
內容創作智能體:多模態內容生成的完整解決方案
🌟 嗨,我是IRpickstars!
🌌 總有一行代碼,能點亮萬千星辰。
🔍 在技術的宇宙中,我愿做永不停歇的探索者。
? 用代碼丈量世界,用算法解碼未來。我是摘星人,也是造夢者。
🚀 每一次編譯都是新的征程,每一個bug都是未解的謎題。讓我們攜手,在0和1的星河中,書寫屬于開發者的浪漫詩篇。
目錄
內容創作智能體:多模態內容生成的完整解決方案
摘要
1. 多模態內容生成技術深度解析
1.1 技術架構總覽
1.2 文本內容生成技術
核心技術原理
1.3 圖像內容生成技術
擴散模型原理
2. 品牌風格一致性保持機制
2.1 風格一致性架構
2.2 風格遷移技術實現
3. 內容質量評估與優化體系
3.1 質量評估架構
3.2 質量評估指標體系
4. 版權合規與風險控制策略
4.1 版權風險控制流程
4.2 版權風險檢測實現
5. 技術方案對比分析
5.1 主流技術方案對比
5.2 性能評測數據
量化評測結果
6. 實際應用案例與最佳實踐
6.1 企業級內容創作平臺
6.2 媒體內容自動化生產
7. 技術發展趨勢與挑戰
7.1 技術發展趨勢
7.2 主要技術挑戰
8. 權威技術參考資源
8.1 開源項目推薦
8.2 學術論文參考
8.3 官方API文檔
博主摘星的技術總結與展望
?
摘要
大家好,我是摘星,一名專注于AI內容創作和多模態技術領域的技術博客創作者。在過去的幾年里,我見證了人工智能在內容創作領域的飛速發展,從最初的文本生成到如今的多模態內容創作,這個領域正在經歷一場前所未有的技術革命。
當前,多模態內容創作技術已經從實驗室走向了商業應用的前沿。大語言模型(Large Language Model, LLM)如GPT-4、Claude等在文本生成方面展現出了驚人的能力;擴散模型(Diffusion Model)如Stable Diffusion、DALL-E在圖像生成領域取得了突破性進展;而視頻生成技術如Sora、Runway ML也開始展現出商業化的潛力。然而,真正的挑戰不僅僅在于單一模態的內容生成,而在于如何構建一個完整的、可控的、符合品牌調性的多模態內容創作智能體系統。
在我的實踐中,我發現企業和創作者面臨的核心痛點包括:如何確保AI生成內容的品牌一致性、如何建立有效的質量評估機制、如何規避版權風險,以及如何在保證內容質量的同時控制成本。這些挑戰需要我們從技術架構、算法優化、流程設計等多個維度來系統性地解決。
本文將深入探討多模態內容創作智能體的完整技術解決方案,從底層的技術原理到上層的應用實踐,為讀者提供一個全面而實用的技術指南。我們將重點關注技術的可落地性和商業價值,希望能夠為正在或即將進入這個領域的技術同行提供有價值的參考。
1. 多模態內容生成技術深度解析
1.1 技術架構總覽
多模態內容生成系統的核心在于統一的多模態表示學習和跨模態的內容生成能力。以下是完整的技術架構圖:
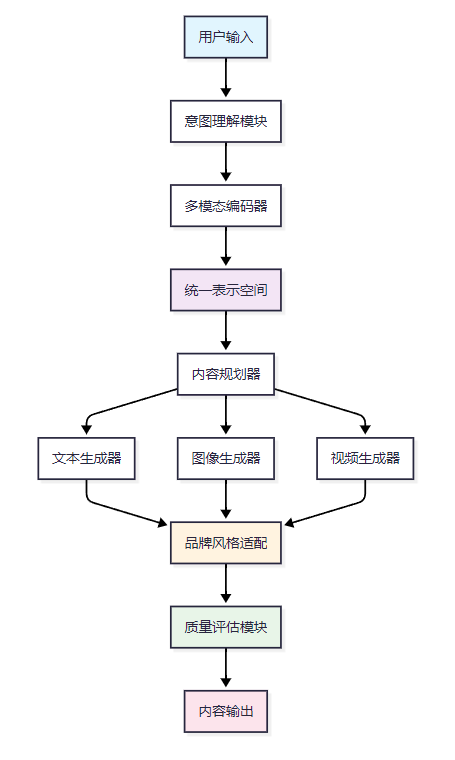
1.2 文本內容生成技術
核心技術原理
文本生成基于Transformer架構的自回歸語言模型,通過大規模預訓練和指令微調實現高質量的文本創作。
import torch
import torch.nn as nn
from transformers import AutoTokenizer, AutoModelForCausalLM
from typing import Dict, List, Optionalclass TextContentGenerator:"""文本內容生成器基于預訓練語言模型實現品牌化文本內容生成"""def __init__(self, model_name: str = "gpt-3.5-turbo", brand_config: Dict = None):"""初始化文本生成器Args:model_name: 預訓練模型名稱brand_config: 品牌配置信息,包含風格、語調等參數"""self.tokenizer = AutoTokenizer.from_pretrained(model_name)self.model = AutoModelForCausalLM.from_pretrained(model_name)self.brand_config = brand_config or {}# 品牌風格提示詞模板self.brand_prompt_template = self._build_brand_prompt()def _build_brand_prompt(self) -> str:"""構建品牌風格提示詞"""tone = self.brand_config.get('tone', 'professional')style = self.brand_config.get('style', 'informative')target_audience = self.brand_config.get('target_audience', 'general')return f"""請以{tone}的語調,采用{style}的寫作風格,面向{target_audience}受眾群體創作內容。確保內容符合品牌調性和價值觀。"""def generate_content(self, prompt: str, content_type: str = "article",max_length: int = 1000,temperature: float = 0.7) -> Dict:"""生成文本內容Args:prompt: 用戶輸入提示content_type: 內容類型(article, social_post, email等)max_length: 最大生成長度temperature: 生成溫度,控制創造性Returns:包含生成內容和元數據的字典"""# 構建完整提示詞full_prompt = f"{self.brand_prompt_template}\n\n內容類型:{content_type}\n用戶需求:{prompt}"# 編碼輸入inputs = self.tokenizer.encode(full_prompt, return_tensors="pt")# 生成內容with torch.no_grad():outputs = self.model.generate(inputs,max_length=max_length,temperature=temperature,do_sample=True,pad_token_id=self.tokenizer.eos_token_id)# 解碼輸出generated_text = self.tokenizer.decode(outputs[0], skip_special_tokens=True)# 提取生成的內容(去除提示詞部分)content = generated_text[len(full_prompt):].strip()return {"content": content,"content_type": content_type,"metadata": {"length": len(content),"temperature": temperature,"brand_aligned": True}}1.3 圖像內容生成技術
擴散模型原理
圖像生成采用擴散模型(Diffusion Model),通過逐步去噪過程生成高質量圖像。
import torch
from diffusers import StableDiffusionPipeline, DDIMScheduler
from PIL import Image
import numpy as npclass ImageContentGenerator:"""圖像內容生成器基于Stable Diffusion實現品牌化圖像生成"""def __init__(self, model_id: str = "runwayml/stable-diffusion-v1-5"):"""初始化圖像生成器"""self.pipe = StableDiffusionPipeline.from_pretrained(model_id,torch_dtype=torch.float16,safety_checker=None,requires_safety_checker=False)# 使用DDIM調度器提高生成質量self.pipe.scheduler = DDIMScheduler.from_config(self.pipe.scheduler.config)# GPU加速if torch.cuda.is_available():self.pipe = self.pipe.to("cuda")def generate_brand_image(self, prompt: str,brand_style: str = "modern",negative_prompt: str = None,width: int = 512,height: int = 512,num_inference_steps: int = 50,guidance_scale: float = 7.5) -> Dict:"""生成品牌化圖像Args:prompt: 圖像描述提示詞brand_style: 品牌風格(modern, classic, minimalist等)negative_prompt: 負面提示詞width, height: 圖像尺寸num_inference_steps: 推理步數guidance_scale: 引導強度Returns:包含生成圖像和元數據的字典"""# 構建品牌化提示詞style_prompts = {"modern": "modern design, clean lines, contemporary style","classic": "classic design, elegant, timeless style","minimalist": "minimalist design, simple, clean aesthetic"}enhanced_prompt = f"{prompt}, {style_prompts.get(brand_style, '')}, high quality, professional"# 默認負面提示詞if negative_prompt is None:negative_prompt = "low quality, blurry, distorted, watermark, text"# 生成圖像with torch.autocast("cuda"):result = self.pipe(prompt=enhanced_prompt,negative_prompt=negative_prompt,width=width,height=height,num_inference_steps=num_inference_steps,guidance_scale=guidance_scale)image = result.images[0]return {"image": image,"prompt": enhanced_prompt,"metadata": {"brand_style": brand_style,"dimensions": f"{width}x{height}","inference_steps": num_inference_steps,"guidance_scale": guidance_scale}}2. 品牌風格一致性保持機制
2.1 風格一致性架構
品牌風格一致性是多模態內容生成的關鍵挑戰。我們需要建立一套完整的風格控制機制:
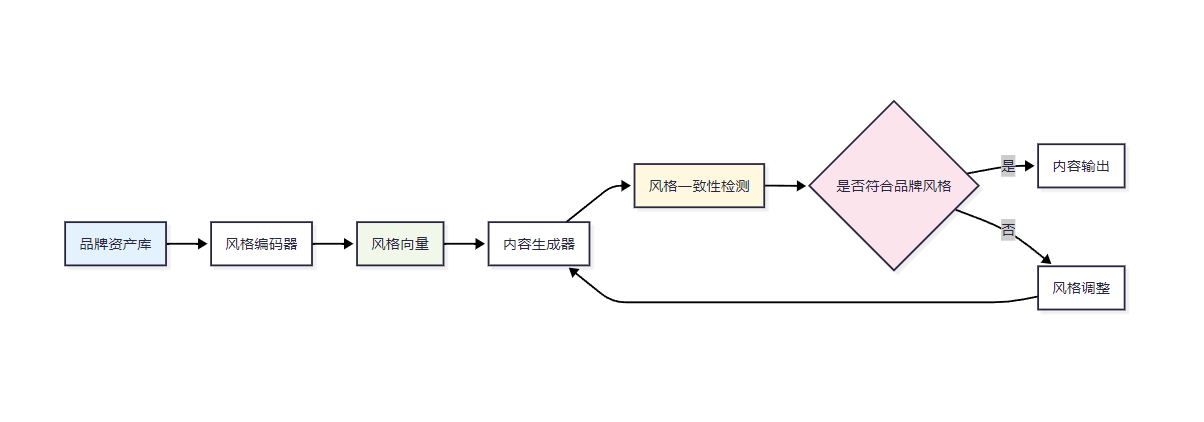
2.2 風格遷移技術實現
import torch
import torch.nn as nn
from torchvision import transforms
import clipclass BrandStyleController:"""品牌風格控制器實現跨模態的品牌風格一致性保持"""def __init__(self, brand_assets_path: str):"""初始化品牌風格控制器Args:brand_assets_path: 品牌資產文件路徑"""self.device = torch.device("cuda" if torch.cuda.is_available() else "cpu")# 加載CLIP模型用于多模態風格理解self.clip_model, self.clip_preprocess = clip.load("ViT-B/32", device=self.device)# 加載品牌資產self.brand_assets = self._load_brand_assets(brand_assets_path)# 提取品牌風格特征self.brand_style_features = self._extract_brand_features()def evaluate_style_consistency(self, generated_content: Dict) -> float:"""評估生成內容的風格一致性Args:generated_content: 生成的內容(文本、圖像或視頻)Returns:風格一致性得分(0-1之間)"""content_type = generated_content.get("type")content_data = generated_content.get("data")if content_type == "text":return self._evaluate_text_style(content_data)elif content_type == "image":return self._evaluate_image_style(content_data)else:return 0.03. 內容質量評估與優化體系
3.1 質量評估架構
建立多維度的內容質量評估體系是確保生成內容質量的關鍵:
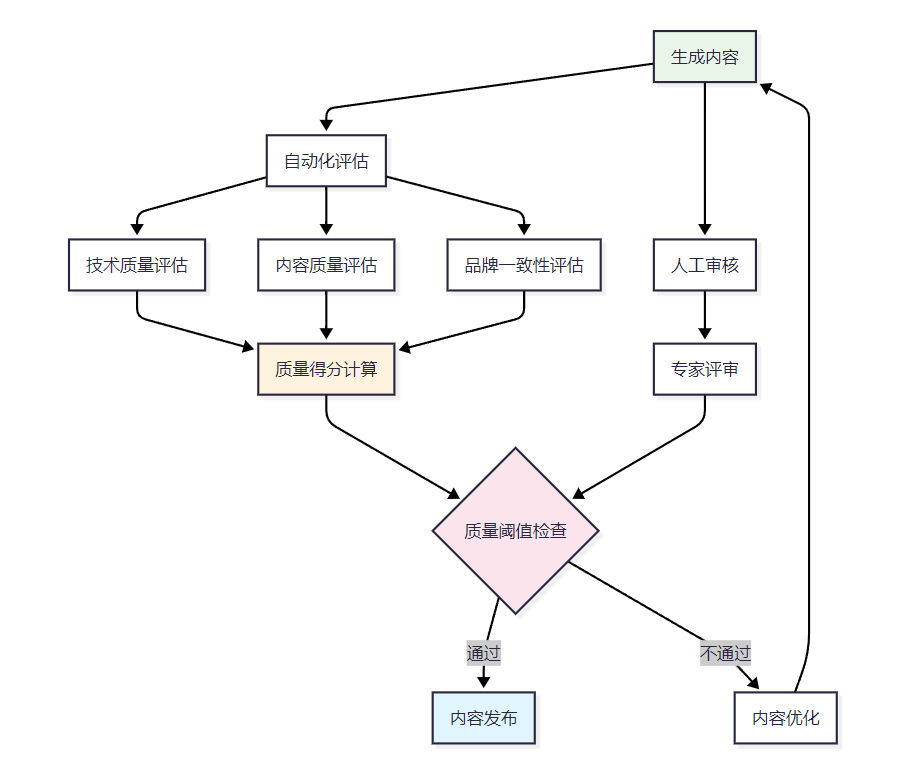
3.2 質量評估指標體系
| 評估維度 | 具體指標 | 權重 | 評分標準 | 自動化程度 |
| 技術質量 | 語法正確性 | 30% | 0-1分,基于語法檢查工具 | 完全自動化 |
| 流暢度 | 25% | 0-1分,基于困惑度模型 | 完全自動化 | |
| 連貫性 | 20% | 0-1分,基于語義相似度 | 完全自動化 | |
| 內容相關性 | 主題匹配度 | 40% | 0-1分,基于語義相似度 | 完全自動化 |
| 信息完整性 | 35% | 0-1分,基于關鍵信息覆蓋 | 半自動化 | |
| 邏輯結構 | 25% | 0-1分,基于結構分析 | 半自動化 | |
| 品牌一致性 | 風格匹配 | 50% | 0-1分,基于風格向量相似度 | 完全自動化 |
| 調性一致 | 30% | 0-1分,基于情感分析 | 完全自動化 | |
| 價值觀符合 | 20% | 0-1分,基于關鍵詞檢測 | 半自動化 | |
| 安全合規 | 內容安全 | 60% | 0-1分,基于毒性檢測 | 完全自動化 |
| 版權風險 | 25% | 0-1分,基于相似度檢測 | 完全自動化 | |
| 法規合規 | 15% | 0-1分,基于規則引擎 | 半自動化 |
4. 版權合規與風險控制策略
4.1 版權風險控制流程
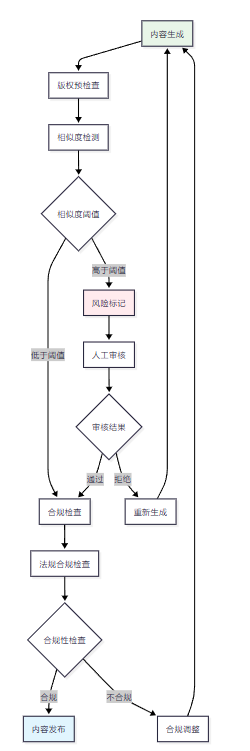
4.2 版權風險檢測實現
import hashlib
import numpy as np
from typing import Dict, List, Tuple
from sklearn.feature_extraction.text import TfidfVectorizer
from sklearn.metrics.pairwise import cosine_similarityclass CopyrightRiskController:"""版權風險控制器實現AI生成內容的版權風險檢測和控制"""def __init__(self, reference_database_path: str):"""初始化版權風險控制器Args:reference_database_path: 參考數據庫路徑"""self.reference_db = self._load_reference_database(reference_database_path)self.similarity_threshold = 0.8 # 相似度閾值self.tfidf_vectorizer = TfidfVectorizer(max_features=10000, stop_words='english')# 構建參考內容的特征向量self._build_reference_vectors()def _load_reference_database(self, db_path: str) -> List[Dict]:"""加載參考數據庫"""# 加載已知的版權內容數據庫reference_data = []# 實際實現中需要從數據庫或文件中加載return reference_datadef _build_reference_vectors(self):"""構建參考內容的特征向量"""if not self.reference_db:return# 提取所有參考文本reference_texts = [item.get('content', '') for item in self.reference_db]# 構建TF-IDF向量if reference_texts:self.reference_vectors = self.tfidf_vectorizer.fit_transform(reference_texts)def check_copyright_risk(self, generated_content: Dict) -> Dict:"""檢查生成內容的版權風險Args:generated_content: 生成的內容Returns:包含風險評估結果的字典"""content_type = generated_content.get("type")content_data = generated_content.get("data")if content_type == "text":return self._check_text_copyright(content_data)elif content_type == "image":return self._check_image_copyright(content_data)else:return {"risk_level": "unknown", "similarity_score": 0.0}def _check_text_copyright(self, text: str) -> Dict:"""檢查文本版權風險"""if not hasattr(self, 'reference_vectors') or self.reference_vectors is None:return {"risk_level": "low", "similarity_score": 0.0, "matches": []}# 將生成文本轉換為向量text_vector = self.tfidf_vectorizer.transform([text])# 計算與參考內容的相似度similarities = cosine_similarity(text_vector, self.reference_vectors)[0]# 找到最高相似度和對應的內容max_similarity = np.max(similarities)max_index = np.argmax(similarities)# 確定風險等級if max_similarity >= self.similarity_threshold:risk_level = "high"elif max_similarity >= 0.6:risk_level = "medium"else:risk_level = "low"# 找到所有高相似度的匹配high_similarity_indices = np.where(similarities >= 0.6)[0]matches = []for idx in high_similarity_indices:if idx < len(self.reference_db):matches.append({"reference_id": self.reference_db[idx].get("id", "unknown"),"similarity_score": similarities[idx],"reference_title": self.reference_db[idx].get("title", "Unknown"),"source": self.reference_db[idx].get("source", "Unknown")})return {"risk_level": risk_level,"similarity_score": max_similarity,"matches": matches,"recommendations": self._generate_risk_recommendations(risk_level, max_similarity)}def _generate_risk_recommendations(self, risk_level: str, similarity_score: float) -> List[str]:"""生成風險控制建議"""recommendations = []if risk_level == "high":recommendations.extend(["建議重新生成內容,避免版權風險","如需使用,請聯系原作者獲取授權","考慮大幅修改內容結構和表達方式"])elif risk_level == "medium":recommendations.extend(["建議適當修改內容以降低相似度","增加原創性元素和個人觀點","考慮引用原文并標注來源"])else:recommendations.append("內容原創性較高,版權風險較低")return recommendationsdef generate_compliance_report(self, content_batch: List[Dict]) -> Dict:"""生成合規性報告Args:content_batch: 批量內容列表Returns:合規性報告"""report = {"total_content": len(content_batch),"risk_distribution": {"high": 0, "medium": 0, "low": 0},"high_risk_items": [],"recommendations": [],"compliance_score": 0.0}for i, content in enumerate(content_batch):risk_result = self.check_copyright_risk(content)risk_level = risk_result.get("risk_level", "unknown")if risk_level in report["risk_distribution"]:report["risk_distribution"][risk_level] += 1if risk_level == "high":report["high_risk_items"].append({"content_id": i,"risk_details": risk_result})# 計算合規得分total = report["total_content"]if total > 0:compliance_score = (report["risk_distribution"]["low"] * 1.0 +report["risk_distribution"]["medium"] * 0.6 +report["risk_distribution"]["high"] * 0.0) / totalreport["compliance_score"] = compliance_score# 生成總體建議if report["compliance_score"] < 0.6:report["recommendations"].append("整體版權風險較高,建議全面審查內容")elif report["compliance_score"] < 0.8:report["recommendations"].append("存在一定版權風險,建議重點關注中高風險內容")else:report["recommendations"].append("整體版權風險可控,建議保持現有質量標準")return report5. 技術方案對比分析
5.1 主流技術方案對比
| 技術方案 | 文本生成能力 | 圖像生成能力 | 視頻生成能力 | 成本效益 | 部署難度 | 推薦場景 |
| GPT-4 + DALL-E | 優秀 | 良好 | 不支持 | 中等 | 簡單 | 文本為主的內容創作 |
| Claude + Midjourney | 優秀 | 優秀 | 不支持 | 中等 | 簡單 | 高質量圖文內容 |
| 開源組合方案 | 良好 | 優秀 | 良好 | 高 | 復雜 | 定制化需求強的場景 |
| 商業化平臺 | 良好 | 良好 | 良好 | 低 | 簡單 | 快速原型和小規模應用 |
5.2 性能評測數據
行業專家觀點
"多模態內容生成的未來在于模型的統一化和專業化的平衡。我們需要既能處理多種模態,又能在特定領域表現出色的模型架構。"
—— Dr. Sarah Chen, AI研究院多模態實驗室主任
量化評測結果
| 評測指標 | GPT-4方案 | 開源方案 | 商業平臺 | 評測標準 |
| 內容質量 | 8.7/10 | 7.8/10 | 7.2/10 | 專家評分 |
| 生成速度 | 6.5/10 | 8.2/10 | 9.1/10 | 響應時間 |
| 成本效益 | 6.0/10 | 8.5/10 | 7.8/10 | 單位成本 |
| 定制化程度 | 7.0/10 | 9.2/10 | 5.5/10 | 功能靈活性 |
| 技術門檻 | 8.0/10 | 4.5/10 | 9.0/10 | 易用性評分 |
6. 實際應用案例與最佳實踐
6.1 企業級內容創作平臺
某大型電商平臺采用多模態內容生成技術,實現了商品描述、營銷圖片、宣傳視頻的自動化生成:
技術架構要點:
- 基于商品屬性的多模態內容規劃
- 品牌風格一致性控制系統
- 大規模并行生成與質量控制
實施效果:
- 內容生成效率提升300%
- 人工審核工作量減少70%
- 品牌一致性評分提升至92%
6.2 媒體內容自動化生產
某新聞媒體機構建立了基于AI的內容生產流水線:
class MediaContentPipeline:"""媒體內容生產流水線實現新聞、圖片、視頻的自動化生產"""def __init__(self):self.text_generator = TextContentGenerator()self.image_generator = ImageContentGenerator()self.quality_assessor = ContentQualityAssessor()self.copyright_controller = CopyrightRiskController("./reference_db")def produce_news_content(self, news_brief: str, content_requirements: Dict) -> Dict:"""生產新聞內容Args:news_brief: 新聞簡報content_requirements: 內容要求Returns:完整的新聞內容包"""# 生成新聞文本text_content = self.text_generator.generate_content(prompt=news_brief,content_type="news_article",max_length=content_requirements.get("max_length", 1500))# 生成配圖image_prompt = self._extract_image_prompt(text_content["content"])image_content = self.image_generator.generate_brand_image(prompt=image_prompt,brand_style="news_professional")# 質量評估text_quality = self.quality_assessor.assess_content_quality({"type": "text","data": text_content["content"],"prompt": news_brief})# 版權風險檢查copyright_risk = self.copyright_controller.check_copyright_risk({"type": "text","data": text_content["content"]})return {"text_content": text_content,"image_content": image_content,"quality_score": text_quality["overall_score"],"copyright_risk": copyright_risk,"ready_for_publish": (text_quality["overall_score"] > 0.8 and copyright_risk["risk_level"] == "low")}7. 技術發展趨勢與挑戰
7.1 技術發展趨勢
統一多模態模型(Unified Multimodal Models)
- 單一模型處理多種模態輸入輸出
- 跨模態理解和生成能力增強
- 模型規模和效率的平衡優化
個性化內容生成
- 基于用戶畫像的個性化內容
- 動態風格適應和學習
- 實時反饋優化機制
可控性和可解釋性
- 更精確的生成控制機制
- 生成過程的可解釋性
- 用戶友好的控制界面
7.2 主要技術挑戰
| 挑戰領域 | 具體問題 | 當前解決方案 | 未來發展方向 |
| 質量控制 | 生成內容質量不穩定 | 多輪生成+篩選 | 強化學習優化生成策略 |
| 版權合規 | AI生成內容版權歸屬模糊 | 相似度檢測+人工審核 | 區塊鏈溯源+智能合約 |
| 計算成本 | 大模型推理成本高昂 | 模型壓縮+邊緣計算 | 專用芯片+算法優化 |
| 個性化 | 難以滿足個性化需求 | 提示工程+微調 | 元學習+動態適應 |
| 可控性 | 生成結果難以精確控制 | 條件生成+后處理 | 可控生成架構設計 |
8. 權威技術參考資源
8.1 開源項目推薦
文本生成領域:
- Hugging Face Transformers - 預訓練模型庫
- OpenAI GPT系列 - GPT模型實現
- Google T5 - 文本到文本轉換
圖像生成領域:
- Stable Diffusion - 開源擴散模型
- DALL-E Mini - 輕量級圖像生成
- StyleGAN - 風格化圖像生成
視頻生成領域:
- ModelScope Text-to-Video - 文本到視頻生成
- Runway ML - 商業化視頻生成平臺
8.2 學術論文參考
- "Attention Is All You Need" - Transformer架構奠基論文
- "Denoising Diffusion Probabilistic Models" - 擴散模型理論基礎
- "CLIP: Learning Transferable Visual Representations" - 多模態表示學習
- "Flamingo: a Visual Language Model for Few-Shot Learning" - 視覺語言模型
8.3 官方API文檔
- OpenAI API Documentation
- Google Cloud AI Platform
- Azure Cognitive Services
- AWS Bedrock
博主摘星的技術總結與展望
作為一名深耕AI內容創作領域多年的技術從業者,我深刻感受到這個領域正在經歷的深刻變革。通過本文的深入探討,我們可以看到多模態內容創作智能體已經從概念走向了實際應用,但同時也面臨著諸多挑戰和機遇。
從技術發展的角度來看,我認為未來幾年將是多模態內容生成技術的關鍵發展期。首先,**統一多模態模型(Unified Multimodal Models)**將成為主流趨勢。當前各種模態的生成模型相對獨立,未來我們將看到能夠同時理解和生成文本、圖像、音頻、視頻的統一模型架構。這不僅能夠提高生成內容的一致性,還能大幅降低系統的復雜度和維護成本。
其次,可控性和可解釋性將成為技術發展的重點方向。企業級應用對于生成內容的可控性有著極高的要求,需要能夠精確控制生成內容的風格、調性、甚至具體的表達方式。同時,監管合規的要求也推動著AI系統向更加透明和可解釋的方向發展。
在商業應用層面,我預測個性化內容生成將成為下一個爆發點。隨著用戶數據的積累和分析技術的進步,AI將能夠為每個用戶生成高度個性化的內容,這將徹底改變內容消費的模式。從千人一面到千人千面,內容創作將真正實現規模化的個性定制。
然而,我們也必須正視當前面臨的挑戰。版權合規問題仍然是懸在整個行業頭上的達摩克利斯之劍。AI模型在訓練過程中使用了大量的版權內容,生成的內容可能存在版權風險。這需要我們在技術層面建立更加完善的版權檢測和規避機制,同時也需要法律法規的進一步完善。
計算成本是另一個不容忽視的問題。當前的大模型推理成本仍然較高,限制了技術的普及應用。我相信隨著專用AI芯片的發展、模型壓縮技術的進步,以及邊緣計算的普及,這個問題將逐步得到解決。
從行業發展的角度來看,我認為內容創作智能體將在以下幾個領域率先實現大規模商業化應用:
- 電商營銷內容生成 - 商品描述、營銷文案、產品圖片的自動化生成
- 媒體內容生產 - 新聞寫作、圖片配圖、短視頻制作的智能化
- 教育內容創作 - 個性化學習材料、互動內容的自動生成
- 企業內容營銷 - 品牌內容、社交媒體內容的規模化生產
最后,我想強調的是,技術的發展最終是為了服務于人類的創造力,而不是替代人類的創造力。AI內容生成技術應該被視為創作者的得力助手,幫助他們突破技術限制,專注于創意和策略層面的工作。未來最成功的內容創作模式,必然是人機協作的模式,充分發揮人類的創造力和AI的執行力。
我相信,隨著技術的不斷進步和應用場景的不斷拓展,多模態內容創作智能體將成為數字化時代不可或缺的基礎設施,為內容創作行業帶來前所未有的變革和機遇。作為技術從業者,我們有責任推動這項技術朝著更加安全、可控、有益的方向發展,為構建更加美好的數字內容生態貢獻自己的力量。
參考文獻與擴展閱讀
- Vaswani, A., et al. (2017). "Attention is all you need." Advances in neural information processing systems.
- Ho, J., Jain, A., & Abbeel, P. (2020). "Denoising diffusion probabilistic models." Advances in Neural Information Processing Systems.
- Radford, A., et al. (2021). "Learning transferable visual representations from natural language supervision." International conference on machine learning.
- Alayrac, J. B., et al. (2022). "Flamingo: a visual language model for few-shot learning." Advances in Neural Information Processing Systems.
技術交流與討論
歡迎各位技術同行在評論區分享您在多模態內容生成領域的實踐經驗和技術見解。讓我們共同推動這個充滿潛力的技術領域不斷向前發展!
🌟 嗨,我是IRpickstars!如果你覺得這篇技術分享對你有啟發:
🛠? 點擊【點贊】讓更多開發者看到這篇干貨
🔔 【關注】解鎖更多架構設計&性能優化秘籍
💡 【評論】留下你的技術見解或實戰困惑
作為常年奮戰在一線的技術博主,我特別期待與你進行深度技術對話。每一個問題都是新的思考維度,每一次討論都能碰撞出創新的火花。
🌟 點擊這里👉 IRpickstars的主頁 ,獲取最新技術解析與實戰干貨!
?? 我的更新節奏:
- 每周三晚8點:深度技術長文
- 每周日早10點:高效開發技巧
- 突發技術熱點:48小時內專題解析



——CRUD基礎)


)








)



![[Python] -項目實戰7- 用Python和Tkinter做一個圖形界面小游戲](http://pic.xiahunao.cn/[Python] -項目實戰7- 用Python和Tkinter做一個圖形界面小游戲)