語言模型,是NLP方向一直主力研究的,通過訓練機器,來讓機器學習人類語言的內在規律,理解自然語言,并將其轉換為計算機語言。
目前的主流語言模型,如GPT、Deepseek等,并不是簡單的搜索背誦。他們的機制更類似于一種猜詞游戲,即通過當前的信息,推測下一個相關的信息是什么,通過這種方式進行資源整合。
NLP語言模型具體涉及解決的問題有:搜索、分類、聚類、總結、生成、重寫、抽象
NLP模型效果依賴兩個方面:一是模型結構,二是語料庫的豐富程度。
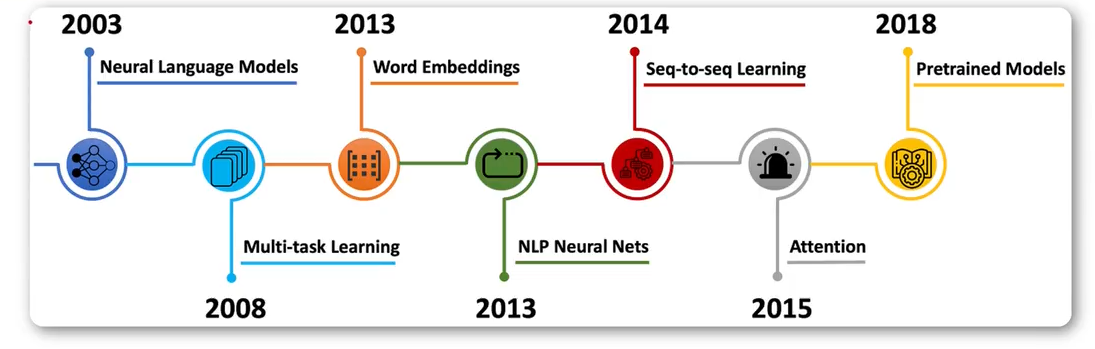
發展階段
-
統計語言模型
是一種基于概率統計的語言模型,旨在預測下一個單詞或句子出現的概率。
將NLP任務視為一個統計問題,使用機器學習算法從大規模語料庫中學習語言的統計規律。
嚴重依賴特征工程。模型的效果很大程度上取決于從業者如何設計和提取特征(如詞形、詞性、詞干、上下文窗口等)。 -
神經網絡語言模型:
基于神經網絡學習特征,比傳統模型效果更好。
使用深度學習模型(尤其是循環神經網絡RNN、長短期記憶網絡LSTM和卷積神經網絡CNN)自動學習語言的底層特征表示,取代手工特征工程。 -
預訓練語言模型
先在超大規模無標注文本數據上訓練一個通用的基礎模型(學習語言本身的語法、語義、知識等),再針對具體下游任務用少量標注數據進行微調。
Transformer架構推出后,并行計算能力強,極大地提升了訓練效率和長程依賴建模能力。改變了語言模型的結構。
統計語言模型
統計語言模型是描述單詞、句子或文檔的概率分布的模型。主要有以下幾種:
- n-gram模型
n-gram模型是將一段文本切分成n個連續的詞組,然后根據前n-1個詞組來預測第n個詞組,從而達到預測的目的(3-gram通過前2個詞,預測第3個詞)。

-
平滑方法
n-gram需要對所有上文進行枚舉的操作,加上要處理出現次數為0的問題,所以可能存在過擬合和數據稀疏的問題。因此,需要引入平滑方法:Laplace平滑、Good-Turing平滑、Katz平滑等。 -
隱馬爾科夫模型(HMM)
HMM是一種將語言轉化為概率狀態序列的模型,可以學習文本中的隱含結構。一般用于識別詞性、命名實體識別等任務。
命名實體識別:是從非結構化的文本中自動識別出專有名詞或特定意義的實體,并將其分類到預定義的類別中。
可以把它理解為一種“信息高亮”,它能在密密麻麻的文字中,快速地把人名、地名、組織機構名等重要信息標記出來。 -
最大熵模型
最大熵模型是一種分類器,用來預測下一個詞或字符的條件概率。以最大化信息熵為目標函數,通過最大熵原理確定模型參數。
神經網絡語言模型
神經網絡語言模型(NNLM),是基于神經網絡實現的模型,相比于傳統模型有更好的性能。
-
基于前饋神經網絡的NNLM
2003年提出,通過前饋神經網絡訓練,用softmax分類。 -
循環神經網絡模型(RNNLM)
是一種基于循環神經網絡的語言模型,優點是對動態的序列進行建模,通過引入長短時記憶單元(LSTM),解決了神經網絡在處理長序列的梯度消失問題,提升了性能。
如果序列過長,隨著訓練,前面的知識可能被遺忘。 -
TransformerLM
基于Transformer的語言模型,通過自注意力機制計算不同單詞間的關系。
相比于RNNLM,Transformer具有更強的并行性,計算效率上有更大優勢。
預訓練模型
基于TransformerLM,后續發展了一批以此為基礎的變體,目前各大廠商也都在進行模型的設計訓練,推出了一系列預訓練語言模型。
- Word2vec
是一種基于神經網絡的詞向量表示方法,于2013年提出,通過將單詞轉化為一個向量,從計算單詞間的相似性,具體講是通過計算向量間的余弦相似度。 - ELMo
是一種基于上下文的動態詞向量,于2018年提出,它是通過雙向LSTM模型來學習模型,從而獲得上下文相關的單詞嵌入。 - Transformer
是一種使用自注意力機制進行特征提取的預訓練語言模型,于2017年提出,被廣泛應用,如:機器翻譯、文本摘要、問答系統等。 - BERT
由Google在2018年發布的一種預訓練語言模型,在NLP領域取得了巨大成功。BERT使用雙向Transformer編碼器來訓練上下文相關的單詞嵌入。和其他的預訓練模型相比,BERT最大的特點是可以同時捕獲上下文中的前后文信息。這使得BERT成為當前效果最好的預訓練語言模型之一,廣泛應用于自然語言處理和文本挖掘任務中。 - GPT
是一系列基于Transformer架構的預訓練語言模型,由OpenAI開發,是目前效果最好的模型之一。






![[docker/大數據]Spark快速入門](http://pic.xiahunao.cn/[docker/大數據]Spark快速入門)





)

)




:mybaits if標簽test條件判斷等號=解析異常解決方案)