本篇文章Designing Data Pipeline Architectures for Machine Learning Models適合對數據管道架構感興趣的讀者,亮點在于詳細解析了傳統數據倉庫、云原生數據湖和現代湖倉這三種架構,幫助理解如何將原始數據轉化為可操作的預測。文中還強調了不同架構的優缺點,提供了清晰的比較。
文章目錄
- 1 簡介
- 2 傳統數據倉庫
- 2.1 案例研究 — 股票價格預測
- 2.2 添加暫存區
- 3 云原生數據湖
- 3.1 標準ELT方法
- 3.2 推送ELT方法
- 3.3 ETLT(提取、輕量轉換、加載和轉換)方法
- 3.4 數據攝取模式
- 3.5 Lambda架構
- 3.6 Kappa架構
- 3.6.1 案例研究 — 股票價格預測
- 4 現代湖倉一體架構
- 4.1 案例研究 — 股票價格預測
- 5 結論

1 簡介
數據管道架構是指導將原始數據轉化為可操作預測的戰略藍圖。
但設計架構似乎很復雜,因為它涉及眾多組件,并且每個組件的具體選擇都取決于數據的特性和業務需求。
在本文中,我將結構化這些組件,并探討三種常見模式:
- 傳統數據倉庫
- 云原生數據湖
- 現代湖倉一體架構
并以股票價格預測作為實際用例。
數據管道架構定義了數據從攝取到可用于分析和機器學習狀態的結構、組件和流向。
下圖展示了數據管道架構中的關鍵組件和主要選項:

關鍵組件包括:
- 數據源(Data Source):數據的來源。
- 攝取(Ingestion):收集數據并將其引入系統的方法。
- 存儲(Storage):數據存放的位置。
- 處理(Processing):數據的轉換和清洗。
- 服務(Serving):使處理后的數據可供最終用戶和應用程序訪問。
- 治理(Governance):確保數據質量、安全性、隱私和合規性。
處理部分涉及加載策略,如全量加載、增量加載和增量更新,以及數據轉換,如清洗、插補和預處理。
每個組件的選擇都由數據特性驅動,包括其多樣性(variety)、數據量(volume)和數據速度(velocity),以及具體的業務需求。
- 多樣性(Variety):數據的多樣性(結構化、半結構化、非結構化)影響存儲選擇。
- 數據量(Volume):數據的龐大數量決定了對可擴展、分布式技術(如Spark、Hadoop)和經濟高效的存儲解決方案(如云對象存儲)的需求。
- 數據速度(Velocity):數據生成和處理的速度決定了它是應該采用用于高速數據的實時流式架構,還是用于低速數據的批處理架構。
- 業務需求是最終的指導力量。
由于某些選項之間存在強關聯性,我將在下一節中介紹三種常見組合,并以股票價格預測為例。
2 傳統數據倉庫
第一種組合是使用 ETL(提取、轉換、加載) 方法的傳統數據倉庫架構。
下圖展示了其標準架構,其中原始數據被提取并轉換為結構化數據,然后加載以適應數據倉庫中預定義的模式:
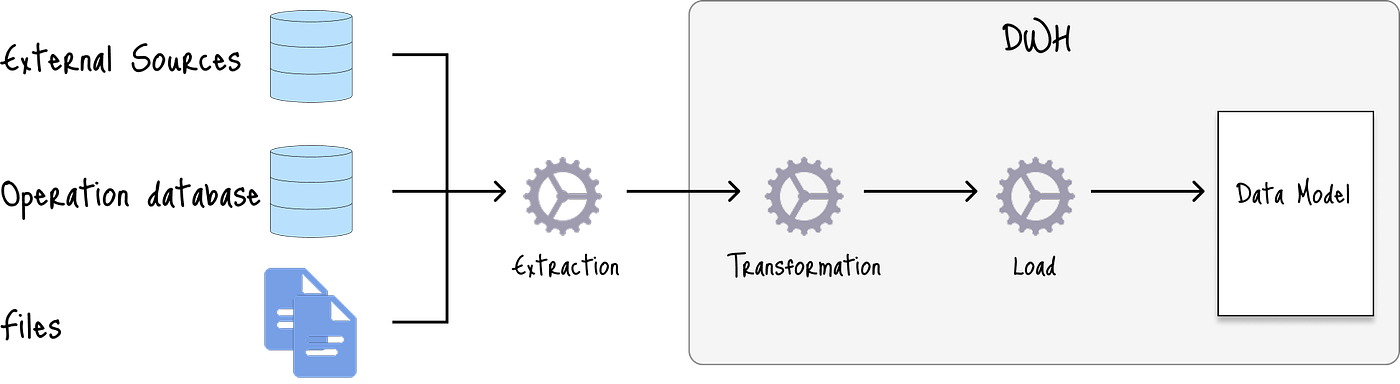
每個組件中選擇的典型選項是:
- 數據源:結構化、批處理
- 攝取:批處理
- 存儲:數據倉庫
- 處理:ETL(提取、轉換、加載)
- 服務:BI、低頻報告和分析
ETL過程在加載之前嚴格清洗和轉換數據,這確保了:
- 對穩定、定義明確的數據源的訪問,
- 高水平的準確性和一致性,以及
- 非常快的查詢性能。
缺點包括:
- 數據類型:不適用于圖像、文本等非結構化或半結構化數據。
- 成本:維護數據倉庫可能很昂貴。
- 延遲:批處理過程意味著數據是按計劃更新的,例如每日或每周。不適用于實時推理。
2.1 案例研究 — 股票價格預測
該架構最適合基于季度或年度財務報告以及歷史日終股票價格的長期預測。
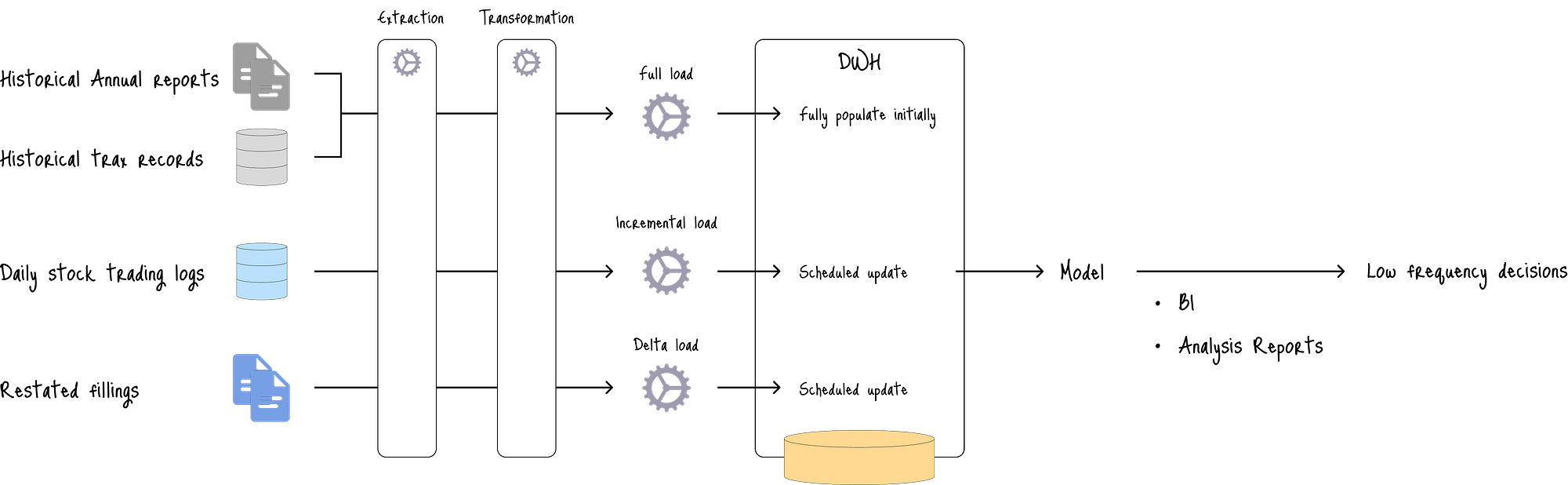
在圖中,該架構首先用數十年的歷史數據填充數據倉庫。
然后,每日股票交易量通過計劃的批處理過程(例如,每日或每周)增量加載。
當財務記錄調整時,批處理過程還會執行增量更新以更新數據倉庫。
然后,結構化數據用于訓練模型,該模型為低頻決策提供預測服務。
這種結構不適合實時股票預測,因為計劃的批處理過程會在數據和預測之間產生延遲。
2.2 添加暫存區
一種高級方法是利用暫存區在通過SQL查詢轉換之前存儲提取的數據:
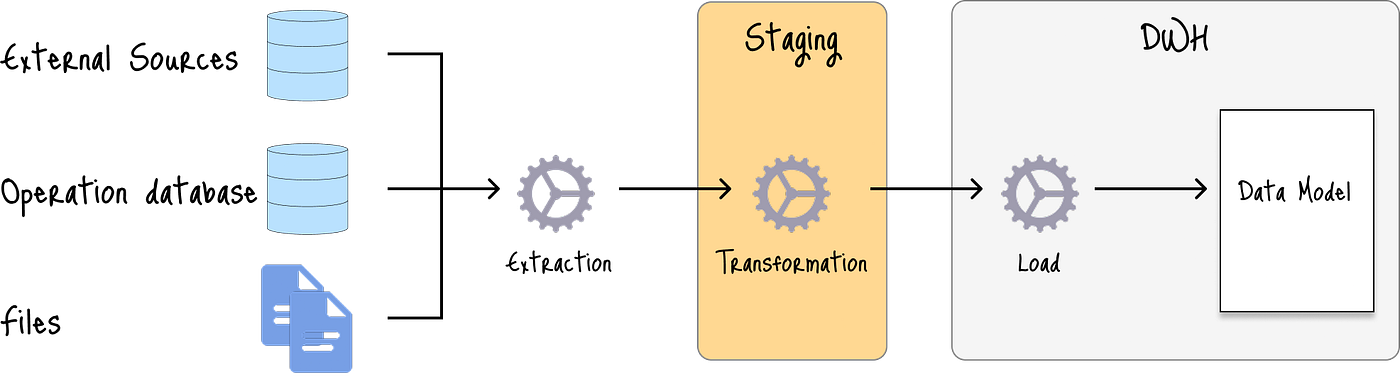
主要區別在于轉換過程的隔離和效率。
如果沒有暫存區,轉換將直接在源系統或目標數據倉庫中完成。這可能效率低下且存在風險:
- 源系統過載:復雜轉換會減慢系統速度,影響核心業務操作。
- 數據倉庫瓶頸:減慢查詢和報告速度,消耗數據倉庫的計算資源。
暫存區可以通過將原始數據加載到臨時存儲空間(如專用的S3存儲桶)來將繁重的轉換過程從數據倉庫或源系統卸載。
然后,一個單獨的處理引擎(如Apache Spark)運行轉換,而不會影響源系統或數據倉庫。
盡管這增加了操作復雜性,但其他優點包括:
- 錯誤處理:即使轉換失敗,數據倉庫中的原始數據也不會受到影響。只需在暫存區中重新運行轉換即可。
- 數據質量控制:通過在暫存區中向轉換添加多步驟(如清洗、特征工程和預處理),確保只有高質量的數據加載到數據倉庫中。
3 云原生數據湖
第二種組合是云原生數據湖架構。
這種架構靈活且經濟高效,非常適合處理大量多樣化數據,包括非結構化數據。
主要有三種方法:
- 標準ELT(提取、加載、轉換)
- 推送ELT
- EtLT(提取、輕量轉換、加載和轉換)
3.1 標準ELT方法
標準方法利用ELT處理:
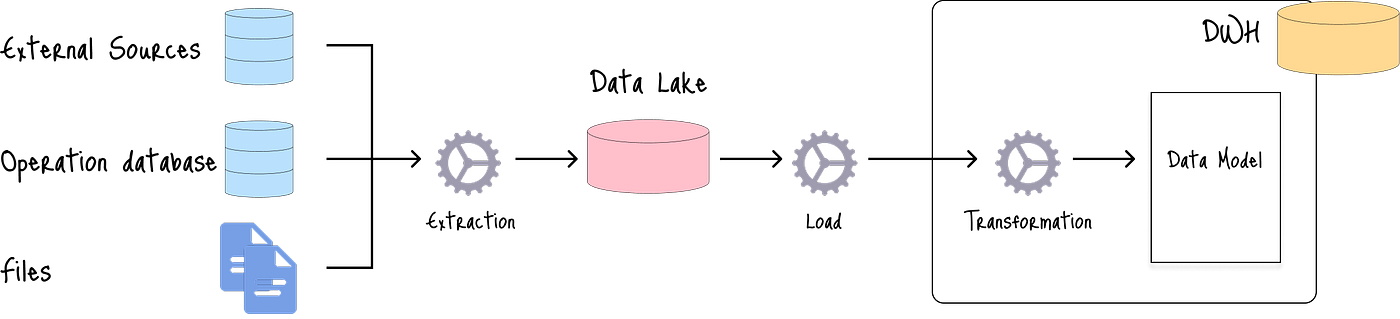
首先,原始數據被提取到數據湖中,然后加載并轉換以存儲在數據倉庫中。
3.2 推送ELT方法
數據攝取到數據湖的另一種方法是推送(Push)方法,其中外部源直接將數據提取到數據湖:
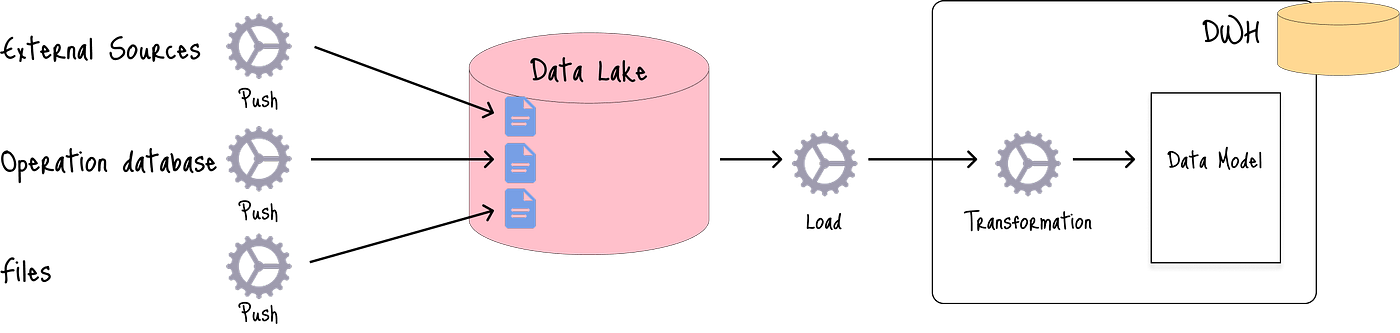
這種方法可能導致對數據提取的控制有限,在數據丟失或損壞的情況下,需要與負責數據源的團隊進行協調。
3.3 ETLT(提取、輕量轉換、加載和轉換)方法
從源中提取的數據可能包含不應被未經授權的個人訪問的機密數據。
EtLT方法包括一個額外的“輕量”轉換步驟,其中敏感信息在加載數據到數據湖之前被屏蔽或加密:
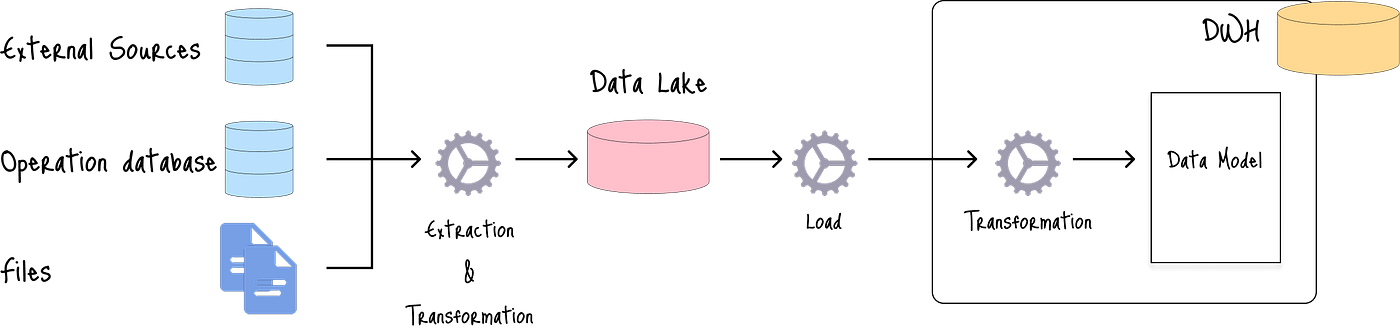
在每種方法中,數據湖和數據倉庫的組合適合對存儲在數據湖中的原始數據應用不同的分析技術。
每個組件中選擇的典型選項是:
- 數據源:數據結構通用,流式
- 攝取:適用于流式,但批處理也可以是一種選擇。
- 存儲:數據湖 + 數據倉庫
- 處理:ELT 或 EtLT
盡管每種方法都增加了管理多個工具的復雜性,但其他優點包括:
- 可擴展性:攝取和轉換過程的分離增強了可擴展性和靈活性。
- 可管理性:易于存儲、跟蹤和審查SQL查詢(轉換)。
3.4 數據攝取模式
所有方法都可以用于批處理和流式管道。
然而,由于ELT和EtLT先加載后轉換的特性,它們非常適合流式數據的實時需求。
但像Lambda和Kappa這樣的混合架構旨在無縫結合批處理和流式攝取,以提供全面的數據處理。
讓我們來看看。
3.5 Lambda架構
Lambda架構采用雙路徑方法,其中批處理層遵循ETL過程來轉換大型歷史數據集,而速度層處理適用于ELT或EtLT方法的實時數據。
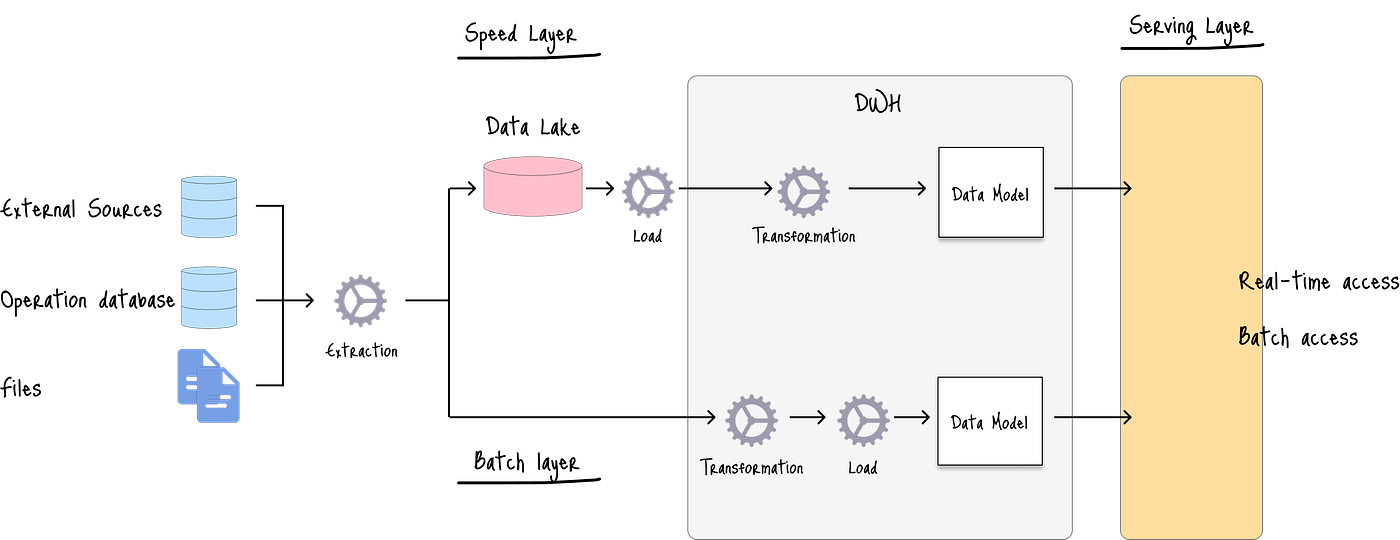
該架構可以根據業務需求提供實時和批處理訪問預測。
在前面架構中相同的股票價格預測案例中,Lambda架構可以擴展為通過速度層提供實時預測,而批處理層則提供長期預測。
來自兩層的預測被組合并提供給用戶,從而提供穩定、長期的展望和波動、實時的預測。
3.6 Kappa架構
Kappa架構通過使用單一、統一的流處理管道來處理實時和歷史數據,從而簡化了Lambda架構。
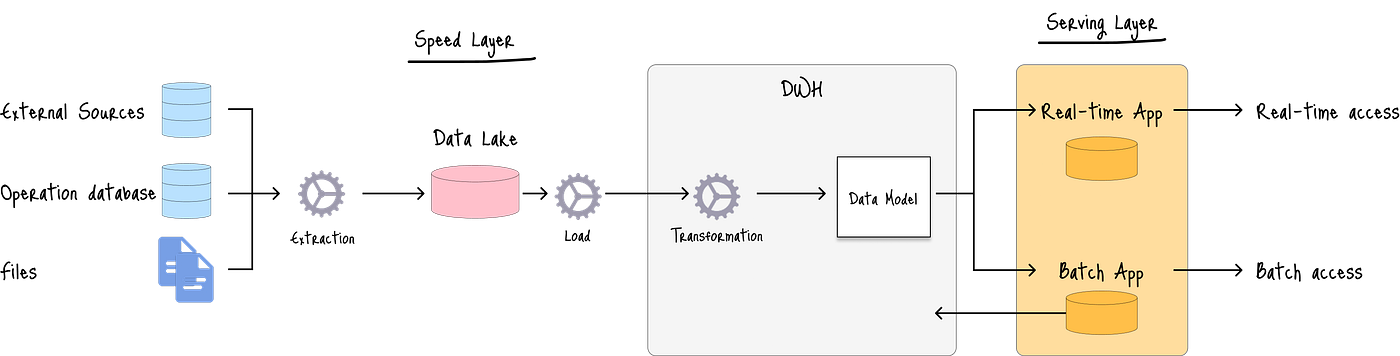
Kappa架構利用ELT模型,其中來自不同源的所有數據都作為流加載,然后由單一處理引擎進行轉換。
3.6.1 案例研究 — 股票價格預測
在股票價格預測的相同用例中,當公司優先考慮降低開發復雜性和運營開銷,同時提供實時預測和長期預測時,Kappa是最佳選擇。
4 現代湖倉一體架構
最后一種組合是湖倉一體架構。
湖倉一體架構旨在結合數據倉庫和數據湖的最佳特性,創建一個統一的平臺,可以處理結構化和非結構化數據:
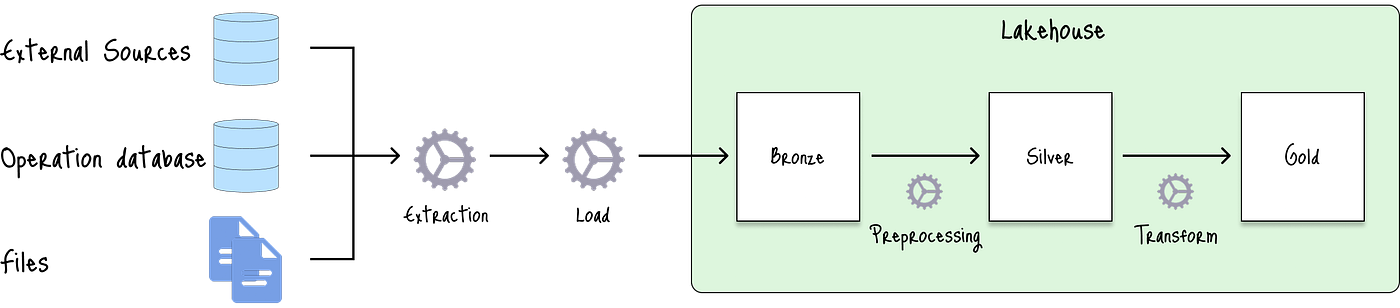
組件選項包括:
- 數據源:通用(適用于結構和數據流)
- 攝取:批處理、流式
- 存儲:湖倉一體
- 處理:ELT(提取、加載、轉換)
在湖倉一體架構中,**青銅層(Bronze Layer)**作為數據湖,用于攝取來自外部源的原始數據。
然后,**白銀層(Silver Layer)**通過清洗和結構化原始數據來處理數據轉換。
**黃金層(Gold Layer)**為特定項目構建精選表,執行特征工程以生成未來預測所需的特征。
這種組合在一個簡化系統中提供了數據湖的靈活性以及數據倉庫的可靠性和性能。
主要優點包括:
- 統一存儲:湖倉一體架構可以在一個平臺上存儲所有類型的數據——結構化、非結構化和半結構化。
- 成本效益:利用S3等低成本、基于云的對象存儲。
- 開放性:通過使用Apache Spark、Delta Lake等開源技術和Parquet等開放文件格式,避免供應商鎖定。
這種架構涉及實現和數據治理的復雜性。
4.1 案例研究 — 股票價格預測
該架構在一個平臺上處理歷史數據和實時流。
帶有青銅層、白銀層和黃金層的獎章結構逐步將原始數據細化為高質量特征。
假設我們有來自三個數據源的原始數據:
- API — 非結構化股票價格
- RSS源 — 非結構化新聞
- 內部數據庫 — 結構化財務記錄
青銅層:
青銅層作為數據湖,用于存儲來自多個數據源的原始數據。
白銀層:
然后,白銀層清洗和結構化原始數據:
- 運行查詢以將所有股票價格與相應的財務記錄連接起來,
- 清洗新聞源中雜亂的文本數據,以及
- 提取給定日期范圍的新聞文章。
黃金層:
最后,黃金層運行特征工程,例如計算30天移動平均線、波動性指標和從清洗后的新聞數據中獲取的市場情緒得分。
這個最終的、高度精煉的數據集用于訓練模型。
5 結論
數據管道架構在將原始數據轉化為有意義的預測方面發揮著關鍵作用。
在本文中,我們了解到三種常見架構——傳統數據倉庫、云原生數據湖和現代湖倉一體架構——各有優缺點。
最佳架構不是一刀切的解決方案,而是根據對數據特性和業務目標的仔細評估而做出的戰略選擇。
)
)
詳解)





—ID3樹 、C4.5樹、CART樹】)

![[光學原理與應用-431]:非線性光學 - 能生成或改變激光波長的物質或元件有哪些?](http://pic.xiahunao.cn/[光學原理與應用-431]:非線性光學 - 能生成或改變激光波長的物質或元件有哪些?)








)