kraken2去除污染
conda create -n kraken2
conda activate kraken2
conda install kraken2 -c bioconda
mkdir kraken2_outputkraken2 --db ../../kraken2_db/k2_pluspf_20250402/ --threads 8 --paired 250811_HS67EV0804_R1.fastq.gz 250811_HS67EV0804_R2.fastq.gz --use-names --report-zero-counts --report ./kraken2_output/sample.report --output ./kraken2_output/sample.kraken#######使用bracken查看species級別占比
bracken-build -d ../../../kraken2_db/k2_pluspf_20250402/ -t 8srun bracken -d ../../../kraken2_db/k2_pluspf_20250402/ -i sample.report -o sample.bracken -r 150 -l S
less sample_bracken.report
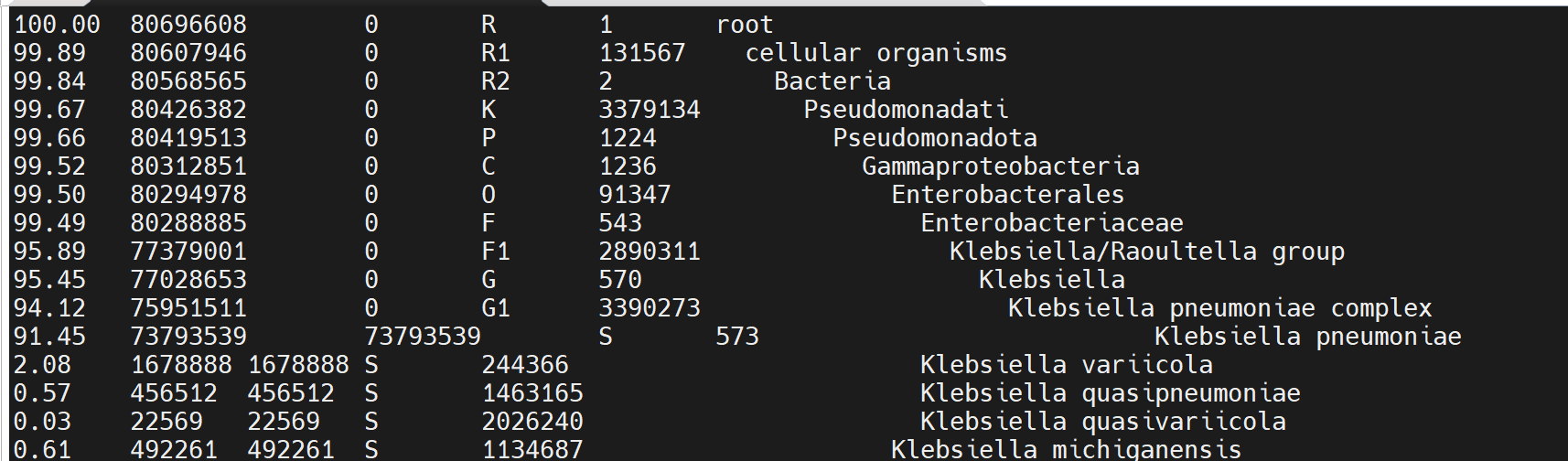
##############使用KrakenTools提取目標reads############
conda install KrakenTools -y -c biocondasrun extract_kraken_reads.py -k sample.kraken -s ../250811_HS67EV0804_R1.fastq.gz -s2 ../250811_HS67EV0804_R2.fastq.gz -o Kpn_573_R1.fastq -o2 Kpn_573_R2.fastq -t 573 --include-children --fastq-output --report sample.reportsample_bracken.report :? S(species)--573為taxid
#####fastp#######
srun fastp \-w 12 \ # 使用12個線程并行加速-i ./raw_data/${sample}_1.fq.gz \ # 輸入文件:R1-I ./raw_data/${sample}_2.fq.gz \ # 輸入文件:R2-o ./clean_data/${sample}_1.fastp.fq.gz \ # 輸出文件:清洗后的 R1-O ./clean_data/${sample}_2.fastp.fq.gz \ # 輸出文件:清洗后的 R2-f 10 \ # 對 R1 每條 read,切除前10個堿基-F 10 \ # 對 R2 每條 read,切除前10個堿基-n 10 \ # 允許最多10個N,否則丟棄-q 20 \ --dedup # 低于Q20的堿基視為低質量--detect_adapter_for_pe \ # 自動檢測并去除接頭(推薦)-h ./clean_data/${sample}.fastp.html \ # 輸出 HTML 報告-j ./clean_data/${sample}.fastp.json # 輸出 JSON 報告(方便統計/批處理)######fastqc質控#############參數----cov-cutoff可用于過濾contig##
srun fastqc HS67_1.clean.fq.gz HS67_2.clean.fq.gz -o clean_fastqc_report#########spades拼接#############
srun spades.py -1 A18GX092_1.clean.fq.gz -2 A18GX092_2.clean.fq.gz --isolate -o spades_output#############quast評估拼接質量#################
srun quast -t 16 -o quast_output spades_output/scaffolds.fasta
##質量評估標準:contig數目小于1000 , N50大于10bp 最小contig>200bp 評估污染:核苷酸ani平均一致性95% fastani 肺克GC含量為54-55%作業
#!/bin/bash
#SBATCH --job-name=spades_HS67 ? ? ? ?# 作業名稱
#SBATCH --nodes=1 ? ? ? ? ? ? ? ? ? ? # 需要的節點數
#SBATCH --ntasks=1 ? ? ? ? ? ? ? ? ? ?# 總任務數
#SBATCH --cpus-per-task=20 ? ? ? ? ? ?# 每個任務的CPU核數
#SBATCH --mem=80G ? ? ? ? ? ? ? ? ? ? # 內存需求
#SBATCH --output=spades_%j.out ? ? ? ?# 標準輸出日志
#SBATCH --error=spades_%j.err ? ? ? ? # 錯誤輸出日志# 運行SPAdes
spades.py -1 bac_HS67_1.clean.fq.gz -2 bac_HS67_2.clean.fq.gz --isolate -t 20 -o spades_out
概念解釋
Kmer
k-mer 就是從 reads 中截取的長度為 k 的連續小片段。
例如 read 序列:ATGCGT,如果 k=3,就有 ATG、TGC、GCG、CGT 四個 3-mer。組裝器(如 SPAdes)用這些 k-mer 構建 de Bruijn 圖,再拼接成 contigs。
k 值的大小 會直接影響組裝的碎片化程度、錯配率和連續性。
- 如果只用一個小 k(比如 21),裝配可能非常連續,但錯誤也多;
- 如果只用一個大 k(比如 77),重復區能拆開,但低覆蓋區會組裝不出來。
SPAdes 默認的 -k 21,33,55,77 表示用不同長度的 k-mer 分階段構建組裝圖:
小 k 保證敏感性,
大 k 提升連續性
N50
N50 = 一種衡量組裝連續性的統計量
把所有 contig 從長到短排序;依次把它們的長度加起來,直到累計長度達到總組裝長度的 50%;此時那個 contig 的長度,就是 N50。
舉例:
假設組裝結果有 5 條 contig,長度如下(單位:kb):
Contig1 = 200 ?
Contig2 = 150 ?
Contig3 = 80 ?
Contig4 = 40 ?
Contig5 = 30 ?
總長度 = 500 kb排序后累加:
Contig1 = 200 → 占 40%
Contig2 = 150 → 累計 350 → 占 70% ≥ 50%
所以 N50 = 150 kb。
解釋:一半以上的基因組長度,來自于長度 ≥ 150 kb 的 contigs。
越大越好:N50 大說明組裝越連續,contig 越長。
L50
達到總長度一半所需的 contig 數量
舉例:
設 contig 長度(kb):200, 150, 80, 40, 30;總長 = 500 kb。
從大到小累加:
200(占 40%)→ 未到 50%
200+150=350(占 70%)→ 首次 ≥50%
此時累計用了 2 條 contig,所以 L50=2
越小越好
L50 越小越好,說明少數長 contig 就能覆蓋一半基因組。
以下是一個細菌基因組拼裝完成后的quast報告:
可以看到total length為5.56Mb,largest contig為0.459Mb,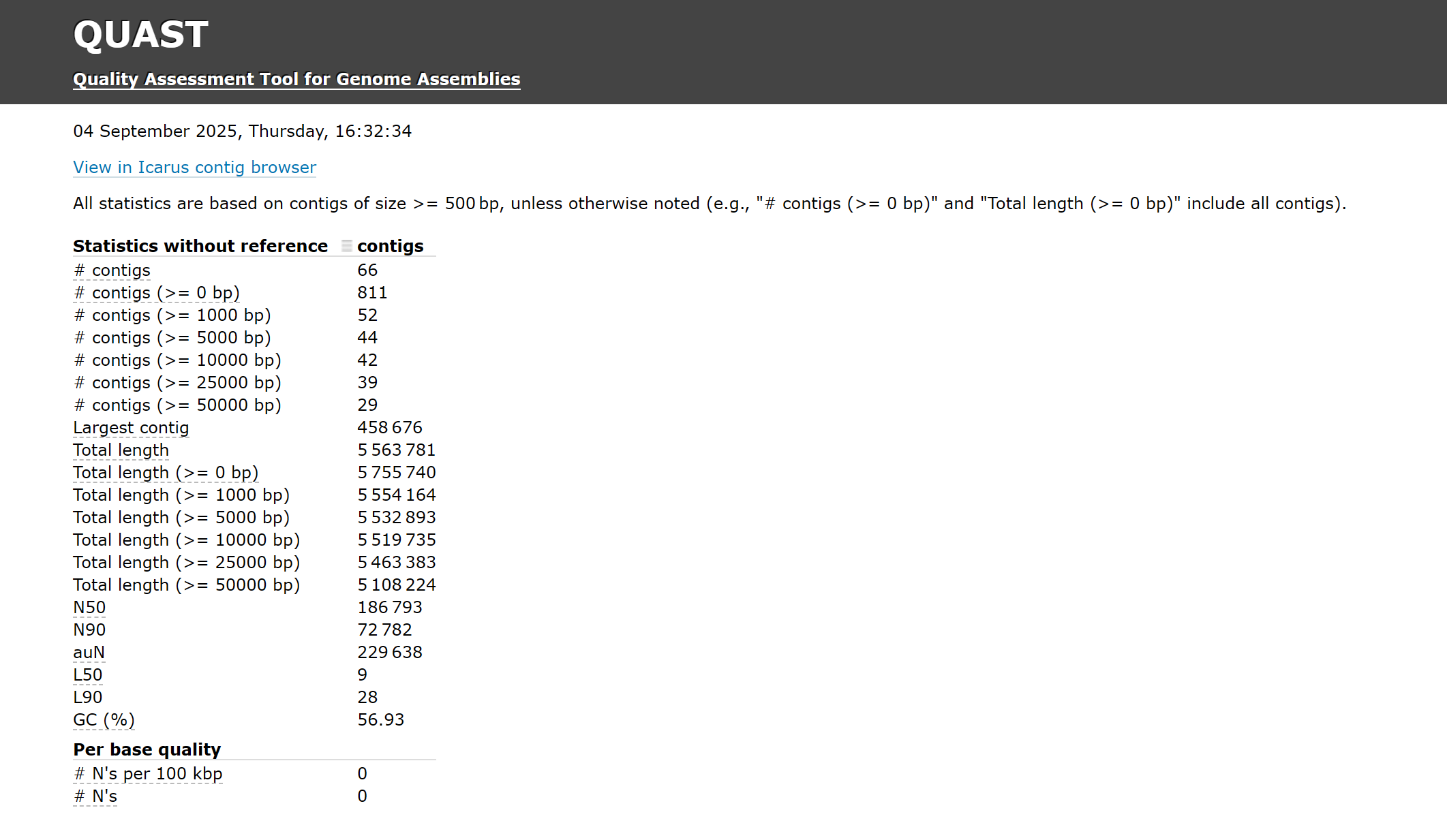
#############prokka注釋############
prokka spades_output/scaffolds.fasta --outdir prokka_output --prefix A18GX092 --kingdom Bacteria --locustag A18GX092 --compliant --force
注釋所得結果
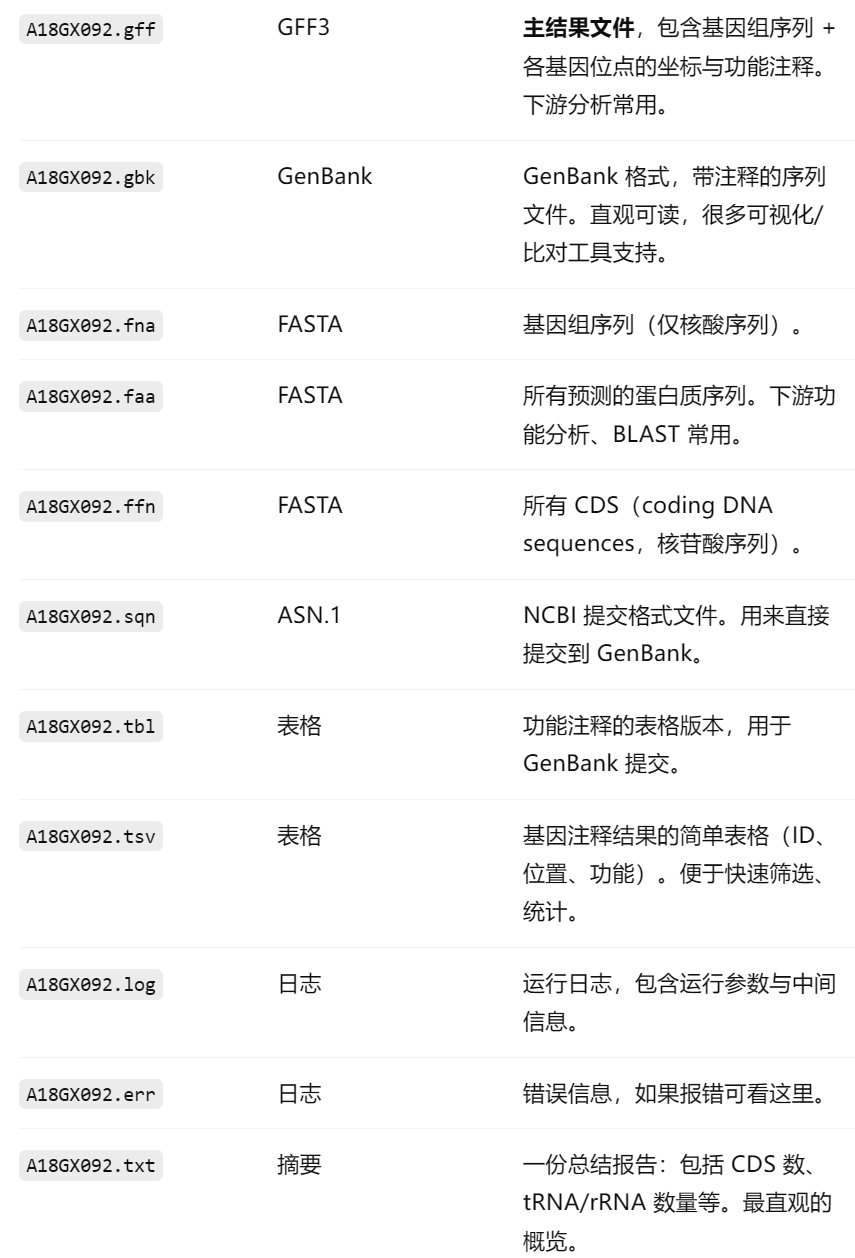
tsv文件包含內容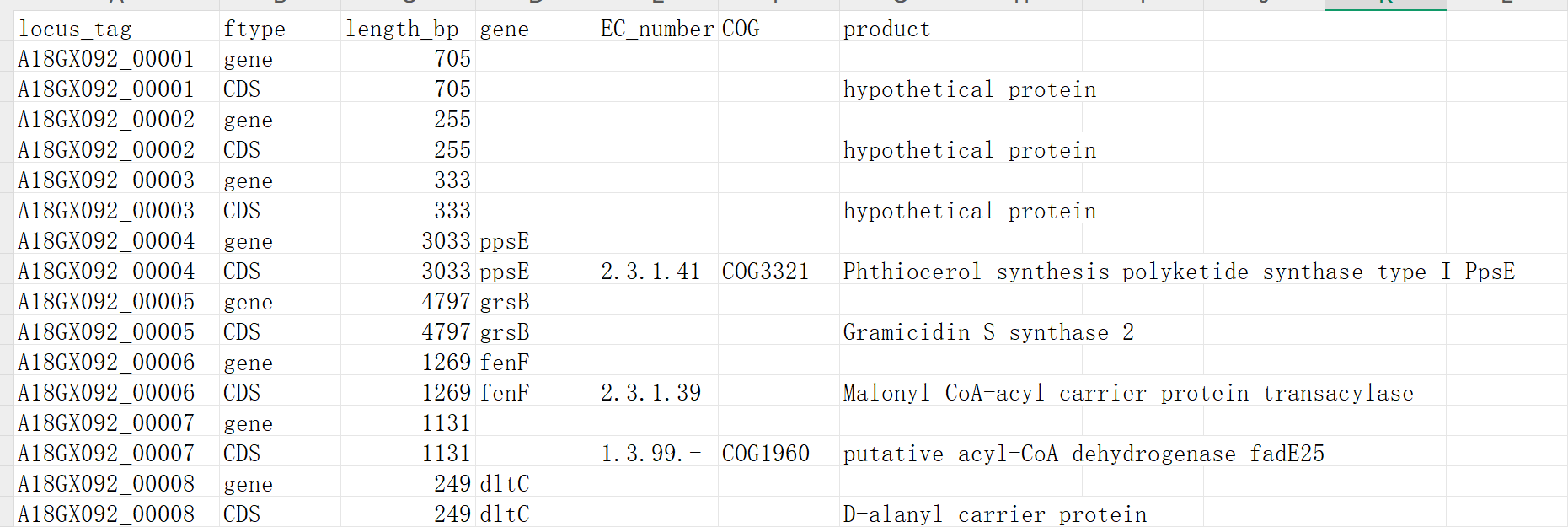
txt文件內容
gff文件內容
開頭
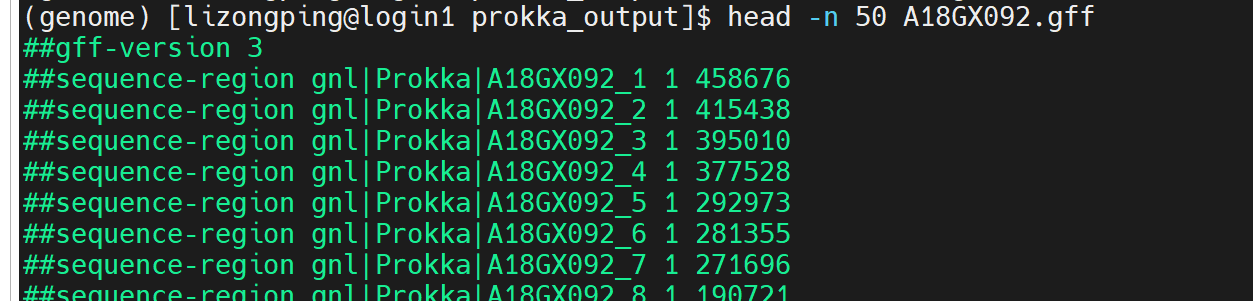
##gff-version 3→ 標準 GFF3 文件頭。
##sequence-region→ 定義每條 contig 的名稱和長度(比如A18GX092_1長度 458,676 bp)
中間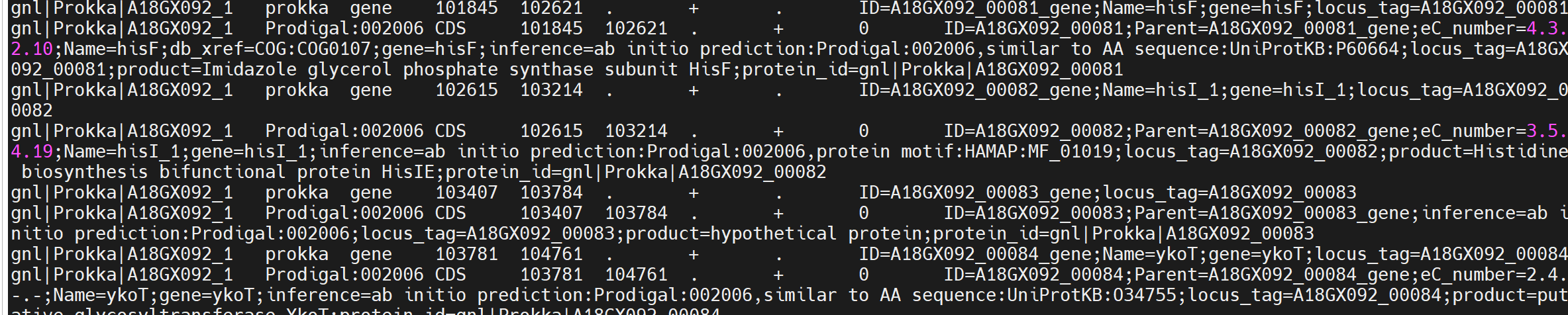
GFF 文件標準列(9 列)解釋:
- seqid:所在的 contig 名稱(如 A18GX092_1)。
- source:注釋來源,這里是 Prokka。
- type:特征類型(CDS, gene, rRNA, tRNA, misc_feature 等)。
- start:起始坐標。
- end:終止坐標。
- score:得分(一般用不到,常為 .)。
- strand:所在鏈,+ 或 -。
- phase:閱讀框,0/1/2(只對 CDS 有意義)。
如果 CDS 起點不同,phase 的值不同:
CDS 從 ATG 開始 → phase = 0 (對齊完整 codon)
CDS 從 ATG 開始 → phase = 2 (要跳過 2 個堿基,才能對齊完整 codon)
CDS 從 ATG 開始 → phase = 1 (要跳過 1 個堿基,才能對齊完整 codon)
- attributes:附加信息,如基因 ID、功能描述、EC/COG 等。
結尾

原始 contigs 的堿基序列,與 .fna、.fsa 內容相同







Ubuntu環境配置)

:xml.dom.minidom模塊高階使用方法)


)
)


的核心板)


