更快的速度、更省的內存訓練、運行、評估大模型
1 支持的模型
All Our Models | Unsloth Documentation
1.1?Dynamic GGUF/instruct 4-bit
- llama.cpp使用的新模型格式,專為高效、本地推理設計
- 注:GGUF無法微調
- 只保留推理所需的內容,如量化后的權重、推理元信息
-
不包含訓練所需的梯度結構、參數層名、優化器狀態
-
不支持反向傳播
-
通常是 4-bit 靜態量化,已經丟失了訓練精度所需的權重信息
-
Instruct 4-bit (safetensors)
-
Instruct:代表模型是指令微調(Instruction-Tuned)版本,即已經訓練過能更好理解指令/對話任務
-
4-bit:表示該模型已經被4-bit 量化(通常用于 QLoRA),顯著降低了顯存需求。
-
safetensors:是一種更安全的模型文件格式(相對
.bin),支持高效加載、避免執行惡意代碼。 -
可直接用于低成本推理或繼續進行LoRA / QLoRA 微調
-
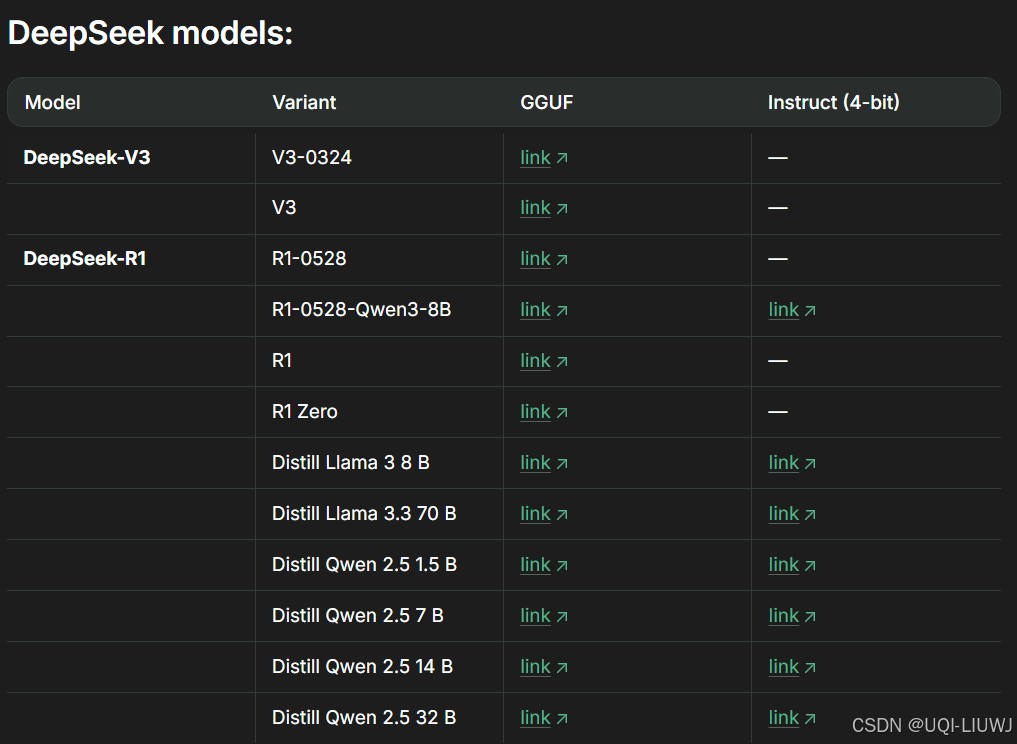
1.1.1 deepseek家族
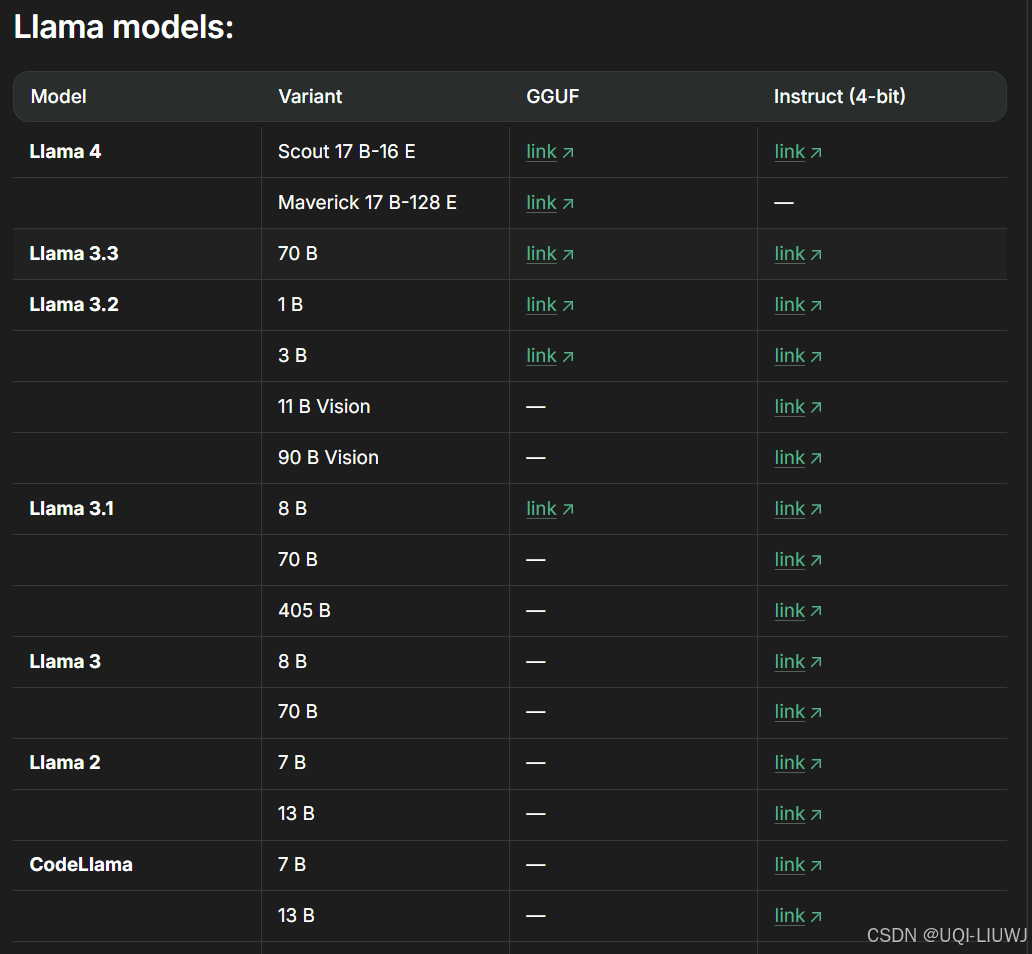
1.1.2?llama家族
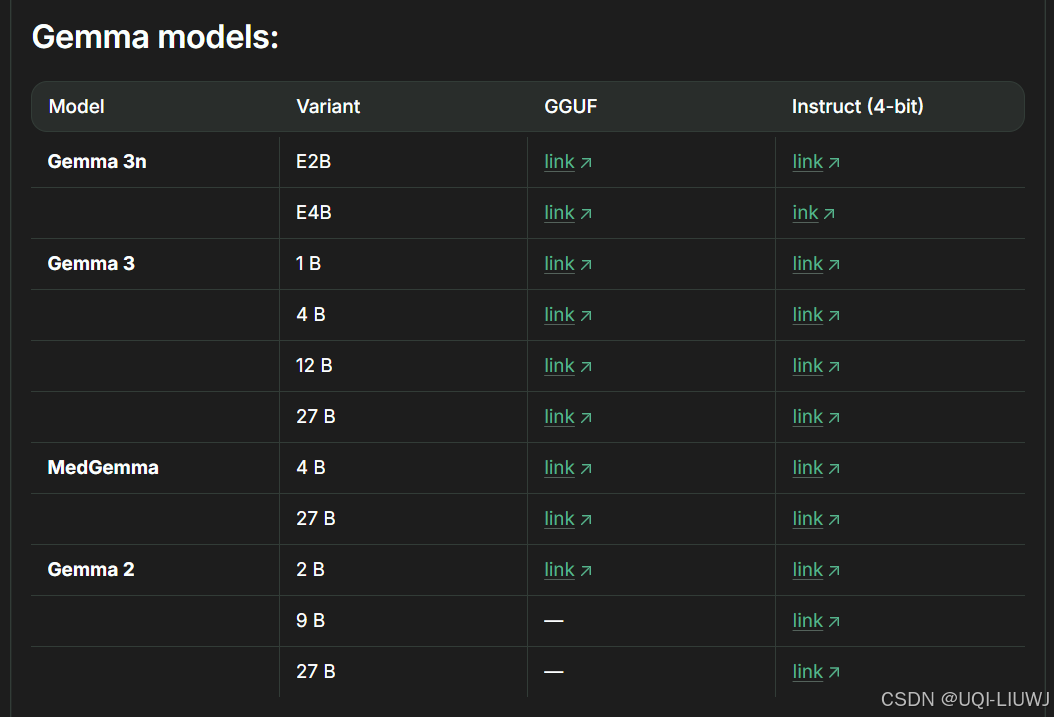
1.1.3 gemma家族
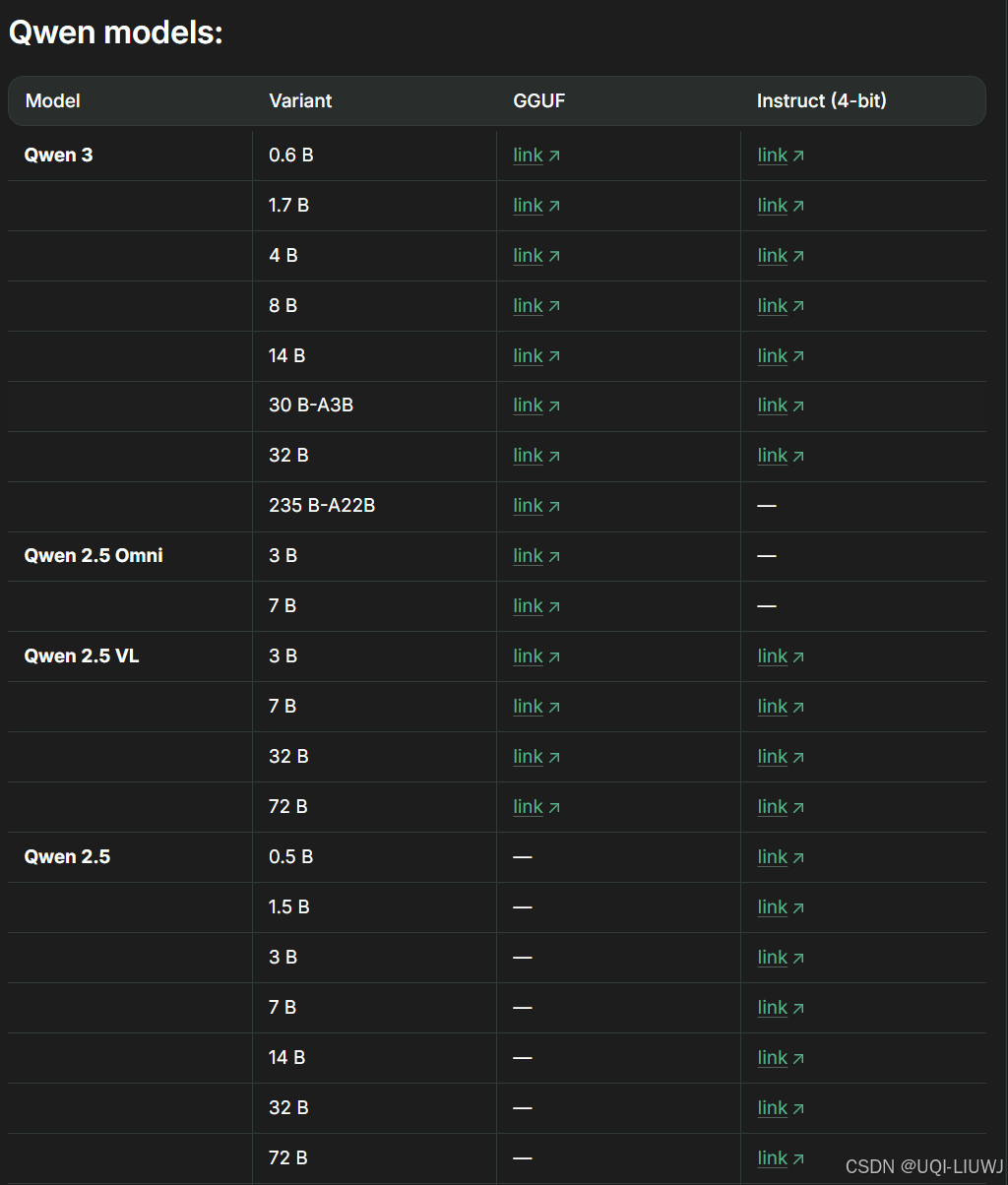
1.1.4 Qwen家族
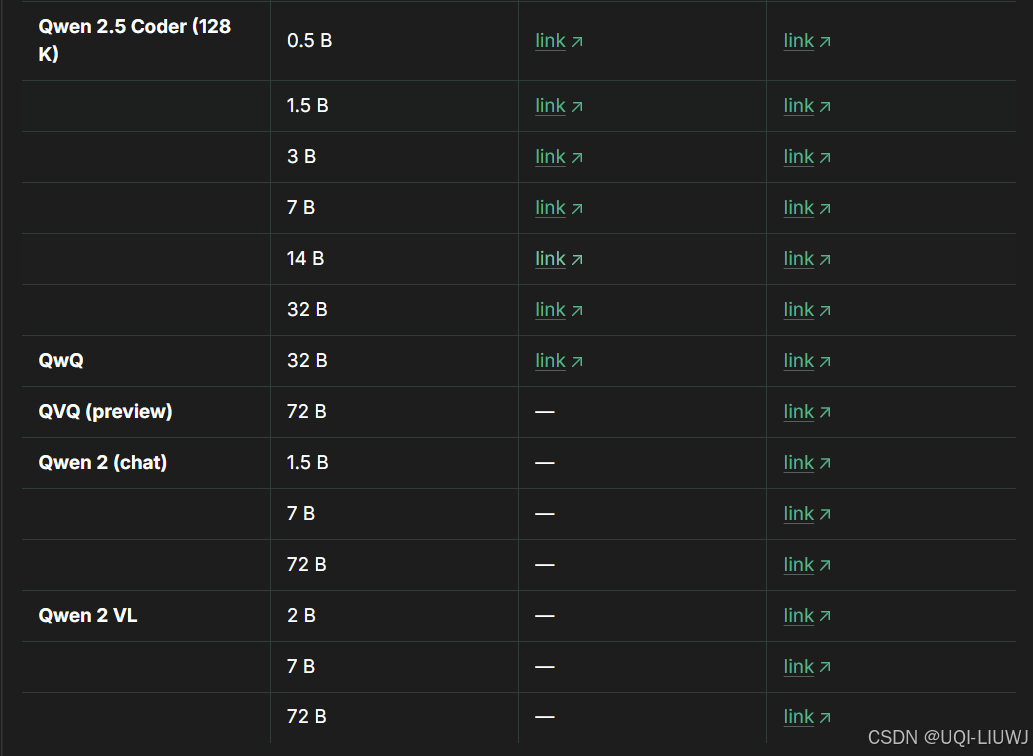
1.1.5 mistral家族
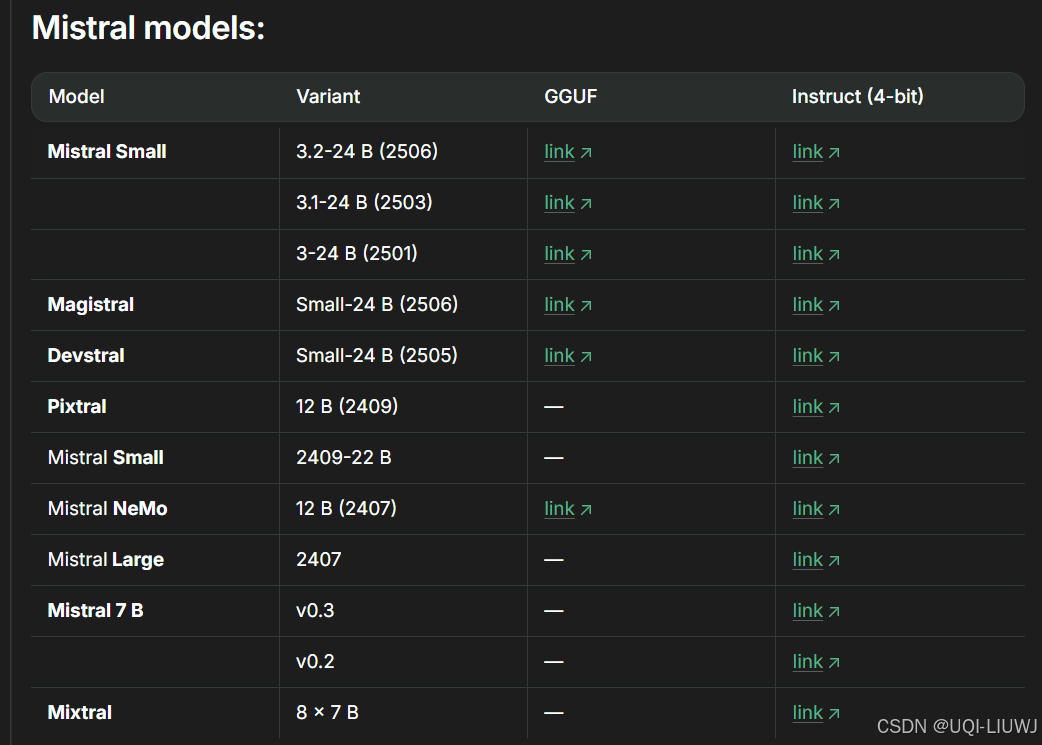
1.1.6 Phi家族
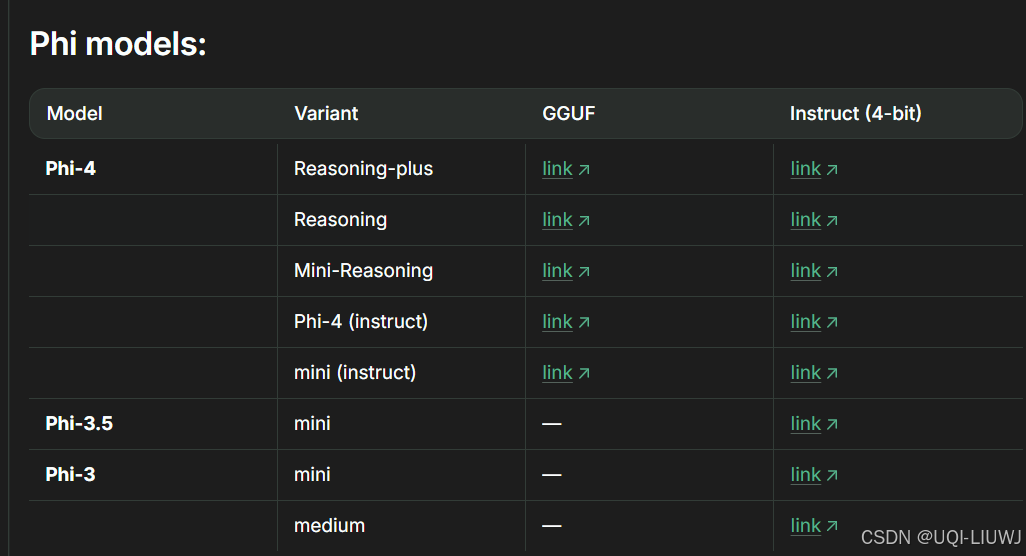
1.1.7 其他
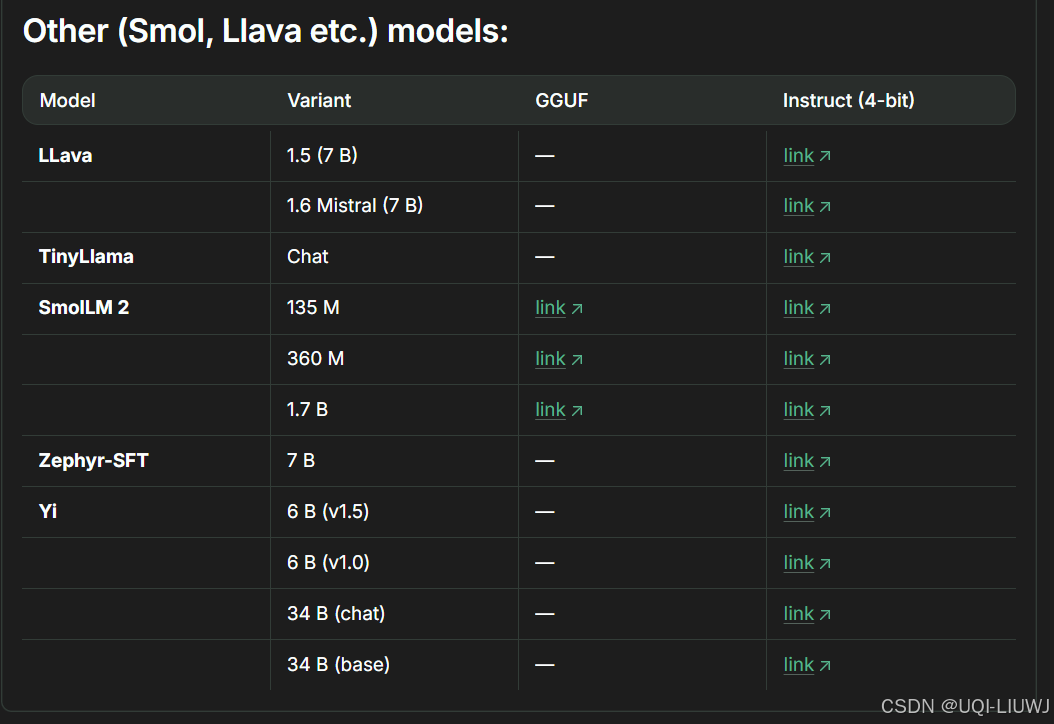
1.2?16-bit and 8-bit Instruct
基本上instruct 4-bit的有的這邊都有
也可用于推理和微調,區別主要在于精度和資源消耗
1.3??Base 4 + 16-bit
未經過指令微調的模型的4-bit和16-bit量化版本
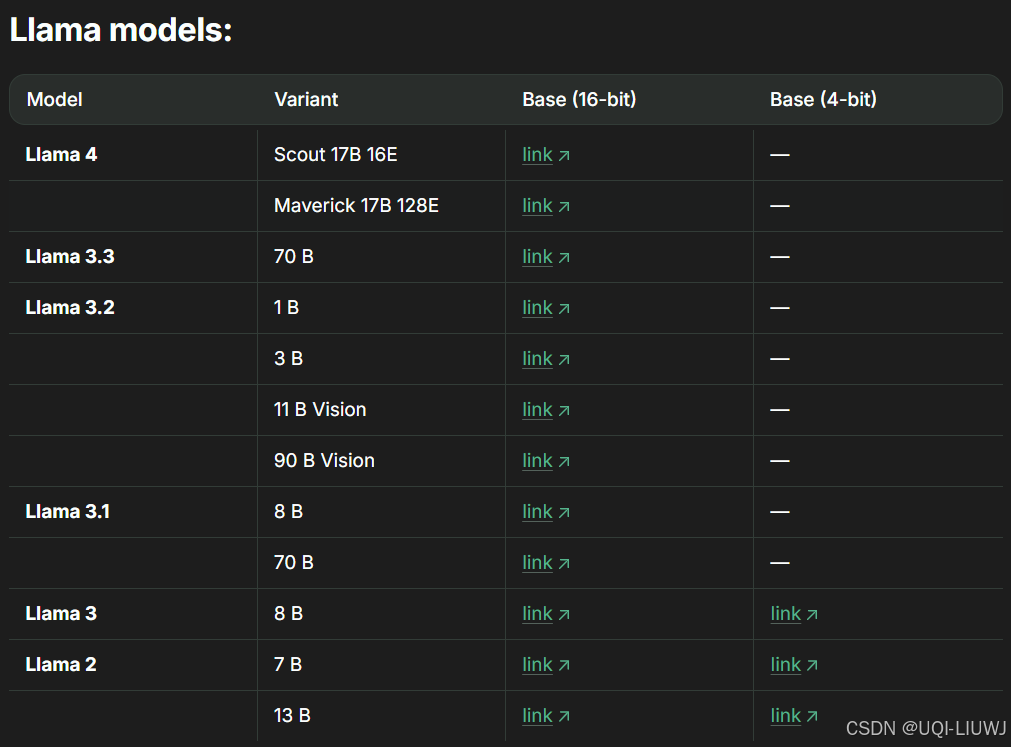
1.3.1 llama家族
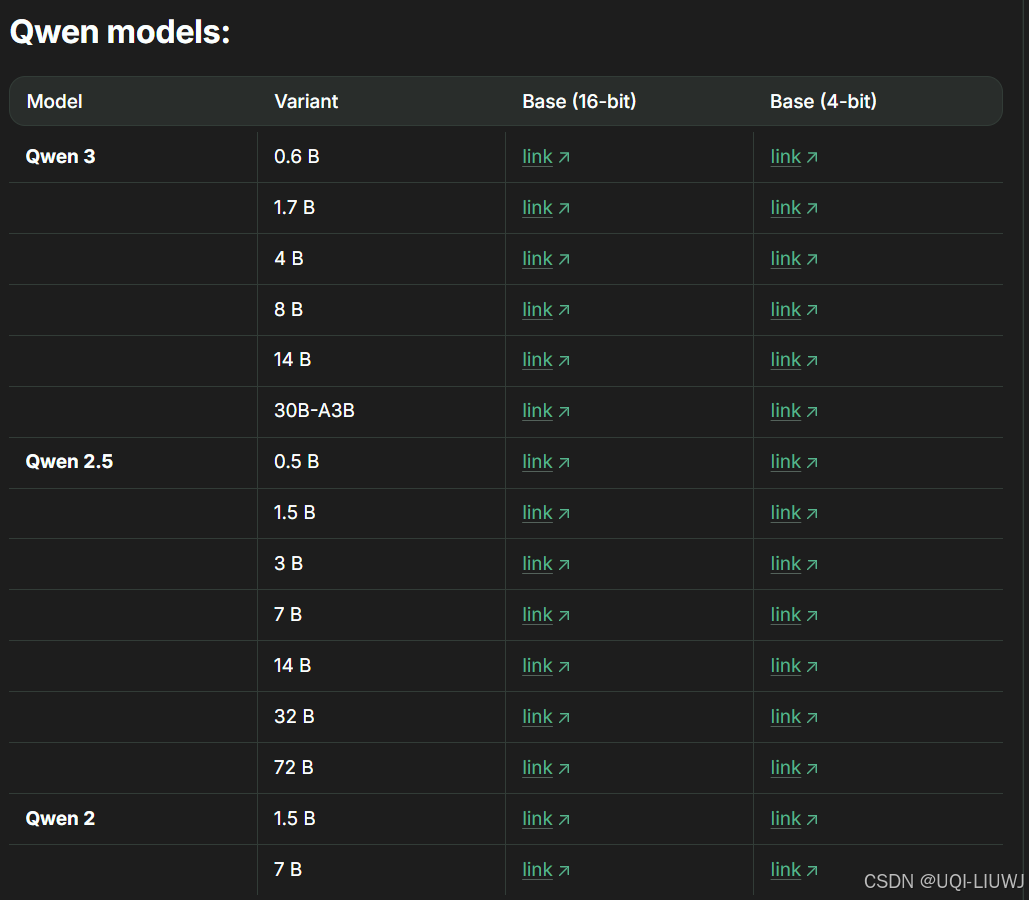
1.3.2 qwen家族
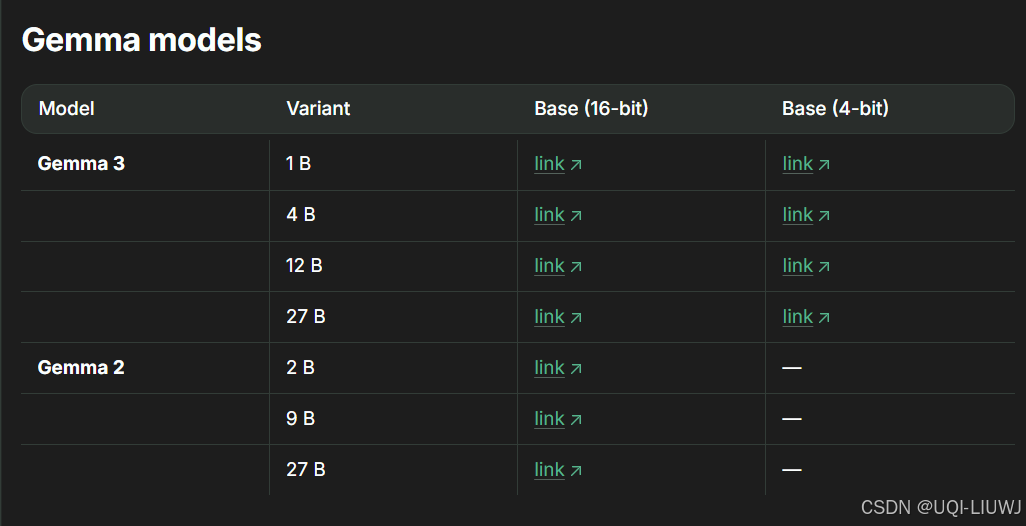
1.3.3 gemma 家族
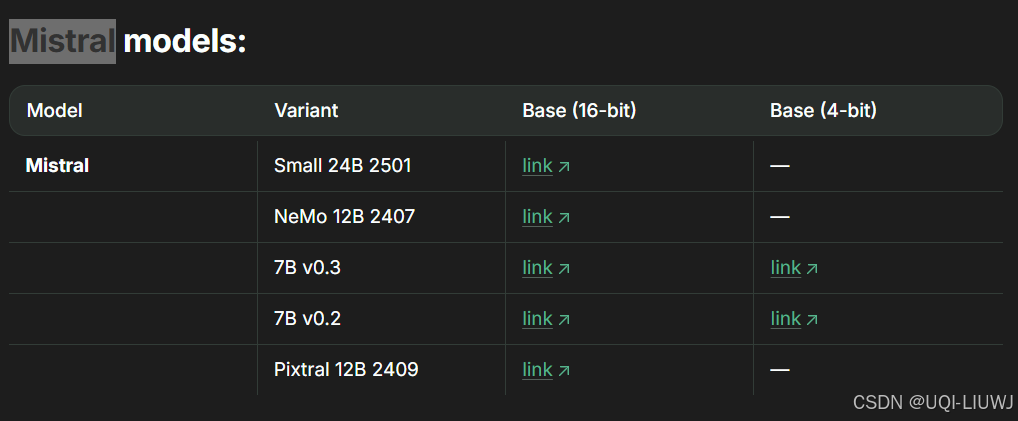
1.3.4?Mistral家族
1.4 unsloth版本模型命名后綴說明
| unsloth-bnb-4bit | Unsloth 的動態 4bit 量化模型,精度更高,占用略多顯存 |
| bnb-4bit | 普通 BitsAndBytes 4bit 量化模型 |
| 無后綴 | 原始模型(16/8bit) |
2 可調參數推薦
| max_seq_length | 下文長度,Llama-3 支持到 8192,但建議先用 2048 測試 |
| dtype? | 默認None,若使用新 GPU 可設為 torch.float16 或 bfloat16 |
| load_in_4bit | 啟用 QLoRA,減少 4 倍顯存消耗 QLoRA 的準確性如今已經接近甚至超過 LoRA,建議默認使用 |
| full_finetuning | 若設為 True,則執行全參數微調(不推薦) |
3 選擇instruct模型還是base模型
| 數據量情況 | 推薦選擇 | 說明 |
|---|---|---|
| 超過 1000 行 | Base 模型 | 數據量充足,能充分訓練出新行為 |
| 300–1000 行高質量數據 | Base 或 Instruct | 視任務而定,兩者都可以 |
| 少于 300 行 | Instruct 模型 | 小樣本建議保留已有指令能力,僅做輕微定制 |
-
任務明確 + 數據少 → 用 Instruct 模型做輕微定制即可
-
任務復雜 / 數據多 → 從 Base 模型開始訓練,得到效果更穩的定制模型

![【STM32】貪吃蛇 [階段 8] 嵌入式游戲引擎通用框架設計](http://pic.xiahunao.cn/【STM32】貪吃蛇 [階段 8] 嵌入式游戲引擎通用框架設計)

—— Web 核心概念、HTTP/HTTPS協議 與 Nginx 安裝)





)
)




 --- 多表連接查詢篇)


---出現interactive_timeout/wait_timeout)
