資料來源:火山引擎-開發者社區
多模態時代的訓練痛點,終于有了“特效藥”
當大模型從單一語言向文本 + 圖像 + 視頻的多模態進化時,算法工程師們的訓練流程卻陷入了 “碎片化困境”:
- 當業務要同時迭代 DiT、LLM 與 VLM時,很難在一套代碼里順暢切換;
- 而當模型形態一旦變化,底層并行組合和顯存調度往往需要大量手工改寫,耗時耗力;
- DIT 模型蒸餾需要大量的資源消耗,但是缺少高效的訓練 infra 支持來提升效率……
這些困擾行業的痛點,字節跳動的工程師們早就遇到了 —— 于是,VeOmni 應運而生。作為字節內部驗證過的 “統一多模態訓練框架”,它經過內部千卡級別真實訓練任務檢驗,訓練了 UI-Tars1.5 等重要模型,為了能將字節跳動核心 AI Infra 能力服務更多用戶,字節跳動決定開源 VeOmni,火山引擎基于進一步上支持了視頻模型訓練等功能,讓 VeOmni 支持了更多模型訓練場景,可以更好地服務更多用戶。
VeOmni 是什么?一套框架,搞定所有多模態訓練
VeOmni 是字節 Seed 團隊與火山機器學習平臺、IaaS 異構計算團隊聯合研發的統一多模態模型訓練框架,核心定位是三個統一:“統一多模態、統一并行策略、統一算力底座”。
它通過統一的 API 將 LoRA 輕量微調、FSDP、Ulysses 和 Expert Parallel 等多種混合并行策略以及自動并行搜索能力內置于框架內部。無論是百億級語言模型、跨模態視覺語言模型,還是 480P/720P、長序列的文本到視頻(T2V)或圖像到視頻(I2V)生成模型,開發者都能夠基于統一的訓練流程快速啟動訓練。
框架支持在千卡級 GPU 集群上自動完成權重張量的切分、通信拓撲的優化、動態顯存回收和異步 checkpoint。在開源的 Wan 2.1 等模型上實測顯示,相較于同類開源方案,VeOmni 能夠將訓練吞吐提高超過 40%,同時顯著降低顯存使用與跨節點通信帶寬壓力。
借助 VeOmni,字節跳動成功實現了“支持最快落地的新模型形態、最大化超大規模算力利用率、最小化業務改動成本”三大目標,有效彌補了開源社區訓練框架在擴展性和抽象層面上的不足,為包括 LLM 和 VLM 在內的多模態生成場景提供了一條統一且高效的訓練路徑。
火山引擎的用戶可在機器學習平臺中運用 VeOmni 的強大功能。
五大核心優勢,破解訓練效率瓶頸
VeOmni 的 “高效” 不是口號,而是用技術細節堆出來的。我們拆解了多模態訓練的核心痛點,給出了針對性解決方案:
顯存計算雙優化:用最少的額外計算,換最多的顯存
傳統 “大顆粒” 重計算要么全關、要么全開,往往用 10%–20% 的額外計算只換一點顯存。VeOmni 不一樣 —— 它先給每個前向張量算一筆 “ROI 賬”:省 1MB 顯存需要付出多少微秒計算。然后按 ROI 排序,只選性價比最高的算子重計算(比如 gate1_mul 省 40MB 只要 180μs,down_proj 要 4000μs,差距 22 倍!)。
VeOmni框架在訓練啟動前自動把 ROI 排序,同等顯存收益只選擇性價比最高的算子進入重計算池:例如 gate1_mul 和 down_proj 都可回收約 40 MB,但前者只需180μs、后者要 4000μs,差距達 22 倍。這樣就能在保證顯存不會超出的前提下,把額外計算開銷壓到最低。
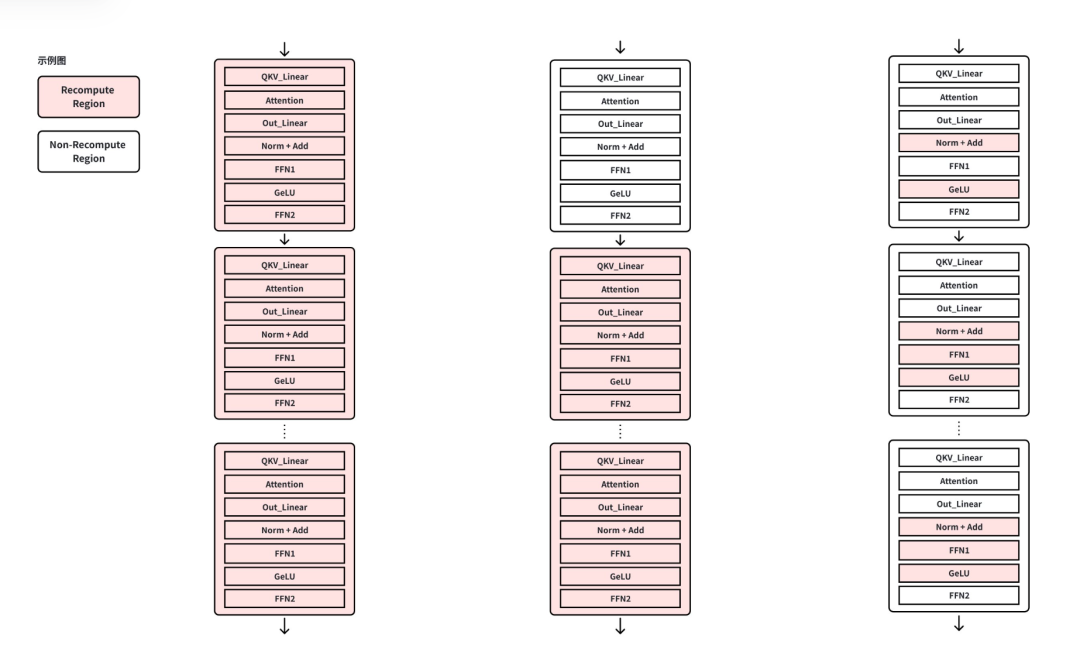
結果是:顯存夠用的前提下,額外計算開銷壓到最低。實測顯示,相比按層重計算,VeOmni 的 Recompute 占比從 60% 降到 30%(Recompute 越低,效率越高),對 DiT 720P 視頻訓練、千億 LLM 長序列訓練效果顯著。
混合并行 “組合拳”:一鍵匹配最優算力切分方案,顯存峰值降 55%
VeOmni 內置多維并行體系,支持 FSDP、Ulysses 和 Expert Parallel (EP) 等多種并行原語,通過啟動腳本可以一鍵進行笛卡爾組合,自動搜索最優的算力切分方案:
- FSDP 負責將參數、梯度和優化器狀態切片到各個 GPU,突破顯存瓶頸,橫向擴批簡單可靠;
- Ulysses Parallel 針對長序列任務,將注意力沿 head 維度拆解,有效緩解單卡顯存壓力;
- Expert Parallel 專門適用于 MoE 模型,可高效支持超大規模專家網絡的訓練。
這套并行體系已被應用于字節跳動內部多種模型的訓練中,在處理 480P 和 720P 分辨率的 T2V/I2V 任務時,通過 FSDP 和 Ulysses 的組合,單輪迭代顯存峰值可降低至原有基線的 45%。
算子級性能深挖:小核算子融合,訪存次數降百倍
針對 DiT 中大量“小核算子”導致的訪存抖動,VeOmni 把注意力-FFN-殘差鏈路重寫為單核 Kernel,長序列下顯存碎片顯著減少,訪存次數下降數百倍。
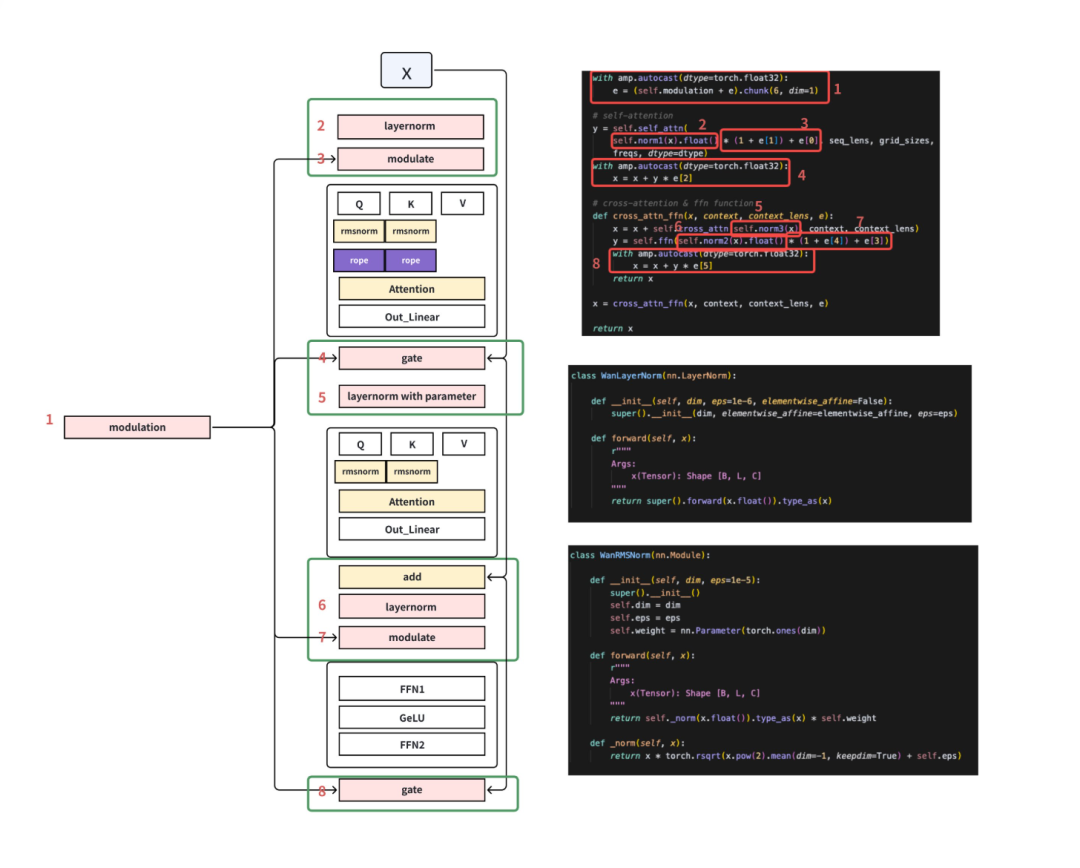
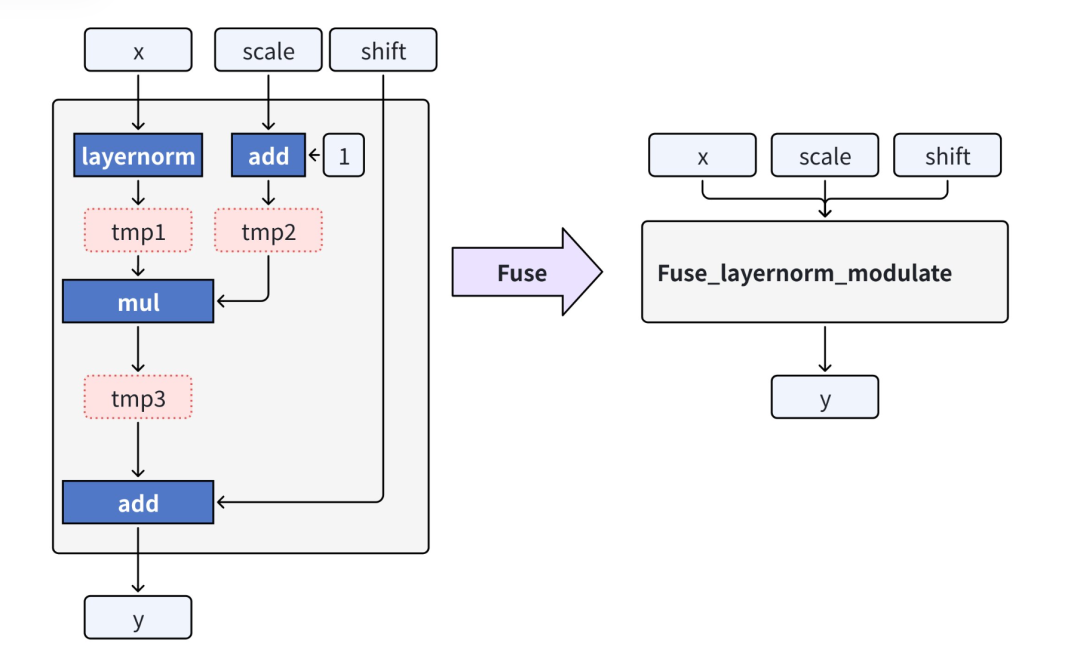
跨模型通吃:LLM/VLM/ 視頻生成,一套框架全搞定
VeOmni 的優化不是 “針對性補丁”,而是對 生成式視頻模型、千億級語言模型 與 視覺語言模型 全部生效:
- DiT 訓練顯存減半;
- LLM 長上下文窗口訓練從“手動調顯存”變為“自動無感切分”;
- VLM 雙塔/單塔架構在 Ring 模式下可線性擴展到更多 GPU,負載均衡無需改代碼。
憑借“算子粒度重計算 + 混合并行 + 算子融合/升級”三大引擎,VeOmni 把原本困擾開源框架的擴展瓶頸徹底拆解,為字節跳動以及合作伙伴在多模態內容生成和大模型服務化道路上提供了即插即用、極致高效的算力底座。
蒸餾加速:減少推理步數,降低推理成本
在生成式模型的推理中,步數蒸餾是提升效率的關鍵一環。然而,蒸餾的訓練周期極長,需要的計算資源也十分龐大。VeOmni 集成了軌跡蒸餾、分布匹配蒸餾(DMD)、自回歸蒸餾等學界前沿方法,并將框架原生的訓練加速能力(如顯存優化、混合并行等)應用在蒸餾算法上,極大地減少了蒸餾的迭代周期和資源消耗。用戶可通過啟動腳本指定蒸餾目標:
- 支持 DMD 等效果優秀的蒸餾方法,能將模型穩定蒸餾至 4 步、8 步等目標步數甚至更少;
- 支持蒸餾掉 CFG(無分類器引導)以消除冗余計算;
- 支持用戶自由編排蒸餾工作流,例如組合 “軌跡蒸餾預處理 + DMD 精調” 的多階段蒸餾邏輯。
經由 VeOmni 蒸餾出的模型能夠顯著減少推理所需步數,同時保持生成結果的高質量,這對于降低計算成本、加速模型部署具有重要意義。
實測性能:比開源方案快 40%,多場景數據說話
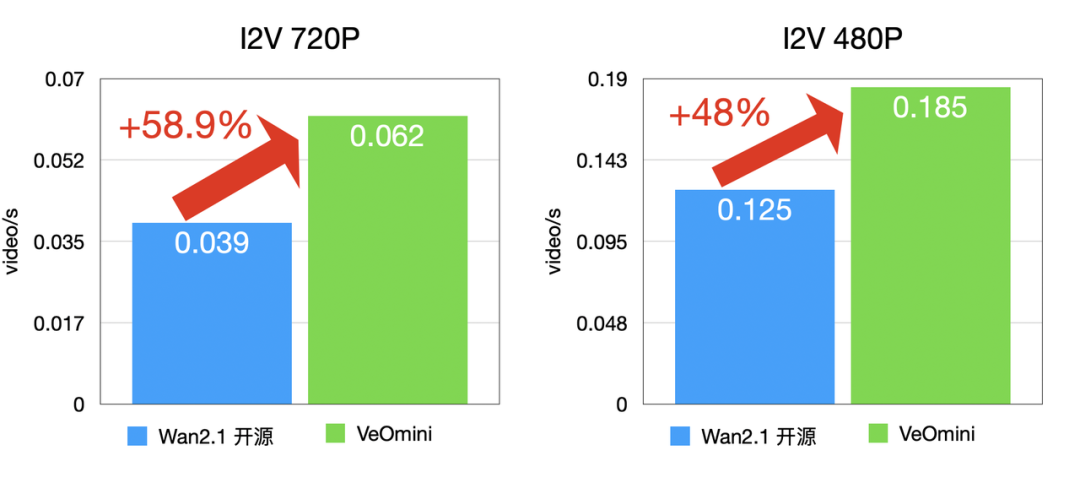
VeOmni 的效率不是 “自說自話”,而是用真實模型測試驗證的,以 Wan2.1-14B 模型為例(Lora 訓練):
- 計算型大卡:I2V 720P 訓練速度比開源方案快 48% 以上,T2V 720P 快 44.4% 以上;
- 訪存型大卡:I2V 720P 快 59.5% 以上,T2V 720P 快 57.4% 以上;
- 小參數量模型(Wan2.1-1.3B):T2V 480P 訓練速度提升 51% 以上。
卡型 1(計算型大卡)
I2V 訓練速度:
T2V 訓練速度:
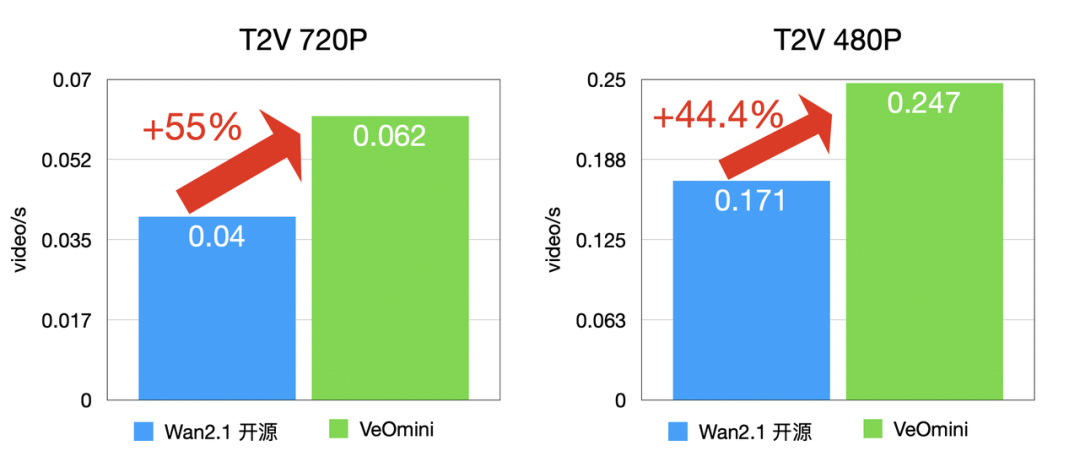
卡型 2(訪存型大卡)
I2V 訓練速度:
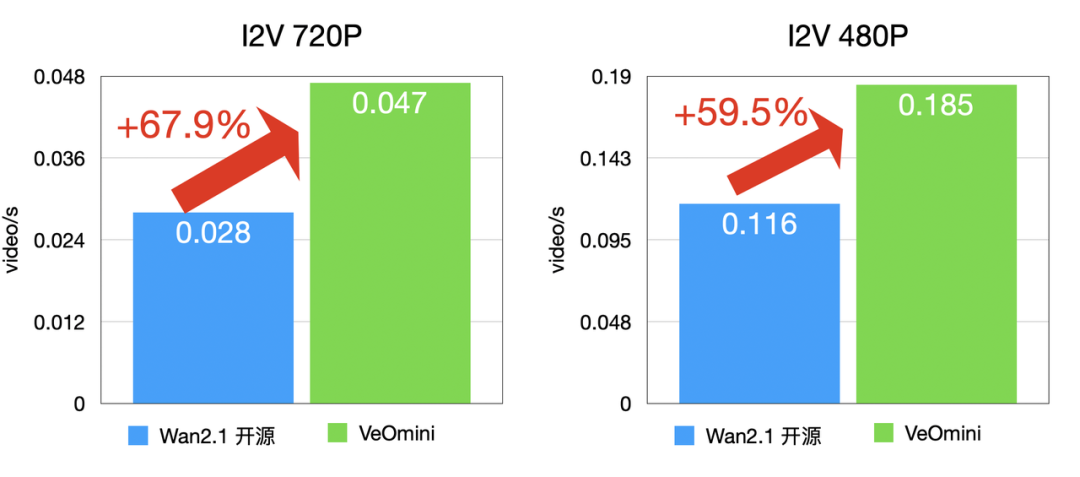
T2V 訓練速度:
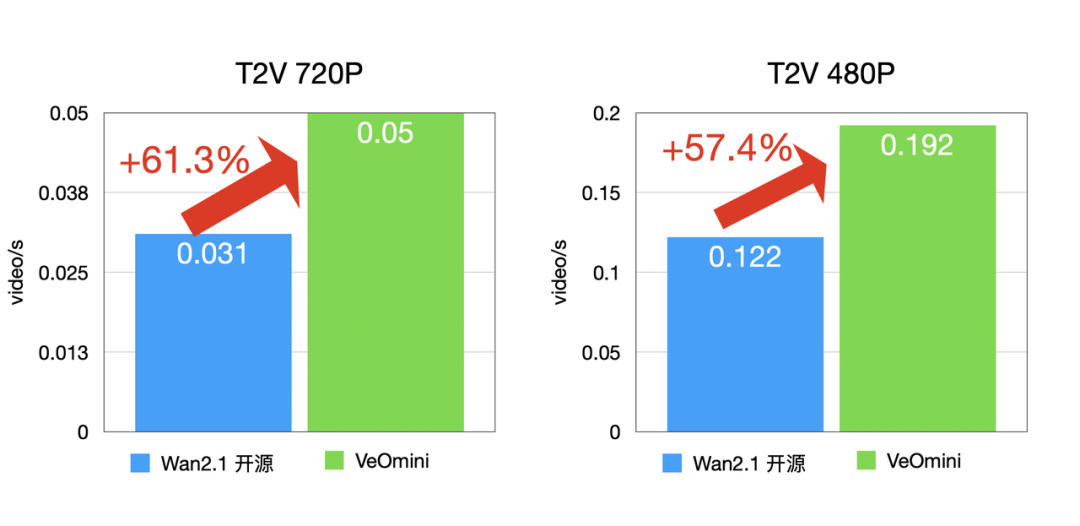
不管是大模型還是小模型,不管是計算型還是訪存型硬件,VeOmni 都能讓算力發揮到極致!
上手超簡單:火山平臺一鍵訓練,性能分析可視化
VeOmni 不是 “專家專屬工具”,而是開箱即用。目前,火山引擎在機器學習平臺和 AI 云原生訓練套件 TrainingKit 上都提供了 VeOmni 訓練的最佳實踐。下面我們以機器學習平臺實踐為例,介紹基于 VeOmni 訓練框架對開源模型 Wan 進行 lora 訓練,后續我們將推出基于 TrainingKit 的 VeOmni 部署實踐。
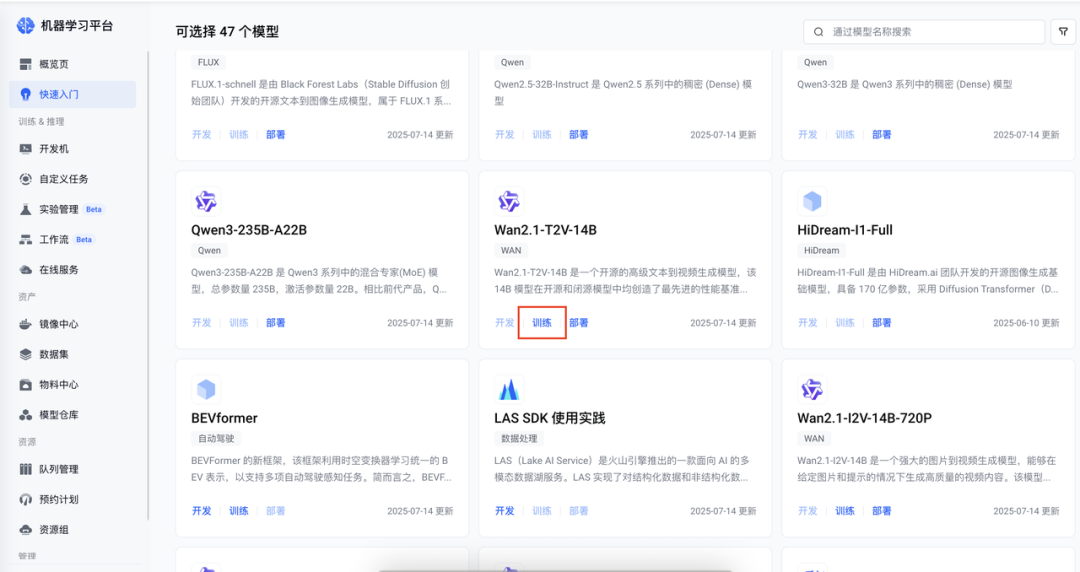
創建訓練任務
在快速入門選擇需要訓練的模型,并且配置實例規格及模型輸出路徑。

查看訓練任務詳情
創建任務后可在「任務詳情-日志」中查看訓練詳情。
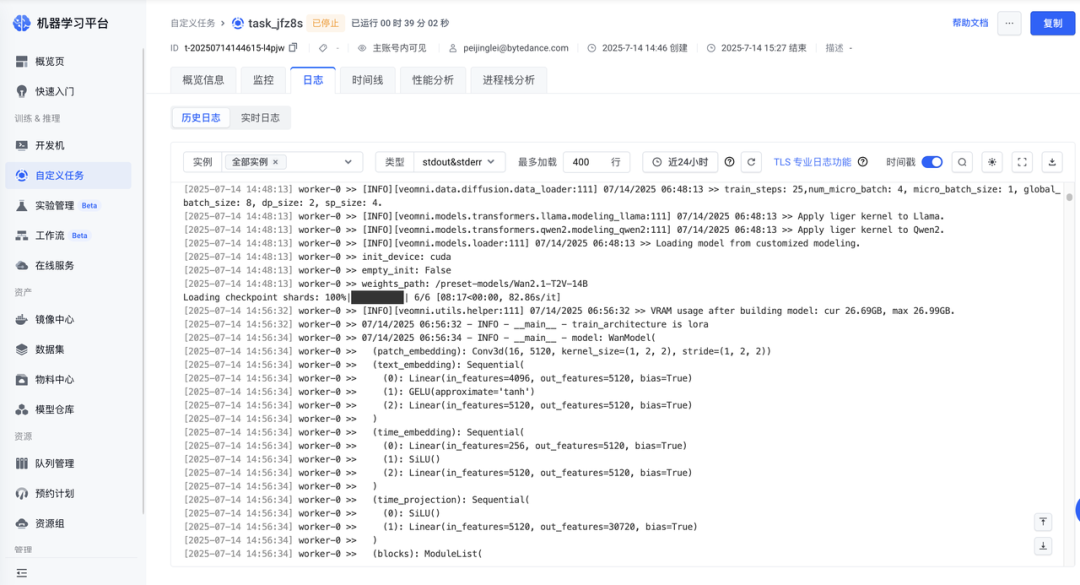
GPU 性能分析
1.導航到 自定義任務 > 任務詳情 頁面,在目標任務的管理頁面單擊 創建性能分析。
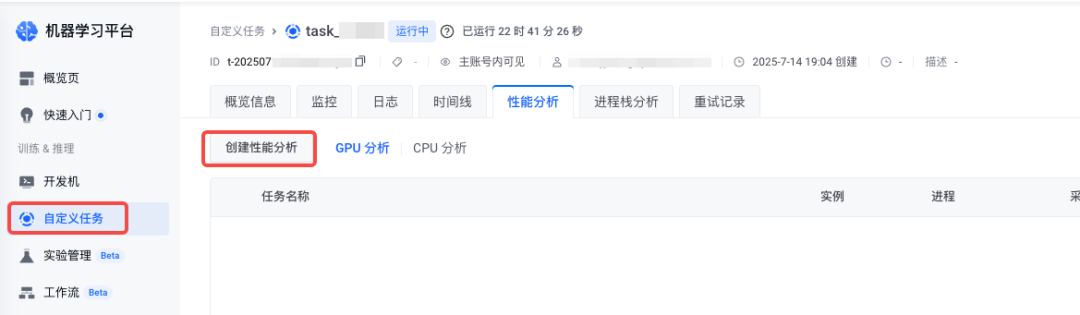
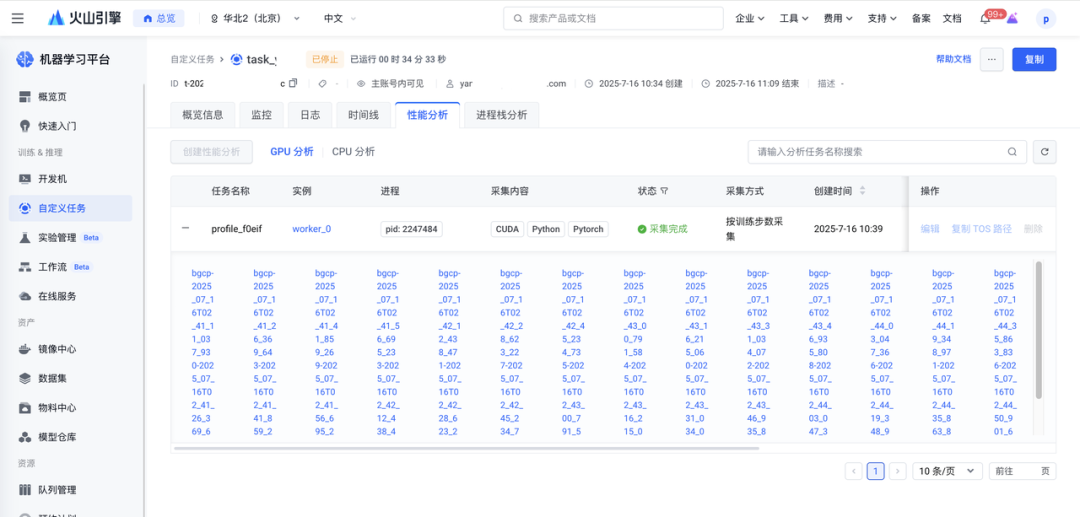
2.完成采集后,可在性能分析結果列表頁面管理所有分析任務。點擊「查看詳情」將跳轉至 perfetto 中展示性能分析火焰圖。
每個 Worker 節點會根據其擁有的 GPU 數量或進程數生成多個進程文件。平臺會將這些文件聚合成一個單一的結果文件,并根據 perfetto 的限制進行自動分片。
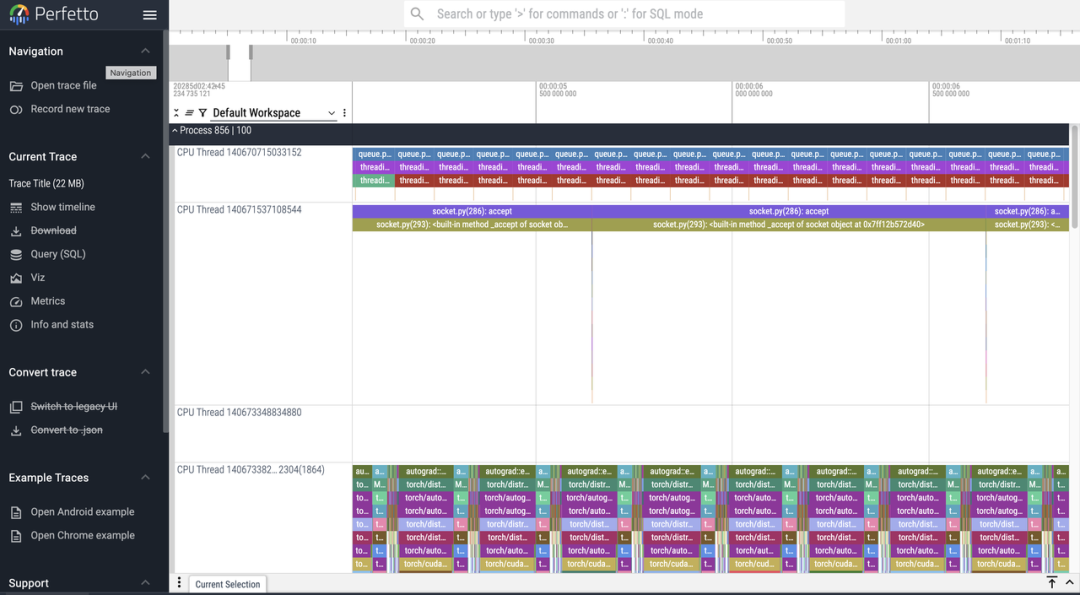
從訓練到推理,全鏈路打通
目前火山引擎機器學習平臺提供的數據集是用來訓練飛天效果的 Lora 數據集,客戶也可以自己選擇合適的數據集進行預處理后來進行訓練,具體使用方法隨后更新。
獲取輸出結果
在一鍵訓練的時候客戶指定了訓練的模型結果保存的地方,如下圖所示。
- 輸出模型結果保存文件路徑類似下圖
checkpoints/
├── global\_step\_xxx/ # 每次保存的權重快照
│ ├── extra\_state/ # 訓練狀態(按 rank 切分)
│ │ └── extra\_state\_rank\_*.pt
│ ├── hf\_ckpt/ # HuggingFace 兼容格式
│ │ ├── config.json
│ │ └── diffusion\_pytorch\_model.safetensors
│ ├── model/ # 模型參數分片
│ │ └── \_\_*\_*.distcp
│ └── optimizer/ # 優化器狀態分片
│ └── \_\_*\_*.distcp
└── latest\_checkpointed\_iteration.txt # 記錄最新步數 - 客戶可以到 hf_ckpt下看到保存的 Lora 訓練權重,得到的路徑為 checkpoints/global_step_xxx/hf_ckpt/diffusion_pytorch_model.safetensors
使用腳本進行權重格式轉換
- 將下列代碼保存為 convert.py
#!/usr/bin/env python # convert.py —— 把 “blocks.…default.weight” → “diffusion\_model.blocks.…weight” from pathlib import Path
from safetensors.torch import load\_file, save\_file
import sys if len(sys.argv) != 2: sys.exit(f"用法: python {Path(\_\_file\_\_).name} <input.safetensors>") inp = Path(sys.argv[1]).expanduser().resolve()
out = inp.with\_name(inp.stem + "\_styleB.safetensors") tensors = load\_file(str(inp))
converted = {} for k, v in tensors.items(): # 若無前綴則加 diffusion\_model. ifnot k.startswith("diffusion\_model."): k = "diffusion\_model." + k # 去掉 .default. k = k.replace(".default.", ".") converted[k] = v save\_file(converted, str(out))
print(f"? 已保存: {out}")
- 執行下面的命令,得到轉換后的權重
python convert.py
yourpath/checkpoints/global\_step\_xxx/hf\_ckpt/diffusion\_pytorch\_model.safetensors
使用 Vefuser 推理
訓練完的模型,用火山 veFuser 推理更高效 ——veFuser 是火山引擎的擴散模型服務框架,針對 VeOmni 訓練的 LoRA / 全量微調模型做了優化,能實現 “超低延遲” 視頻生成。從訓練到部署,全鏈路流暢!






:拷貝構造函數與賦值運算符重載深度解析》)

![[ 數據結構 ] 時間和空間復雜度](http://pic.xiahunao.cn/[ 數據結構 ] 時間和空間復雜度)




)



--54-65關)

