目錄
一、Apache Ozone是什么?
二、Ozone的誕生背景
三、Ozone的架構設計
1. 分層架構設計
2. Ozone Manager (OM)
3. Storage Container Manager (SCM)
4. DataNode
5. Raft協議應用
四、Ozone解決的關鍵問題
1. 元數據管理瓶頸
2. 小文件性能問題
3. 數據冗余與一致性保障
五、Ozone的關鍵特性
1. 強一致性
2. 高擴展性
3. 云原生友好
4. 安全可靠
5. 多協議支持
6. 高可用性
六、與同類產品的對比
1. HDFS
2. Amazon S3
3. Ceph
七、Ozone的部署與使用指南
1. 部署流程
2. 配置優化
3. 安全設置
4. 使用方法
5. 常見應用場景
八、總結與展望
?參考資料:
?
Apache Ozone是Apache Hadoop生態中的新一代分布式對象存儲系統,專為解決HDFS在擴展性和小文件處理方面的局限性而設計。作為面向技術開發人員的深度指南,本文將從基礎概念到架構設計,再到實際應用,全面解析Ozone的技術特性與價值。
Apache Ozone是一個基于Hadoop的可擴展、冗余和分布式對象存儲系統,設計用于處理海量小文件和對象存儲需求,同時提供與HDFS兼容的文件系統接口,使大數據應用無需修改即可無縫遷移。其核心創新在于分層架構設計,將元數據管理與數據存儲分離,突破了HDFS的元數據瓶頸,支持從數十億到千億級的對象存儲能力,為現代大數據和云原生應用提供了更靈活、可擴展的存儲解決方案。

一、Apache Ozone是什么?
Apache Ozone是一種分布式對象存儲系統,屬于Apache Hadoop項目的一部分。它最初設計是為了解決HDFS在處理海量小文件時的性能問題,但隨著發展,它已成為一個獨立的對象存儲解決方案,支持多種協議和接口。
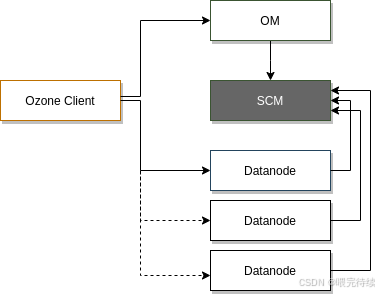
從存儲模型來看,Ozone采用分層結構,包括Volume(卷)、Bucket(桶)和Key(鍵)三個層次。Volume類似于HDFS中的命名空間,由管理員創建和管理;Bucket類似于目錄,用戶可以在Volume下創建任意數量的Bucket;Key則類似于文件,存儲實際的數據。這種分層模型使得Ozone能夠高效管理海量對象,同時保持與HDFS的兼容性。
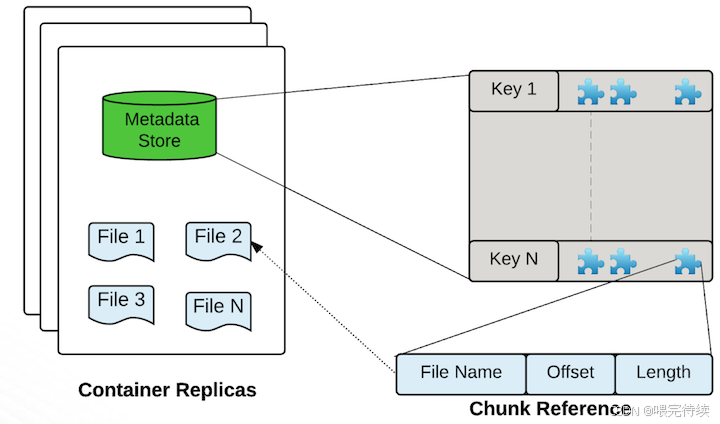
Ozone的核心存儲單元是Container(容器),默認大小為5GB,可以包含多個Block(塊),而每個Block又由多個Chunk(塊碎片)組成。這種設計使得Ozone能夠在管理大量小文件時,減少元數據開銷,提高系統性能。
二、Ozone的誕生背景
Ozone的誕生源于HDFS在擴展性和小文件處理方面的局限性。HDFS作為Hadoop生態系統的核心組件,雖然在處理大文件時表現出色,但在面對海量小文件時卻面臨嚴重挑戰。
HDFS的元數據管理采用集中式架構,所有元數據都存儲在NameNode的內存中,這導致了兩個主要問題:首先,文件數量受到Java堆內存的限制,通常最多只能支持4億到5億個文件;其次,NameNode的單點故障風險較高,難以實現真正的高可用。
隨著大數據應用的發展,尤其是日志、事件流、元數據等場景的普及,存儲系統需要處理越來越多的小文件,而HDFS在這種場景下性能顯著下降。此外,Hadoop生態系統的擴展需求也促使社區尋找更靈活、可擴展的存儲解決方案。
Ozone正是在這一背景下誕生,它通過分層架構設計,將元數據管理與數據存儲分離,解決了HDFS的元數據瓶頸問題,同時提供對象存儲接口,滿足了云原生應用的需求。
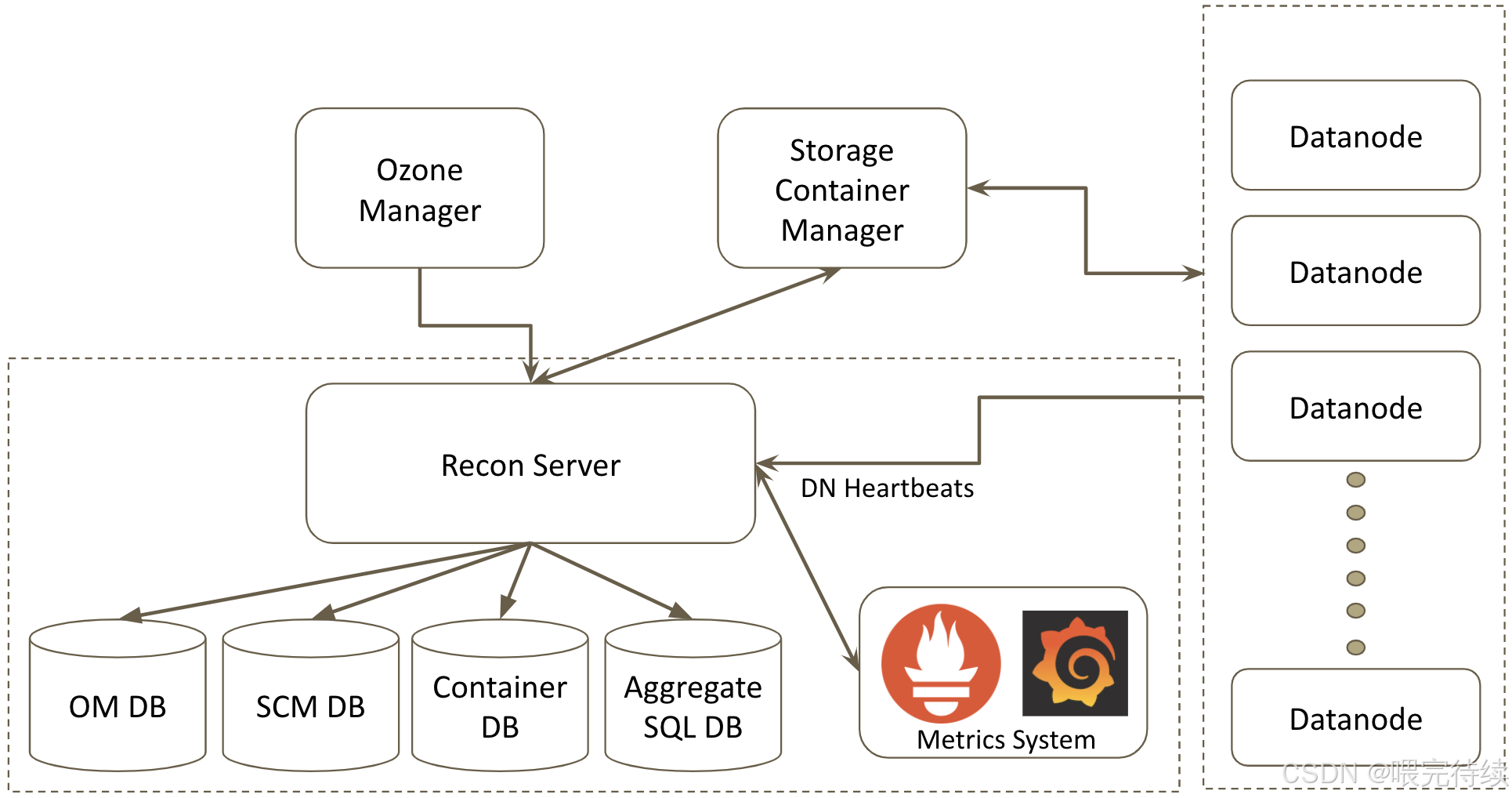
三、Ozone的架構設計
Apache Ozone采用分層架構設計,主要包括協議層、元數據層和數據層,這種設計使得系統能夠獨立擴展不同組件,滿足大規模存儲需求。
1. 分層架構設計
Ozone的分層架構可以分為以下三個層次:
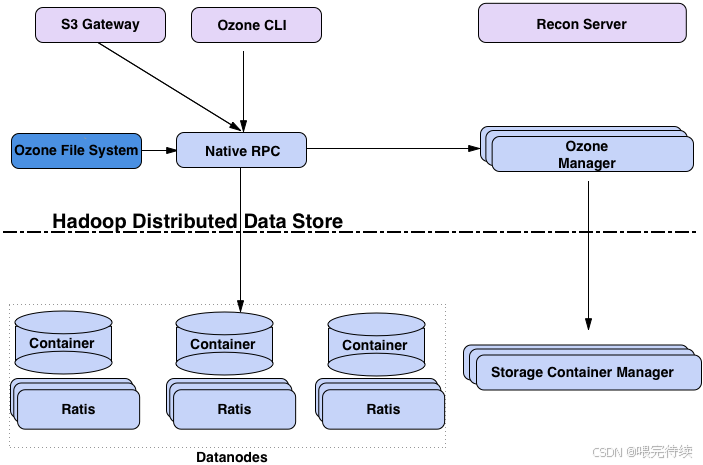
協議層:提供多種訪問協議,包括S3、NFS和POSIX等,使Ozone能夠與各種應用程序集成。S3 Gateway支持Amazon S3 API,使Ozone能夠與AWS生態兼容;而OzoneFileSystem則提供與HDFS兼容的API,使Hadoop應用無需修改即可使用Ozone。
元數據層:包括Ozone Manager(OM)和Storage Container Manager(SCM)兩個組件,分別負責管理對象存儲元數據和容器生命周期。
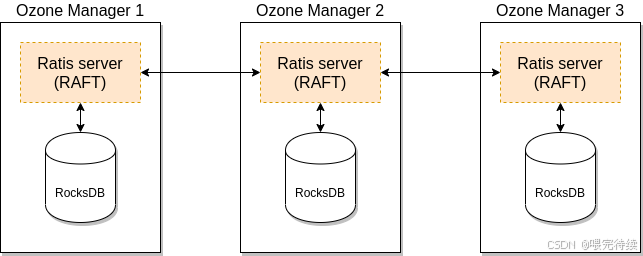
數據層:由DataNode組成,負責存儲實際數據。DataNode通過Raft協議(由Apache Ratis實現)管理數據副本的一致性,確保數據的高可用性和強一致性。
此外,Ozone還包含Recon Server作為監控和管理組件,用于集群健康監控、元數據修復和性能分析。
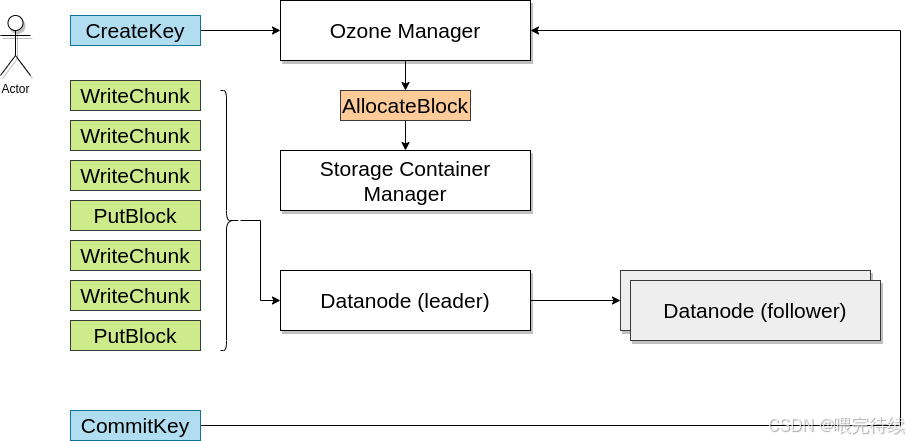
2. Ozone Manager (OM)
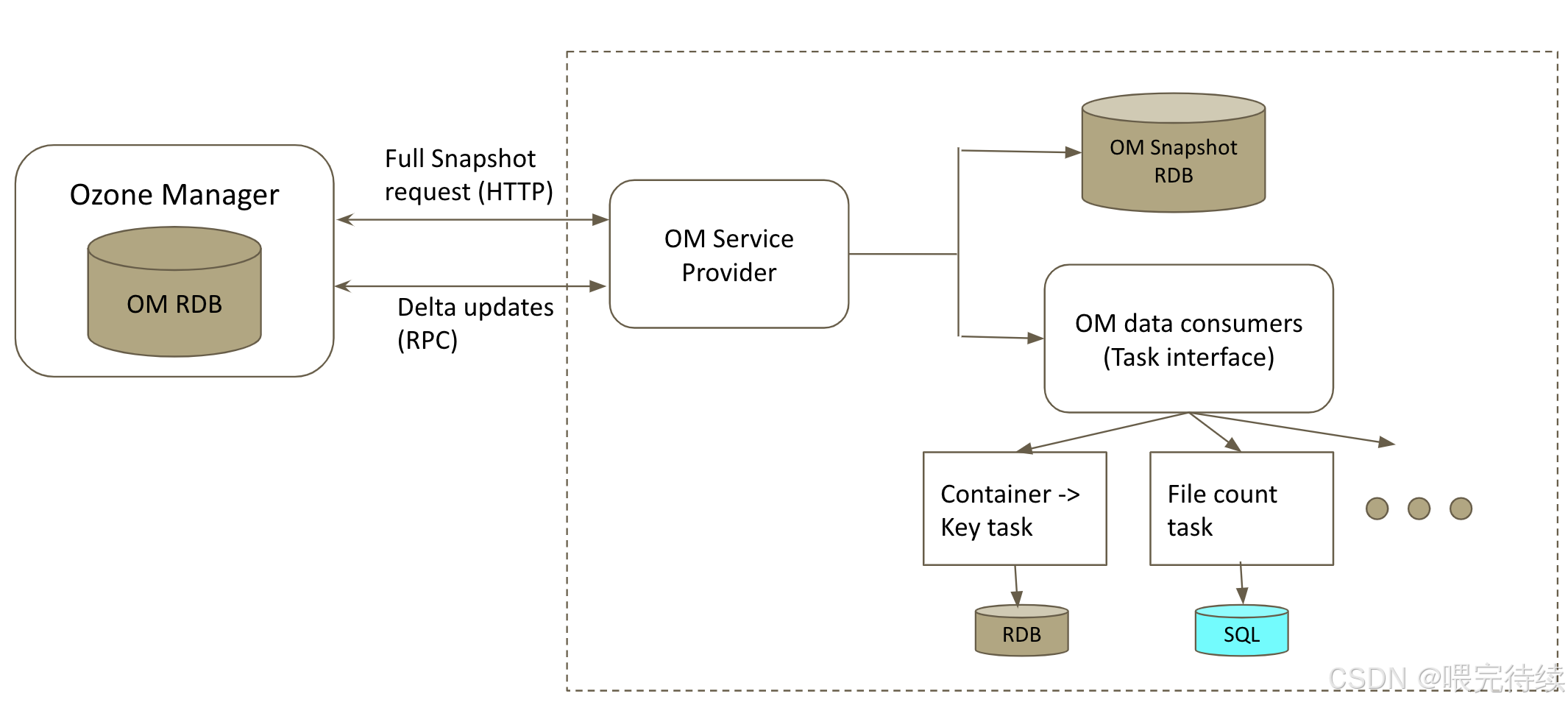
OM是Ozone的元數據管理組件,主要負責管理Volume、Bucket和Key的命名空間元數據。與HDFS的NameNode不同,OM不將所有元數據加載到內存中,而是使用RocksDB作為持久化存儲,僅將高頻訪問的元數據緩存在內存中,大大提高了元數據的管理能力和擴展性。
OM的核心功能包括:
- Volume和Bucket的創建、刪除和管理
- Key的元數據管理,如大小、創建時間等
- 與客戶端交互,處理對象存儲請求
OM的高可用性可以通過多實例+ZooKeeper實現,確保元數據管理的容災能力。
3. Storage Container Manager (SCM)
SCM是Ozone的容器管理組件,主要負責管理Container、Block和副本,以及數據節點的生命周期。SCM作為證書頒發機構(CA),為集群中的每個服務頒發身份證書,支持網絡層的雙向認證(mTLS)。
SCM的核心功能包括:
- 創建和管理Container
- 將Block分配給適當的數據節點
- 跟蹤所有Block的副本狀態
- 當數據節點或磁盤故障時,啟動副本修復
- 為集群組件頒發證書
SCM的高可用性通常通過部署多個SCM節點實現,建議在生產環境中部署三個SCM節點,以提高系統的容錯能力。
4. DataNode
DataNode是Ozone的數據存儲組件,負責存儲實際數據。與HDFS的DataNode類似,Ozone的DataNode也負責處理數據的讀寫請求,但有所不同的是,Ozone的DataNode以Container為單位上報狀態,而不是每個Block,大大減少了心跳和復制管理的開銷。
DataNode的核心功能包括:
- 存儲和管理Container中的數據
- 處理客戶端的讀寫請求
- 參與Raft協議,確保數據副本的一致性
- 上報容器和節點狀態給SCM
5. Raft協議應用
Ozone使用Apache Ratis實現的Raft協議來保證數據的一致性和高可用性。Raft協議是一種分布式一致性算法,用于管理多個節點之間的數據同步。
在Ozone中,Raft協議應用于數據層的Pipeline(即容器副本間的復制)。每個Container的副本分布在不同的DataNode上,形成一個Raft Group。當客戶端寫入數據時,數據首先寫入Leader節點,然后同步到Follower節點,只有當大多數副本成功寫入后,客戶端才會收到寫入成功的響應,從而保證數據的強一致性。
Raft協議的三個角色——Leader、Follower和Candidate——確保了在節點故障時能夠快速選舉新的Leader,維持系統的可用性。
四、Ozone解決的關鍵問題
Apache Ozone主要解決了HDFS在以下方面的局限性:
1. 元數據管理瓶頸
HDFS的NameNode將所有元數據加載到內存中,導致文件數量受到Java堆內存的限制,通常最多只能支持4億到5億個文件。而Ozone通過將元數據管理分層,OM管理Volume、Bucket和Key的命名空間元數據,SCM管理Container、Block和副本的元數據,大大提高了元數據的管理能力和擴展性。
此外,Ozone使用RocksDB作為持久化存儲,而不是將所有元數據加載到內存中,進一步提高了系統的擴展性。OM僅將高頻訪問的元數據緩存在內存中,減少了內存壓力。
2. 小文件性能問題
HDFS在處理小文件時性能顯著下降,主要原因是每個文件對應一個或多個Block,每個Block都需要元數據管理。當文件數量激增時,NameNode的元數據管理能力成為瓶頸。
Ozone通過引入Container作為存儲單元,將多個Block聚合到一個Container中,減少了元數據管理的開銷。DataNode以Container為單位上報狀態,而不是每個Block,大大降低了心跳和復制管理的開銷。
3. 數據冗余與一致性保障
Ozone通過SCM管理數據副本,確保數據的冗余存儲和高可用性。當數據節點或磁盤故障時,SCM能夠檢測到并啟動相應的數據節點復制缺失的塊,以確保數據的完整性。
Ozone使用Raft協議保證數據的一致性,確保客戶端在寫入數據時,數據能夠同步到大多數副本中,從而保證數據的強一致性和高可用性。
五、Ozone的關鍵特性
Apache Ozone具有以下關鍵特性,使其成為處理海量數據的理想選擇:
1. 強一致性
Ozone提供強一致性的分布式存儲,通過Raft協議確保數據在多個副本之間同步。這種一致性保證簡化了應用程序的設計,避免了數據不一致帶來的復雜問題。
2. 高擴展性
Ozone采用分層架構設計,可以獨立擴展元數據層和數據層,支持從數十億到千億級的對象存儲能力。這種擴展性使得Ozone能夠適應不斷增長的數據存儲需求。
3. 云原生友好
Ozone原生支持S3 API,能夠與AWS生態兼容,同時也能在容器化環境(如Kubernetes和YARN)中高效運行。這種云原生友好性使得Ozone能夠適應現代微服務架構的需求。
4. 安全可靠
Ozone與Kerberos基礎設施集成,提供細粒度的權限控制。SCM作為證書頒發機構,為集群中的每個服務頒發身份證書,支持網絡層的雙向認證(mTLS)。Ozone還支持透明數據加密(TDE)和網絡加密,確保數據的安全性。
5. 多協議支持
Ozone提供多種訪問協議,包括S3、HDFS、NFS和POSIX等,使各種應用程序能夠無縫集成。這種多協議支持使得Ozone能夠在不改變現有應用程序的情況下,提供更靈活、可擴展的存儲解決方案。
6. 高可用性
Ozone通過多實例+ZooKeeper實現OM的高可用性,同時建議部署多個SCM節點(通常三個)來提高系統的容錯能力。這種高可用性設計確保了即使在節點故障的情況下,系統仍然能夠正常運行。
六、與同類產品的對比
在大數據存儲領域,Apache Ozone與以下產品有相似之處,但也有其獨特優勢:
1. HDFS
HDFS是Hadoop生態中的傳統文件系統,與Ozone相比,有以下區別:
| 特性 | HDFS | Ozone |
|---|---|---|
| 元數據管理 | NameNode內存存儲 | OM(RocksDB)+ SCM分離管理 |
| 文件數量上限 | 約4-5億 | 百億到千億級 |
| 小文件性能 | 差 | 好 |
| 接口支持 | HDFS API | S3 API + HDFS API |
| 擴展性 | 受NameNode限制 | 分層架構獨立擴展 |
HDFS的元數據管理采用集中式架構,所有元數據都存儲在NameNode的內存中,導致文件數量受到限制。而Ozone通過分層架構和持久化存儲,突破了這一限制,支持更海量的對象存儲。
2. Amazon S3
Amazon S3是AWS提供的對象存儲服務,與Ozone相比,有以下區別:
| 特性 | Amazon S3 | Ozone |
|---|---|---|
| 部署環境 | 云環境 | Hadoop生態 + 云原生 |
| 兼容性 | S3 API | S3 API + HDFS API |
| 數據一致性 | 最終一致性 | 強一致性 |
| 集群管理 | AWS托管 | 需要自行管理 |
| 成本 | 按使用付費 | 自建集群成本 |
Amazon S3是云原生的對象存儲服務,提供最終一致性的數據訪問,適合云環境下的大規模數據存儲。而Ozone則更注重強一致性和與Hadoop生態的兼容性,適合需要與Hadoop應用深度集成的場景。
3. Ceph
Ceph是開源的分布式存儲系統,與Ozone相比,有以下區別:
| 特性 | Ceph | Ozone |
|---|---|---|
| 存儲模型 | 對象、塊、文件 | 對象(Volume/Bucket/Key) |
| 元數據管理 | 元數據與數據混合存儲 | OM(RocksDB)+ SCM分離管理 |
| 與Hadoop生態集成 | 需要適配 | 原生支持 |
| 數據一致性 | 最終一致性 | 強一致性 |
| 集群管理 | Ceph管理層 | HDDS管理層 |
Ceph是一個通用的分布式存儲系統,支持對象、塊和文件三種存儲模型,但需要額外的適配才能與Hadoop生態集成。而Ozone則專為Hadoop生態設計,原生支持HDFS API,使得Hadoop應用可以無縫遷移。
七、Ozone的部署與使用指南
1. 部署流程
部署Apache Ozone需要以下步驟:
首先,準備環境。確保所有節點已安裝Java JDK(8或更高版本),并配置好網絡環境。
然后,安裝Ozone。可以從Apache官網下載最新版本的Ozone二進制包,并解壓到指定目錄:
wget https://dl.apache.org/ozone/ozone-<version>.tar.gz
tar zxvf ozone-<version>.tar.gz
cd ozone-<version>接下來,生成配置文件。使用ozone genconf命令生成基礎配置文件:
bin/ozone genconf etc/hadoop然后,配置ozone-site.xml。根據集群需求,設置以下關鍵參數:
<property><name>ozone.om.address</name><value><OM主機IP></value><tag>OM, REQUIRED</tag>
</property><property><name>ozone.metadata.dirs</name><value><元數據存儲路徑></value><tag>OZONE, OM, SCM, CONTAINER, STORAGE, REQUIRED</tag>
</property><property><name>ozone.scm.client.address</name><value><SCM主機IP>:9860</value><tag>OZONE, SCM, REQUIRED</tag>
</property><property><name>ozone.scm.datanode.id.dir</name><value><數據節點存儲路徑></value>
</property>最后,啟動服務。使用ozone.sh start all命令啟動所有服務 :
bin/ozone.sh start all2. 配置優化
在生產環境中,Ozone的性能可以通過以下參數優化:
容器大小:ozone.scm.container.size默認為5GB,可以根據小文件場景調整為更小的值,如2GB或1GB,以減少尋址開銷。
塊大小:ozone.scm.block.size默認為256MB,對于小文件密集的場景,可以適當減小塊大小,如64MB或32MB。
安全模式節點數:hdds.scm.safemode.min.datanode設置安全模式所需的最小數據節點數,默認為3,可以根據集群規模調整。
SCM心跳間隔:默認為30秒,可以根據網絡狀況和負載情況調整,如增加到60秒以減少網絡開銷。
JVM參數調優:為OM和SCM設置適當的堆大小和垃圾回收算法:
export OZONE_OM_heapsize=8192m
export SCM_heapsize=4096mexport OZONE_JVM_FLAGS="$OZONE_JVM_FLAGS -XX:+UseG1GC"
export OZONE_JVM_FLAGS="$OZONE_JVM_FLAGS -Xlog:gc*:file=/var/log/ozone/gc.log:time,uptime,pid,tid"3. 安全設置
Ozone的安全設置主要包括Kerberos認證和證書管理:
首先,配置Kerberos環境。在ozone-site.xml中設置以下參數:
<property><name:ozone.security.enabled</name><value>TRUE</value>
</property><property><name:hadoop.security authentication</name><value>kerberos</value>
</property>然后,為每個組件創建Kerberos Principal和Keytab文件:
kadmin.local -q "addprinc ozone/om@REALM"
kadmin.local -q "addprinc ozone/s cm@REALM"
kadmin.local -q "addprinc ozone/datanode@REALM"最后,配置krb5.conf文件,確保所有組件能夠正確解析Kerberos Principal。
4. 使用方法
Ozone可以通過多種方式使用:
命令行接口:使用ozone命令行工具創建Volume、Bucket和Key:
ozone sh volume create /volume
ozone sh bucket create /volume/bucket
ozone sh key create /volume/bucket/keyS3 API:通過Ozone S3 Gateway訪問Ozone,使用AWS SDK或命令行工具:
aws s3 mb s3://bucket.volume --region us-east-1
aws s3 cp /local/file s3://bucket.volume/HDFS API:將Ozone作為HDFS的替代品使用,無需修改現有Hadoop應用:
<property><name>fs.o3fs.impl</name><value>org.apache.hadoop fs.ozone.OzoneFileSystem</value>
</property><property><name>fs.defaultFS</name><value>o3fs://bucket.volume</value>
</property>Java客戶端:使用Hadoop API操作Ozon
Configuration conf = new Configuration();
conf.set("fs.defaultFS", "o3fs://bucket.volume");FileSystem fs =FileSystem.get(conf);
Path path = new Path("o3fs://bucket.volume/test");
fs開創性地CreateNewFile(path);Python客戶端:使用pyarrow操作Ozone:
import pyarrow as pa# 配置Ozone連接信息
ozone_config = {"ozoneomaddress": "<OM主機IP>:9861","ozonebucketname": "bucket","ozonevolumename": "volume"
}# 創建Ozone文件系統
fs = paarrow fs.OzoneFileSystem(ozone_config)# 創建文件并寫入數據
with fs.open("o3fs://bucket.volume/test", "w") as f:f.write("Hello Ozone!")5. 常見應用場景
Apache Ozone適用于多種大數據存儲場景:
Hadoop生態應用:如Hive、Spark、YARN/MR等大數據應用可以在不修改代碼的情況下直接使用Ozone作為存儲系統。Hive可以將元數據存儲在Ozone中,提高元數據管理的效率。
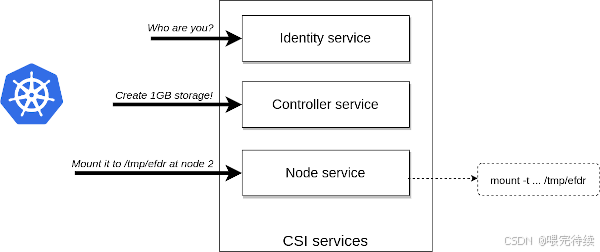
云原生應用:Ozone支持S3 API,可以與云原生應用集成。可以使用Ozone作為Kubernetes的持久化存儲,通過Ozone CSI驅動實現動態卷供應。
小文件密集場景:如日志、事件流、元數據等需要存儲大量小文件的場景。Ozone通過Container作為存儲單元,將多個Block聚合到一個Container中,大大提高了小文件的存儲效率。
混合云存儲:Ozone可以部署在本地數據中心和云環境中,提供一致的存儲接口和管理體驗。
高可用存儲:Ozone通過多實例+ZooKeeper實現OM的高可用性,同時建議部署多個SCM節點,確保數據的高可用性和一致性。
八、總結與展望
Apache Ozone作為Hadoop生態中的新一代分布式存儲系統,通過分層架構設計和Raft協議應用,解決了HDFS在擴展性和小文件處理方面的局限性。它不僅提供了與HDFS兼容的文件系統接口,還支持S3等云原生接口,為大數據應用提供了更靈活、可擴展的存儲解決方案。
Ozone的核心價值在于其分層架構和強一致性設計,使其能夠支持從數十億到千億級的對象存儲能力,同時保證數據的高可用性和一致性。這種設計使得Ozone成為處理海量數據的理想選擇,尤其是在小文件密集的場景下。
未來,隨著大數據應用的不斷發展,Ozone可能會在以下方面進一步改進:
性能優化:通過Multi-Raft等技術提高數據節點的吞吐量,優化寫入性能。
功能擴展:支持更多類型的存儲協議和接口,如NFS和POSIX,提高與各種應用程序的兼容性。
云原生集成:進一步優化與Kubernetes等云原生平臺的集成,提供更便捷的部署和管理體驗。
企業級功能:增加更多企業級功能,如數據壓縮、加密、備份和災難恢復,提高系統的安全性和可靠性。
對于技術開發人員來說,Apache Ozone提供了一個強大而靈活的存儲解決方案,值得深入探索和應用。無論是替換HDFS,還是作為云原生應用的存儲后端,Ozone都能為大數據應用提供更高效、可擴展的存儲支持。
?參考資料:
- Apache Ozone 文檔
- Apache Ozone 源碼
?本博客專注于分享開源技術、微服務架構、職場晉升以及個人生活隨筆,這里有:
📌 技術決策深度文(從選型到落地的全鏈路分析)
💭 開發者成長思考(職業規劃/團隊管理/認知升級)
🎯 行業趨勢觀察(AI對開發的影響/云原生下一站)
關注我,每周日與你聊“技術內外的那些事”,讓你的代碼之外,更有“技術眼光”。
日更專刊:
🥇 《Thinking in Java》 🌀 java、spring、微服務的序列晉升之路!
🏆 《Technology and Architecture》 🌀 大數據相關技術原理與架構,幫你構建完整知識體系!關于博主:
🌟博主GitHub
🌞博主知識星球
?
?











Ubuntu環境配置)

:xml.dom.minidom模塊高階使用方法)


)
)

