Pytorch Yolov11 OBB 旋轉框檢測+window部署+推理封裝 留貼記錄
上一章寫了下【Pytorch Yolov11目標檢測+window部署+推理封裝 留貼記錄】,這一章開一下YOLOV11 OBB旋轉框檢測相關的全流程,有些和上一章重復的地方我會簡寫,要兩篇結合著看,好了,開始吧
1.數據標注和格式轉換
1.1 依舊是先下載預訓練模型/和源碼,或者程序運行時自己下載
1.2 主要講一下數據標注和數據處理成YOLO OBB需要的格式
1.2.1 標注軟件 roLabelImg
在conda虛擬環境自己部署和下載吧
和正常labelimg標注框是一樣的,多了zxcv鍵盤按鍵調整旋轉框旋轉角度的功能
文件夾規則:
images
labels_all
1.2.2 先看下標完的格式是啥樣子的
標完的格式是:name cx cy w h angle

實際需要的格式是:name x1 y1 x2 y2 x3 y3 x4 y4 歸一化
0 0.289583 0.151667 0.471354 0.311667 0.436979 0.708333 0.255208 0.546667
2 0.426042 0.458333 0.457292 0.48 0.450521 0.576667 0.419271 0.555
1.2.3 先格式轉換,將xml轉為txt
分了好幾步做的,至于為什么不一步寫到位,因為我也是抄別人的,我python沒什么基礎,我只想C++能調用起來就行
1.先將標注軟件的xml轉為了四角點的xml

2.然后提取出xml中的四角點和label,輸出到txt

3.還不算完哈,需要先劃分訓練集和測試集,再做最后的轉換
# 文件名稱 :roxml_to_dota.py
# 功能描述 :把rolabelimg標注的xml文件轉換成dota能識別的xml文件,
# 再轉換成dota格式的txt文件
# 把旋轉框 cx,cy,w,h,angle,或者矩形框cx,cy,w,h,轉換成四點坐標x1,y1,x2,y2,x3,y3,x4,y4
import os
import xml.etree.ElementTree as ET
import mathcls_list = ['Target','label','Top'] # 修改為自己的標簽def edit_xml(xml_file, dotaxml_file):"""修改xml文件:param xml_file:xml文件的路徑:return:"""# dxml_file = open(xml_file,encoding='gbk')# tree = ET.parse(dxml_file).getroot()tree = ET.parse(xml_file)objs = tree.findall('object')for ix, obj in enumerate(objs):x0 = ET.Element("x0") # 創建節點y0 = ET.Element("y0")x1 = ET.Element("x1")y1 = ET.Element("y1")x2 = ET.Element("x2")y2 = ET.Element("y2")x3 = ET.Element("x3")y3 = ET.Element("y3")# obj_type = obj.find('bndbox')# type = obj_type.text# print(xml_file)if (obj.find('robndbox') == None):obj_bnd = obj.find('bndbox')obj_xmin = obj_bnd.find('xmin')obj_ymin = obj_bnd.find('ymin')obj_xmax = obj_bnd.find('xmax')obj_ymax = obj_bnd.find('ymax')# 以防有負值坐標xmin = max(float(obj_xmin.text), 0)ymin = max(float(obj_ymin.text), 0)xmax = max(float(obj_xmax.text), 0)ymax = max(float(obj_ymax.text), 0)obj_bnd.remove(obj_xmin) # 刪除節點obj_bnd.remove(obj_ymin)obj_bnd.remove(obj_xmax)obj_bnd.remove(obj_ymax)x0.text = str(xmin)y0.text = str(ymax)x1.text = str(xmax)y1.text = str(ymax)x2.text = str(xmax)y2.text = str(ymin)x3.text = str(xmin)y3.text = str(ymin)else:obj_bnd = obj.find('robndbox')obj_bnd.tag = 'bndbox' # 修改節點名obj_cx = obj_bnd.find('cx')obj_cy = obj_bnd.find('cy')obj_w = obj_bnd.find('w')obj_h = obj_bnd.find('h')obj_angle = obj_bnd.find('angle')cx = float(obj_cx.text)cy = float(obj_cy.text)w = float(obj_w.text)h = float(obj_h.text)angle = float(obj_angle.text)obj_bnd.remove(obj_cx) # 刪除節點obj_bnd.remove(obj_cy)obj_bnd.remove(obj_w)obj_bnd.remove(obj_h)obj_bnd.remove(obj_angle)x0.text, y0.text = rotatePoint(cx, cy, cx - w / 2, cy - h / 2, -angle)x1.text, y1.text = rotatePoint(cx, cy, cx + w / 2, cy - h / 2, -angle)x2.text, y2.text = rotatePoint(cx, cy, cx + w / 2, cy + h / 2, -angle)x3.text, y3.text = rotatePoint(cx, cy, cx - w / 2, cy + h / 2, -angle)# obj.remove(obj_type) # 刪除節點obj_bnd.append(x0) # 新增節點obj_bnd.append(y0)obj_bnd.append(x1)obj_bnd.append(y1)obj_bnd.append(x2)obj_bnd.append(y2)obj_bnd.append(x3)obj_bnd.append(y3)tree.write(dotaxml_file, method='xml', encoding='utf-8') # 更新xml文件# 轉換成四點坐標
def rotatePoint(xc, yc, xp, yp, theta):xoff = xp - xcyoff = yp - yccosTheta = math.cos(theta)sinTheta = math.sin(theta)pResx = cosTheta * xoff + sinTheta * yoffpResy = - sinTheta * xoff + cosTheta * yoffreturn str(int(xc + pResx)), str(int(yc + pResy))def totxt(xml_path, out_path):# 想要生成的txt文件保存的路徑,這里可以自己修改files = os.listdir(xml_path)i = 0for file in files:tree = ET.parse(xml_path + os.sep + file)root = tree.getroot()name = file.split('.')[0]output = out_path + '/' + name + '.txt'file = open(output, 'w')i = i + 1objs = tree.findall('object')for obj in objs:cls = obj.find('name').textbox = obj.find('bndbox')x0 = int(float(box.find('x0').text))y0 = int(float(box.find('y0').text))x1 = int(float(box.find('x1').text))y1 = int(float(box.find('y1').text))x2 = int(float(box.find('x2').text))y2 = int(float(box.find('y2').text))x3 = int(float(box.find('x3').text))y3 = int(float(box.find('y3').text))if x0 < 0:x0 = 0if x1 < 0:x1 = 0if x2 < 0:x2 = 0if x3 < 0:x3 = 0if y0 < 0:y0 = 0if y1 < 0:y1 = 0if y2 < 0:y2 = 0if y3 < 0:y3 = 0for cls_index, cls_name in enumerate(cls_list):if cls == cls_name:file.write("{} {} {} {} {} {} {} {} {} {}\n".format(x0, y0, x1, y1, x2, y2, x3, y3, cls, cls_index))file.close()# print(output)print(i)if __name__ == '__main__':# -----**** 第一步:把xml文件統一轉換成旋轉框的xml文件 ****-----roxml_path = '.../ultralytics-main/datasets/data_zsyobb/labels_all'dotaxml_path = '.../ultralytics-main/datasets/data_zsyobb/dotaxml'out_path = '.../ultralytics-main/datasets/data_zsyobb/dotatxt'filelist = os.listdir(roxml_path)for file in filelist:edit_xml(os.path.join(roxml_path, file), os.path.join(dotaxml_path, file))# -----**** 第二步:把旋轉框xml文件轉換成txt格式 ****-----totxt(dotaxml_path, out_path)1.2.4 劃分訓練集和測試集
這個代碼運行完,會在images和dotatxt文件夾下,按照比例7:3,劃分和拷貝
import os
import shutilfrom tqdm import tqdm
import randomDataset_folder = r'...\ultralytics-main\datasets\data_zsyobb'
# 把當前工作目錄改為指定路徑
os.chdir(os.path.join(Dataset_folder, 'images')) # images : 圖片文件夾的名稱
folder = '.' # 代表os.chdir(os.path.join(Dataset_folder, 'images'))這個路徑
imgs_list = os.listdir(folder)random.seed(123) # 固定隨機種子,防止運行時出現bug后再次運行導致imgs_list 里面的圖片名稱順序不一致random.shuffle(imgs_list) # 打亂val_scal = 0.3 # 驗證集比列
val_number = int(len(imgs_list) * val_scal)
val_files = imgs_list[:val_number]
train_files = imgs_list[val_number:]print('all_files:', len(imgs_list))
print('train_files:', len(train_files))
print('val_files:', len(val_files))os.mkdir('train')
for each in tqdm(train_files):shutil.move(each, 'train')os.mkdir('val')
for each in tqdm(val_files):shutil.move(each, 'val')os.chdir('../dotatxt')os.mkdir('train_original')
for each in tqdm(train_files):json_file = os.path.splitext(each)[0] + '.txt'shutil.move(json_file, 'train')os.mkdir('val_original')
for each in tqdm(val_files):json_file = os.path.splitext(each)[0] + '.txt'shutil.move(json_file, 'val')print('劃分完成')
1.2.5 最后一步了,堅持
等熟悉python后,要把這個寫到一個腳本里面,真是煩死了
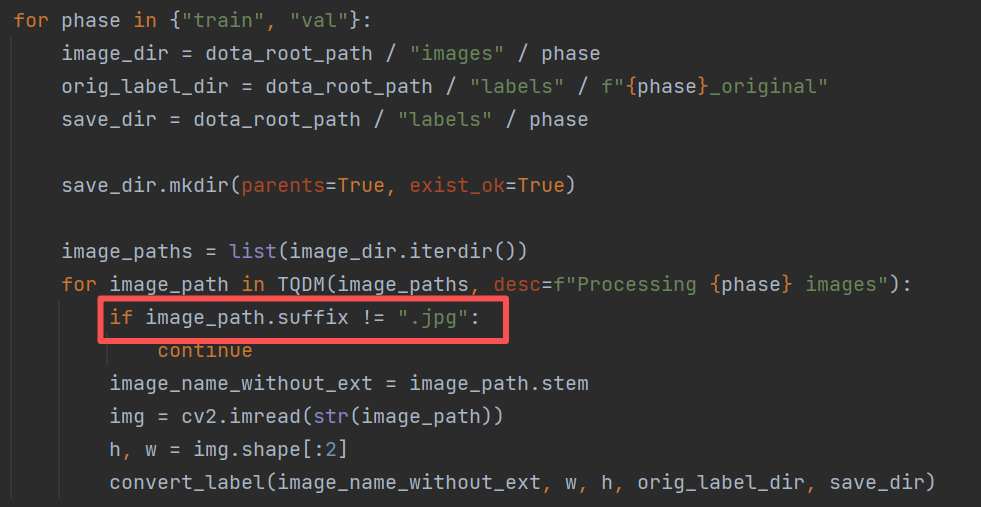
1.新建labels文件夾,將dotatxt文件夾中的兩個文件夾train_original val_original拷貝過去,或者直接改了dotatxt文件夾名稱也行
2.運行該代碼,直接用pytorch的數據轉換代碼
from ultralytics.data.converter import convert_dota_to_yolo_obb
convert_dota_to_yolo_obb("...\\ultralytics-main\\datasets\\data_zsyobb")
前提: 進去convert_dota_to_yolo_obb函數,把label替換為自己的
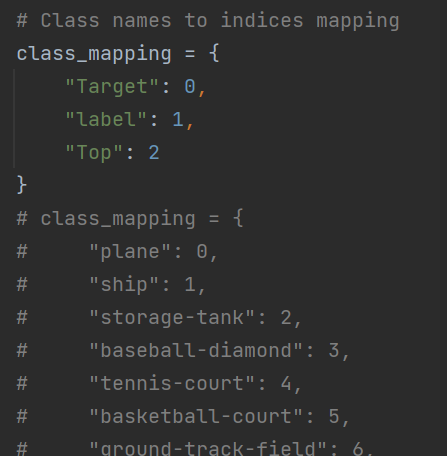
換成自己后綴的圖像
1.2.6 格式轉換結束,可以開始訓練了
2.訓練模型
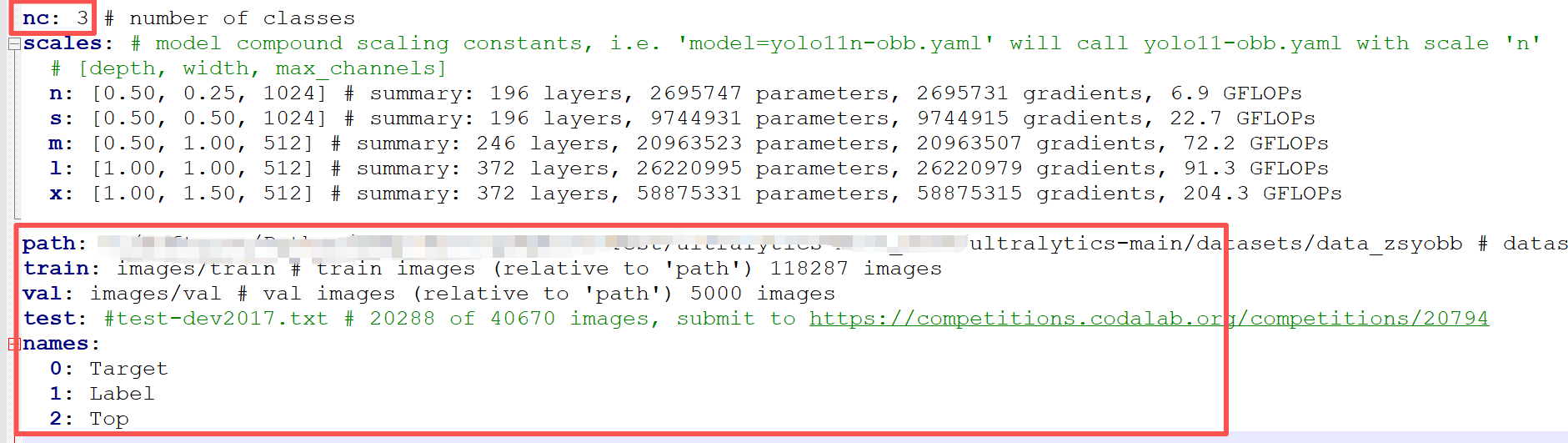
2.1 修改ymal文件,拷貝一個ultralytics-main\ultralytics\cfg\models\11\yolo11-obb.yaml
修改一下,加幾行就行
2.2 大功告成,直接粘貼訓練源碼即可
至于調參,后面再說,先把流程走通
import argparse
from ultralytics import YOLO
def parse_opt(known=False):parser = argparse.ArgumentParser()parser.add_argument('--model', type=str, default='yolov8n-obb.pt', help='initial weights path')parser.add_argument('--epochs', type=int, default=640, help='total training epochs')parser.add_argument('--imgsz', type=int, default=640, help='train, val image size (pixels)')parser.add_argument('--batch', type=str, default=2, help='total batch size for all GPUs, -1 for autobatch')parser.add_argument('--lr0', type=str, default=0.01, help=' (float) initial learning rate (i.e. SGD=1E-2, Adam=1E-3)')parser.add_argument('--cls', type=str, default=1.5, help=' (float) cls loss gain (scale with pixels)')parser.add_argument('--data', type=str, default='..../ultralytics-main/yolo11-zsyobb.yaml', help='dataset.yaml path')parser.add_argument('--workers', type=str, default=0)parser.add_argument('--device', type=str, default=0, help='cuda device, i.e. 0 or 0,1,2,3 or cpu')return parser.parse_known_args()[0] if known else parser.parse_args()def main(opt):model = YOLO(opt.model)model.train(data=opt.data, epochs=opt.epochs, imgsz=opt.imgsz, batch=opt.batch, device=opt.device, lr0=opt.lr0, cls=opt.cls)model.val(imgsz=opt.imgsz)if __name__ == '__main__':opt = parse_opt()main(opt)
2.3 預測一下
#-------------------------------預測--------------------------
from ultralytics import YOLO
import cv2
yolo = YOLO("best_sypobb.pt", task = "detect")
result = yolo(source="..../ultralytics-main/datasets/data_zsyobb/images_all",conf=0.6,vid_stride=1,iou=0.3,save = True)
print(result[0].obb)2.4 模型導出 torchscrip
#---------------------模型導出------------------------------
from ultralytics import YOLO
# Load a model
model = YOLO("best_sypobb.pt")
# Export the model
model.export(format="torchscript",imgsz = 640,device = 0,batch = 1)3.windos libtorch 部署
真是見鬼了,在網上搜了好久,都沒有個直接能粘貼的源碼,都是onnx部署的,我好不容易調通了libtorch的yolo11檢測,想換個obb就不知道咋弄了,我這個部署教程寫細一點,應該是CSDN獨一份能直接粘貼的OBB libtorch部署的C++源碼
3.1 首先是環境安裝,大家直接到我上一篇的地方去看吧,首行后鏈接
3.2 直接上源碼
#include <iostream>#include <opencv2/core.hpp>
#include <opencv2/imgproc.hpp>
#include <opencv2/imgcodecs.hpp>
#include <torch/torch.h>
#include <torch/script.h>using torch::indexing::Slice;
using torch::indexing::None;
struct ResizeParams
{//實際圖像的左上角點與原始圖像0 0 的偏移int top;int left;//去除灰邊的圖像寬高int imgw;int imgh;//ratio 縮放圖像和原始圖像的寬高比例float ratiow;float ratioh;
};
struct Object
{cv::RotatedRect rrect;int label;float prob;
};
float intersection_area(const Object& a, const Object& b)
{std::vector<cv::Point2f> intersection;cv::rotatedRectangleIntersection(a.rrect, b.rrect, intersection);if (intersection.empty())return 0.f;return cv::contourArea(intersection);
}
void nms_sorted_bboxes(const std::vector<Object>& objects, std::vector<int>& picked, float nms_threshold, bool agnostic = false)
{picked.clear();const int n = objects.size();std::vector<float> areas(n);for (int i = 0; i < n; i++){areas[i] = objects[i].rrect.size.area();}for (int i = 0; i < n; i++){const Object& a = objects[i];int keep = 1;for (int j = 0; j < (int)picked.size(); j++){const Object& b = objects[picked[j]];if (!agnostic && a.label != b.label)continue;// intersection over unionfloat inter_area = intersection_area(a, b);float union_area = areas[i] + areas[picked[j]] - inter_area;// float IoU = inter_area / union_area;if (inter_area / union_area > nms_threshold)keep = 0;}if (keep)picked.push_back(i);}
}
//flg true/false 分別為降序/升序
template<typename T>void vector_sort(std::vector<T>vector_input, std::vector<size_t>&idx,float flg){int num = vector_input.size();idx.resize(num);for (int i = 0; i < num; i++){idx[i] = i;}if(flg){std::sort(idx.begin(), idx.end(), [&vector_input](size_t i1, size_t i2){return vector_input[i1] > vector_input[i2]; });}else{std::sort(idx.begin(), idx.end(), [&vector_input](size_t i1, size_t i2){return vector_input[i1] < vector_input[i2]; });}
}
//開始非極大抑制前的數據準備
void PrepareData(torch::Tensor output, std::vector<Object>& objects,float conf) {objects.clear();auto output_data = output.squeeze();int num_params = output_data.size(0); // 8int num_boxes = output_data.size(1); // 8400int classnum = num_params - 5;std::vector<Object>Tobjvec;std::vector<float>confvec;for (int i = 0; i < num_boxes; i++) {float x_center = output_data[0][i].item<float>(); // 中心 x 坐標float y_center = output_data[1][i].item<float>(); // 中心 y 坐標float width = output_data[2][i].item<float>(); // 寬度float height = output_data[3][i].item<float>(); // 高度float angle = output_data[num_params-1][i].item<float>(); // 高度int label = 0;float maxconf = 0;for (int j = 4; j < num_params-1; j++) {float conf_ = output_data[j][i].item<float>();if (conf_ > maxconf) {maxconf = conf_;label = j - 4;}}//如果最大的置信度小于給定的閾值,跳過if (maxconf < conf) {continue;}//開始把結果賦值給結構體Object obj1;obj1.label = label;obj1.prob = maxconf;obj1.rrect = cv::RotatedRect(cv::Point2f{ x_center,y_center }, cv::Size(width, height), angle*180.0 / M_PI);Tobjvec.push_back(obj1);confvec.push_back(maxconf);}//按照概率大小進行排序,降序std::vector<size_t>sortid;vector_sort(confvec, sortid, true);for (int i = 0; i < sortid.size(); i++) {objects.push_back(Tobjvec[sortid[i]]);}
}
float generate_scale(cv::Mat& image, const std::vector<int>& target_size) {int origin_w = image.cols;int origin_h = image.rows;int target_h = target_size[0];int target_w = target_size[1];float ratio_h = static_cast<float>(target_h) / static_cast<float>(origin_h);float ratio_w = static_cast<float>(target_w) / static_cast<float>(origin_w);float resize_scale = std::min(ratio_h, ratio_w);return resize_scale;
}float letterbox(cv::Mat &input_image, cv::Mat &output_image, const std::vector<int> &target_size, ResizeParams ¶ms) {if (input_image.cols == target_size[1] && input_image.rows == target_size[0]) {if (input_image.data == output_image.data) {return 1.;}else {output_image = input_image.clone();return 1.;}}float resize_scale = generate_scale(input_image, target_size);int new_shape_w = std::round(input_image.cols * resize_scale);int new_shape_h = std::round(input_image.rows * resize_scale);float padw = (target_size[1] - new_shape_w) / 2.;float padh = (target_size[0] - new_shape_h) / 2.;int top = std::round(padh - 0.1);int bottom = std::round(padh + 0.1);int left = std::round(padw - 0.1);int right = std::round(padw + 0.1);params.top = top;params.left = left;params.imgw = new_shape_w;params.imgh = new_shape_h;params.ratiow = resize_scale;params.ratioh = resize_scale;cv::resize(input_image, output_image,cv::Size(new_shape_w, new_shape_h),0, 0, cv::INTER_AREA);cv::copyMakeBorder(output_image, output_image, top, bottom, left, right,cv::BORDER_CONSTANT, cv::Scalar(114., 114., 114));return resize_scale;
}
void drawImage(cv::Mat &image, Object obj1, ResizeParams params)
{std::vector<cv::Scalar>colorlabel;colorlabel.push_back(cv::Scalar(255, 0, 0));colorlabel.push_back(cv::Scalar(0, 255, 0));colorlabel.push_back(cv::Scalar(0, 0, 255));cv::Point2f corners[4];obj1.rrect.points(corners);cv::Point2f ori_corners[4];for (size_t i = 0; i < 4; i++) {ori_corners[i].x = (corners[i].x - params.left) / params.ratiow;ori_corners[i].y = (corners[i].y - params.top) / params.ratioh;}for (int i = 0; i < 4; i++) {cv::line(image, ori_corners[i], ori_corners[(i + 1) % 4], colorlabel[obj1.label], 1);}
}
std::vector<float>RotatedRectToXY4(Object obj1, ResizeParams params) {cv::Point2f corners[4];obj1.rrect.points(corners);cv::Point2f ori_corners[4];for (size_t i = 0; i < 4; i++) {ori_corners[i].x = (corners[i].x - params.left) / params.ratiow;ori_corners[i].y = (corners[i].y - params.top) / params.ratioh;}std::vector<float>corner;for (size_t i = 0; i < 4; i++) {corner.push_back(ori_corners[i].x);corner.push_back(ori_corners[i].y);}corner.push_back(obj1.label);corner.push_back(obj1.prob);return corner;
}
#include<windows.h>
int main() {printf("torch::cuda::is_available:%d\n", torch::cuda::is_available());// Device//torch::Device device(torch::cuda::is_available() ? torch::kCUDA : torch::kCPU);torch::Device device(torch::kCUDA);std::vector<std::string> classes{ "pepper" };try {std::string model_path = ".../ultralytics-main/best_sypobb.torchscript";torch::jit::script::Module yolo_model;LoadLibraryA("ATen_cuda.dll");LoadLibraryA("c10_cuda.dll");LoadLibraryA("torch_cuda.dll");LoadLibraryA("torchvision.dll");yolo_model = torch::jit::load(model_path, device);yolo_model.eval();yolo_model.to(device, torch::kFloat32);ResizeParams params;// Load image and preprocesscv::Mat image = cv::imread(".../ultralytics-main/20250829-102331640.jpg");cv::Mat input_image;letterbox(image, input_image, { 640, 640 }, params);cv::cvtColor(input_image, input_image, cv::COLOR_BGR2RGB);torch::Tensor image_tensor = torch::from_blob(input_image.data, { input_image.rows, input_image.cols, 3 }, torch::kByte).to(device);image_tensor = image_tensor.toType(torch::kFloat32).div(255);image_tensor = image_tensor.permute({ 2, 0, 1 });image_tensor = image_tensor.unsqueeze(0);std::vector<torch::jit::IValue> inputs{ image_tensor };auto start = std::chrono::high_resolution_clock::now();// Inferencetorch::Tensor output = yolo_model.forward(inputs).toTensor().cpu();std::vector<Object> objects;PrepareData(output, objects, 0.6);for (int i = 0; i < objects.size(); i++) {printf("%d %d %.3f\n",i, objects[i].label, objects[i].prob);}//開始非極大抑制std::vector<int> picked;nms_sorted_bboxes(objects, picked, 0.3);for (int i = 0; i < picked.size(); i++) {printf("%d %d %d %.3f\n", i, picked[i], objects[picked[i]].label, objects[picked[i]].prob);}for (int i = 0; i < picked.size(); i++) {int id = picked[i];//繪制框drawImage(image, objects[id], params);//打印四角點std::vector<float>corner = RotatedRectToXY4(objects[id], params);for (int j = 0; j < corner.size(); j++) {printf("%.3f ", corner[j]);}printf("\n");}cv::imwrite("..../20250829-102331640_out.jpg", image);}catch (const c10::Error& e) {std::cout << e.msg() << std::endl;}return 0;
}3.3 簡單說一下
3.3.1 就是模型加載,前向,最后得到的是1 * 8 * 8400的輸出數據
1 表示一張影像
8 表示一個框的所有參數 分別表示 cenx ceny w h conf1 conf2 conf3 angle
8400 表示有8400個框的數據
注意:如果類別更多,那就是1*(x,y,w,h,nc1,nc2,…,ncn,angle)*8400了,對應修改代碼吧
3.3.2 下來就是非極大抑制
1.首先 需要把每個框的lable確認一下,即 conf1 conf2 conf3 哪個最大就是哪一類
2.將符合置信度閾值的先拿出來
3.然后按照概率大小降序排列,非極大抑制要從最大置信度開始判斷
4.非極大抑制,主要是看IOU,這里的IOU直接利用opencv自帶的函數確定,交并比,小于nms閾值的保留下來,就是最終的預測結果
3.3.3 得到預測框后,需要把四角點坐標取出來,然后反算回原始圖像位置
1.獲取四角點位置,直接用opencv帶的函數,省去自己寫了
2.換算回去,不能直接根據寬高比反算,因為最開始縮放圖像是添加了灰條,所有要看灰條的頂和左起始像素位置和寬高比反算
3.這些代碼去上面里面扒吧
非極大抑制前,符合conf閾值的效果類似這樣
有灰條 + 一堆框框

非極大抑制后,換算回原始圖像預測的效果類似這樣
代碼輸出:四角點坐標+三類(0,1,2)+置信度(0.961,0.914,0.892)

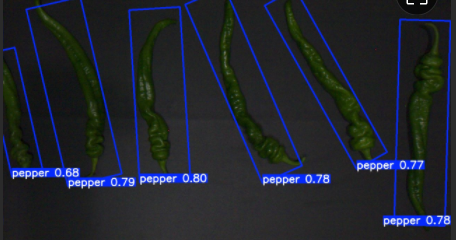
換算回去的圖就不貼了,涉及項目,自己按照坐標繪制就行
貼一個其他項目應用的截圖吧,代替一下
4.windos libtorch 動態庫封裝 + QT mingw調用
看上一章內容吧,一模一樣,把代碼重新組織一下就行了

)






市場分析:領先企業格局與未來趨勢分析)







)
中,使用 ECharts 圖表(豆包版))

工具實測:批量轉存 + 自動換號 + 資源監控 賬號添加失敗 / 轉存中斷?這樣解決(含功能詳解))