?
【MySql】事務的原理
- 數據庫的隔離級別原理
- 讀未提交
- 讀已提交
- 可重復讀(Repeatable Read)
- 串行化(最高的隔離級別,強制事務串行執行,避免了所有并發問題)
- MVCC(Multi-Version Concurrency Control多版本并發控制)
- UNDO日志版本鏈(數據庫原子性原理)
- 介紹
- UNDO的實現
- Read View(一致性視圖)
- ***Read View的執行流程***
- Read View的可見性規則
- 數據庫的一致性
- 持久性
- 事務的優化
事務:要么全部成功要么全部失敗,目的是為了保證數據最終的一致性。
數據庫的隔離級別原理
在事務并發執行時,他們內部的操作不能互相干擾,隔離 性由MySQL的各種鎖以及MVCC機制來實現
先了解下面三個概念
- 臟讀(Dirty Read)
指一個事務讀取到了另一個未提交事務修改的數據。 - 不可重復讀(Non-Repeatable Read)
指同一個事務內,兩次讀取同一數據時,結果不一致(因為中間被其他已提交事務修改 / 刪除了)。 - 幻讀(Phantom Read)
指同一個事務內,兩次執行相同的查詢語句時,返回的結果集行數不一致(因為中間被其他已提交事務新增 / 刪除了符合條件的記錄)。 - 可重復讀
可重復讀的核心目標是:保證同一事務內,多次讀取同一數據時,結果始終一致,不受其他已提交事務的修改影響,從而避免 “不可重復讀” 問題。
例子:在這個事務執行的時候,InnoDB 會為該事務創建一個 一致性視圖(Read View),他事務即使修改了數據并提交,只要當前事務沒結束,就看不到這些修改(因為視圖沒變)。 - 臟寫(Dirty Write)
是指一個事務修改了另一個未提交事務已經修改過的數據。
比如:事務 A 修改數據 X 為 100(未提交);
事務 B 此時也修改數據 X 為 200(未提交);
最終無論 A/B 是否提交,A 的修改都會被 B 覆蓋(或反之),導致未提交的中間狀態被直接覆蓋。
所以不建議在 Java 代碼中先讀取數據、在內存中計算(如做加法),再更新回數據庫。這種方式在并發場景下很容易出現 “更新丟失” 問題,而應該盡量通過數據庫層面的原子操作來實現。
優先用數據庫原子操作(推薦)
示例:給用戶余額加 100 元
// 條件構造器:更新id=1的用戶,balance = balance + 100
UpdateWrapper<User> updateWrapper = new UpdateWrapper<>();
updateWrapper.eq("id", 1).setSql("balance = balance + 100"); // 直接在數據庫層面計算// 執行更新(底層生成 SQL:UPDATE user SET balance = balance + 100 WHERE id = 1)
userMapper.update(null, updateWrapper);
讀未提交
讀未提交(Read Uncommitted)
最低的隔離級別,允許一個事務讀取另一個未提交事務的數據
可能出現的問題:臟讀、不可重復讀、幻讀
適用場景:對數據一致性要求極低,追求最高并發性能的場景
SET transaction_isolation = 'READ-UNCOMMITTED';
BEGIN;
select * from app_userw where id = 1;
使用讀未提交事務進行修改
SET transaction_isolation = 'READ-UNCOMMITTED';-- 開啟事務
BEGIN;-- 執行更新操作
UPDATE app_userw
SET age = 30
WHERE id = 1;
我并沒有提交更新但是讀到的age已經被修改成了30這就是讀未提交(READ UNCOMMITTED)

在這種情況下如果使用代碼去讀就會”臟讀“。
讀已提交
讀已提交(Read Committed)
跟上面不一樣的點則是如果未提交則不能被讀
保證一個事務只能讀取另一個已提交事務的數據
解決了臟讀問題,但仍可能出現不可重復讀和幻讀
適用場景:大多數關系型數據庫的默認隔離級別(如 SQL Server、Oracle),適用于對數據一致性有一定要求的場景
可重復讀(Repeatable Read)
確保同一事務中多次讀取同一數據的結果一致
解決了臟讀和不可重復讀問題,但仍可能出現幻讀
適用場景:MySQL 的默認隔離級別,適用于需要保證數據可重復讀取的場景
串行化(Serializable)
實現原理:
第一次查的時候都是查視圖,除非使用了update等操作才會進行數據的更新,但是也僅限于更新的那條數據而已,其他的數據還是視圖的數據。
串行化(最高的隔離級別,強制事務串行執行,避免了所有并發問題)
解決了臟讀、不可重復讀和幻讀所有問題
適用場景:對數據一致性要求極高,但可以接受極低并發性能的場景
對事務操作的數據加鎖(如表鎖、行鎖、范圍鎖),阻止其他事務同時修改或讀取。例如,事務 A 操作某行數據時,其他事務必須等待 A 完成后才能操作。
MVCC(Multi-Version Concurrency Control多版本并發控制)
MVCC 通過 “版本鏈存儲歷史數據 + Read View 判斷可見性” 的機制,巧妙地讓讀寫操作并行執行,同時通過事務 ID 和可見性規則保證隔離性。
數據庫事務是通過MVCC機制來實現的,其核心思想是通過UNDO保存數據的多個歷史版本,讓讀寫操作在不阻塞彼此的情況下并行執行,同時保證事務隔離性。
InnoDB 會為每個數據行自動添加三個隱藏列,用于版本管理:
DB_TRX_ID:記錄最后一次修改該行數據的事務 ID(6 字節)。
DB_ROLL_PTR:回滾指針(7 字節),指向該行的上一個歷史版本(存儲在 undo 日志中)。
DB_ROW_ID:若表沒有主鍵,InnoDB 會自動生成該列作為隱含主鍵(6 字節)。
UNDO日志版本鏈(數據庫原子性原理)
介紹
UNDO 日志作為版本鏈的載體,不僅支撐了 MVCC,還為事務回滾提供了基礎,是數據庫高并發能力的核心技術之一。 記錄事務對數據的修改操作(如插入、更新、刪除)的反向操作,用于在事務回滾或需要讀取歷史版本時恢復數據。
若事務執行失敗(如代碼異常、數據庫崩潰),數據庫會通過 undo 日志反向執行所有操作,將數據恢復到事務開始前的狀態,保證 “全不做”。
1.事務提交機制
事務只有在顯式執行COMMIT時,所有修改才會被確認(持久化到磁盤);若執行ROLLBACK或異常終止,數據庫直接根據 undo 日志回滾,確保 “全不做”。
2.崩潰恢復
數據庫崩潰后重啟時,會通過事務日志(如 InnoDB 的 redo log 和 undo log) 檢查未完成的事務:對已提交的事務,確保修改生效;對未提交的事務,通過 undo 日志回滾,避免殘留中間狀態。
UNDO的實現
trx_id是事務的唯一id,roll_poiner是回滾指針,指向前一條數據,如果出現了問題就會通過這個回滾指針回滾到上一個版本,每個事務都是單獨的,第一條事務的id就是他自己。
注意(begin/start transaction 命令并不是一個事務的起點,在執行到它們之后第一條執行的修改操作的InnoDB語句事務才真正的啟動,才會像數據庫申請事務id(trx_id),mysql內部是嚴格按照事務的啟動順序來分配id。)
每一次的修改就是把上一個的事務的事務id寫到roll_poiner中并且在新增一個新的trx_id,不管事務有沒有執行commit他都會存儲在這個版本鏈里面
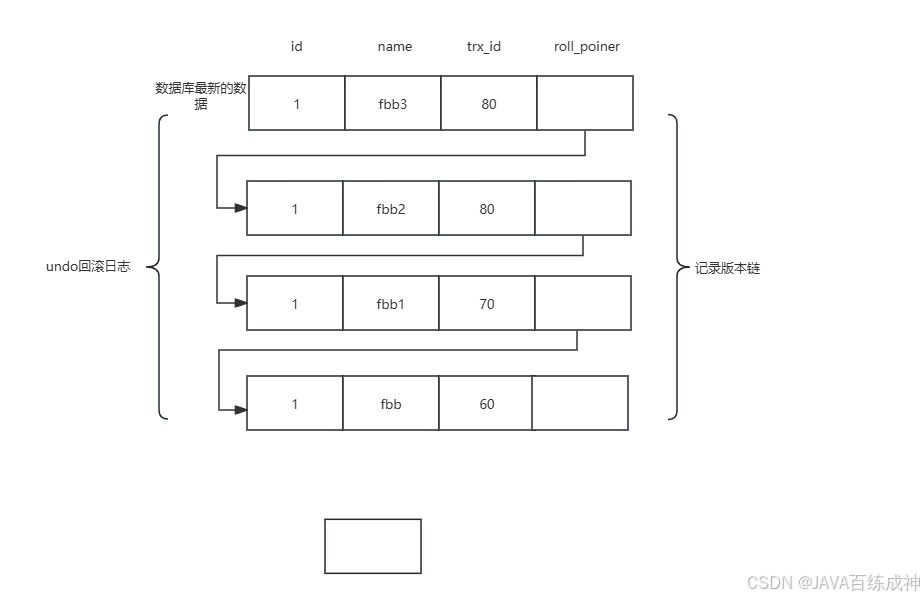
這種機制既保證了事務的原子性(要么全做,要么全不做),又為多版本并發控制提供了基礎。
Read View(一致性視圖)
Read View 是 MVCC 中判斷數據版本可見性的依據。
他有4 個參數:
m_ids:當前未提交的活躍事務 ID 數組
min_trx_id:活躍事務中最小的 ID
max_trx_id:下一個要分配的事務 ID(未開始的事務)這是一個全局遞增的計數器,用于為新事務分配唯一 ID。
creator_trx_id:當前事務自己的 ID
組成規則:
這個視圖包含查詢時所有未提交事務的 ID 數組,以及該數組中的最小事務 ID、已創建的最大事務 ID,同時還包括生成此視圖的當前事務自身 ID,共同作為判斷數據版本可見性的依據。
Read View的執行流程
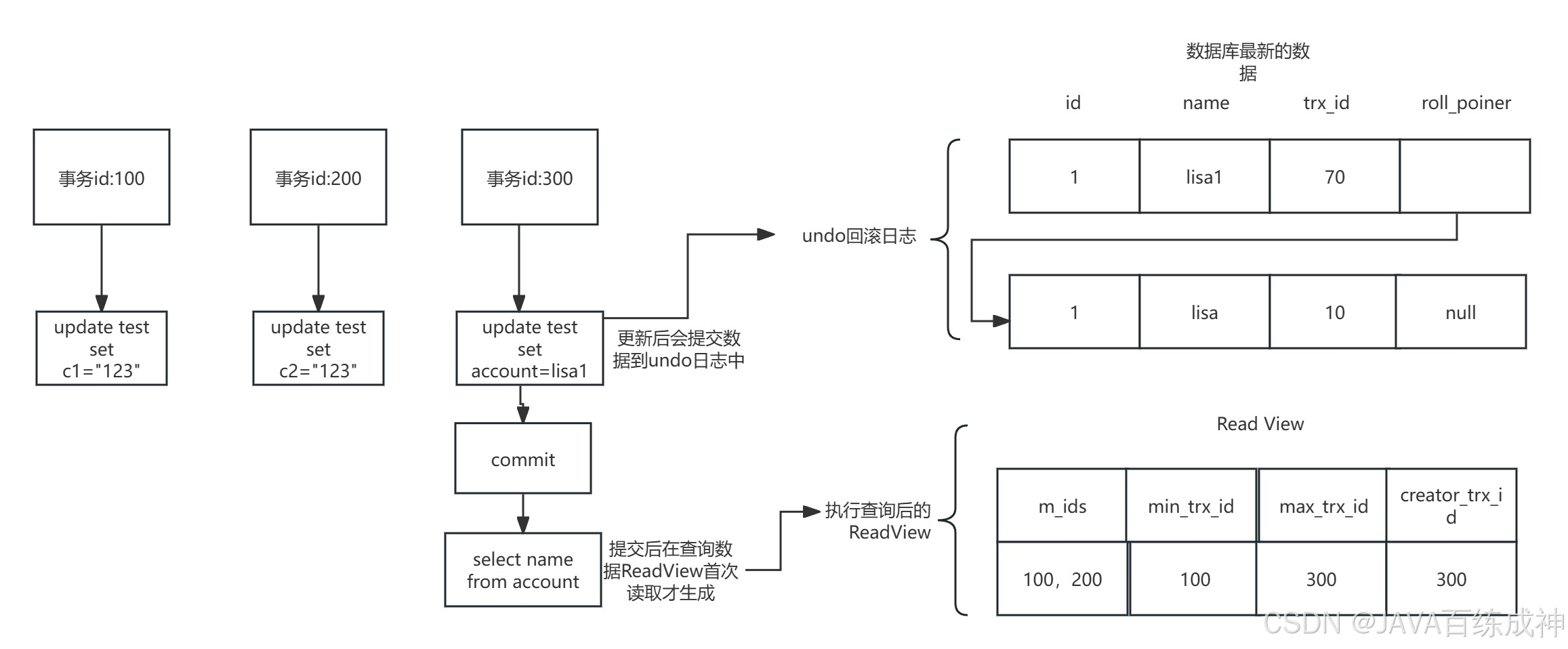
圖里事務 300 提交后執行查詢,此時生成 Read View 時,會記錄當前數據庫里的活躍事務(也就是未提交的事務,比如圖里的 100、200 ,因為 300 自己提交了,不算活躍了),用來決定查詢能看到哪些版本的數據。
注意:
只要事務第一次需要讀數據 ,InnoDB 就會給這個事務生成一個 Read View 。一旦生成,在可重復讀(Repeatable Read)隔離級別 下,這個 Read View 會跟著事務走到底。
Read View的可見性規則
在可重復讀隔離級別,當事務開啟,執行任何查詢sql時會生成當前事務的一致性視圖read-view,該視圖在事務結束之前都不會變化(如果是讀已提交隔離級別在每次執行查詢sql時都會重新生成),這個視圖由執行查詢時所有未提交事務id數組(數組里最小的id為min_id)和已創建的最大事務id(max_id)組成,事務里的任何sql查詢結果需要從對應版本鏈(undo回滾日志)里的最新數據開始逐條跟read-view做比對從而得到最終的視圖結果。
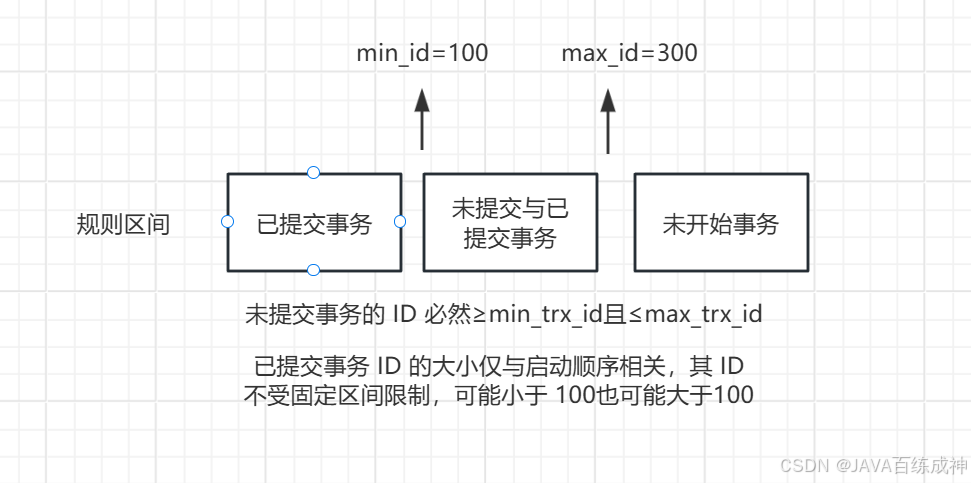
在讀已提交的隔離級別中, Read View的讀取規則是有變化的,在可重復讀中只有第一次查詢的 Read View視圖會從表里面拿最新的數據而在讀已提交的隔離級別中每一次查詢都會去數據庫中拿一份新的來生成一個 Read View最新的值是什么 Read View里面就是什么,底層和可重復讀也是通過版本鏈來比對。
數據庫的一致性
一致性是 ACID 的最終目標,其他三個特性(原子性、隔離性、持久性)以及業務代碼正確邏輯來實現的。
原子性確保事務不殘留中間狀態;
隔離性避免并發事務相互干擾(如臟讀導致的數據邏輯錯誤);
持久性確保已提交的合法狀態不丟失。
持久性
一旦提交了事務,它對數據庫的改變是永久性的,持久性由redo log日志來實現。
REDO LOG 稱為重做日志,提供再寫入操作,恢復提交事務修改的頁操作,用來保證事務的持久性
這篇文章的介紹比較詳細。
【MySql】數據庫Redo日志介紹
事務的優化
事務優化原則
1.將查詢等數據準備操作放到事務外
2.事務中避免遠程調用,若必須進行遠程調用則要設置超時,防止事務等待時間過久
3.事務中避免一次性處理太多數據,可以拆分成多個事務分次處理
4.更新等涉及加鎖的操作盡可能放在事務靠后的位置
5.能異步處理的盡量異步處理
6.應用側(業務代碼)保證數據一致性,采用非事務方式執行(當業務邏輯相對簡單時,可以不依賴數據庫事務,而是通過 Java 等業務代碼手動實現數據一致性保障)
最后避免大事務



)



)
)

 - 加法器)



)
傳輸層(上)運輸層協議概述)


vllm在線啟動集成openweb-ui)
)
