目錄
一、圖數據庫介紹
二、安裝Neo4j
2.1 安裝java環境
2.2?安裝 Neo4j(社區版)
2.3 修改配置
2.4 驗證測試
2.5 卸載
2.6 ?基本用法
2.7 windows連接服務器可視化
三、neo4j和mysql對比
3.1 場景對比
3.2 Mysql和neo4j的映射對比
3.3 mysql數據轉換到neo4j存儲
四、實操mysql到neo4j轉化
4.1 場景描述
4.2 neo4j數據建模設計
4.3 python代碼實現數據導入
4.4 常見錯誤及解決方法
4.5 代碼不使用apoc插件
五、參考資料
一、圖數據庫介紹
圖形數據庫(例如 Neo4j)是用于表示和處理以圖形形式存儲的數據的數據庫。圖形數據由節點?、?邊(?或關系)?和屬性組成。節點表示實體,關系連接實體,屬性提供有關節點和關系的附加元數據。
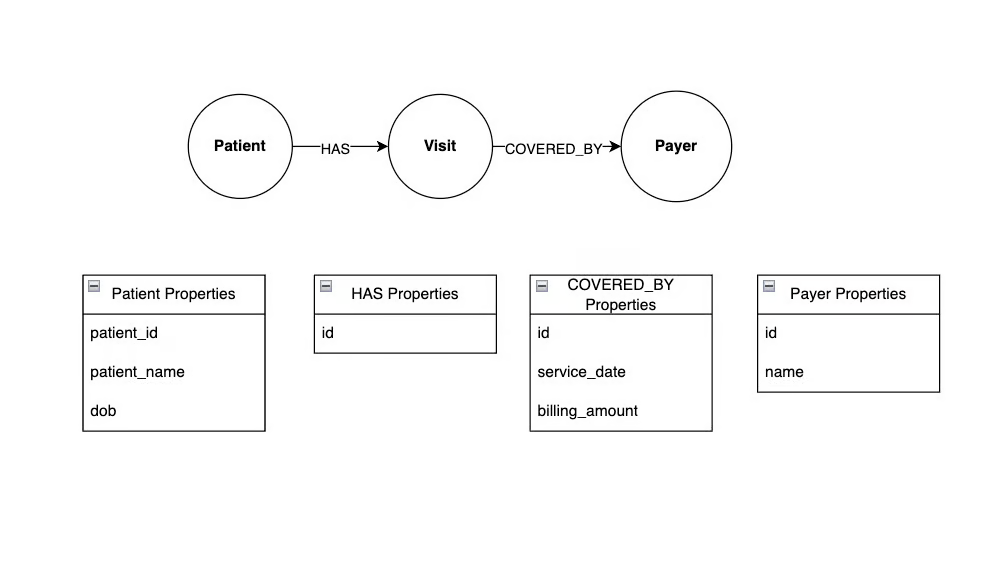
該圖包含三個節點 -?Patient?、?Visit?和?Payer?。?Patient?和?Visit?通過?HAS?關系連接,表示某位住院患者進行了一次就診。同樣,?Visit?和?Payer?通過?COVERED_BY?關系連接,表示某位保險支付方承擔了某次住院費用。
注意,這些關系是用箭頭表示方向的。例如,?HAS?關系的方向表示患者可以就診,但就診不能有患者。
節點和關系都可以具有屬性。在本例中,?Patient?節點具有 ID、姓名和出生日期屬性,而?COVERED_BY?關系具有服務日期和賬單金額屬性。像這樣將數據存儲在圖中有幾個優點:
簡單性?:在圖形數據庫中對實體之間的真實關系進行建模是很自然的,從而減少了需要多個連接操作來回答查詢的復雜模式的需要。
關系?:圖形數據庫擅長處理復雜的關系。遍歷關系非常高效,可以輕松查詢和分析關聯數據。
靈活性?:圖形數據庫無模式,可以輕松適應不斷變化的數據結構。這種靈活性有利于不斷發展的數據模型。
性能?:在圖形數據庫中檢索連接數據的速度比在關系數據庫中更快,特別是對于涉及具有多種關系的復雜查詢的場景。
模式匹配?:圖形數據庫支持強大的模式匹配查詢,使得表達和查找數據中的特定結構變得更加容易。
當您的數據具有許多復雜的關系時,與關系數據庫相比,圖數據庫的簡單性和靈活性使其更易于設計和查詢。正如您稍后將看到的,在圖數據庫查詢中指定關系非常簡潔,并且不需要復雜的連接操作。如果您感興趣,Neo4j 在其文檔中通過一個實際的示例數據庫很好地說明了這一點。
由于這種簡潔的數據表示,LLM 生成圖數據庫查詢時出錯的可能性更小。這是因為您只需告知 LLM 圖數據庫中的節點、關系和屬性。相比之下,關系數據庫的 LLM 必須遍歷并保留整個數據庫中的表模式和外鍵關系,這導致 SQL 生成過程中更容易出錯。
二、安裝Neo4j
需求,在ubuntu服務器安裝neo4j,windows上安裝可視化
2.1 安裝java環境
Neo4j 依賴 Java 運行環境,需先安裝 OpenJDK:
sudo apt update
sudo apt install openjdk-11-jdk
java -version ?# 驗證安裝

2.2?安裝 Neo4j(社區版)
# 下載并添加 Neo4j 官方 GPG 密鑰
wget -O - https://debian.neo4j.com/neotechnology.gpg.key | sudo apt-key add -# 添加 Neo4j 5.x 的倉庫源
echo 'deb https://debian.neo4j.com stable 5' | sudo tee /etc/apt/sources.list.d/neo4j.list# 安裝 Neo4j
sudo apt updatesudo apt install neo4j
# 或者安裝特定版本
sudo apt install neo4j=1:5.26.11
# 啟動服務
sudo systemctl start neo4j# 查看運行狀態
sudo systemctl status neo4j
sudo systemctl enable neo4j ?# 設置開機自啟
2.3 修改配置
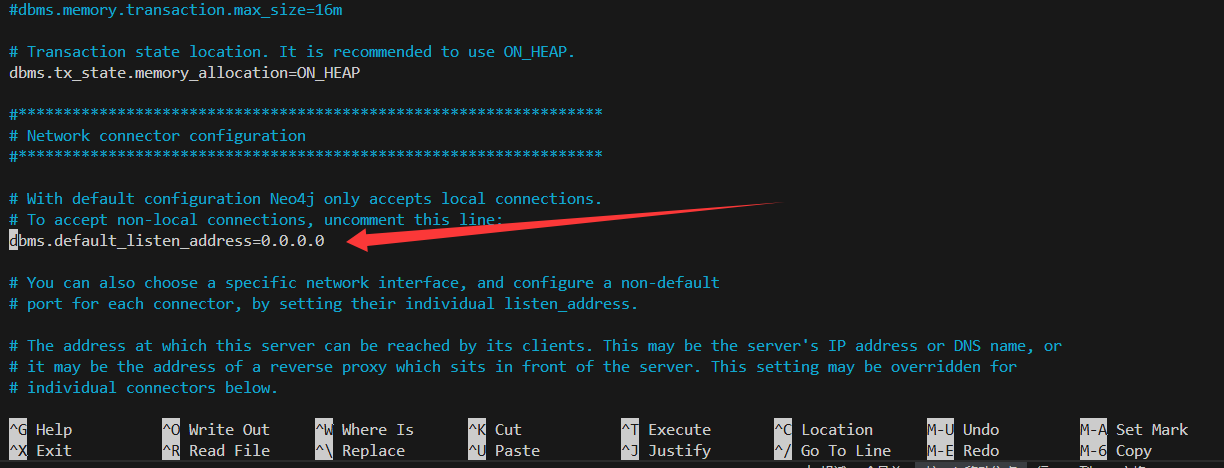
默認配置下,Neo4j 只允許本地連接。要允許從 Windows 機器訪問,需修改其配置文件。
找到并修改以下行,確保 Neo4j 監聽所有網絡接口:
sudo nano /etc/neo4j/neo4j.conf
# 取消注釋或修改為以下內容
dbms.default_listen_address=0.0.0.0# 分配內存
dbms.memory.heap.initial_size=1G
dbms.memory.heap.max_size=2G
重啟服務,配置信息才會生效
sudo systemctl restart neo4j? ? ? # 重啟服務
sudo systemctl enable neo4j ? ? ?# 設置開機自動啟動
sudo systemctl status neo4j ? ? ?# 檢查服務狀態
2.4 驗證測試
- 打開?http://localhost:7474
- 使用默認用戶名?
neo4j?和初始密碼?neo4j?登錄 - 按提示設置新密碼
2.5 卸載
# 停止 Neo4j 服務
sudo systemctl stop neo4j# 卸載 neo4j 軟件包(保留配置文件可選)
sudo apt remove neo4j# 如果你想徹底刪除所有配置文件和數據,可以使用 purge
sudo apt purge neo4j
2.6 ?基本用法
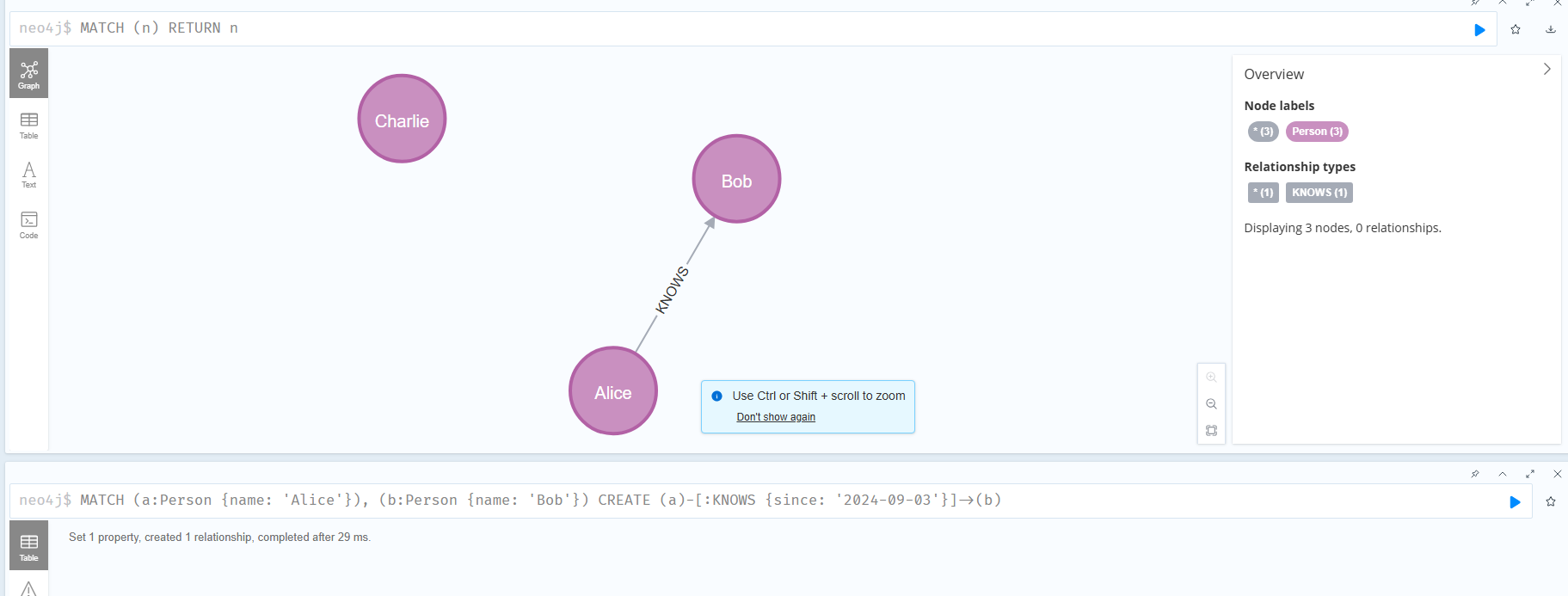
使用瀏覽器來進行增刪改查
CREATE (n:Person {name: 'Alice', age: 30})
CREATE (a:Person {name: 'Bob', age: 25}), (b:Person {name: 'Charlie', age: 35})
# 創建關系
MATCH (a:Person {name: 'Alice'}), (b:Person {name: 'Bob'}) CREATE (a)-[:KNOWS {since: '2024-09-03'}]->(b)
# 查詢
MATCH (n) RETURN n
MATCH (p:Person {name: 'Alice'}) RETURN p
#?查找年齡大于 25 且名字以 'A' 開頭的人
MATCH (p:Person)
WHERE p.age > 25 AND p.name STARTS WITH 'A'RETURN p
查詢節點和關系的個數
-- 檢查是否還有任何節點存在,期望結果為 0
MATCH (n) RETURN count(n);-- 檢查是否還有任何關系存在,期望結果為 0
MATCH ()-[r]->() RETURN count(r);
刪除所有節點信息:
-- 這將匹配并刪除所有節點及其所有關系
MATCH (n) DETACH DELETE n;
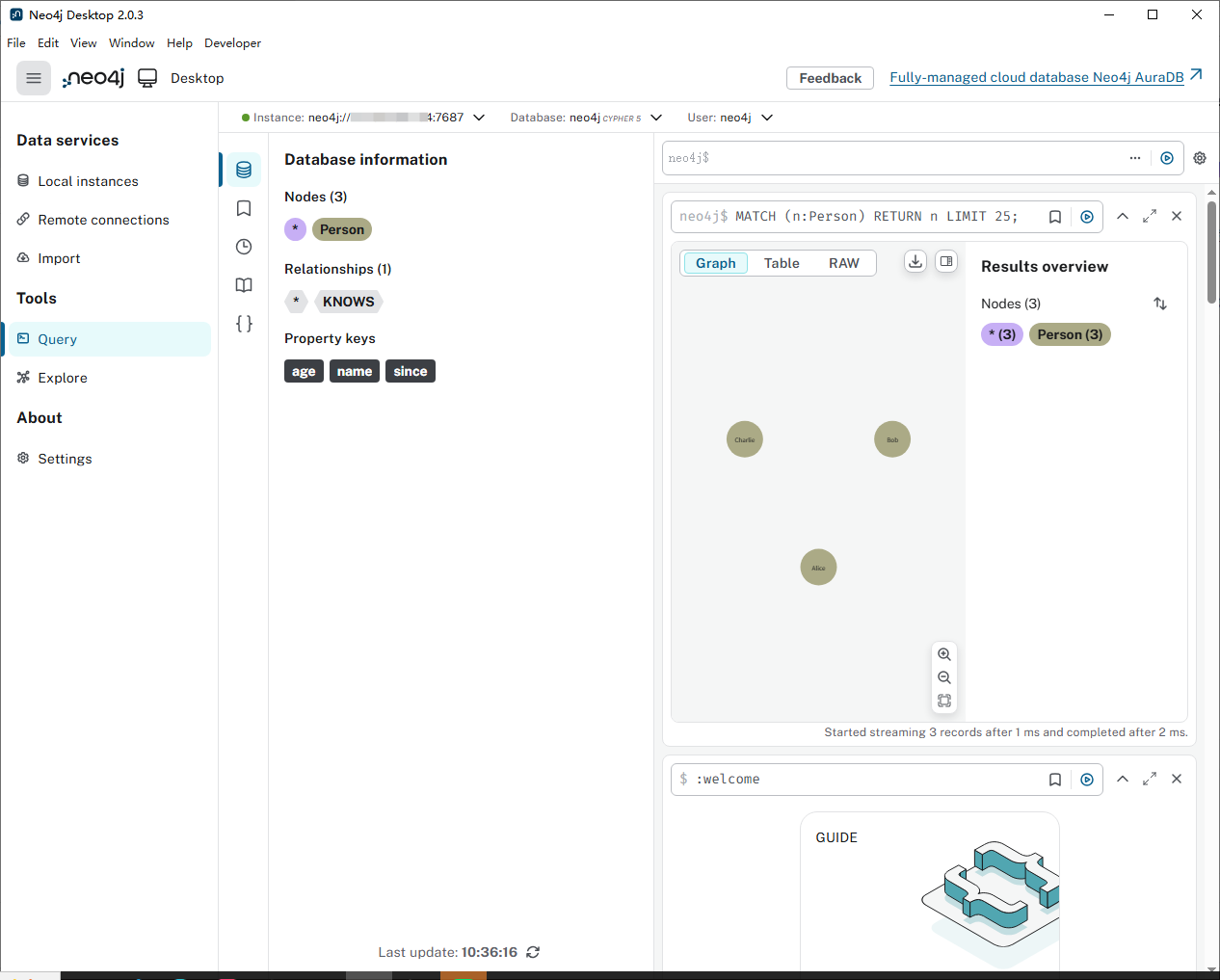
2.7 windows連接服務器可視化
訪問官網,下載windows的軟件
Thanks for Downloading Neo4j Desktop - Graph Database & Analytics
然后選擇連接,用戶名是 neoj4 ,密碼如果沒有在瀏覽器改過,就是neoj4,修改過就是修改后的密碼。
連接的協議是?neo4j://? 地址是 服務器公網IP:7687? 用戶名:neoj4 密碼初始是 neoj4
三、neo4j和mysql對比
3.1 場景對比
| 對比維度 | Neo4j (圖數據庫) | MySQL (關系型數據庫) |
|---|---|---|
| ??數據模型?? | ??圖結構??:節點(實體)、關系(連接)、屬性(鍵值對) | ??表結構??:表、行、列,通過外鍵關聯 |
| ??查詢語言?? | ??Cypher??:聲明式語言,直觀描述圖形模式(如? | ??SQL??:聲明式語言,用于操作和查詢表數據(如? |
| ??核心優勢?? | ??處理深度關聯數據??:多跳查詢(如朋友的朋友)、路徑查找、復雜關系分析性能極高,近乎實時 | ??處理結構化數據??:事務處理(OLTP)、復雜報表(OLAP)、多表連接查詢,技術成熟穩定 |
| ??典型應用場景?? | 社交網絡、推薦系統、欺詐檢測、知識圖譜、權限管理、供應鏈分析 | 電商平臺、ERP系統、財務系統、內容管理系統(CMS) |
| ??模式靈活性?? | ??動態模式(Schema-less)??:節點和關系的屬性可以隨時增減,無需預先定義嚴格結構 | ??固定模式(Schema-full)??:表結構需預先設計定義(DDL),修改成本較高 |
| ??擴展性?? | 支持原生圖存儲和優化,擅長垂直擴展;企業版支持因果集群實現高可用和水平讀擴展 | 支持主從復制、分片(Sharding)等方式進行水平和垂直擴展,方案成熟 |
| ??事務支持?? | 完全支持 ACID 事務 | 完全支持 ACID 事務 |
3.2 Mysql和neo4j的映射對比
| MySQL (關系型數據庫) | Neo4j (圖數據庫) | 說明 |
|---|---|---|
| ??表 (Table)?? | ??節點標簽 (Label)?? | 在 MySQL 中,一個表定義了一類實體的結構。在 Neo4j 中,一類實體用節點標簽表示,如? |
| ??一行記錄 (Row)?? | ??一個節點 (Node)?? | MySQL 表中的一行具體數據,對應 Neo4j 中的一個具體節點。 |
| ??列 (Column)?? | ??節點屬性 (Property)?? | MySQL 中描述實體屬性的列,對應 Neo4j 中節點的屬性鍵值對。 |
| ??外鍵關聯 (Foreign Key)?? | ??關系 (Relationship)?? | MySQL 中通過外鍵建立的表間關聯,在 Neo4j 中轉化為節點之間有方向、有類型的關系邊。 |
| ??關聯表 (Junction Table)?? | ??關系屬性 (Property)?? | 在處理多對多關系時,MySQL 可能需要關聯表,而 Neo4j 的關系本身可以直接擁有屬性。 |
| ??JOIN 查詢?? | ??關系遍歷?? | MySQL 中通過 JOIN 操作關聯多表,Neo4j 通過直接遍歷節點間的關系進行查詢,效率更高。 |
3.3 mysql數據轉換到neo4j存儲
🔄 從 MySQL 轉換到 Neo4j 的關鍵步驟
將 MySQL 數據庫遷移到 Neo4j 通常包含以下幾個核心階段
- 1?數據建模(核心)??:
- ?識別 MySQL 中的每個??表??:這些表通常會成為 Neo4j 中的??節點標簽??(Label)。例如,
Users表對應?:User節點。 - ?識別 MySQL 表中的??列??:這些列通常會成為 Neo4j 中節點的??屬性??。例如,
Users表中的?name,?email列。 - ?識別 MySQL 中的??外鍵關系??或??關聯表??:這些是轉換的關鍵。它們會成為 Neo4j 中連接節點的??關系??(Relationship)。你需要為每種關系定義一個??類型??(Type)和??方向??(Direction)。例如,
FRIENDS_WITH、PLACED_ORDER、BELONGS_TO。
- ?識別 MySQL 中的每個??表??:這些表通常會成為 Neo4j 中的??節點標簽??(Label)。例如,
- 2?數據遷移??:
- ?編寫 ETL (Extract, Transform, Load) 腳本或使用數據遷移工具。
- ?提取 (Extract)??:從 MySQL 中讀取數據。
- ?轉換 (Transform)??:將 MySQL 的數據結構轉換為 Neo4j 的圖數據結構(按照上一步的模型)。
- ?加載 (Load)??:將轉換后的數據導入 Neo4j。這可以通過 Neo4j 的?
neo4j-admin批量導入工具實現,或者使用官方驅動(如?neo4j-python-driver)通過 Cypher 語句寫入
- 3?應用層調整??:
- ?將應用程序中原先的 SQL 查詢語句??重寫為 Cypher 查詢語句??。
- ?調整代碼中與數據庫交互的部分,使其適應 Neo4j 的查詢方式和返回結果。
比如:假設有一個簡單的 MySQL 數據庫,包含?Users表和?Orders表
CREATE TABLE Users (UserID INT PRIMARY KEY,UserName VARCHAR(50)
);
CREATE TABLE Orders (OrderID INT PRIMARY KEY,UserID INT,ProductName VARCHAR(50),FOREIGN KEY (UserID) REFERENCES Users(UserID)
);轉換為 Neo4j 的 Cypher 語句:?
// 創建 User 節點
CREATE (u:User {UserID: 123, UserName: 'Alice'});// 創建 Order 節點
CREATE (o:Order {OrderID: 456, ProductName: 'Laptop'});// 創建用戶和訂單之間的關系 (假設用戶ID123下了訂單ID456)
MATCH (u:User {UserID: 123}), (o:Order {OrderID: 456})
CREATE (u)-[:PLACED_ORDER]->(o);四、實操mysql到neo4j轉化
4.1 場景描述
mysql數據庫中有兩張表,用于記錄用戶和大模型交互系統的數據。
一張是chat_feedback.csv,用戶反饋的表格
詳細記錄了哪個組織的哪個用戶對哪個會話的哪輪回答進行點贊還是點踩(也可能沒有點贊點踩),還有相關原因。
org_id user_id conversation_id task_id query answer is_like reasons comment created_at updated_at
還有一個表格是conversations.csv,用戶會話表格
詳細記錄了 哪個組織的哪個用戶的會話信息情況,下面是相關字段
org_id user_id conversation_id conversation_len conversation_name created_at updated_at
現在我們的目的是把上述兩張表信息存儲到neo4j中,然后進行高效的查詢下述問題:
1)?查詢某個組織(例如org_id為'XYZ')收到的所有負面反饋(is_like為0)及其原因
2)?查找用戶'user123'提交的所有反饋所在的會話及其會話名稱
3)分析某個會話(conversation_id為'conv456')中反饋的分布情況(點贊、點踩數量)
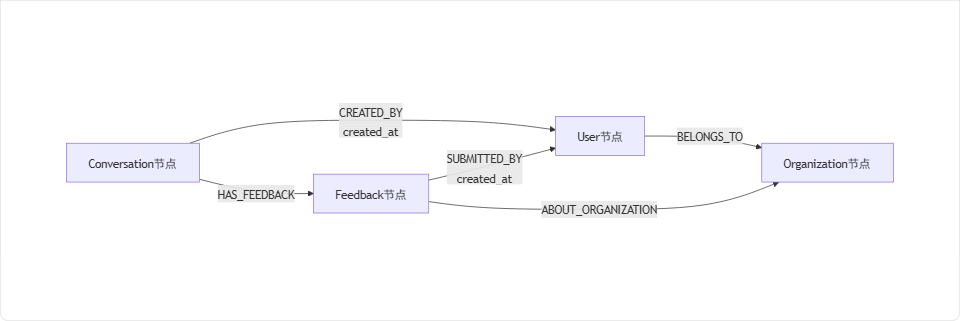
4.2 neo4j數據建模設計
| 節點名稱 | 屬性 | 標簽 |
|---|---|---|
| ??組織?? |
|
|
| ??用戶?? |
|
|
| ??會話?? |
|
|
| ??反饋?? |
|
|
| 關系名稱 | 方向 | 屬性(示例) | 描述 |
|---|---|---|---|
|
| 用戶 → 組織 | - | 用戶屬于某個組織 |
|
| 會話 → 用戶 | ?? | 會話由某個用戶在特定時間創建 |
|
| 會話 → 反饋 | - | 會話包含多條反饋 |
|
| 反饋 → 用戶 | ?? | 反饋由某個用戶在特定時間提交 |
|
| 反饋 → 組織 | - | 反饋針對某個組織(可選,根據查詢需求) |
4.3 python代碼實現數據導入
import pandas as pd
from neo4j import GraphDatabase# Neo4j 連接配置
NEO4J_URI = "bolt://localhost:7687"
NEO4J_USER = "neo4j"
NEO4J_PASSWORD = "your_password" # 請替換為你的密碼# 初始化驅動
driver = GraphDatabase.driver(NEO4J_URI, auth=(NEO4J_USER, NEO4J_PASSWORD))def import_to_neo4j(conversations_csv_path, chat_feedback_csv_path):"""將CSV數據導入Neo4j:param conversations_csv_path: 會話CSV文件路徑:param chat_feedback_csv_path: 反饋CSV文件路徑"""# 讀取CSV文件df_conversations = pd.read_csv(conversations_csv_path)df_feedback = pd.read_csv(chat_feedback_csv_path)with driver.session() as session:# 1. 清空現有數據庫(謹慎使用!根據需求決定是否保留)# session.run("MATCH (n) DETACH DELETE n")# 2. 創建索引以提高查詢和導入性能session.run("CREATE INDEX IF NOT EXISTS FOR (o:Organization) ON (o.org_id)")session.run("CREATE INDEX IF NOT EXISTS FOR (u:User) ON (u.user_id)")session.run("CREATE INDEX IF NOT EXISTS FOR (c:Conversation) ON (c.conversation_id)")session.run("CREATE INDEX IF NOT EXISTS FOR (f:Feedback) ON (f.created_at)")# 3. 批量處理組織、用戶和會話節點及其關系# 使用apoc.periodic.iterate進行批量處理,提高大規模數據導入效率create_nodes_relationships_query = """CALL apoc.periodic.iterate('UNWIND $batch AS row RETURN row','MERGE (org:Organization {org_id: row.org_id})MERGE (user:User {user_id: row.user_id})MERGE (conv:Conversation {conversation_id: row.conversation_id})ON CREATE SET conv.conversation_name = row.conversation_name,conv.conversation_len = row.conversation_len,conv.created_at = row.created_at,conv.updated_at = row.updated_atMERGE (user)-[:BELONGS_TO]->(org)// 創建CREATED_BY關系并設置created_at屬性MERGE (conv)-[:CREATED_BY {created_at: row.created_at}]->(user)',{batchSize: 10000, parallel: false, params: {batch: $batch}})"""conversations_batch = df_conversations.to_dict('records')session.run(create_nodes_relationships_query, batch=conversations_batch)# 4. 批量處理反饋節點及其關系create_feedback_relationships_query = """CALL apoc.periodic.iterate('UNWIND $batch AS row RETURN row','MATCH (conv:Conversation {conversation_id: row.conversation_id})MATCH (user:User {user_id: row.user_id})MATCH (org:Organization {org_id: row.org_id})CREATE (feedback:Feedback {is_like: row.is_like,reasons: row.reasons,comment: row.comment,query: row.query,answer: row.answer,created_at: row.created_at,updated_at: row.updated_at})CREATE (conv)-[:HAS_FEEDBACK]->(feedback)// 創建SUBMITTED_BY關系并設置created_at屬性CREATE (feedback)-[:SUBMITTED_BY {created_at: row.created_at}]->(user)CREATE (feedback)-[:ABOUT_ORGANIZATION]->(org)',{batchSize: 10000, parallel: false, params: {batch: $batch}})"""feedback_batch = df_feedback.to_dict('records')session.run(create_feedback_relationships_query, batch=feedback_batch)print("數據導入完成!")if __name__ == "__main__":try:import_to_neo4j("conversations.csv", "chat_feedback.csv")except Exception as e:print(f"導入過程中發生錯誤: {e}")finally:driver.close()4.4 常見錯誤及解決方法
{code: Neo.ClientError.Procedure.ProcedureNotFound} {message: There is no procedure with the name `apoc.periodic.iterate` registered for this database instance. Please ensure you've spelled the procedure name correctly and that the procedure is properly deployed.}
報錯說明neo4j服務器端沒有安裝匹配版本的apoc插件,或者沒有啟用這個插件。
查找一下插件目錄位置
sudo systemctl status neo4j
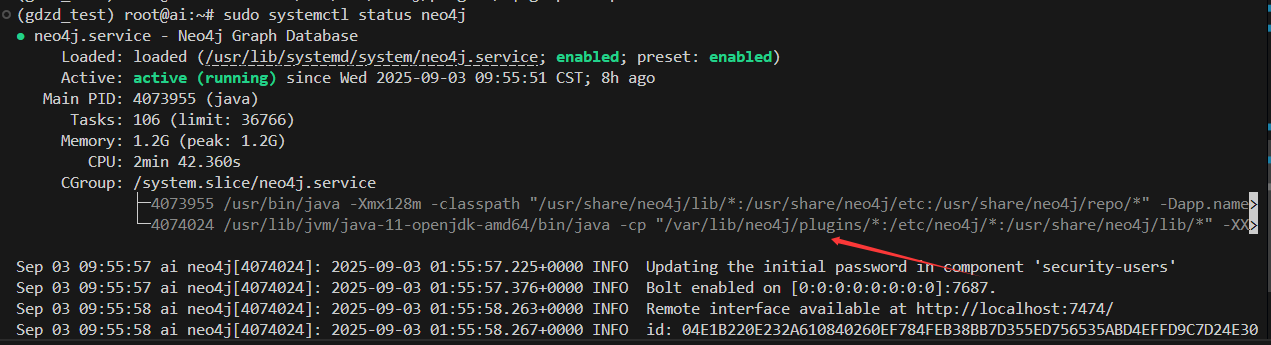
確認插件目錄/var/lib/neo4j/plugins/,再查找目錄下有沒有apoc插件
cd /var/lib/neo4j/plugins/
ls

說明沒有安裝插件
確認neo4j版本號
CALL dbms.components() YIELD name, versions
RETURN name, versions;
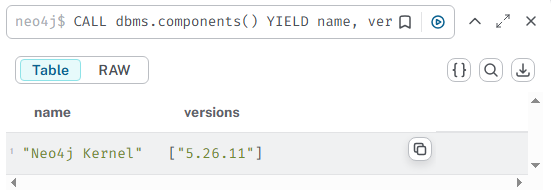
根據查詢得到的 Neo4j 版本號,去 ??GitHub Release?? 頁面下載對應版本的 APOC 插件。
確保你下載的 APOC 版本與你的 Neo4j 版本完全一致(例如 Neo4j 4.4.45對應 APOC 4.4.45)。
然后直接將 Jar 文件放入?plugins目錄,??不要??新建子文件夾,也??不要??解壓 Jar 包
sudo cp /path/to/your/downloaded/apoc-*.jar /var/lib/neo4j/plugins/
sudo cp /root/apoc-5.26.11-core.jar /var/lib/neo4j/plugins/
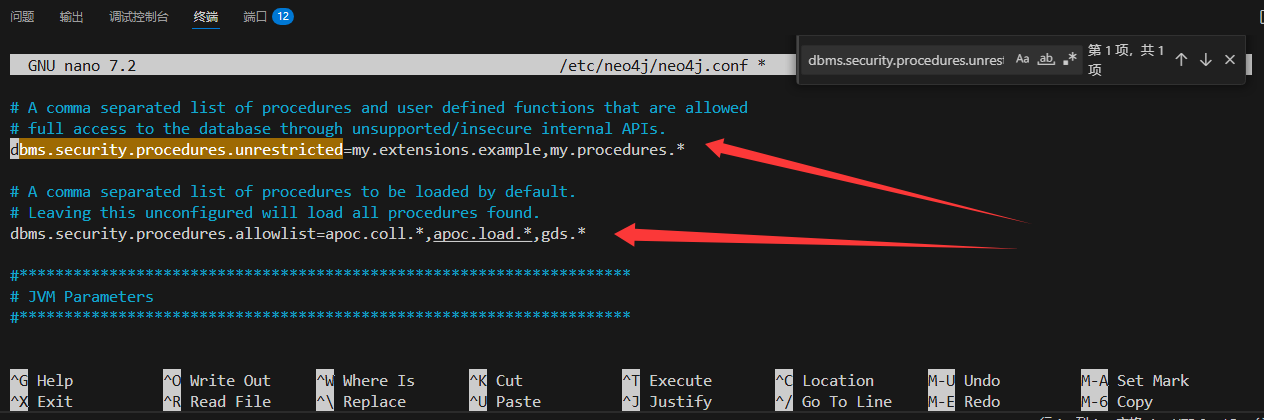
修改配置文件
sudo nano /etc/neo4j/neo4j.conf
#找到如下配置打開
dbms.security.procedures.unrestricted=apoc.*
dbms.security.procedures.allowlist=apoc.*# 重啟生效
sudo systemctl restart neo4j
# 驗證
RETURN apoc.version();
4.5 代碼不使用apoc插件
如果插件apoc安裝還是失敗,那就修改代碼,不用apoc插件,這個插件比較快。面對大文件或者多種格式的文件都可以。
import pandas as pd
from neo4j import GraphDatabase
import chardet # 用于自動檢測文件編碼# Neo4j 連接配置
NEO4J_URI = "neo4j://yourIP:7687"
NEO4J_USER = "neo4j"
NEO4J_PASSWORD = "password" # 請替換為你的密碼def detect_encoding(file_path):"""自動檢測文件的編碼格式:param file_path: 文件路徑:return: 檢測到的編碼字符串,如 'utf-8', 'gbk' 等"""with open(file_path, 'rb') as f:raw_data = f.read(10000) # 讀取文件前10000字節來檢測編碼,通常足夠result = chardet.detect(raw_data)encoding = result['encoding']confidence = result['confidence']print(f"文件 '{file_path}' 檢測到編碼: {encoding} (置信度: {confidence:.2f})")return encoding if confidence > 0.7 else 'utf-8' # 如果置信度太低,則默認使用utf-8嘗試def read_csv_with_encoding(file_path, fallback_encodings=['utf-8', 'gbk', 'gb18030', 'iso-8859-1']):"""嘗試使用檢測到的或備選的編碼讀取CSV文件:param file_path: 文件路徑:param fallback_encodings: 備選編碼列表:return: DataFrame對象"""# 首先嘗試自動檢測編碼try:detected_encoding = detect_encoding(file_path)if detected_encoding:df = pd.read_csv(file_path, encoding=detected_encoding)print(f"使用檢測到的編碼 '{detected_encoding}' 成功讀取文件 '{file_path}'")return dfexcept Exception as e:print(f"使用檢測到的編碼 '{detected_encoding}' 讀取文件 '{file_path}' 失敗: {e}")print("開始嘗試備選編碼...")# 如果自動檢測失敗,則逐個嘗試備選編碼for enc in fallback_encodings:try:df = pd.read_csv(file_path, encoding=enc)print(f"使用備選編碼 '{enc}' 成功讀取文件 '{file_path}'")return dfexcept UnicodeDecodeError as e:print(f"備選編碼 '{enc}' 失敗: {e}")continueexcept Exception as e:print(f"使用備選編碼 '{enc}' 讀取文件時發生其他錯誤: {e}")continue# 所有編碼嘗試都失敗raise ValueError(f"無法讀取文件 '{file_path}',所有嘗試的編碼均失敗。")def import_to_neo4j(conversations_csv_path, chat_feedback_csv_path):"""將CSV數據導入Neo4j:param conversations_csv_path: 會話CSV文件路徑:param chat_feedback_csv_path: 反饋CSV文件路徑"""# 讀取CSV文件,處理編碼問題try:df_conversations = read_csv_with_encoding(conversations_csv_path)df_feedback = read_csv_with_encoding(chat_feedback_csv_path)# 確保日期列是字符串類型,避免后續處理問題for df in [df_conversations, df_feedback]:if 'created_at' in df.columns:df['created_at'] = df['created_at'].astype(str)if 'updated_at' in df.columns:df['updated_at'] = df['updated_at'].astype(str)except Exception as e:print(f"讀取CSV文件時發生錯誤: {e}")return# 初始化Neo4j驅動driver = GraphDatabase.driver(NEO4J_URI, auth=(NEO4J_USER, NEO4J_PASSWORD))try:with driver.session() as session:# 1. 清空現有數據庫(謹慎使用!根據需求決定是否保留)session.run("MATCH (n) DETACH DELETE n")# 2. 創建索引以提高查詢和導入性能[3](@ref)session.run("CREATE INDEX IF NOT EXISTS FOR (o:Organization) ON (o.org_id)")session.run("CREATE INDEX IF NOT EXISTS FOR (u:User) ON (u.user_id)")session.run("CREATE INDEX IF NOT EXISTS FOR (c:Conversation) ON (c.conversation_id)")session.run("CREATE INDEX IF NOT EXISTS FOR (f:Feedback) ON (f.created_at)")# 3. 批量處理組織、用戶和會話節點及其關系(使用UNWIND代替APOC)[1,3](@ref)print("開始導入會話數據...")conversations_batch = df_conversations.to_dict('records')batch_size = 10000 # 每批處理的數據量[3](@ref)for i in range(0, len(conversations_batch), batch_size):batch = conversations_batch[i:i+batch_size]create_nodes_relationships_query = """UNWIND $batch AS rowMERGE (org:Organization {org_id: row.org_id})MERGE (user:User {user_id: row.user_id})MERGE (conv:Conversation {conversation_id: row.conversation_id})ON CREATE SET conv.conversation_name = row.conversation_name,conv.conversation_len = row.conversation_len,conv.created_at = row.created_at,conv.updated_at = row.updated_atMERGE (user)-[:BELONGS_TO]->(org)MERGE (conv)-[:CREATED_BY {created_at: row.created_at}]->(user)"""session.run(create_nodes_relationships_query, batch=batch)print(f"已處理 {min(i+batch_size, len(conversations_batch))}/{len(conversations_batch)} 條會話記錄")print("會話數據導入完成!")# 4. 批量處理反饋節點及其關系(使用UNWIND代替APOC)print("開始導入反饋數據...")feedback_batch = df_feedback.to_dict('records')for i in range(0, len(feedback_batch), batch_size):batch = feedback_batch[i:i+batch_size]create_feedback_relationships_query = """UNWIND $batch AS rowMATCH (conv:Conversation {conversation_id: row.conversation_id})MATCH (user:User {user_id: row.user_id})MATCH (org:Organization {org_id: row.org_id})CREATE (feedback:Feedback {is_like: row.is_like,reasons: row.reasons,comment: row.comment,query: row.query,answer: row.answer,created_at: row.created_at,updated_at: row.updated_at})CREATE (conv)-[:HAS_FEEDBACK]->(feedback)CREATE (feedback)-[:SUBMITTED_BY {created_at: row.created_at}]->(user)CREATE (feedback)-[:ABOUT_ORGANIZATION]->(org)"""session.run(create_feedback_relationships_query, batch=batch)print(f"已處理 {min(i+batch_size, len(feedback_batch))}/{len(feedback_batch)} 條反饋記錄")print("反饋數據導入完成!")print("所有數據導入完成!")except Exception as e:print(f"導入Neo4j過程中發生錯誤: {e}")finally:driver.close()if __name__ == "__main__":try:import_to_neo4j(r"C:\Users\GDZD-BG-202115\Desktop\knowlege\medgraph-ai\data\conversations.csv",r"C:\Users\GDZD-BG-202115\Desktop\knowlege\medgraph-ai\data\chat_feedback.csv")except Exception as e:print(f"導入過程中發生錯誤: {e}")導入數據成功后,就是增刪改查了。
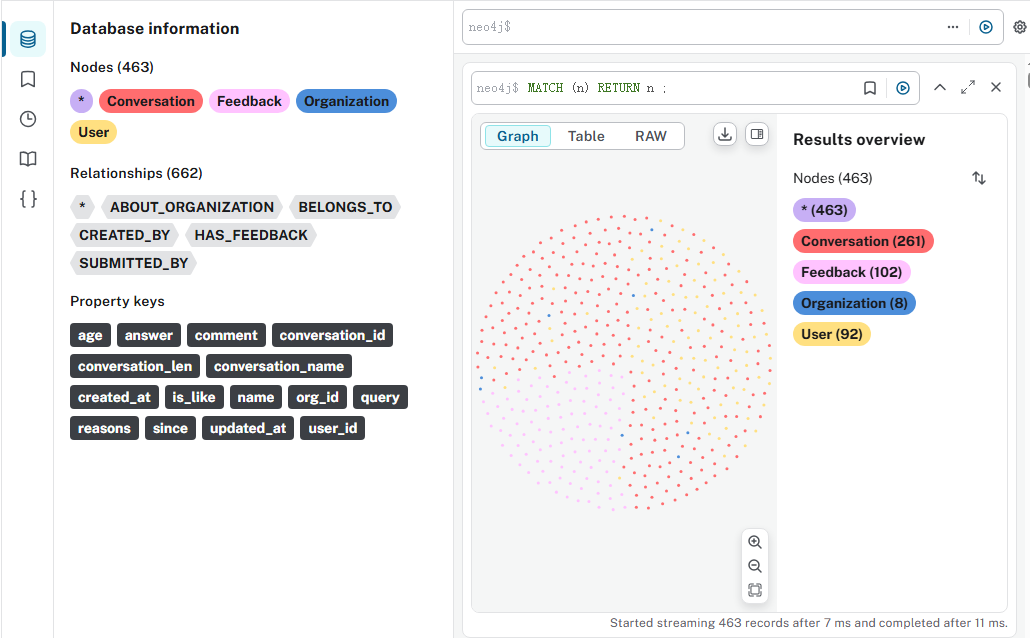
五、參考資料
asanmateu/medgraph-ai:基于 Neo4j 知識圖譜的醫療保健 RAG 代理 - 使用 LangChain、FastAPI 和 Streamlit 查詢醫療數據 --- asanmateu/medgraph-ai: Healthcare RAG agent with Neo4j knowledge graphs - Query medical data using LangChain, FastAPI & Streamlit
Cypher 與 SQL 的比較 - 入門 --- Comparing Cypher with SQL - Getting Started
企業知識庫AI助手的知識圖譜構建架構:從數據到圖譜-CSDN博客
Neo4j簡介及安裝_neo4j安裝-CSDN博客
Neo4j簡介及安裝_neo4j安裝-CSDN博客
從關系型到圖數據庫:MySQL到Neo4j的平滑遷移策略_mysql數據導入neo4j-CSDN博客
使用 LangChain 構建 LLM RAG 聊天機器人 – Real Python --- Build an LLM RAG Chatbot With LangChain – Real Python

---出現interactive_timeout/wait_timeout)


)



)










