一、大模型微調
1.1、解釋
????????微調(Fine-tuning)是在預訓練大模型基礎上,針對特定領域數據進行二次訓練的技術過程。這一過程使大型語言模型(如GPT、BERT等)能夠更好地適應具體應用場景,顯著提升在專業領域的表現。
1.2、微調的基本流程
-
模型選擇:根據任務類型選擇合適的預訓練模型(如GPT用于生成任務,BERT用于分類任務)
-
數據準備:收集整理與目標領域相關的高質量訓練數據
-
參數調整:優化學習率、訓練輪次、批次大小等關鍵參數
-
模型訓練:在保持原有知識的基礎上融入領域專業知識
-
驗證優化:通過測試集評估效果,進行必要的參數調整和迭代
1.3、微調的核心價值
性能提升
????????顯著提高模型在特定領域的表現精度
????????使模型掌握專業術語和領域知識(如法律、醫療等)
資源效率
????????相比從頭訓練可節省90%以上的計算資源
????????大幅縮短模型開發周期和部署時間
功能增強
????????保持通用能力的同時獲得專業領域優勢
????????提升對領域細微差異的識別和處理能力
商業價值
????????支持企業級個性化定制(如品牌語調和風格適配)
????????實現生產環境中的高效精準服務(如金融客服場景)
持續進化
????????快速適應語言變化和新詞匯
????????跨文化語境保持優異表現
????????微調技術使大模型在保留強大通用能力的同時,能夠深度適配垂直領域需求,是AI應用落地的關鍵環節。通過精細化的微調過程,企業可以以較低成本獲得高度專業化的智能解決方案。
二、參數高效微調(Parameter-Efficient Fine-Tuning, PEFT)
????????參數高效微調(PEFT) 是一種針對大規模預訓練模型(如 GPT、Qwen、DeepSeek等)的優 化策略。其核心思想是通過僅調整少量參數或引入額外的輕量級模塊,來實現對新任務的快速 適配,而無需對整個模型進行重新訓練。這種方法在資源受限的場景中表現出色,顯著降低了 計算成本和存儲需求,同時避免了傳統微調方法可能導致的過擬合問題。?
面臨挑戰:
高計算成本:需要更新數十億甚至上百億、上千億個參數,消耗大量 GPU/TPU/NPU 資 源。
高存儲需求:每個任務都需要保存一份完整的模型副本,占用大量存儲空間。
易過擬合:在小數據集上微調時,容易導致模型性能下降。
傳統微調的局限性
資源消耗大:傳統微調需要更新模型的所有參數,計算和存儲開銷巨大。
任務間干擾:當模型需要適配多個任務時,全參數微調可能導致不同任務之間的沖突。
難以擴展:對于大規模模型,全參數微調的可擴展性較差,尤其在多任務場景下。
PEFT 的優勢
低資源需求:僅需更新少量參數或引入輕量級模塊,顯著降低計算和存儲成本。
任務隔離性:通過凍結原始模型參數,避免任務間的干擾,提升模型的魯棒性。
快速部署:適用于資源受限環境(如邊緣設備),支持快速迭代和部署。
三、常用方法
| 方法名稱 | 核心思想 | 參數更新量 | 適用場景 | 優點 | 缺點 |
|---|---|---|---|---|---|
| BitFit | 僅更新模型中的偏置參數 | 極少 | 資源受限場景 | 簡單高效,計算成本極低 | 表達能力有限,性能提升較小 |
| Prompt Tuning | 優化輸入提示詞(硬提示) | 較少 | 分類、生成任務 | 表現穩定,不修改模型結構 | 提示設計復雜,依賴人工經驗 |
| Prefix Tuning | 添加可訓練的前綴向量 | 中等 | 生成式任務 | 靈活性強,效果優于Prompt | 計算成本較高,需要更多顯存 |
| P-Tuning | 在輸入層加入可訓練的"軟提示" | 較少 | 小數據集任務 | 輕量化,適合資源有限場景 | 對超參數敏感,調優難度較大 |
| Adapter | 在網絡層間插入小型適配器模塊 | 中等 | 多任務學習、跨領域遷移 | 模塊化設計,擴展性強 | 增加推理延遲,結構設計復雜 |
| LoRA | 通過低秩分解更新參數矩陣 | 極少 | 超大規模模型微調 | 高效且性能接近全參數微調 | 需要矩陣秩選擇經驗 |
| (IA)3 | 注入可學習的縮放激活向量 | 極少 | 多任務學習 | 參數效率極高 | 訓練穩定性需要精細控制 |
| QLoRA | 量化+LoRA的混合方法 | 極少 | 超大規模模型的低資源微調 | 可在單卡上微調超大模型 | 需要量化專業知識 |
| Freeze | 凍結大部分參數僅微調頂層 | 較少 | 領域適應任務 | 簡單直接,資源消耗低 | 可能丟失底層重要特征 |
| DiffPruning | 差異化剪枝+參數更新 | 中等 | 需要模型壓縮的場景 | 可生成稀疏化模型 | 實現復雜度高 |
四、BitFit
????????BitFit 是一種稀疏微調方法,其核心思想是僅更新模型中的偏置(bias)參數,而保持權重 (weight)參數不變。
????????優點:參數更新量極小,適合資源極度受限的場景。
????????缺點:可能無法充分捕捉復雜任務的特征。
論文地址:[2106.10199] BitFit: Simple Parameter-efficient Fine-tuning for Transformer-based Masked Language-models
使用AutoModelForCausalLM加載因果語言模型
from transformers import AutoModelForCausalLMmodel_name = "/home/AI_big_model/models/Qwen/Qwen2.5-7B-Instruct"model = AutoModelForCausalLM.from_pretrained(model_name, torch_dtype="auto")
凍結其它參數,只保留bias可訓練?
for name, param in model.named_parameters():if "bias" not in name:param.requires_grad = False # 凍結參數設置隨機數種子?
torch.manual_seed(42)
if torch.cuda.is_available():torch.cuda.manual_seed(42)設置分詞器?
from transformers import AutoTokenizer
tokenizer = AutoTokenizer.from_pretrained(model_name)處理和加載訓練數據
class CustomDataset(Dataset):def __init__(self, file_path, tokenizer, max_length=128):"""filr_path: 數據集路徑tokenizer: 分詞器max_length: 每個樣本的最大長度,超過部分會被截斷,不足的被填充"""self.file_path = file_pathself.tokenizer = tokenizerself.max_length = max_lengthself.data = [] # 存放數據集的所有樣本with open(self.file_path, "r", encoding="utf-8") as f:data_list = json.load(f) # 讀取json文件for item in data_list:self.data.append(item)def __len__(self):return len(self.data)def __getitem__(self, idx):# 獲取對應索引的樣本數據example = self.data[idx]# 使用分詞器處理指令部分的文本,不需要添加特殊標記。# 整理的格式是和qwen要保持統一的。instruction = self.tokenizer(f"<|im_start|>system\n<|im_end|>\n<|im_start|>user\n{example['instruction']}<|im_end|>\n<|im_start|>assistant\n",add_special_tokens=False,)# 使用分詞器處理輸出部分的文本,不需要添加特殊標記。response = self.tokenizer(f"{example['output']}",add_special_tokens=False,)# 將指令和輸出的token id拼接在一起input_ids = instruction["input_ids"] + response["input_ids"]# 合并attention_maskattention_mask = (instruction["attention_mask"] + response["attention_mask"])# 創建標簽 labels# instruction部分的標簽是-100,表示不參與訓練,計算損失時會忽略這些位置# 因為模型只需要學習生成目標部分,也就是assistant的回復內容labels = [-100] * len(instruction["input_ids"]) + response["input_ids"]if len(input_ids) > self.max_length: # 如果序列長度超過128,那么截斷input_ids = input_ids[:self.max_length]attention_mask = attention_mask[:self.max_length]labels = labels[:self.max_length]else: # 如果不足128,需要填充padding_len = self.max_length - len(input_ids)input_ids = input_ids + [self.tokenizer.pad_token_id] * padding_lenattention_mask = attention_mask + [0] * padding_lenlabels = labels + [self.tokenizer.pad_token_id] * padding_len# 返回構建好的張量return {"input_ids": torch.tensor(input_ids),"attention_mask": torch.tensor(attention_mask),"labels": torch.tensor(labels),}transformers trainer訓練
from transformers import Trainer, TrainingArguments, DataCollatorForSeq2Seq
args = TrainingArguments(output_dir="./chatbot/",per_device_train_batch_size=4, # bs=4gradient_accumulation_steps=8, # 梯度累計后,相當于bs=32logging_steps=10, # 每10步打印一次日志max_steps=1000, # 最大訓練步數learning_rate=6e-4, # 學習率lr_scheduler_type="cosine", # 學習率調度器warmup_ratio=0.1, # warmup比例bf16=True, # 是否使用bf16save_steps=100, # 保存模型的步數
)# 實例化Trainer
trainer = Trainer(model=model, # 模型args=args, # 訓練參數train_dataset=dataset, # 訓練數據集data_collator=DataCollatorForSeq2Seq(tokenizer=tokenizer, padding=True) # 數據收集器
)trainer.train()五、提示微調(Prompt Tuning)
????????Prompt Tuning(提示調優)是一種通過優化輸入的"提示"來調整模型行為的方法,它通過引入可訓練的"軟提示"(Soft Prompts)來實現對預訓練模型的引導,而不需要修改模型本身的參數。
| 特性 | 軟提示 (Soft Prompt) | 硬提示 (Hard Prompt) |
|---|---|---|
| 形式 | 可訓練的嵌入向量 | 自然語言文本 |
| 可讀性 | 非人類可讀的連續向量 | 人類可讀的離散文本 |
| 參數 | 需要優化提示向量 | 固定不變 |
| 靈活性 | 可通過訓練自動優化 | 需要人工設計 |
| 存儲 | 通常需要額外存儲少量提示參數 | 無需額外存儲 |
技術特點
????????參數高效:僅需優化少量提示參數(通常占模型總參數的0.1%-1%)
????????模型凍結:保持原始預訓練模型參數不變
????????任務適配:通過提示向量引導模型適應特定任務
????????計算高效:相比全參數微調,訓練成本顯著降低
軟提示的實現步驟?
(1) 初始化軟提示
????????嵌入向量的形狀:假設我們希望插入n個軟提示向量,每個向量的維度為d(與模型的詞 嵌入維度一致)。那么軟提示的形狀為(n,d) 。
????????隨機初始化:這些嵌入向量通常使用標準正態分布或其他初始化方法(如均勻分布)進行隨 機初始化。
(2) 將軟提示插入輸入序列
????????原始輸入:預訓練模型的輸入通常是經過分詞器(Tokenizer)處理后的標記序列(Token Sequence),其形狀為[B,L,D] ,其中:
????????????????B是批量大小(Batch Size)。
????????????????L是序列長度(Sequence Length)。
????????????????D是詞嵌入維度(Embedding Dimension)。
????????插入位置:軟提示通常被插入到輸入序列的開頭(或特定位置)。例如,將其拼接到原始輸 入序列的前面。
(3) 輸入到模型
????????將拼接后的嵌入向量作為模型的輸入,傳遞給預訓練模型進行前向傳播。
import os
import torch
from transformers import AutoTokenizer, AutoModelForCausalLMmodel_name = "/home/AI_big_model/models/Qwen/Qwen2.5-7B-Instruct"torch.manual_seed(42)
if torch.cuda.is_available():torch.cuda.manual_seed(42)# 移動模型到 GPU (如果可用)
device = torch.device("cuda" if torch.cuda.is_available() else "cpu")# 加載預訓練的因果語言模型
model = AutoModelForCausalLM.from_pretrained(model_name, torch_dtype="bfloat16").to(device)
tokenizer = AutoTokenizer.from_pretrained(model_name)# # 打印模型結構,查看原始模型的架構和參數
# print("原始模型結構:")
# print(model)"""------------------------------------------------------------------------------------------------"""# PromptTuningConfig是用于配置提示微調(Prompt Tuning)參數的類
# 它可以幫助定義微調過程中所需的各項配置,如學習率、批次大小等
# TaskType是一個枚舉類,用于指定模型處理的任務類型,例如序列分類、命名實體識別等
# get_peft_model是一個用于根據配置獲取具體微調模型的函數
# 通過這個函數,用戶可以根據自己的需求獲取到適合任務的微調模型實例
from peft import PromptTuningConfig, get_peft_model, TaskType# 定義一個提示文本(prompt),用于引導模型的行為
# 這段文本將作為虛擬 token 的初始化內容,告訴模型如何扮演特定角色# 可以使用:
# config = PromptTuningConfig(task_type=TaskType.CAUSAL_LM, num_virtual_tokens=10)# 但是為了追求快速實現和語義引導,建議使用 prompt_encoder。
prompt = "請使用以上角色回答用戶問題。"# 配置 Prompt Tuning 參數
config = PromptTuningConfig(task_type=TaskType.CAUSAL_LM, # 指定任務類型為因果語言建模(Causal Language Modeling)num_virtual_tokens=len(tokenizer(prompt)["input_ids"]), # 設置虛擬 token 的數量# 虛擬 token 的數量由提示文本的 token 數量決定prompt_tuning_init_text=prompt, # 使用提示文本初始化虛擬 token 的嵌入tokenizer_name_or_path=model_name,
)
print(config)
# import sys;sys.exit(0)
# 創建 PEFT 模型
# 將原始模型與 Prompt Tuning 配置結合,生成一個新的支持 Prompt Tuning 的模型
model = get_peft_model(model, config)
# print("PEFT模型結構:")
# print(model)
# import sys;sys.exit(0)
# print(sum(p.numel() for p in model.parameters() if p.requires_grad))六、P-tuning
????????P-Tuning 是一種基于“軟提示”的微調方法,其核心思想是通過引入一組可學習的“軟提示”(Soft Prompt)嵌入向量來調整預訓練語言模型的行為。與傳統的硬提示(Hard Prompt,即直接在 輸入文本中添加自然語言提示)不同,P-Tuning 的軟提示是以連續的嵌入向量形式存在,并且 這些嵌入向量是通過訓練優化得到的。
與 Prompt Tuning 的區別:
????????提示生成方式:Prompt Tuning 直接使用隨機初始化的嵌入向量作為軟提示,而 P Tuning 使用一個小型的神經網絡(稱為“提示生成器”)動態生成軟提示,從而增強軟提 示的表現力。
????????復雜度:Prompt Tuning 的實現較為簡單,僅限于輸入層;而 P-Tuning 的實現更加復 雜,可能涉及多層優化或動態調整機制。
????????適用場景:Prompt Tuning 更適合簡單任務(如分類),而 P-Tuning 更適合復雜任務 (如生成式任務)。
P-Tuning 實現步驟?
(1) 初始化軟提示
????????軟提示的形狀:假設我們希望插入 個軟提示向量,每個向量的維度為 (與模型的詞嵌 入維度一致)。那么軟提示的形狀為 。
????????隨機初始化:這些嵌入向量通常使用標準正態分布或其他初始化方法(如均勻分布)進行隨 機初始化。
????????提示生成器:P-Tuning 的軟提示通常由一個小型神經網絡(提示生成器)動態生成,而不 是直接隨機初始化。
(2) 將軟提示插入輸入序列
????????原始輸入:預訓練模型的輸入通常是經過分詞器(Tokenizer)處理后的標記序列(Token Sequence),其形狀為(B,L,D)?,
????????其中: B是批量大小(Batch Size)。
????????????????L是序列長度(Sequence Length)。
????????????????D是詞嵌入維度(Embedding Dimension)。
????????插入位置:軟提示通常被插入到輸入序列的開頭(或特定位置)。例如,將其拼接到原始輸 入序列的前面。
(3) 輸入到模型
????????將拼接后的嵌入向量作為模型的輸入,傳遞給預訓練模型(如 BERT、GPT 等)進行前向傳播。
import os
import torch
from transformers import AutoTokenizer, AutoModelForCausalLMmodel_name = "./models/Qwen/Qwen2___5-0___5B-Instruct"torch.manual_seed(42)
if torch.cuda.is_available():torch.cuda.manual_seed(42)# 移動模型到 GPU (如果可用)
device = torch.device("cuda" if torch.cuda.is_available() else "cpu")from peft import PromptEncoderConfig, TaskType, get_peft_model, PromptEncoderReparameterizationType
model = AutoModelForCausalLM.from_pretrained(model_name)
tokenizer = AutoTokenizer.from_pretrained(model_name)print("原始模型結構:")
print(model)# 初始化PromptEncoderConfig配置對象
# 該配置用于定義提示編碼器的參數,以適應特定的任務類型
# 參數:
# task_type: 任務類型,這里設置為因果語言模型(CAUSAL_LM)
# num_virtual_tokens: 虛擬令牌的數量,這里設置為10
# encoder_reparameterization_type: 編碼器重新參數化類型,這里使用LSTM
config = PromptEncoderConfig(task_type=TaskType.CAUSAL_LM,num_virtual_tokens=10,encoder_reparameterization_type=PromptEncoderReparameterizationType.LSTM,)# 創建 peft model
model = get_peft_model(model, config)
print("PEFT模型結構:")
print(model)
# import sys;sys.exit(0)
# print(sum(p.numel() for p in model.parameters() if p.requires_grad))
total_params = 0
for name, param in model.named_parameters():if param.requires_grad:print(f"{name}: {param.shape} -> {param.numel()}")total_params += param.numel()
print(f"Total trainable parameters: {total_params}")總結
????????Prompt Tuning 是一種簡單高效的微調方法,適合資源受限場景和簡單任務。它的實現方 式直接且易于理解,但表現力相對有限。
????????P-Tuning 則通過引入提示生成器等機制增強了軟提示的表現力,適合復雜任務(如生成式 任務)和對性能要求較高的場景。雖然其實現復雜度和計算成本略高,但在生成式任務中表 現出色。
推薦使用 Prompt Tuning 的場景
資源受限環境:邊緣設備、移動端部署
簡單判別任務:文本分類、情感分析、實體識別
快速原型開發:需要快速驗證模型適配性的場景
少樣本學習:訓練數據少于1,000條時效果顯著
推薦使用 P-Tuning 的場景
復雜生成任務:對話生成、文本摘要、創意寫作
多步推理任務:數學解題、邏輯推理、復雜問答
領域自適應:需要深度調整模型行為的情況
數據充足時:訓練數據超過10,000條時優勢明顯
| 特性 | Prompt Tuning | P-Tuning |
|---|---|---|
| 核心思想 | 直接優化連續提示嵌入 | 通過提示生成器產生動態提示 |
| 參數更新量 | 僅提示參數(0.1%-1%模型參數) | 提示生成器參數(1%-5%模型參數) |
| 模型改動 | 無結構改動 | 需添加提示生成器模塊 |
| 訓練效率 | 極高(僅反向傳播提示參數) | 較高(需訓練小型神經網絡) |
| 任務表現力 | 適用于簡單分類/回歸任務 | 擅長復雜生成/推理任務 |
| 實現復雜度 | ★★☆ | ★★★☆ |
| 硬件需求 | 單卡GPU即可運行 | 可能需要更大顯存 |
| 任務類型 | Prompt Tuning (準確率) | P-Tuning (準確率) |
|---|---|---|
| 文本分類 | 92.3% | 93.1% |
| 實體識別 | 88.7% | 89.5% |
| 文本生成(ROUGE) | 0.65 | 0.72 |
| 數學推理 | 54.2% | 68.9% |
七、Prefix-tuning
????????Prefix Tuning 核心思想是在模型的輸入中添加一組可訓練的前綴向量(Prefix Vectors),這 些向量作為任務特定的上下文信息,幫助模型適應新任務。與 Prompt Tuning 不同的是, Prefix Tuning 的前綴向量通常被插入到 Transformer 模型的每一層,而不僅僅是輸入層。
特點:
????????前綴向量可以看作是模型輸入的一部分,影響模型的輸出。
????????相較于 Prompt Tuning 更靈活,適用于生成式任務(如對話、翻譯)。
優勢:在生成任務中表現優異,同時保留了原始模型的通用性。
實現步驟
(1) 初始化前綴向量
????????前綴向量的形狀:假設我們希望為每個 Transformer 層插入n個前綴向量,每個向量的維 度為 d(與模型的隱藏層維度一致)。那么前綴向量的形狀為[L,n,d]?,
????????其中: L是 Transformer 層數。
????????????????n是每層前綴向量的數量。
????????????????d是隱藏層維度。
????????隨機初始化:這些前綴向量通常使用標準正態分布或其他初始化方法進行隨機初始化。?
(2) 將前綴向量插入 Transformer 層
????????Transformer 的結構:Transformer 模型的每一層包含兩個主要部分:
????????????????自注意力機制(Self-Attention):計算輸入序列的注意力權重。
????????????????前饋網絡(Feed-Forward Network, FFN):對注意力輸出進行非線性變換。
????????插入位置:前綴向量被插入到每一層的自注意力機制中,作為額外的上下文信息。
(3) 輸入到模型
????????將修改后的鍵值對傳遞給 Transformer 模型的每一層,完成前向傳播。
import os
import torch
from transformers import AutoTokenizer, AutoModelForCausalLMmodel_name = "./models/Qwen/Qwen2___5-0___5B-Instruct"# 構建數據集
import jsontorch.manual_seed(42)
if torch.cuda.is_available():torch.cuda.manual_seed(42)# 移動模型到 GPU (如果可用)
device = torch.device("cuda" if torch.cuda.is_available() else "cpu")# PromptTuningConfig是用于配置提示微調(Prompt Tuning)參數的類
# 它可以幫助定義微調過程中所需的各項配置,如學習率、批次大小等
# TaskType是一個枚舉類,用于指定模型處理的任務類型,例如序列分類、命名實體識別等
# get_peft_model是一個用于根據配置獲取具體微調模型的函數
# 通過這個函數,用戶可以根據自己的需求獲取到適合任務的微調模型實例
from peft import PrefixTuningConfig, get_peft_model, TaskTypemodel = AutoModelForCausalLM.from_pretrained(model_name, torch_dtype="bfloat16").to(device)
tokenizer = AutoTokenizer.from_pretrained(model_name)# print("原始模型結構:")
# print(model)# 創建一個PrefixTuningConfig對象,用于配置前綴調優的參數
# 參數task_type指定任務類型為因果語言模型(CAUSAL_LM)
# 參數num_virtual_tokens指定虛擬令牌的數量為15,這些虛擬令牌作為前綴使用
# 設置prefix_projection為True,意味著在前綴和模型主體之間會有一個投影層
config = PrefixTuningConfig(task_type=TaskType.CAUSAL_LM,num_virtual_tokens=15,prefix_projection=True,)# 創建 peft model
model = get_peft_model(model, config)
# print("PEFT模型結構:")
# print(model)
# import sys;sys.exit(0)
print(sum(p.numel() for p in model.parameters() if p.requires_grad))?八、LORA
????????低秩適配(LoRA) 是一種基于低秩分解的參數高效微調(PEFT)方法。其核心思想是將需要 調整的權重矩陣分解為兩個低秩矩陣,并僅訓練這些低秩矩陣,而原始模型的權重保持凍結。 這種方法通過低秩近似顯著減少了需要訓練的參數量,同時保持了較高的任務性能。
| 對比項 | LoRA(Low-Rank Adaptation) | QLoRA(Quantized LoRA) |
|---|---|---|
| 核心思想 | 在模型的權重矩陣上添加低秩適配層(Low-Rank Adapters),并僅訓練這部分參數 | 先將模型量化到更低的精度(如 4-bit),再應用 LoRA 進行訓練 |
| 是否量化 | ? 否,保持原始模型權重精度 | ? 是,使用 4-bit 量化(NF4 量化格式) |
| 計算效率 | 需要全精度(FP16 或 BF16)存儲模型 | 量化后大幅降低顯存占用 |
| 顯存占用 | 高(需要存儲 LoRA 適配層和全模型) | 低(4-bit 量化后顯存需求減少 3-4 倍) |
| 訓練速度 | 需要更高的顯存,但仍比全量微調快 | 由于量化,計算更高效,適合更大模型 |
| 適用場景 | 適用于 中等規模 LLM(如 7B、13B) | 適用于 超大規模 LLM(如 30B、65B) |
| 存儲需求 | 需要存儲 FP16/BF16 權重 + LoRA 適配層 | 僅存儲 4-bit 量化權重 + LoRA 適配層 |
| 推理性能 | 需要全精度計算,但開銷比全量微調小 | 量化后推理更快,適用于低資源部署 |
import os
import torch
from transformers import AutoTokenizer, AutoModelForCausalLMmodel_name = "./models/Qwen/Qwen2___5-0___5B-Instruct"# 構建數據集
import jsontorch.manual_seed(42)
if torch.cuda.is_available():torch.cuda.manual_seed(42)# 移動模型到 GPU (如果可用)
device = torch.device("cuda" if torch.cuda.is_available() else "cpu")# 加載預訓練的因果語言模型
model = AutoModelForCausalLM.from_pretrained(model_name, torch_dtype="bfloat16").to(device)
tokenizer = AutoTokenizer.from_pretrained(model_name)# 打印模型結構,查看原始模型的架構和參數
print("原始模型結構:")
print(model)# target_modules = None 時Qwen2默認對q和v進行處理
from peft import PeftModel, PeftConfig, get_peft_model, LoraConfig, TaskType# 配置LoRA(Low-Rank Adaptation)參數以微調語言模型
config = LoraConfig(task_type=TaskType.CAUSAL_LM, # 設置任務類型為因果語言模型(Causal Language Model)r=4, # 設置低秩矩陣的秩(rank)為4,影響模型的微調參數量和計算復雜度lora_alpha=32, # 設置LoRA的alpha參數為32,用于縮放注意力權重,影響模型性能lora_dropout=0.01, # 設置LoRA層的dropout概率為0.01,用于正則化防止過擬合# target_modules = ['query'] # (此行注釋掉,未使用)可指定需要應用LoRA的模塊,例如'query'注意力模塊
)# 創建 peft model
model = get_peft_model(model, config)
print("PEFT模型結構:")
print(model)
# import sys;sys.exit(0)
# print(sum(p.numel() for p in model.parameters() if p.requires_grad))九、集合微調驗證
微調?
import json
import torch
from torch.utils.data import Dataset
from transformers import AutoModelForCausalLM, AutoTokenizer, Trainer, TrainingArguments, DataCollatorForSeq2Seq
from peft import (PromptTuningConfig,TaskType,get_peft_model,PromptEncoderConfig,PromptEncoderReparameterizationType,PrefixTuningConfig,LoraConfig,
)
import torch.nn as nnclass CustomDataset(Dataset):"""自定義數據集類,用于加載和預處理訓練數據。"""def __init__(self, file_path, tokenizer, max_length=128):"""初始化數據集。Args:file_path: 數據集文件路徑。tokenizer: 用于文本分詞的tokenizer。max_length: 每個樣本的最大長度,超出部分將被截斷,不足部分將被填充。"""self.file_path = file_pathself.tokenizer = tokenizerself.max_length = max_lengthself.data = [] # 存放數據集的所有樣本with open(self.file_path, "r", encoding="utf-8") as f:data_list = json.load(f) # 讀取json文件for item in data_list:self.data.append(item)def __len__(self):"""返回數據集中的樣本數量。"""return len(self.data)def __getitem__(self, idx):"""根據索引獲取單個樣本并進行處理。Args:idx: 樣本的索引。Returns:一個字典,包含input_ids, attention_mask, 和 labels。"""# 獲取對應索引的樣本數據example = self.data[idx]# 使用分詞器處理指令部分的文本,不需要添加特殊標記。# 整理的格式是和qwen要保持統一的。# <|im_start|> 和 <|im_end|> 是Qwen模型特有的對話標記。# system: 系統角色,user: 用戶角色,assistant: 助手角色。instruction = self.tokenizer(f"<|im_start|>system\n<|im_end|>\n<|im_start|>user\n{example['instruction']}<|im_end|>\n<|im_start|>assistant\n",add_special_tokens=False, # 不添加tokenizer的默認特殊標記)# 使用分詞器處理輸出部分的文本,不需要添加特殊標記。response = self.tokenizer(f"{example['output']}",add_special_tokens=False, # 不添加tokenizer的默認特殊標記)# 將指令和輸出的token id拼接在一起,形成完整的輸入序列。input_ids = instruction["input_ids"] + response["input_ids"]# 合并attention_mask。attention_mask用于指示哪些token是實際內容(1)哪些是填充(0)。attention_mask = instruction["attention_mask"] + response["attention_mask"]# 創建標簽 labels。# instruction部分的標簽是-100,表示這些token在計算損失時會被忽略。# 這是因為在因果語言建模中,模型只需要學習生成assistant的回復內容。labels = [-100] * len(instruction["input_ids"]) + response["input_ids"]if len(input_ids) > self.max_length: # 如果序列長度超過最大長度,則進行截斷。input_ids = input_ids[: self.max_length]attention_mask = attention_mask[: self.max_length]labels = labels[: self.max_length]else: # 如果序列長度不足最大長度,則進行填充。padding_len = self.max_length - len(input_ids)input_ids = input_ids + [self.tokenizer.pad_token_id] * padding_len # 使用pad_token_id填充input_idsattention_mask = attention_mask + [0] * padding_len # attention_mask填充0labels = labels + [self.tokenizer.pad_token_id] * padding_len # labels也使用pad_token_id填充# 返回構建好的張量,轉換為PyTorch tensor類型。return {"input_ids": torch.tensor(input_ids),"attention_mask": torch.tensor(attention_mask),"labels": torch.tensor(labels),}def change_model(model_name, selcet="Bitfit", file_path="./dataset/data.json"):"""根據選擇的微調方法加載模型、tokenizer和數據集,并對模型進行相應的設置。Args:model_name: 預訓練模型的名稱或路徑。selcet: 選擇的微調方法("Bitfit", "Prompt-tuning", "P-tuning", "Prefix-tuning", "LORA")。file_path: 數據集文件路徑。Returns:model: 配置好的模型。tokenizer: 對應的tokenizer。dataset: 處理好的數據集。"""# 從預訓練模型加載因果語言模型model = AutoModelForCausalLM.from_pretrained(model_name, torch_dtype="auto")# 從預訓練模型加載分詞器tokenizer = AutoTokenizer.from_pretrained(model_name)# 創建自定義數據集實例dataset = CustomDataset(file_path, tokenizer)if selcet == "Bitfit":# BitFit方法:只訓練模型的偏置(bias)參數,凍結其他參數。for name, param in model.named_parameters():if "bias" not in name:param.requires_grad = False # 凍結非偏置參數elif selcet == "Prompt-tuning":# Prompt-tuning方法:通過添加可學習的虛擬token來調整模型的行為。prompt = "請使用以上角色回答用戶問題。" # 定義一個提示文本config = PromptTuningConfig(task_type=TaskType.CAUSAL_LM, # 指定任務類型為因果語言建模num_virtual_tokens=len(tokenizer(prompt)["input_ids"]), # 虛擬token的數量由提示文本的token數量決定prompt_tuning_init_text=prompt, # 使用提示文本初始化虛擬token的嵌入tokenizer_name_or_path=model_name,)model = get_peft_model(model, config) # 獲取PEFT模型elif selcet == "P-tuning":# P-tuning方法:使用一個編碼器(如LSTM)來生成提示的嵌入。config = PromptEncoderConfig(task_type=TaskType.CAUSAL_LM, # 指定任務類型為因果語言建模num_virtual_tokens=10, # 虛擬token的數量encoder_reparameterization_type=PromptEncoderReparameterizationType.LSTM, # 編碼器類型為LSTM)model = get_peft_model(model, config) # 獲取PEFT模型elif selcet == "Prefix-tuning":# Prefix-tuning方法:在每個Transformer層前添加可學習的前綴。config = PrefixTuningConfig(task_type=TaskType.CAUSAL_LM, # 指定任務類型為因果語言建模num_virtual_tokens=15, # 虛擬token的數量作為前綴prefix_projection=True, # 在前綴和模型主體之間添加一個投影層)model = get_peft_model(model, config) # 獲取PEFT模型elif selcet == "LORA":# LORA(Low-Rank Adaptation)方法:通過低秩矩陣分解來高效微調大模型。config = LoraConfig(task_type=TaskType.CAUSAL_LM, # 設置任務類型為因果語言模型r=4, # 設置低秩矩陣的秩,影響微調參數量lora_alpha=32, # LoRA的alpha參數,用于縮放注意力權重lora_dropout=0.01, # LoRA層的dropout概率# target_modules = ['query'] # 可以指定需要應用LoRA的模塊,例如'query'注意力模塊)model = get_peft_model(model, config) # 獲取PEFT模型return model, tokenizer, datasetif __name__ == "__main__":# 配置訓練參數args = TrainingArguments(output_dir="./chatbot/", # 模型輸出目錄per_device_train_batch_size=4, # 每個設備的訓練批量大小gradient_accumulation_steps=8, # 梯度累積步數,相當于有效批量大小為 4 * 8 = 32logging_steps=10, # 每10步打印一次日志max_steps=1000, # 最大訓練步數learning_rate=6e-4, # 學習率lr_scheduler_type="cosine", # 學習率調度器類型為cosinewarmup_ratio=0.1, # warmup比例,在前10%的步數內逐漸增加學習率bf16=True, # 是否使用bf16(bfloat16)混合精度訓練save_steps=100, # 每100步保存一次模型)# 指定預訓練模型路徑model_name = "/home/AI_big_model/models/Qwen/Qwen2.5-0.5B-Instruct"# 調用change_model函數,根據選擇的微調方法獲取模型、tokenizer和數據集model, tokenizer, dataset = change_model(model_name,selcet="LORA", # 選擇LORA微調方法file_path="/home/model_change/identity.json", # 數據集文件路徑)# 實例化Trainertrainer = Trainer(model=model, # 待訓練的模型args=args, # 訓練參數train_dataset=dataset, # 訓練數據集# 數據收集器,用于將樣本批量化并進行填充data_collator=DataCollatorForSeq2Seq(tokenizer=tokenizer, padding=True),)# 開始訓練模型trainer.train()| 模塊包 | 主要功能 | 代碼中主要用途 | 備注 |
json | 處理 JSON (JavaScript Object Notation) 數據格式。 | 從 .json 文件中加載訓練數據集。 | Python 內置模塊,用于數據序列化和反序列化。 |
torch | PyTorch 深度學習框架的核心庫,提供張量計算能力。 | 將 Python 數據(如列表)轉換為 PyTorch 張量 (Tensor),用于模型輸入和計算。 | 支持 GPU 加速計算。 |
torch.utils.data.Dataset | PyTorch 中用于創建自定義數據集的抽象基類。 | 繼承此類以實現 CustomDataset,定義如何加載和處理單個數據樣本。 | 通常與 DataLoader 配合使用,實現數據的批量加載。 |
transformers | Hugging Face 提供的預訓練模型和分詞器庫。 | 提供各種大模型(如 Qwen)及其配套工具。 | |
AutoModelForCausalLM | 自動加載因果語言模型,用于文本生成任務。 | 根據模型名稱加載 Qwen 預訓練模型。 | Auto 前綴表示自動識別模型架構。 |
AutoTokenizer | 自動加載與模型對應的分詞器。 | 將文本轉換為模型可理解的數字 ID 序列,并處理注意力掩碼。 | 負責文本的預處理。 |
Trainer | Hugging Face 提供的高級訓練 API。 | 封裝了訓練循環,簡化模型訓練、評估、日志記錄和保存等流程。 | 大幅減少訓練代碼量。 |
TrainingArguments | 定義訓練過程中的各種超參數和配置。 | 設置學習率、批量大小、訓練步數、日志步數等。 | 用于配置 Trainer。 |
DataCollatorForSeq2Seq | 數據收集器,用于將單個樣本組合成批次并進行填充。 | 對批次內的序列進行動態填充,以確保長度一致,方便模型并行處理。 | 對于變長序列尤其重要。 |
peft | Hugging Face 提供的參數高效微調 (PEFT) 庫。 | 允許在只訓練少量參數的情況下微調大型預訓練模型,節省資源。 | |
PromptTuningConfig | 配置 Prompt Tuning (提示微調) 方法的參數。 | 定義虛擬 token 數量和初始化提示文本,通過可學習的提示向量調整模型行為。 | |
TaskType | 枚舉類,用于指定 PEFT 任務類型。 | 在 PEFT 配置中指定任務為因果語言建模 (CAUSAL_LM)。 | 幫助 PEFT 庫內部正確配置微調策略。 |
get_peft_model | 根據 PEFT 配置修改原始模型,使其成為 PEFT 模型。 | 將加載的預訓練模型轉換為只訓練少量參數的 PEFT 模型實例。 | PEFT 庫的核心函數。 |
PromptEncoderConfig | 配置 P-tuning 方法的參數。 | 定義虛擬 token 數量和提示編碼器類型(如 LSTM)。 | P-tuning 使用編碼器生成提示嵌入。 |
PromptEncoderReparameterizationType | 指定 P-tuning 中提示編碼器的重新參數化類型。 | 指定編碼器使用 LSTM。 | |
PrefixTuningConfig | 配置 Prefix-tuning (前綴微調) 方法的參數。 | 定義虛擬 token 數量和是否使用投影層,在 Transformer 層前添加可學習前綴。 | |
LoraConfig | 配置 LoRA (Low-Rank Adaptation) 方法的參數。 | 定義秩 r、lora_alpha 和 lora_dropout,通過低秩矩陣分解高效微調。 | 廣泛應用于大型語言模型微調。 |
torch.nn | PyTorch 中用于構建神經網絡的模塊。 | 提供各種神經網絡層、激活函數、損失函數等,此處代碼中雖導入但未直接使用。 | 通常在定義自定義模型結構時用到。 |
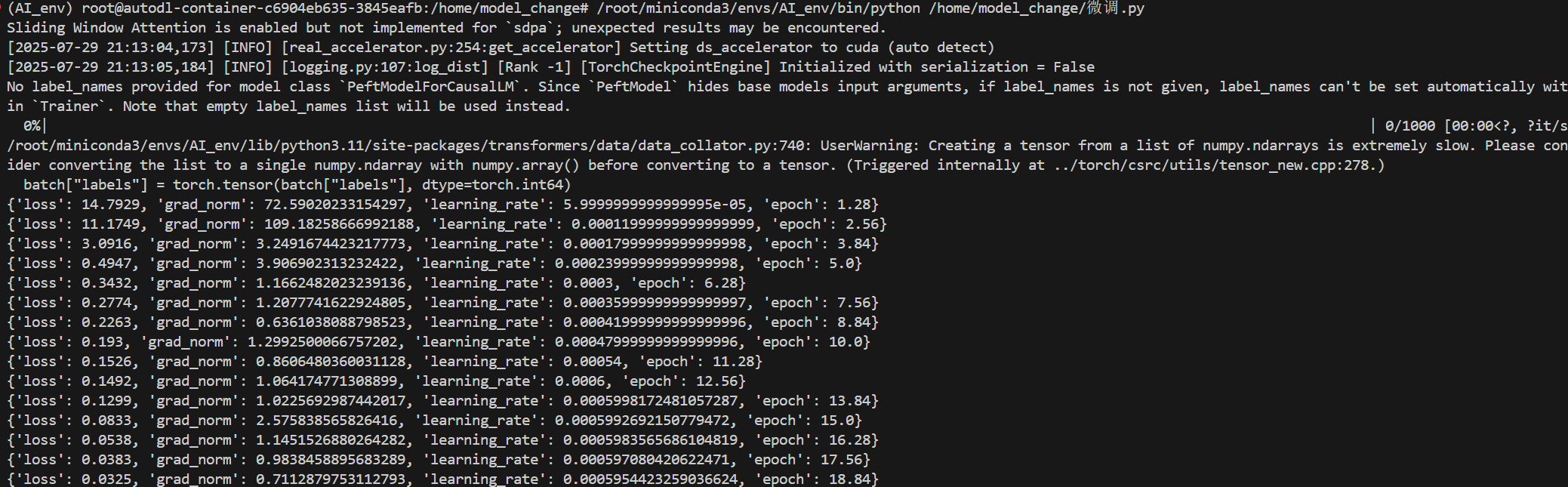
驗證模型?
import torch
from transformers import AutoModelForCausalLM, AutoTokenizer
from peft import AutoPeftModelForCausalLM
device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
model_name = "/home/model_change/chatbot/checkpoint-100"# Bitfit
# model = AutoModelForCausalLM.from_pretrained(model_name, torch_dtype="auto").to(device)
# Prompt-tuning, P-tuning, Prefix-tuning, LORA
model = AutoPeftModelForCausalLM.from_pretrained(model_name).to(device)tokenizer = AutoTokenizer.from_pretrained(model_name)prompt = "你是誰"message = [{"role": "system", "content": ""},{"role": "user", "content": prompt},
]text = tokenizer.apply_chat_template(message, tokenize=False, add_generation_prompt=True)model_ids = tokenizer([text], return_tensors="pt").to(device)generated_ids = model.generate(**model_ids, max_new_tokens=512)generated_ids = [output_ids[len(input_ids):] for input_ids, output_ids in zip(model_ids.input_ids, generated_ids)]response = tokenizer.batch_decode(generated_ids, skip_special_tokens=True)print(response)



)
)

 - 加法器)



)
傳輸層(上)運輸層協議概述)


vllm在線啟動集成openweb-ui)
)



