vue+flask農產品推薦與價格預測系統、雙推薦+機器學習價格預測+知識圖譜
文章結尾部分有CSDN官方提供的學長 聯系方式名片
文章結尾部分有CSDN官方提供的學長 聯系方式名片
關注B站,有好處!
編號: D010
技術架構: vue+flask+mysql+neo4j
核心技術:
- 基于用戶和基于物品雙推薦算法
- 回歸價格預測算法
- echarts 可視化
- 知識圖譜
- 爬蟲更新數據
背景
隨著數據科學技術的發展和農業信息化的深入推進,農產品價格預測系統成為了農業生產和經營管理中的重要工具。本系統基于Vue + Django的前后端分離架構,結合MySQL和Neo4j數據庫,采用scikit-learn多項式回歸算法進行價格預測,并利用協同過濾算法推薦農產品,旨在為用戶提供準確的農產品價格預測和信息服務。系統不僅包括用戶和管理員的常規管理功能,還引入了知識圖譜和數據可視化技術,以增強系統的信息處理能力和用戶體驗。
1 系統介紹
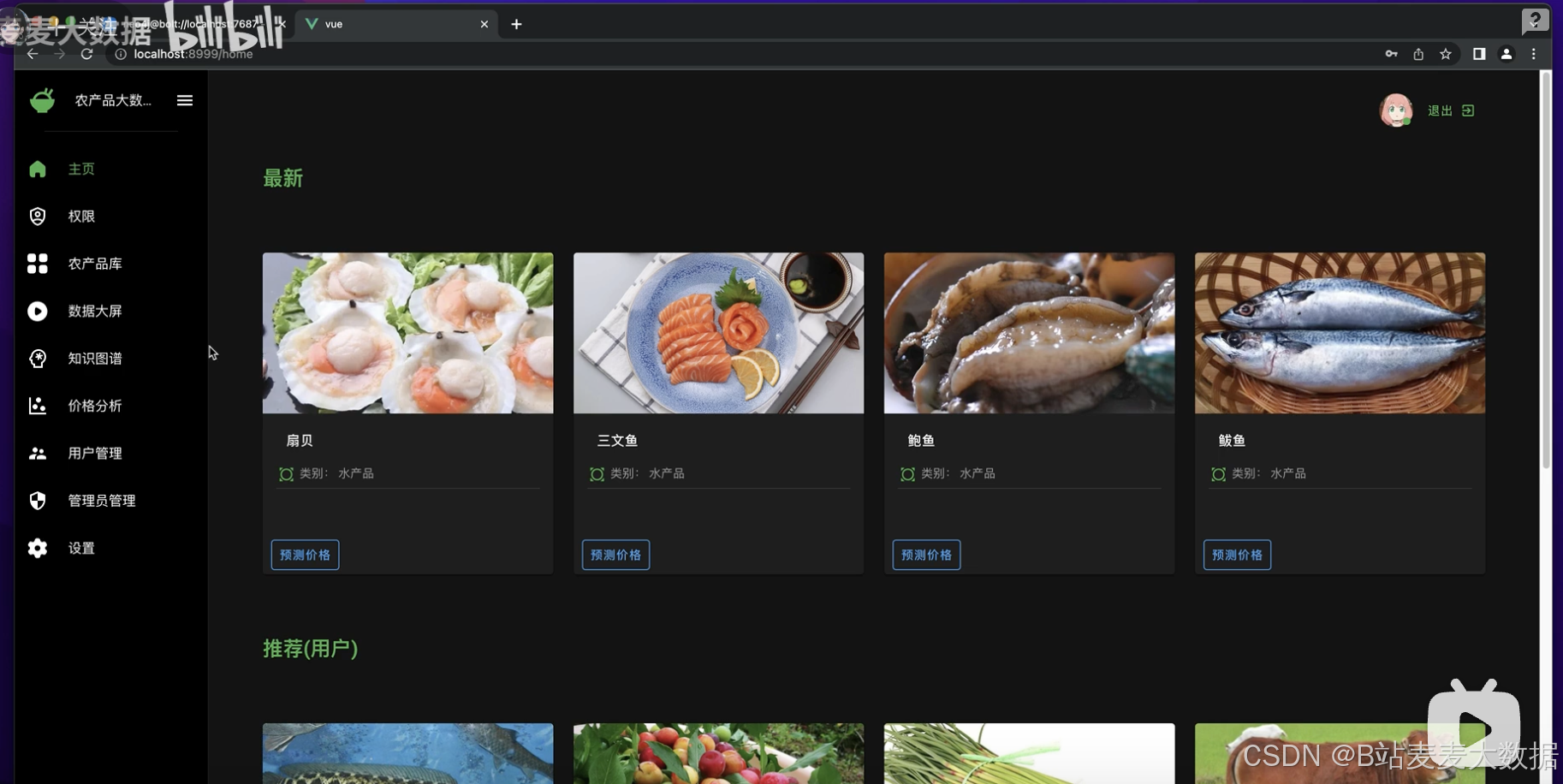
農產品價格預測系統是一個集數據采集、處理、分析、預測于一體的綜合信息服務平臺。系統主要針對農業領域的企業和個人,提供60多種蔬菜、水果、水產和糧食等農產品的當前最新價格和歷史價格數據,以及基于歷史數據的價格預測服務。系統采用Vue + Django構建前后端分離架構,前端使用Vuetify框架提高開發效率和用戶交互質量,后端以Django框架處理業務邏輯,數據存儲則選用MySQL和Neo4j數據庫,以適應不同的數據存儲需求。
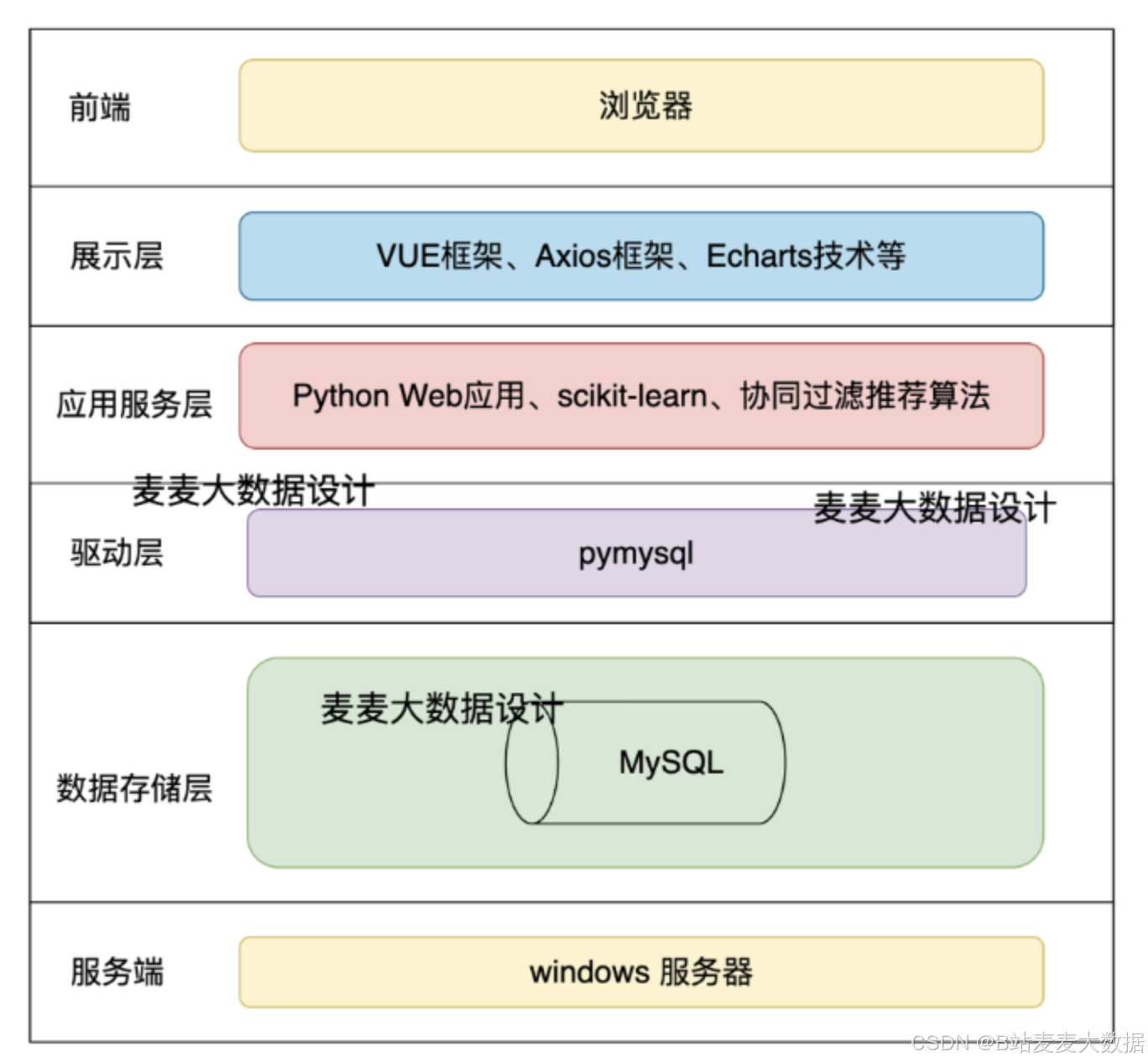
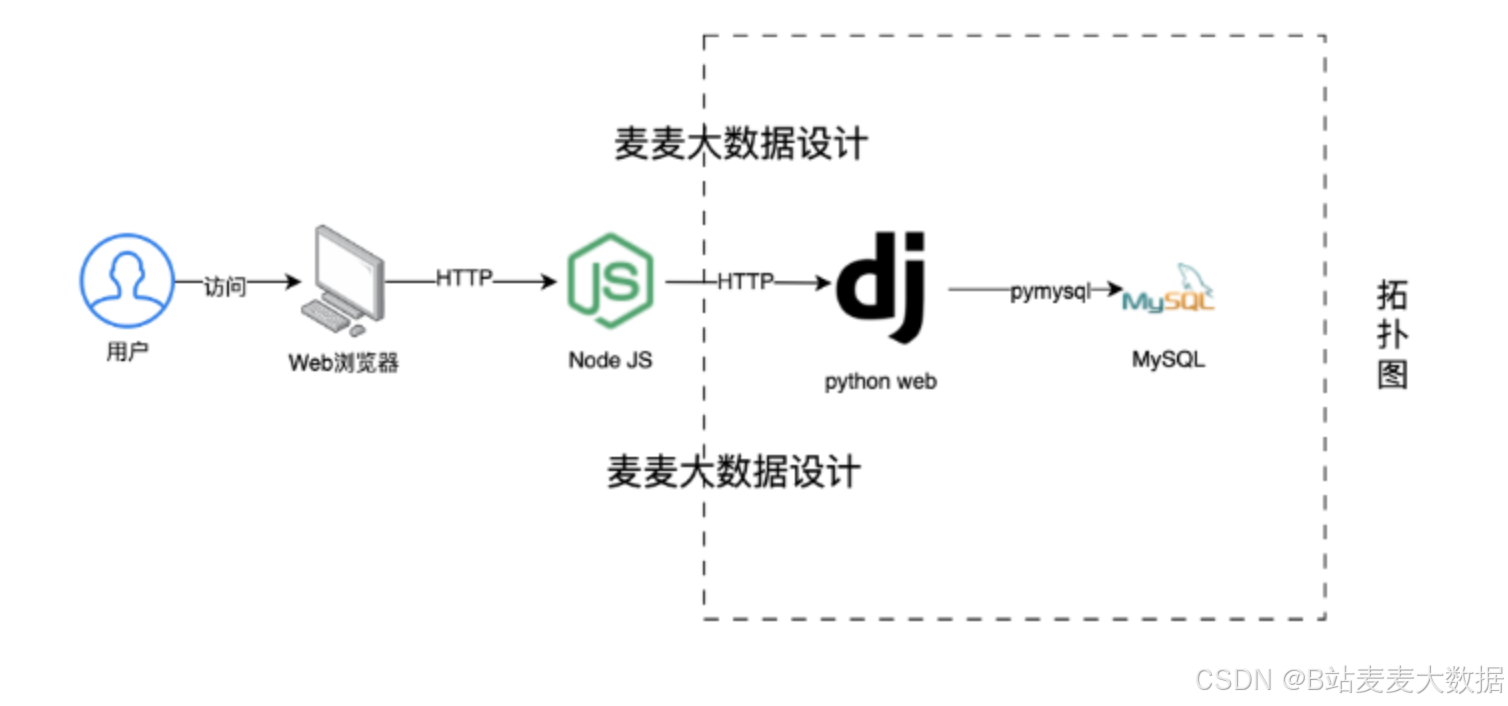
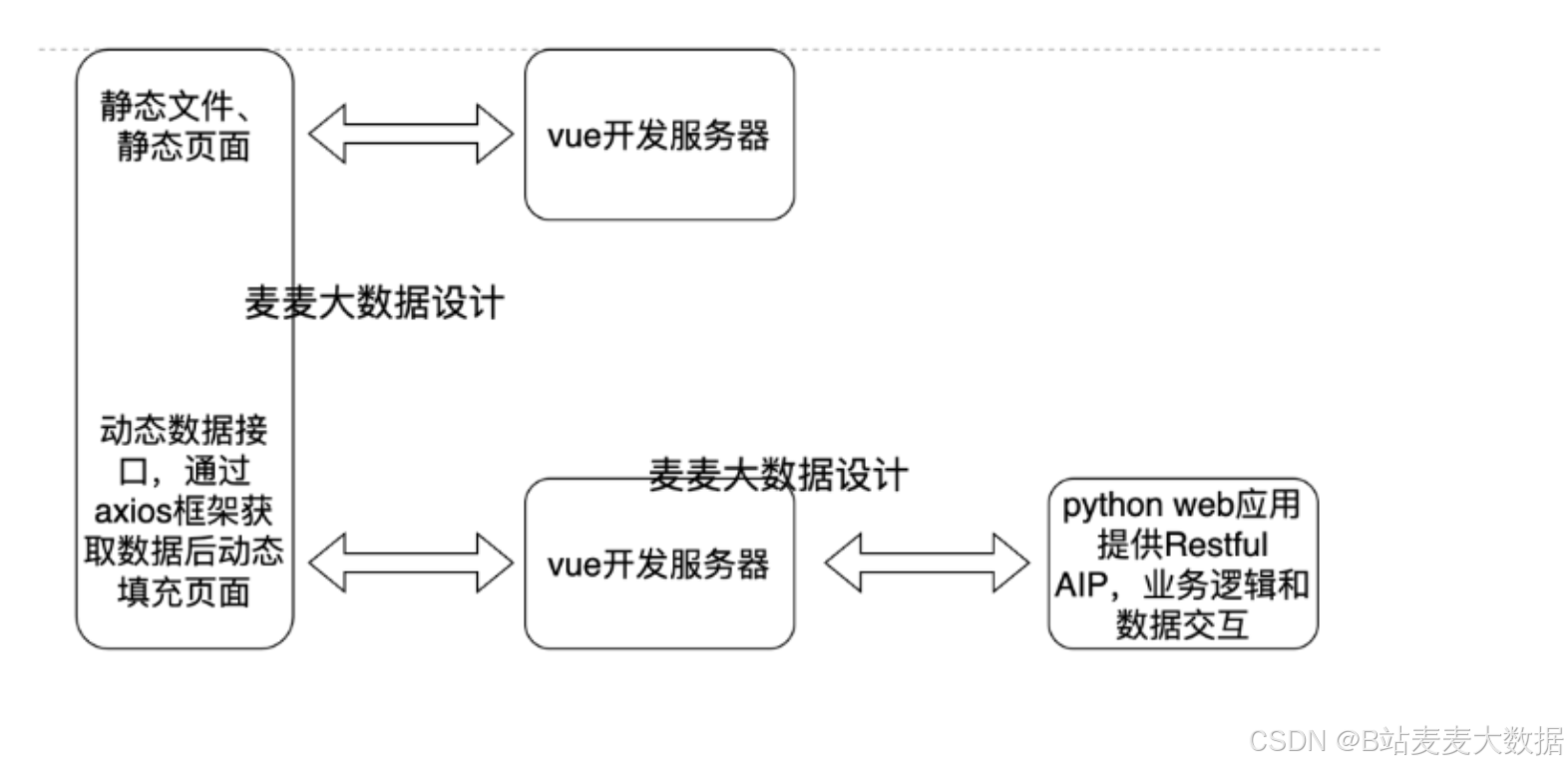
2 系統架構
前端技術:系統前端采用Vue.js框架和Vuetify組件庫,構建了一個響應式、用戶友好的界面。利用Vue的高效數據綁定和組件系統,配合Vuetify提供的豐富UI組件,為用戶提供了流暢的操作體驗。
后端技術:Django作為后端框架,不僅提供了強大的模型系統和自動的管理工具,還通過Django REST framework支持構建RESTful API,實現與前端的高效數據交互。
數據存儲:系統采用MySQL和Neo4j雙數據庫設計。MySQL負責存儲用戶數據、農產品價格數據等結構化信息,而Neo4j用于構建農業領域的知識圖譜,支持復雜的關系數據查詢。
架構
技術報告

運行說明

3 核心功能
數據采集與處理:系統能夠自動采集60多種農產品的最新和歷史價格信息,通過數據清洗和處理,保證數據質量和時效性。
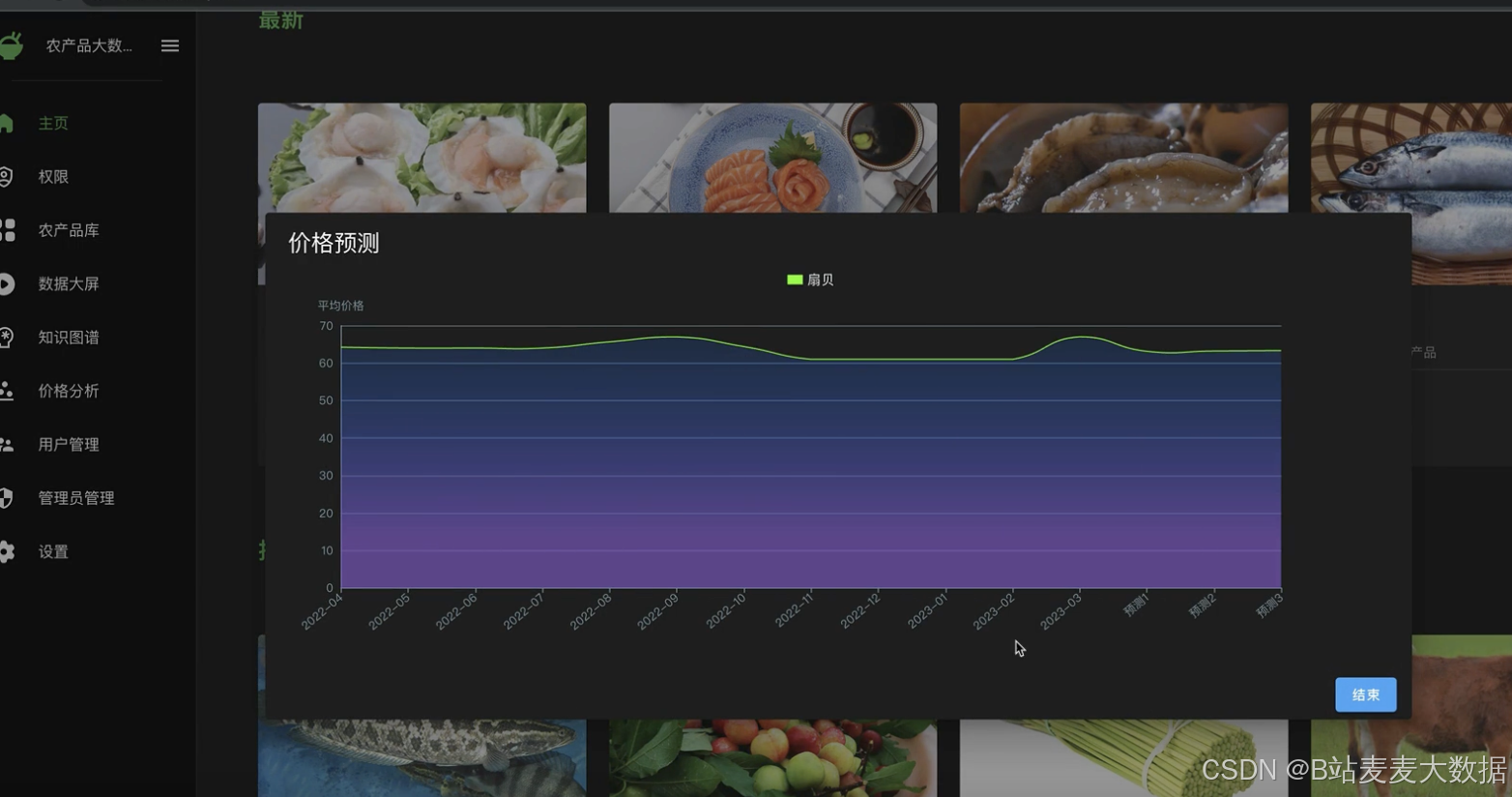
價格預測:采用scikit-learn的多項式回歸算法,根據農產品的歷史價格數據進行價格預測,幫助用戶預測未來價格變動趨勢。
import numpy as np
import matplotlib.pyplot as plt
import pymysqlcnn = pymysql.connect(host=host, user=user, password=password, port=port, database=database,charset='utf8')###########1.數據生成部分##########
def f(x1, x2):y = 0.5 * np.sin(x1) + 0.5 * np.cos(x2) + 3 + 0.1 * x1return ydef load_data():x1_train = np.linspace(0, 50, 500)x2_train = np.linspace(-10, 10, 500)data_train = np.array([[x1, x2, f(x1, x2) + (np.random.random(1) - 0.5)] for x1, x2 in zip(x1_train, x2_train)],dtype=object)x1_test = np.linspace(0, 50, 100) + 0.5 * np.random.random(100)x2_test = np.linspace(-10, 10, 100) + 0.02 * np.random.random(100)data_test = np.array([[x1, x2, f(x1, x2)] for x1, x2 in zip(x1_test, x2_test)])return data_train, data_testdef load_data_my():name = '肉蟹'sql = "select time1, avg(price) from tb_crop_price" \" where name='%s' group by time1 limit 12" % (name)with cnn.cursor() as cursor:cursor.execute(sql)print(sql)names = []y = []for line in cursor.fetchall():# print(line)y.append(line[1])names.append(line[0])y = np.array(y)x1_train = np.linspace(1, 12, 12)data_train = np.array([[x1, y] for x1, in zip(x1_train)], dtype=object)x1_test = np.linspace(1, 12, 12)data_test = np.array([[x1, y] for x1, in zip(x1_test)], dtype=object)return data_train, data_testtrain, test = load_data_my()# x_train, y_train = train[:, :2], train[:, 2] # 數據前兩列是x1,x2 第三列是y,這里的y有隨機噪聲
# x_test, y_test = test[:, :2], test[:, 2] # 同上,不過這里的y沒有噪聲
x_train, y_train = train[:, :1], train[:, 1] # 數據前兩列是x1,x2 第三列是y,這里的y有隨機噪聲
x_test, y_test = test[:, :1], test[:, 1] # 同上,不過這里的y沒有噪聲###########2.回歸部分##########
def try_different_method(model):model.fit(x_train, y_train)score = model.score(x_test, y_test)result = model.predict(x_test)plt.figure()plt.plot(np.arange(len(result)), y_test, 'go-', label='true value')plt.plot(np.arange(len(result)), result, 'ro-', label='predict value')plt.title('score: %f' % score)plt.legend()plt.show()###########3.具體方法選擇##########
####3.1決策樹回歸####
from sklearn import treemodel_DecisionTreeRegressor = tree.DecisionTreeRegressor()
####3.2線性回歸####
from sklearn import linear_modelmodel_LinearRegression = linear_model.LinearRegression()
####3.3SVM回歸####
from sklearn import svmmodel_SVR = svm.SVR()
####3.4KNN回歸####
from sklearn import neighborsmodel_KNeighborsRegressor = neighbors.KNeighborsRegressor()
####3.5隨機森林回歸####
from sklearn import ensemblemodel_RandomForestRegressor = ensemble.RandomForestRegressor(n_estimators=20) # 這里使用20個決策樹
####3.6Adaboost回歸####
from sklearn import ensemblemodel_AdaBoostRegressor = ensemble.AdaBoostRegressor(n_estimators=50) # 這里使用50個決策樹
####3.7GBRT回歸####
from sklearn import ensemblemodel_GradientBoostingRegressor = ensemble.GradientBoostingRegressor(n_estimators=100) # 這里使用100個決策樹
####3.8Bagging回歸####
from sklearn.ensemble import BaggingRegressormodel_BaggingRegressor = BaggingRegressor()
####3.9ExtraTree極端隨機樹回歸####
from sklearn.tree import ExtraTreeRegressormodel_ExtraTreeRegressor = ExtraTreeRegressor()
###########4.具體方法調用部分##########
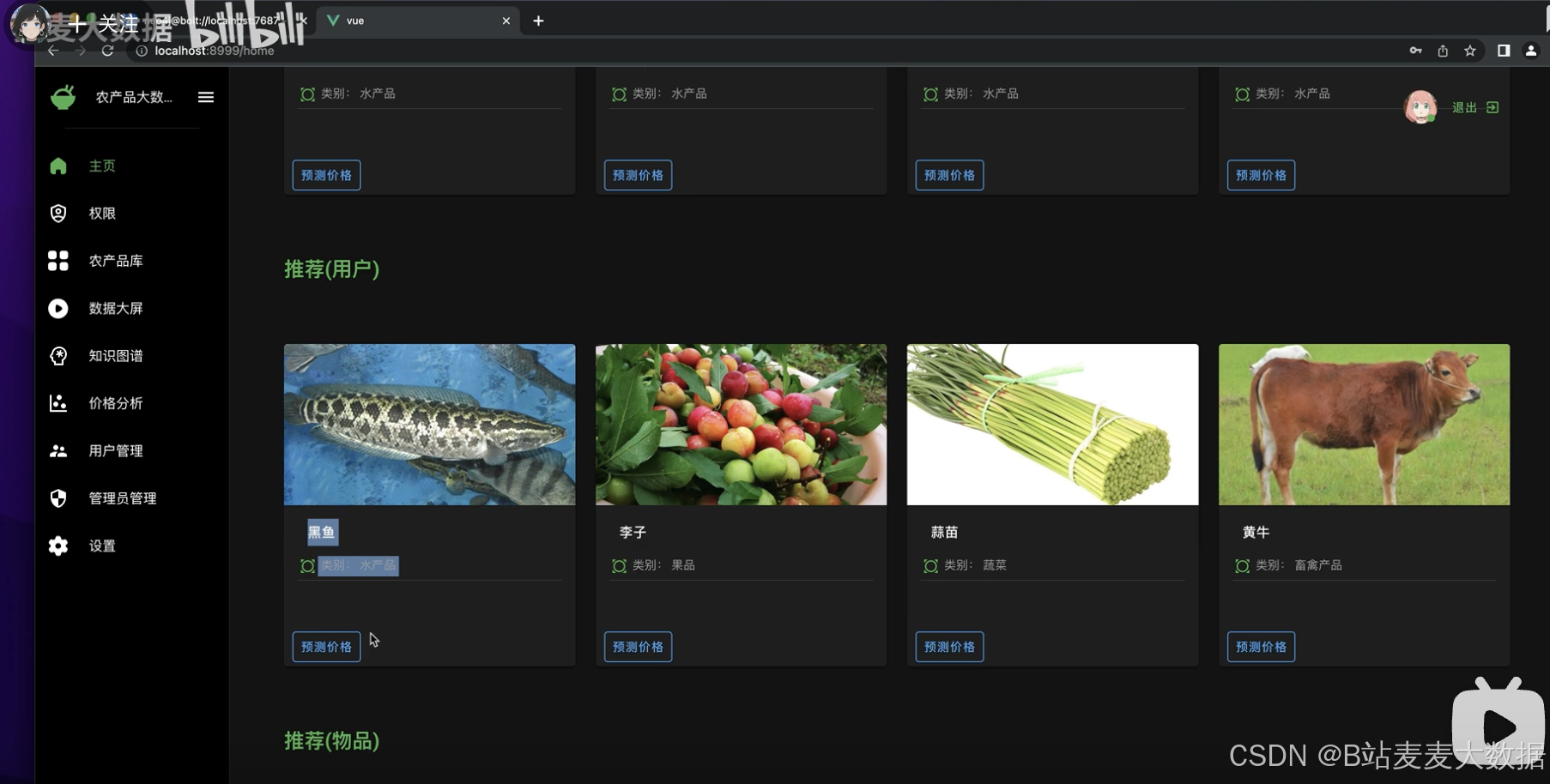
try_different_method(model_ExtraTreeRegressor)推薦算法:系統集成了兩種協同過濾推薦算法,根據用戶的瀏覽和購買行為,推薦潛在感興趣的農產品。
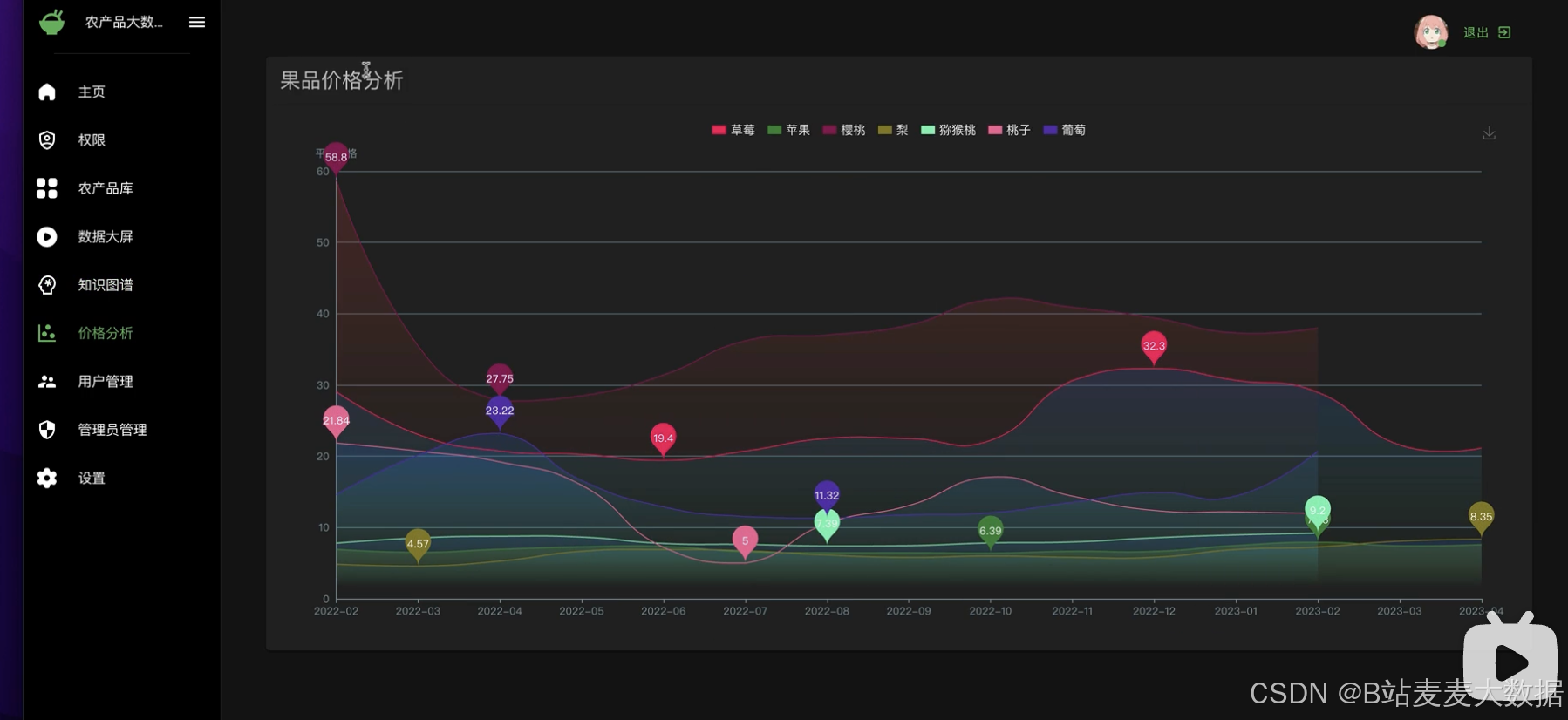
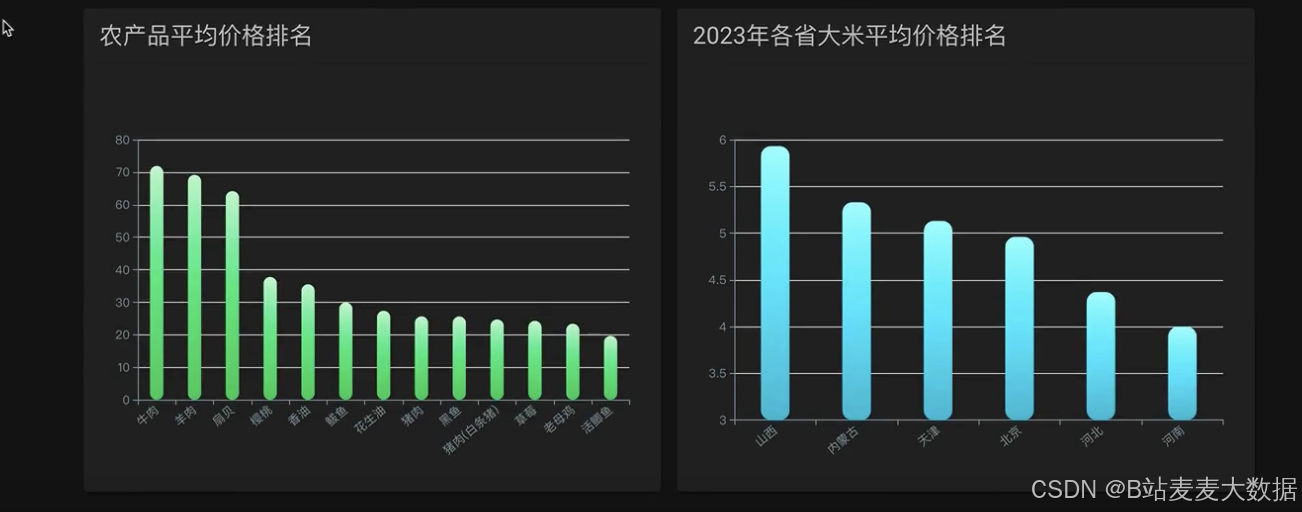
數據可視化:使用ECharts進行數據可視化,包括大屏展示、果品價格分析等功能,直觀展現農產品價格趨勢和分析結果。
可視化大屏:針對果品價格分析和其他農產品的數據可視化需求,系統設計了可視化大屏功能,通過圖表和圖形直觀展示數據分析結果,增強用戶體驗。
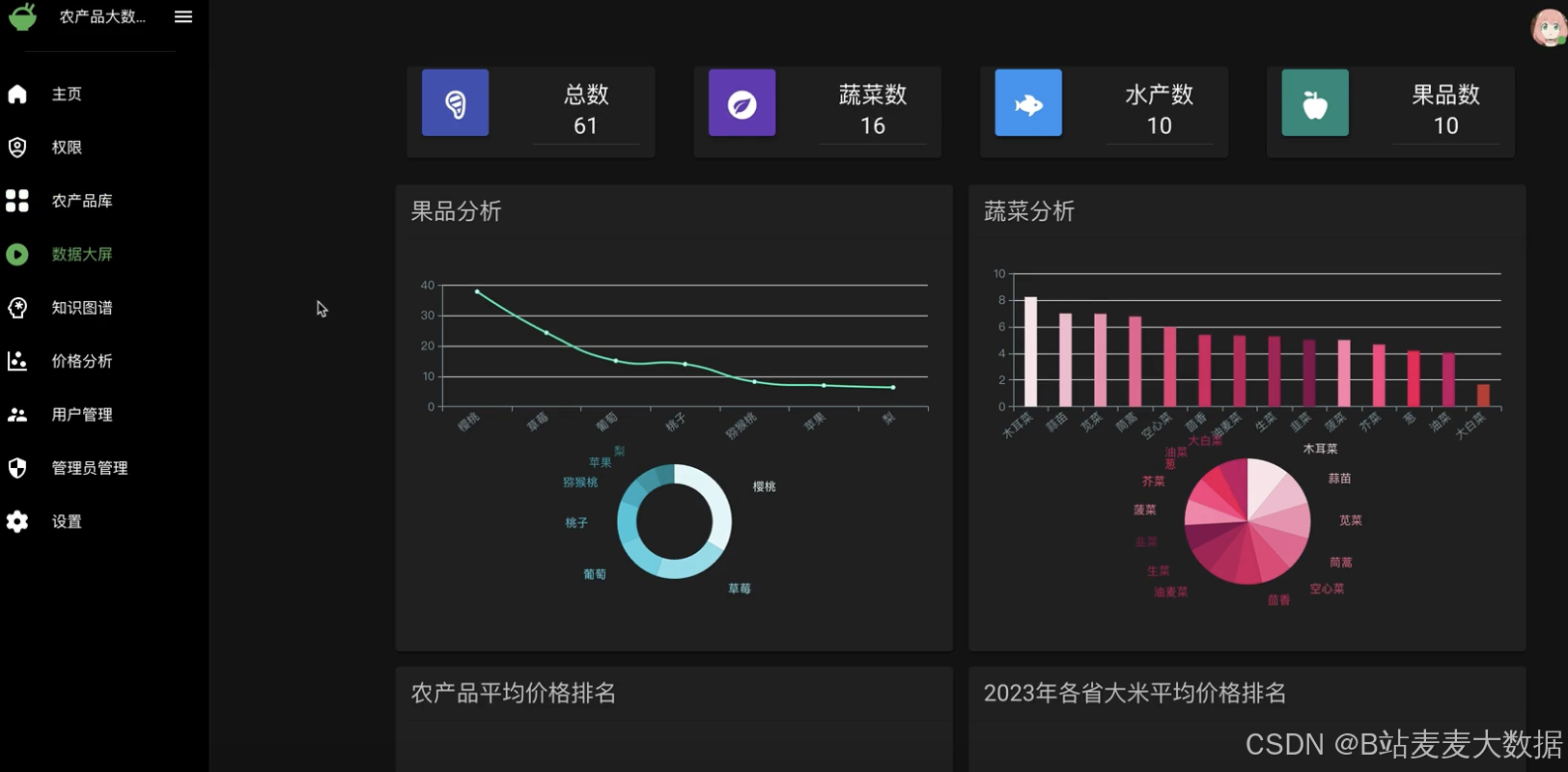
用戶和管理員管理:完整的用戶管理功能,包括注冊、登錄、信息修改、短信驗證碼修改密碼等,管理員則具有權限管理功能。

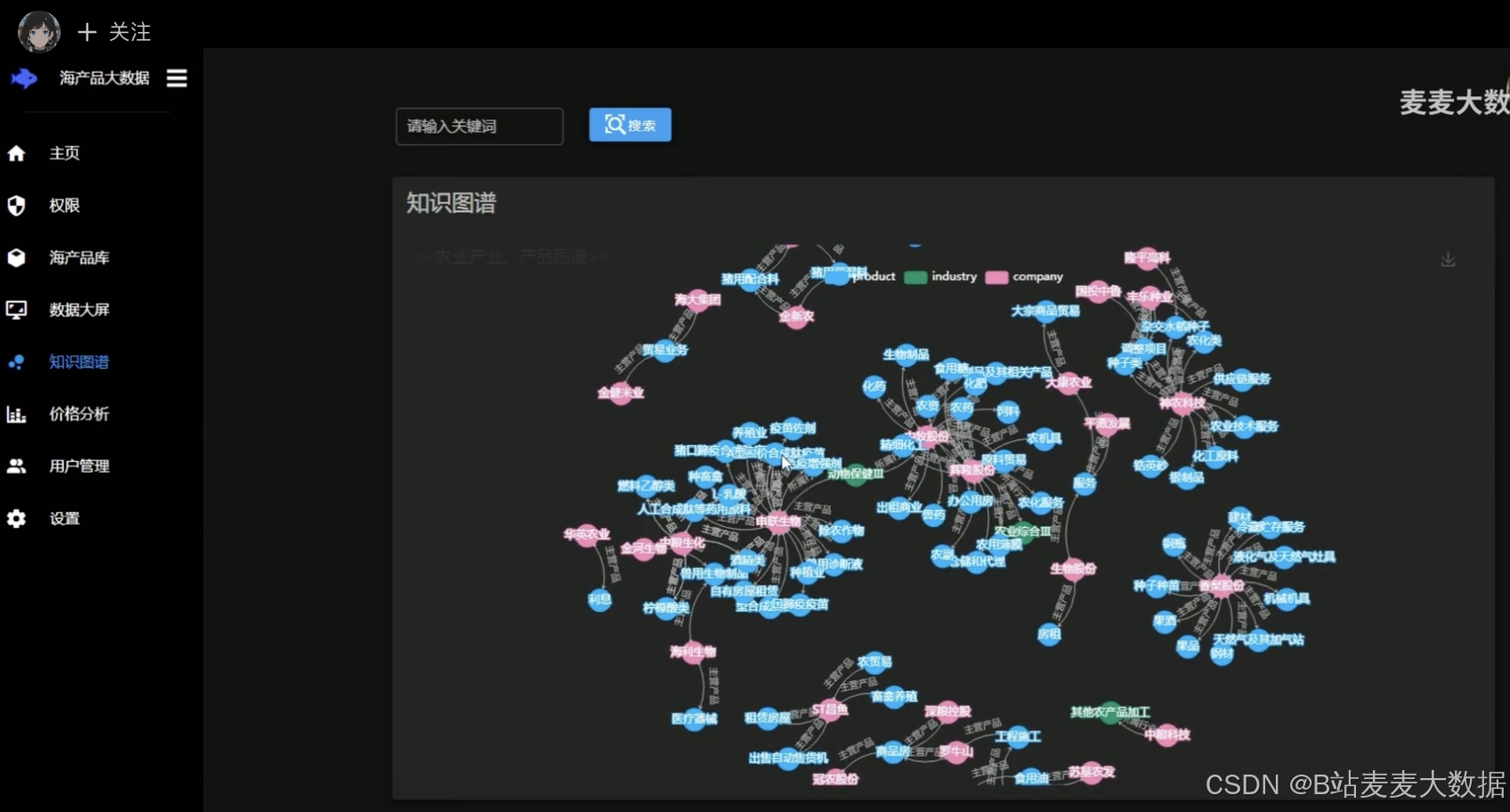
知識圖譜:創建農業領域的知識圖譜,為用戶提供豐富的農業知識和信息。知識圖譜的引入,不僅豐富了系統的數據維度,還提高了數據分析和推薦的準確性。
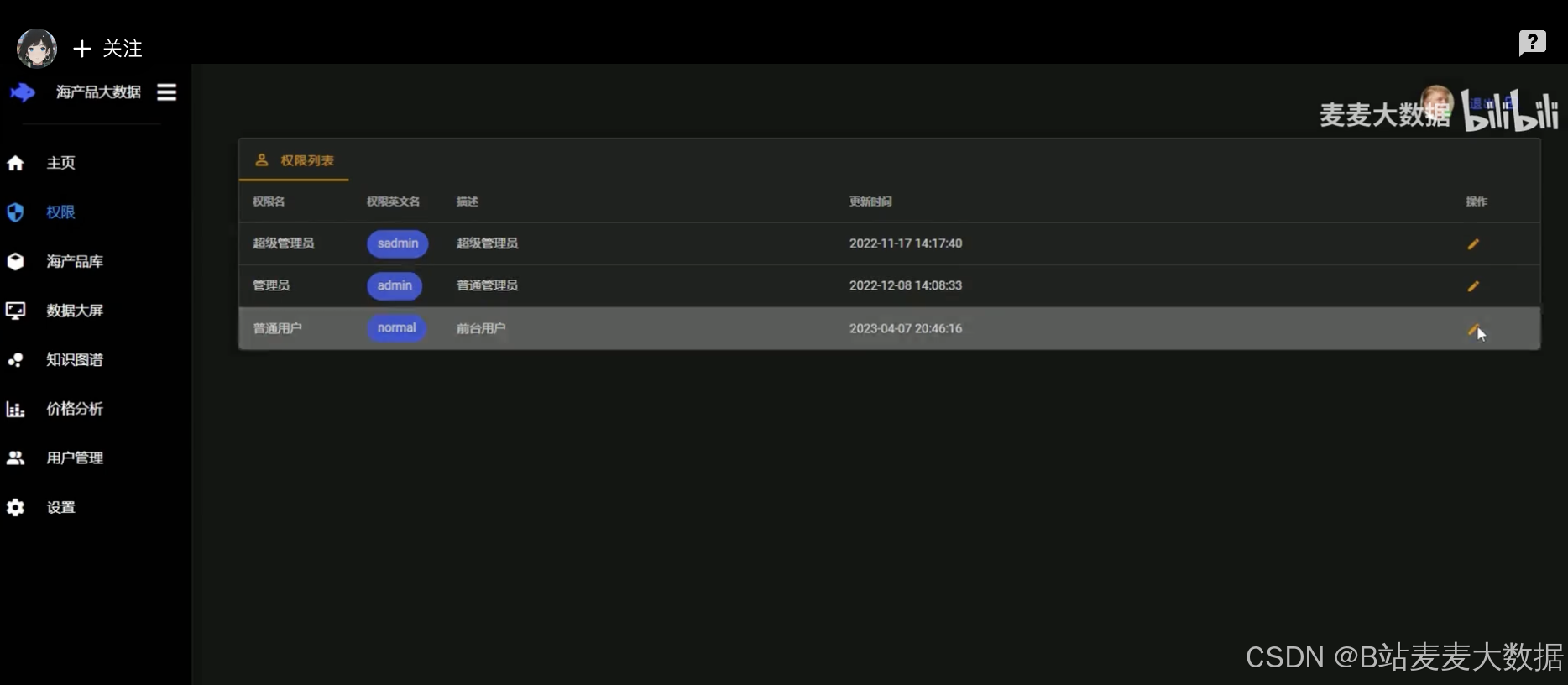
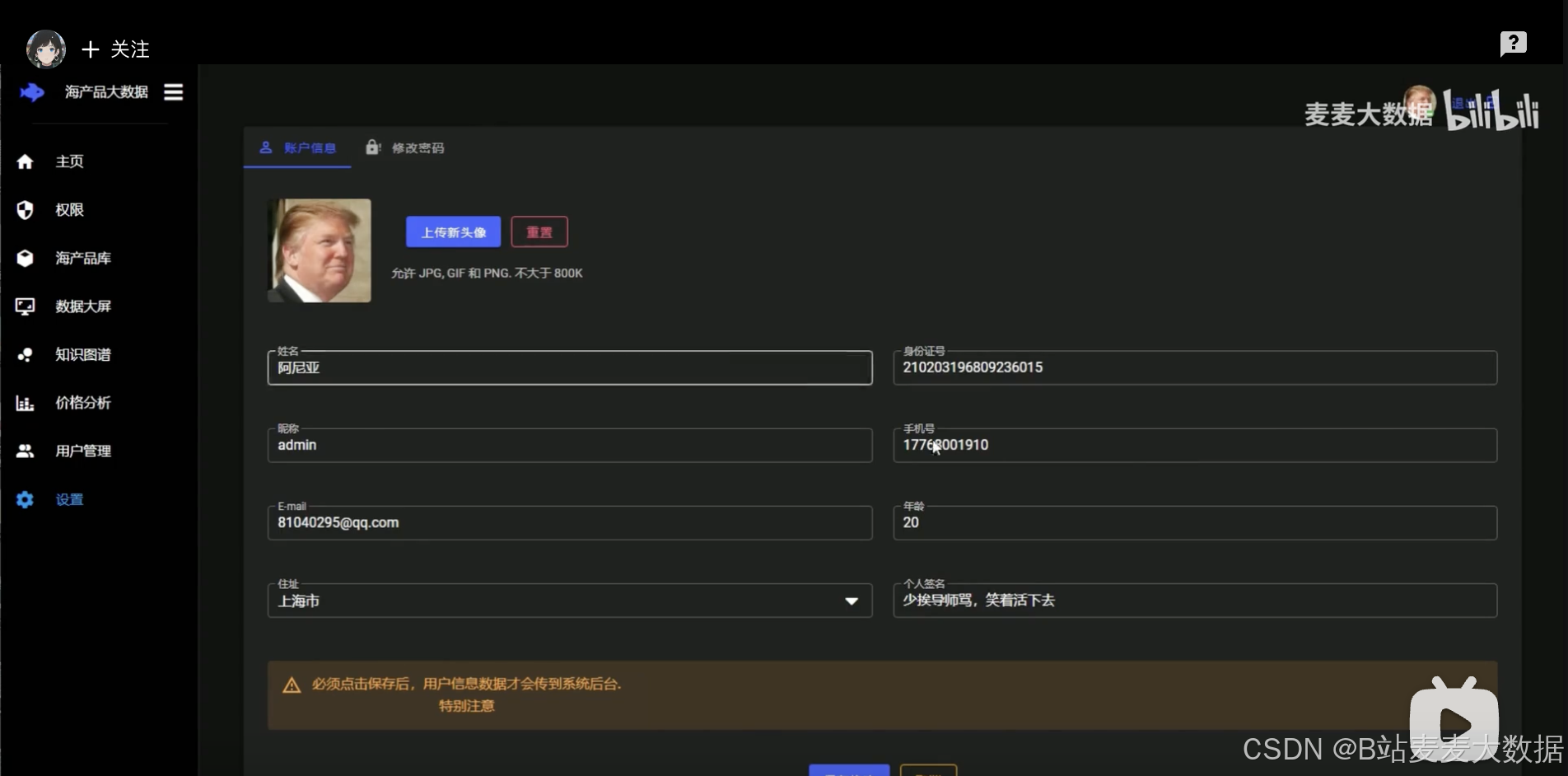
管理員可以使用權限和用戶管理功能
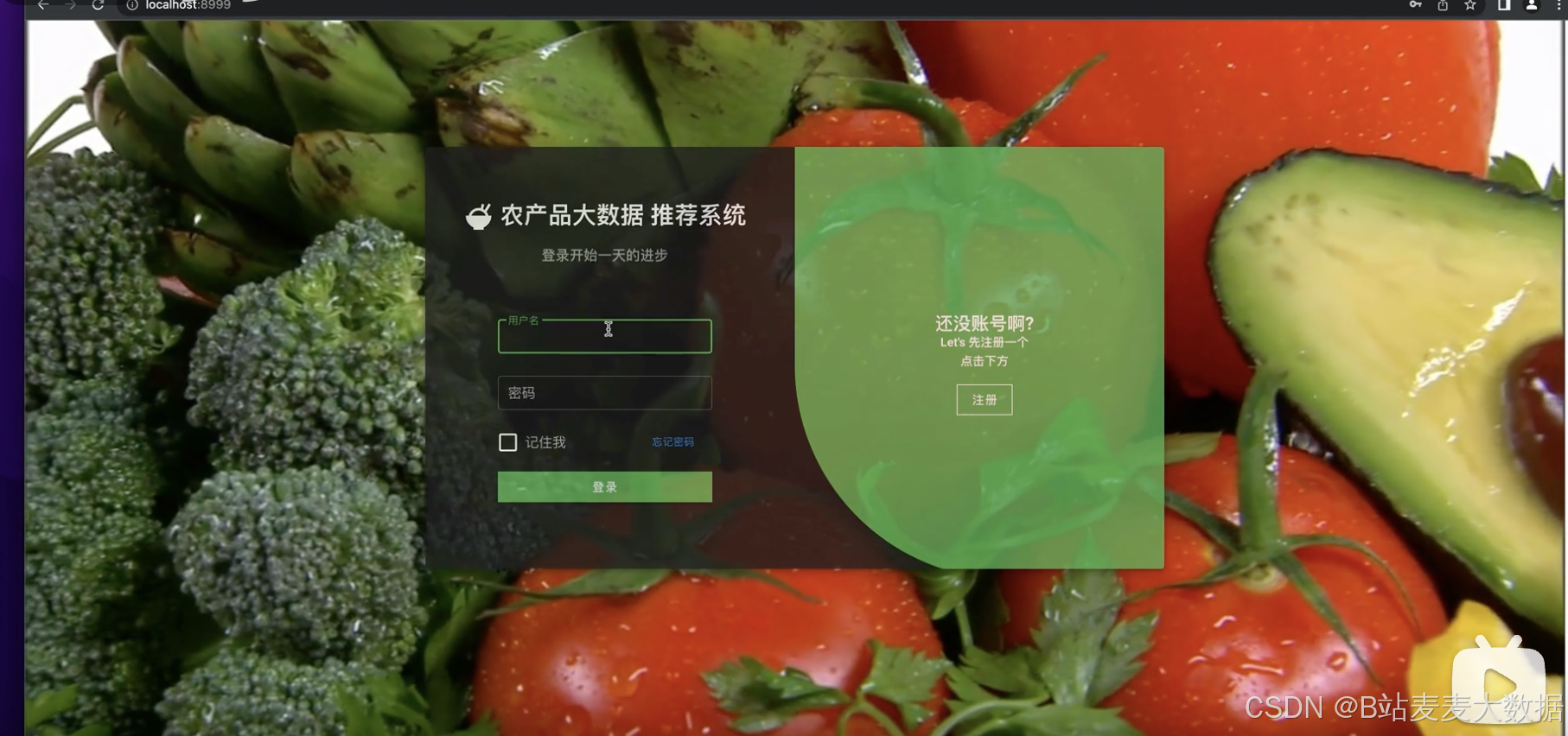
登錄、注冊和個人設置
4 實現難點與解決方案
數據采集的準確性和時效性:系統通過定時任務自動采集數據,并結合人工審核機制,確保數據的準確性和更新及時。
價格預測的準確度:選擇適合的多項式回歸模型并進行細致的參數調優,通過歷史數據訓練確保預測結果的可靠性。
知識圖譜的構建和應用:采用專業的農業知識進行知識圖譜的構建,并通過Neo4j數據庫高效管理和查詢復雜的關系數據。
5 數據獲取與處理
爬取數據
系統的數據采集核心依賴于對中國農產品交易信息網(pfsc.agri.cn)的實時監控與數據抓取。通過編寫高效的數據爬蟲程序,使用Python的requests庫直接向目標網站的API發送請求,獲取農產品的最新及歷史價格數據。返回的數據格式為JSON,便于進一步的處理和分析。我們的數據處理流程包括數據清洗、去重、格式化,最終將整理好的數據存儲到MySQL數據庫中,以供后續的數據分析和價格預測使用。
此外,系統設計了一套靈活的數據更新機制,確保無需修改代碼即可定期自動更新數據,并且實時展示到用戶界面。這一機制不僅大大降低了系統維護的工作量,也保證了用戶總能獲取到最新的市場價格信息。
需要注意的是,系統中農產品的圖片是我們自己去網上找之后放在系統中的,如果新增農產品,圖片是需要自己去找到的。
結論
農產品價格預測系統的建立為農業生產和市場分析提供了有力的技術支持。未來,我們計劃引入更多的數據源和先進的預測模型,進一步提高價格預測的準確度。同時,將探索利用機器學習和人工智能技術,優化推薦算法,提升用戶個性化服務的質量。此外,系統將繼續豐富知識圖譜內容,拓展可視化分析功能,以滿足用戶更為多樣化的信息需求。
(下篇))
 :哈希表(Hash Table)中的一個關鍵性能指標)
原理)




Digit Recognizer 手寫數字識別)










:拷貝構造函數與賦值運算符重載深度解析》)
