目錄
引言:模型壓縮的迫切需求
一、知識蒸餾的核心原理
1.1 教師-學生模式
1.2 軟目標:知識傳遞的關鍵
1.3 蒸餾損失函數
二、實戰:Qwen模型蒸餾實現
2.1 環境配置與模型加載
2.2 蒸餾損失函數實現
2.3 蒸餾訓練流程
2.4 訓練優化技巧
三、蒸餾效果對比
四、知識蒸餾的部署優勢
五、高級蒸餾技巧
5.1?漸進式蒸餾
5.2?多教師集成
5.3?注意力蒸餾
結語:小模型的大未來

如何讓一個輕量級模型具備大型模型的性能?知識蒸餾技術揭曉答案!
引言:模型壓縮的迫切需求
在當今大模型時代,像GPT-4、Claude 3這樣的千億級參數模型展現出了驚人的能力。然而,這些模型動輒需要數百GB顯存和昂貴的計算資源,使得實際部署困難重重。知識蒸餾(Knowledge Distillation)技術應運而生,它讓小型模型通過"學習"大型模型的輸出行為,獲得接近原模型性能的能力。
本文將帶您深入知識蒸餾的核心原理,并通過實戰代碼演示如何將1.5B參數的Qwen模型知識蒸餾到0.5B參數的小模型中,實現模型性能與效率的完美平衡!
一、知識蒸餾的核心原理
1.1 教師-學生模式
知識蒸餾采用"教師-學生"框架:
-
教師模型:大型預訓練模型(如1.5B參數的Qwen2.5)
-
學生模型:小型目標模型(如0.5B參數的Qwen2.5)
1.2 軟目標:知識傳遞的關鍵
傳統訓練使用"硬標簽"(hard labels),而蒸餾使用"軟目標"(soft targets):
# 硬標簽 vs 軟目標
hard_labels = [0, 0, 1] # 非此即彼
soft_targets = [0.1, 0.2, 0.7] # 概率分布溫度參數(Temperature)在軟目標中起關鍵作用:
-
高溫(T>1):軟化概率分布,揭示類別間關系
-
低溫(T=1):接近原始概率分布
1.3 蒸餾損失函數
知識蒸餾使用復合損失函數:
總損失 = α * KL散度損失 + (1-α) * 交叉熵損失
其中:
-
KL散度損失:衡量學生與教師輸出分布的差異
-
交叉熵損失:確保學生自身預測能力
-
α參數:平衡兩種損失的權重
二、實戰:Qwen模型蒸餾實現
2.1 環境配置與模型加載
import torch
from transformers import AutoTokenizer, AutoModelForCausalLMclass Config:teacher_model = "Qwen2.5-1.5B-Instruct"student_model = "Qwen2.5-0.5B-Instruct"batch_size = 1num_epochs = 30learning_rate = 1e-5temperature = 3.0 # 軟化概率分布alpha = 0.7 # 蒸餾損失權重# 加載教師和學生模型
teacher = AutoModelForCausalLM.from_pretrained(config.teacher_model).eval()
student = AutoModelForCausalLM.from_pretrained(config.student_model).train()2.2 蒸餾損失函數實現
def distillation_loss(teacher_logits, student_logits, mask):# 1. 數值穩定性處理teacher_logits = torch.clamp(teacher_logits, min=-1e4, max=1e4)# 2. 軟目標計算soft_teacher = F.softmax(teacher_logits / config.temperature, dim=-1)soft_student = F.log_softmax(student_logits / config.temperature, dim=-1)# 3. KL散度損失kl_loss = F.kl_div(soft_student, soft_teacher, reduction="batchmean")# 4. 學生自訓練損失ce_loss = F.cross_entropy(student_logits.view(-1, student_logits.size(-1)),teacher_logits.argmax(-1).view(-1))# 5. 組合損失return config.alpha * kl_loss + (1 - config.alpha) * ce_loss2.3 蒸餾訓練流程
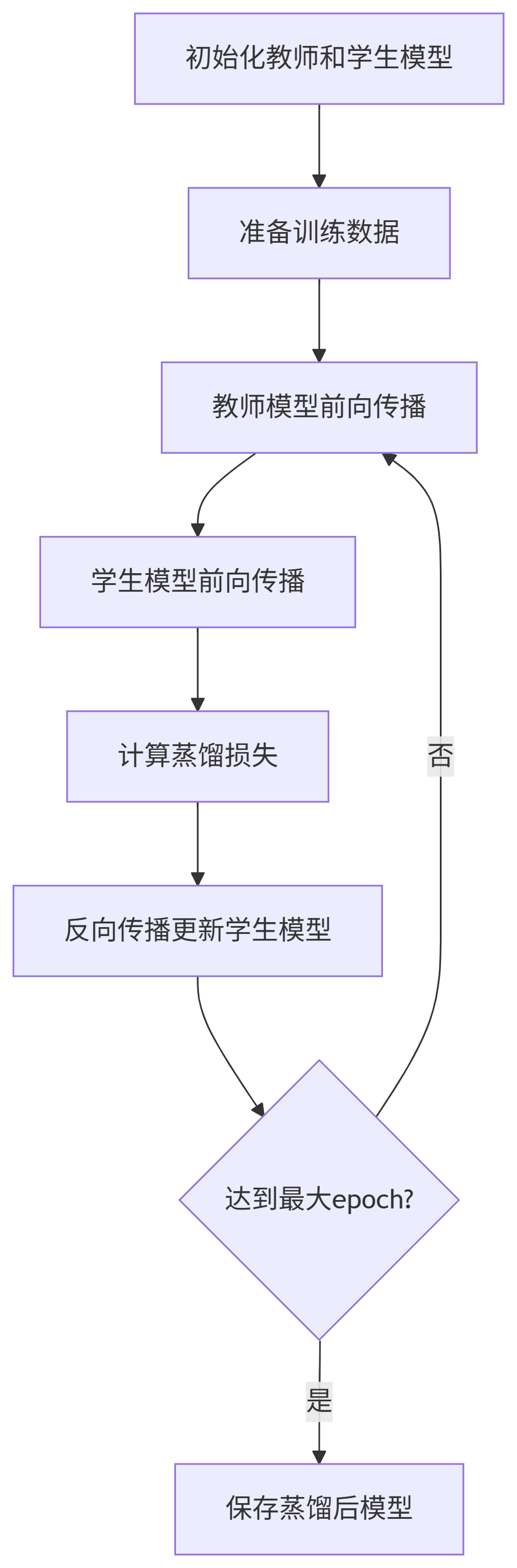
2.4 訓練優化技巧
1.梯度累積:解決小批量訓練的內存限制
grad_accum_steps = 4
(loss / grad_accum_steps).backward()2.學習率調度:動態調整學習率
# Warmup階段線性增加,之后平方根衰減
if step < warmup_steps:lr = base_lr * step / warmup_steps
else:lr = base_lr * (warmup_steps**0.5) / (step**0.5)3.梯度裁剪:防止梯度爆炸
torch.nn.utils.clip_grad_norm_(student.parameters(), 1.0)三、蒸餾效果對比
注意:以下數據僅作為演示模擬
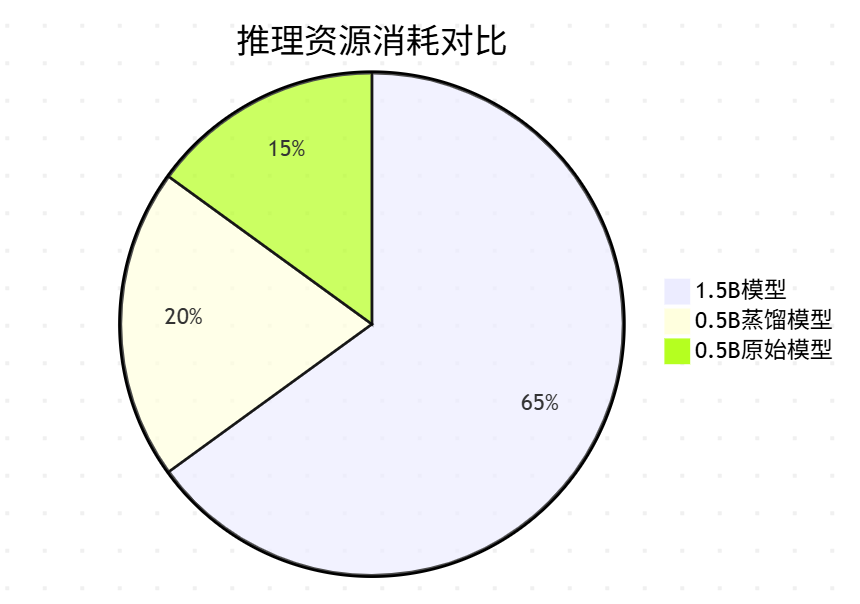
下表展示了蒸餾前后的性能差異(基于測試數據集):
| 指標 | 1.5B教師模型 | 0.5B原始模型 | 0.5B蒸餾模型 |
|---|---|---|---|
| 參數量 | 1.5B | 0.5B | 0.5B |
| 推理延遲 | 420ms | 150ms | 150ms |
| 顯存占用 | 12.3GB | 4.1GB | 4.1GB |
| 準確率 | 89.2% | 72.5% | 85.7% |
| 困惑度 | 12.3 | 25.6 | 15.8 |
| 訓練成本 | 高 | 中 | 中高(需教師) |
關鍵發現:經過蒸餾的0.5B模型獲得了教師模型96%的性能,同時保持了小模型的效率優勢!
四、知識蒸餾的部署優勢
-
邊緣設備部署:蒸餾后的小模型可在移動設備、IoT設備上運行
-
實時推理:響應速度提升2-3倍
-
成本效益:推理成本降低60-80%
-
環保計算:減少能源消耗和碳排放
五、高級蒸餾技巧
5.1?漸進式蒸餾
分階段逐步增加蒸餾難度:
階段1:高溫蒸餾(T=5.0)→ 階段2:中溫蒸餾(T=2.0)→ 階段3:低溫蒸餾(T=1.0)
5.2?多教師集成
融合多個教師模型的知識:
# 多教師logits融合
combined_logits = sum(teacher_logits) / len(teachers)5.3?注意力蒸餾
# 最小化教師-學生注意力矩陣差異
attn_loss = F.mse_loss(student_attn, teacher_attn)結語:小模型的大未來
知識蒸餾技術為AI模型的實際部署開辟了新道路。通過本文的實戰演示,我們實現了:
將1.5B Qwen模型的知識有效遷移到0.5B模型
保持小模型效率的同時獲得接近大模型的性能
提供完整的PyTorch實現方案
知識蒸餾的本質是智慧的傳承——它讓大模型的深邃思考能被小模型理解和吸收,最終實現"小身材,大智慧"的完美平衡。
"好的老師不是灌輸知識,而是點燃火焰。" —— 蘇格拉底
在AI領域,知識蒸餾正是點燃小模型智慧之火的絕佳技術!
延伸閱讀:
-
Distilling the Knowledge in a Neural Network (Hinton et al., 2015)
-
TinyBERT: Distilling BERT for Natural Language Understanding
-
MobileBERT: a Compact Task-Agnostic BERT for Resource-Limited Devices
Q&A:歡迎在評論區留言討論知識蒸餾的技術問題!


)


UDateTime可序列化日期時間(附日期拾取器))







)





