
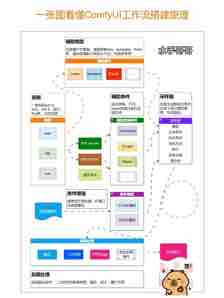
為什么要先講SD原理 ?
- 邏輯理解:?ComfyUI是節點式操作,需要自行搭建工作流,理解原理才能靈活定制工作流
- 學習效率: 基礎原理不懂會導致后續學習吃力,原理是掌握ComfyUI的關鍵
- 核心價值: ComfyUI最有價值的功能就是自主搭建工作流,這需要深入理解SD原理
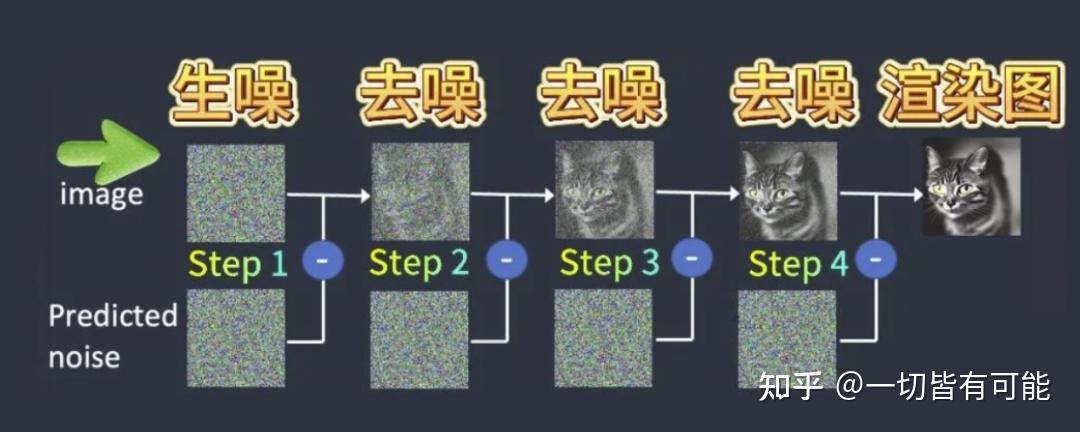
Stable Diffusion?擴散算法
- 基本概念: SD基于擴散算法(diffusion)生成圖像,中文譯為"穩定的擴散"
- 核心過程:
- 正向擴散: 生噪過程,增加噪點
- 反向擴散: 去噪過程,消除噪點
- 實現方式: 先將圖片鋪滿噪點,然后根據步數逐步降噪,最終得到目標圖像
- 關鍵結論: 圖像生成是從噪點到清晰圖片的漸進過程
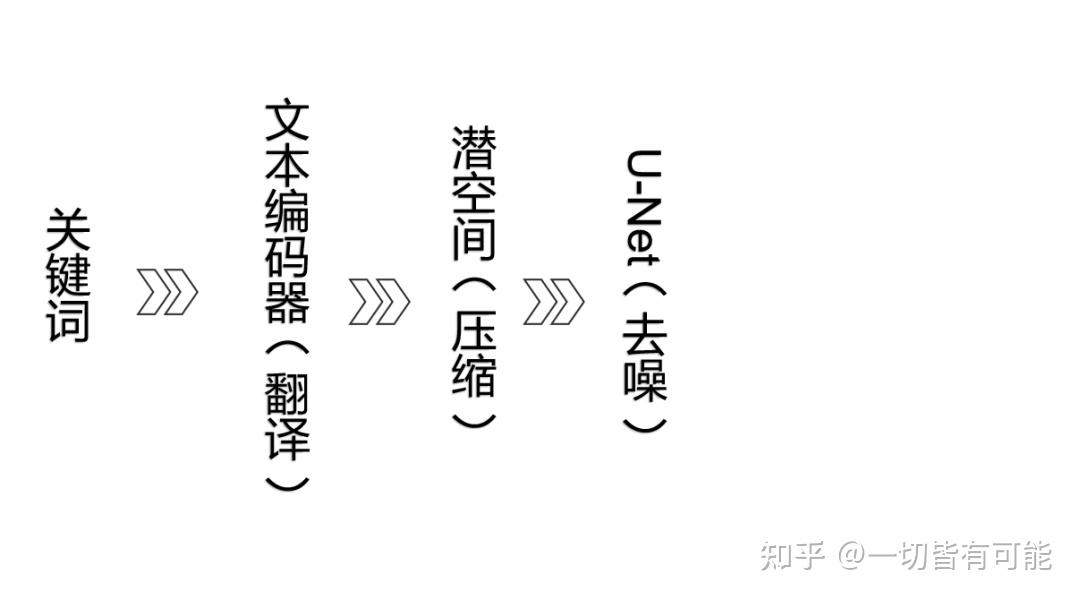
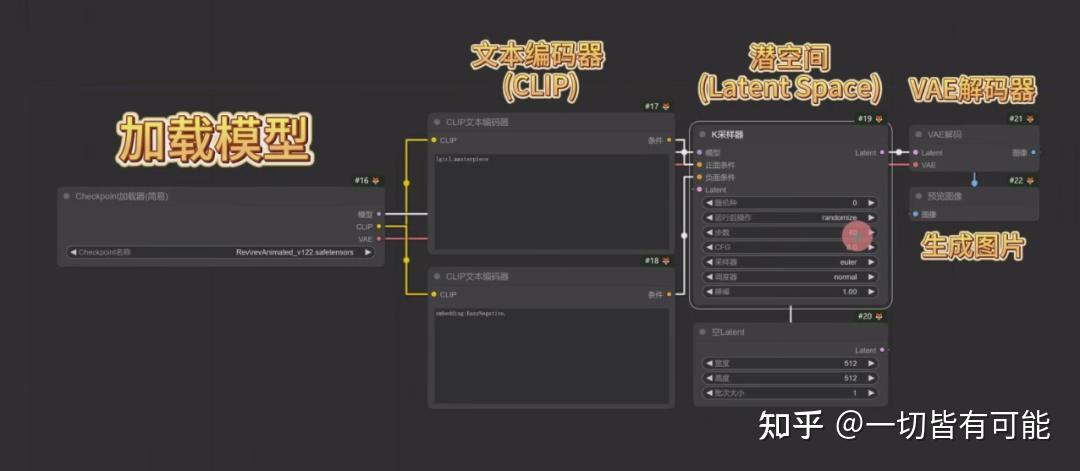
工作流示例
我們現在用一個實例來走一遍AI生圖的流程。比如說我們要讓AI生成一個美麗的女孩。
我們把關鍵詞"beautiful girl"輸入給計算機的時候,計算機無法理解"beautiful girl"。人類語言與計算機語言需要轉換,就像中英文交流需要翻譯。這就需要一個翻譯:CLIP。
CLIP
CLIP是Text Encoder(文本編碼器)的一種,其作用是將文本信息("beautiful girl")數字化,根據模型訓練經驗識別特征(大眼睛、好身材等)。將人類語言翻譯為計算機能理解的數字化描述(函數/向量)。CLIP使AI能捕捉文本含義,是SD工作流的關鍵組件。
Latent Space(潛空間)
剛才被CLIP編譯完的數字化信息會進入到 Latent Space(潛空間)。我們所使用的調度器,采樣器,CFG Scale都是在潛空間里進行工作的。
在 ComfyUI 中,Latent Space 是連接文本、模型和生成圖像的橋梁。它的核心價值在于:
高效性:壓縮表示降低計算成本。
靈活性:支持多種潛在空間操作和擴展。
模塊化:與 ComfyUI 的節點式工作流完美契合,便于可視化調試。
我們這里說一下其節省計算成本的作用,例如我要生成一張512x512的圖片。

在Latent Space(潛空間)內,數據會被壓縮:

Latent Space(潛空間)中有U-Net(作用是給圖片去噪),其可以對隨機種子生成噪聲圖進行引導。
VAE解碼器
到這一步,圖片其實已經被生成出來了,只不過此時的圖片是一張被壓縮的,數字化的(一堆向量和參數)的圖片,我們人類還無法看懂。
我們需要解碼器對圖片進行解壓,解碼器的作用是將計算機數據轉變為人類可視圖像
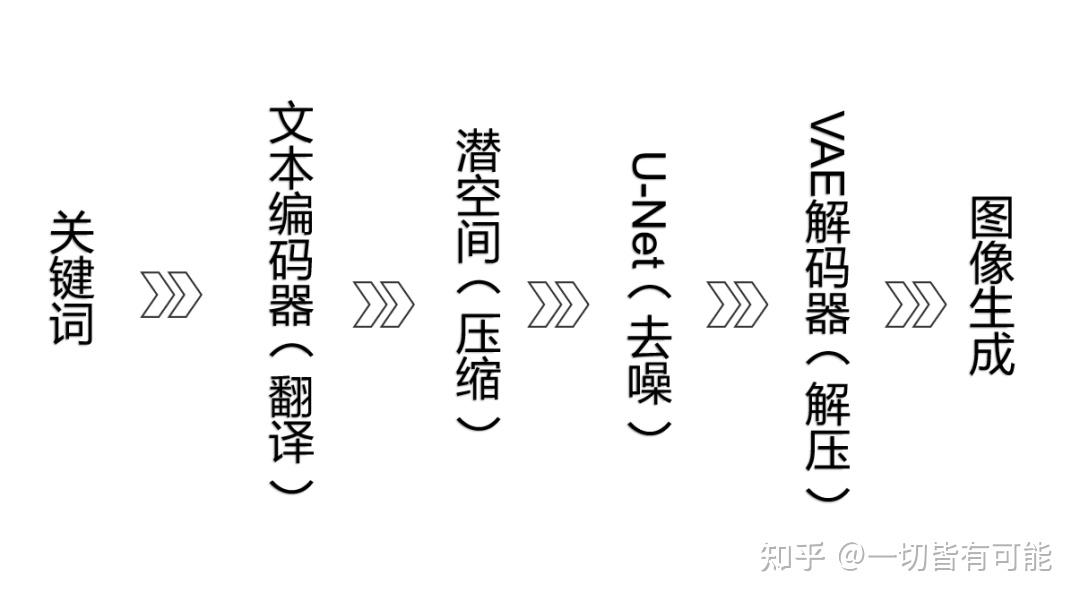
以上就是文生圖的大致工作流程,下圖為Comfy UI的工作流節點










)



)




