數據庫自己會關閉嗎?
從現象來說Oracle MySQL Redis等都會出現進程意外停止的情況。而這些停止都是非人為正常關閉或者暴力關閉(abort或者kill 進程)
一次測試環境的非關閉
一般遇到這種情況先看一下錯誤日志吧。
2025-06-01T06:26:06.352576+08:00
PMON (ospid: ): terminating the instance due to ORA error
2025-06-01T06:26:06.374973+08:00
Cause - ‘Instance is being terminated due to fatal process death (pid: 14, ospid: 118685, DBRM)’
2025-06-01T06:26:06.968910+08:00
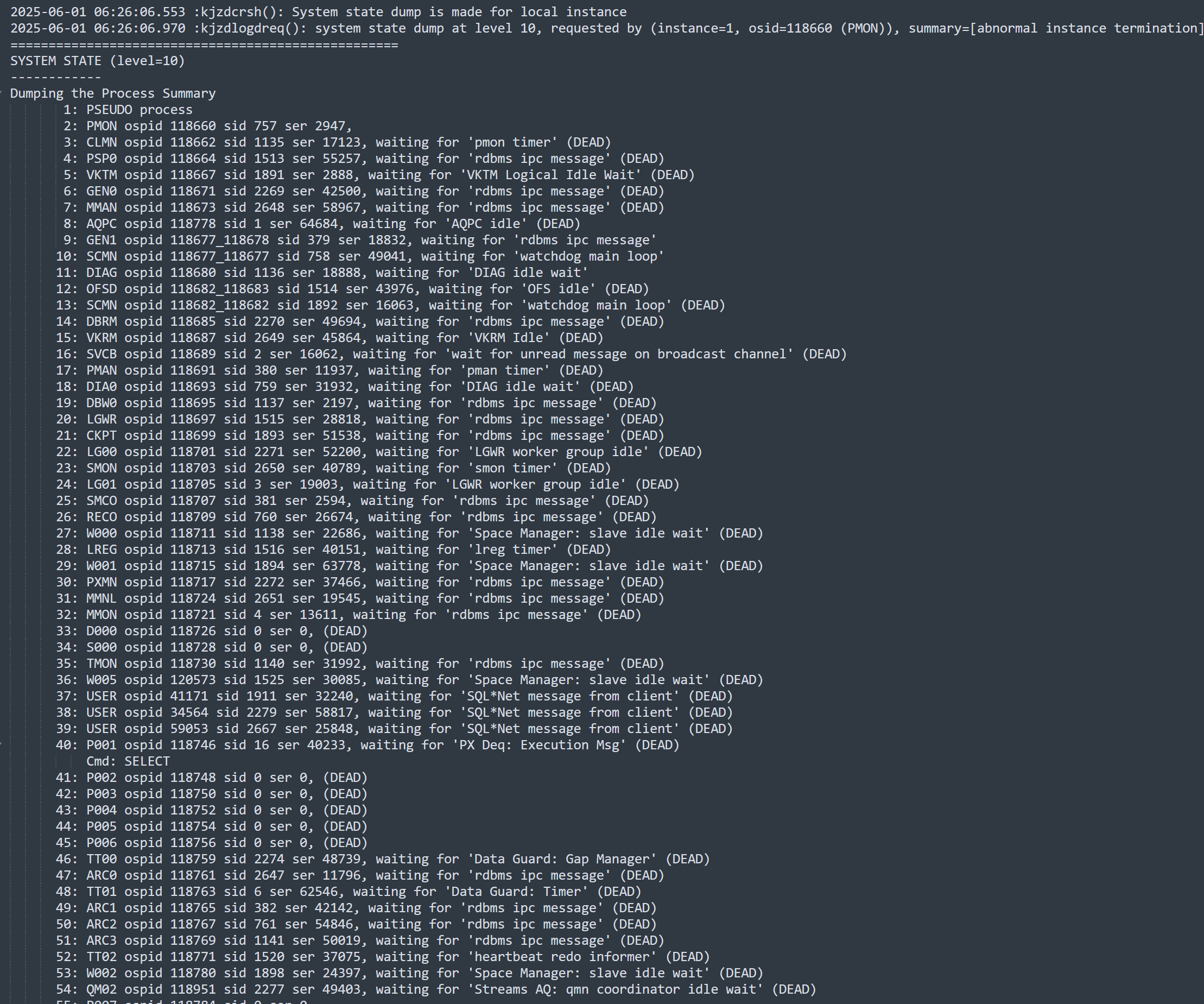
System state dump requested by (instance=1, osid=118660 (PMON)), summary=[abnormal instance termination].
System State dumped to trace file /u01/oracle/diag/rdbms/uatsoc/uatsoc/trace/uatsoc_diag_118680.trc
2025-06-01T06:26:12.505063+08:00
Instance terminated by PMON, pid = 118660
從字面翻譯:由于進程死亡,實例正在終止。這里提到一個關鍵字DBRM。按說應該是Oracle資源管理器(Oracle Database Resource Manager,簡稱DBRM)管理數據庫的資源分配。那么一般都是CPU、IO和內存之類的。就去這些看看。
從trace文件中看到一開始(一般外國人的產品思維先把重要的寫在前面)
俗話說:事情出現之前都有先兆(我說的)
-
通常這種情況下我會先看一下出問題之前的最近的AWR
-
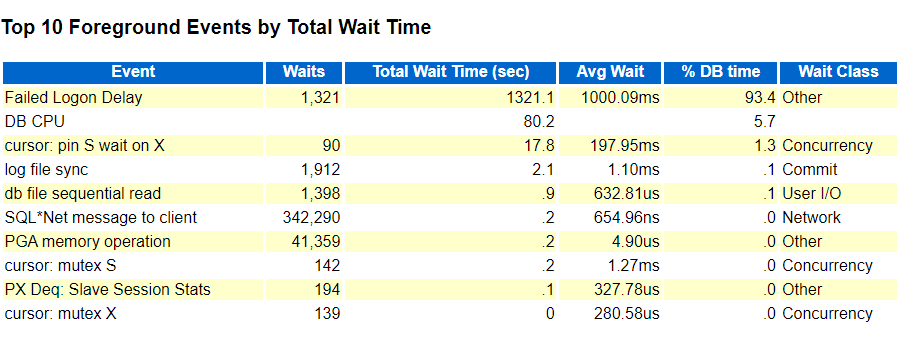
第一個等待事件非常少見。Failed Logon Delay這個異常一般都是因為有自動或者定時任務的程序使用的用戶名和密碼錯誤引起的。只能猜測不停地連接,而Oracle為了防止暴力破解,每次輸入錯誤,會延遲下一次輸入的時間。這個就行手機密碼錯了,然后要再多一段時間才行。但是一般來說不至于說登錄密碼錯誤多了就導致數據庫奔潰。
-
似乎內存分配的多了一點。SGA和PGA占了物理內存86%左右。這是出問題前30分鐘的AWR后面就沒有生成了。
-

-
只能靠ASH看看有沒有進一步的信息。
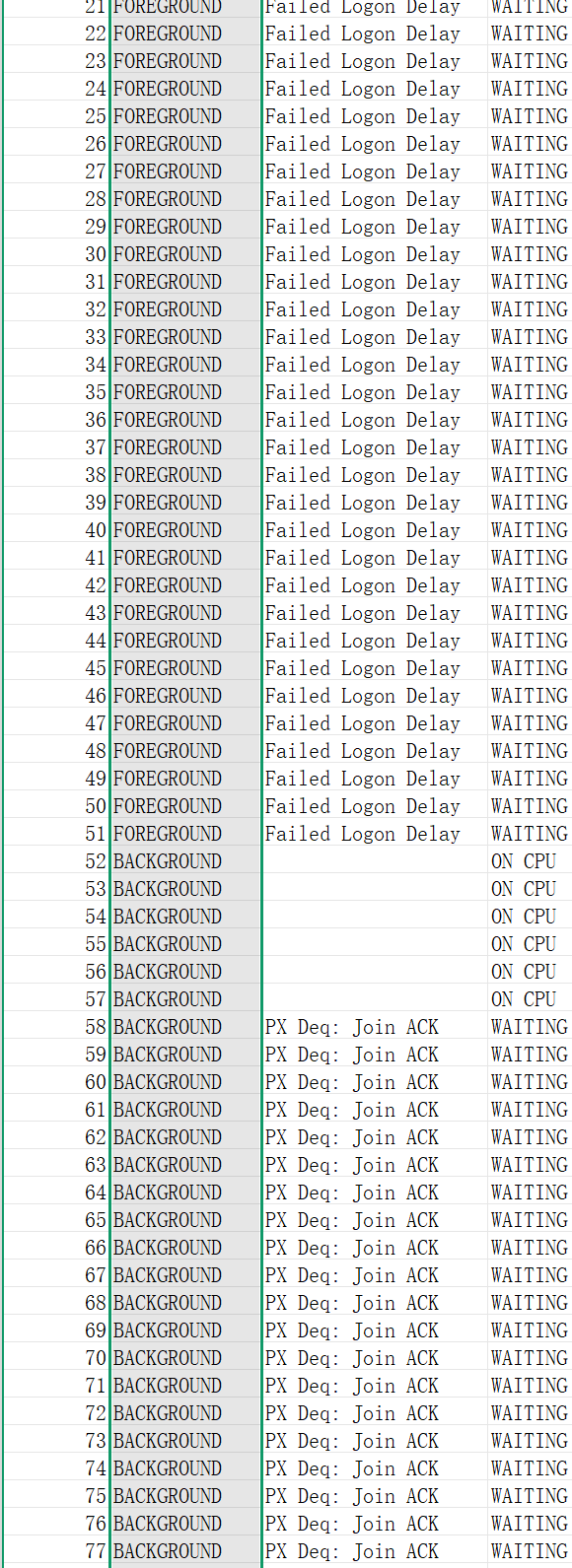
select session_type,event,session_state from dba_hist_active_sess_history t where t.SAMPLE_TIME>to_date(‘2025-06-01 06:00’,‘yyyy-mm-dd hh24:mi’) and t.SAMPLE_TIME<to_date(‘2025-06-01 06:26’,‘yyyy-mm-dd hh24:mi’) -
結果大致是這樣的:
-
-
PX Deq: Join ACK這個我沒有專門研究過,直到現在依然發現還有很多不懂的。
-
以我個人愚見:這些進程自動死亡(trace中的確寫了很多進程死掉了)
-
那么為什么進程死掉?結合剛才說的錯誤等待和內存占用高,可能是內存不足?
-
查找message日志
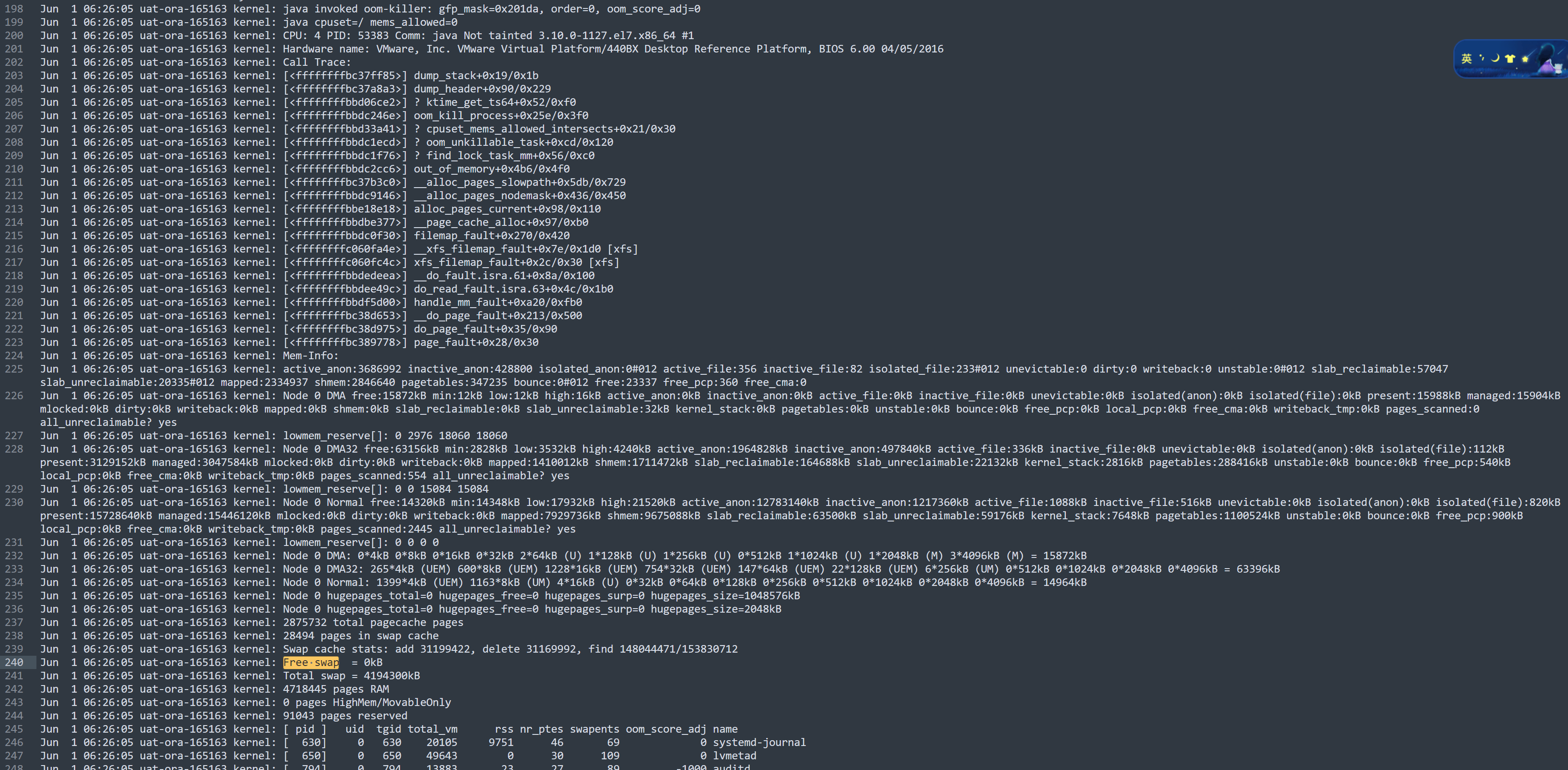
看到這里的確是oom被系統kill了。還提到了swap用完了。
- 當然這本身和分配過大有關。
- 為什么要分配這么大?因為測試環境的SQL質量不高,SGA和PGA都有很高的占用
記錄一下這個案例
- 給數據庫分配內存過大是遷就
- 根本上還是要SQL治理



邏輯圖解+實驗詳解)











)



)