Digit Recognizer | Kaggle 題面
Digit Recognizer-CNN | Kaggle 下面代碼的kaggle版本
使用CNN進行手寫數字識別
學習到了網絡搭建手法+學習率退火+數據增廣 提高訓練效果。
使用混淆矩陣 以及對分類出錯概率最大的例子單獨拎出來分析。

最終以99.546%正確率 排在 86/1035
1. 數據準備
拆成X和Y 輸出每個數字 train中的數據量
import pandas as pd
import seaborn as sns
train = pd.read_csv("/kaggle/input/digit-recognizer/train.csv")
test = pd.read_csv("/kaggle/input/digit-recognizer/test.csv")
Y_train = train["label"]
X_train = train.drop(labels = ["label"],axis = 1)
del train g = sns.countplot(x=Y_train)
Y_train.value_counts()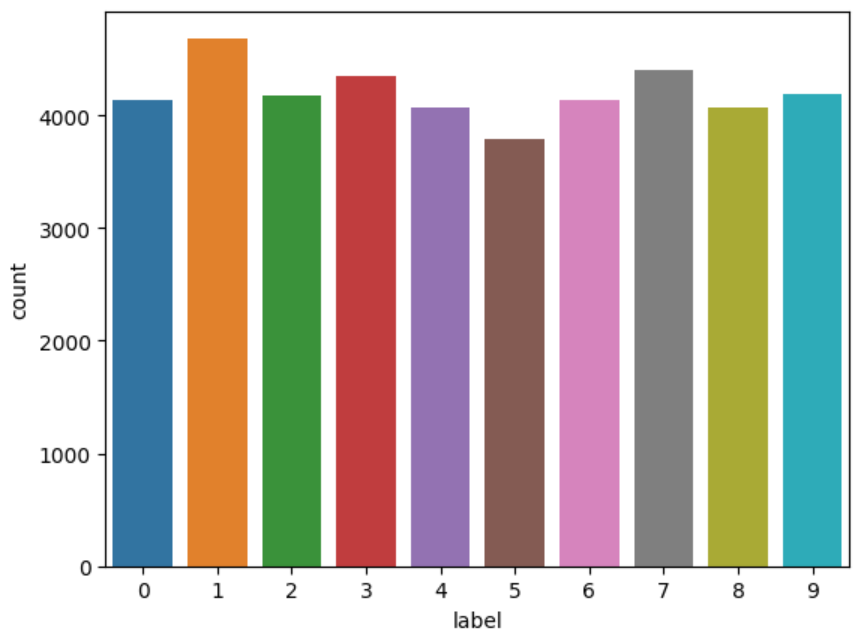
1.確認數據干凈 → 沒有缺失值。
print(X_train.isnull().any().describe()) # 下面代表所有列 都是False
print(test.isnull().any().describe())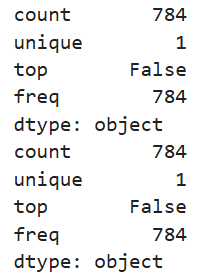
2.灰度歸一化(除以255) → 提升訓練速度和穩定性。
reshape → 轉換成 CNN 所需的 (height, width, channel) 格式。 ?
原來是(樣本數, 784) -> (樣本數, 高度, 寬度, 通道數)? 樣本數, 28, 28, 1
X_train, test = X_train / 255.0, test / 255.0
X_train = X_train.values.reshape(-1, 28, 28, 1)
test = test.values.reshape(-1, 28, 28, 1)3.One-Hot 編碼 只有一個位置為1的標簽 → 后續 softmax 輸出10個類別的概率。
from tensorflow.keras.utils import to_categorical
Y_train = to_categorical(Y_train, num_classes=10)4.劃分驗證集 → 用于調參、防止過擬合。
from sklearn.model_selection import train_test_split
X_train, X_val, Y_train, Y_val = train_test_split(X_train, Y_train, test_size=0.1, random_state=2)5.可視化一個樣本 → 檢查數據是否正確加載。
import matplotlib.pyplot as plt
plt.imshow(X_train[0][:,:,0], cmap='gray')
plt.title("Example Image")
plt.show()
2. CNN模型建構
卷積塊:2個Conv(5 * 5)+ BN + 池化? ? ? ~? ? ?2個Conv(3 * 3) + BN + 池化。
Dropout舍棄一些神經元防止過擬合。
import numpy as np
import tensorflow as tffrom tensorflow.keras.models import Sequential
from tensorflow.keras.layers import Conv2D, MaxPooling2D as MaxPool2D
from tensorflow.keras.layers import Dense, Dropout, Flatten, BatchNormalization
from tensorflow.keras.optimizers import Adam
from tensorflow.keras.callbacks import ReduceLROnPlateau
from tensorflow.keras.preprocessing.image import ImageDataGeneratormodel = Sequential()# 卷積塊 1
model.add(Conv2D(32, (5,5), padding='same', activation='relu', input_shape=(28,28,1)))
model.add(BatchNormalization()) # 批歸一化
model.add(Conv2D(32, (5,5), padding='same', activation='relu'))
model.add(BatchNormalization())
model.add(MaxPool2D(pool_size=(2,2)))
model.add(Dropout(0.25))# 卷積塊 2
model.add(Conv2D(64, (3,3), padding='same', activation='relu'))
model.add(BatchNormalization())
model.add(Conv2D(64, (3,3), padding='same', activation='relu'))
model.add(BatchNormalization())
model.add(MaxPool2D(pool_size=(2,2), strides=(2,2)))
model.add(Dropout(0.25))輸出層:Flatten + Dense + Softmax
model.add(Flatten())
model.add(Dense(256, activation='relu'))
model.add(BatchNormalization())
model.add(Dropout(0.5))
model.add(Dense(10, activation='softmax'))model.compile? ? ?Adam優化器 + 交叉熵損失 + accuracy評估
optimizer = Adam(learning_rate=0.001)model.compile(optimizer=optimizer,loss='categorical_crossentropy',metrics=['accuracy'])學習率退火 若 3 個 epoch 內沒提升,就把 lr 減半
learning_rate_reduction = ReduceLROnPlateau(monitor='val_accuracy', patience=3, verbose=1,factor=0.5, min_lr=1e-5
)數據增廣(ImageDataGenerator) 輕微旋轉、縮放、平移等擴充數據
datagen = ImageDataGenerator(rotation_range=10,zoom_range=0.1,width_shift_range=0.1,height_shift_range=0.1
)訓練 設置 epoch? batch_size? steps
datagen.fit(X_train)# ===== 訓練 =====
epochs = 30
batch_size = 86
steps = int(np.ceil(len(X_train) / batch_size)) # 一次訓練覆蓋所有樣本history = model.fit(datagen.flow(X_train, Y_train, batch_size=batch_size), # 數據增強epochs=epochs,steps_per_epoch=steps, validation_data=(X_val, Y_val), # 驗證數據callbacks=[learning_rate_reduction], # 回調學習率verbose=2 # 每個 epoch 輸出一次
)440/440 - 144s - 327ms/step - accuracy: 0.9950 - loss: 0.0170 - val_accuracy: 0.9957 - val_loss: 0.0134 - learning_rate: 6.2500e-05 Epoch 30/30Epoch 30: ReduceLROnPlateau reducing learning rate to 3.125000148429535e-05. 440/440 - 145s - 329ms/step - accuracy: 0.9952 - loss: 0.0153 - val_accuracy: 0.9955 - val_loss: 0.0141 - learning_rate: 6.2500e-05
這是訓練日志的最后一部分輸出 準確率達到 99.5%
3. 模型評估 evaluation
1. history報告中 訓練集和驗證集的 Loss 和 Accuracy 可視化。
val為驗證,驗證不比訓練差 說明沒有太過擬合。
fig, ax = plt.subplots(2,1)# 繪制訓練集和驗證集的 Loss
ax[0].plot(history.history['loss'], color='b', label="Training loss")
ax[0].plot(history.history['val_loss'], color='r', label="validation loss")
ax[0].legend(loc='best', shadow=True)# 繪制訓練集和驗證集的 Accuracy
ax[1].plot(history.history['accuracy'], color='b', label="Training accuracy")
ax[1].plot(history.history['val_accuracy'], color='r', label="Validation accuracy")
ax[1].legend(loc='best', shadow=True)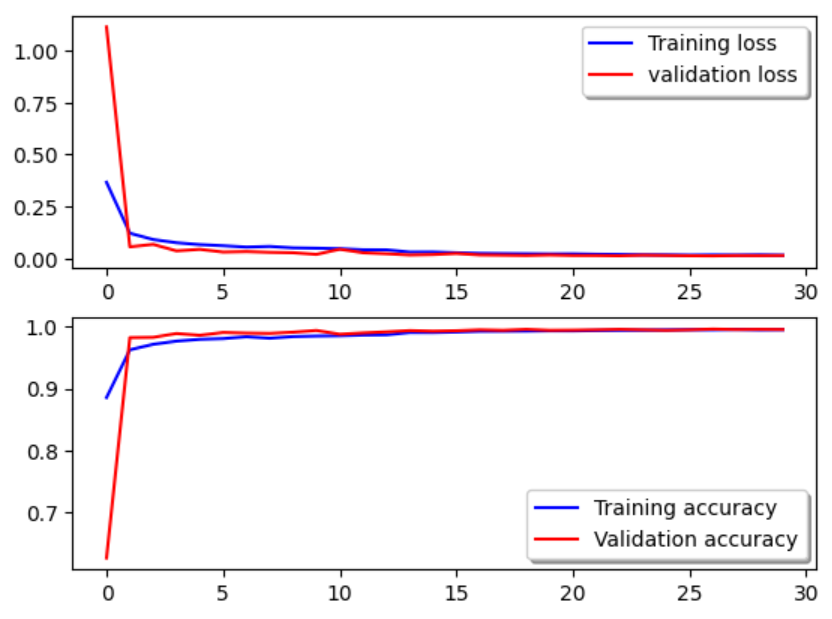
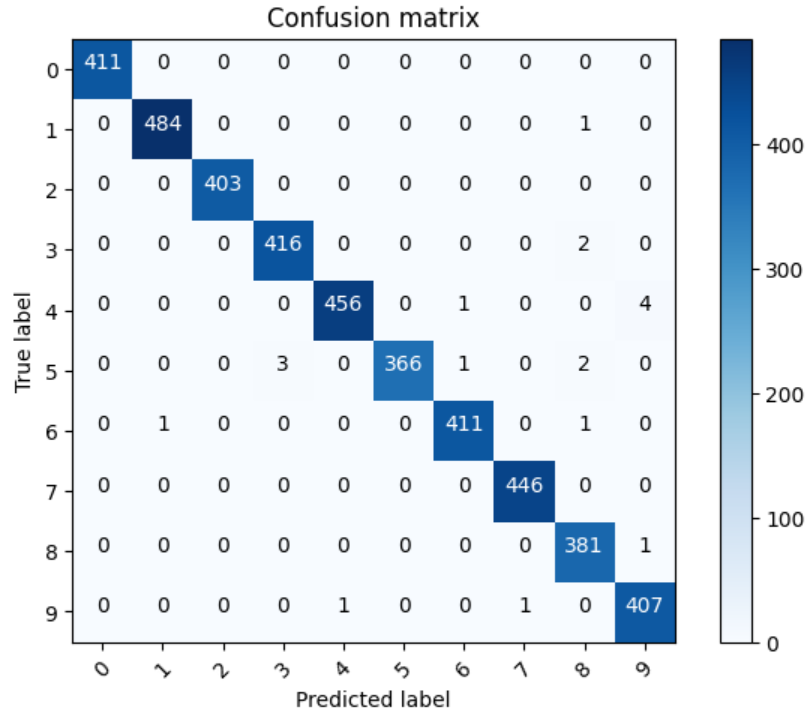
2. 混淆矩陣 confusion_matrix
from sklearn.metrics import confusion_matrix
import itertoolsdef plot_confusion_matrix(cm, classes,normalize=False,title='Confusion matrix',cmap=plt.cm.Blues):plt.imshow(cm, interpolation='nearest', cmap=cmap)plt.title(title)plt.colorbar()tick_marks = np.arange(len(classes))plt.xticks(tick_marks, classes, rotation=45)plt.yticks(tick_marks, classes)if normalize:cm = cm.astype('float') / cm.sum(axis=1)[:, np.newaxis]thresh = cm.max() / 2.for i, j in itertools.product(range(cm.shape[0]), range(cm.shape[1])):plt.text(j, i, cm[i, j],horizontalalignment="center",color="white" if cm[i, j] > thresh else "black")plt.tight_layout()plt.ylabel('True label')plt.xlabel('Predicted label')Y_pred = model.predict(X_val) # 預測值
Y_pred_classes = np.argmax(Y_pred, axis = 1) # 預測對應類別
Y_true = np.argmax(Y_val,axis = 1) # 真實類別confusion_mtx = confusion_matrix(Y_true, Y_pred_classes)
plot_confusion_matrix(confusion_mtx, classes = range(10))
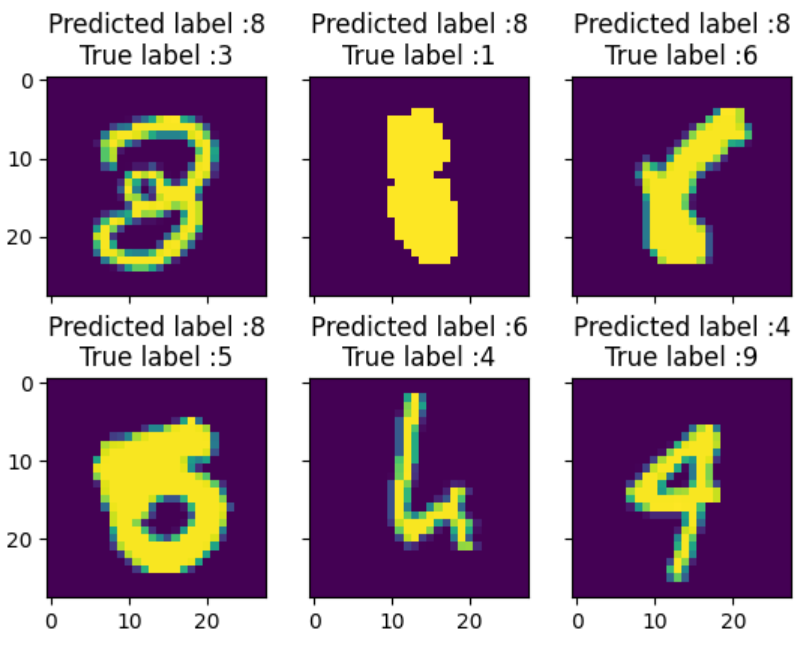
3. 對于分類錯誤的位置 用預測(錯誤數字的概率 - 正確標簽的概率)
輸出預測錯誤差別最大的圖片 是什么樣的。
# 找出預測錯誤的位置 布爾數組
errors = (Y_pred_classes != Y_true )# 提取錯誤預測的詳細數據
Y_pred_classes_errors = Y_pred_classes[errors]
Y_pred_errors = Y_pred[errors]
Y_true_errors = Y_true[errors]
X_val_errors = X_val[errors]# 錯誤預測的最大概率
Y_pred_errors_prob = np.max(Y_pred_errors,axis = 1)# 正確標簽對應的預測概率
true_prob_errors = np.diagonal(np.take(Y_pred_errors, Y_true_errors, axis=1))# 差值:預測的最大概率 - 正確標簽概率
delta_pred_true_errors = Y_pred_errors_prob - true_prob_errors# 找出概率差最大的錯誤
most_important_errors = np.argsort(delta_pred_true_errors)[-6:]def display_errors(errors_index,img_errors,pred_errors, obs_errors):""" This function shows 6 images with their predicted and real labels"""n = 0nrows = 2ncols = 3fig, ax = plt.subplots(nrows,ncols,sharex=True,sharey=True)for row in range(nrows):for col in range(ncols):error = errors_index[n]ax[row,col].imshow((img_errors[error]).reshape((28,28)))ax[row,col].set_title("Predicted label :{}\nTrue label :{}".format(pred_errors[error],obs_errors[error]))n += 1display_errors(most_important_errors, X_val_errors, Y_pred_classes_errors, Y_true_errors)發現預測錯誤的幾張圖片 本身就很容易誤解
4. 預測&提交結果
results = model.predict(test)
results = np.argmax(results,axis = 1) # 概率轉類別
results = pd.Series(results,name="Label")submission = pd.concat([pd.Series(range(1,28001),name = "ImageId"),results],axis = 1)
submission.to_csv("cnn_mnist_datagen.csv",index=False)









:拷貝構造函數與賦值運算符重載深度解析》)

![[ 數據結構 ] 時間和空間復雜度](http://pic.xiahunao.cn/[ 數據結構 ] 時間和空間復雜度)




)

