目錄
- 引言:從"機器模仿"到"智能協同"的時代跨越
- 一、人工智能2.0的技術演進:從規則到大模型的三次躍遷
- 1. 人工智能0.0(1956-2006):規則驅動的"專家系統時代"
- 2. 人工智能1.0(2006-2020):數據驅動的"深度學習時代"
- 3. 人工智能2.0(2020- ):大模型主導的"智能涌現時代"
- 二、大模型的技術內核:從"文字接龍"到"邏輯推理"的底層邏輯
- 1. 核心原理:Next Token Prediction(NTP)
- 2. 能力邊界與突破路徑
- 3. 產業影響:從"壟斷"到"普惠"的格局重塑
- 三、AI 2.0時代的人才需求:能力維度的重構與分化
- 1. 應用人才(全員必備)
- 2. IT專業人才(產品與開發)
- 3. AI 2.0專業人才(技術攻堅)
- 四、人工智能通識教育:面向未來的核心素養培養
- 1. 目標定位:從"懂原理"到"會協同"
- 2. 課程內容:模塊化與場景化結合
- 3. 教學創新:跨學科融合與實踐導向
- 結語:人與AI的共生之道
引言:從"機器模仿"到"智能協同"的時代跨越
當ChatGPT在2022年底掀起全球AI熱潮時,一個新的技術紀元悄然開啟——人工智能2.0時代。與此前聚焦"機器如何模仿人類智能"的1.0時代不同,2.0時代的核心命題是"人類如何與超大規模智能系統協同進化"。從DeepSeek等國產大模型實現推理能力的代際突破,到Sora等視頻生成技術拓展創造力邊界,人工智能正從實驗室走向產業深水區,這一變革不僅重塑技術生態,更對人才培養與教育體系提出了全新要求。
一、人工智能2.0的技術演進:從規則到大模型的三次躍遷
人工智能的發展并非一蹴而就,而是歷經半個多世紀的技術迭代,形成了清晰的演進脈絡:
1. 人工智能0.0(1956-2006):規則驅動的"專家系統時代"
這一階段以"知識+規則"為核心,試圖通過人工定義邏輯框架模擬人類專家思維。典型代表如早期的專家系統(由知識庫與推理機組成),以及邏輯回歸、決策樹等傳統機器學習方法。其局限顯著:依賴小數據與人工特征工程,缺乏通用性,跨模態能力幾乎為零。
2. 人工智能1.0(2006-2020):數據驅動的"深度學習時代"
2006年Hinton提出的深度學習理論,標志著AI進入"數據+學習"新階段。深度神經網絡通過多層非線性變換自動提取特征,實現了從"人工設計特征"到"機器自主學習特征"的突破:
- 2012年AlexNet在ImageNet競賽中超越人眼識別精度;
- 2016年AlphaGO擊敗李世石,證明AI可掌握復雜戰略思維;
- 2017年Transformer架構問世,注意力機制為大模型奠定基礎,BERT、GPT等預訓練模型開始嶄露頭角。
3. 人工智能2.0(2020- ):大模型主導的"智能涌現時代"
以GPT-3為起點,AI進入"大模型時代"——其核心是"三多":數據多、參數多、算力多。技術特征表現為:
- 多模態融合:從單一文本(LLM)擴展到圖像(Stable Diffusion)、視頻(Sora)、音頻等跨模態生成;
- 推理能力躍升:從"生成內容"向"邏輯分析"突破,如DeepSeek R1實現復雜數學問題、代碼生成的精準處理;
- 架構創新:混合專家模型(MoE)、多頭潛注意力(MLA)等技術大幅提升效率,降低成本(如DeepSeek訓練成本僅557萬美元,推理成本降低83%)。
二、大模型的技術內核:從"文字接龍"到"邏輯推理"的底層邏輯
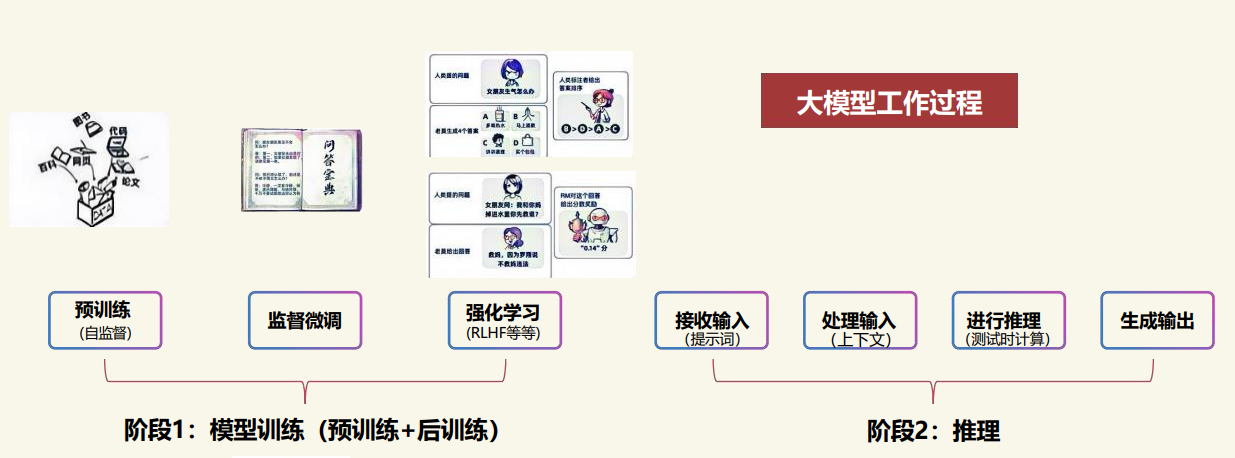
理解大模型的工作原理,是把握AI 2.0時代的關鍵。其核心機制可概括為"預訓練-推理"的閉環:
1. 核心原理:Next Token Prediction(NTP)
大語言模型本質是"概率預測機器":收到提示詞后,先將文本拆分為可計算的token(語義最小單位),通過Transformer架構分析token間關系,再基于上下文預測下一個token的概率分布(如"今天天氣不錯,我決定"后,"去"的概率可能達70%),最終通過自回歸生成完整內容。這種"文字接龍"式的工作模式,卻能在大規模數據訓練后涌現出類人智能。
2. 能力邊界與突破路徑
大模型并非萬能,其局限包括:
- 幻覺問題:因數據壓縮與概率預測特性,可能生成看似合理卻錯誤的內容;
- 記憶限制:多輪對話中存在信息遺忘,受計算成本約束;
- 邏輯短板:擅長"快思考"(如3+5=8),但"慢思考"(如127×206)需外部工具輔助。
行業通過提示詞工程(Prompt)、思維鏈(CoT)、搜索增強(RAG)等技術彌補短板,其中DeepSeek R1通過強化學習(GRPO算法)與長鏈推理(TTC)技術,將國產模型與國際頂尖水平的差距縮短至3-5個月。
3. 產業影響:從"壟斷"到"普惠"的格局重塑
以DeepSeek為代表的國產大模型,正推動行業三大變革:
- 打破壟斷:開源開放策略(MIT協議)與低成本優勢,終結頭部企業技術霸權;
- 價格革命:API定價僅為行業均價1/10,讓中小企業可負擔AI能力;
- 價值轉向:從"唯參數規模論"到"性價比競爭",倒逼技術創新聚焦實際效能。
三、AI 2.0時代的人才需求:能力維度的重構與分化
人工智能的普及正在重塑職業能力體系,形成三類核心人才需求:
1. 應用人才(全員必備)
核心要求:會用AI解決實際問題,而非掌握技術細節。
- 能力增量:問題定義(將現實需求轉化為AI任務)、判斷力(鑒別AI輸出質量)、溝通表達(用提示詞精準傳遞意圖);
- 能力減量:記憶力(知識儲備可由AI替代)、機械計算(復雜運算交由工具);
- 教育路徑:AI通識教育,聚焦"人機協同"思維培養。
2. IT專業人才(產品與開發)
核心要求:架起技術與場景的橋梁。
- 能力增量:數據思維(理解數據分布規律)、模型認知(掌握大模型適配場景)、工程落地(Prompt工程、微調部署);
- 能力減量:純代碼能力(部分可由AI生成)、文檔編寫(自動化工具替代);
- 教育路徑:新IT教育,融合大模型原理與行業場景。
3. AI 2.0專業人才(技術攻堅)
核心要求:推動技術邊界突破。
- 能力增量:數據合成(生成高質量訓練數據)、底層工程(芯片適配、并行計算)、范式創新(Transformer/Diffusion架構優化);
- 能力減量:傳統機器學習算法(被大模型范式替代);
- 教育路徑:AI專業教育,聚焦數學基礎與前沿技術研發。
四、人工智能通識教育:面向未來的核心素養培養
在AI成為"基礎工具"的時代,通識教育需擺脫傳統技術課的局限,構建全新體系:
1. 目標定位:從"懂原理"到"會協同"
- 全局觀:理解AI 2.0的范式轉換(從"判別"到"生成"再到"推理");
- 實踐力:掌握提示詞工程、多模態工具應用等實操技能;
- 批判性思維:清晰認知AI的能力邊界,避免盲目依賴或恐懼。
2. 課程內容:模塊化與場景化結合
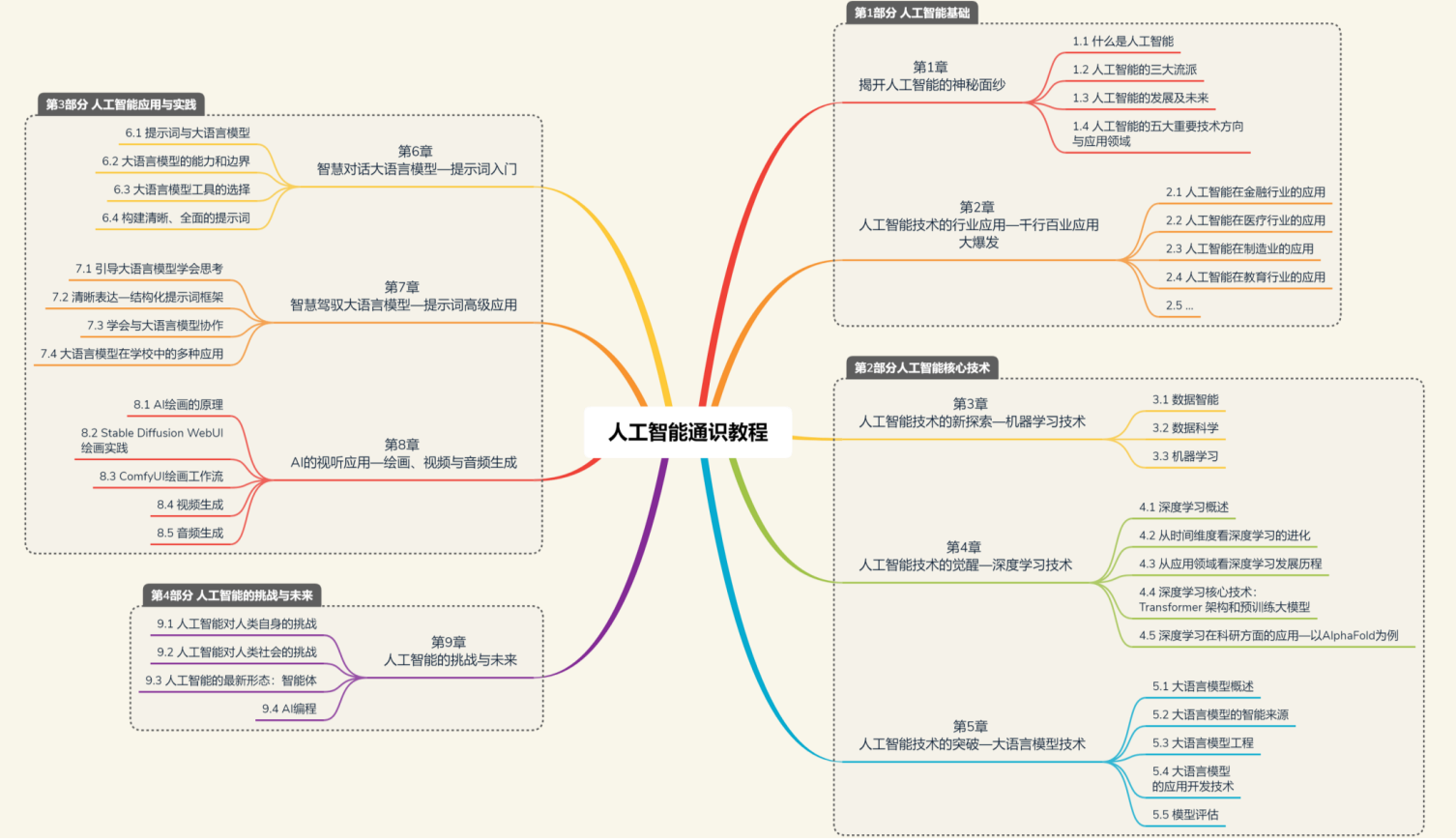
課程體系可分為四部分:
- 基礎層:AI定義、發展歷程、三大流派(符號主義、連接主義、行為主義);
- 技術層:大語言模型原理、多模態生成技術、智能體(Agent)應用;
- 應用層:行業案例(金融風控、醫療診斷、教育輔助等)、工具實操(提示詞進階、數據驗證);
- 倫理層:數據隱私、算法偏見、人機協作的社會影響。
3. 教學創新:跨學科融合與實踐導向
- 案例教學:通過"四步法"(問題拆解→AI工具選擇→結果驗證→優化迭代)培養解決思維;
- 學科融合:如教育學專業聚焦"AI輔助教學設計",法學專業側重"算法合規審查";
- 工具支撐:通過實訓平臺提供低成本實操環境,結合開源模型(DeepSeek R1)開展項目制學習。
結語:人與AI的共生之道
人工智能2.0時代的終極命題,不是"機器能否超越人類",而是"人類如何善用機器智能"。正如北大肖睿團隊所言:"人是目的,不是手段,不要去和人工智能比工具性。"未來的競爭壁壘,將是人類的判斷力、創造力與AI的效率、算力的協同程度。
面向這一趨勢,教育的核心任務是:讓每個人都能成為AI的"駕馭者"而非"旁觀者"——這既是技術變革的要求,更是人類文明進階的必然。





)


)
)

)







