目錄
Linux線程概念
什么是線程
重新理解進程
線程的優點
線程的缺點
線程的異常
線程用途
Linux線程概念
什么是線程
- 在一個程序里的一個執行路線就叫做線程(thread)。更準確的定義是:線程是“一個進程內部的控制序列”。
- 一切進程至少都有一個執行線程。
- 線程在進程內部運行,本質是在進程地址空間內運行。
- 在Linux系統中,在CPU眼中,看到的PCB都要比傳統的進程更輕量化。
- 透過進程虛擬地址空間,可以看到進程的大部分資源,將進程資源合理分配給每個執行流,就形成了線程執行流。
根據前言知識,我們創建一個進程的時候,實際上伴隨著其進程控制塊(task_struct)、進程地址空間(mm_struct)以及頁表的創建,而虛擬地址與物理地址就是通過頁表映射的。
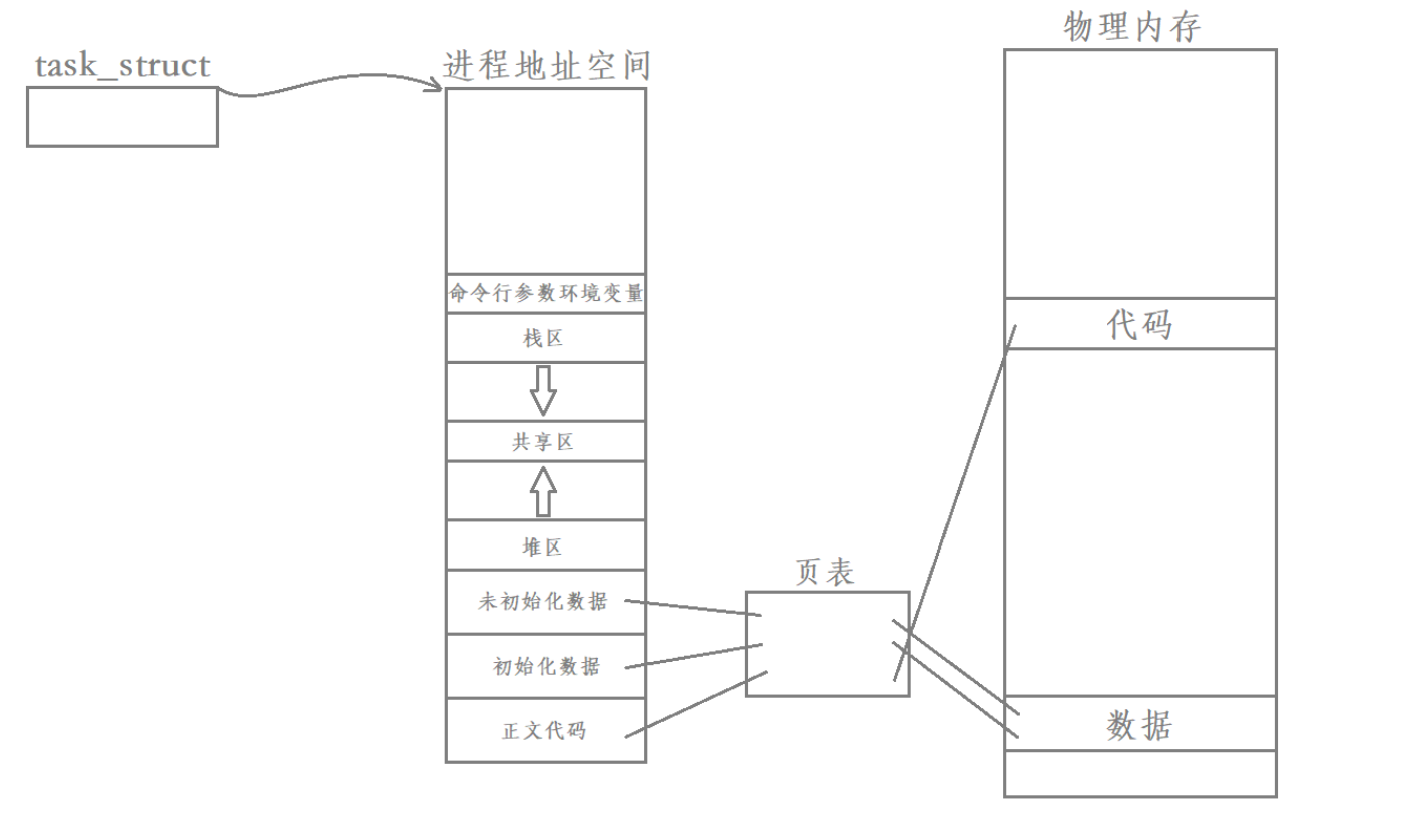
對于每一個進程的創建都會經過此過程,所以每個進程都是相互獨立的,互不干擾的。
對于前面線程的定義來說,一個程序中的一個執行路線就叫線程, 一切進程至少又一個執行線程。所以我們可以簡單的知道進程與線程的一個簡單的關系:線程是進程的一個執行分支。
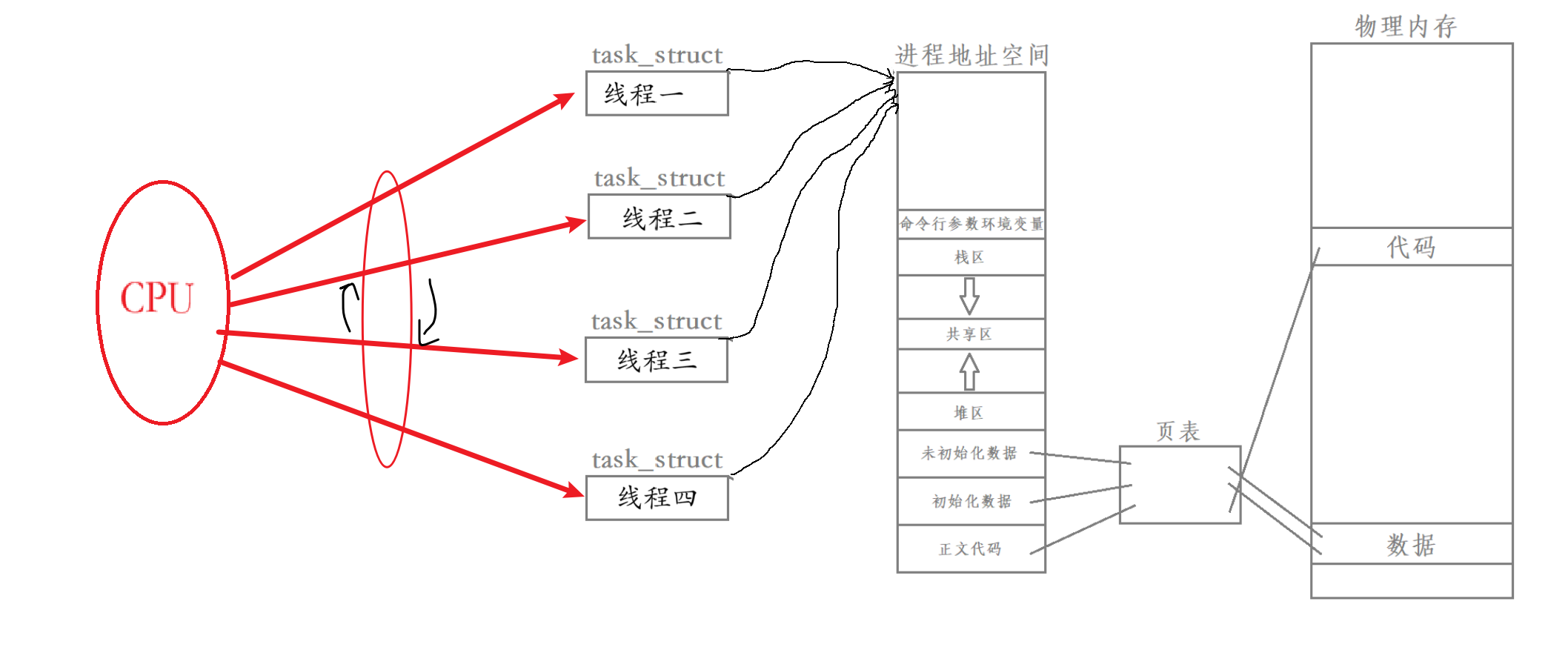
除此之外,線程是在進程內部運行的,本質在進程的地址空間上運行,并且進程的資源合理分配給每一個執行流。所以我們可以簡單畫出線程創建的結果:
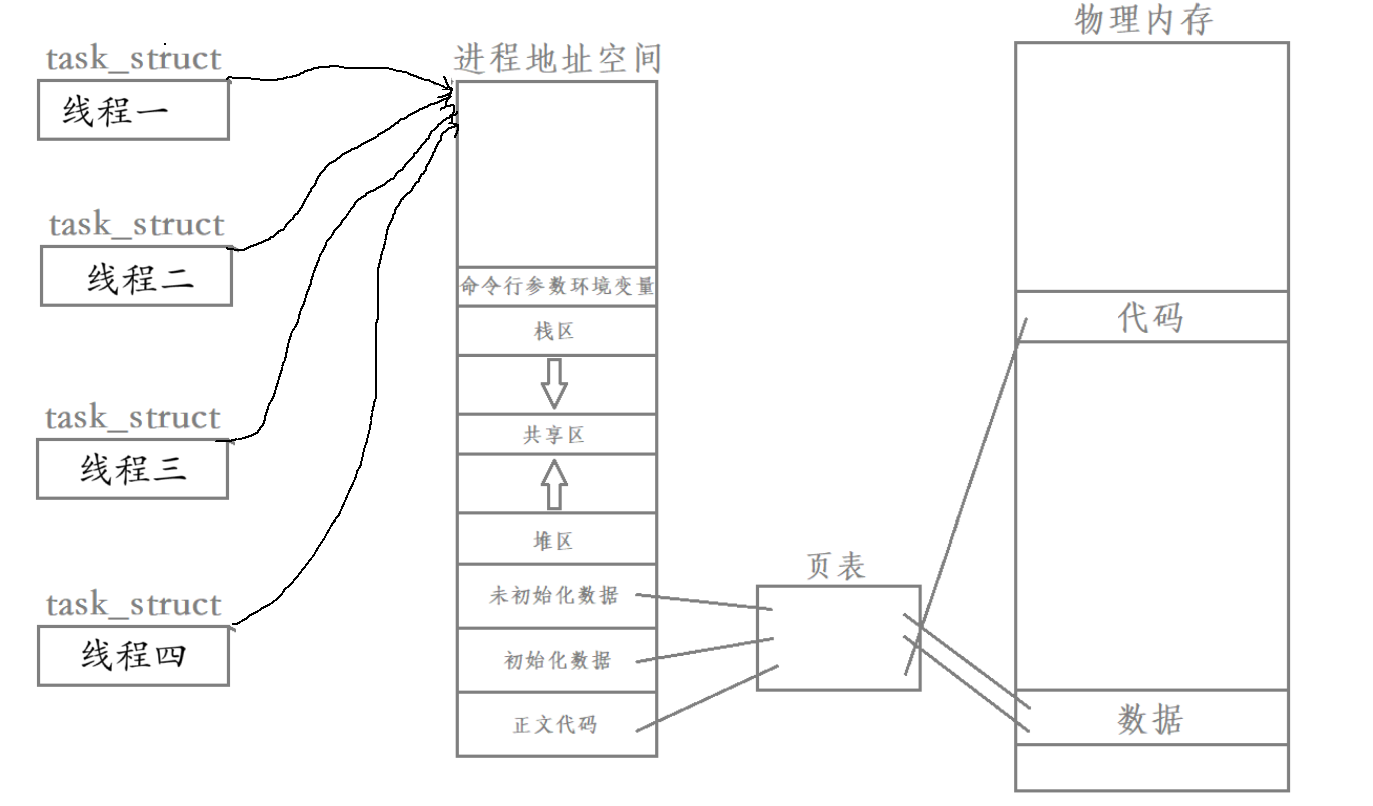
此時我們創建了四個線程。
- 其每一個線程都是進程的一個執行流,也就是我們說的執行分支。
- 其每一個線程都是在進程內部運行的,都是在進程地址空間內運行的。
- 并且,進程資源合理分配給每個執行流,幾乎都是被所有線程共享的。
所以簡單的來說,一個進程可以包含多個線程,這些線程共享進程的資源。
單純從技術角度,這個是一定能實現的,因為它比創建一個原始進程所做的工作更輕量化了。
?那么剛剛了解了線程,肯定會對以前對進程的了解有一定的困惑,那該如何重新理解之前的進程?
重新理解進程
如圖用紅色方框框起來的內容,我們將這個整體叫做進程。
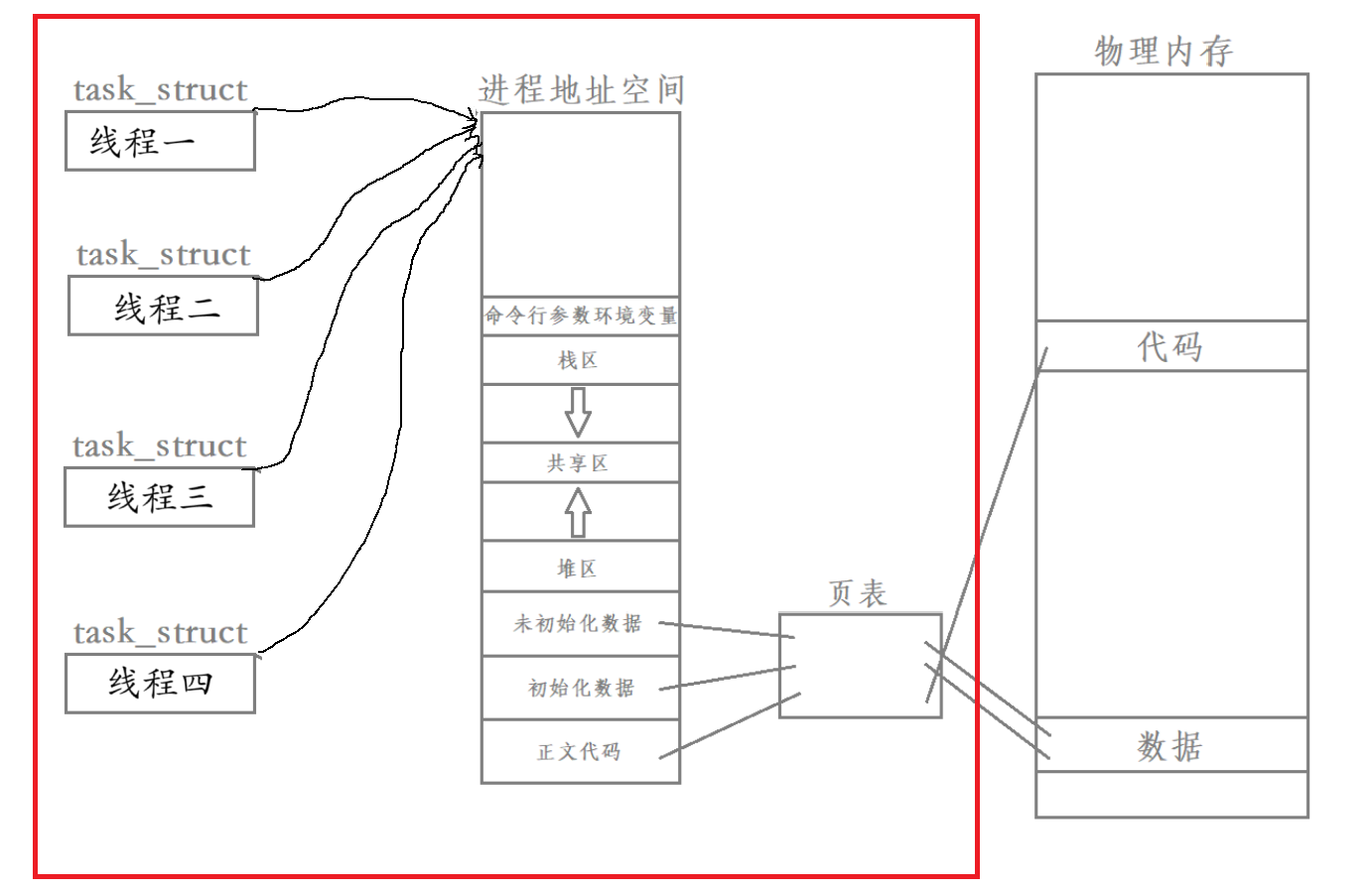
因此,對于進程的定義,進程 = 內核數據結構 + 程序的代碼和數據,此定義就不準確了。不能簡簡單單通過task_struct來衡量了。所以的定義應該是 進程 = 多個內核數據結構 + 程序的代碼和數據 + 所占的物理內存
現在我們應該站在內核角度來理解進程:承擔分配系統資源的基本實體,叫做進程。
換言之,當我們創建進程時是創建一個task_struct、創建地址空間、維護頁表,然后在物理內存當中開辟空間、構建映射,打開進程默認打開的相關文件、注冊信號對應的處理方案等等。
而我們之前接觸到的進程都只有一個task_struct,也就是該進程內部只有一個執行流,即單執行流進程,反之,內部有多個執行流的進程叫做多執行流進程。
在Linux中,站在CPU的角度,是什么樣呢?
根據前言對進程的學習,CPU是無法直接以進程為單位進行調度的,而是通過一個隊列,然后task_struct?通過內嵌的?sched_entity?間接參與隊列。
站在CPU的角度,能否識別當前調度的task_struct是進程還是線程?
答案是不能的,而且也不需要。因為CPU只關心一個一個的獨立執行流。無論進程內部只有一個執行流還是有多個執行流,對于CPU而言,只需要將執行流安排好,以他們為基本單位進行調度即可。
單執行流被調度
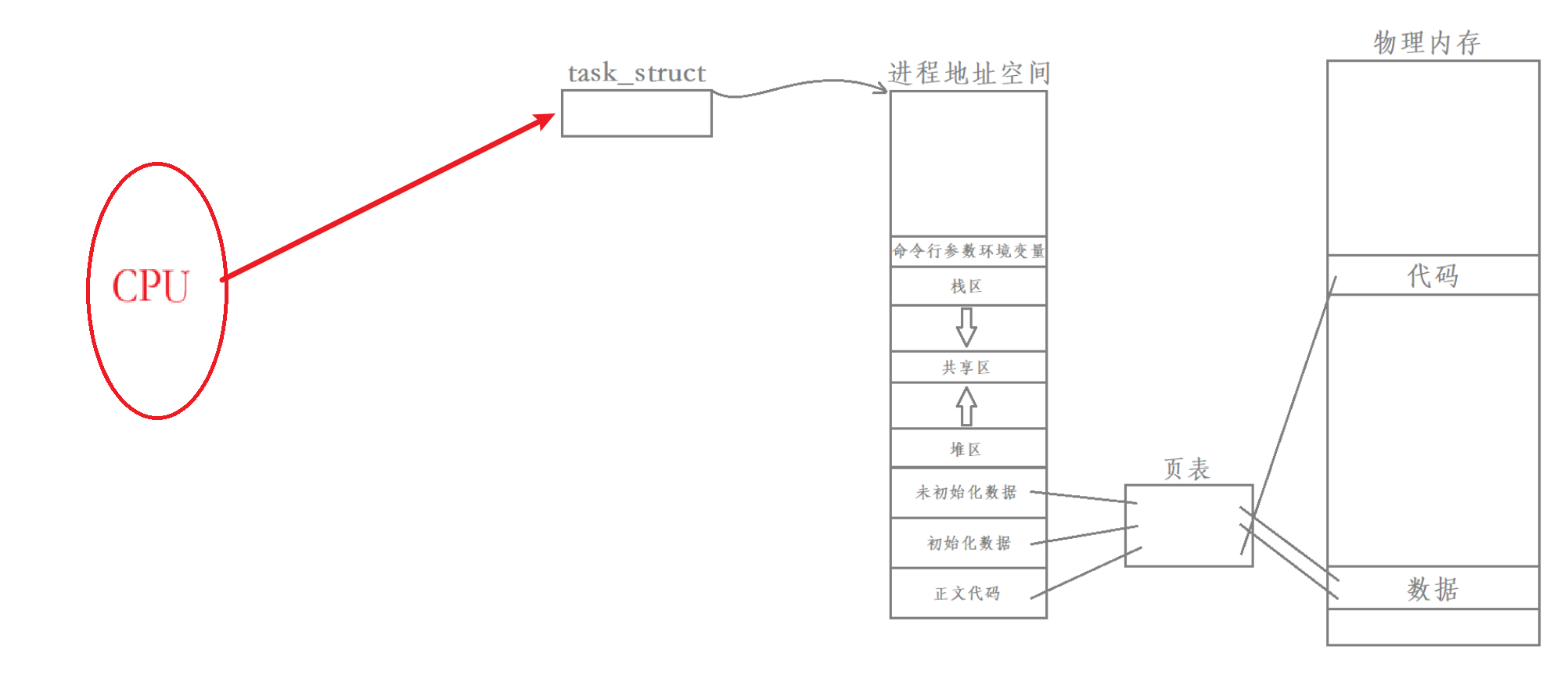
多執行流被調度
 ?所以在Linux系統中,對于CPU來說,雖然看到的是task_struct,但是比傳統的PCB要更加輕量化。
?所以在Linux系統中,對于CPU來說,雖然看到的是task_struct,但是比傳統的PCB要更加輕量化。
-
傳統PCB:在經典操作系統中,PCB是描述進程的核心數據結構,包含進程的所有信息(PID、狀態、內存映射、文件描述符、上下文等)。
-
Linux的
task_struct:雖然名字叫“任務結構體”,但它實際是線程的抽象(因為Linux不區分進程和線程,均用task_struct表示)。一個進程可能包含多個task_struct(多線程時),共享同一份資源(如內存空間)。
所以在Linux系統下,對CPU而言,線程<=執行流<=進程。
所以在Liunx系統下,線程是基本調度單位,線程也就是task_struct!!!但僅限Linux下。
Linux下并不存在真正的線程!而是用進程模擬的!
操作系統中存在大量的進程,一個進程內又存在一個或多個線程,因此線程的數量一定比進程的數量多,當線程的數量足夠多的時候,很明顯線程的執行粒度要比進程更細。
如果一款操作系統要支持真的線程,那么就需要對這些線程進行管理。比如說創建線程、終止線程、調度線程、切換線程、給線程分配資源、釋放資源以及回收資源等等,所有的這一套相比較進程都需要另起爐灶,搭建一套與進程平行的線程管理模塊。
因此,如果要支持真的線程一定會提高設計操作系統的復雜程度。在Linux看來,描述線程的控制塊和描述進程的控制塊是類似的,因此Linux并沒有重新為線程設計數據結構,而是直接復用了進程控制塊,所以我們說Linux中的所有執行流都叫做輕量級進程。
但也有支持真的線程的操作系統,比如Windows操作系統,因此Windows操作系統系統的實現邏輯一定比Linux操作系統的實現邏輯要復雜得多。
既然在Linux沒有真正意義的線程,那么也就絕對沒有真正意義上的線程相關的系統調用!
這很好理解,既然在Linux中都沒有真正意義上的線程了,那么自然也沒有真正意義上的線程相關的系統調用了。但是Linux可以提供創建輕量級進程的接口,也就是創建進程,共享空間,其中最典型的代表就是vfork函數。
vfork函數的功能就是創建子進程,但是父子共享空間,v函數fork的函數原型如下:
pid_t vfork(void);vfork函數的返回值與fork函數的返回值相同:
- 給父進程返回子進程的PID。
- 給子進程返回0。
只不過vfork函數創建出來的子進程與其父進程共享地址空間,例如在下面的代碼中,父進程使用vfork函數創建子進程,子進程將全局變量g_val由100改為了200,父進程休眠3秒后再讀取到全局變量g_val的值。
#include <iostream>
#include <stdlib.h>
#include <sys/types.h>
#include <unistd.h>using namespace std;int g_val = 100;int main()
{pid_t id = vfork();if (id == 0){//childg_val = 200;printf("child:PID:%d, PPID:%d, g_val:%d\n", getpid(), getppid(), g_val);exit(0);}// fathersleep(2);printf("father:PID:%d, PPID:%d, g_val:%d\n", getpid(), getppid(), g_val);return 0;
}父進程讀取到g_val的值是子進程修改后的值,也就證明了vfork創建的子進程與其父進程是共享地址空間的。
其實這樣暗示了fork創建的子進程并不屬于線程!!! fork創建的是完整的子進程,該子進程是父進程的完整副本。

線程的優點
- 創建一個新線程的代價要比創建一個新進程小得多
- 與進程之間的切換相比,線程之間的切換需要操作系統做的工作要少很多
- 線程占用的資源要比進程少很多
- 能充分利用多處理器的可并行數量
- 在等待慢速I/O操作結束的同時,程序可執行其他的計算任務
- 計算密集型應用,為了能在多處理器系統上運行,將計算分解到多個線程中實現
- I/O密集型應用,為了提高性能,將I/O操作重疊。線程可以同時等待不同的I/O操作。
線程的缺點
- 性能損失:一個很少被外部事件阻塞的計算密集型線程往往無法與共它線程共享同一個處理器。如果計算密集型線程的數量比可用的處理器多,那么可能會有較大的性能損失,這里的性能損失指的是增加了額外的同步和調度開銷,而可用的資源不變。
- 健壯性降低:編寫多線程需要更全面更深入的考慮,在一個多線程程序里,因時間分配上的細微偏差或者因共享了不該共享的變量而造成不良影響的可能性是很大的,換句話說線程之間是缺乏保護的。
- 缺乏訪問控制:進程是訪問控制的基本粒度,在一個線程中調用某些OS函數會對整個進程造成影響。
- 程難度提高:編寫與調試一個多線程程序比單線程程序困難得多
線程的異常
- 單個線程如果出現除零,野指針問題導致線程崩潰,進程也會隨著崩潰
- 線程是進程的執行分支,線程出異常,就類似進程出異常,進而觸發信號機制,終止進程,進程終止,該進程內的所有線程也就隨即退出
線程用途
- 合理的使用多線程,能提高CPU密集型程序的執行效率
- 合理的使用多線程,能提高IO密集型程序的用戶體驗(如生活中我們一邊寫代碼一邊下載開發工具,就是多線程運行的一種表現)
最用再用一張圖在總結一下
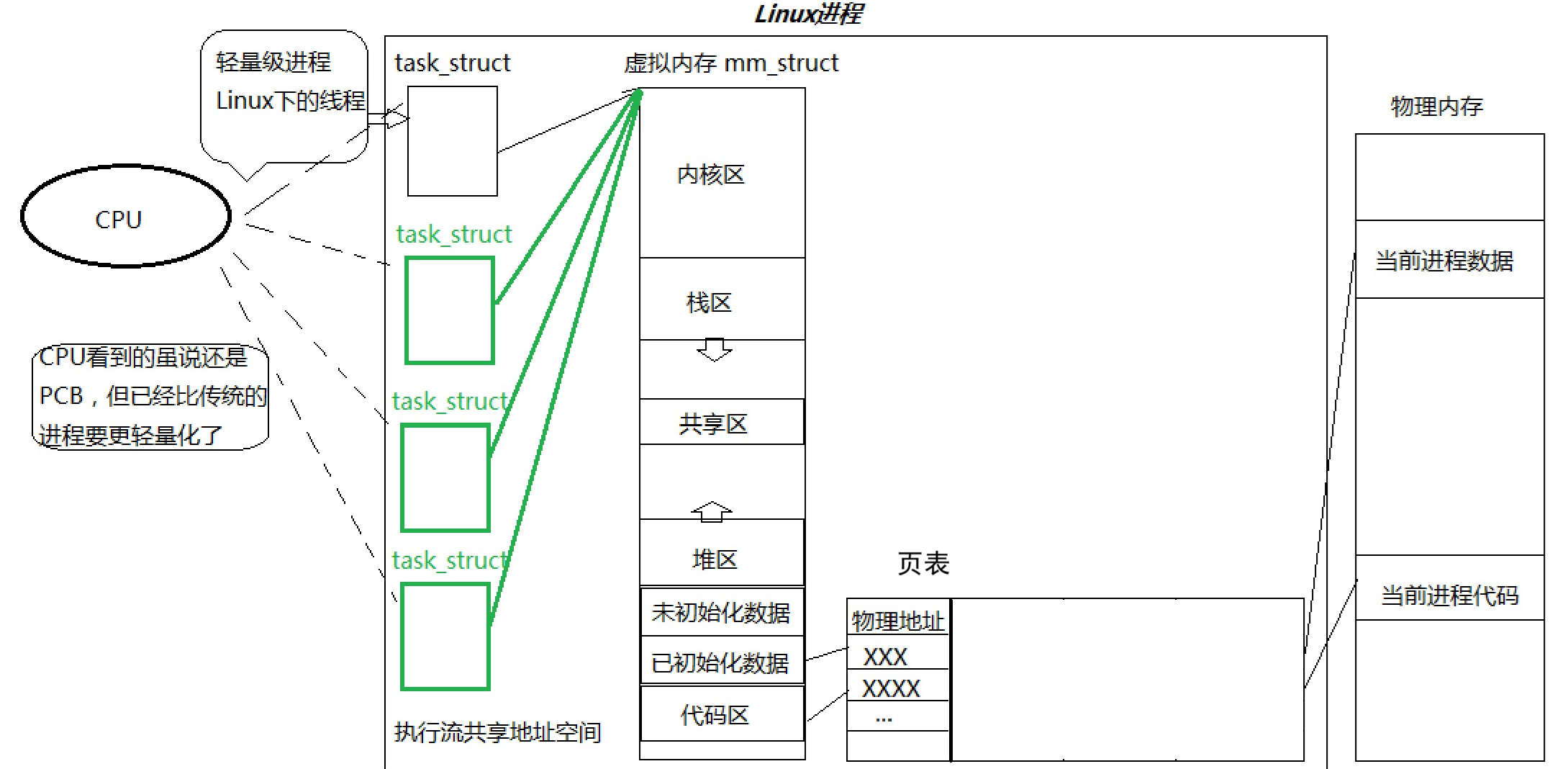
?這篇文章僅僅是對線程的一個簡單的入門,后面還會對線程進行更為詳細的講解與其應用場景!





)

)


)





)
最小棧)
)
 技術指南)