背景
????????在使用flink的過程中,多次遇到過反壓(backpressure)的問題,這通常是因為數據處理的速率超過了數據源或下游系統的處理能力導致。
反壓的底層剖析
網絡流控

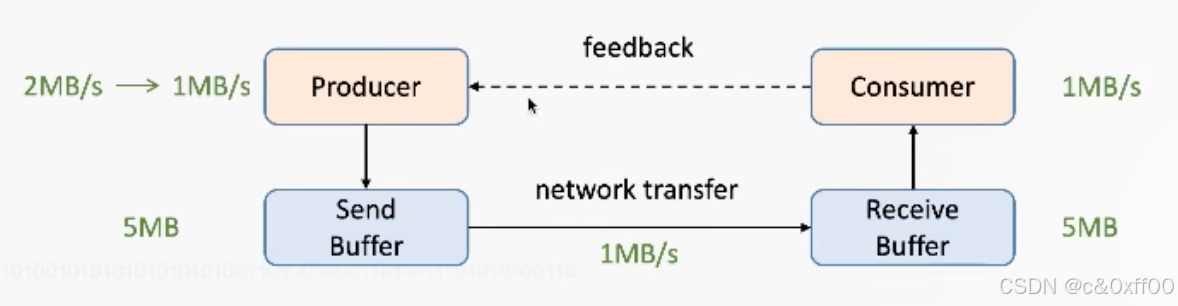
????????一個重要的概念是網絡流控,如上圖,不同的Consumer和Producer的消費和生產速率不一樣,那么一定時候后,receive buffer和send buffer就肯定會滿,導致生產端癱瘓。
為了能提前感知這一問題,引入了反壓機制,增加了一個feedback:
在設計的過程中,會包含正反饋和負反饋,在反壓的場景下,就是負反饋,讓生產端降低發送速率,甚至停止發送。
 Flink1.5以前的流控方式
Flink1.5以前的流控方式
在1.5以前,Flink基于TCP實現流控,如圖:
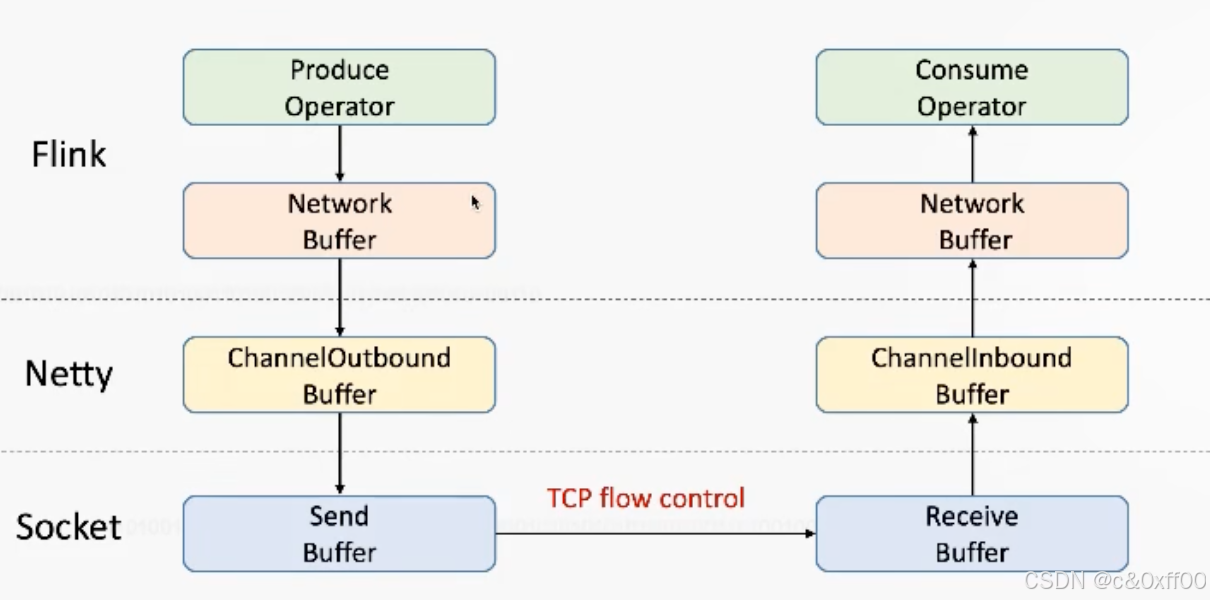 我們知道TCP通過滑動窗口ack機制實現了流量控制,簡單來說就是TCP接收端會在每次收到數據包后給發送端返回兩個主要信息:
我們知道TCP通過滑動窗口ack機制實現了流量控制,簡單來說就是TCP接收端會在每次收到數據包后給發送端返回兩個主要信息:
ACK=下次從哪個index繼續發送
window=最多發送多少個字節
ack=8
window=1
如上表示從第8個字節繼續發送,但只能發送1個,從而控制發送端的發送速度
拓展:如果返回window=0,代表接收端buffer已滿,發送端會停止發送。為了知道什么時候可以繼續發送,發送端會發送一個探測信號zeroWindowProbe來檢測接收端的buffer情況。
Flink反壓如何傳播
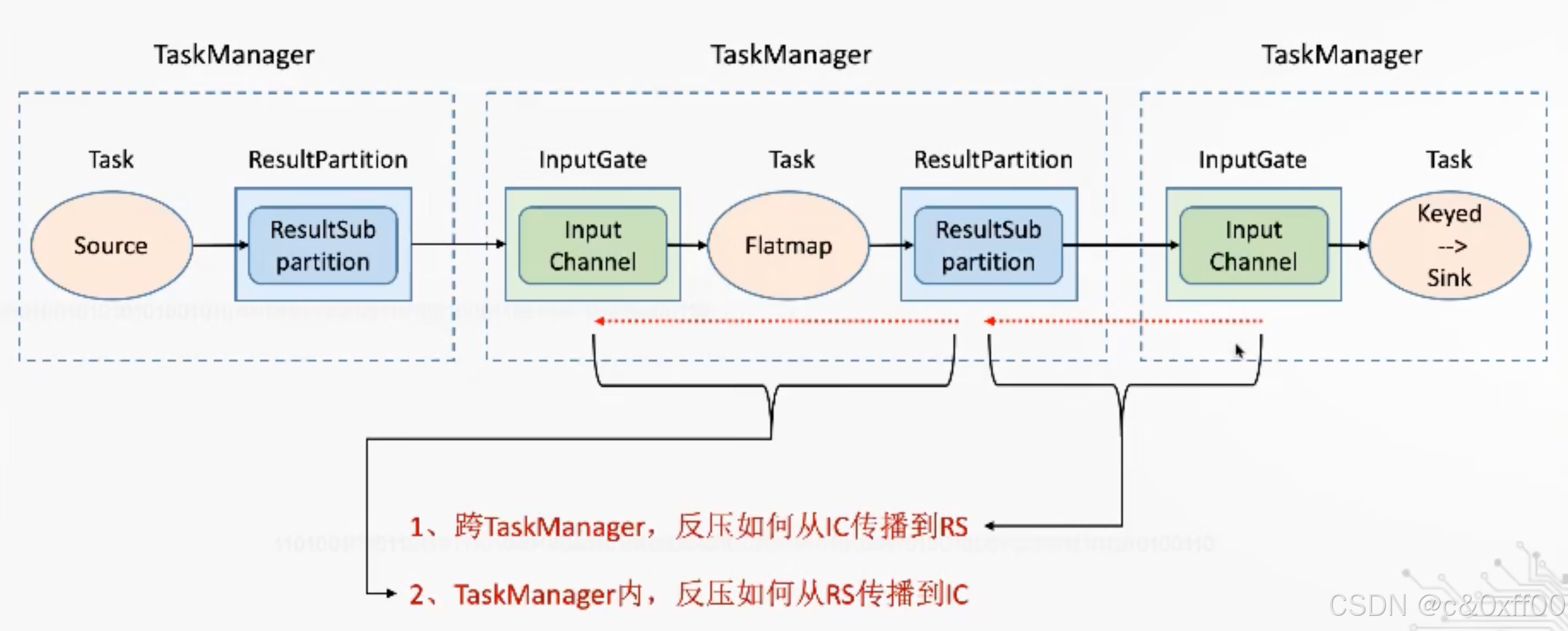
簡單來說,基于對接收緩沖區的剩余大小感知,如果下游的緩存區滿了,信號會從下游不斷傳遞給上游,直到所有算子的所有緩存區均打滿。
至于是跨TaskManager還是TaskManager內部,反壓的機制是同理的,主要關注不同邊界的緩沖區情況。
跨taskManager的反壓示意
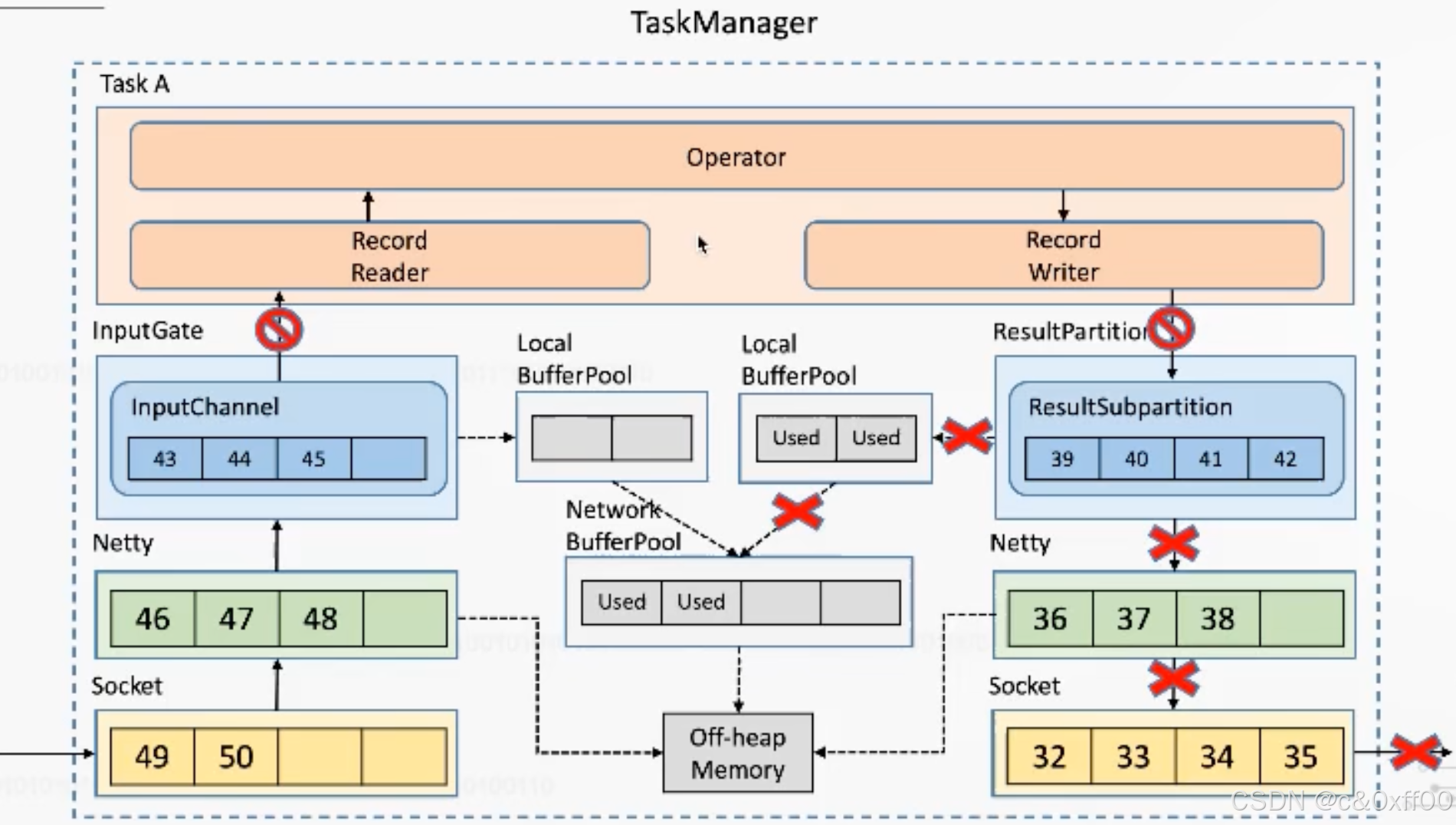
taskManager內反壓示意
基于TCP的反壓機制的弊端
? ? ? ? 雖然通過TCP可以實現反壓機制,但是因為過于通用,還是產生了一些犧牲,因為一個taskManager內可能會有多個Task進行,而多個Task會復用一個socket進行傳送(多路復用),如果某個task把tcp打滿,會導致Task間相互影響
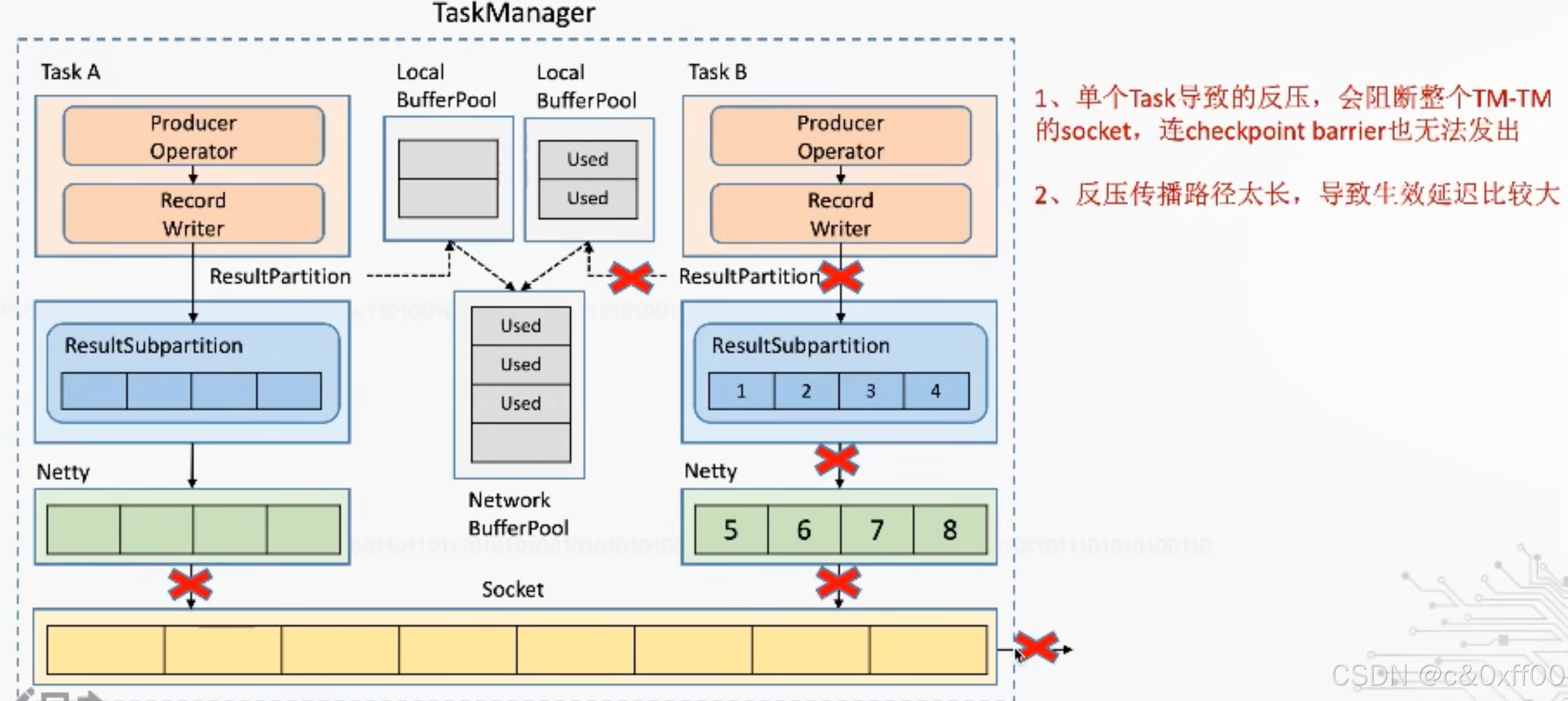
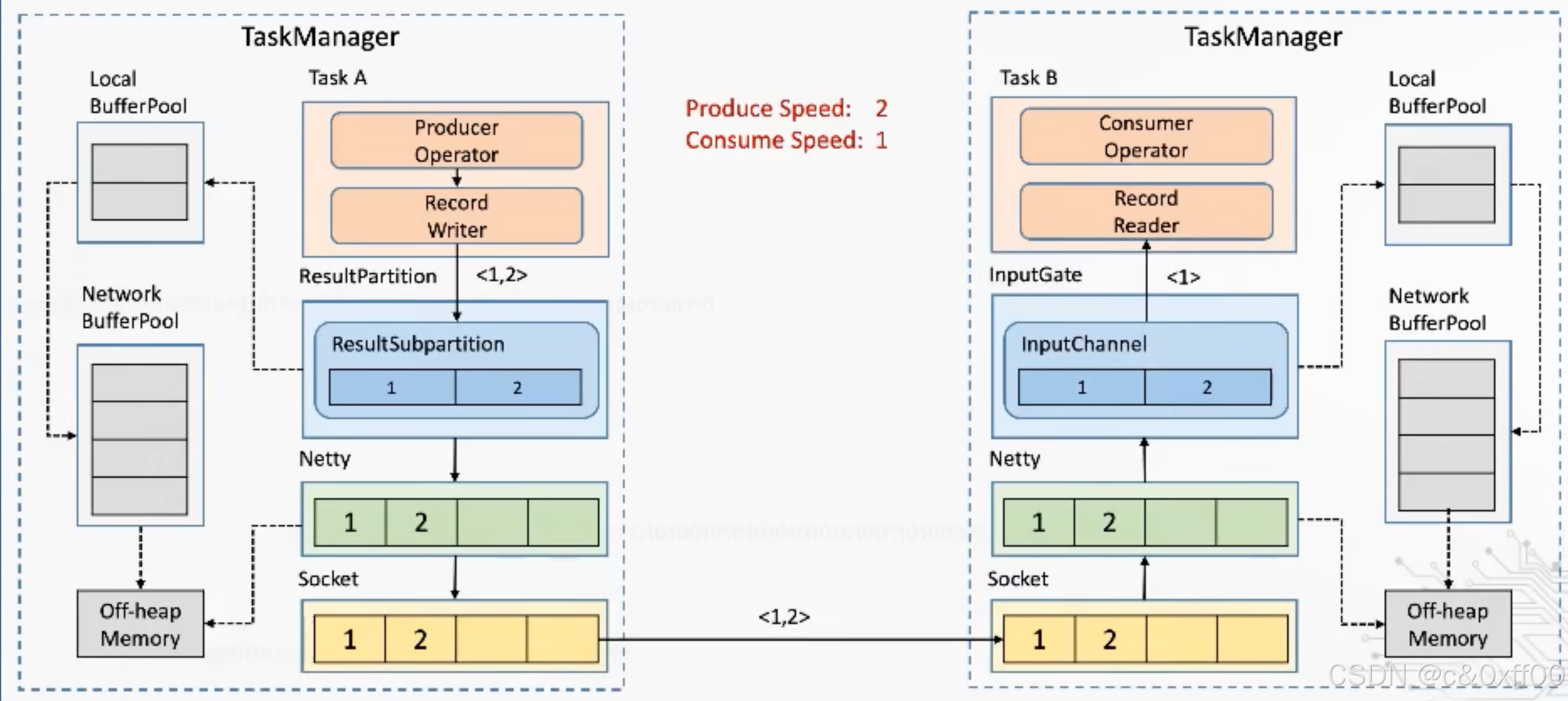
Flink1.5之后基于Credit-based的反壓機制
????????核心是通過Flink應用層來實現TCP流控的機制,避免影響底層tcp網絡
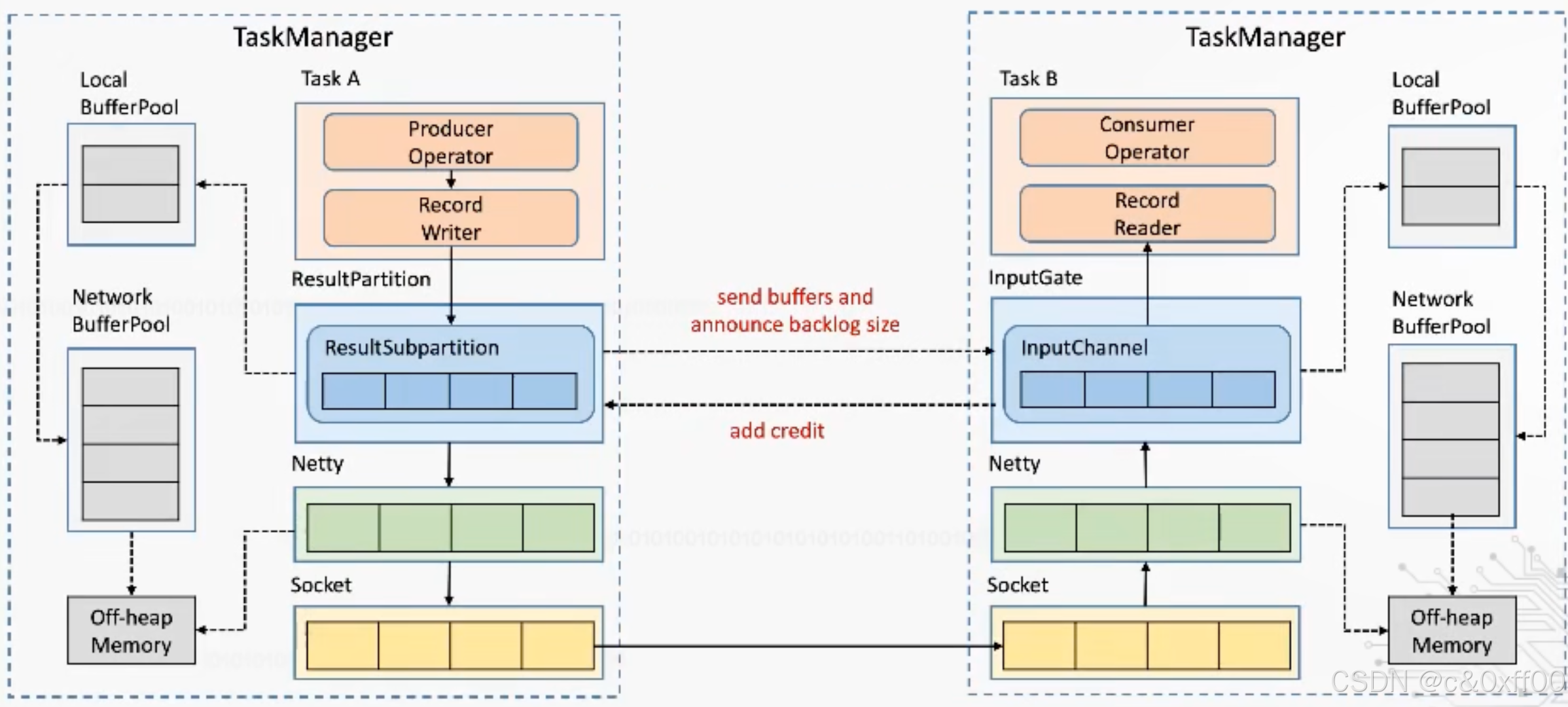
如上圖,通過ResultSubpartition這一層來控制,在每次發送內容的時候,發送端會帶上自己剩余的內容大小,而接收端收到后也會反饋inputChannel的剩余大小。這樣就可以跨過TCP、Netty這兩層,也就可以避免一個TaskManager中多個Task的相互影響。
反壓場景解決
? ? ? ? 了解的反壓的原理后,在面對Flink反壓時,我們核心要分析出哪個環節慢了,然后通過調整并行度,資源分配、性能優化等手段進行解決。

具體case
后續補充



 增量更新 po)

)






——Contextual Chunk Headers(CCH)技術)



)


什么時候引入Seata‘‘)