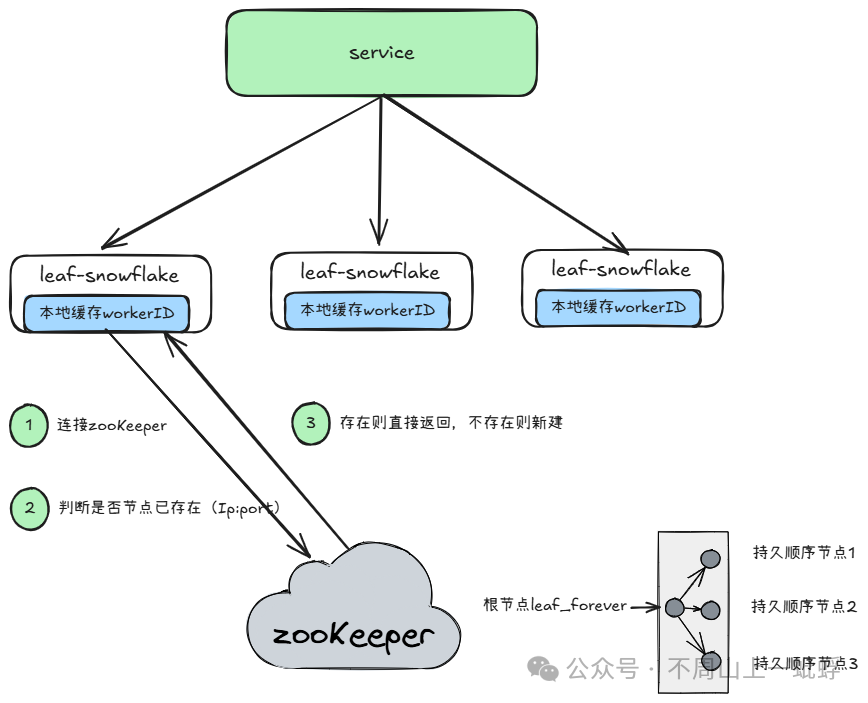
如何解決時鐘回撥問題
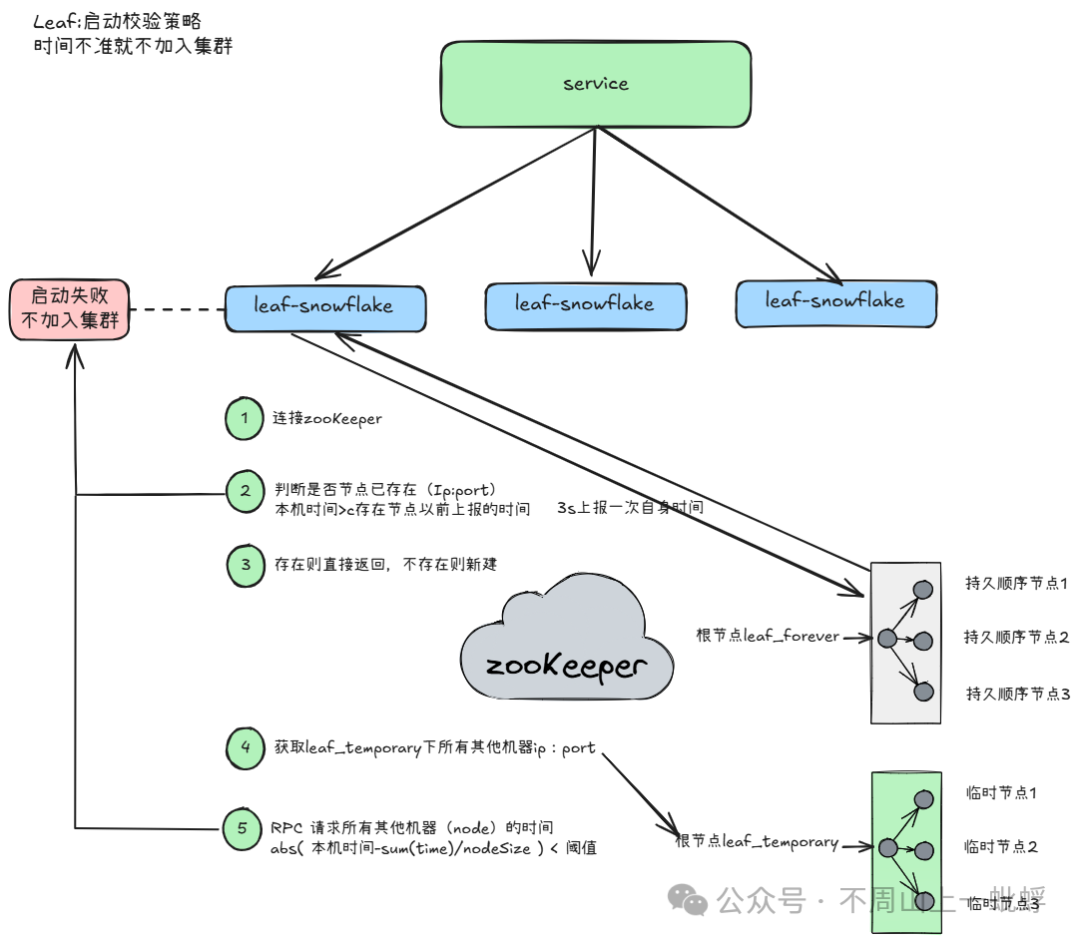
1.啟動時時間校準
如果啟動時校驗失敗,則此機器啟動失敗,不接入發號集群。
(1)連接zookeeper
(2)判斷是否節點已存在(Ip:port)本機時間>存在節點以前上報的時間
(3)存在則直接返回,不存在則新建
(4)獲取leaf_temporary下所有其他機器ip:port
(5)RPC 請求所有其他機器的時間abs( 本機時間-sum(time)/nodeSize ) < 閾值,如果大于預置則直接失敗
(6)成功后3s定時上報當前機器時間
2.發號過程等待或失敗
做一層自旋等待重試,然后上報報警系統,自動摘除或者人工接收報警處理。
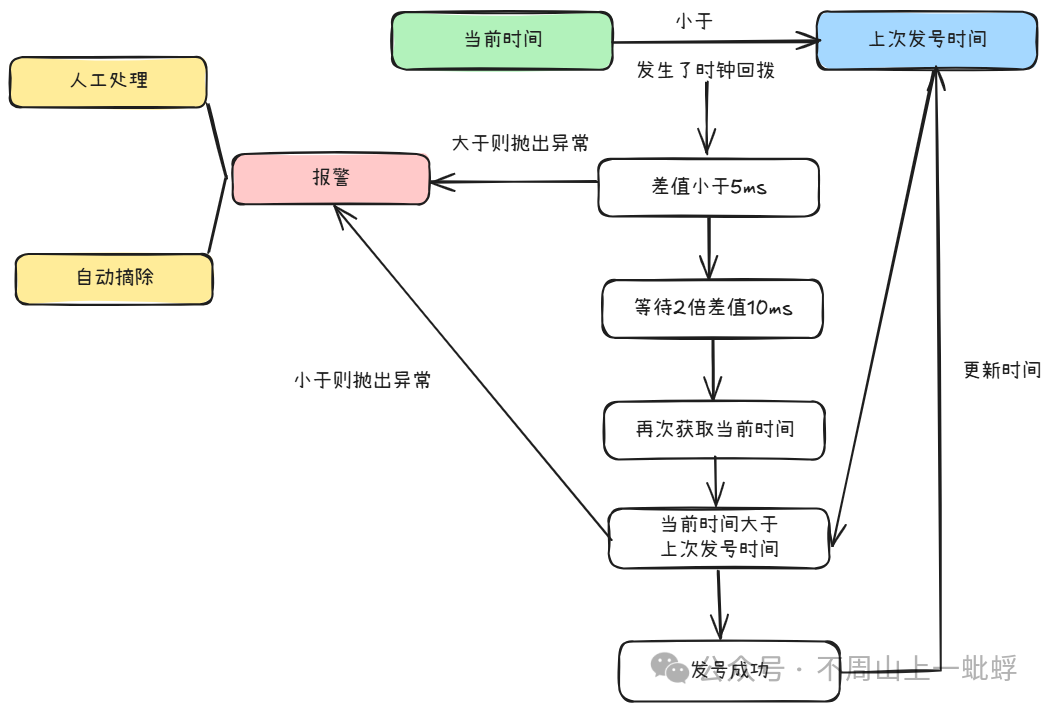
總結:美團leaf的雪花算法通過檢測兩個方面保證生成分布式ID單調遞增,1.在啟動時依賴zookeeper存儲數據校驗,失敗則不允許加入集群,2.在每次發號時比較上次發號時間,小于5ms 則等待10ms再次校驗,失敗則報警或自動摘除。
分布式ID-百度uid-generator
百度主要實現了兩種generator:
DefaultUidGenerator
雪花算法(以秒位單位)+時鐘回撥報異常(沒有自旋等待)

- sign(1bit)
固定1bit符號標識,即生成的UID為正數。 - delta seconds (28 bits)
當前時間,相對于時間基點"2016-05-20"的增量值,單位:秒,最多可支持約8.7年 - worker id (22 bits)
機器id,最多可支持約420w次機器啟動。內置實現為在啟動時由數據庫分配,默認分配策略為用后即棄,后續可提供復用策略。 - sequence (13 bits)
每秒下的并發序列,13 bits可支持每秒8192個并發。
CachedUidGenerator
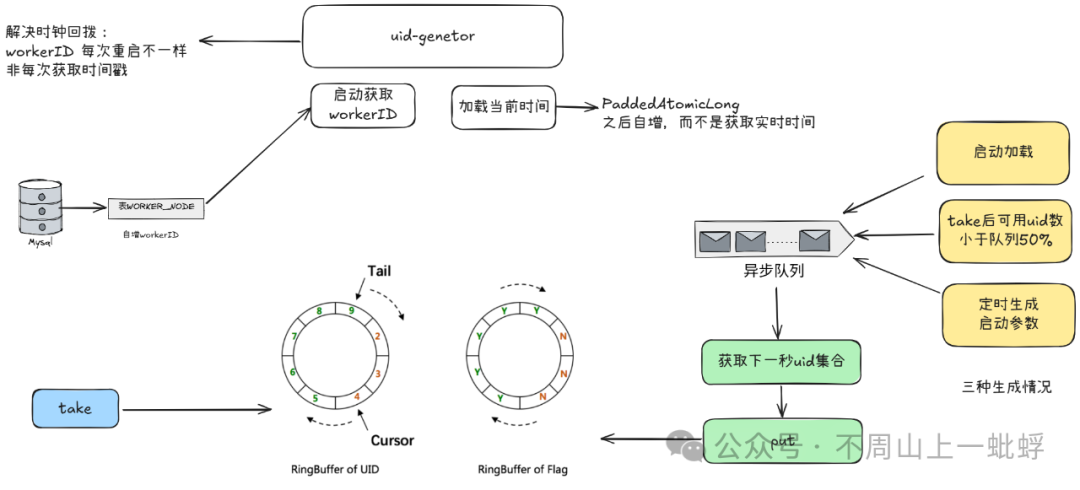
解決時鐘回撥:
它不是每次實時獲取當前時間而是只啟動加載一次,之后通過原子自增實現;
那如果啟動加載的時間有問題就是老時間呢,它通過每次重啟的自增ID解決。
所以此方案通過自增的workerID +原子自增時間戳 解決了時鐘回撥問題。
數據填充時機:
通過異步預生成uid環,提升整體tps性能。
初始化預填充:RingBuffer初始化時,預先填充滿整個RingBuffer。
即時填充:Take消費時,即時檢查剩余可用slot量(tail - cursor),如小于設定閾值,則補全空閑slots。閾值可通過paddingFactor來進行配置,請參考Quick Start中CachedUidGenerator配置。
周期填充:通過Schedule線程,定時補全空閑slots。可通過scheduleInterval配置,以應用定時填充功能,并指定Schedule時間間隔。
總結:百度CachedUidGenerator 通過于每次啟動自增workerID和原子自增時間戳解決了時鐘回撥問題;采用離線預生成的方案提升了整體生成的性能。
分布式ID-snowflake小結
主流的基于snowflake的從原理到實現與優化基本介紹完成,簡單做下小結。
方案 | 依賴 | 峰值TPS | 優化方案 |
原生snowflake | 無 | 409.6w | 無,存在時鐘回撥問題 |
美團leaf-snowflake | zookeeper | 409.6w | 自動化workerID分配,自旋等待時鐘,回撥則報錯 |
百度uid-generator | mysql | 600w+ | 自動化workerId分配,解決時鐘回撥問題,緩存環提升了生成性能 |
其實,目前基于雪花方式兩種優化方案基本上可以解決99.99%我們的分布式ID生成了,無論你要業務訂單號,還是業務唯一標識;當然從原理角度,我們還有另一種方案號段模式,
再回顧下這個圖,此文詳細描述了基于UUID的模式下的主流方案及原理,下一篇會講上半部分“自增ID”模式。



















Ubuntu環境配置)