目錄
一、Apache Kafka是什么
二、Kafka的誕生背景
三、Kafka的架構設計
四、Kafka解決的技術問題
五、Kafka的關鍵特性
六、Kafka與其他消息隊列系統的對比
七、Kafka的工作原理
八、Kafka的部署與使用方法
1. 集群部署
2. 生產者與消費者配置
3. 安全配置
4. 監控與管理
5. 客戶端最佳實踐
九、Kafka的最佳實踐與調優
1. 集群調優
2. 性能調優
3. 安全實踐
4. 集成方案
十、Kafka的典型應用場景
1. 日志收集與傳輸
2. 實時監控與告警
3. 數據管道與ETL
4. 消息傳遞與微服務通信
5. 實時分析與處理
十一、Kafka的局限性及解決方案
十二、總結與展望
?參考資料:
Apache Kafka是一種高性能的分布式流處理平臺,最初由LinkedIn于2010年開發,2011年開源,2012年捐贈給Apache基金會。作為現代大數據生態系統中的核心組件,Kafka不僅是一個消息隊列系統,更是一個統一的分布式流數據處理平臺,能夠高效地處理海量實時數據流。Kafka以其高吞吐量、低延遲、持久化存儲和分布式架構的特性,在日志收集、實時監控、數據管道和事件驅動架構等領域得到廣泛應用。

一、Apache Kafka是什么
Apache Kafka是一種分布式發布-訂閱消息系統,設計上結合了消息隊列和發布-訂閱兩種模型的優勢。在Kafka中,數據以消息流的形式存在,生產者將消息發布到主題(Topic),消費者訂閱主題并消費消息。Kafka的核心設計思想是將消息視為一種持久化的數據流,而非簡單的臨時消息傳遞,這種設計使其在大數據生態系統中扮演著關鍵角色。
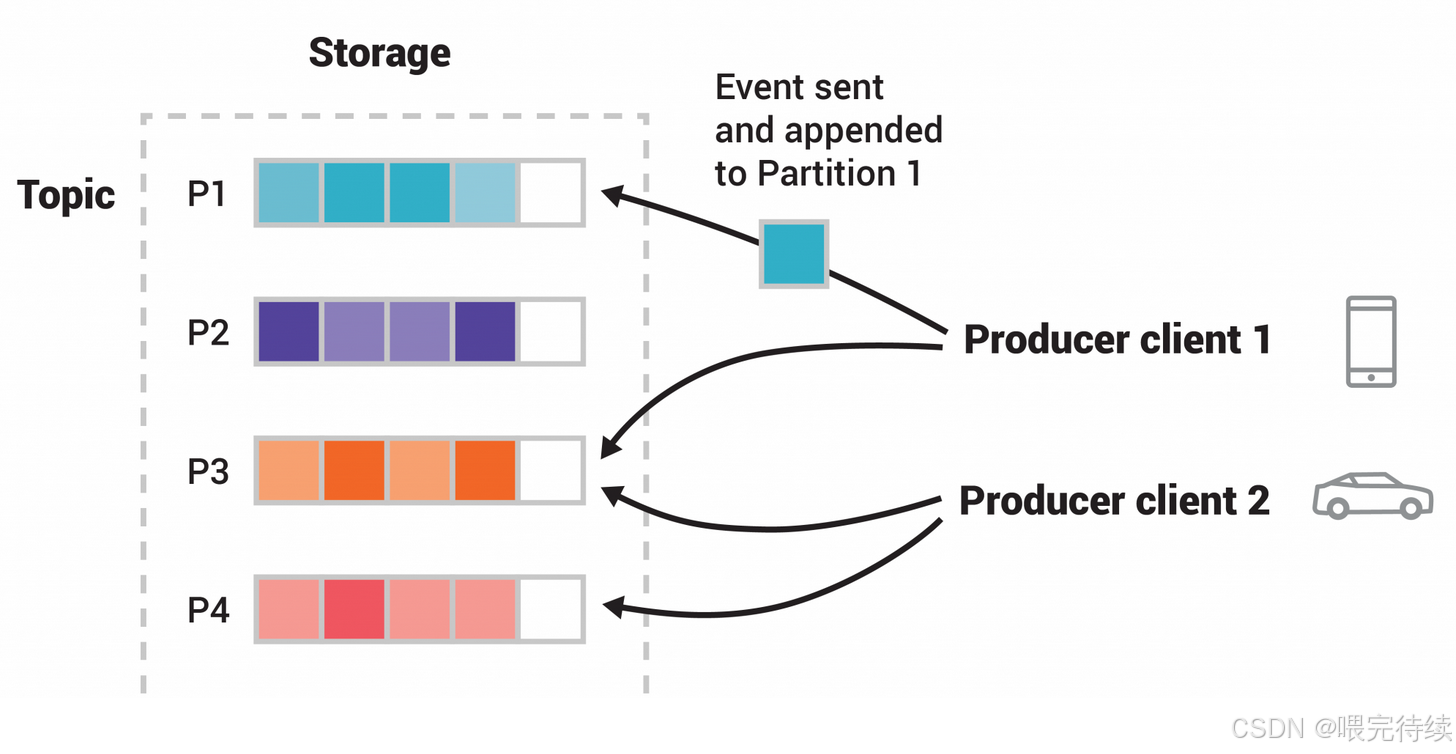
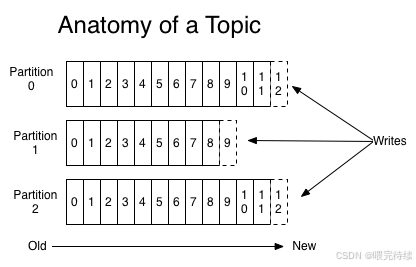
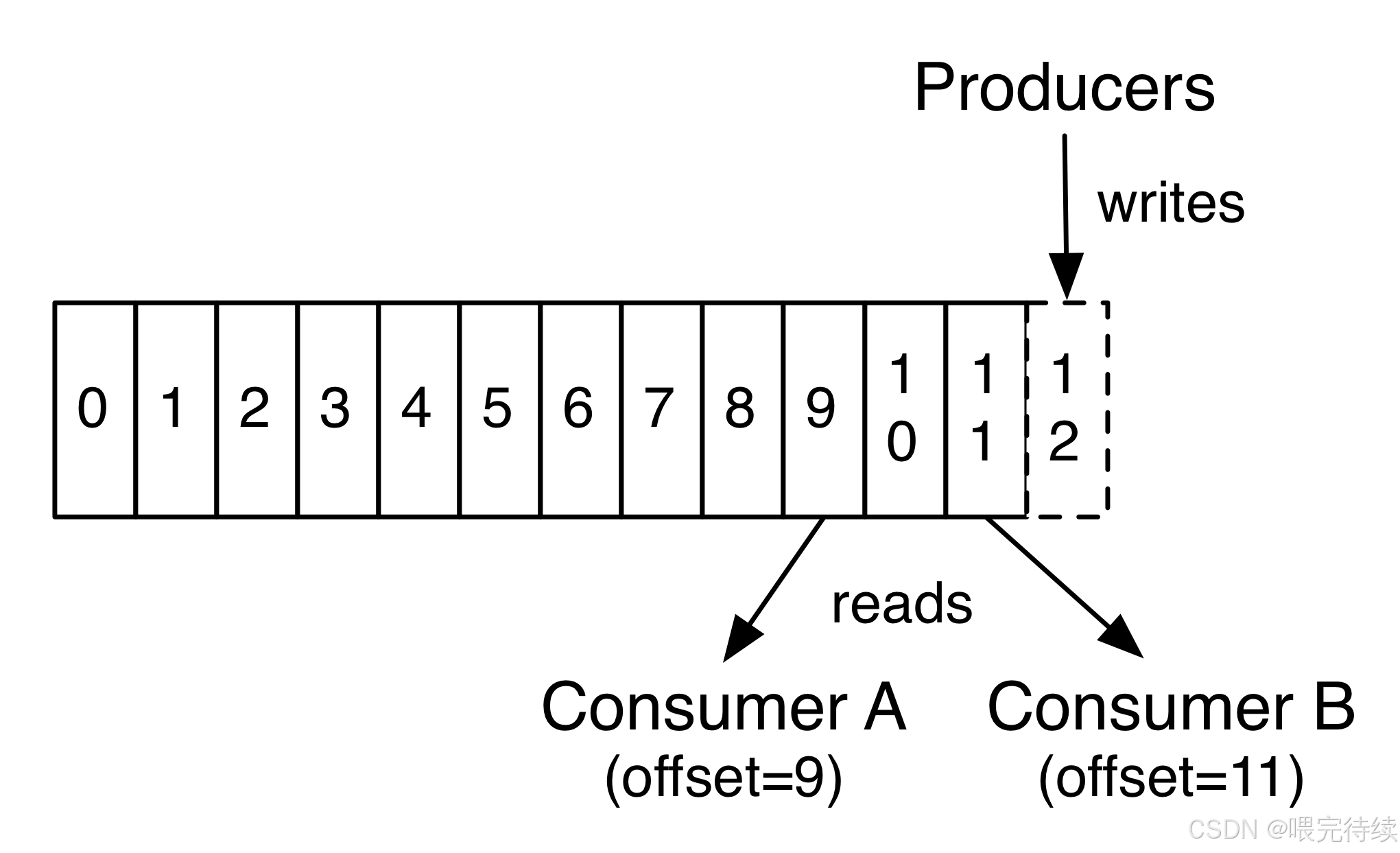
Kafka的數據結構采用分區日志模型,每個主題被劃分為多個分區(Partition),每個分區是一個有序、不可變的消息序列,按順序追加到提交日志文件中。這種設計使得Kafka能夠同時支持高吞吐量和消息持久化,消息即使未被消費也能長期保留。每個分區的消息都有一個稱為偏移量(Offset)的序列化編號,用于唯一標識消息在分區中的位置。
Kafka的架構簡單而強大,主要由五個組件構成:Producer(生產者)、Broker(消息代理)、Consumer(消費者)、Topic(主題)和Partition(分區) 。生產者負責發布消息,Broker負責存儲和轉發消息,Consumer負責消費消息,Topic是對消息的分類,而Partition則是消息的物理存儲單元。這種設計使得Kafka能夠在單個集群中同時處理數十萬甚至百萬級的消息讀寫,成為處理大規模數據流的理想選擇。
二、Kafka的誕生背景
Kafka的誕生源于LinkedIn在2010年面臨的大規模數據處理挑戰。當時,LinkedIn需要處理海量用戶活動數據和日志,傳統的消息隊列系統如ActiveMQ和RabbitMQ在吞吐量和擴展性方面無法滿足需求。LinkedIn的工程師團隊發現,現有的消息系統在處理大規模數據流時存在明顯的性能瓶頸,尤其是在消息持久化和高并發讀寫方面。
LinkedIn最初開發Kafka是為了構建一個統一的實時數據管道,能夠將用戶活動數據和運營日志高效地收集、存儲和傳輸。這一需求催生了Kafka的核心設計理念:將消息視為一種持久化的數據流,而非簡單的臨時消息傳遞。這種設計理念使得Kafka能夠在保證低延遲的同時,提供高吞吐量和持久化存儲能力。
2011年,LinkedIn將Kafka開源,2012年捐贈給Apache基金會,成為Apache頂級項目。此后,Kafka迅速在各大互聯網公司和大數據生態系統中得到廣泛應用。如今,Kafka已成為分布式流處理領域的標準解決方案,被全球數千家企業采用。
三、Kafka的架構設計
Kafka的架構設計簡潔而高效,主要由以下幾個核心組件構成:
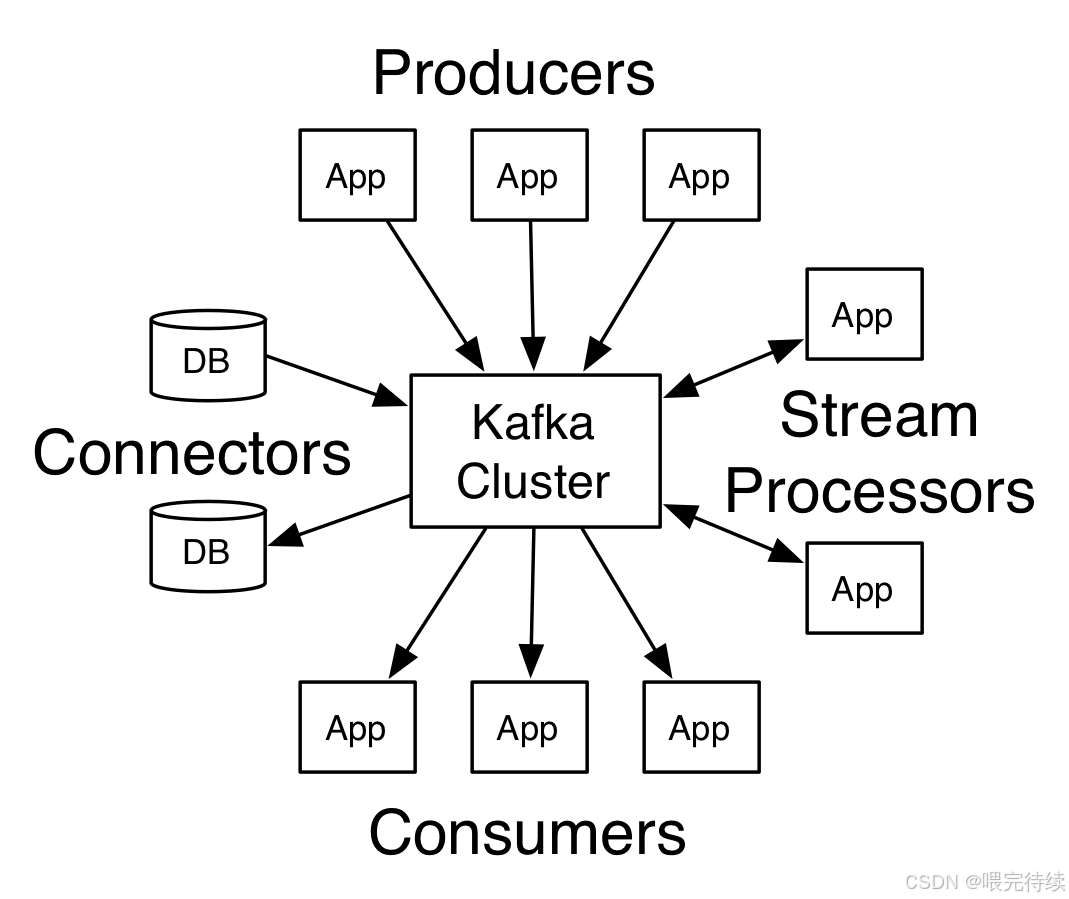
Broker集群:Kafka集群由多個Broker組成,每個Broker是一個獨立的服務器節點,負責存儲和轉發消息。Broker之間通過TCP協議通信,集群中的節點平等協作,沒有主從之分 。
Topic與Partition:消息按主題(Topic)分類,每個Topic可以劃分為多個分區(Partition)。分區是Kafka實現高吞吐量和并行處理的關鍵機制。每個分區是一個有序的、不可變的消息序列,消息按順序追加到提交日志中。這種設計使得Kafka能夠在保證消息順序的同時,實現高并發處理。
Producer與Consumer:生產者(Producer)負責將消息發布到Topic,消費者(Consumer)負責從Topic訂閱并消費消息。Kafka采用Pull模式,消費者根據自身消費能力控制消息拉取速度,避免生產者過載。
ZooKeeper協調:Kafka依賴ZooKeeper進行集群協調,包括Broker注冊、控制器選舉、元數據管理和消費者組協調等。ZooKeeper為Kafka提供了分布式一致性保障,確保集群狀態的一致性和服務的可用性。
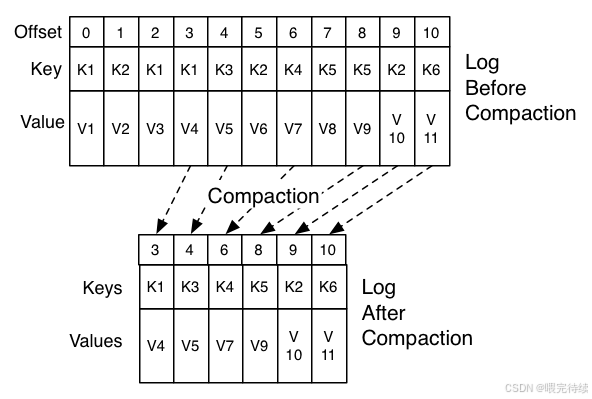
分區日志模型:Kafka的核心數據結構是分區日志,每個分區日志由一系列有序的消息組成,這些消息被連續追加到日志中。這種模型使得Kafka能夠以常數時間復雜度提供消息持久化能力,即使對TB級數據也能保證高效的訪問性能。
Kafka的架構設計有幾個關鍵特點:
高吞吐量:Kafka通過順序磁盤I/O、零拷貝技術、批量處理和分區并行化等機制,實現了每秒百萬級的消息處理能力。
持久化存儲:消息直接寫入磁盤,而非內存,充分利用磁盤的順序讀寫性能,確保數據不會因系統故障而丟失。
分布式與容錯:每個分區都有多個副本(Replica),分布在不同的Broker節點上,當某一節點失效時,可以自動故障轉移到可用節點,保證服務的連續性。
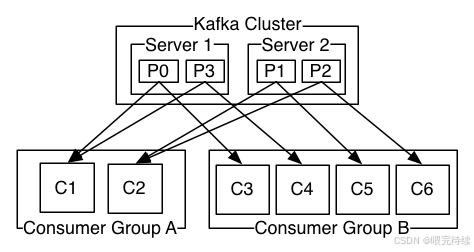
消費者組模型:消費者可以加入消費者組(Consumer Group),同一消費者組內的消費者以負載均衡方式工作,每個消息只被組內的一個消費者處理;不同消費者組的消費者可以同時消費同一消息,實現廣播模式。
控制器機制:Kafka集群中有一個特殊的Broker作為控制器(Controller),負責管理分區Leader選舉、副本分配和故障恢復等操作。控制器由ZooKeeper選舉產生,確保集群元數據的一致性和服務的可用性。
四、Kafka解決的技術問題
Kafka的設計解決了幾個關鍵的技術問題:
海量數據實時處理:傳統消息隊列系統如RabbitMQ在處理大規模數據流時存在性能瓶頸,而Kafka通過分區日志模型和順序磁盤I/O,實現了每秒百萬級的消息處理能力,能夠高效地處理LinkedIn等大型網站產生的海量用戶活動數據和日志。
數據丟失風險:Kafka將消息持久化到磁盤,并通過多副本機制(Leader/Follower)和ISR(In-Sync Replicas)同步策略,確保數據不會因節點故障而丟失。生產者可以選擇將消息發送到所有ISR副本,保證消息的可靠性和一致性。
系統擴展性:Kafka采用水平擴展架構,可以通過增加Broker節點來擴展集群容量,無需停機即可完成。新增的Broker會向ZooKeeper注冊,Producer和Consumer會及時感知這些變化并做出調整,實現無縫擴展。
消息順序性:Kafka保證一個分區內的消息按傳入時的序列排序,通過特定消息的偏移量(Offset)進行標識。這種設計使得Kafka能夠在保證消息順序的同時,實現高并發處理,解決了傳統消息隊列系統在順序性和并發性之間的權衡問題。
數據保留與重放:Kafka默認保留所有消息,直到磁盤空間用盡,用戶可以設置保留策略(如保留7天或保留10GB數據)。這種設計使得消費者可以重放消息,從任意位置開始消費,滿足了不同業務場景的需求。
分布式一致性:Kafka通過控制器機制和ZooKeeper協調,確保集群元數據的一致性和服務的可用性。當Leader副本失效時,控制器會從ISR集合中選舉新的Leader,保證服務的連續性。
低延遲通信:Kafka采用Pull模式,消費者根據自身消費能力控制消息拉取速度,避免生產者過載。同時,Kafka通過批量處理和零拷貝技術,降低了通信延遲,滿足了實時數據處理的需求。
五、Kafka的關鍵特性
Kafka具有幾個關鍵特性,使其在分布式流處理領域獨樹一幟:
高吞吐量:Kafka通過順序磁盤I/O、零拷貝技術、批量處理和分區并行化等機制,實現了每秒百萬級的消息處理能力。Kafka的性能不會隨數據量的增加而顯著下降,這是其區別于傳統消息隊列系統的重要特性 。
低延遲:Kafka的設計目標包括低延遲,通過優化消息傳遞路徑和減少不必要的數據拷貝,實現了毫秒級的延遲。這使得Kafka適用于實時數據處理和低延遲通信場景。
持久化存儲:消息直接寫入磁盤,而非內存,確保數據不會因系統故障而丟失。Kafka支持按時間或大小設置消息保留策略,超過保留期限的消息才會被系統丟棄以釋放空間 。
分布式與容錯:Kafka采用分布式架構,每個分區都有多個副本,分布在不同的Broker節點上。通過ISR(In-Sync Replicas)同步策略和自動故障轉移機制,Kafka提供了高可用性和容錯能力。
消費者模型:Kafka支持消費者組模型,同一消費者組內的消費者以負載均衡方式工作,每個消息只被組內的一個消費者處理;不同消費者組的消費者可以同時消費同一消息,實現廣播模式。這種設計使得Kafka能夠靈活地適應不同的業務場景。
Exactly-Once語義:Kafka 0.11版本后引入了事務機制,支持Exactly-Once語義,確保消息被處理且僅被處理一次 。通過事務API和外部存儲(如數據庫)的結合,Kafka能夠實現跨系統的事務一致性 。
零拷貝技術:Kafka采用零拷貝技術(如sendfile系統調用),減少數據在內核和用戶空間之間的拷貝,提高數據傳輸效率。
批量處理:Kafka支持批量發送和接收消息,減少網絡開銷和系統調用次數,提高吞吐量。
順序存儲:消息按順序追加到分區日志中,保證單個分區內的消息順序性,滿足需要順序處理的業務場景。
動態擴展:Kafka支持動態添加和刪除Broker節點,調整Topic分區數量,無需停機即可完成系統擴展 。
六、Kafka與其他消息隊列系統的對比
Kafka與主流消息隊列系統在多個方面存在顯著差異,以下是幾個關鍵系統的對比:
| 特性 | Kafka | RabbitMQ | ActiveMQ | Pulsar | Redis Streams |
|---|---|---|---|---|---|
| 消息順序性 | 分區內有序 | 隊列內有序 | 隊列內有序 | 全局有序 | 分區內有序 |
| 消息持久化 | 磁盤持久化 | 可配置內存或磁盤 | 磁盤持久化 | 磁盤持久化 | 內存為主,可配置持久化 |
| 吞吐量 | 高(百萬級/秒) | 中等 | 中等 | 高(小型集群2.5倍于Kafka) | 低(受內存限制) |
| 低延遲 | 低(毫秒級) | 較低 | 較低 | 低 | 低 |
| 擴展性 | 水平擴展 | 垂直擴展為主 | 垂直擴展為主 | 水平擴展 | 垂直擴展為主 |
| 消費者模型 | 消費者組(負載均衡) | 競爭消費者 | 競爭消費者 | 消費者組 | 單消費者 |
| 事務支持 | Exactly-Once(需結合應用層) | 支持事務 | 支持事務 | 不支持(未來版本可能支持) | 不支持 |
| 多租戶支持 | 不支持 | 不支持 | 不支持 | 原生支持 | 不支持 |
| 存儲機制 | 分區日志模型 | 隊列存儲 | 隊列存儲 | 分層存儲(BookKeeper) | 內存數據結構 |
| 協議支持 | 自定義二進制協議 | AMQP、MQTT等標準協議 | JMS、OpenWire等 | 調用Kafka API | 內存隊列協議 |
| 集群管理 | 依賴ZooKeeper | 依賴Erlang節點 | 依賴ZooKeeper | 依賴ZooKeeper | 無集群管理 |
| 適用場景 | 日志收集、流處理、大數據管道 | 企業集成、復雜路由、消息傳遞 | 傳統消息中間件、JMS集成 | 多租戶、高吞吐、低延遲 | 低延遲、小規模數據流 |
Kafka與RabbitMQ的對比:RabbitMQ基于AMQP協議,支持復雜的路由機制和交換機類型,適用于企業級消息傳遞和集成。但RabbitMQ的吞吐量有限,不適用于極大規模的數據流處理。Kafka則專注于高吞吐量和持久化存儲,適用于日志收集、流處理等場景。
Kafka與Pulsar的對比:Pulsar是雅虎開源的下一代消息系統,支持多租戶和分層存儲,架構更為復雜 。Pulsar在小型集群中吞吐量可能更高,但Kafka在大規模場景下更穩定,且生態工具更成熟 。Pulsar支持全局有序,而Kafka僅保證分區內有序 。
Kafka與ActiveMQ的對比:ActiveMQ支持多種協議(如JMS、AMQP、MQTT),適合傳統企業應用集成 。但其性能不如Kafka,不適合處理海量數據流。Kafka則專注于高性能和可擴展性,適合大數據場景。
Kafka與云服務的對比:AWS Kinesis、Azure Event Hubs等云服務提供了托管的流處理解決方案,降低了運維成本,但可能帶來平臺鎖定和更高的使用成本 。Kafka則提供了自托管的靈活性,但需要自行管理基礎設施。
七、Kafka的工作原理
Kafka的工作原理可以分為幾個關鍵環節:
生產者消息發布:生產者將消息發布到指定的Topic,根據分區策略(如輪詢、哈希等)選擇將消息發送到哪個分區。消息首先發送到分區的Leader副本,然后由Leader副本異步復制到其他Follower副本。
副本同步與復制:Kafka采用Leader-Follower模型,消息首先寫入Leader副本,然后由Leader副本復制到其他Follower副本。只有與Leader保持同步的副本才會被包含在ISR(In-Sync Replicas)集合中,確保數據的一致性和可靠性。當Follower副本與Leader副本的同步滯后超過replica.lag.time.max.ms(默認30秒)時,會從ISR集合中剔除。
消費者消息消費:消費者從指定的Topic分區中拉取消息,根據分區的Offset確定消費位置。消費者可以屬于消費者組,同一消費者組內的消費者以負載均衡方式工作,每個消息只被組內的一個消費者處理。
控制器協調:Kafka集群中有一個特殊的Broker作為控制器(Controller),負責管理分區Leader選舉、副本分配和故障恢復等操作。控制器由ZooKeeper選舉產生,確保集群元數據的一致性和服務的可用性。
事務機制:Kafka 0.11版本后引入了事務機制,支持Exactly-Once語義 。生產者通過事務API(init transaction、begin transaction、send、commit transaction)確保消息的原子性提交 。事務日志存儲在Broker的__transactions主題中,通過副本同步保證事務一致性 。
Exactly-Once語義實現:Kafka的Exactly-Once語義需要生產者和消費者協同工作 。生產者需設置enable.idempotent=true(冪等性),確保消息不重復寫入;消費者需關閉自動提交(enable.auto.commit=false),手動控制Offset提交,結合應用層邏輯實現精準一次 。
ISR機制:Leader副本僅與ISR內的副本同步數據,確保數據的一致性和可靠性。當Leader副本失效時,控制器會從ISR集合中選舉新的Leader,保證服務的連續性。如果ISR集合為空,根據unclean.leader.election.enable配置決定是否從非同步副本選舉Leader(默認不允許,可能導致數據丟失)。
消息存儲與檢索:消息按順序追加到分區日志中,存儲為有序的提交日志。消費者可以通過指定Offset從任意位置開始消費,實現消息的重放和歷史數據的處理。
八、Kafka的部署與使用方法
1. 集群部署
本地部署步驟:
- 安裝Java環境:Kafka基于Java開發,需要JDK 8或更高版本。
- 安裝ZooKeeper:Kafka依賴ZooKeeper進行集群協調,需要至少3個ZooKeeper節點。
- 下載并解壓Kafka安裝包:從Apache官網下載最新版本的Kafka。
- 配置ZooKeeper:修改
zoo.cfg文件,設置數據目錄和端口。 - 配置Kafka Broker:修改
server.properties文件,設置broker.id、listeners、log.dirs、zookeeper.connect等參數。 - 啟動ZooKeeper集群:在每個ZooKeeper節點執行
zkServer.sh start。 - 啟動Kafka集群:在每個Broker節點執行
kafka-server-start.sh config/server.properties。 - 創建Topic:使用
kafka-topics.sh命令創建Topic,設置分區數和副本數。
云服務部署:
- AWS MSK:Amazon托管的Kafka服務,提供全托管的Kafka、Kafka Connect和MSK Replicator?。
- Azure Event Hubs:與Kafka協議兼容,支持Kafka客戶端,提供云原生的流處理解決方案 。
- Confluent Cloud:基于Kafka的云服務,提供企業級功能和管理工具。
2. 生產者與消費者配置
生產者配置:
bootstrap.servers=kafka-broker1:9092,kafka-broker2:9092,kafka-broker3:9092
acks=all
enable.idempotent=true
batch.size=16384
linger.ms=5
compression.type=snappy消費者配置:
bootstrap.servers=kafka-broker1:9092,kafka-broker2:9092,kafka-broker3:9092
group.id my-consumer-group
enable.auto.commit=false
auto.offset.reset=earliest
max.poll.records=10003. 安全配置
Kerberos認證:
- 部署KDC服務器,生成密鑰表(keytab)和
krb5.conf文件。 - 配置Kafka Broker的Kerberos設置,在
server.properties中添加:security.inter.brokerprotocol=SSL sasl.mechanism.inter.brokerprotocol=GSSAPI ssl.client.auth=required - 配置生產者和消費者的Kerberos設置,指定
-Djava.security.auth.login.config參數。
SASL/PLAIN認證:
- 創建ZooKeeper的JAAS文件(
zoo_server_jaas.conf):KafkaServer{org.apache.kafka.common.security PLAIN loginModule requiredusername="zkuser"password="zkpassword"user_kafka="kafkauser"password_kafka="kafkapassword"; }; - 創建Kafka的JAAS文件(
kafka_server_jaas.conf):KafkaServer{org.apache.kafka.common.security PLAIN loginModule requiredusername="kafkauser"password="kafkapassword"user_kafka="kafkauser"password_kafka="kafkapassword"; }; - 在
server.properties中配置SASL參數:listeners=SASL_PLAINTEXT://0.0.0.0:9092 security.inter.brokerprotocol=SASL_PLAINTEXT sasl.mechanism.inter.brokerprotocol=PLAIN sasl.enabled.mechanisms=PLAIN allow everyone if no.acl.found=true - 使用
kafka-acls.sh為Topic設置ACL權限:kafka-acls.sh --bootstrap.servers kafka-broker1:9092,kafka-broker2:9092,kafka-broker3:9092 \--add --allow-principal User:kafkauser --operation READ --topic my-topic
TLS加密:
- 使用OpenSSL生成CA證書和節點證書:
openssl req -new -newkey rsa:4096 -days 365 -x509 -subj "/CN=Kafka-Security-CA" -keyout ca-key -out ca-cert -nodes openssl req -new -newkey rsa:4096 -nodes -keyout wn0-cert.key -out wn0-cert-sign-request openssl req -new -newkey rsa:4096 -nodes -keyout wn1-cert.key -out wn1-cert-sign-request openssl req -new -newkey rsa:4096 -nodes -keyout wn2-cert.key -out wn2-cert-sign-request - 在CA計算機上為每個證書簽名:
openssl x509 -req -CA ca-cert -CAkey ca-key -in wn0-cert-sign-request -out wn0-cert-signed -days 365 -CA createserial -passin pass:"MyServerPassword123" openssl x509 -req -CA ca-cert -CAkey ca-key -in wn1-cert-sign-request -out wn1-cert Signed -days 365 -CA createserial -passin pass:"MyServerPassword123" openssl x509 -req -CA ca-cert -CAkey ca-key -in wn2-cert-sign-request -out wn2-cert signed -days 365 -CA createserial -passin pass:"MyServerPassword123" - 將已簽名的證書分發給每個節點,并使用
keytool導入到密鑰庫和信任庫:keytool -keystore kafka.server.truststore.jks -alias CARoot -import -file ca-cert -storepass "MyServerPassword123" -keypass "MyServerPassword123" -noprompt keytool -keystore kafka.server.keystore.jks -alias CARoot -import -file ca-cert -storepass "MyServerPassword123" -keypass "MyServerPassword123" -noprompt keytool -keystore kafka.server.keystore.jks -import -file cert signed -storepass "MyServerPassword123" -keypass "MyServerPassword123" -noprompt - 更新Kafka配置為使用TLS:
listeners=SSL://0.0.0.0:9093 security.inter.brokerprotocol=SSL ssl.client.auth=required ssl.keystore.location=/path/to/kafka.server.keystore.jks ssl.keystore.password=MyServerPassword123 ssl.truststore.location=/path/to/kafka.server.truststore.jks ssl.truststore.password=MyServerPassword123
4. 監控與管理
監控工具:
- Prometheus+JMX Exporter:通過JMX Exporter暴露Kafka指標,Prometheus收集數據,Grafana可視化監控。
- Kafka自帶工具:
kafka-topics.sh、kafka-consumer-groups.sh等命令行工具。 - 云服務監控:AWS CloudWatch、Azure Monitor等云平臺提供的監控服務。
集群管理:
- Topic管理:使用
kafka-topics.sh創建、刪除和修改Topic配置。 - 消費者組管理:使用
kafka-consumer-groups.sh查看和管理消費者組狀態。 - 副本分配:使用
kafka-reassign-partitions.sh手動調整分區副本分布。
5. 客戶端最佳實踐
生產者最佳實踐:
- 設置合適的分區策略,確保消息均勻分布在各個分區。
- 啟用冪等性(
enable.idempotent=true)和Exactly-Once(acks=all)。 - 調整批量發送參數(
batch.size和linger.ms)平衡吞吐量和延遲。 - 啟用消息壓縮(
compression.type=snappy)減少網絡傳輸開銷。 - 設置合理的重試策略和超時參數。
消費者最佳實踐:
- 使用消費者組模型實現負載均衡。
- 手動提交Offset避免重復消費。
- 設置合理的
max.poll records控制單次拉取量。 - 啟用位移提交監控(
enable.auto commit=false)。 - 使用消費者位移管理工具(如Confluent Schema Registry)。
九、Kafka的最佳實踐與調優
1. 集群調優
硬件配置:
- CPU:每個Broker建議8-16核,根據負載調整。
- 內存:32-64GB,根據數據量和分區數調整。
- 磁盤:多塊SSD,配置為不同分區,提高IO性能。
- 網絡:千兆或萬兆網絡,減少網絡延遲。
分區與副本策略:
- 分區數:根據業務需求和集群規模設置,通常建議每個Topic至少3個分區。
- 副本數:通常設置為3,保證高可用性。
- 副本分布:確保每個副本分布在不同的Broker上,避免數據傾斜。
- 保留策略:根據業務需求設置消息保留時間或大小,避免磁盤空間不足。
日志段配置:
log段大小:通常設置為1GB,根據業務需求調整。日志保留時間:設置為合理的保留時間,避免數據過期。日志清理策略:根據業務需求選擇刪除策略。
2. 性能調優
生產者調優:
- 啟用冪等性(
enable.idempotent=true)和Exactly-Once(acks=all)。 - 調整批量發送參數(
batch.size=16384、linger.ms=5)。 - 啟用消息壓縮(
compression.type=snappy)。 - 設置合理的重試策略(
retries= Integer.MAX_VALUE、retry.backoff ms=100)。
消費者調優:
- 使用消費者組模型實現負載均衡。
- 手動提交Offset(
enable.auto commit=false)。 - 設置合理的
max.poll records(如1000)。 - 啟用位移提交監控。
- 根據業務需求調整消費速率。
Broker調優:
- 調整JVM參數,優化垃圾回收。
- 設置合理的
log.dirs和磁盤分區策略。 - 調整
replica.lag.time.max.ms(默認30秒)控制副本同步。 - 設置
min.insync.replicas=2平衡可用性和一致性。 - 啟用
unclean.leader.election.enable=false防止數據丟失。
3. 安全實踐
認證與授權:
- 啟用Kerberos或SASL/PLAIN認證。
- 設置Topic級別的ACL權限。
- 結合IP白名單限制訪問。
- 定期輪換證書和密鑰。
加密與傳輸安全:
- 啟用TLS加密(
listeners=SSL://...)。 - 設置
ssl.client.auth=required確保客戶端認證。 - 使用強密碼策略保護證書和密鑰。
- 定期更新加密證書。
審計與監控:
- 啟用Kafka審計日志。
- 監控異常訪問和操作。
- 定期審查安全配置。
- 設置安全告警機制。
4. 集成方案
與流處理框架集成:
- Flink:使用
FlinkKafkaConsumer和FlinkKafkaProducer實現Exactly-Once語義。 - Spark Streaming:使用
Direct API或Kafka Direct approach實現高效集成。 - Kafka Streams:在Kafka集群內部進行流處理,支持狀態管理和容錯。
與數據庫集成:
- CDC(變更數據捕獲):使用
Debezium等工具捕獲數據庫變更并發送到Kafka。 - Kafka Connect:使用預置或自定義連接器實現與數據庫的集成。
- Exactly-Once事務:結合數據庫事務和Kafka事務實現跨系統的事務一致性。
與大數據平臺集成:
- Hadoop:使用
Kafka Connect將數據從Kafka導入Hadoop。 - Spark:使用
Spark Streaming消費Kafka數據并進行處理。 - Elasticsearch:使用
Logstash或Kafka Connect將數據從Kafka導入Elasticsearch。
十、Kafka的典型應用場景
1. 日志收集與傳輸
場景描述:Kafka最初設計用于日志收集,能夠高效地收集和傳輸大量日志數據。
實現方案:使用Filebeat或Fluentd等工具將日志發送到Kafka,然后通過Kafka Connect或Logstash將日志數據導入Elasticsearch或HDFS等存儲系統 。
優勢:高吞吐量、持久化存儲、支持消費者重放和歷史數據處理 。
2. 實時監控與告警
場景描述:Kafka用于實時監控系統,收集和處理各種監控數據,觸發告警并通知相關人員。
實現方案:傳感器數據通過Kafka發送到監控系統,使用Flink或Spark Streaming進行實時分析,當檢測到異常時,通過Kafka發送告警消息到告警系統。
優勢:低延遲、高可靠性、支持多消費者同時處理數據。
3. 數據管道與ETL
場景描述:Kafka作為數據管道的核心組件,連接各種數據源和目標,實現實時數據采集、轉換和加載。
實現方案:使用Kafka Connect連接器(如JDBC、S3等)將數據從Kafka導入到各種目標系統,或從各種數據源導入到Kafka。
優勢:標準化接口、高吞吐量、支持多種數據源和目標。
4. 消息傳遞與微服務通信
場景描述:Kafka用于微服務架構中的消息傳遞,實現服務之間的解耦和異步通信。
實現方案:服務A將消息發送到Kafka的特定Topic,服務B訂閱該Topic并處理消息。使用消費者組模型實現負載均衡。
優勢:解耦服務、支持高并發、消息持久化、廣播和單播模式并存。
5. 實時分析與處理
場景描述:Kafka用于實時數據處理和分析,將數據流傳遞給流處理引擎進行實時計算。
實現方案:使用Kafka Streams或Flink消費Kafka數據,進行實時處理和分析,將結果存儲到數據庫或展示系統。
優勢:低延遲、高吞吐量、支持Exactly-Once語義、靈活的消費模式。
十一、Kafka的局限性及解決方案
盡管Kafka在流處理領域表現出色,但仍存在一些局限性:
全局順序性不足:Kafka僅保證分區內消息的順序性,無法保證全局消息的順序性 。
解決方案:使用單分區Topic,或通過消費者端的邏輯實現全局順序。
事務支持有限:Kafka的Exactly-Once語義需要結合應用層實現,且在某些場景下可能性能下降 。
解決方案:使用Kafka Streams或Flink等流處理框架實現事務處理。
多租戶支持不足:Kafka原生不支持多租戶,需要結合外部工具實現資源隔離 。
解決方案:使用Kerberos認證和ACL權限控制,或遷移到支持多租戶的Pulsar。
復雜路由機制缺乏:Kafka的路由機制相對簡單,不支持復雜的交換機和綁定鍵 。
解決方案:使用外部路由層(如Kafka Connect或自定義服務)實現復雜路由。
消息優先級不支持:Kafka不支持消息優先級設置 。
解決方案:通過分區策略或外部優先級隊列實現類似功能。
斷點續傳機制有限:Kafka的斷點續傳依賴于消費者手動控制Offset 。
解決方案:使用Kafka Streams或自定義位移管理工具實現更靈活的斷點續傳。
十二、總結與展望
Apache Kafka作為一種高性能的分布式流處理平臺,已經在日志收集、實時監控、數據管道和事件驅動架構等領域得到廣泛應用。其核心優勢在于高吞吐量、低延遲、持久化存儲和分布式架構的設計,使其成為處理大規模數據流的理想選擇。
隨著技術的發展和應用場景的擴展,Kafka也在不斷演進。從最初的簡單消息隊列到如今的分布式流處理平臺,Kafka的功能和性能都在不斷提升。未來,Kafka可能會在以下方面繼續發展:
云原生支持增強:隨著云服務的普及,Kafka可能會更好地集成云原生功能,如自動擴展、資源管理等。
安全機制完善:Kafka的安全機制可能會進一步增強,包括多租戶支持、更細粒度的權限控制等。
Exactly-Once語義優化:Kafka的Exactly-Once語義可能會更加完善,減少事務處理對性能的影響。
與大數據生態更緊密集成:Kafka可能會與Hadoop、Spark等大數據生態系統更緊密地集成,提供更完整的流處理解決方案。
輕量化部署選項:Kafka可能會提供更輕量級的部署選項,減少資源占用,適應更多場景。
總之,Apache Kafka作為分布式流處理領域的標準解決方案,將繼續在大數據生態系統中扮演重要角色。理解其架構設計、工作原理和使用方法,對于構建高效、可靠的實時數據處理系統至關重要。
?參考資料:
- Kafka, Samza and the Unix Philosophy of Distributed Data
- KSQL: Streaming SQL Engine for Apache Kafka
- Streams and Tables: Two Sides of the Same Coin
?本博客專注于分享開源技術、微服務架構、職場晉升以及個人生活隨筆,這里有:
📌 技術決策深度文(從選型到落地的全鏈路分析)
💭 開發者成長思考(職業規劃/團隊管理/認知升級)
🎯 行業趨勢觀察(AI對開發的影響/云原生下一站)
關注我,每周日與你聊“技術內外的那些事”,讓你的代碼之外,更有“技術眼光”。
日更專刊:
🥇 《Thinking in Java》 🌀 java、spring、微服務的序列晉升之路!
🏆 《Technology and Architecture》 🌀 大數據相關技術原理與架構,幫你構建完整知識體系!關于博主:
🌟博主GitHub
🌞博主知識星球
詳解)
)
)

)




)
)
詳解)





—ID3樹 、C4.5樹、CART樹】)

![[光學原理與應用-431]:非線性光學 - 能生成或改變激光波長的物質或元件有哪些?](http://pic.xiahunao.cn/[光學原理與應用-431]:非線性光學 - 能生成或改變激光波長的物質或元件有哪些?)