銜接上篇文章:數據分析小白訓練營:基于python編程語言的Numpy庫介紹(第三方庫)(上篇)
(十一)數組的組合
核心功能:
一、生成基數組
np.arange().reshape()?+ 基礎運算
功能:創建初始數組并進行數值變換
- 示例:
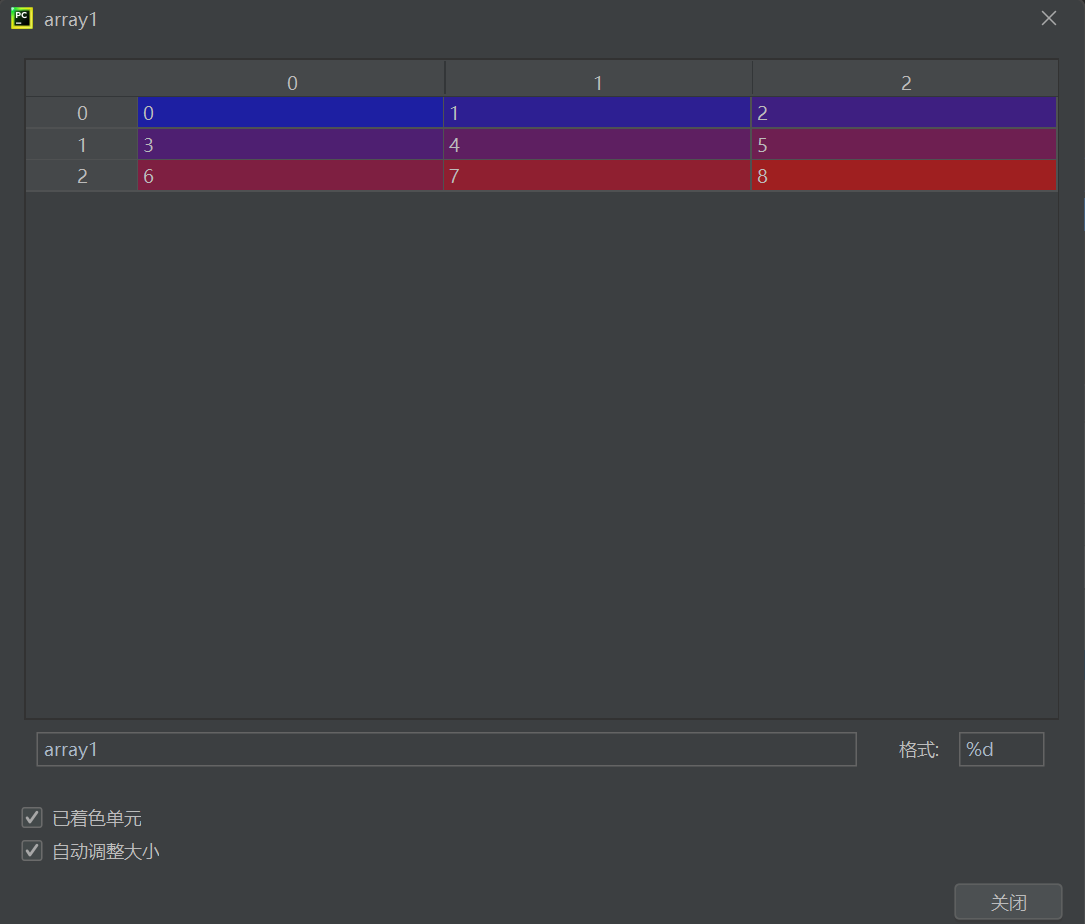
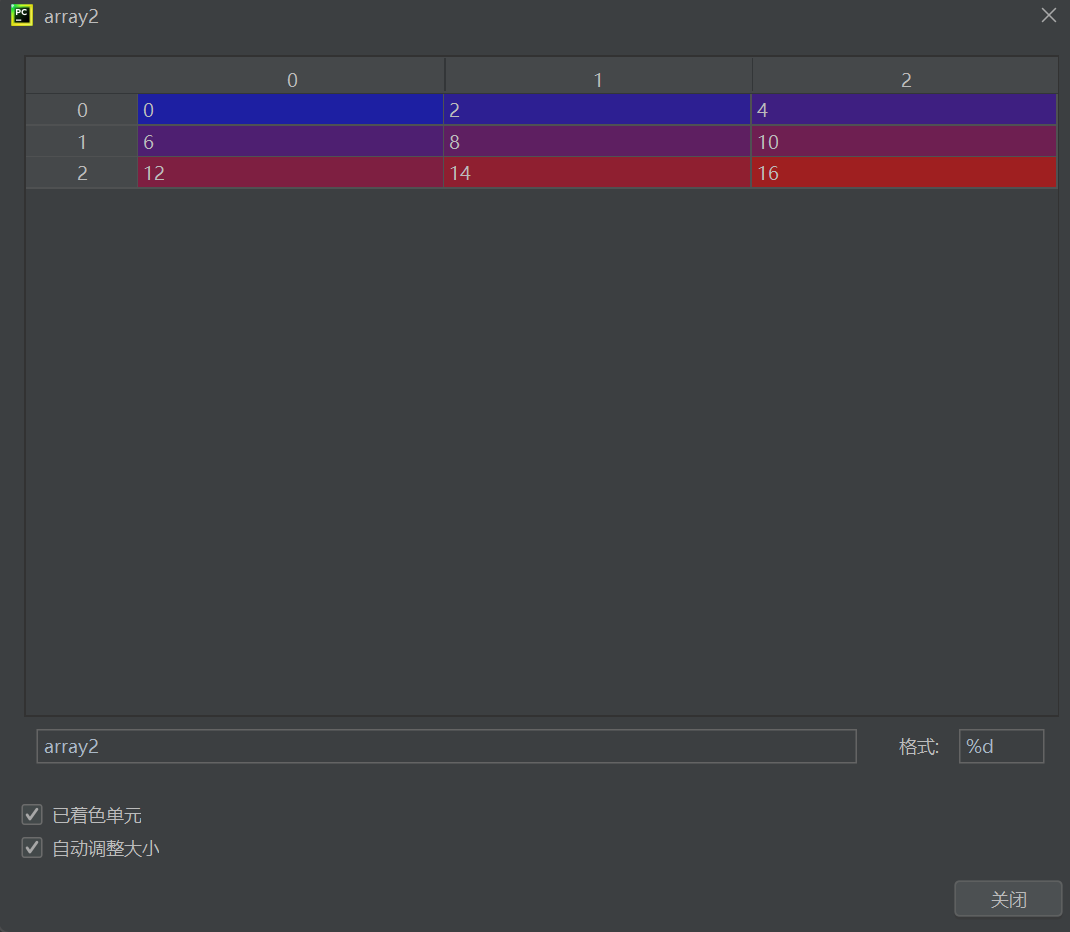
array1 = np.arange(9).reshape(3,3) # 生成3x3矩陣 [[0,1,2],[3,4,5],[6,7,8]] array2 = 2 * array1 # 逐元素乘以2 → [[0,2,4],[6,8,10],[12,14,16]] 關鍵操作:
np.arange(9):生成0~8的一維數組.reshape(3,3):重塑為3行3列的二維數組2 * array1:利用廣播機制對每個元素進行標量乘法
二、水平組合(橫向拼接)
np.hstack()?與?np.concatenate(axis=1)
功能:將多個數組沿列方向(水平)拼接
示例:
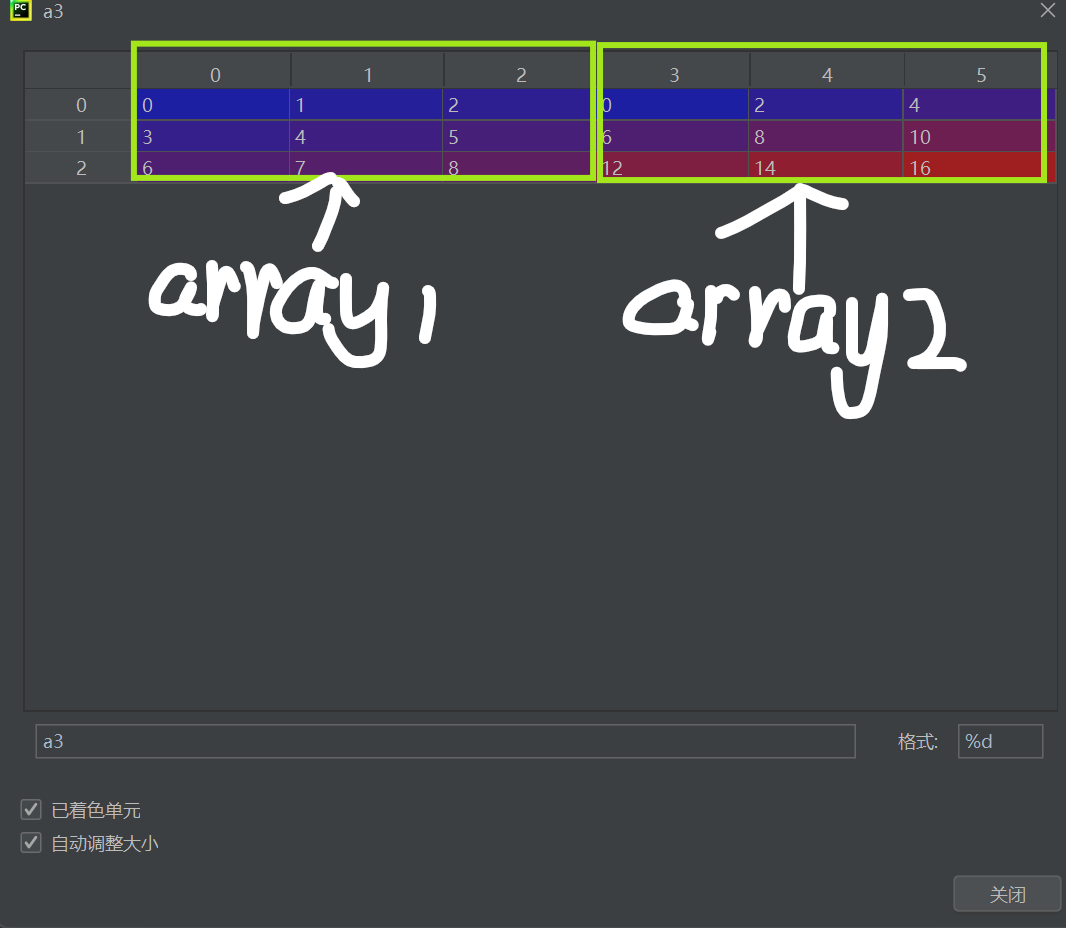
a3 = np.hstack((array1, array2)) # 拼接后形狀: 3x6 a4 = np.hstack((array2, array1)) # 交換順序拼接 a5 = np.hstack((array1, array2, array1)) # 連續拼接三個數組 a6 = np.concatenate((array1, array2), axis=1) # 等價于hstack特點:
hstack:專門用于水平拼接,自動按列對齊concatenate(axis=1):通過指定軸實現相同效果,靈活性更高
三、垂直組合(縱向拼接)
np.vstack()?與?np.concatenate(axis=0)
功能:將多個數組沿行方向(垂直)拼接
- 示例:
a7 = np.vstack((array2, array1)) # 拼接后形狀: 6x3 a8 = np.concatenate((array1, array2), axis=0) # 等價于vstack 特點:
vstack:專門用于垂直拼接,自動按行對齊concatenate(axis=0):通過指定軸實現相同效果,適用于多數組拼接
關鍵區別總結:
| 操作類型 | 語法示例 | 拼接方向 | 維度變化 | 適用場景 |
|---|---|---|---|---|
np.hstack() | hstack((A, B)) | 水平 | 列數相加 | 合并同類特征的不同樣本 |
concatenate(axis=1) | concatenate((A,B), axis=1) | 水平 | 同上 | 更靈活的多數組拼接 |
np.vstack() | vstack((A, B)) | 垂直 | 行數相加 | 堆疊不同樣本的數據 |
concatenate(axis=0) | concatenate((A,B), axis=0) | 垂直 | 同上 | 更靈活的多數組拼接 |
示例代碼:
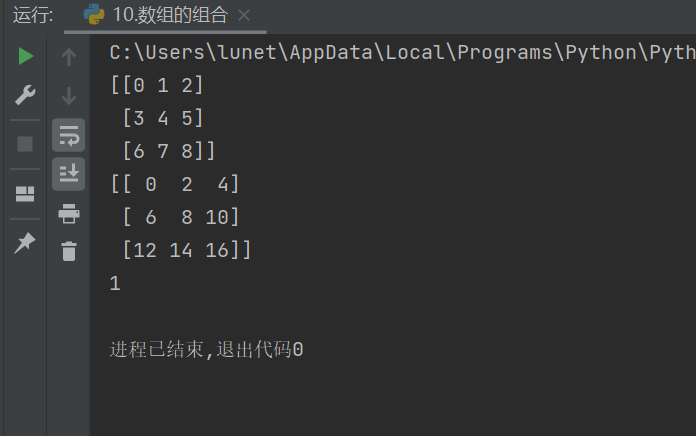
import numpy as np#生成基數組
array1 = np.arange(9).reshape(3,3)
array2 = 2*array1
print(array1)
print(array2)#水平組合
a3 = np.hstack((array1,array2))#水平方向變長
a4 = np.hstack((array2,array1))
a5 = np.hstack((array1,array2,array1))a6 = np.concatenate((array1,array2),axis=1)#1為水平組合,0為垂直組合#垂直組合
a7 = np.vstack((array2,array1))a8 = np.concatenate((array1,array2),axis=0)
print(1)
(十二)numpy內數組元素的切割
核心功能:
一、創建基礎數組
np.arange().reshape()
功能:生成連續數值并重塑為指定形狀的二維數組
示例:
array1 = np.arange(16).reshape(4,4) # 生成4x4矩陣 [[0,1,2,3],[4,5,6,7],...] print(array1)關鍵點:
np.arange(16)?生成0~15的一維數組,.reshape(4,4)?將其重塑為4行4列的二維數組
二、等分切割(嚴格均分)
1.?水平切割(沿列方向)
方法1:
np.hsplit(array, n)功能:將數組沿水平方向(列)均分為?
n?等份示例:
a = np.hsplit(array1, 2)?→ 將4列均分為2份,每份2列,返回兩個形狀為?(4,2)?的子數組
方法2:
np.split(array, n, axis=1)功能:與?
hsplit?等價,通過?axis=1?明確指定列方向示例:
b = np.split(array1, 2, axis=1)?→ 結果同?a
2.?垂直切割(沿行方向)
方法1:
np.vsplit(array, n)功能:將數組沿垂直方向(行)均分為?
n?等份示例:
c = np.vsplit(array1, 2)?→ 將4行均分為2份,每份2行,返回兩個形狀為?(2,4)?的子數組
方法2:
np.split(array, n, axis=0)功能:與?
vsplit?等價,通過?axis=0?明確指定行方向示例:
d = np.split(array1, 2, axis=0)?→ 結果同?c
三、強制切割(允許不等分)
1.?水平強制切割
函數:
np.array_split(array, n, axis=1)功能:將數組沿水平方向(列)強制分為?
n?份,允許不等分示例:
e = np.array_split(array1, 3, axis=1)?→ 將4列分為3份,前兩份各2列,最后一份0列(實際為2列,因余數分配)特點:若無法均分,余數會分配到前面的塊中
2.?垂直強制切割
函數:
np.array_split(array, n, axis=0)功能:將數組沿垂直方向(行)強制分為?
n?份,允許不等分示例:
f = np.array_split(array1, 3, axis=0)?→ 將4行分為3份,前兩塊各2行,最后一塊0行(實際為0行,但此處無意義)
四、非均勻數組的強制切割
示例:5x5數組的切割
代碼:
array1 = np.arange(25).reshape(5,5) # 5x5矩陣 g = np.array_split(array1, 3, axis=1) # 水平切分為3份 h = np.array_split(array1, 3, axis=0) # 垂直切分為3份特點:
水平切割:5列分為3份 → 前兩塊各2列,最后一塊1列
垂直切割:5行分為3份 → 前兩塊各2行,最后一塊1行
關鍵區別總結:
| 函數 | 是否允許不等分 | 切割方向 | 適用場景 |
|---|---|---|---|
np.hsplit() | 否 | 水平 | 嚴格均分列 |
np.vsplit() | 否 | 垂直 | 嚴格均分行 |
np.split(axis=1) | 否 | 水平 | 同?hsplit |
np.split(axis=0) | 否 | 垂直 | 同?vsplit |
np.array_split() | 是 | 任意 | 需處理不等分場景(如數據不足) |
代碼示例:
import numpy as nparray1 = np.arange(16).reshape(4,4)
print(array1)#水平切割
a = np.hsplit(array1,2)#其中第二個參數2,表示將矩陣array1進行2等份的切分
print(a)b = np.split(array1,2,axis=1)#垂直切割
c = np.vsplit(array1,2)
d = np.split(array1,2,axis=0)#強制切割
#水平切割
e = np.array_split(array1,3,axis=1)#垂直切割
f = np.array_split(array1,3,axis=0)###########################################
array1 = np.arange(25).reshape(5,5)
print(array1)g = np.array_split(array1,3,axis=1)h = np.array_split(array1,3,axis=0)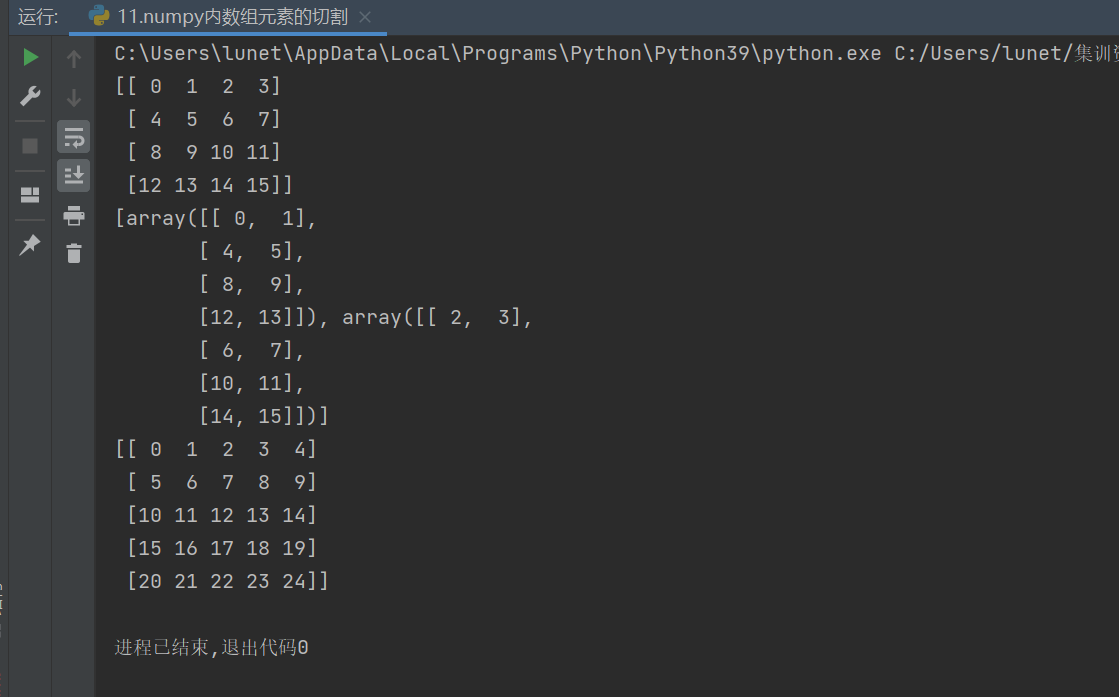
(十三)數組的算數運算
核心功能:
一、創建基礎數組
np.arange().reshape()
功能:生成指定范圍內的等差數列并重塑為指定形狀的數組
示例:
array1 = np.arange(1,5,1).reshape(2,2) # 生成 [[1,2],[3,4]]關鍵參數:
np.arange(1,5,1):起始值=1,終止值=5(不含),步長=1 → 生成?[1,2,3,4].reshape(2,2):將一維數組重塑為2行2列的二維數組
標量乘法生成新數組
功能:通過標量乘法快速生成關聯數組
示例:
array2 = 2 * array1 # 每個元素乘以2 → [[2,4],[6,8]]特點:利用 NumPy 的廣播機制,標量自動擴展至與數組同形
二、逐元素數學運算
1.?加法?+
功能:對應位置元素相加
示例:
print(array1 + array2) # 輸出: [[3,6],[9,12]]計算邏輯:
1+2=3,?2+4=6,?3+6=9,?4+8=12
2.?減法?-
功能:對應位置元素相減
示例:
print(array1 - array2) # 輸出: [[-1,-2],[-3,-4]]計算邏輯:
1-2=-1,?2-4=-2,?3-6=-3,?4-8=-4
3.?乘法?*
功能:對應位置元素相乘
示例:
print(array1 * array2) # 輸出: [[2,8],[18,32]]計算邏輯:
1×2=2,?2×4=8,?3×6=18,?4×8=32
4.?除法?/
功能:對應位置元素相除
示例:
print(array1 / array2) # 輸出: [[0.5,0.5],[0.5,0.5]]計算邏輯:
1/2=0.5,?2/4=0.5,?3/6=0.5,?4/8=0.5
5.?取余?%
功能:對應位置元素取余數
示例:
print(array2 % array1) # 輸出: [[0,0],[0,0]]計算邏輯:
2%1=0,?4%2=0,?6%3=0,?8%4=0
6.?整除?//
功能:對應位置元素整除(向下取整)
示例:
print(array1 // array2) # 輸出: [[0,0],[0,0]]計算邏輯:
1//2=0,?2//4=0,?3//6=0,?4//8=0
示例代碼:
import numpy as nparray1 = np.arange(1,5,1).reshape(2,2)
array2 = 2*array1
print(array1)
print(array2)#數組的加法【對應位置的元素求和】
print(array1 + array2)#數組的減法[對應位置元素相減]
print(array1 - array2)#數組的乘法【對應位置相乘】
print(array1 * array2)#數組的除法[對應位置相除]
print(array1 / array2)#數組的取余(%)
print(array2 % array1)#數組的取整
print(array1 // array2)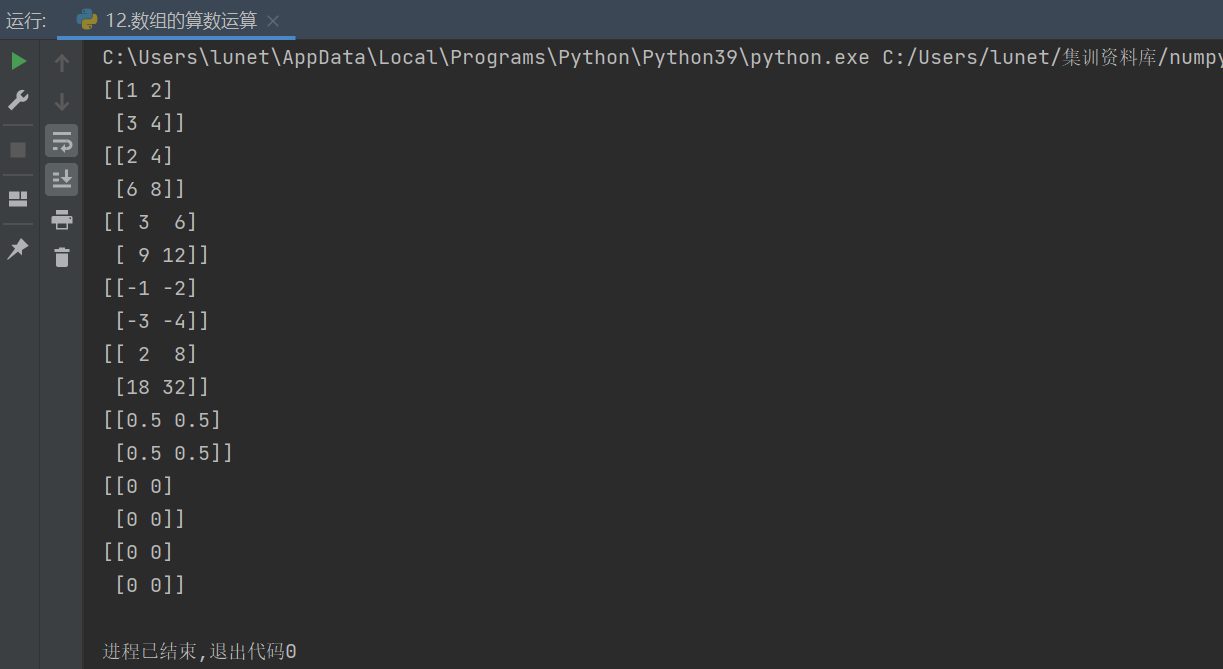
(十四)數組的深拷貝與淺拷貝
?NumPy 中淺拷貝與深拷貝的本質區別:
- 淺拷貝:通過直接賦值實現,新舊數組共享內存,修改其一會影響另一者。
- 深拷貝:通過?
.copy()?方法創建獨立副本,修改副本不影響原數組
核心功能:
1.?創建原始數組
array1 = np.array([1,2,3]) # 創建一維數組 [1,2,3]
- 作用:初始化一個包含?
[1,2,3]?的 NumPy 數組
2.?淺拷貝(引用賦值)
array2 = array1 # 淺拷貝:僅傳遞引用
- 本質:
array2?和?array1?共享同一塊內存,修改任一變量會影響另一個 - 驗證:
array2[0] = 100 # 修改 array2 的第一個元素 print(array2) # 輸出: [100, 2, 3] print(array1) # 輸出: [100, 2, 3] ← 原數組也被修改! - 結論:淺拷貝不安全,對副本的修改會直接影響原數組
3.?深拷貝(獨立副本)
array3 = array1.copy() # 深拷貝:創建獨立副本
- 本質:
array3?是?array1?的完全獨立副本,擁有獨立內存空間 - 驗證:
array3[0] = 10 # 修改 array3 的第一個元素 print(array3) # 輸出: [10, 2, 3] print(array1) # 輸出: [1, 2, 3] ← 原數組未被修改! - 結論:深拷貝安全,對副本的修改不影響原數組
關鍵區別總結:
| 操作 | 內存機制 | 修改影響 | 適用場景 |
|---|---|---|---|
| 淺拷貝 | 共享原數組內存 | ?修改副本 → 影響原數組 | 無需保留原數據時(需謹慎使用) |
| 深拷貝 | 創建獨立內存 | ?修改副本 → 不影響原數組 | 需保留原數據時(推薦使用) |
示例代碼:
import numpy as nparray1 = np.array([1,2,3])
#淺拷貝
array2 = array1#更改array2的元素的值
array2[0] = 100
print(array2)
print("#####################")
print(array1)#深拷貝
array3 = array1.copy()
array3[0] = 10
print(array3)
print("##################")
print(array1)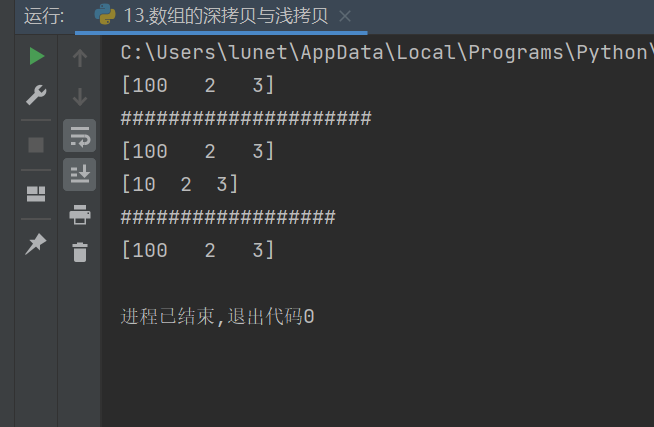
(十五)numpy內的隨機模塊兒(一)
核心功能:
1.?導入依賴庫
import numpy as np
import matplotlib.pyplot as plt
作用:引入 NumPy(高效數值計算)和 Matplotlib(數據可視化)庫
2.?設置隨機種子
np.random.seed(1000) # 固定隨機種子以保證結果可復現
關鍵作用:鎖定隨機數生成器的初始狀態,使后續所有隨機操作的結果在多次運行中保持一致(便于調試和驗證)
3.?生成單個隨機整數
r1 = np.random.randint(0, 10) # 左閉右開區間 [0, 10)
print(r1)
功能:從?
[0, 10)?的左閉右開區間內隨機抽取一個整數示例輸出:若種子為1000,則固定輸出?
8(可通過多次運行驗證)
4.?生成隨機數組
a = []
for i in range(10):a0 = np.random.randint(0, 10) # 每次獨立生成一個隨機整數a.append(a0)
print(a)
功能:循環10次,每次生成一個?
[0, 10)?范圍內的隨機整數,存入列表?a特點:由于已設置隨機種子,即使重啟程序,只要種子不變,生成的序列也完全相同
示例輸出:
[8, 7, 9, 5, 8, 7, 6, 8, 5, 7](種子1000下的固定結果)
5.?繪制直方圖
a = []
for i in range(10):a0 = np.random.randint(0, 10) # 每次獨立生成一個隨機整數a.append(a0)
print(a)
功能:統計列表?
a?中各數值的出現頻率,并以柱狀圖形式可視化參數說明:
color='r':設置柱子顏色為紅色plt.show():渲染并顯示圖像窗口
預期效果:展示10個隨機數在?
[0, 10)?區間內的分布情況(因樣本量較小,可能呈現非完美均勻分布)
示例代碼:
import numpy as np
import matplotlib.pyplot as plt
"""
randint(start,end):
產生一個隨機整數
(0,10) ->左閉右開的區間
"""
#隨機種子
np.random.seed(1000)#矩陣類型隨機
r1 = np.random.randint(0,10)
print(r1)#
a = []
for i in range(10):a0 = np.random.randint(0,10)a.append(a0)
print(a)
plt.hist(a,color='r')
plt.show()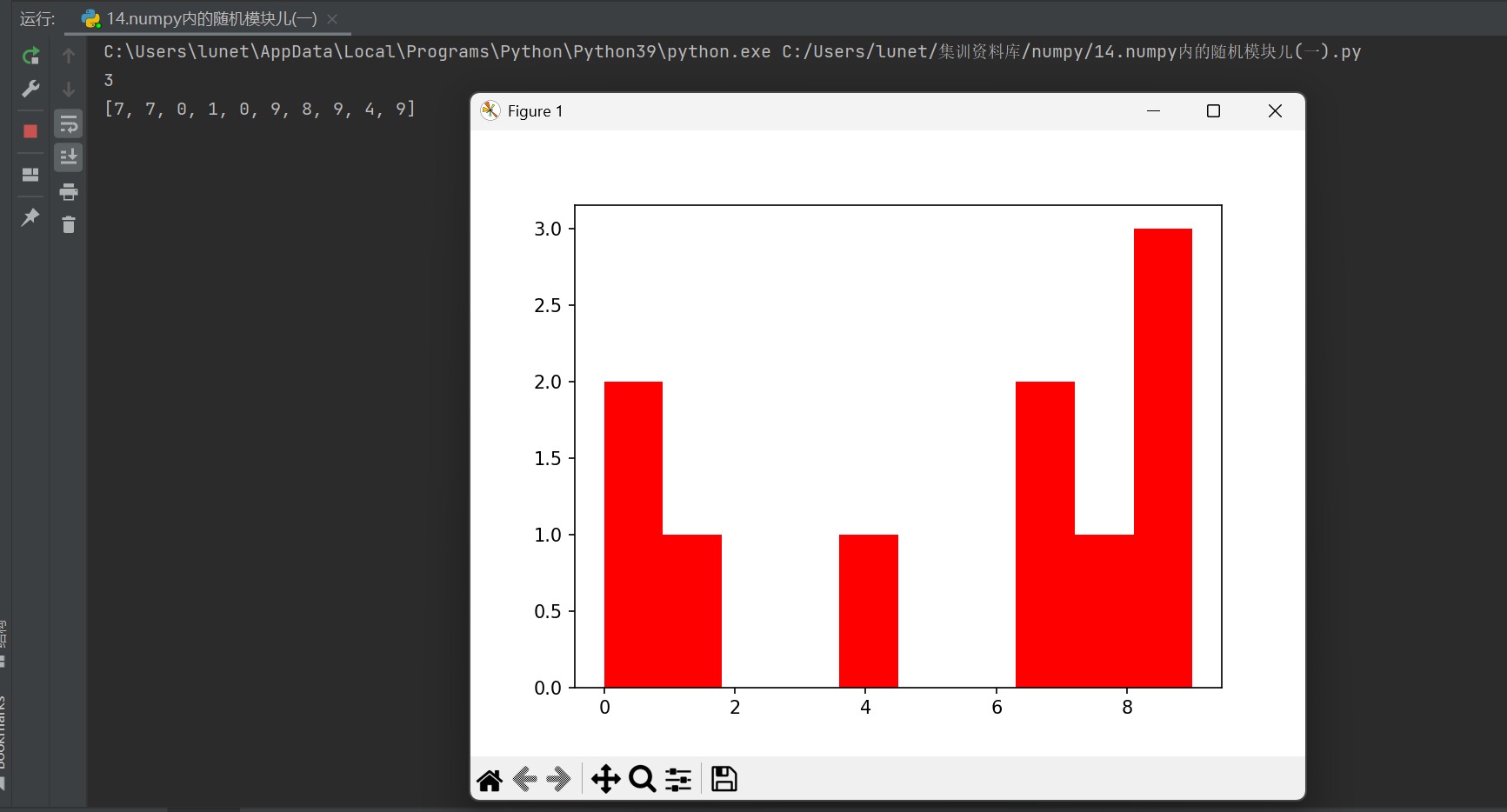
(十六)numpy內的隨機模塊兒(二)
核心功能:
1.?單次隨機浮點數?np.random.rand()
r1 = np.random.rand() # 生成 [0,1) 區間內的隨機浮點數
print(r1)功能:返回一個服從?均勻分布?的隨機浮點數,取值范圍?
[0, 1)特點:無參數,適用于簡單隨機采樣場景
示例輸出:如?
0.7892(每次運行不同)
2.?標準正態分布隨機數?np.random.normal()
r1 = np.random.rand() # 生成 [0,1) 區間內的隨機浮點數
print(r1)
功能:從?標準正態分布(均值 μ=0,標準差 σ=1)中抽取一個樣本
擴展性:可通過參數調整均值和標準差(見后續示例)
示例輸出:如?
1.2345(可能為負值)
3.?生成隨機整數矩陣?np.random.randint()
r3 = np.random.randint(0, 10, size=(5,5)) # 生成 5x5 的 [0,10) 區間內隨機整數矩陣
print(r3)
功能:創建指定形狀的整數矩陣,元素取自?
[low, high)?區間關鍵參數:
low=0,?high=10:左閉右開區間size=(5,5):輸出形狀為 5 行 5 列
示例輸出:
[[3 7 9 1 5][8 2 6 4 0]...]
4.?生成均勻分布浮點矩陣?np.random.rand()
r4 = np.random.rand(5,5) # 生成 5x5 的 [0,1) 區間內隨機浮點矩陣
print(r4)
功能:創建指定形狀的浮點數矩陣,元素服從?
[0,1)?均勻分布優勢:比循環更高效,直接生成多維數組
示例輸出:全為?
0~1?之間的浮點數
5.?生成自定義正態分布矩陣?np.random.normal()
r5 = np.random.normal(5, 10, size=(5,5)) # 生成均值 μ=5,標準差 σ=10 的正態分布矩陣
print(r5)
功能:創建指定形狀的正態分布矩陣,可自定義均值和標準差
參數說明:
loc=5:均值 μscale=10:標準差 σsize=(5,5):輸出形狀
示例輸出:大部分值集中在?
5 ± 3×10?范圍內(約?-25 ~ 35)
關鍵區別總結:
| 函數 | 分布類型 | 取值范圍 | 典型用途 |
|---|---|---|---|
np.random.rand() | 均勻分布 | [0, 1) | 簡單隨機采樣、初始化權重 |
np.random.normal() | 正態分布 | (-∞, +∞) | 模擬自然現象、噪聲添加 |
np.random.randint() | 離散均勻分布 | [low, high) | 生成隨機索引、分類標簽 |
np.random.rand() | 連續均勻分布 | [0, 1) | 快速生成多維隨機浮點矩陣 |
np.random.normal() | 自定義正態分布 | (μ - kσ, μ + kσ) | 數據增強、蒙特卡洛模擬 |
示例代碼:
import numpy as np"""
rand() ->(0,1)之間的隨機浮點數
"""
#np.random.seed(100)
r1 = np.random.rand()
print(r1)"""
normal() ->生成一些符合正態分布的數據
N~(0,1)
"""
r2 = np.random.normal()
print(r2)
#################################
#生成隨機數矩陣r3 = np.random.randint(0,10,size=(5,5))
print(r3)r4 = np.random.rand(5,5)
print(r4)r5 = np.random.normal(5,10,size=(5,5))
print(r5)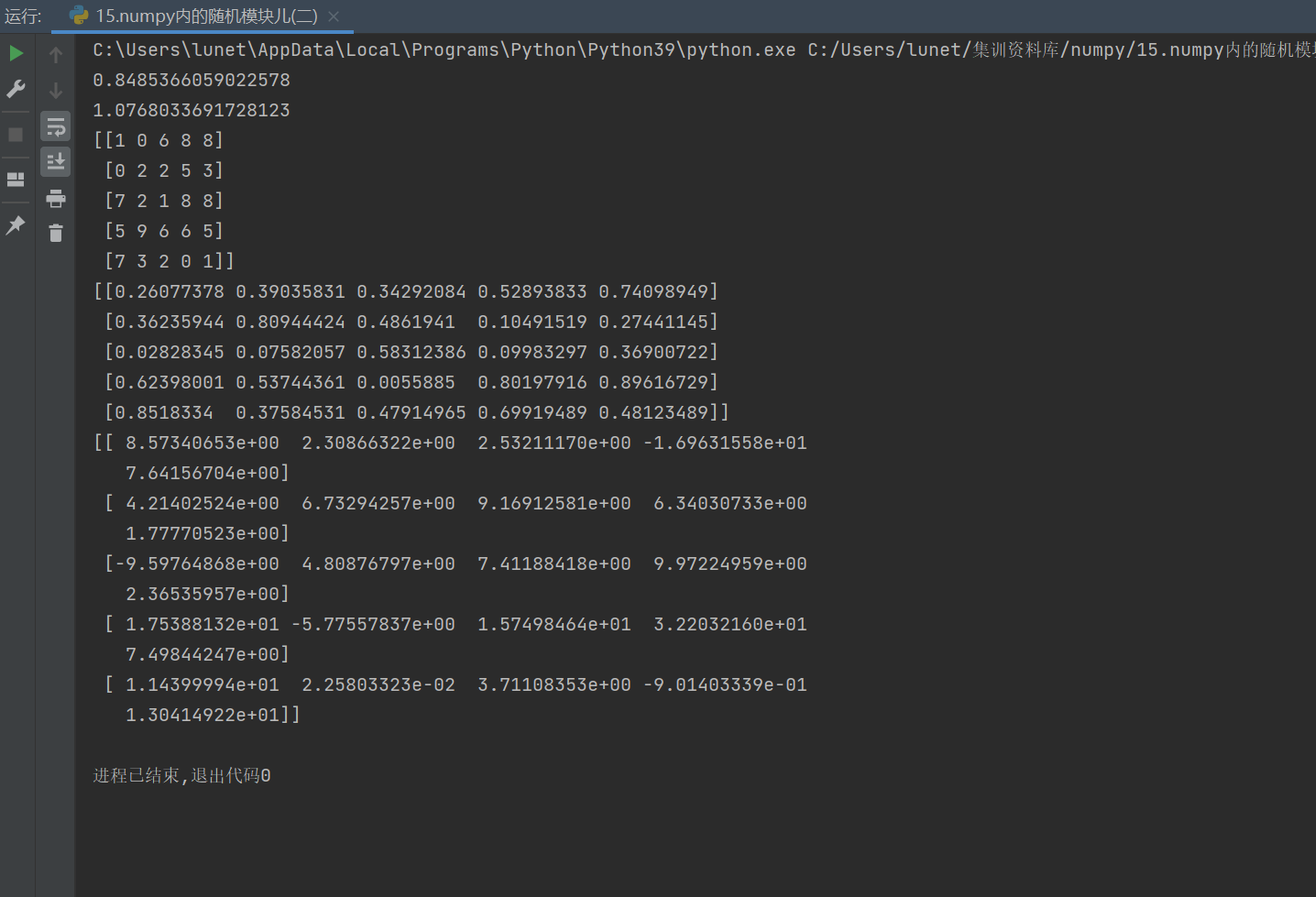
(十七)numpy內一些函數的使用
核心功能:
1.?生成正態分布隨機矩陣
array1 = np.random.normal(size=(3,3)) # 生成3x3的正態分布隨機矩陣
print(array1)
功能:創建一個形狀為?
(3,3)?的二維數組,其中每個元素獨立采樣自標準正態分布(默認均值 μ=0,標準差 σ=1)特點:無需顯式指定均值和標準差時,默認使用標準正態分布;若需自定義參數可添加?
loc(均值)和?scale(標準差)參數示例輸出:類似如下結構(具體數值因隨機性不同):
[[ 0.4967 1.5292 -0.0769][ 0.2784 0.8655 1.2064][-0.4052 0.1763 0.7658]]
2.?基礎統計量計算
# 求方差
print(array1.var()) # 全局方差(所有元素的方差)# 求標準差
a = array1.std() # 全局標準差# 求均值
b = array1.mean() # 全局均值# 求和
c = array1.sum() # 所有元素的總和# 求中位數
d = np.median(array1) # 全局中位數
關鍵函數:
var():計算數組所有元素的方差(衡量數據離散程度)std():計算標準差(方差的平方根,更直觀反映波動幅度)mean():計算算術平均值(數據的中心趨勢)sum():對所有元素求和np.median():計算中位數(排序后中間值,抗異常值干擾)
注意:直接調用?
array1.median()?會報錯,需使用?np.median(array1)
3.?按行/列求和
# 對矩陣的行求和(axis=1)
e = array1.sum(axis=1) # 每行元素相加,結果為長度為3的一維數組# 對矩陣的列進行求和(axis=0)
f = array1.sum(axis=0) # 每列元素相加,結果為長度為3的一維數組
axis?參數含義:axis=1:沿行方向求和(壓縮行維度,保留列維度)axis=0:沿列方向求和(壓縮列維度,保留行維度)
示例輸出:
e:每行的總和,如?[1.9489, 2.2793, 0.5369]f:每列的總和,如?[0.3699, 2.5710, 1.8953]
關鍵概念總結:
| 操作 | 功能描述 | 返回值類型 | 典型用途 |
|---|---|---|---|
np.random.normal() | 生成正態分布隨機數 | ndarray | 模擬自然現象、初始化權重 |
var() | 計算全局方差 | float | 評估數據離散程度 |
std() | 計算全局標準差 | float | 衡量數據波動范圍 |
mean() | 計算全局均值 | float | 獲取數據平均水平 |
sum() | 所有元素求和 | float | 快速累加總和 |
np.median() | 計算全局中位數 | float | 避免極端值影響的中心度量 |
sum(axis=1) | 按行求和 | 1D array | 分析每行數據的總效應 |
sum(axis=0) | 按列求和 | 1D array | 分析每列數據的總效應 |
代碼示例:
import numpy as nparray1 = np.random.normal(size = (3,3))
print(array1)#一些函數
#求方差
print(array1.var())#求標準差
a = array1.std()#求均值
b = array1.mean()#求和
c = array1.sum()#求中位數
#array1.median()
d = np.median(array1)#求和運算
#對矩陣的行求和
e = array1.sum(axis=1)
#對矩陣的列進行求和
f = array1.sum(axis=0)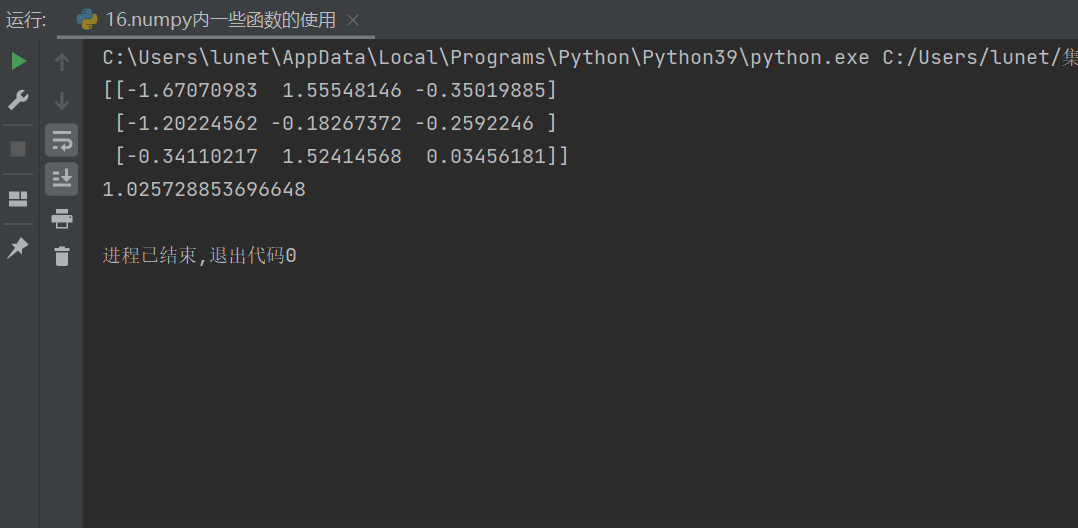
(十八)矩陣的運算
核心功能:
1.?生成基數組
a = np.arange(4).reshape(2,2) # 創建2x2矩陣 [[0,1],[2,3]]
b = a.copy() # 深拷貝生成獨立副本
np.arange(4):生成一維數組?[0,1,2,3].reshape(2,2):將一維數組重塑為 2 行 2 列的二維矩陣copy():創建深拷貝,確保?b?與?a?獨立(修改?b?不影響?a)
2.?矩陣乘法
a1 = a.dot(b) # 方法1:通過 .dot() 計算矩陣乘積
a2 = np.dot(a, b) # 方法2:通過 np.dot() 計算矩陣乘積
功能:計算兩個 2x2 矩陣的標準矩陣乘積(行列對應相乘再求和)
等價性:兩種方法結果相同,均返回新的 2x2 矩陣
數學公式:若?
A=[[a,b],[c,d]],?B=[[e,f],[g,h]],則?AB=[[ae+bg, af+bh], [ce+dg, cf+dh]]
3.?矩陣求逆
a3 = np.linalg.inv(a) # 計算矩陣 a 的逆矩陣
前提:僅當矩陣滿秩且行列式不為零時存在逆矩陣
作用:若?
a?可逆,則?a @ a3 == I(單位矩陣),用于求解線性方程組或反轉變換風險提示:若矩陣不可逆(如奇異矩陣),會拋出?
LinAlgError
4.?自定義矩陣乘法
a4 = a.dot([[-1.5, 0.5], [1. , 0. ]]) # 手動指定第二個矩陣進行乘法
print(a4)
功能:將原始矩陣?
a?與預定義的 2x2 矩陣相乘,模擬線性變換應用場景:此類操作常見于圖像處理(仿射變換)、機器學習特征轉換等場景
輸出示例:假設?
a=[[0,1],[2,3]],則計算過程為:第一行:
0*(-1.5)+1*1=1,?0*0.5+1*0=0?→?[1, 0]第二行:
2*(-1.5)+3*1=-3+3=0,?2*0.5+3*0=1?→?[0, 1]最終結果:
[[1, 0], [0, 1]](單位矩陣)
關鍵概念總結:
| 操作 | 功能描述 | 注意事項 |
|---|---|---|
np.arange().reshape() | 創建指定形狀的初始化矩陣 | 默認按行優先填充數據 |
.copy() | 生成深拷貝,避免共享內存 | 修改副本不影響原數組 |
.dot()?/?np.dot() | 計算矩陣乘積 | 要求矩陣維度匹配(前導矩陣列數=后繼行數) |
np.linalg.inv() | 計算矩陣的逆 | 僅適用于非奇異矩陣(行列式≠0) |
| 自定義矩陣乘法 | 實現線性變換或復合操作 | 可用于驗證變換效果或設計特定算法 |
示例代碼:
import numpy as np#生成兩個基數組
a = np.arange(4).reshape(2,2)
b = a.copy()#矩陣的運算
#加減乘除(求逆)
#加減 ->對應元素加減#矩陣的乘法【點乘】
#a * b
a1 = a.dot(b)
a2 = np.dot(a,b)#矩陣求逆
"""
inv():
并不是所有的矩陣都有逆;
即使你沒有逆,給你一個逆【偽逆】
"""
a3 = np.linalg.inv(a)a4 = a.dot([[-1.5, 0.5],[ 1. , 0. ]])
print(a4)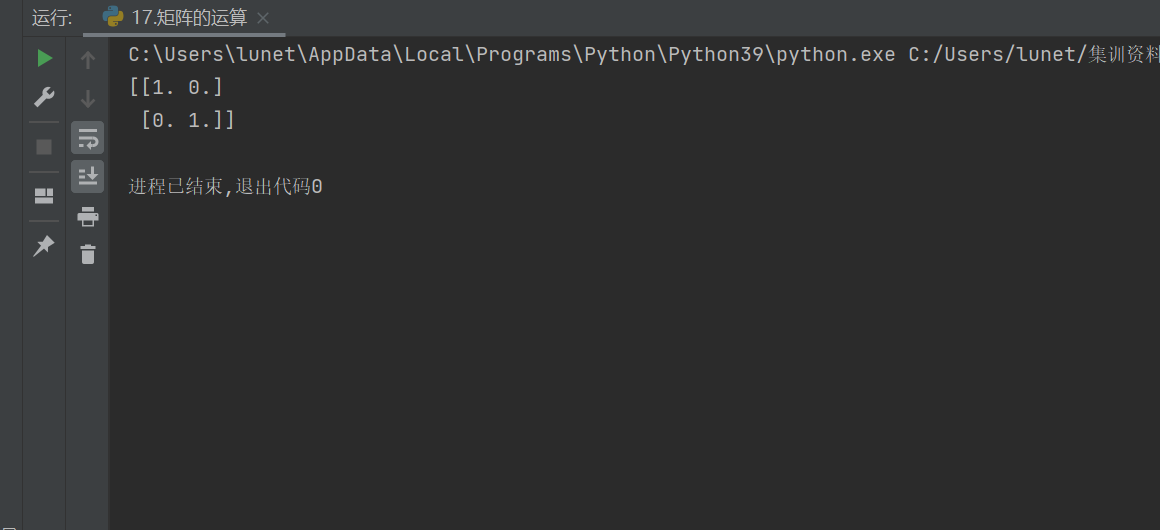
(十九)讀取文件
核心功能:
一、np.loadtxt()?- 從文本文件加載數據
核心功能
?高效讀取結構化文本數據:將純文本文件中的數值數據快速轉換為 NumPy 數組
靈活處理分隔符:支持通過?delimiter?參數自定義列分隔符(如?\t、,、空格等)
自動適配行列結構:假設文件中每一行的數值數量相同,按順序填充到數組的行與列中
代碼示例 & 關鍵參數
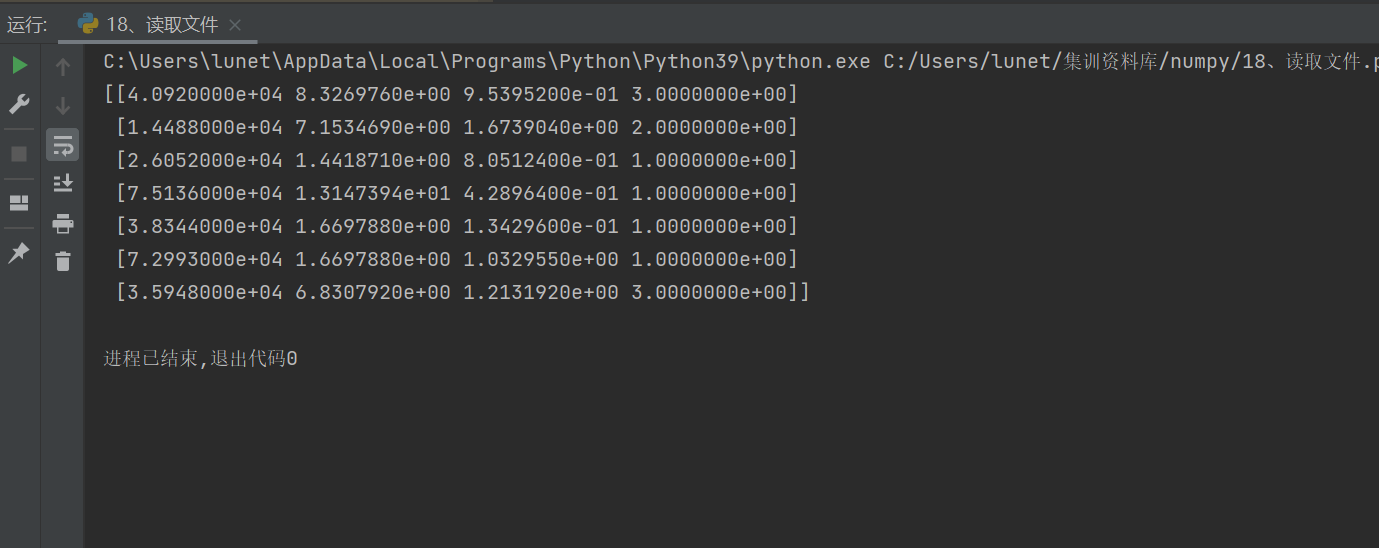
data = np.loadtxt('文件讀取.txt', delimiter='\t') # 若為CSV文件則用 delimiter=','
print(data)
delimiter: 定義字段分隔符(默認為任意空白字符)- 適用場景:讀取傳感器日志、CSV/TSV格式數據、科學計算輸入文件等
典型應用
# 假設文件內容如下(制表符分隔):
# 1 2 3
# 4 5 6
# 7 8 9# 執行后 data 變為:
array([[1, 2, 3],[4, 5, 6],[7, 8, 9]])
二、np.savetxt()?- 將數組保存到文本文件
核心功能
?反向操作:將 NumPy 數組以純文本形式持久化存儲
人性化輸出:默認以固定寬度排版,便于閱讀;可通過?fmt?參數定制數值格式
跨平臺兼容:生成標準文本文件,無需依賴特定二進制格式
代碼示例 & 關鍵參數
array = np.array([[1, 2, 3], [4, 5, 6], [7, 8, 9]])
np.savetxt('array.txt', array) # 默認用空白分隔
- 擴展性:可添加?
fmt='%d'(整數)、delimiter=', '(逗號分隔)等參數 - 適用場景:導出模型預測結果、調試中間變量、與其他工具交換數據
典型輸出文件內容
1.00000000e+00 2.00000000e+00 3.00000000e+00
4.00000000e+00 5.00000000e+00 6.00000000e+00
7.00000000e+00 8.00000000e+00 9.00000000e+00對比總結:
| 功能 | np.loadtxt() | np.savetxt() |
|---|---|---|
| 方向 | 文件 → 內存(讀取) | 內存 → 文件(寫入) |
| 核心用途 | 加載結構化文本數據 | 導出數組為文本文件 |
| 關鍵參數 | delimiter(解析分隔符) | fmt(控制輸出格式) |
| 數據類型限制 | 僅支持數值型數據 | 自動處理浮點數精度 |
| 典型場景 | 數據分析前序步驟 | 結果可視化/長期存檔 |
示例代碼:
# numpy.loadtxt():從文本文件中加載數據。這個函數假定文件中的每一行都有相同數量的值,并將這些值分隔開。
# 你可以使用 delimiter 參數指定分隔符,如逗號、制表符等。例如:系統的簡單介紹這段代碼的核心功能
data = np.loadtxt('文件讀取.txt', delimiter='\t')#csv格式的文件delimiter=','
print(data)#將數組保存到txt文件中
import numpy as np
array = np.array([[1, 2, 3], [4, 5, 6], [7, 8, 9]])# 創建一個 NumPy 數組
np.savetxt('array.txt', array)# 使用 savetxt() 將數組保存到文本文件中
 :哈希表(Hash Table)中的一個關鍵性能指標)
原理)




Digit Recognizer 手寫數字識別)










:拷貝構造函數與賦值運算符重載深度解析》)

![[ 數據結構 ] 時間和空間復雜度](http://pic.xiahunao.cn/[ 數據結構 ] 時間和空間復雜度)