論文閱讀 | CVPR 2024 | UniRGB-IR:通過適配器調優實現可見光-紅外語義任務的統一框架?
- 1&&2. 摘要&&引言
- 3.方法
- 3.1 整體架構
- 3.2 多模態特征池
- 3.3 補充特征注入器
- 3.4 適配器調優范式
- 4 實驗
- 4.1 RGB-IR 目標檢測
- 4.2 RGB-IR 語義分割
- 4.3 RGB-IR 顯著目標檢測
- 4.4 消融研究
- 4.5 可視化分析
- 5 結論

題目:UniRGB-IR: A Unified Framework for Visible-Infrared
Semantic Tasks via Adapter Tuning
期刊:Computer Vision and Pattern Recognition(CVPR)
論文:paper
代碼:code
年份:2024
1&&2. 摘要&&引言
由于可見光(RGB)和紅外(IR)圖像在低光照和惡劣天氣等挑戰性條件下能提供更高的準確性和魯棒性,對它們的語義分析已受到廣泛關注。
然而,由于缺乏在大規模紅外圖像數據集上預訓練的基礎模型,現有方法傾向于設計特定于任務的框架,并直接在它們的RGB-IR語義相關數據集上使用預訓練的基礎模型進行微調,這導致了可擴展性差和泛化能力有限的問題。
為了克服這些限制,我們提出了UniRGB-IR,這是一個用于RGB-IR語義任務的可擴展且高效的框架,它引入了一種新穎的適配器機制,能夠有效地將豐富的多模態特征融入預訓練的基于RGB的基礎模型中。
我們的框架包含三個關鍵組件:一個視覺變換器(ViT)基礎模型、一個多模態特征池(MFP)模塊和一個補充特征注入器(SFI)模塊。MFP和SFI模塊相互協作作為一個適配器,有效地利用上下文多尺度特征來補充ViT特征。在訓練過程中,我們凍結整個基礎模型以繼承先驗知識,僅優化MFP和SFI模塊。
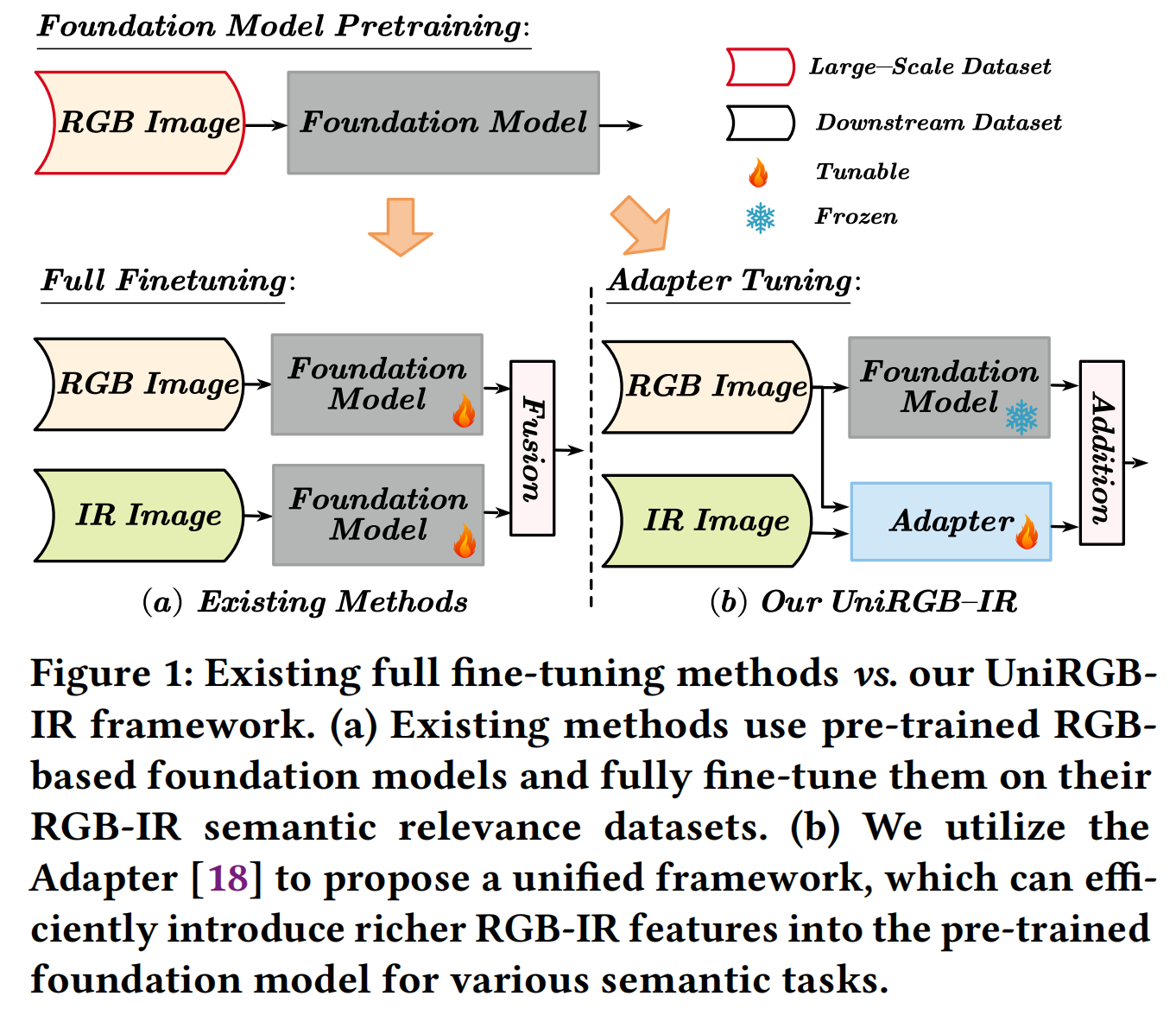
圖1:現有全微調方法 vs. 我們的UniRGB-IR框架。(a) 現有方法使用預訓練的基于RGB的基礎模型,并在其RGB-IR語義相關數據集上對其進行全微調。(b) 我們利用適配器[18]提出一個統一框架,能夠高效地將更豐富的RGB-IR特征引入預訓練的基礎模型,用于各種語義任務。?
總體而言,我們的貢獻總結如下:??
- 我們探索了一個名為UniRGB-IR的可擴展且高效的框架,用于RGB-IR語義任務。據我們所知,這是首次嘗試為各種RGB-IR下游任務構建統一框架。
- 我們設計了一個多模態特征池(MFP)模塊和一個補充特征注入器(SFI)模塊。前者從兩種模態圖像中提取上下文多尺度特征,后者將所需特征動態注入預訓練模型。這兩個模塊可以通過適配器調優范式進行高效微調,以用更豐富的RGB-IR特征補充預訓練的基礎模型,用于特定的語義任務。
- 我們將視覺變換器基礎模型納入UniRGB-IR框架,以評估我們方法在RGB-IR語義任務上的有效性,包括RGB-IR目標檢測、RGB-IR語義分割和RGB-IR顯著目標檢測。廣泛的實驗結果表明,我們的方法可以在這些下游任務上高效地實現卓越的性能。
3.方法
3.1 整體架構
UniRGB-IR 的整體框架如圖 2 所示,它包含三個部分:視覺變換器 (Vision Transformer, ViT) 模型、多模態特征池 (Multi-modal Feature Pool, MFP) 模塊和補充特征注入器 (Supplementary Feature Injector, SFI) 模塊。
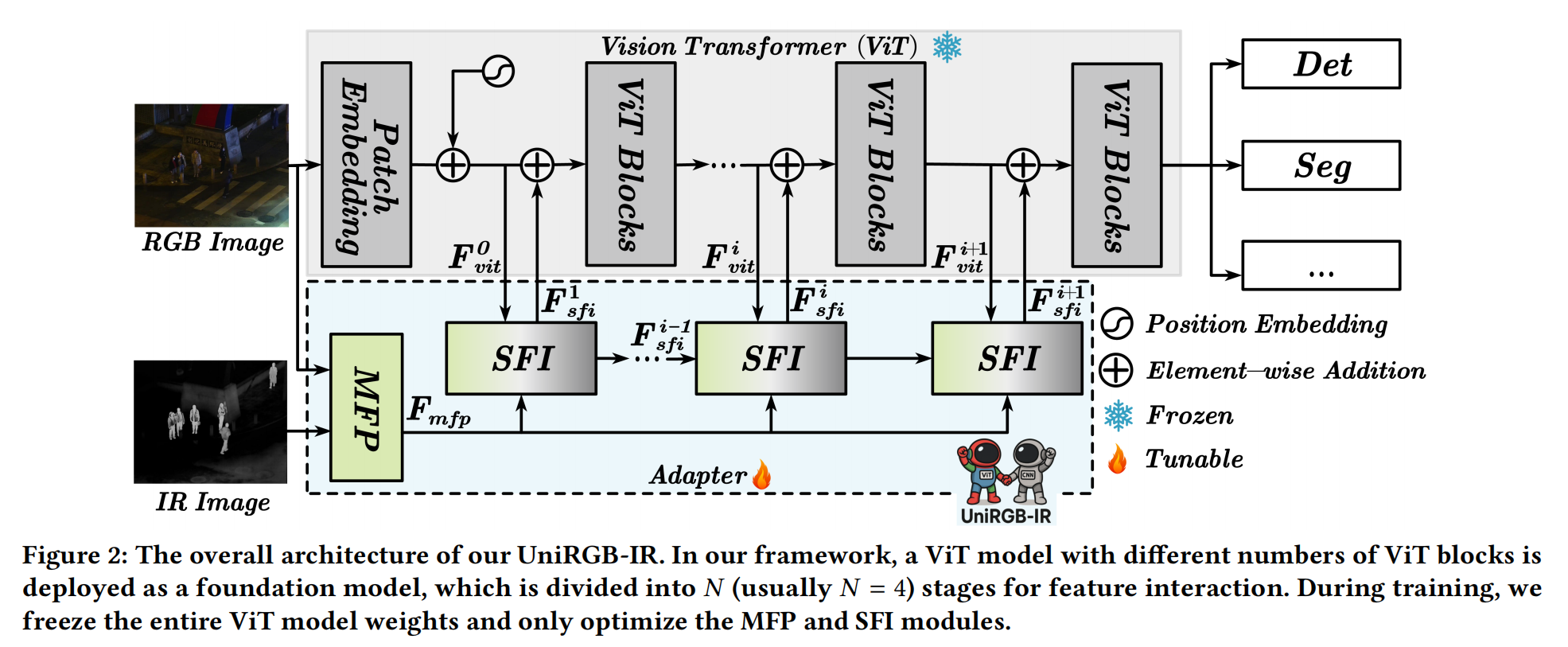
在我們的框架中,ViT 模型被用作預訓練的基礎模型,并在訓練過程中凍結。具體來說,對于 ViT 模型,RGB 圖像直接輸入到塊嵌入 (patch embedding) 過程中以獲得 D 維特征標記 (token),其分辨率通常是原始圖像的 1/16。
為了補充各種 RGB-IR 語義任務所需的更豐富特征,我們將 RGB 和 IR 圖像輸入到 MFP 模塊中,以從兩種模態中提取上下文多尺度特征(例如,原始圖像分辨率的 1/8、1/16 和 1/32)。之后,這些更豐富的特征通過 SFI 模塊動態注入到 ViT 模型的特征中,這可以自適應地將所需的 RGB-IR 特征引入 ViT 模型。為了將提取的特征完全集成到 ViT 模型中,我們在每個 ViT 階段 (stage) 開始時添加一個 SFI 模塊。因此,經過 N 個階段的特征注入后,來自 ViT 模型的最終特征可以用于各種 RGB-IR 語義任務。
3.2 多模態特征池
為了補充 RGB-IR 語義任務的豐富特征表示,我們引入了多模態特征池 (MFP) 模塊,包括多感知 (multiple perception) 和特征金字塔 (feature pyramid)。前者可以使用不同的卷積核提取具有長距離建模能力的上下文特征。與增加模型寬度或深度的現有工作[17,64]不同,我們在通道維度上高效地實現了多感受野感知。至于特征金字塔,它可以獲得多尺度特征以增強小目標特征。因此,這兩個操作串聯連接以構建 MFP 模塊,如圖 3 所示。
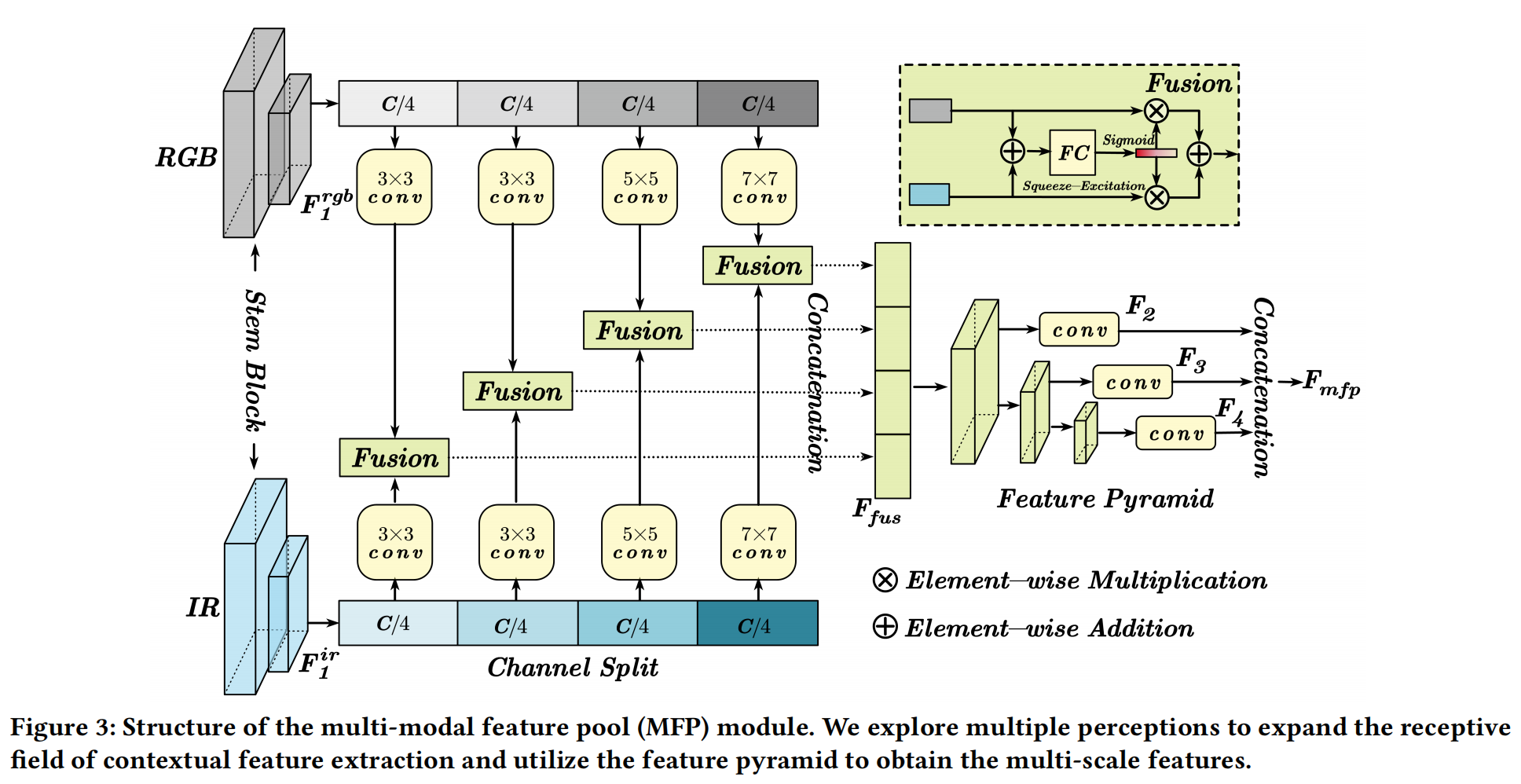
具體來說,對于輸入的 RGB(H×W×3) 和 IR(H×W) 圖像,我們首先使用從 ResNet[16] 借鑒的 stem 塊來提取兩種模態的特征 F1rgbF_{1}^{rgb}F1rgb? 和 F1ir∈RH/4×W/4×CF_{1}^{ir} \in R^{H/4 \times W/4 \times C}F1ir?∈RH/4×W/4×C。然后,利用通道分割 (channel splitting) 將這兩個特征分成四個相等的部分。為了提取多感受野感知,每個部分都經過不同核大小(3×3, 3×3, 5×5 和 7×7)的卷積操作。然后,我們使用 SE 注意力[19](如圖 3 所示)融合來自兩種模態的每個處理后的特征。因此,我們連接每個融合部分以獲得 RGB-IR 上下文特征 FfusF_{fus}Ffus?,其公式表示為:
Ffus=Γk=14(Fus?(Wkrgb?fkrgb,Wkir?fkir)),(1)F_{fus}=\Gamma_{k=1}^4\left(\operatorname{Fus}\left(W_k^{rgb}* f_k^{rgb}, W_k^{ir}* f_k^{ir}\right)\right),\qquad(1)Ffus?=Γk=14?(Fus(Wkrgb??fkrgb?,Wkir??fkir?)),(1)
其中 Ffus∈RH/4×W/4×CF_{fus} \in R^{H/4 \times W/4 \times C}Ffus?∈RH/4×W/4×C, fkrgbf_k^{rgb}fkrgb? 和 fkirf_k^{ir}fkir? 分別是 F1rgbF_{1}^{rgb}F1rgb? 和 F1irF_{1}^{ir}F1ir? 特征的第 k 部分,WkW_kWk? 是第 k 個核大小的卷積,Γ\GammaΓ 是連接操作,Fus?(?,?)\operatorname{Fus}(\cdot,\cdot)Fus(?,?) 表示圖 3 所示的融合模塊。
對于特征金字塔,應用了一組三個步長 (stride)=2 的 3×3 卷積來下采樣特征圖的大小。然后,每個尺度的特征被輸入到一個 1×1 卷積中,將特征圖投影到 D 維。因此,我們可以獲得一組多尺度特征 {F2,F3,F4}\{F_2, F_3, F_4\}{F2?,F3?,F4?},其分辨率分別為原始圖像的 1/8、1/16 和 1/32。最后,我們將這些特征展平 (flatten) 并連接 (concatenate) 成特征標記 Fmfp∈R(HW82+HW162+HW322)×DF_{mfp} \in R^{\left(\frac{HW}{8^{2}} + \frac{HW}{16^{2}} + \frac{HW}{32^{2}}\right) \times D}Fmfp?∈R(82HW?+162HW?+322HW?)×D,它將用作 ViT 基礎模型的補充特征。
3.3 補充特征注入器
為了在不改變 ViT 結構的情況下自適應地引入上下文多尺度特征,我們提出了一個補充特征注入器 (SFI) 模塊,如圖 4 所示。
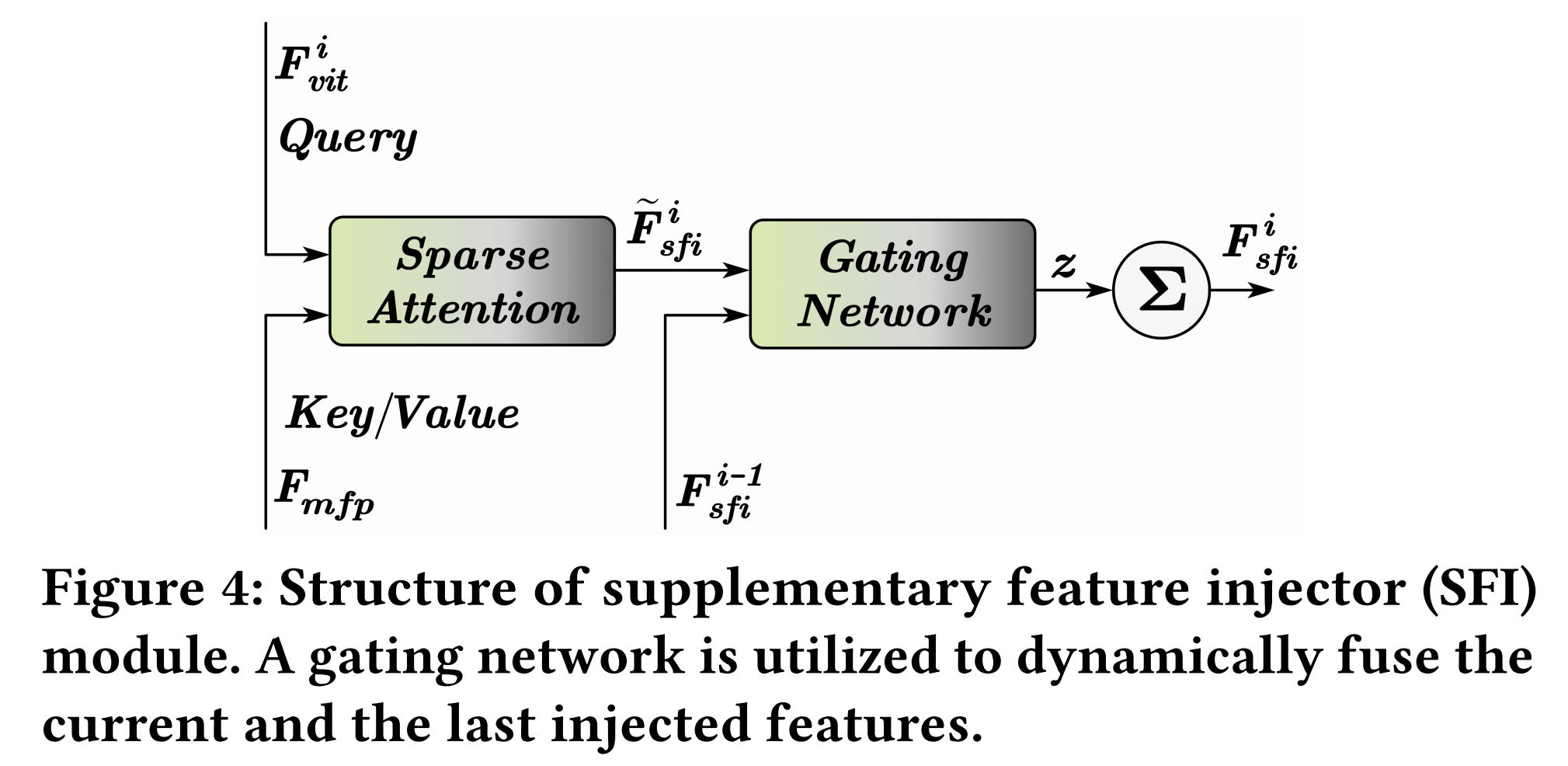
由于上下文多尺度特征 FmfpF_{mfp}Fmfp? 和 ViT 特征 FvitiF_{vit}^{i}Fviti? 的序列長度不同,為了解決這個問題,我們采用稀疏注意力(例如 Pale Attention[62] 和 Deformable Attention[89])來動態地從每個尺度采樣補充特征。具體來說,我們利用 ViT 特征 Fviti∈RHW162×DF_{vit}^{i} \in R^{\frac{HW}{16^{2}} \times D}Fviti?∈R162HW?×D 作為查詢 (query),利用上下文多尺度特征 Fmfp∈R(HW82+HW162+HW322)×DF_{mfp} \in R^{\left(\frac{HW}{8^{2}} + \frac{HW}{16^{2}} + \frac{HW}{32^{2}}\right) \times D}Fmfp?∈R(82HW?+162HW?+322HW?)×D 作為鍵 (key) 和值 (value),其可以表示為:
F~sfii=Attention?(LN(Fviti),LN(Fmfp)),\tilde{F}_{sfi}^{i} = \operatorname{Attention}\left(LN\left(F_{vit}^{i}\right), LN\left(F_{mfp}\right)\right),F~sfii?=Attention(LN(Fviti?),LN(Fmfp?)),
其中 Attention?(?)\operatorname{Attention}(\cdot)Attention(?) 是稀疏注意力,LN(?)LN(\cdot)LN(?) 是 LayerNorm[1],旨在減少訓練期間的模態差異。
此外,我們采用漸進式注入 (progressive injection) 來引入上下文多尺度特征,這可以平衡基礎模型特征和注入的特征 F~sfii\tilde{F}_{sfi}^{i}F~sfii?。因此,我們探索了一個門控網絡 (gating network) 來預測融合權重 zzz,以門控 (gate) Fsfii?1F_{sfi}^{i-1}Fsfii?1? 和 F~sfii\tilde{F}_{sfi}^{i}F~sfii? 進行動態融合。具體來說,我們將兩個特征 Fsfii?1F_{sfi}^{i-1}Fsfii?1? 和 F~sfii\tilde{F}_{sfi}^{i}F~sfii? 連接起來,并將其輸入線性層以預測權重 zzz。然后,zzz 和 1?z1-z1?z 分別用于融合 Fsfii?1F_{sfi}^{i-1}Fsfii?1? 和 F~sfii\tilde{F}_{sfi}^{i}F~sfii? 特征。SFI 模塊的最終輸出特征 FsfiiF_{sfi}^{i}Fsfii? 可以表示為:
Fsfii={F~sfii,i=1(1?z)?F~sfii+z?Fsfii?1,i=2…NF_{sfi}^i=\begin{cases}\tilde{F}_{sfi}^i,& i=1\\ (1-z)*\tilde{F}_{sfi}^i + z* F_{sfi}^{i-1},& i=2\ldots N\end{cases}Fsfii?={F~sfii?,(1?z)?F~sfii?+z?Fsfii?1?,?i=1i=2…N?
3.4 適配器調優范式
為了完全繼承在大規模數據集上預訓練的 ViT 的先驗知識,我們探索了適配器調優范式 (Adapter Tuning Paradigm) 而非全微調 (Full Fine-tuning) 方式。
對于不同語義任務的數據集 D={(xj,gtj)}j=1MD=\{(x_j, gt_j)\}_{j=1}^{M}D={(xj?,gtj?)}j=1M?,全微調過程計算預測值和真實值 (ground truth) 之間的損失,其可以表示為:
L(D,θ)=∑j=1Mloss?(Fθ(xj),gtj),(4)\mathcal{L}(D,\theta)=\sum_{j=1}^{M}\operatorname{loss}\left(F_{\theta}\left(x_{j}\right), gt_{j}\right), \qquad(4)L(D,θ)=j=1∑M?loss(Fθ?(xj?),gtj?),(4)
其中 loss?\operatorname{loss}loss 表示損失函數,FθF_{\theta}Fθ? 表示由 θ\thetaθ 參數化的整個網絡。之后,θ\thetaθ 通過以下公式進行優化:
θ←arg?min?θL(D,θ).(5)\theta \leftarrow \underset{\theta}{\arg\min} \, \mathcal{L}(D,\theta). \qquad(5)θ←θargmin?L(D,θ).(5)
然而,在我們的適配器調優范式中,參數 θ\thetaθ 由兩部分組成:一部分是原始 ViT 模型中的參數 θV\theta_VθV?,另一部分是我們 UniRGB-IR 中的參數 θA\theta_AθA?(即 MFP 和 SFI 模塊的參數)。在訓練期間,我們凍結參數 θV\theta_VθV?,僅優化參數 θA\theta_AθA?。因此,我們的損失函數和優化可以表示為:
L(D,θV,θA)=∑j=1Mloss?(FθV,θA(xj),gtj),(6)\mathcal{L}\left(D,\theta_{V},\theta_{A}\right)=\sum_{j=1}^{M}\operatorname{loss}\left(F_{\theta_{V},\theta_{A}}\left(x_{j}\right), gt_{j}\right), \qquad(6)L(D,θV?,θA?)=j=1∑M?loss(FθV?,θA??(xj?),gtj?),(6)
θA←arg?min?θAL(D,θV,θA).(7)\theta_{A} \leftarrow \underset{\theta_{A}}{\arg\min} \, \mathcal{L}\left(D,\theta_{V},\theta_{A}\right). \qquad(7)θA?←θA?argmin?L(D,θV?,θA?).(7)
4 實驗
為了評估我們提出的 UniRGB-IR 的有效性,我們利用在 COCO[34] 數據集上預訓練的 ViT-Base 模型作為基礎模型,并將該框架應用于執行 RGB-IR 語義任務。我們僅優化 MFP 和 SFI 模塊。我們評估并比較了我們的方法與各種競爭模型,包括基于 CNN 和基于 Transformer 的模型。此外,我們的評估涵蓋了多種任務,包括在 FLIR[73]、LLVIP[23] 和 KAIST[22] 數據集上的 RGB-IR 目標檢測,在 PST900[47] 和 MFNet[15](見補充材料)數據集上的 RGB-IR 語義分割,以及在 VT821[57]、VT1000[54] 和 VT5000[52] 數據集上的 RGB-IR 顯著目標檢測。此外,還對設計的模塊進行了消融實驗和定性實驗,以驗證 UniRGB-IR 框架可以作為一個統一框架,有效地將 RGB-IR 特征引入基礎模型以實現卓越的性能。
4.1 RGB-IR 目標檢測
- 數據集 (Datasets):
- FLIR[73]: 這是一個配對的可見光和紅外目標檢測數據集,包含白天和夜間場景。它包含 4,129 個對齊的 RGB-IR 圖像對用于訓練,1,013 個用于測試。
- LLVIP[23]: 該數據集包含 15,488 個對齊的 RGB-IR 圖像對,其中 12,025 張圖像用于訓練,3,463 張圖像用于測試。
- KAIST[22]: 這是一個對齊的多光譜行人檢測數據集,其中 8,963 個圖像對用于訓練,2,252 個圖像對用于測試。
- 評估指標 (Metrics):
- 對于 FLIR 和 LLVIP 數據集,我們采用 平均精度均值 (mean Average Precision, mAP) 來評估檢測性能。
- 對于 KAIST 數據集,我們使用在每張圖像誤報數 (False Positives Per Image, FPPI) 范圍 [10?2, 10?] 上的 對數平均漏檢率 (log-average miss rate, MR?2) 來評估行人檢測性能。
- 實驗設置 (Settings):
- 所有實驗均在 NVIDIA GeForce RTX 3090 GPU 上進行。
- 我們在 MMDetection 庫上實現了我們的框架,并使用 Cascade R-CNN[3] 作為基本框架來執行 RGB-IR 目標檢測。
- 檢測器使用初始學習率為 2×10?? 訓練 48 個周期 (epoch)。
- 批量大小 (batch size) 設置為 16,使用 AdamW[41] 優化器,權重衰減 (weight decay) 為 0.1。
- 也使用了水平翻轉進行數據增強。
- 結果 (Results):
- FLIR 和 LLVIP 數據集上的結果: 如表 1 所示,我們將我們的方法與五種常見的單模態方法和四種有競爭力的多模態方法進行了比較。可以看出,大多數多模態檢測器甚至比單模態檢測器(例如 IR 模態的 Cascade R-CNN)還要差。這是因為在有限光照條件下,RGB 特征會干擾紅外特征,對用于目標檢測任務的融合特征產生了負面影響。然而,我們的 UniRGB-IR 通過 SFI 模塊有效地解決了這個問題,使檢測器能夠實現更好的分類和定位過程。我們的方法在 FLIR 和 LLVIP 數據集上均取得了最佳性能(mAP 分別為 44.1% 和 63.2%)。
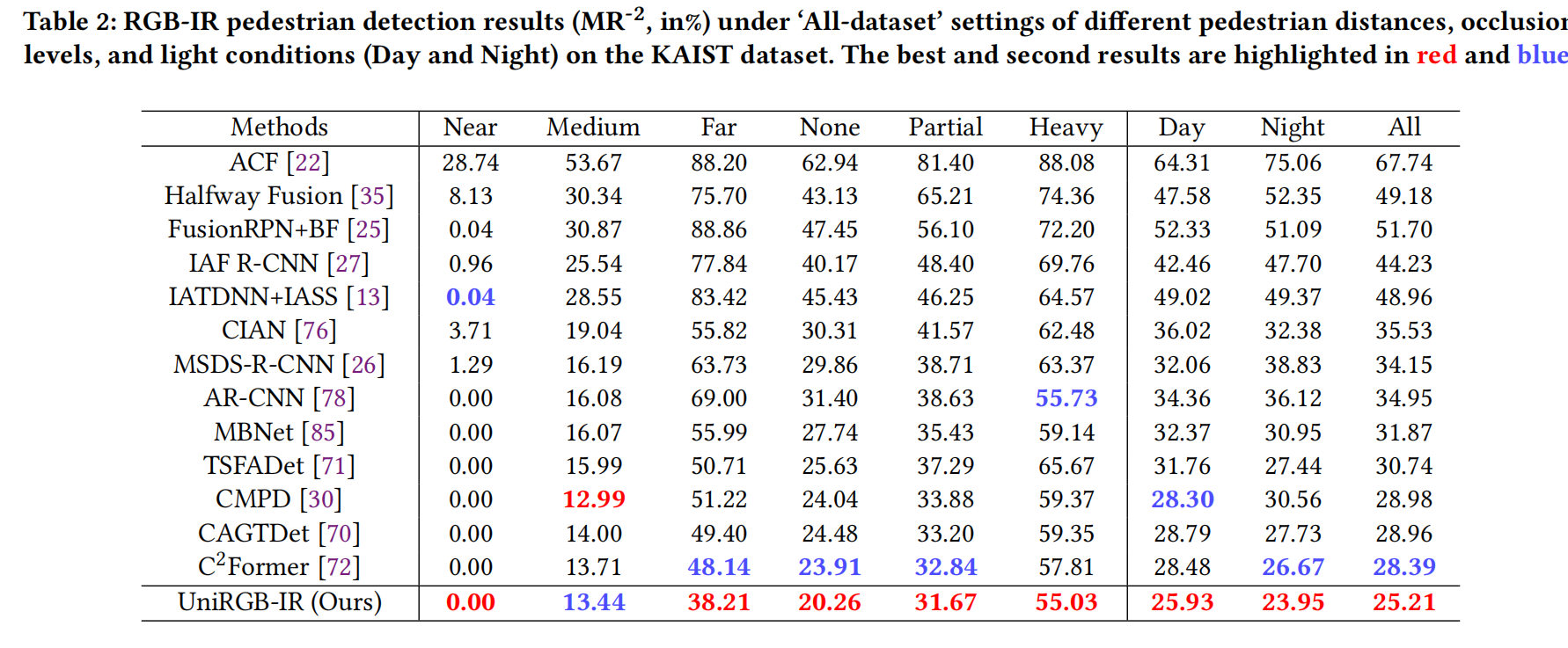
- KAIST 數據集上的結果: 表 2 展示了在 KAIST 數據集“All-dataset”設置[22]下,不同方法在不同行人距離、遮擋程度和光照條件(白天和夜晚)下的結果。我們的模型在“All”、“Day”和“Night”條件以及其他五個子集(“Near”、“Far”、“None”、“Partial”和“Heavy”)中的四個上取得了最佳性能,僅在“Medium”子集上排名第二。此外,我們的檢測器在“All”條件下超越了之前的最佳競爭對手 C2Former 3.18%(MR?2 從 28.39% 降至 25.21%),這表明 UniRGB-IR 對復雜場景具有魯棒性。
表 1:在 FLIR 和 LLVIP 數據集上的 RGB-IR 目標檢測結果 (mAP, %)。最佳結果標紅,次佳結果標藍。“-”表示作者未提供相應結果。
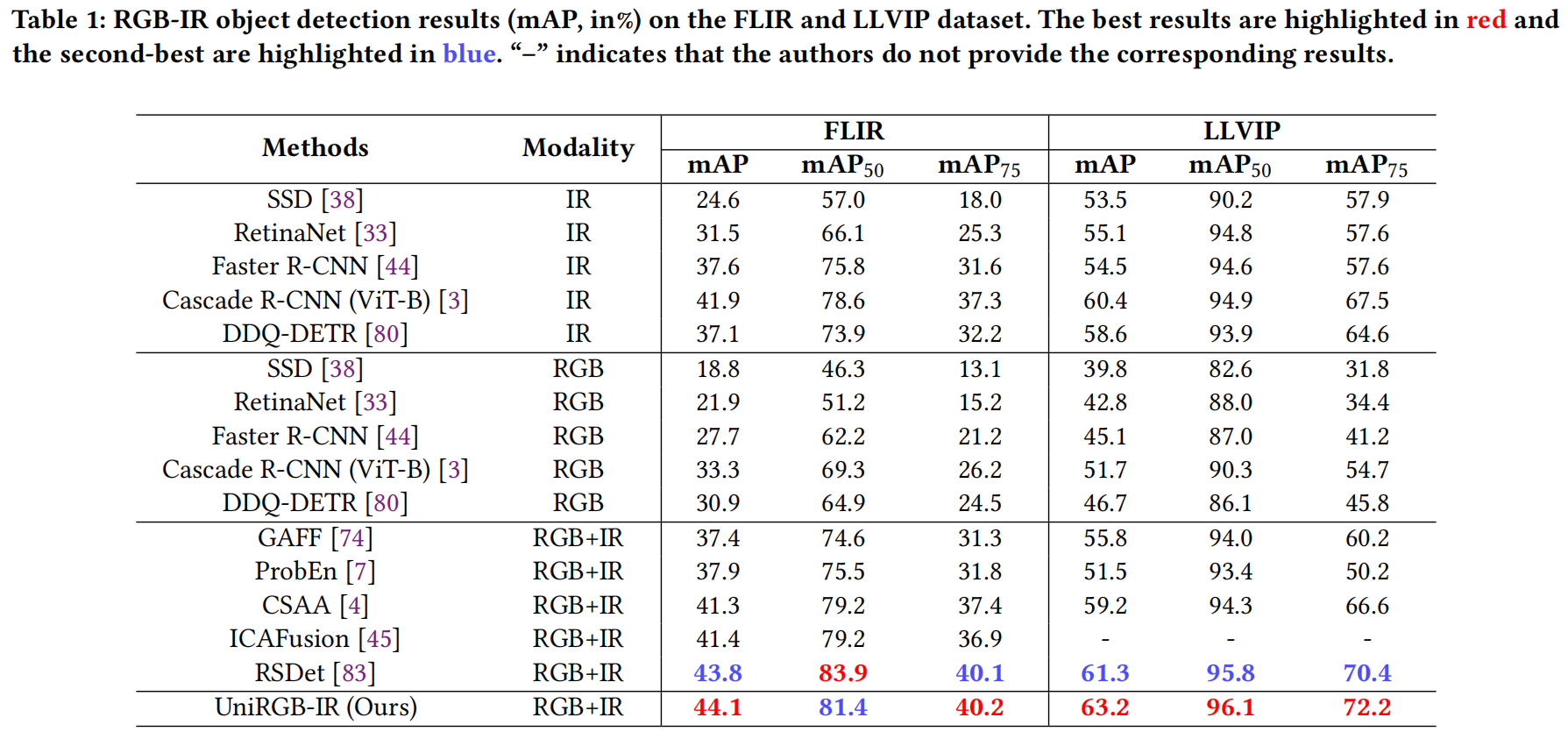
表 2:KAIST 數據集上不同距離、遮擋和光照條件下的 RGB-IR 行人檢測結果 (MR?2, %)。最佳結果標紅,次佳結果標藍。
4.2 RGB-IR 語義分割
- 數據集 (Datasets):
- PST900[47]: 該數據集包含 597 個圖像對用于訓練,288 個用于測試,包含五個類別(背景、滅火器、背包、手鉆和幸存者)。數據集按照 2:1:1 的比例分為訓練集、驗證集和測試集。
- MFNet[15]: (見補充材料)。
- 評估指標 (Metrics):
- 使用兩個指標評估性能:平均準確率 (mean accuracy, mAcc) 和 平均交并比 (mean Intersection over Union, mIoU)。兩者都是通過平均所有類別的交集與并集的比率來計算的。
- 實驗設置 (Settings):
- 與 RGB-IR 目標檢測任務類似,我們將我們的方法集成到 SETR[84] 基礎框架中,并在 MMSegmentation 庫上實現。
- 微調過程總共進行 10K 次迭代,初始學習率為 0.01。
- 我們使用 SGD 優化器,并將批量大小設置為 16。
- 結果 (Results):
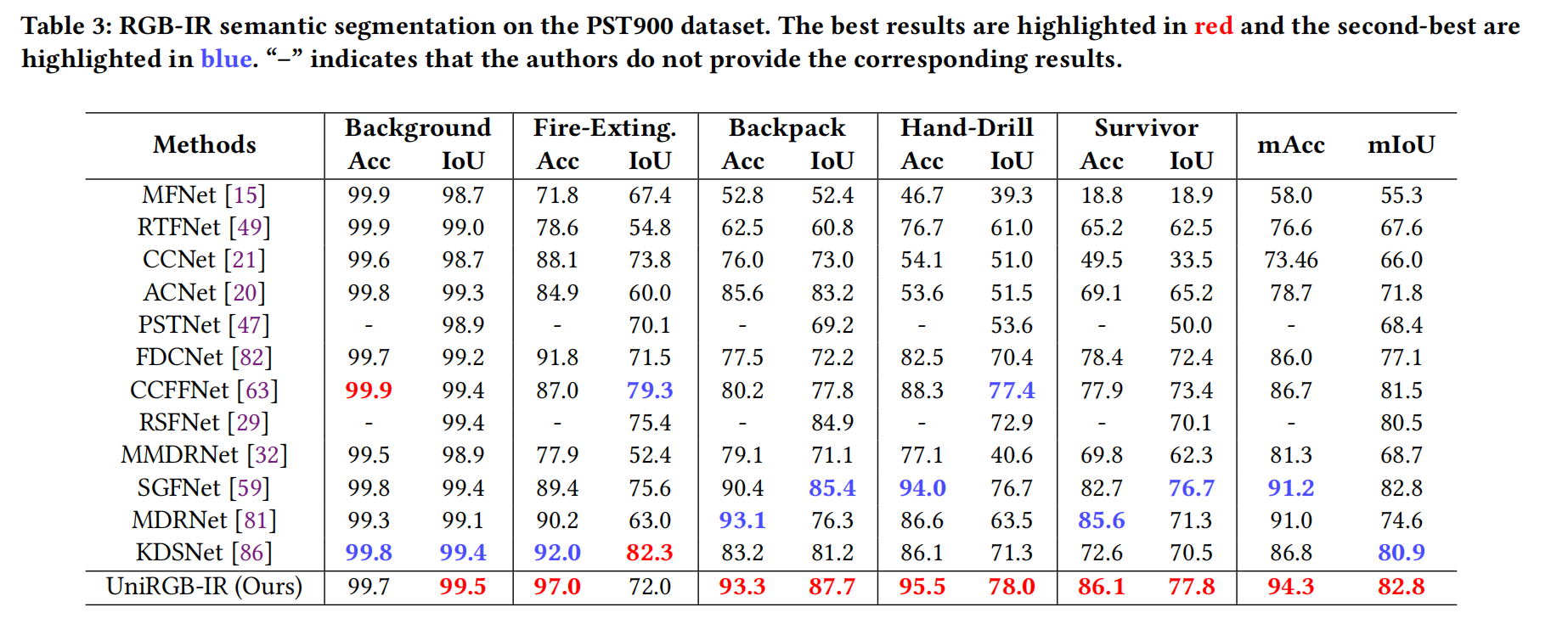
- 表 3 展示了不同 RGB-IR 分割方法在 PST900 數據集上的定量結果。結果表明,我們的模型在 mAcc 和 mIoU 方面均顯著優于其他方法(分別為 94.3% 和 82.8%)。此外,我們的模型在背包 (Backpack)、手鉆 (Hand-Drill) 和幸存者 (Survivor) 類別上表現出色,IoU 分別超過第二名方法 2.3%、0.6% 和 1.1%,這有力地證明了我們 UniRGB-IR 的有效性。
表 3:PST900 數據集上的 RGB-IR 語義分割結果。最佳結果標紅,次佳結果標藍。“-”表示作者未提供相應結果。
4.3 RGB-IR 顯著目標檢測
- 數據集 (Datasets):
- VT821[57]: 包含 821 張配準的 RGB 和 IR 圖像。
- VT1000[54]: 包含 1000 張配準的 RGB-IR 圖像,場景簡單且圖像對齊。
- VT5000[52]: 這是一個近期的大規模 RGB-IR 數據集,包含全天候各種有限光照條件下的場景。按照 [52] 中的慣例,我們使用 VT5000 數據集中的 2500 個圖像對作為訓練數據集,其余圖像對以及來自 VT821 和 VT1000 數據集的圖像對用作測試數據集。
- 評估指標 (Metrics):
- 使用四個指標評估性能:F-measure (adpF↑), E-Measure (adpE↑), S-Measure (S↑) 和 平均絕對誤差 (Mean Absolute Error, MAE↓)。↑ 表示越高越好,↓ 表示越低越好。
- 實驗設置 (Settings):
- 與 RGB-IR 語義分割任務相同,我們將我們的方法集成到 SETR 基礎框架中,并在 MMSegmentation 庫上實現。
- 微調過程總共進行 10K 次迭代,初始學習率為 0.01。
- 我們使用 SGD 優化器,并將批量大小設置為 64。
- 為方便起見,所有輸入圖像在測試時都調整為 224×224。
- 結果 (Results):
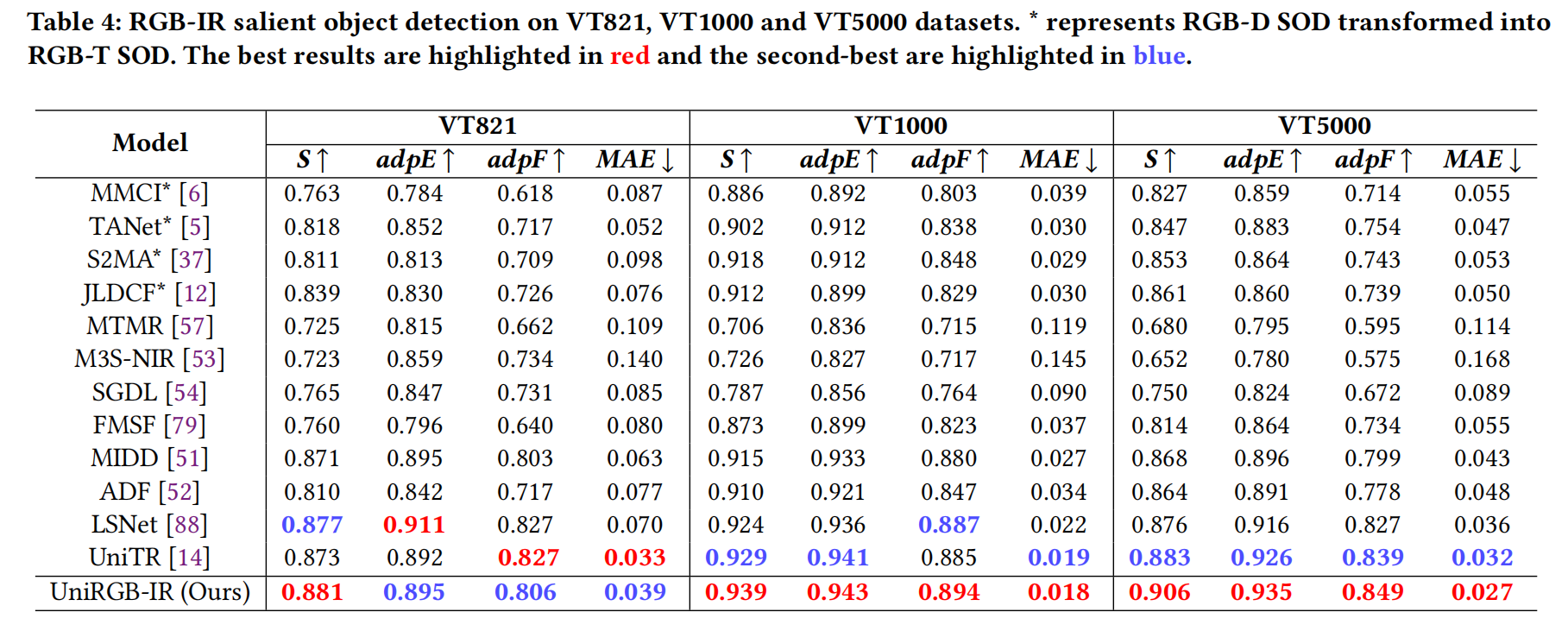
- 表 4 報告了定量比較結果。可以看出,我們的 UniRGB-IR 在 VT1000 和 VT5000 數據集上的所有評估指標均優于 SOTA 方法。具體來說,我們的 UniRGB-IR 在 VT5000 上的 S、adpE、adpF 和 MAE 指標分別達到 0.906、0.935、0.849 和 0.027,所有這些都高于之前的競爭對手 UniTR[14]。這些顯著的結果清楚地表明,UniRGB-IR 預測的顯著圖非常接近相應的真實標注 (ground-truth)。
表 4:在 VT821、VT1000 和 VT5000 數據集上的 RGB-IR 顯著目標檢測結果。 表示 RGB-D SOD 轉換為 RGB-T SOD。最佳結果標紅,次佳結果標藍。
4.4 消融研究
我們進行了一系列消融實驗來驗證我們框架中關鍵組件的有效性。
- 組件消融 (Ablation for components): 為了研究 SFI 和 MFP 模塊的貢獻,我們逐步將每個模塊添加到基線模型中(僅使用堆疊的 RGB 和 IR 圖像輸入 Cascade R-CNN 或 SETR 進行全微調)。如表 5 所示,僅添加 MFP 模塊(通過逐元素加法融合)分別帶來了 1.6% mAP 和 1.3% mIoU 的提升。最后,用 SFI 模塊替換逐元素加法操作進一步將 mAP 和 mIoU 指標分別提高了 2.9% 和 4.0%,在兩個數據集上都取得了最佳性能。
- SFI 模塊在不同階段的添加 (SFI module at different stages): 我們在 ViT 預訓練模型的不同階段開始處添加 SFI 模塊。從表 6 可以看出,在第一階段添加 SFI 模塊后,檢測器在 FLIR 數據集上達到 41.7% mAP。在第二階段和第三階段添加 SFI 模塊后,性能分別進一步提高了約 2% 和 3% mAP。然而,繼續將其添加到最終階段會降低檢測性能,同時增加計算開銷。因此,我們從 ViT 模型的第一階段到第三階段添加 SFI 模塊。
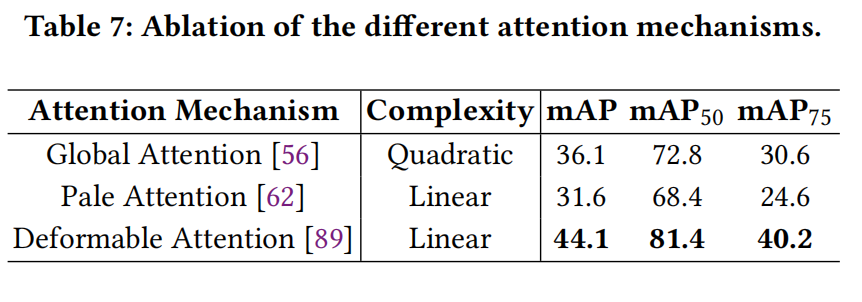
- SFI 模塊中的不同注意力機制 (Attention type in SFI module): 由于我們 SFI 模塊中的注意力機制是可替換的,我們在 UniRGB-IR 中采用了三種流行的注意力機制來討論它們對模型性能的影響。如表 7 所示,通過利用可變形注意力 (deformable attention),檢測器在線性復雜度下實現了最佳性能(44.1% mAP)。因此,可變形注意力更適合我們的框架,并被用作默認配置。
表 5:在 FLIR 和 PST900 數據集上關鍵組件的消融研究。最佳結果以粗體標出。
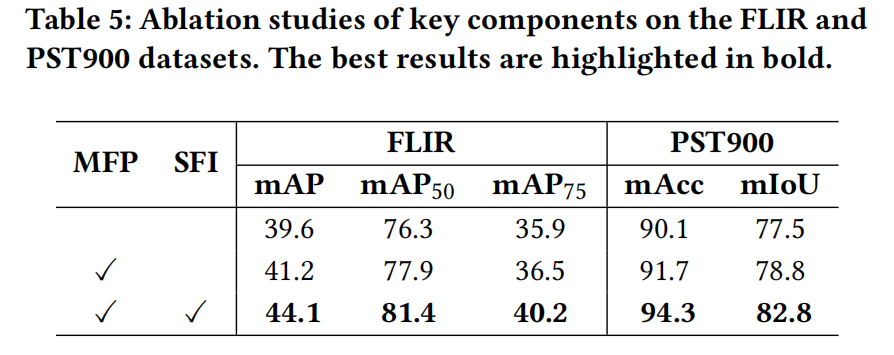
表 6:在不同階段添加 SFI 模塊的消融。

表 7:不同注意力機制的消融。
4.5 可視化分析
-
中間結果 (Intermediate results): 為了說明 SFI 模塊的有效性,我們在 FLIR 數據集上可視化了中間結果。從圖 5 中的 FmfpF_{mfp}Fmfp? 和 FsfiF_{sfi}Fsfi? 可以看出,通過 SFI 模塊,FsfiF_{sfi}Fsfi? 中的前景物體變得顯著。此外,我們還分別可視化了 Fmfp?FvitF_{mfp}-F_{vit}Fmfp??Fvit? 和 Fsfi?FvitF_{sfi}-F_{vit}Fsfi??Fvit? 的 t-SNE 圖。在使用 SFI 模塊后,注入的特征 FsfiF_{sfi}Fsfi? 的分布比 ViT 特征 FvitF_{vit}Fvit? 的分布更集中,這表明所需的更豐富的 RGB-IR 特征可以通過 SFI 模塊很好地補充到 ViT 模型中。
-
訓練效率 (Training efficiency): 我們進一步繪制了 UniRGB-IR 在不同訓練范式下每個 epoch 的 mAP 曲線,以證明 UniRGB-IR 的效率,如圖 6 所示。在訓練過程中,兩個模型的所有超參數都相同。從圖 6 可以看出,適配器調優范式的收斂速度超過了全微調策略。此外,通過利用適配器調優范式,我們的 UniRGB-IR 以更少的可訓練參數(約占全微調模型的 10%)實現了卓越的性能。上述結果驗證了我們方法的效率。
5 結論
在本文中,我們提出了一個用于 RGB-IR 語義任務的高效且可擴展的框架(名為 UniRGB-IR)。該框架包含一個多模態特征池(MFP)模塊和一個補充特征注入器(SFI)模塊。前者從兩種模態圖像中提取上下文多尺度特征,后者自適應地將這些特征注入到變換器模型中。這兩個模塊可以通過適配器調優范式進行高效優化,以用更豐富的 RGB-IR 特征補充預訓練的基礎模型,用于特定的語義任務。為了評估我們方法的有效性,我們將 ViT-Base 模型納入 UniRGB-IR 框架,并在各種 RGB-IR 語義任務上進行了評估。廣泛的實驗結果表明,我們的 UniRGB-IR 可以有效地作為一個統一框架,用于 RGB-IR 下游任務,以實現卓越的性能。我們相信我們的方法可以應用于更多的多模態現實世界應用。








:拷貝構造函數與賦值運算符重載深度解析》)

![[ 數據結構 ] 時間和空間復雜度](http://pic.xiahunao.cn/[ 數據結構 ] 時間和空間復雜度)




)



--54-65關)