在AI應用極速發展的當下,LLM(大語言模型)與RAG(檢索增強生成)系統已成為構建智能問答、知識管理等高階應用的核心引擎。
然而,許多團隊在項目落地時遭遇了現實的挑戰:模型的實際表現——無論是回答的準確性、相關性,還是系統整體的響應效率——往往難以達到預期。究其根源,一個常被低估的關鍵環節浮出水面:文檔解析的質量。
核心問題在于輸入數據的“可理解性”。現實世界中的知識載體——PDF報告、掃描文件、圖文結合的技術文檔——本質上是高度非結構化的。傳統OCR工具就像個“近視的搬運工”,只能機械地把圖像上的文字“摳”下來,卻看不懂文檔的內在“藍圖”:標題的層級關系迷失了,段落被拆得七零八落,復雜的表格像被撕碎的拼圖,跨頁的內容徹底斷了聯系,圖表更是成了沒有注釋的“孤島”。當這種缺乏結構、語義斷裂的“原料”被直接喂入RAG系統時,后果是顯而易見的:
- 檢索效率低下:系統難以精準定位包含答案的關鍵片段,在海量碎片中“大海撈針”,耗時費力。
- 答案準確性受損:上下文缺失或錯位,導致模型“理解偏差”,生成跑題甚至錯誤的回答。
- 信息完整性打折:表格數據混亂、跨頁信息斷裂、圖表意義不明,關鍵細節丟失。
可以說,文檔解析的質量,直接鎖定了RAG系統乃至整個AI應用效果的上限。優質的解析不是簡單的文字提取,而是對文檔內容進行深度理解與結構化重建的過程。這正是TextIn xParse智能文檔解析引擎致力于解決的痛點。

目前從 PDF、JPG、PNG 等格式的圖文混排文檔中提取表格數據并轉化為 Excel 等可編輯形式,常面臨兩大難點:一是人工提取效率極低,二是傳統 OCR 工具僅能提取文本,無法理解數據邏輯,難以滿足精準提取需求。
例如在金融、科研等對數據依賴性強的領域,這類問題更為突出。例如金融機構需解析上市公司年報、行業研報中的大量表格數據,這些文件多為 PDF、圖片格式,甚至存在加密 PDF,批量處理難度極大。因此,如何高效、準確地提取表格數據,成為影響后續分析工作的關鍵。
針對這一問題,【TextIn】文檔解析工具作為大模型加速器,為解決這一難點量身定制。TextIn文檔解析上架新功能——圖表解析,通過線上參數配置即可調用,完成全文解析,無需對樣本進行預先分割或其他預處理。其核心優勢在于:
- 技術融合:結合 OCR 的文本識別能力與大模型的語義理解能力,不僅能提取文本,更能解析表格數據邏輯,將非結構化數據轉化為結構化數據。
- 操作便捷:無需對文檔進行預先分割、格式轉換等預處理,通過線上參數配置即可直接調用功能,完成全文解析。
- 適用廣泛:支持 PDF(包括加密 PDF)、JPG、PNG 等多種格式,既能處理有明確數值標注的表格,也能對無具體數值的復雜圖表進行精確測量并給出預估數值,充分挖掘數據價值。
- 賦能大模型:解析后生成的結構化數據(如?Markdown?格式)可直接輸入大模型,避免原始圖表對大模型理解的干擾,提升大模型處理效率和回答準確性。
讓我們來看幾個例子:
案例1:密集少線表格識別
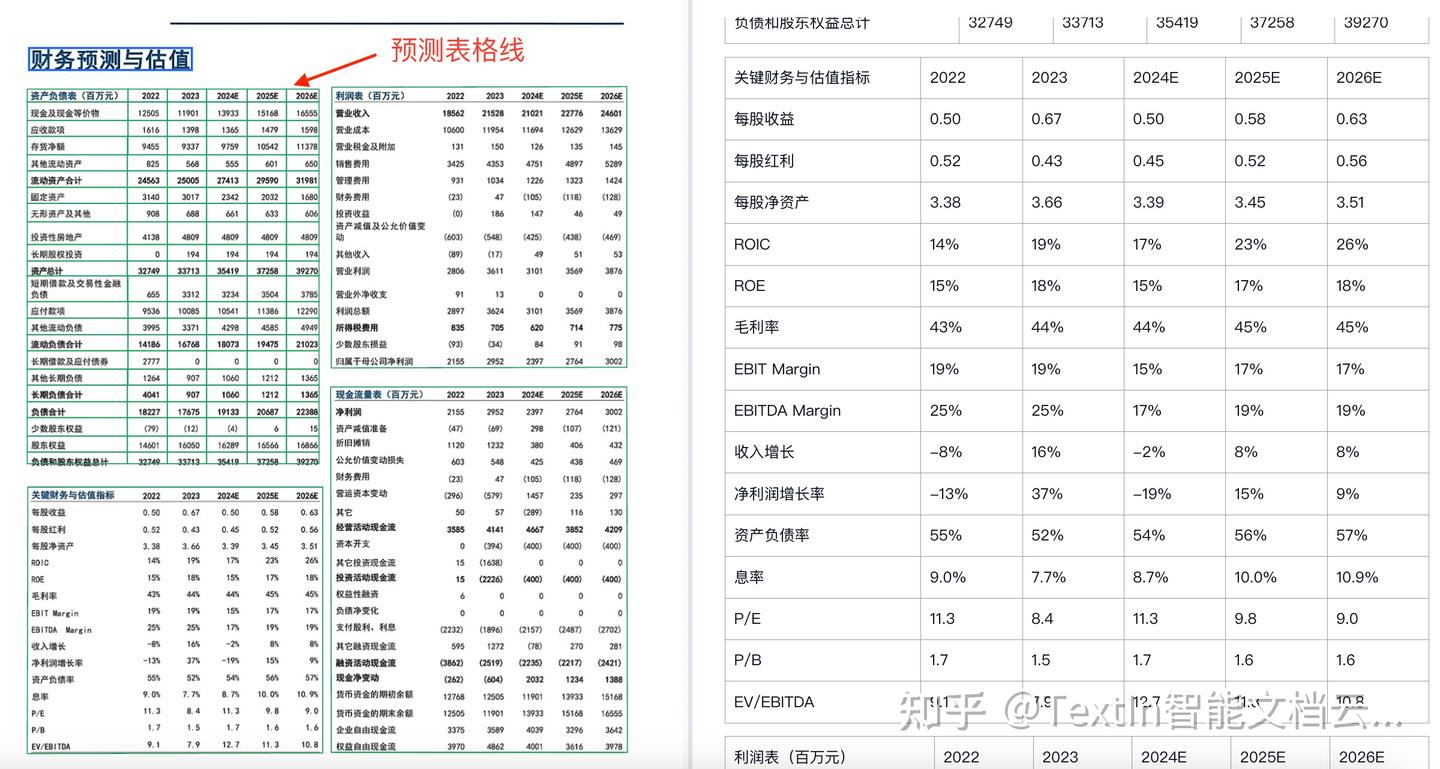
前端支持選中表格并在原圖上顯示模型預測的單元格,如圖中左上表格效果。
案例2:跨頁表格合并、頁眉頁腳識別

案例3:圖表識別
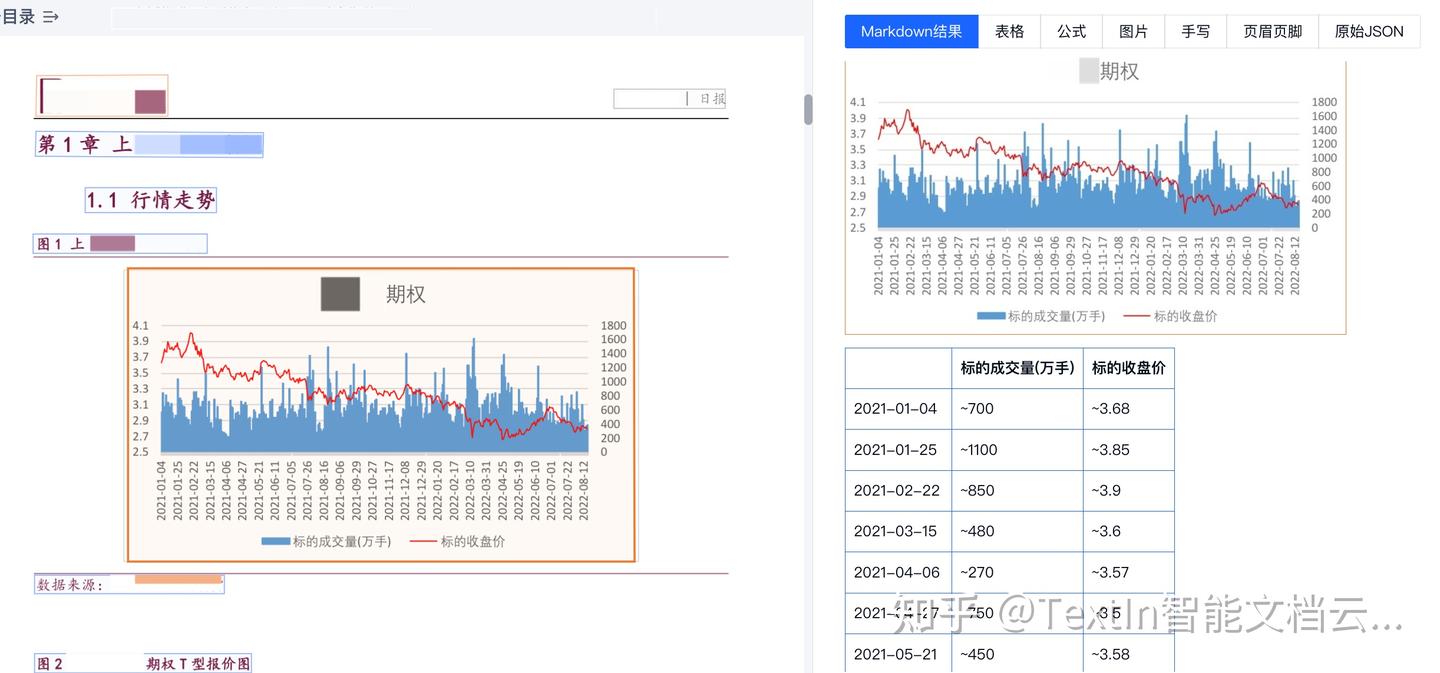
對于肉眼讀取困難的圖表,TextIn xParse也會通過精確測量給出預估數值,幫助挖掘更多有效數據信息,完成分析及預測工作。
操作步驟講解
- 登錄平臺:訪問【TextIn】官網完成用戶登錄。
- 上傳文檔:在文檔解析功能界面,上傳需要處理的含表格文檔(支持 PDF、JPG、PNG 等格式,包括加密 PDF)。
- 參數配置:根據文檔特點和提取需求,在線設置解析參數(如是否需要預估無數值圖表的數值等)。
- 執行解析:確認參數后,點擊解析按鈕,工具將自動完成文檔掃描、表格識別與數據結構化處理。
- 獲取結果:解析完成后,可獲取結構化數據(如表格形式)或 Markdown 格式文件,直接用于 Excel 導入、數據入庫、大模型輸入等后續操作。
客戶案例
某頭部券商研究所日常需處理大量上市公司年報、行業研報,其中包含數百張表格數據,傳統人工提取方式耗時且易出錯,嚴重影響研究效率。
應用TextIn后的效果數據:
- 效率提升:單份含 20 張表格的 PDF 文檔,人工提取需 3-4 小時,使用后僅需 5-8 分鐘,效率提升約 95%;批量處理(100 份文檔)時,總耗時從原本的 300 + 小時縮短至 15 小時以內。
- 準確性提升:人工提取數據誤差率約 3%-5%,TextIn對有明確數值的表格提取準確率達 99.2%,對無數值的復雜圖表預估數值誤差率控制在 2% 以內。
- 大模型協作效果:將解析后的 Markdown 文件輸入大模型,相比直接上傳原始 PDF,大模型對表格數據的理解準確率從 65% 提升至 98%,回答質量顯著提高(如針對 “全球工業機器人銷售額趨勢” 的問題,原始 PDF 因圖表干擾導致大模型回答模糊,解析后大模型能基于結構化數據給出精準的數值分析和趨勢判斷)。
通過【TextIn】的圖表解析功能,該研究所不僅降低了數據提取的人力成本,更通過結構化數據賦能大模型,加速了研究報告的產出效率,為投資決策提供了更及時、準確的數據支持。



)


)
)

)









