一原文
在第一階段,用重定位的人體運動數據在模擬中預訓練運動跟蹤策略。
在第二階段,在現實世界中部署策略并收集現實世界數據來訓練一個增量(殘差)動作模型來補償動態不匹配。
,ASAP 使用集成到模擬器中的增量動作模型對預訓練策略進行微調,以有效地與現實世界的動態保持一致。
與 SysID、DR 和增量動態學習基線相比,減少跟蹤誤差。ASAP 實現以前難以實現的高度敏捷運動,展示增量動作學習在連接模擬和現實世界動態方面的潛力。
實現人形機器人的敏捷全身技能仍然是一項根本挑戰,這不僅是因為硬件限制,還因為模擬動力學與現實世界物理之間的不匹配。
出現了三種主要方法來彌合動力學不匹配:系統識別 (SysID) 方法、域隨機化 (DR) 和學習動力學方法。
SysID 方法直接估計關鍵物理參數,例如電機響應特性、每個機器人連桿的質量和地形特性。
DR 方法依賴于隨機化模擬參數 [87, 68];但這可能導致過于保守的策略 [26]
彌合動態不匹配的另一種方法是使用現實世界數據學習現實世界物理的動態模型。雖然這種方法已經在無人機[81]和地面車輛[97]等低維系統中取得了成功,但其對人形機器人的有效性仍未得到探索。
二 步驟
(a) 從視頻中捕捉人體動作。(b) 使用 TRAM [93],以 SMPL 參數格式重建 3D 人體運動。(c) 在模擬中訓練強化學習 (RL) 策略以跟蹤 SMPL 運動。(d) 在模擬中,將學習的 SMPL 運動重定位到 Unitree G1 人形機器人。(e) 訓練有素的 RL 策略部署在真實機器人上,在物理世界中執行最終運動。
(a):從2D視頻幀中恢復3D人體姿態和動作序列,計算機視覺的方法,有很多現有的模型。需要動作優化和后處理,例如限位、例如瞬時高速移動的濾波,去噪等等。
(b):時序感知的3D姿態估計方法。TRAM 是一個 ??“視頻動作翻譯器”??,它把普通視頻里的人物動作,轉換成計算機能懂的 ??SMPL數字人參數??,生成3D動畫。(1標記出每幀的關節位置,2 根據前后幀的關系,推測關節在3D空間中的位置,??匹配數字人(SMPL)??:調整SMPL模型的 ??“姿勢旋鈕”??(72個參數控制關節旋轉)和 ??“體型旋鈕”??(10個參數控制高矮胖瘦),讓3D數字人的動作和視頻里真人一致。)
TRAM [93] 的核心創新在于 ??聯合優化時序連續性與SMPL參數空間??,使用HRNet或ViTPose檢測視頻每一幀的2D人體關鍵點(17或25點),
最終得到一串 ??SMPL參數??,導入到3D軟件(如Blender)就能看到和視頻一樣的數字人動畫。
TRAM 的聰明之處是,像“腦補”連續動作,避免突然卡頓,自動過濾不可能的動作(比如膝蓋不會往后彎)。
基于模型的數據清理:讓一個 ??數字人(SMPL模型)?? 在虛擬世界里做這些動作。
MaskedMimic ,:一個 ??基于物理的動作修正器??,用于修復3D人體動作中的物理錯誤(如穿模、反關節、速度突變等)。主要配合SMPL動作數據(如TRAM的輸出)和物理模擬器(如IsaacGym)使用。
c) 將 SMPL 運動重定位為機器人運動:階段1:優化體型(β′調整),讓SMPL模型的“骨架”盡量接近機器人。
階段2:優化動作(θ和p調整),在匹配的體型下,讓動作軌跡也適合機器人。固定優化后的β′??,只調動作參數(姿勢θ + 根節點平移p)。
機器人殘差學習:這些模型可以改進初始控制器的動作,其他方法利用殘差組件來糾正動力學模型中的不準確性。
三 理解
1?如何進行模仿學習。(通過強化學習獎勵的形式學習
不只是各個關節的位置。還包括:
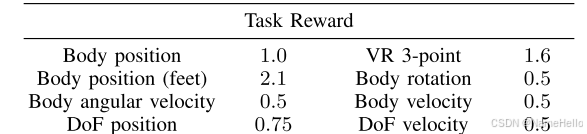
主要任務是跟蹤腳的位置,
實時跟蹤用戶 ??頭顯(1點) + 雙手控制器(2點)?? 的空間位置,共3個關鍵點(故稱"3-point")?
除此之外,當然加入一些正則化和懲罰措施。
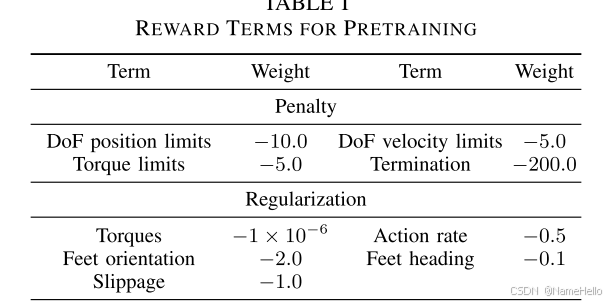
殘差模型。
直接將預訓練的策略,部署到真實機器人上,
記錄真實的狀態-動作對。 其中,狀態,
![]()
包括基座位置,基座的線速度,基座的線加速度、基座的角速度、關節位置、關節速度。
其中,基座的位置、線速度是無法直接獲得的。
殘差模型:下一狀態= F_sim(當前狀態,真實action, + 殘差action)
理解:假設在仿真中按相位直接給真實的action軌跡,那么表現的動作和真實不像,和原策略的動作也不像。如果要是和真機表現一致的話,也就說明沒有sim和real差了。
加入殘差action讓狀態表現的和原策略一樣,這毫無意義,因為這個優化目標是(殘差為原策略仿真action 和真機action的差)
但是,如果殘差action能讓仿真中的表現和現實一樣的話?,那么就量化了仿真與現實的差異,也就是殘差模型代表了現實和仿真的差異。所以優化目標是:在訓練殘差模型時,讓機器人的環境反饋狀態和現實采集的狀態一致。
所以ASAP是確切的real2sim,將現實的策略部署到仿真環境中。如果只訓練一個策略讓仿真和現實狀態一致,就變成了克隆學習,而采集現實的action是獲取殘差action的關鍵,假設采集的數據足夠多,那么其實是具有足夠泛性應用到其他動作的。
可以直接在原策略- 殘差策略,輸出到真機(注意,是減不是加)。
論文:固定殘差模型,在原策略action下加入殘差策略action,如果直接play,那在仿真中的表現要比原策略差,但應該是偏向于真實表現一側的。
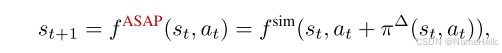
再訓練一下原策略,假設訓練的足夠充分,那么新的策略 = 原策略 - 殘差策略,因為優化目標和最初是一致的。
新的策略+殘差策略在仿真中表現良好,然后不要殘差策略,直接將新策略部署到真機。
微調的原因是:殘差策略是從真機軌跡上得到的,但真機軌跡又不太好,存在過擬合的問題。
舉例子:仿真策略訓練到10度,部署真機到9度,采集真機狀態和動作,動作放到仿真中去,可能是9度左右,可能是10度左右度,? 假設是10.5, 原策略上加一個殘差策略,按仿真狀態和真機狀態一致對殘差策略進行訓練,那么這個策略最終的action效果是-1.5度,這代表了仿真和現實差異。?
方法1 :直接部署,原策略-殘差策略 到真機,真機角度比原來更接近10度。
方法2:ASAP,原策略+殘差策略(凍結),訓練原策略,獎勵與最初一致。若完全充分訓練,新策略 = 原策略-殘差策略,此時部署新策略到真機。也可控制訓練程度,只對原策略進行微調。










 文件對話框 QFileDialog 篇二:源碼帶注釋)

)






