一、基本認知
1.1目標檢測的定義
? ? ? ? 目標檢測(Object Detection):在圖像或視頻中檢測出目標圖像的位置,并進行分類和識別的相關任務。
? ? ? ? 主要是解決圖像是什么,在哪里的兩個具體問題。
1.2使用場景
? ? ? ? 目標檢測的使用場景眾多,比如疫情期間有是否帶口罩的目標檢測,現在十分火爆的智能駕駛、安防監控、人臉檢測等都用到了目標檢測。
1.3目標識別與標注
? ? ? ? 目標識別包含了分類標簽信息和圖像坐標信息(x,y,w,h),其中(x,y)是中心點的位置坐標,w為寬度,h為高度。
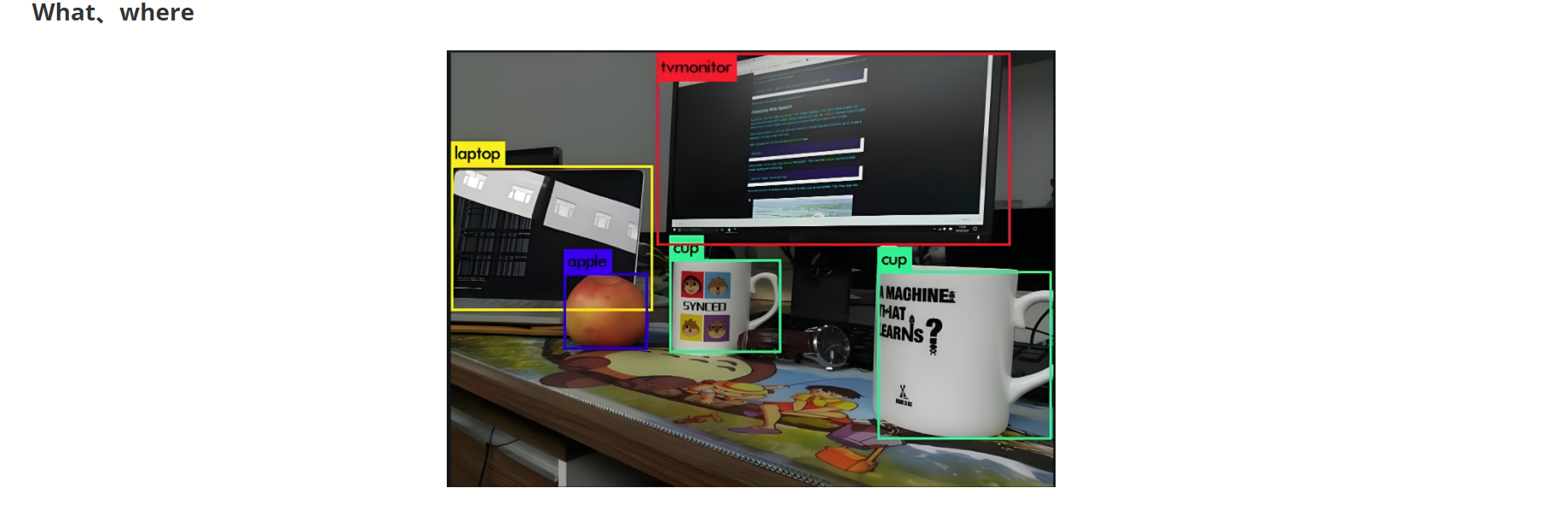
????????目標標注可以選擇使用labelimg或者labelme ,但是常用的是labelimg,它可以直接生成txt文件,直接用在YOLO算法中。
? ? ? ? labelimg下載指令:
#創建虛擬環境
conda create -n labelenv python=3.9 -y
#激活虛擬環境
conda activate labelenv
#下載pyqt和sip
conda install -c conda-forge pyqt=5.15.4 sip=6.5.1 -y
#阿里云下載labelimg,注釋的內容是降低Set的版本的,根據實際情況查看是否需要
#pip install setuptools==65.5.0 -i https://mirrors.aliyun.com/pypi/simple/
pip install labelimg==1.8.6 -i https://mirrors.aliyun.com/pypi/simple/
#啟動labelimg開始進行圖像標注
labelimg二、網絡基礎
2.1目標檢測方法
? ? ? ? 這里主要介紹一步到位法:one-stage
one-stage是單階段,一步到位,特點如下:
(1)直接從圖像中提取特征并進行分類和回歸,即同時進行目標分類、位置回歸;
(2)計算速度快,適合實時使用;
(3)經典算法:YOLO系列、SSD。
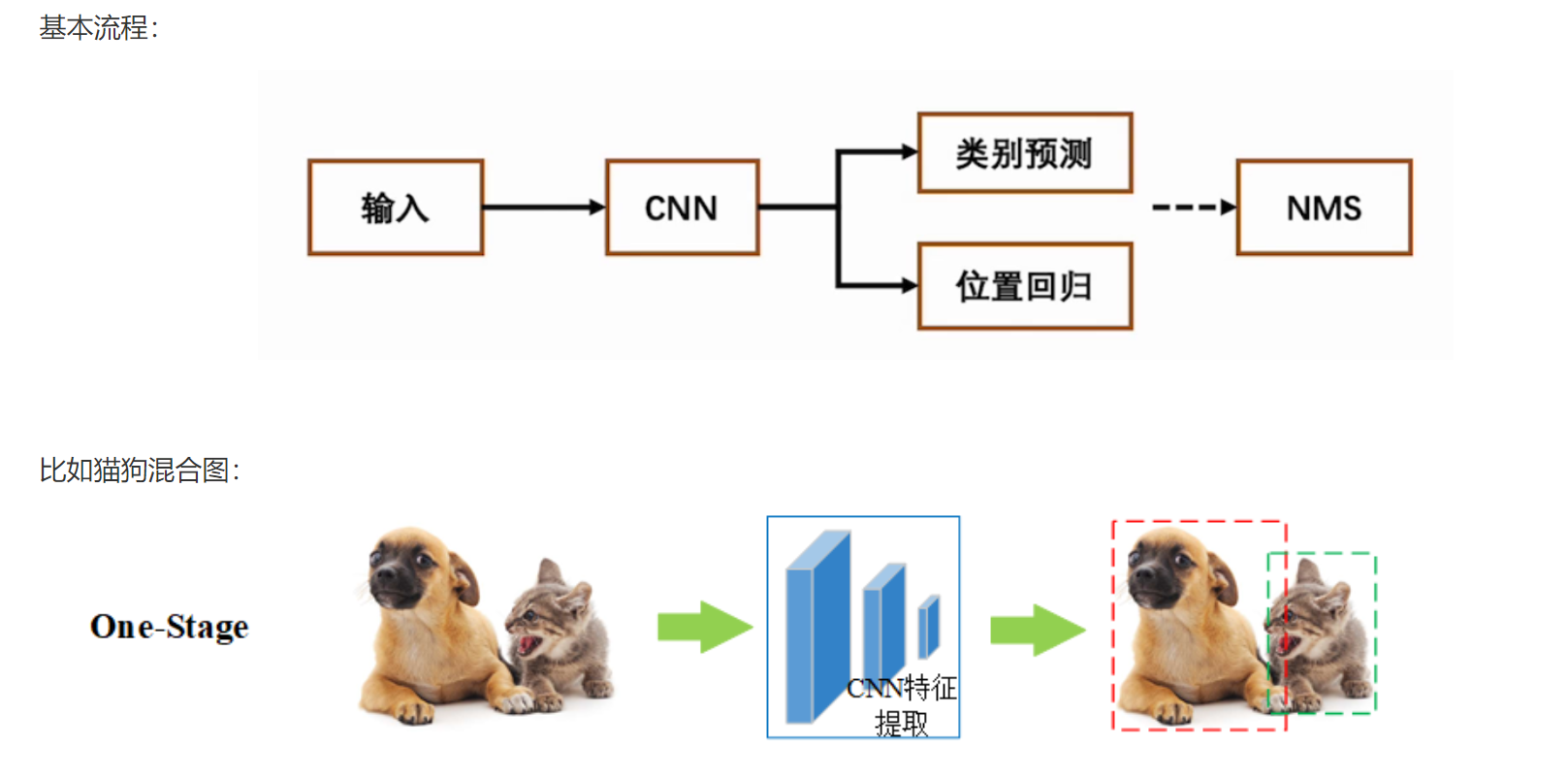
????????注意:NMS?是?Non-Maximum Suppression(非極大值抑制)?的縮寫,是一種用于去除冗余檢測框的關鍵后處理技術。?
2.2目標檢測指標
2.2.1目標框指標
? ? ? ? 目標框(Bounding Box):檢測目標物體時,會帶有的一個標注框,用于表示目標的位置和大小。
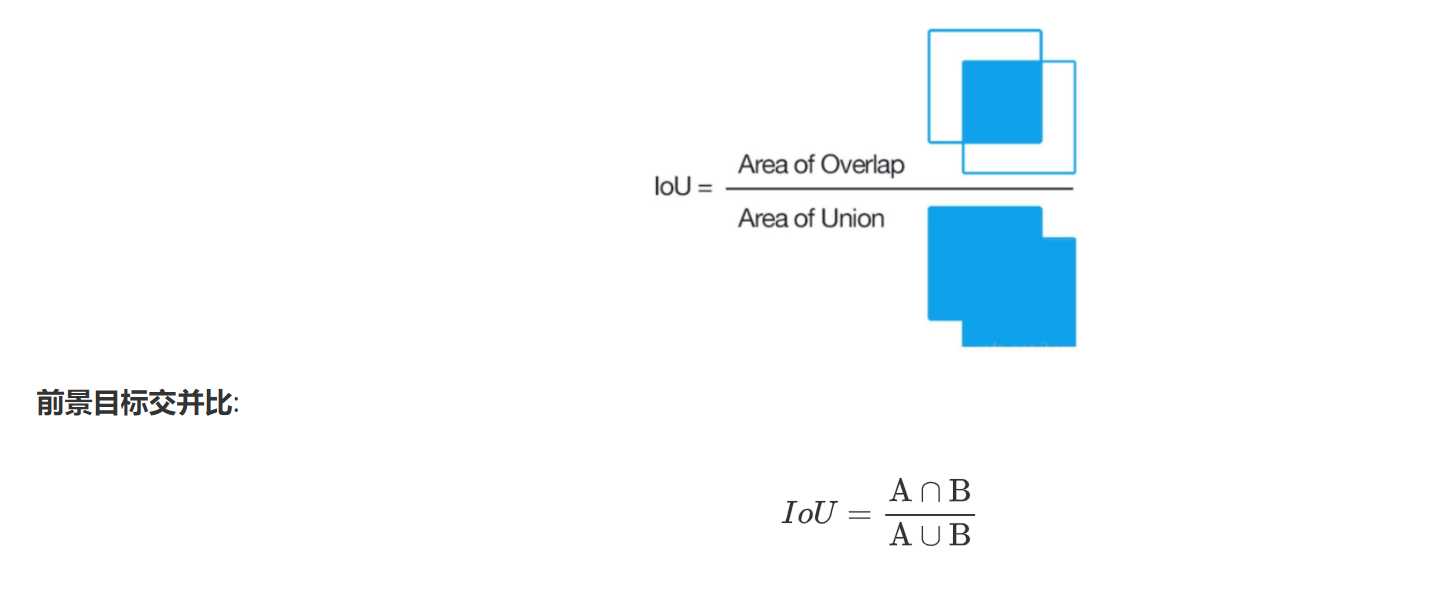
IoU
IoU:預選框正確性的度量指標,其中A通常表示真實框,B表示預測框。計算公式如下:
confidence
confidence:置信度,表示該框包含目標的概率以及預測框的定位準確性。
計算公式:

2.2.2精度和召回率
? ? ? ? 在了解精度和召回率之前,我們要了解的是混淆矩陣:
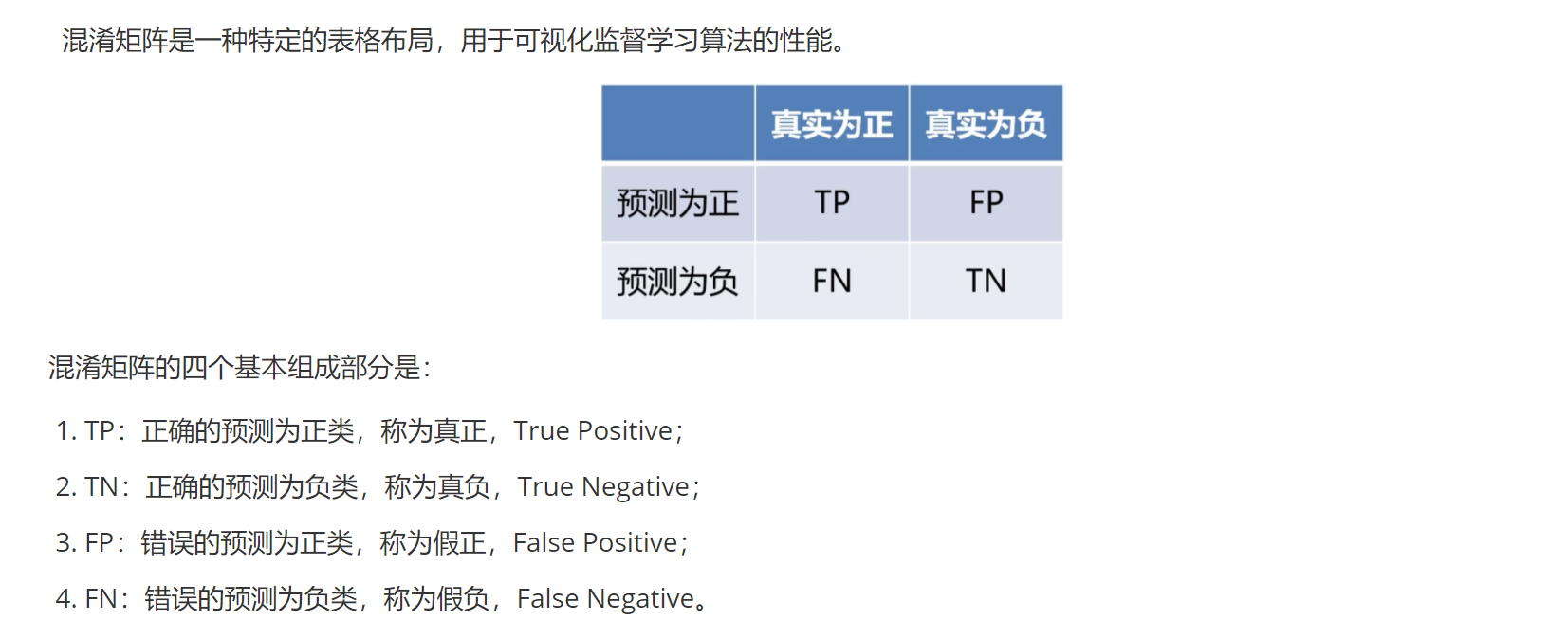
?????????注意:這里的正類和負類不能按照平常認知來區分,只要是根據目標任務的要求來,若要求檢測的是工廠里的殘次品,那么此刻這里的正類就是殘次品。
????????準確度:預測正確的樣本數與總數的比例
A = TP+TN/(TP+TN+FP+FN)
????????精確度:正類中預測正確的比例
P = TP/(TP+FP)
????????召回率:目標檢測中找到的正類的比例
R = TP/(TP+FN)
????????F1分數:精確度和召回率的平均數
F = 2*(P * R)/(P + R)
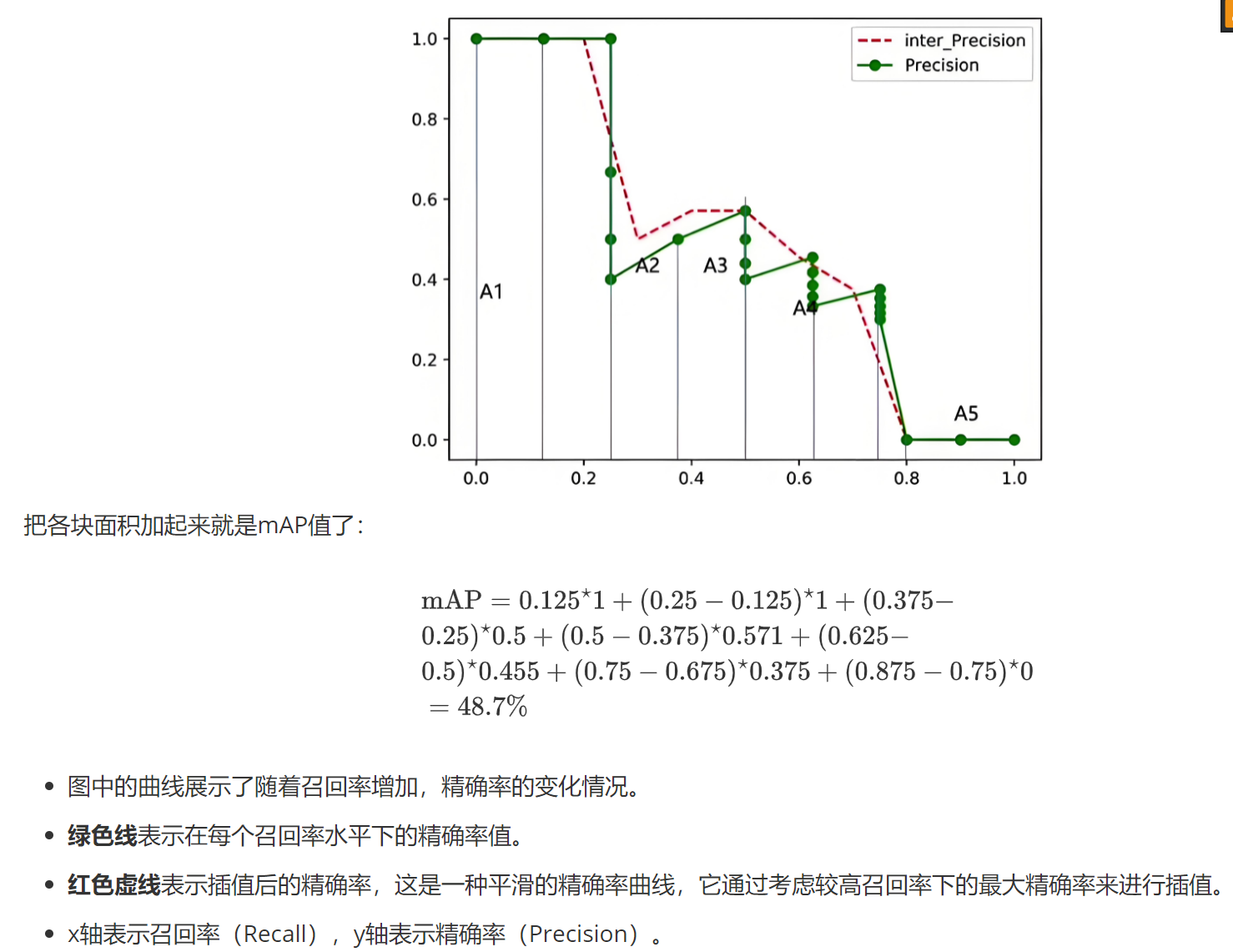
2.2.3mAP的計算
? ? ? ? mAP是評估模型的綜合指標,主要是根據召回率和精確度進行計算的。但是暫時只記錄AP的計算方法。
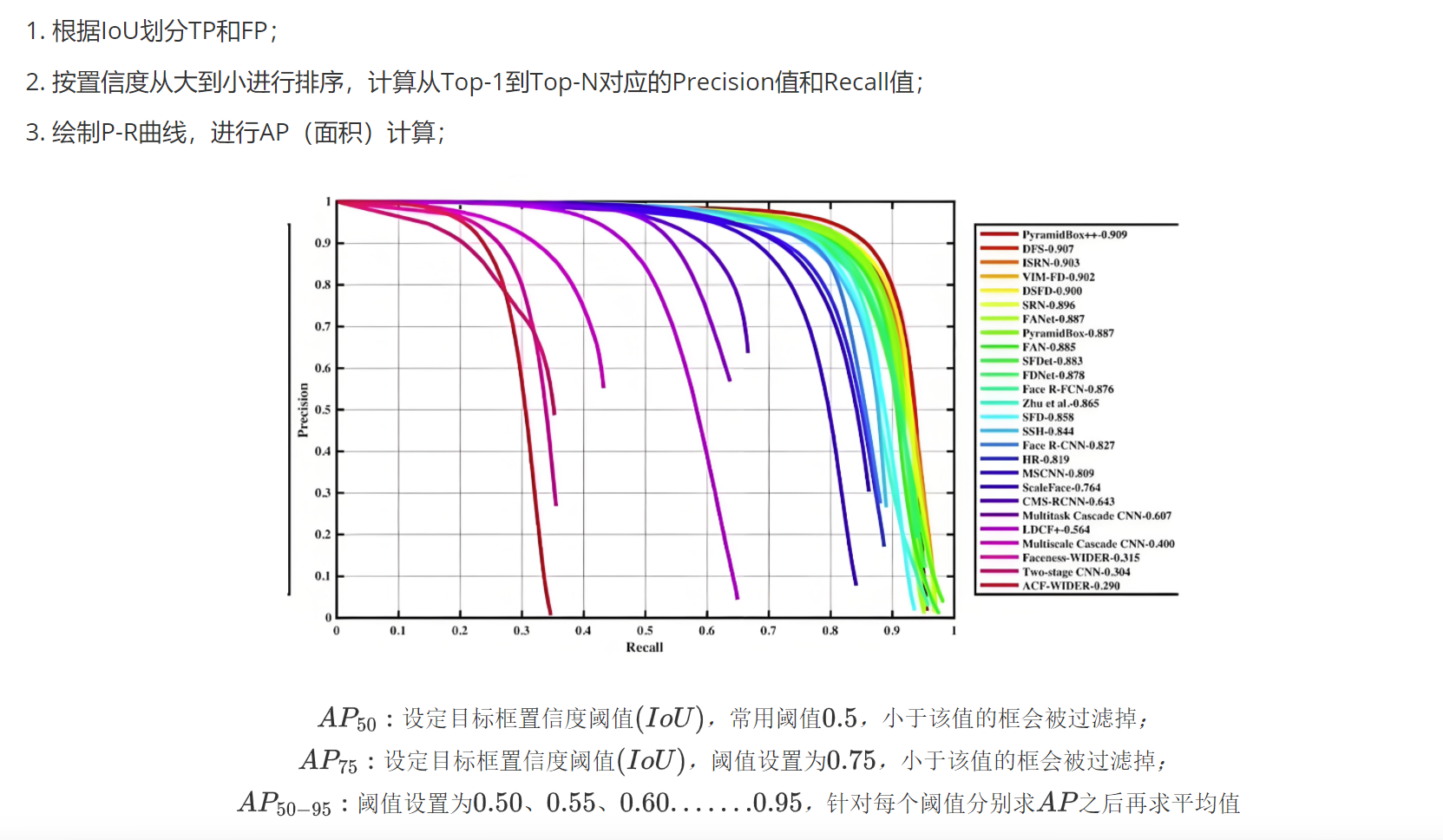
Top-N:?返回前N個框計算指標
AP(平均精度):
(1)根據公式計算,直接求平均值得到AP值
(2)還是會利用公式,然后根據最大值所在高度的矩形面積相加得到AP值
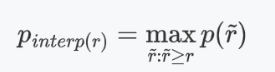 ?
?
三、NMS
3.1簡單介紹
? ? ? ? NMS(Non-Maxmum suppression)非極大值抑制:是目標檢測目標庫后處理的方法。
它的出現主要是為了解決對同一個檢測目標出現多個目標框的問題。
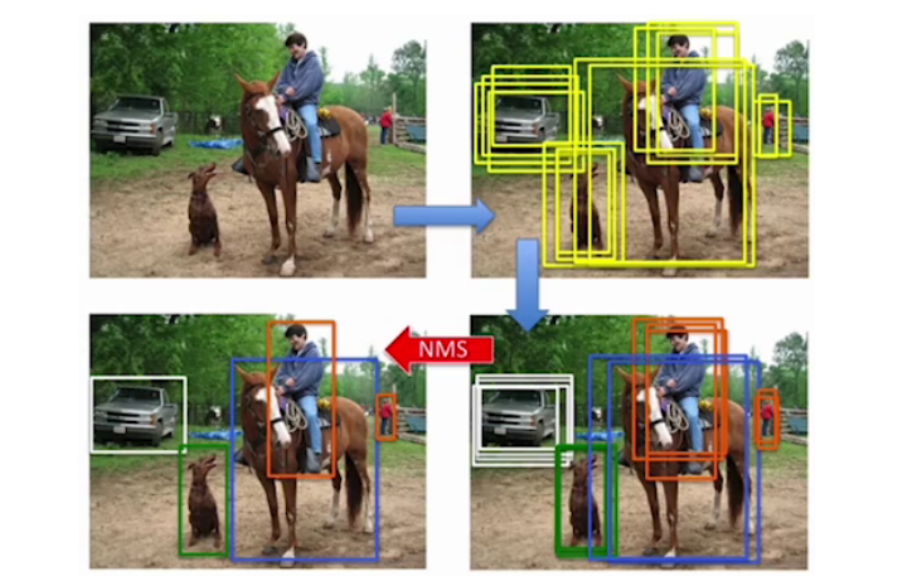
如圖,在最后的結果中,我們往往只需要一個最終的,最準確的目標框,所以NMS就發揮了很大的作用。
3.2運算流程
(1)設置IoU(目標框置信度閾值),一般設為0.5,小于這個值的框會被過濾,一般是用來過濾網格中心Bounding Box中沒有預測到目標的目標框;
(2)根據置信度進行降序排列候選框;
(3)將置信度最大的框添加到輸出列表,并將這個框從候選框中刪除;
(4)候選框中的所有框與輸出列表的框計算IoU,刪除大于IoU閾值的框(這是因為大于閾值的框可能與目標框相似,預測的是同一個目標,這就有一個去重的意思在的感覺)
(5)重復三、四步驟,直到候選框列表為空;
(6)輸出列表就是最后的目標框。
3.3 API
pred?=?non_max_suppression(pred,conf_thres=0.25,iou_thres=0.45,classes,agnostic_nms,max_det=max_det)
參數解釋:
classes:
類別限制(Classes):這個參數用于指定只對特定類別的目標進行NMS操作。如果它是一個整數(例如
classes=0),則僅對類別0的目標進行NMS;如果它是一個列表(例如classes=[0, 2, 3]),則僅對類別0、2、3的目標進行NMS。如果不傳遞該參數,NMS會對所有類別進行操作。
agnostic_nms:
類別無關的NMS(Class-Agnostic NMS):如果該參數設置為
True,NMS會忽略目標的類別信息,所有的框會一起進行NMS處理,不論它們屬于哪個類別。如果設置為False(默認值),則會分別對每個類別進行NMS操作,意味著同一類別的框才會相互抑制,而不同類別的框不會相互影響。
max_det=max_det:
最大檢測數量(Maximum Detection):這個參數控制NMS后返回的最大框數。它限制了每張圖片中最多保留多少個框(目標)。例如,
max_det=100表示每張圖片最多保留100個框,超出這個數量的框會被刪除。
四、檢測速度
4.1前傳耗時
? ? ? ? 從輸入圖像到輸出結果所消耗的時間。單位毫秒。
4.2FPS
? ? ? ? FPS(frames per second),每秒鐘能處理的圖像數量。YOLO目標檢測中要求實時監測的最低要求就是一秒鐘處理30張圖像。
4.3FLOPs
? ? ? ? 浮點運算量,處理一張圖像所需要的浮點運算數量。
五、整體網絡結構
5.1網絡結構圖
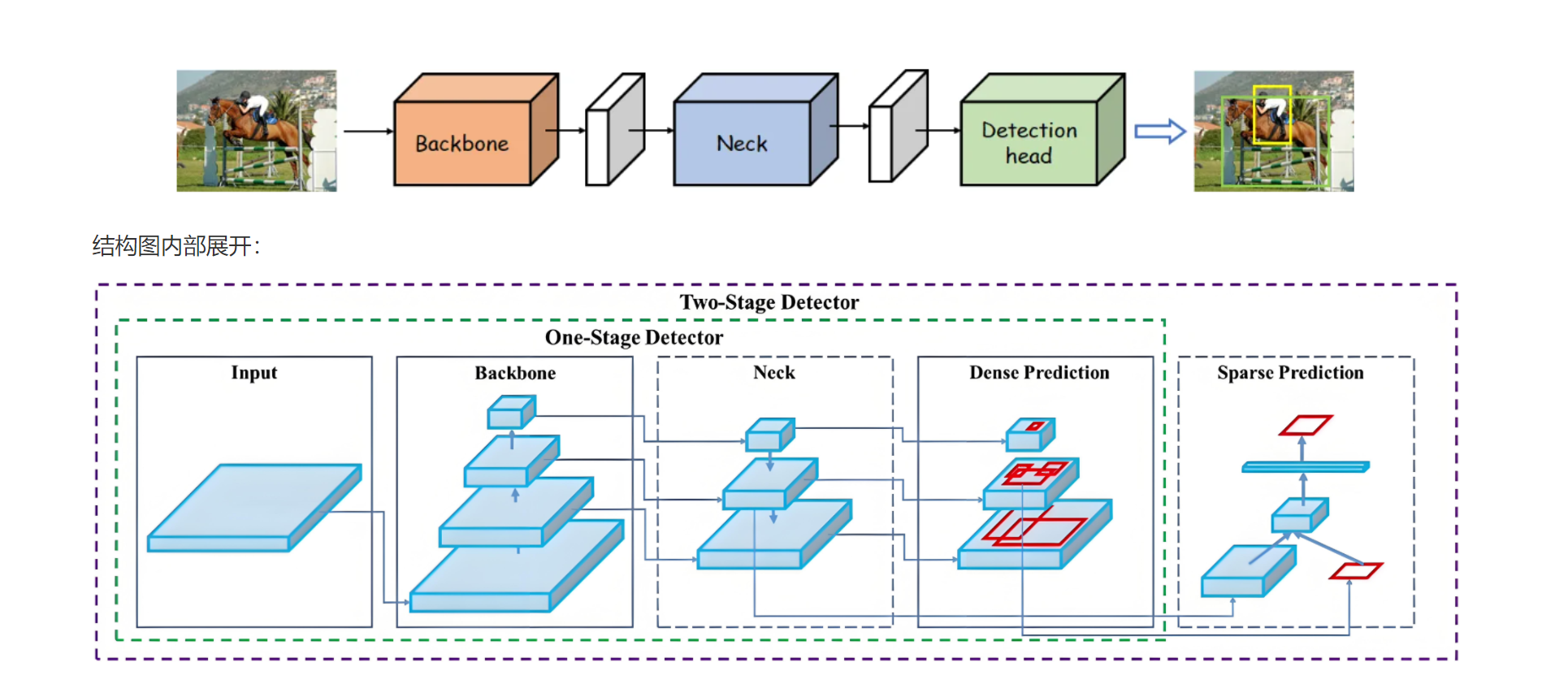
簡單理解:?
輸入圖像input:
模型的輸入是圖像,圖像經過后續的處理,生成預測結果。
單階段檢測器(One-Stage Detector):
Backbone:負責提取圖像的特征,通常使用卷積神經網絡(CNN)來獲取圖像的特征表示。
Neck:通常由額外的網絡層(如FPN,特征金字塔網絡)組成,用于進一步處理特征圖并增強不同尺度的信息。
Dense Prediction:在這個階段,模型對圖像進行密集的預測,通常會生成大量的候選框,并為每個候選框預測類別和邊界框回歸。
Detection Head:最后,模型的檢測頭會處理預測結果,選擇最優的邊界框并進行分類。
雙階段檢測器(Two-Stage Detector):
Backbone & Neck:與單階段檢測器類似,特征提取和處理。
Sparse Prediction:與單階段檢測器的密集預測不同,雙階段檢測器會在第一階段產生少量候選框(即稀疏預測),然后通過第二階段(如RPN, 區域提議網絡)對這些候選框進行精細調整。
5.2YOLO網絡結構

? ? ? ? 該圖展示了目標檢測模型的架構,模型主要是YOLOv1-v5。參數部分要注意:
FC → 7×7×(5+5+20)(v1):這是一個全連接層(Fully Connected)到7×7的輸出,5表示邊界框的4個坐標(x,y,h,w)加一個置信度值,20表示類別數(即分類任務中的類別數)。
13×13×5×(5+20)(v2):通過卷積層進行目標檢測,每個特征圖位置有5個錨框(Anchor boxes),每個錨框有5個參數(4個坐標(這四個坐標主要是預測參數----邊界框回歸參數(t_x, t_y, t_w, t_h))和1個置信度)和20個類別預測。
13×13×3×(5+80)(v3-v5):這個結構表示輸出為3個尺度的特征圖,每個尺度對應一個不同大小的特征圖,預測5個錨框的坐標和80個類別。不同版本的模型在Head的結構上略有差異。

)



)
)

 - 加法器)



)
傳輸層(上)運輸層協議概述)


vllm在線啟動集成openweb-ui)
)

