????????在了解了各種協議的使用以及簡單的socket接口后,學會了“怎么傳”的問題,現在來了解一下“傳什么”的問題。
1. 序列化與反序列化
????????在前面的TCP、UDP的socket api 的接口, 在讀寫數據時, 都是按 "字符串" 的方式來發送接收的. 如果我們要傳輸一些 "結構化的數據" 怎么辦呢?? ? ? ? 在最初的對網絡的整體結構的學習中,我們了解了網絡分層的概念,也知道了消息在傳輸的時候是會被分段的——用于描述信息的叫報頭,實際傳輸的內容叫報文,但是我們前面的demo代碼都是直接把消息當作一個個直接的string當作信息傳來傳去,沒有所謂報頭或者序列化的概念,這是很不嚴謹的。
協議不僅僅是TCP或UDP等傳輸協議,傳輸的內容也是可以被定義的
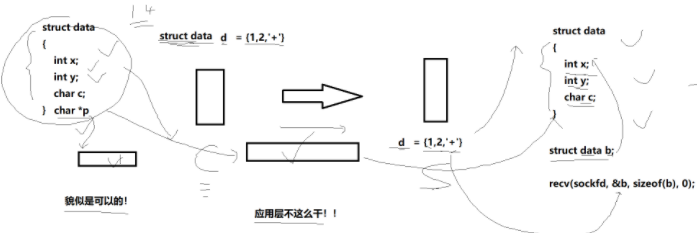
????????在同一臺機器內,結構體的“打包”與“解包”由同一套編譯器和運行時完成,直接按字節傳遞即可(比如在本地電腦的文件讀寫,就是直接二進制入再二進制出);一旦跨過網絡,就可能遇到不同操作系統、不同 CPU 體系結構帶來的字節序、對齊方式等差異,貿然按原樣發送結構體極易出錯,因此網絡通信中不宜直接傳遞裸結構體(也就是避免直接傳二進制)。
????????譬如:結構體對齊方法可能不一樣,客戶端可能是安卓平臺等等
????????既想保留結構化信息的便利,又要回避兼容性問題,業界給出的答案是序列化:把結構體按既定規則轉成一段無歧義的字符串(字節流)。接收方再通過反序列化,把這串字節重新還原成結構體。序列化與反序列化互為逆過程,屏蔽了底層差異。
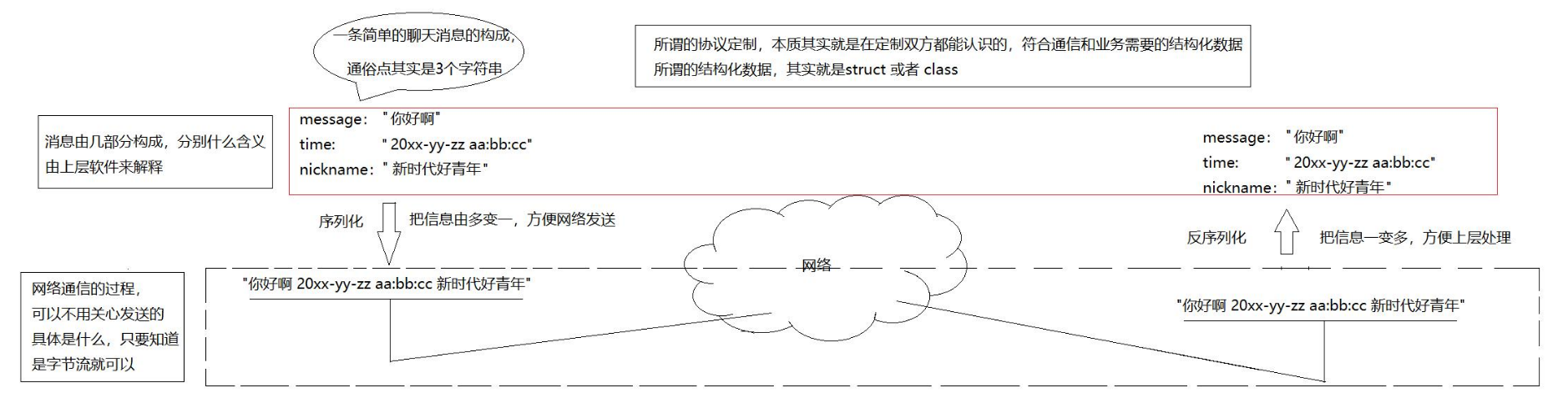
????????為了讓兩端都能準確還原數據,雙方必須持有同一份“數據藍圖”——即完全一致的類型定義(也就是雙方要有一樣的協議)。這份共享的結構體定義就是應用層協議本身:它既描述了報文的字段順序、類型與含義,又隱含了編碼/解碼規則;因其隨應用程序一起部署,故屬于應用層協議范疇。
比如要傳以上的data,可以先寫成{1,2,'+'},應用層傳輸這個字符串,在服務器接受到這個字符串之后按照相同的規則進行反序列化
2.?如何理解socketfd全雙工
前面都提到UDP和TCP是全雙工的,如何理解一個fd支持同時讀寫呢?
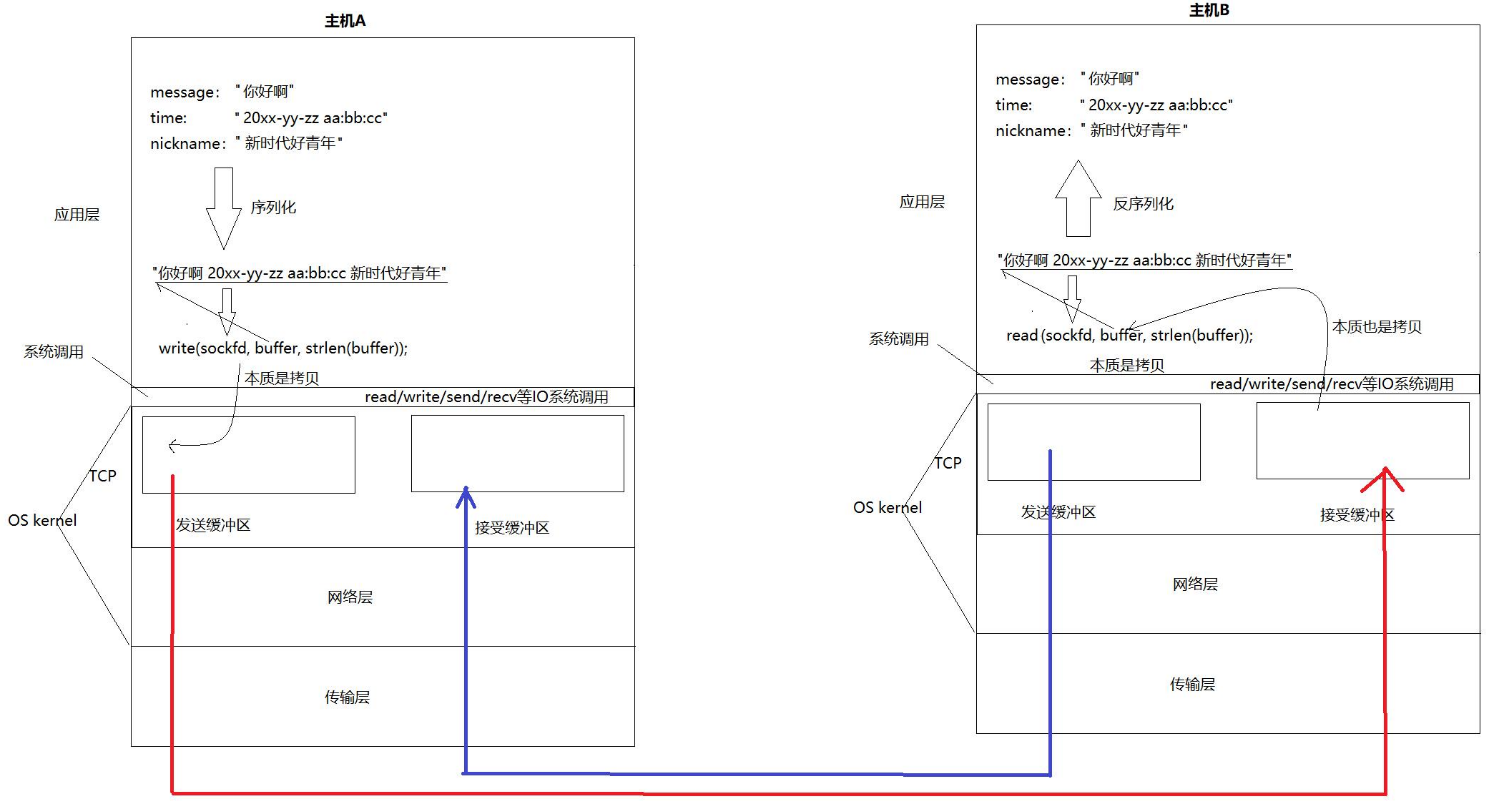
? ? ? ? 本質是因為TCP的底層有兩個緩沖區,一個是發送緩沖區,一個是接受緩沖區。
? ? ? ? 就像OS傳輸文件給磁盤一樣,read/write/send/recv等系統調用只負責把內容發送到緩沖區,至于緩沖區多久刷新、如何刷新,都是由TCP或UDP的Kernel代碼自動進行的。
而發送和接受的本質就是拷貝,所以其實就是應用層對于內核的拷貝
? ? ? ? 所以,所謂的全雙工本質就是利用兩個緩沖區,客戶端的發送緩沖區對應服務端的接收緩沖區,服務端的發送緩沖區對應客戶端的接收緩沖區
????????不管是客戶端還是服務器,OS內部都可能積累大量的報文,操作系統需要對這些報文進行管理,管理就必須先組織。
所以內部一定有對應的結果體在描述這些報文。
觀察、了解報文是如何被管理的?
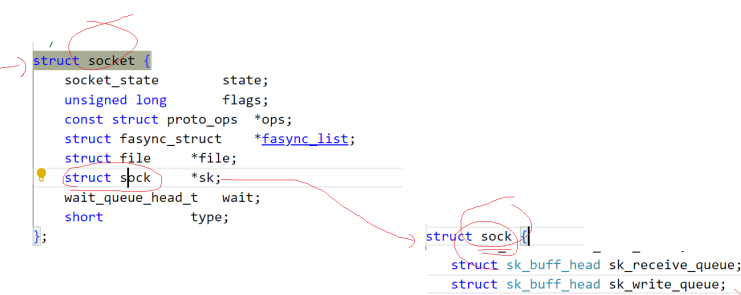
? ? ? ? 每個fd指向的struct file中都有一個隱藏的private_data指針,作為VFS的描述普通文件的struct file時,private_data沒有明確的指向。
private_data指向具體文件系統或驅動的私有數據
但是當file作為一個套接字的描述結構體時,private_data指向的就是一個socket結構體,而socket結構體中也有一個struct file指回 file。
然后這個socket還包括了一個sock結構體,sock結構體里包含了兩個隊列,這兩個隊列里裝的都是sk_buff
sk_buff就是管理報文的。
各個報文以鏈表形式被組織管理起來。而這些鏈表就由sock中的接受隊列和寫隊列分別管理。
由此,TCP\UDP等就能進行全雙工了。

????????現在將視角集中到客戶端向服務端發送的一條信息之上,因為TCP是面向字節流的,所以在客戶端給服務端發送數據時可能存在發送的數據只有待發送數據的一半甚至更少,那這樣服務端接收到數據就屬于不完整的數據,在上面應用層轉換時也就可能轉換失敗。
????????基于這個原因,所以說TCP的讀寫,不論是使用文件流的read和write,還是網絡中的recv和send都是不完善的,因為這些接口不會檢測數據是否是上層需要的有效數據,而且這些接口也無法做到判斷數據是否是上層需要的有效數據,所以這就需要應用層自己判斷收到的數據是否是可以被正確轉換的,如果不是就應該繼續接收直到至少有一條有效數據。
????????TCP更像自來水,自來水公司只負責把水放到你家的水箱里,你自己可能一桶一桶接,可能一杯一杯接。TCP按照真實情況,控制著一點一點發,所以需要由應用層來控制報文的完整性。因此,TCP中必須要有序列化和反序列化的操作。
????????但是對于UDP來說就不存在上面TCP這個問題,因為UDP是面向數據包的,所謂數據包就是將數據整個打包,在發送時要么就發整個數據包,要么就一點也不發,這樣不論是哪一個接口,拿到的都是完整的數
?????????而UDP就是發快遞。永遠都是完整的一個包裹,快遞員不被允許送半個包裹給你。
JSONCPP?
所以,要把這個結構體給控制成什么樣子才作為標準呢?我們可以自己制定,也有一些被規定好并且比較有名的方案:
一句話理解:? XML:「文檔+元數據」時代的老大哥,現在只做配置/協議兼容。
? JSON:「前后端通用語」,無 schema,想改就改,調試最爽。
? Protobuf:「高性能 RPC 專用二進制」,IDL 一把梭,版本演進最省心。

作為后端開發者,我們重點學習jsoncpp插件的使用 :
JsoncppJsoncpp 是一個用于處理 JSON 數據的 C++ 庫。它提供了將 JSON 數據序列化為字符串以及從字符串反序列化為 C++ 數據結構的功能。Jsoncpp 是開源的,廣泛用于各種需要處理 JSON 數據的 C++ 項目中
1.簡單易用:Jsoncpp 提供了直觀的 API,使得處理 JSON 數據變得簡單。2.高性能:Jsoncpp 的性能經過優化,能夠高效地處理大量 JSON 數據。3.全面支持:支持 JSON 標準中的所有數據類型,包括對象、數組、字符串、數字、布爾值和 null。4.錯誤處理:在解析 JSON 數據時,Jsoncpp 提供了詳細的錯誤信息和位置,方便開發者調試。當使用 Jsoncpp 庫進行 JSON 的序列化和反序列化時,確實存在不同的做法和工具類可供選擇。
以下是三種常見用法(JSON組件只要會用就行,不需要掌握很多,忘記了就AI)
使用 Json::Value 的 toStyledString 方法:○優點:將 Json::Value 對象直接轉換為格式化的 JSON 字符串。○?實例如下:
#include <iostream>
#include <string>
#include <jsoncpp/json/json.h>
int main()
{Json::Value root;root["name"] = "joe";root["sex"] = "男";std::string s = root.toStyledString();std::cout << s << std::endl;return 0;
}$ ./test.exe
{
"name" : "joe",
"sex" : "男"
}//第一種,使用toStyledString。直接把一個JSON::VALUE對象轉換成string:使用 Json::StreamWriter:○優點:提供了更多的定制選項,如縮進、換行符等。#include <iostream> #include <string> #include <sstream> #include <memory> #include <jsoncpp/json/json.h> int main() {Json::Value root;root["name"] = "joe";root["sex"] = "男";Json::StreamWriterBuilder wbuilder; // StreamWriter 的工廠std::unique_ptr<Json::StreamWriter> writer(wbuilder.newStreamWriter());std::stringstream ss;writer->write(root, &ss);std::cout << ss.str() << std::endl;return 0; }$ ./test.exe { "name" : "joe", "sex" : "男" }這次的代碼示例中我們沒有展示如何定制,不過AI之后就可以了解到:


反序列化:
????????反序列化指的是將序列化后的數據重新轉換為原來的數據結構或對象。Jsoncpp 提供了以下方法進行反序列化:1.使用 Json::Reader:○優點:提供詳細的錯誤信息和位置,方便調試。#include <iostream> #include <string> #include <jsoncpp/json/json.h> int main() { // JSON 字符串 std::string json_string = "{\"name\":\"張三\", \"age\":30, \"city\":\"北京\"}"; // 解析 JSON 字符串 Json::Reader reader; Json::Value root; // 從字符串中讀取 JSON 數據 bool parsingSuccessful = reader.parse(json_string, root); if (!parsingSuccessful) { // 解析失敗,輸出錯誤信息 std::cout << "Failed to parse JSON: " << reader.getFormattedErrorMessages() << std::endl; return 1; } // 訪問 JSON 數據 std::string name = root["name"].asString(); int age = root["age"].asInt(); std::string city = root["city"].asString(); // 輸出結果 std::cout << "Name: " << name << std::endl; std::cout << "Age: " << age << std::endl; std::cout << "City: " << city << std::endl; return 0; } $ ./test.exe Name: 張三 Age: 30 City: 北京
?在今天的demo代碼中,我們采取部分自定義+JSON
????????????????????????????????
可以避免1+22+3的歧義,不知道是1+2? 2+3還是1+22+3
3. 網絡計算器
網絡計算器:
????????上面已經基本介紹了一些概念,下面基于TCP實現一個網絡計算器,通過這個計算器更深刻得去理解上面的概念????????網絡計算器的基本功能就是客戶端發送計算表達式(本次只實現五種運算,分別是:+、-、*、/和%),服務端接收到計算表達式后通過相關接口對這個表達式進行處理并將結果返回給客戶端
現在就來構思這個網絡計算器,如何通過協議模塊以及之前的TCP框架進行傳輸。
今天的demo都是基于【LINUX網絡】使用TCP簡易通信-CSDN博客中實現的TCP框架進行的
socket code of TCP demo · 78028f9 · lsnmjp/code of cpp Linux 算法 - Gitee.com
使用JSON進行序列化?
????????很明顯,客戶端傳過去的是諸如“1+2”,服務器要傳回去的是“3,正確計算”或者“0xfffff,非正常計算”等字段。
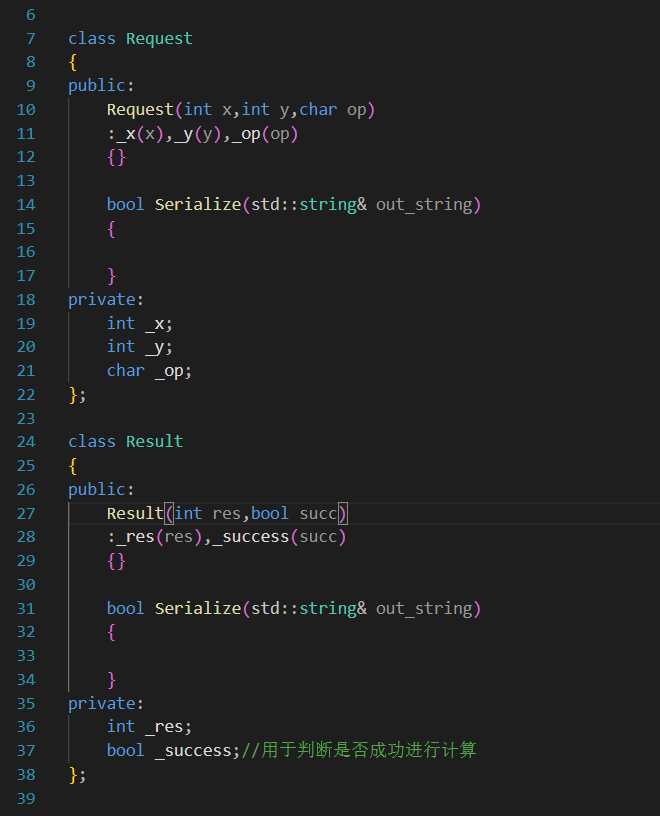
? ? ? ? 所以,需要把這兩種數據都進行結構化,一個是class Request,另一個是class Resluat
客戶端生成Req,經過序列化之后傳到服務器,服務器經過反序列化獲得Req,丟給運算邏輯函數,運算邏輯函數會返回Res需要的數據,再生成一個Res之后經過序列化傳給客戶端。
并且,兩個類還需要搭配相應的序列化函數和反序列化函數。
????????
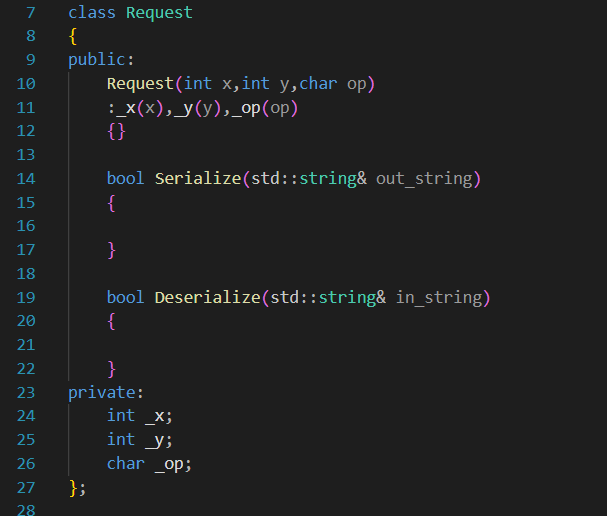
?前面我們提到了,應用層需要我們自行進行檢查,得到的報文是不是完整的(read或者recv得到的不一定是完整的一個Res或者Req),所以其實在設計應用層時,到時候還需要設計類似的檢測“報頭”的函數
編碼來看看細節:
所以到時候在main函數里大概是:
Request req(10,20,"+"); string str; req.Serialize(str); 相當于str是一個輸出型參數
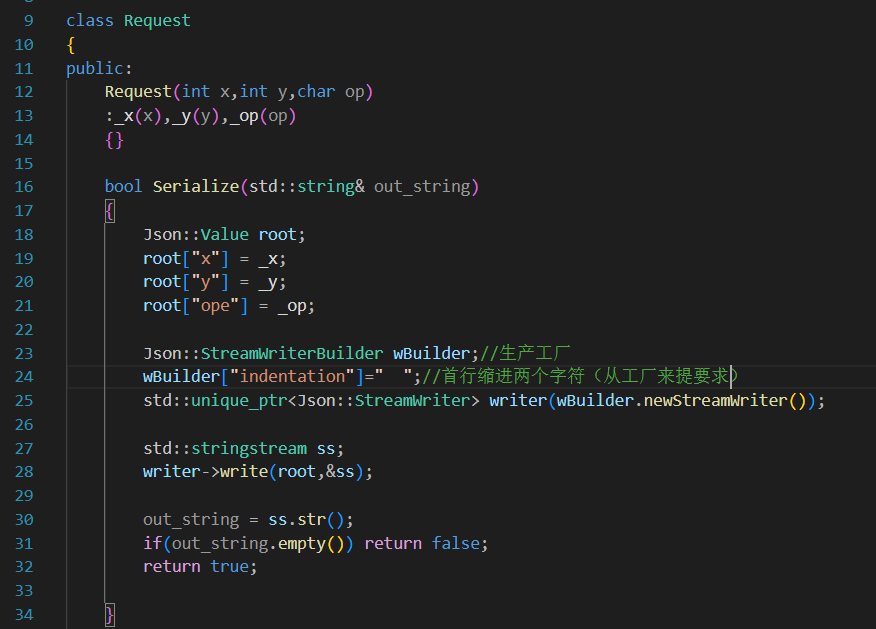
寫進去的時候自動判斷是什么類型的,拿出來的時候需要手動指定是什么類型的
bool Deserialize(std::string& in_string){//反序列化Json::Value root;Json::Reader reader;bool ParseSuccess = reader.parse(in_string,root);if(!ParseSuccess){LOG(LogLevel::ERROR)<<"Parse Failed";return false;}//使用Json數據_res = root["res"].asInt();_success = root["y"].asBool();return true;}簡單一個測試
#include "Protocol.hpp" #include <iostream> #include <string>int main() {Request req(10,20,'+');std::string out;req.Serialize(&out);std::cout<<out<<std::endl;req.Deserialize(out);req.Print();return 0; }
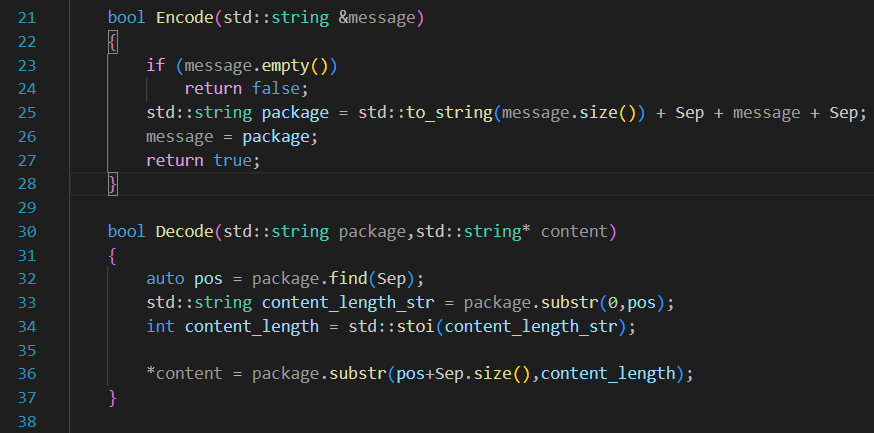
序列化得到了報文,現在為了在應用層區分每一條消息(一次完整的x和y的計算),我們使用一個Encode函數和Decode函數來添加、取消報頭,希望我們的每一次完整格式都是:
12\r\n{JSON}\r\n? ? 、 34\r\n{JSON}\r\n? ?其中,前面的數表示后面JSON串的長度
應用層添加報頭?
Encode可以給每一個配置好的JSON串添加報頭:
?
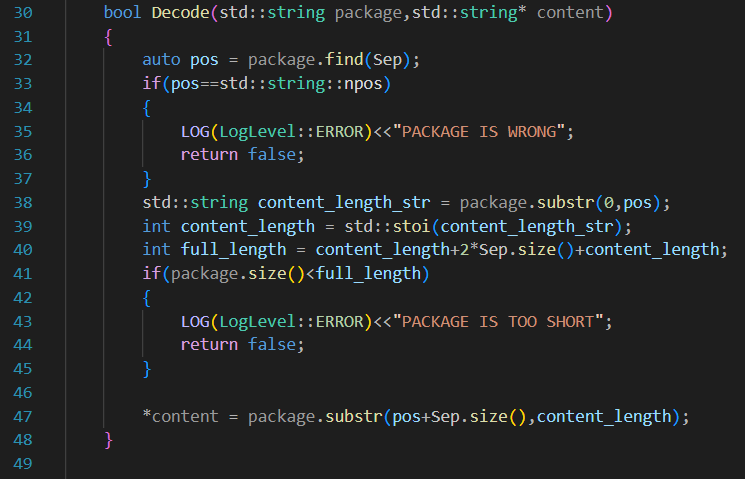
為了增加代碼的健壯性,大概處理下Decode中可能出現的各種問題:
1.避免可能整個包不完整的情況
? ? ? ? 通過計算一個full_length來避免一條報文過于短
2.避免壓根沒找到Sep
? ? ? ? 通過判斷pos來決定。? ? ? ??
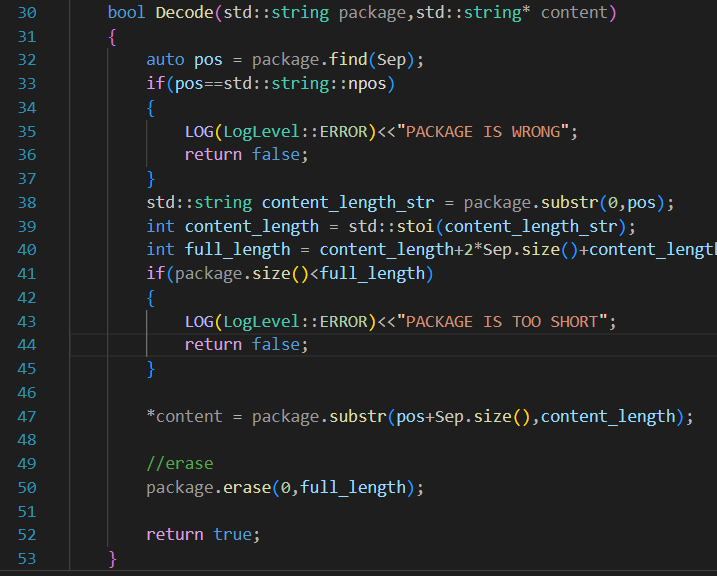
3. 有可能送了好幾條完整的報文,需要能剔除前面的完整的、已經被獲取的報文
諸如:12\r\n{JSON}\r\n
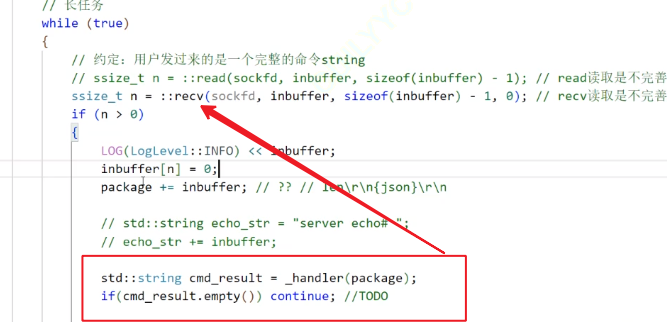
?回歸Server.hpp。對于recv函數,由于tcp通信的特性,放到inbuffer里的可能是半個Request(序列化后的JSON串),可能是一個,也可能是多個。同樣,下面的send也是不完善的
那么,我們是不是需要一個package用來存每一輪接受到inbuffer里的內容,再對這個package進行解析,拿走完整的JSON,讓留在package里面的半個json等待下一輪的inbuffer傳進來。
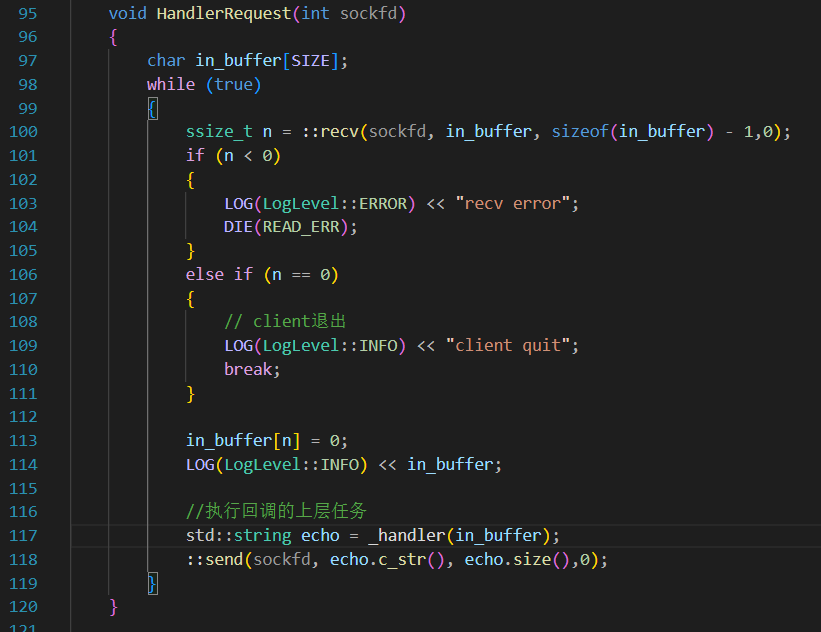
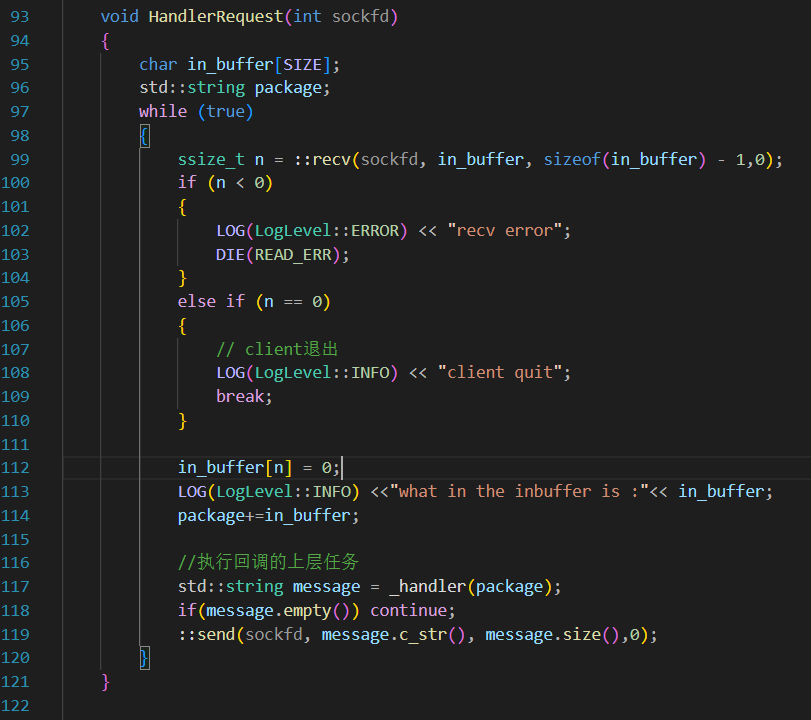
當然,HandleRequest作為“網絡計算器”這個程序的在網絡通信層中處理任務的模塊,肯定不該被用于處理類似于“package是不是不完善”的問題,只管把這個package丟給中間層就可以了?
只需要知道,_handler返回的也一定是一個被序列化的Response結構體,所以這個_handler不應該直接傳給計算器層,應該傳給一個用于解析的中間層。不過,如果是調用別人的庫的話,這種中間層都是應該直接被寫好的,只不過我們今天是純手搓,所以必須實現這一層Decode和Desiralize
實現一下計算器
計算器的邏輯就不過多贅述了。
這個Calculator的參數和返回值就很能說明序列化的必要性,只針對兩個結構進行運算
????????
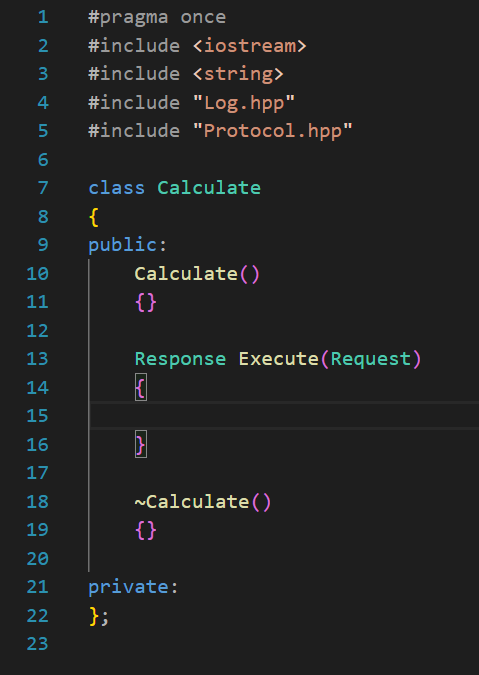
此處的計算器本身的業務邏輯應該就不需要多說了:
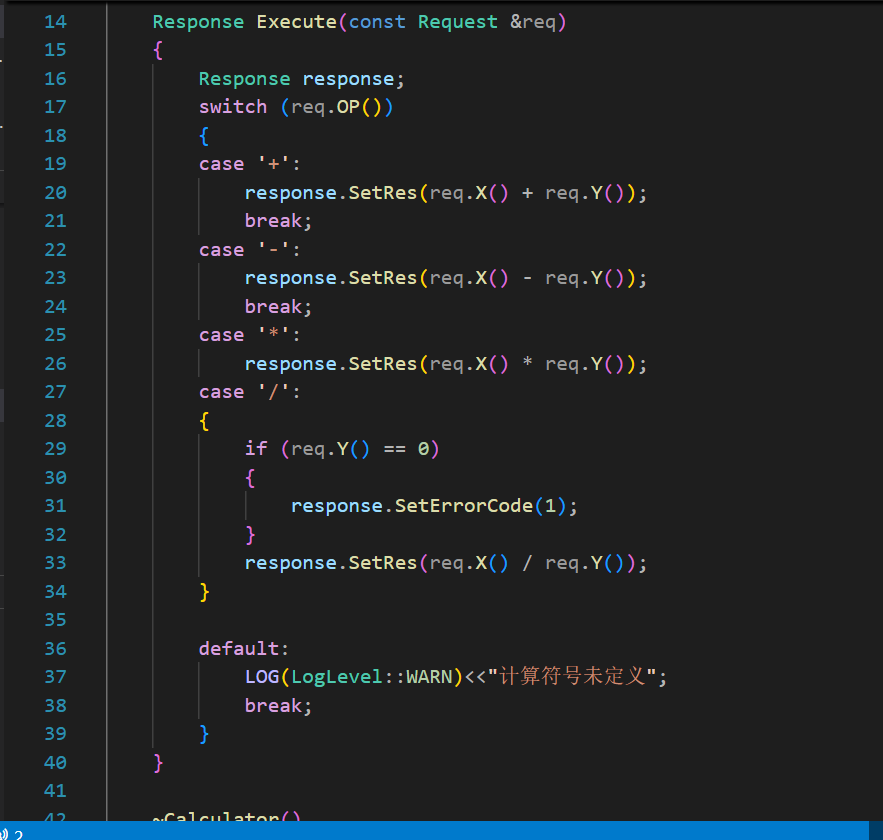
將計算功能注冊進入服務中
注冊進入之后,保證整個TCP層就只需要負責IO了。
using Cal_t = std::function<Response(Request)>;class Parse
{
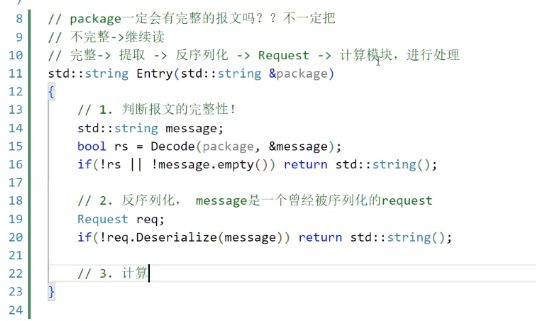
public:Parse(Cal_t cal): _cal(cal){}std::string Parse2Entry(std::string &package){std::string message; // package解包之后的信息// 1.解包bool ret = Decode(package, &message);if (!ret || message.empty()){// 如果Decode失敗,返回空串,這樣在Server.hpp中就可以去重新recvreturn std::string();}// 2.反序列化Request req;if (!req.Deserialize(message)){LOG(LogLevel::ERROR) << "反序列化失敗";return std::string();}// 3.計算Response ans;ans = _cal(req);// 4.序列化std::string message_back;if (!ans.Serialize(&message_back)){LOG(LogLevel::ERROR) << "序列化失敗";}// 5.添加報頭if (!Encode(message_back)){LOG(LogLevel::ERROR) << "Encode failed";}}private:Cal_t _cal;
};如上述代碼,解碼、解析等工作主要就是靠這個Decode
之前寫的Decode就有這個功能:1、探測報文完整性。2、報文完整就提取出來
保證返回為true,并且content不為空。
解碼成功的時候:
如果Decode失敗,或者message是空,那么我們就返回一個空串。
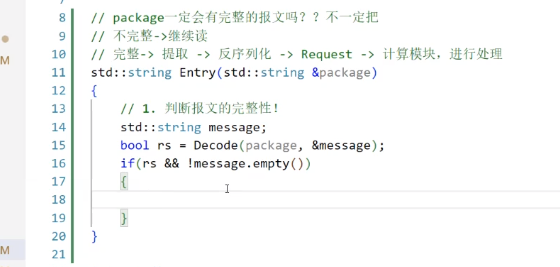
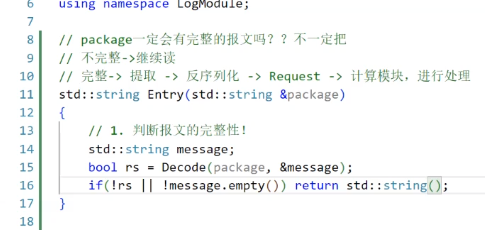
而一旦返回一個空串(對于服務器)
就會執行continue,從而繼續recv
這也體現了package+=的意義,如果在_handler中package沒有被處理,那么我們就可以通過+=
從而拿到完整的報文?
一旦拿到這個message,此時的message就是一個曾經被序列化的request
為了健壯性,如果反序列化失敗,還是要返回一個空串
????????
走到最后一步,就是計算(也可以像演示中的代碼那樣,直接using一個新的函數類別,這樣能形成類之間的解耦合)
現在要返回的是一個Response的結果,應以被序列化過的狀態去返回
?
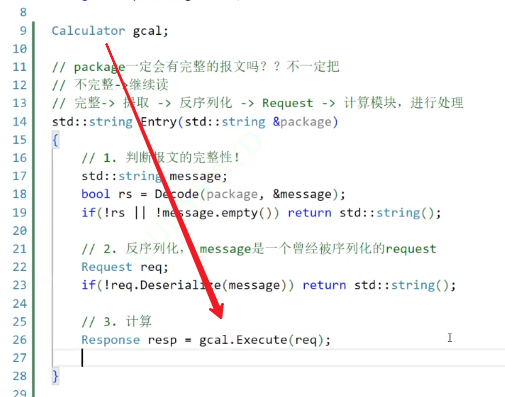

所以現在的整個代碼就形成了三層:計算器、分析、服務器
package處理多個完整JSON
????????如果 一個package里有多個完整的請求該怎么辦呢?還需要簡單修改一下剛剛的parse邏輯。
????????package有點像生產消費隊列中的生產者
只要package不為空,就可以一直去decode package,不過也因此package必須要傳引用
?std::string Parse2Entry(std::string &package){std::string message; // package解包之后的信息std::string return_response_str;// 1.解包while (!Decode(package, &message)){if (message.empty()){// 如果Decode失敗,返回空串,這樣在Server.hpp中就可以去重新recvreturn std::string();}// 2.反序列化Request req;if (!req.Deserialize(message)){LOG(LogLevel::ERROR) << "反序列化失敗";return std::string();}// 3.計算Response ans;ans = _cal(req);// 4.序列化std::string message_back;if (!ans.Serialize(&message_back)){LOG(LogLevel::ERROR) << "序列化失敗";}// 5.添加報頭if (!Encode(message_back)){LOG(LogLevel::ERROR) << "Encode failed";}return_response_str+=message_back;}//可能是多個JSON拼接的return_response_strreturn return_response_str;}
主程序
現在的主程序就非常清晰了,只需要一層一層的使用lambda綁定進去就可以了
注意,給tcp_server綁定的時候package也必須傳引用,否則還是存在不能解決多個JSON串的問題。
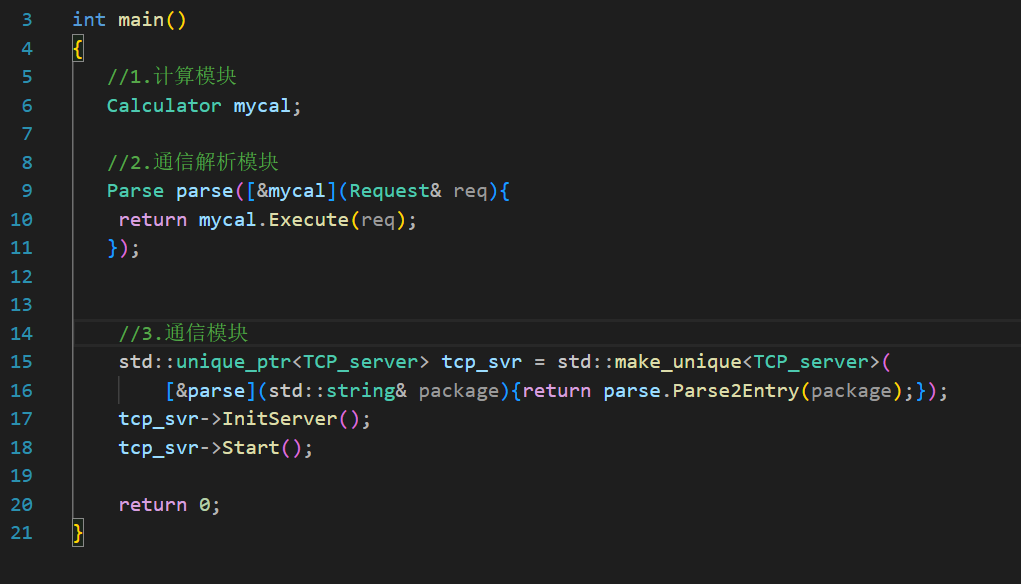
客戶端(簡化)
客戶端就可以直接按照序列化、Decode的順序來做:
注意,第四步的位置應該是要加循環的,必須保證recv到了一個完整的、可以被Decode的字符串才行
簡單測試一下:
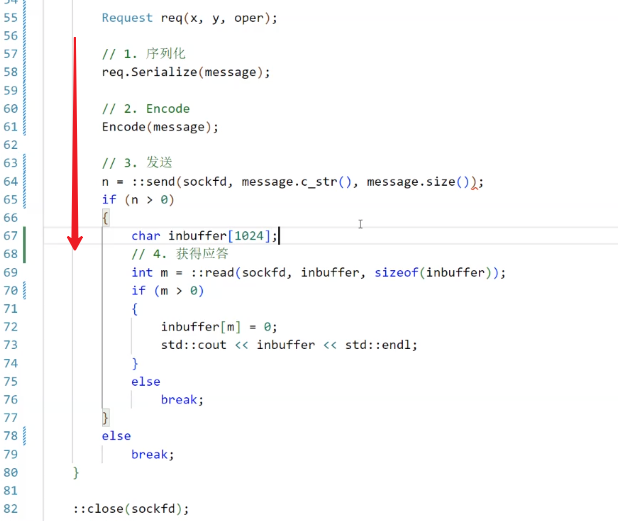
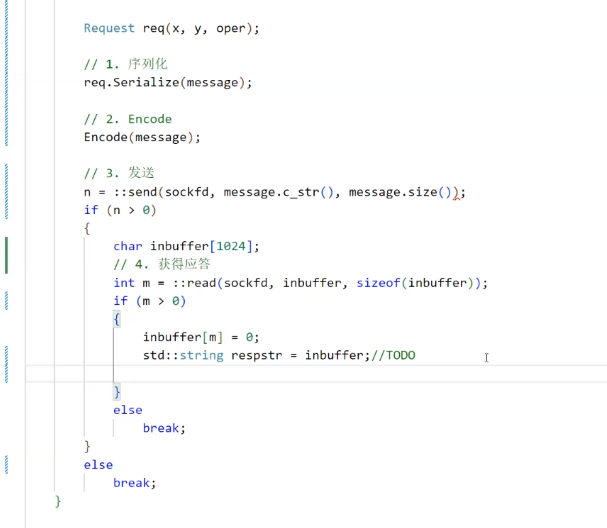
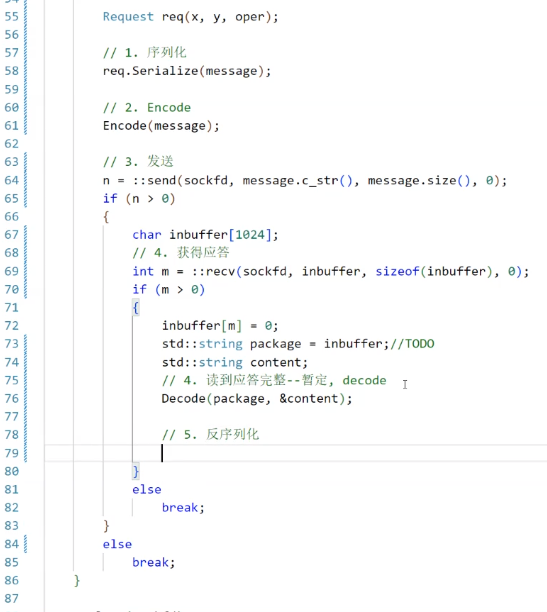
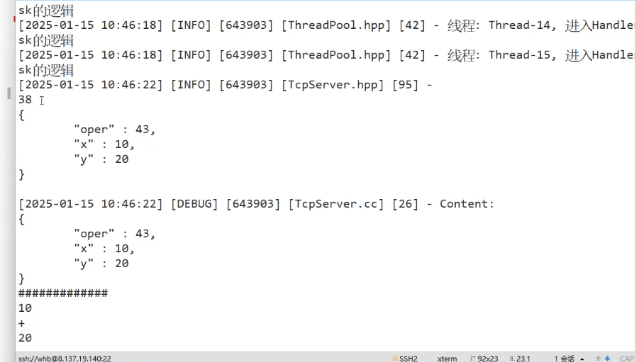
-------------------------------------------------------code end--------------------------------------------------------------
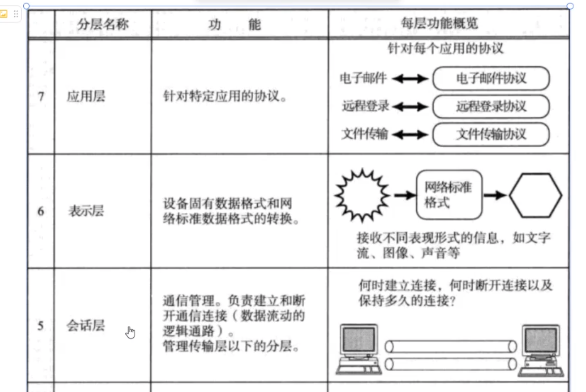
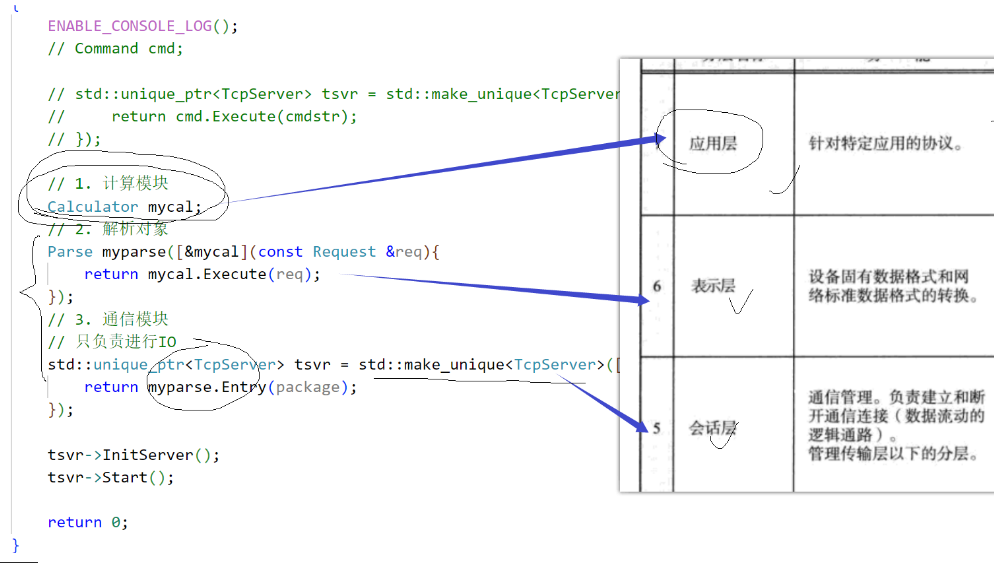
4. 再看OSI七層模型與TCP/IP四層協議
在比較 OSI 七層模型和 TCP/IP 模型時,我們可以觀察到兩者在低四層上是相同的。這種一致性的本質原因在于,這四層的功能是可以通過操作系統實現的。為了確保網絡通信的順暢進行,這四層的實現必須是統一的。
然而,當我們將目光轉向 OSI 七層模型的上三層時,情況就有所不同了:
????????
會話層(Session Layer):這一層主要負責通信管理,定義了客戶端和服務器之間如何進行通信。這一功能的實現依賴于操作系統底層的接口,因此,會話層實際上是對下四層通信的管理和協調。在網絡計算器的設計中,這一層對應于客戶端和服務端的通信設計。再直白一點,這一層就是使用TCP這些接口的代碼
表示層(Presentation Layer):一旦客戶端和服務端能夠正常通信,接下來的關鍵問題就是確定通信的具體內容。表示層負責設定傳輸內容的格式,確保雙方能夠識別并正確解析彼此的數據。在網絡計算器的實現中,這一層對應于序列化和反序列化的過程,以及編碼和解碼的操作。這一層就是parse層次
應用層(Application Layer):最后,我們需要定義傳輸的內容,即結構化數據的設置。在網絡計算器中,這一層對應于請求類和響應類的字段定義。這一層就是計算器
這三層緊密相連,缺少任何一層都會導致通信無法正確進行。TCP/IP 協議將 OSI 模型的這三層合并為一層的原因在于,這些功能無法由操作系統具體實現,它們屬于操作系統之上的應用層面。這種合并簡化了模型,同時保持了網絡通信的核心功能。
)










--計數排序,排序算法復雜度對比和穩定性分析)
)
)


:繪圖)


