YOLOv4(You Only Look Once v4)于2020年由Alexey Bochkovskiy等人提出,是YOLO系列的重要里程碑。它在YOLOv3的基礎上整合了當時最先進的計算機視覺技術,實現了檢測速度與精度的顯著提升。以下從主干網絡、頸部網絡、頭部檢測、訓練策略、損失函數、正則化方法
一、主干網絡(Backbone):從Darknet53到CSPDarknet53
YOLOv3的瓶頸
- Darknet53:采用全卷積結構,包含53個卷積層,結合殘差連接(Residual Connection),在精度與速度間取得平衡,但計算量較大,且特征復用效率有待提升。
YOLOv4的改進
-
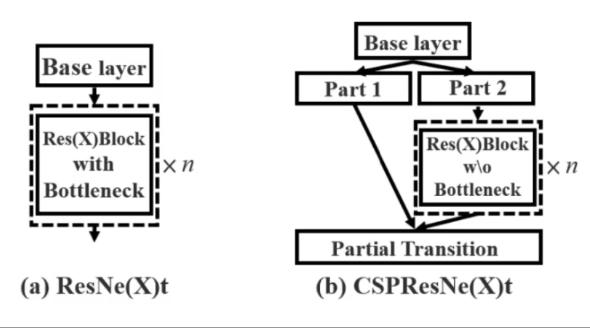
CSP結構引入(Cross Stage Partial Network)
- 核心思想:將主干網絡的每個階段(Stage)的特征圖分為兩部分,一部分直接傳遞(Partial Connection),另一部分進行常規卷積,最后拼接融合。
- 優勢:
- 減少計算量:通過跨階段特征融合,避免重復計算,提升計算效率。
- 增強梯度傳播:分離的梯度路徑使網絡更易訓練,緩解梯度消失。
- 輕量化設計:在YOLOv4中,CSPDarknet53相比Darknet53減少約15%的參數量,同時保持精度。
-
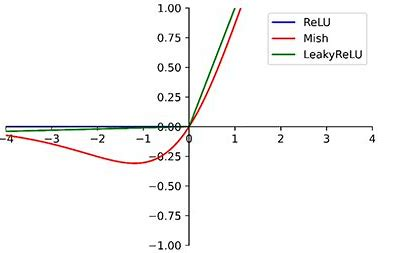
激活函數替換:Mish替代LeakyReLU
- Mish公式: Mish = x ? tanh ? ( ln ? ( 1 + e x ) ) \text{Mish} = x \cdot \tanh(\ln(1 + e^x)) Mish=x?tanh(ln(1+ex))
- 優勢:
- 光滑連續的非單調特性,保留負值信息,增強特征表達能力。
- 相比LeakyReLU,在深層網絡中精度更高,但計算量略有增加。
- 例外:YOLOv4-tiny仍使用LeakyReLU以降低計算成本。
-
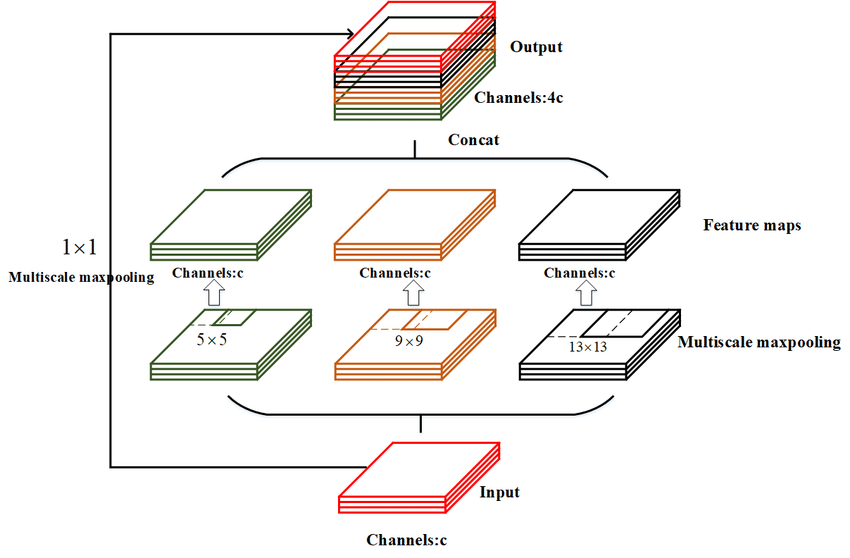
SPP模塊集成(Spatial Pyramid Pooling)
- 位置:在CSPDarknet53的末端加入SPP模塊(YOLOv3無此結構)。
- 作用:通過多尺度池化(如1×1, 5×5, 9×9, 13×13最大池化)擴大感受野,融合不同尺度特征,提升目標多尺度檢測能力。
- 效果:實驗表明,SPP模塊使YOLOv4的mAP提升2.7%~3.2%。
二、頸部網絡(Neck):從FPN到PAN+SPP
YOLOv3的瓶頸
- 單一FPN結構:僅通過自上而下路徑融合高層語義特征,底層細節特征(如小目標位置信息)傳遞不足。
YOLOv4的改進
- FPN+PAN結構(Path Aggregation Network)
- 雙向特征融合:
- 自上而下路徑(FPN):傳遞高層語義特征(如“汽車”“人”的類別信息)。
- 自下而上路徑(PAN):增強底層細節特征(如邊緣、紋理)的傳遞,尤其提升小目標檢測性能。
- 對比YOLOv3:YOLOv3僅使用FPN,而YOLOv4通過PAN補充底層特征流動,形成更強大的特征金字塔。
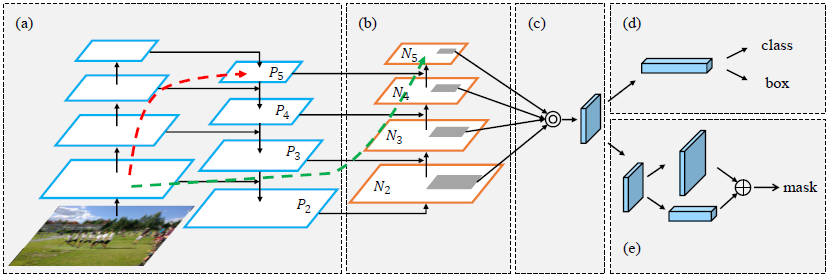
- 雙向特征融合:
YOLOv4中的PAN不是加法,是拼接
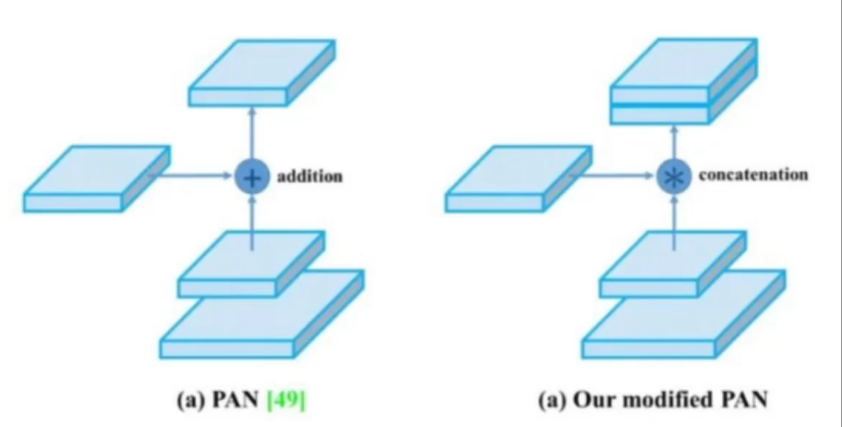
- SPP模塊的延續作用
- 在頸部網絡中,SPP模塊進一步擴大感受野,且計算成本低(僅在主干末端和頸部各用一次)。
三、頭部檢測(Head):多尺度檢測與激活函數優化
YOLOv3的設計
- 三尺度檢測:輸出13×13、26×26、52×52三種尺度特征圖,分別檢測大、中、小目標。
- 激活函數:分類頭使用Softmax(單標簽分類),回歸頭使用Sigmoid預測坐標偏移。
YOLOv4的改進
-
分類頭:Logistic激活替代Softmax
- 支持多標簽分類:YOLOv3的Softmax強制單標簽,而YOLOv4通過Logistic激活(獨立二分類)支持目標的多標簽預測(如“人”同時屬于“運動員”和“行人”)。
-
錨框優化
- 使用K-means聚類重新生成錨框,適配COCO數據集的目標尺寸分布,提升先驗框與真實框的匹配度。
-
檢測頭結構輕量化
- 通過減少卷積層數量或使用深度可分離卷積(如YOLOv4-tiny),降低計算量,適配移動端。
四、訓練策略:數據增強與自對抗訓練
YOLOv3的數據增強
- 基礎增強:隨機翻轉、裁剪、縮放、顏色抖動等。
YOLOv4的改進
-
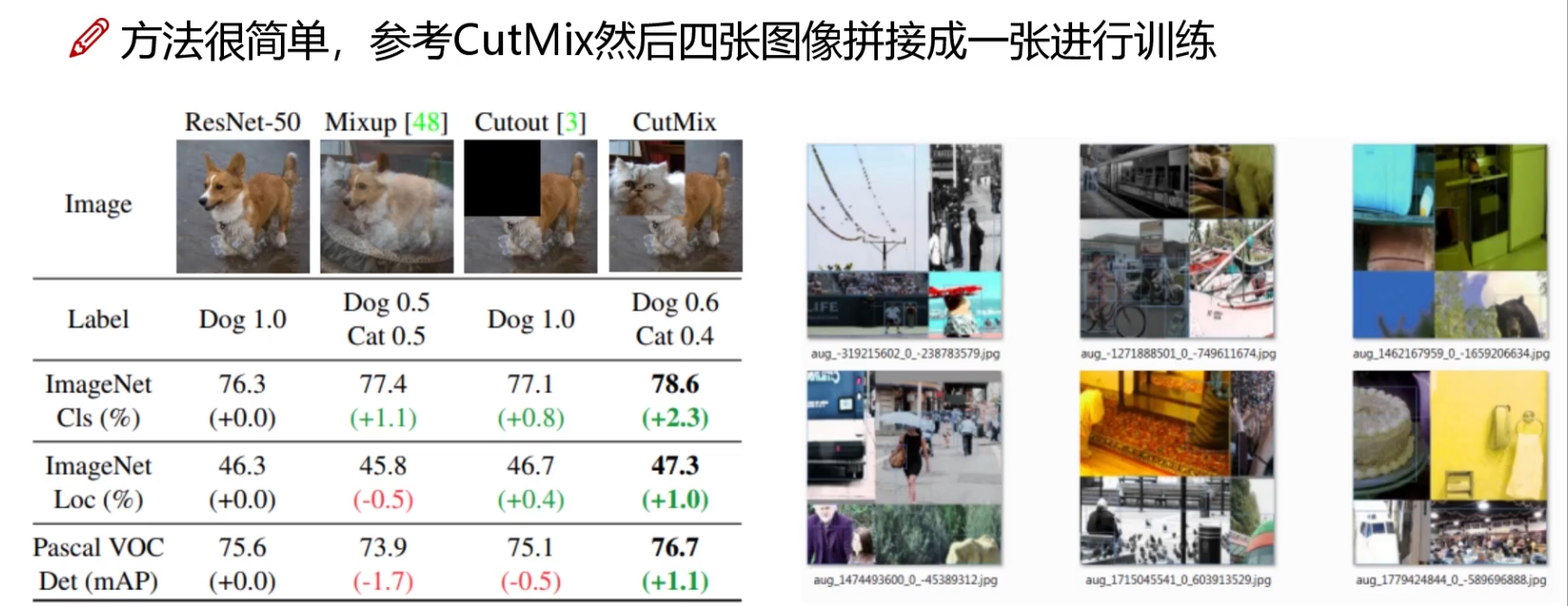
Mosaic數據增強
- 原理:將4張圖像隨機縮放、裁剪、拼接成1張新圖像,背景豐富且包含更多小目標。
- 優勢:
- 提升小目標檢測性能(小目標在拼接后可能成為中/大目標)。
- 減少對Batch Normalization的依賴(單張圖像包含4張圖的統計特征),可使用更小的Batch Size訓練。
-
MixUp增強
- 混合兩張圖像及其標簽,通過線性插值生成新樣本,提升模型泛化能力,抑制過擬合。
-
Random Erase:用隨機值或訓練集的平均像素值替換圖像中的區域
-
Hide and Seek:根據概率設置隨機隱藏一些補丁

-
自對抗訓練(Self-Adversarial Training, SAT)
- 兩階段流程:
- 階段1:模型反向更新輸入圖像(而非網絡參數),生成對抗樣本(使模型誤檢)。
- 階段2:用對抗樣本正常訓練模型,提升魯棒性。
- 對比傳統對抗訓練:無需外部攻擊算法,僅通過模型自身生成擾動,計算成本更低。
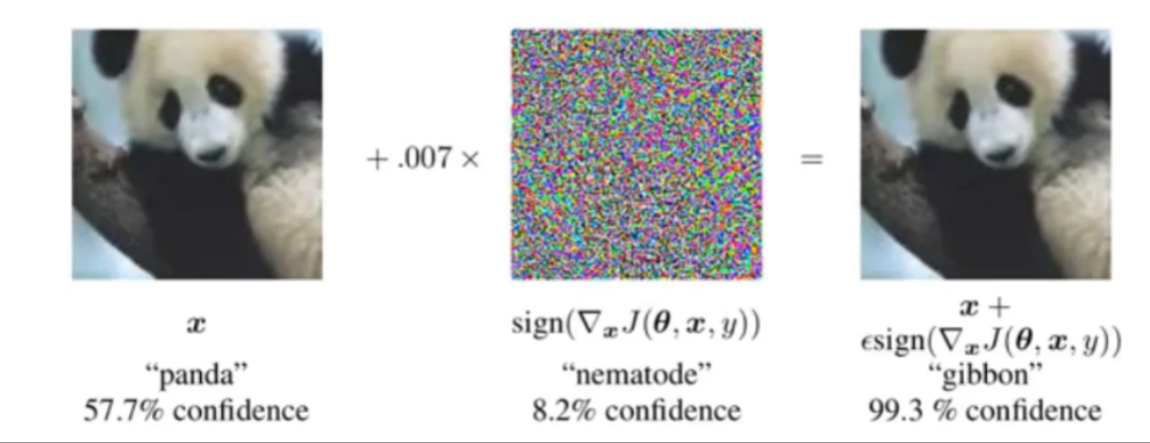
- 兩階段流程:
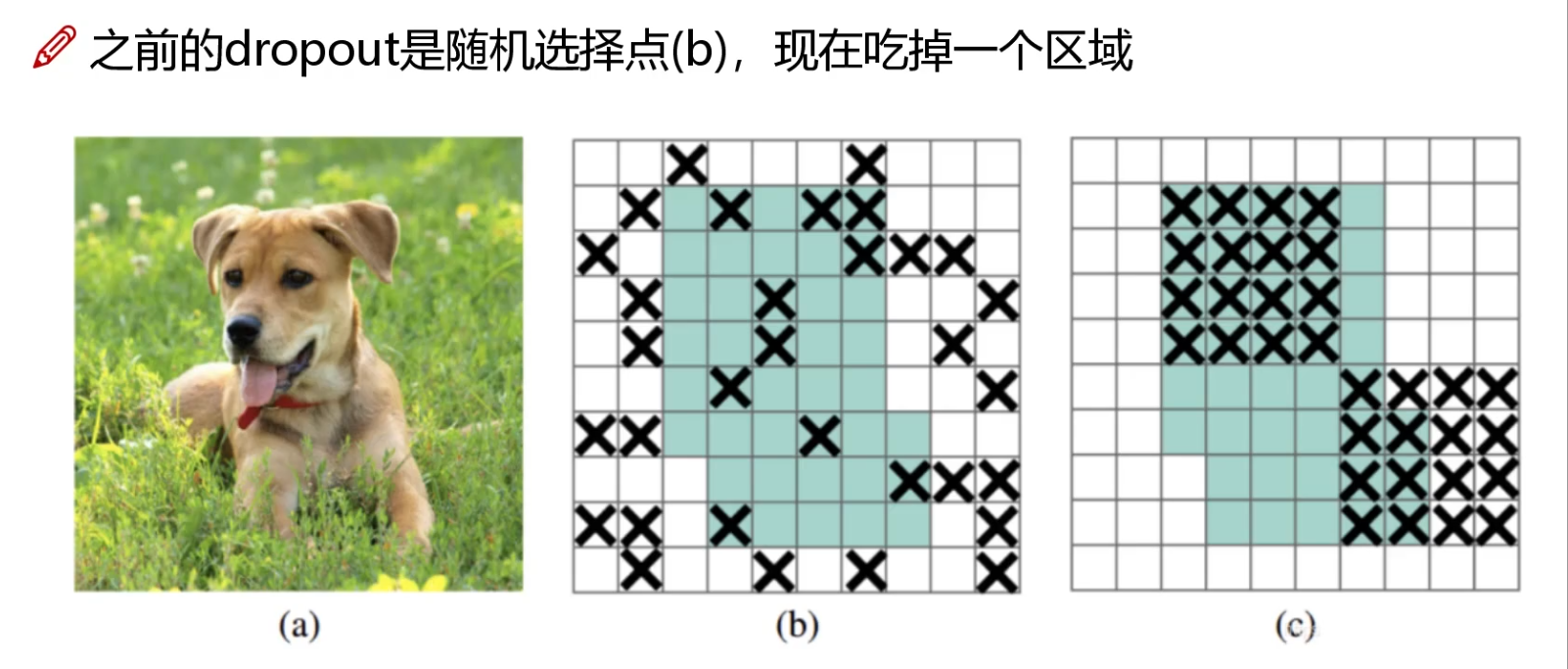
6.DropBlock
五、損失函數:從Smooth L1到CIoU Loss
YOLOv3的損失函數
- 坐標損失:Smooth L1損失,僅計算預測框與真實框的坐標偏移,未考慮框的重疊面積和形狀。
- 分類損失:交叉熵損失。
- 置信度損失:二元交叉熵損失,衡量預測框與真實框的重疊程度(IoU)。
存在的問題:沒有相交則IOU=0無法進行梯度計算,相同的IOU卻反應不出實際情況是怎么樣
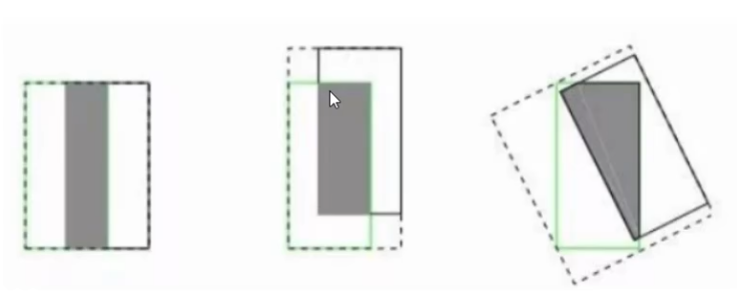
YOLOv4的改進
GIOU引入面積
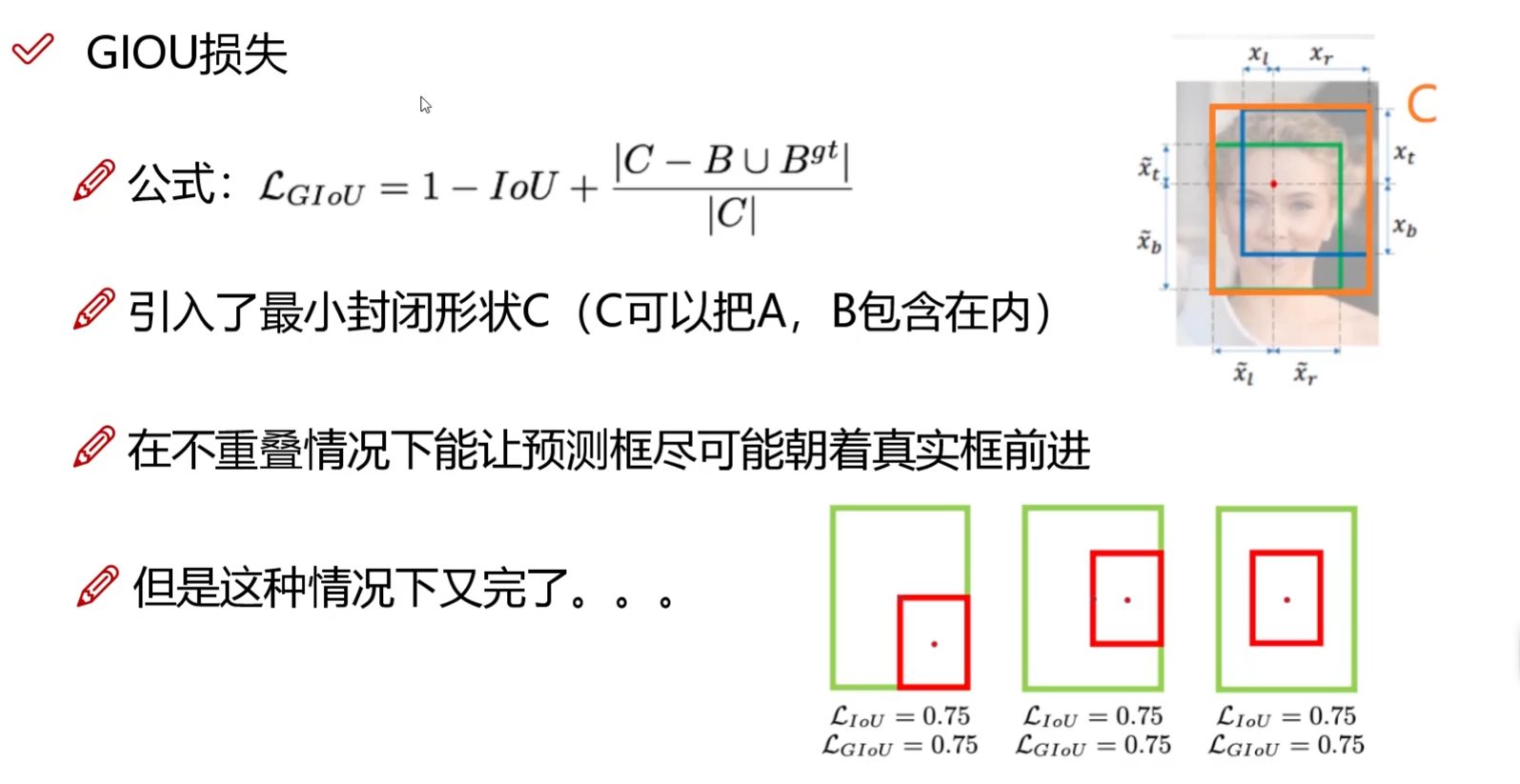
DIOU引入中心點距離
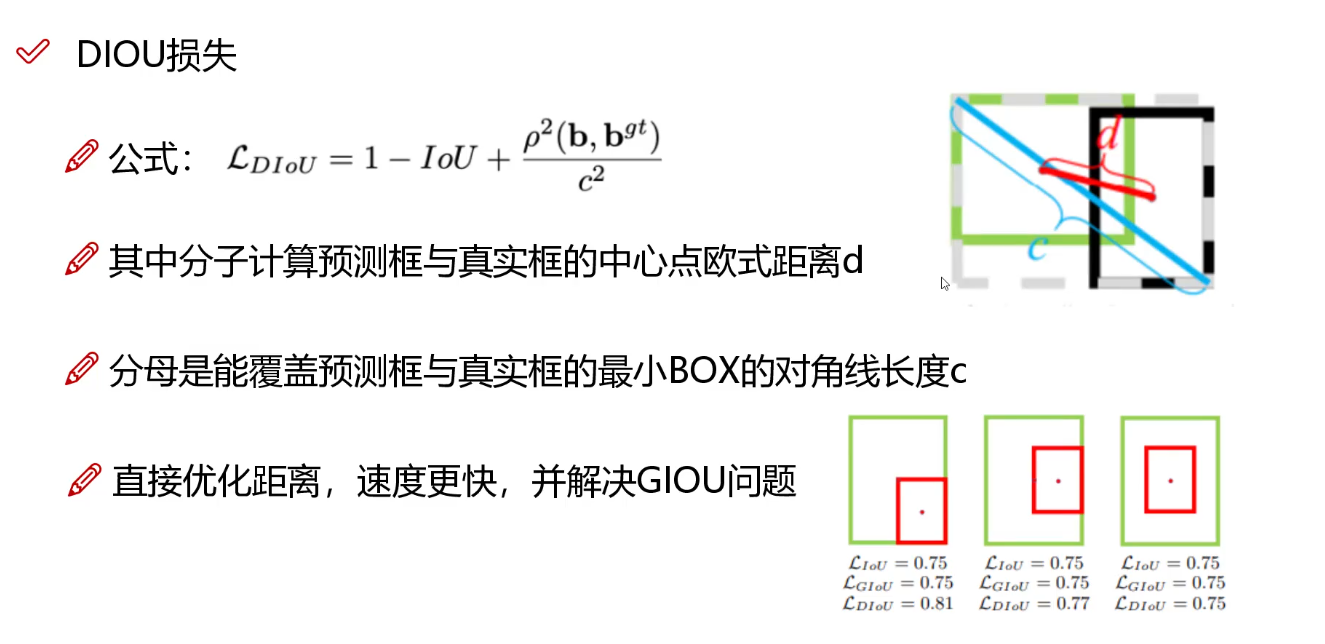
-
CIoU Loss替代Smooth L1
-
公式:
CIoU = 1 ? IoU + ρ 2 ( b , b g t ) c 2 + α v \text{CIoU} = 1 - \text{IoU} + \frac{\rho^2(b, b^{gt})}{c^2} + \alpha v CIoU=1?IoU+c2ρ2(b,bgt)?+αv
其中:- ρ 2 \rho^2 ρ2:預測框與真實框中心點的歐氏距離。
- c c c:包含兩框的最小外接矩形對角線長度。
- α \alpha α:權重參數,(v):衡量預測框與真實框的寬高比一致性。
-
優勢:
- 同時優化重疊面積(IoU)、中心點距離、寬高比,收斂更快,定位更精準。
- 解決傳統IoU/L1損失在無重疊時梯度消失的問題。
-
-
置信度損失結合CIoU
- 置信度不僅反映IoU,還融入CIoU的懲罰項,使模型更關注框的形狀和位置匹配。
六、正則化與優化技術
1. 跨卡批量歸一化(CmBN, Cross mini-Batch Normalization)
- 背景:YOLOv3使用普通BN,多卡訓練時各卡獨立計算統計量,可能導致模型不穩定。
- CmBN改進:在每個Batch內跨GPU收集統計量(而非全量數據),平衡訓練穩定性與計算效率,尤其適合小Batch Size場景。
2. 優化器與學習率策略
- 優化器:YOLOv4默認使用SGD(YOLOv3也常用SGD,但YOLOv4調參更精細)。
- 學習率調度:
- 余弦退火(Cosine Annealing):周期性衰減學習率,避免過早收斂到局部最優。
- Warmup策略:訓練初期緩慢提升學習率,防止模型在隨機初始化階段崩潰。
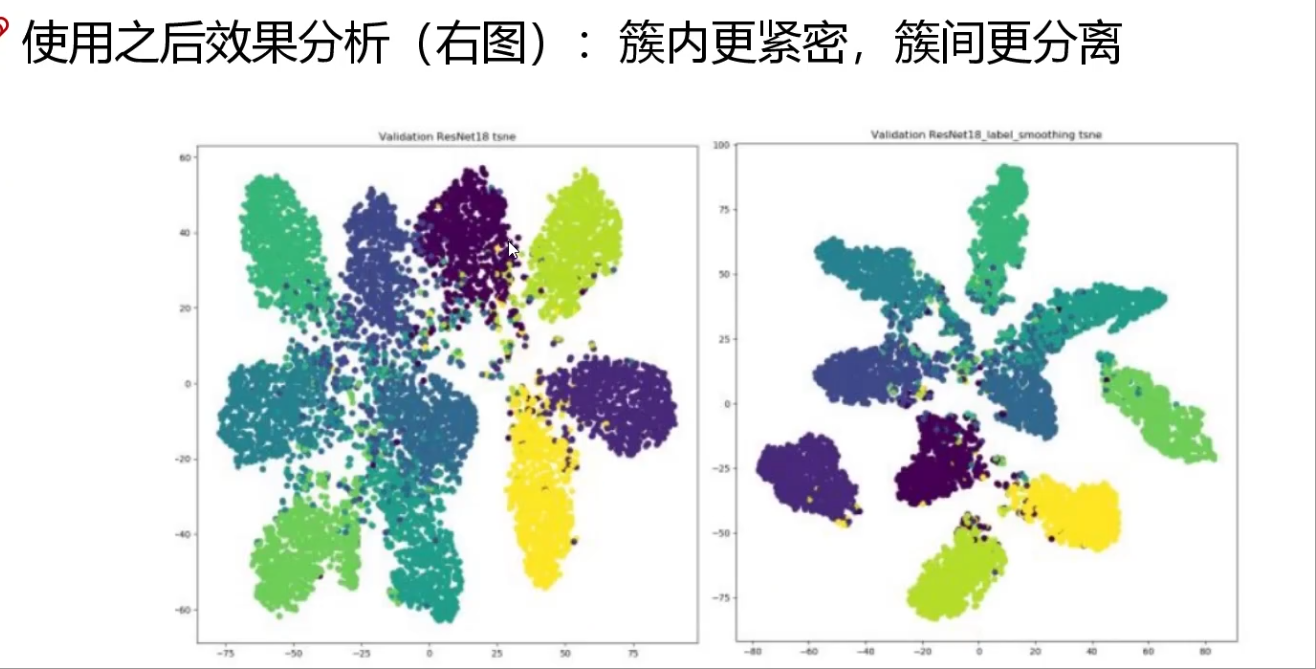
3. 標簽平滑(Label Smoothing)
- 對真實標簽添加微小噪聲(如將one-hot標簽從[0,1,0]改為[0.05,0.9,0.05]),抑制模型對標簽的過度自信,提升泛化能力。
非極大值抑制NMS改進
DIOU-NMS


七、SAM注意力機制模塊
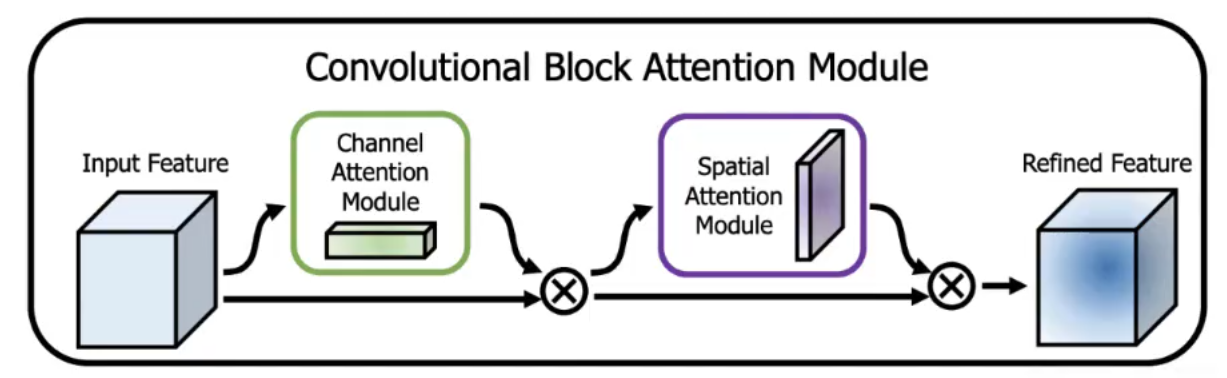
Convolutional Block Attention Module(CBAM)是一種輕量級卷積神經網絡注意力模塊。它通過通道注意力和空間注意力雙重機制優化特征表達:先對特征圖進行全局平均池化與最大池化,經全連接層生成通道注意力權重,聚焦重要特征通道;再對通道維度做平均與最大池化,通過卷積生成空間注意力權重,定位關鍵空間區域。兩者順序堆疊,為特征圖分配動態權重,增強有效信息、抑制冗余,可無縫嵌入各類CNN架構,在幾乎不增加計算量的前提下提升模型表征能力。CBAM注意力機制在NLP,CV等領域廣泛應用。
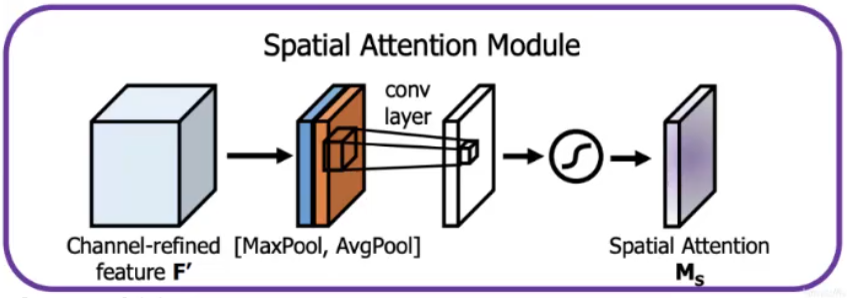
YOLOv4引入了SAM(Spatial Attention Module)
SAM(空間注意力模塊)是神經網絡中聚焦空間維度的注意力機制模塊。其輸入特征圖后,先在通道維度分別進行平均池化與最大池化,生成兩張空間特征圖;再將二者拼接,通過卷積操作輸出空間注意力權重圖,該權重圖與原特征圖相乘,可增強關鍵空間區域的特征響應,抑制無關位置信息。SAM能讓模型更關注“何處”是重要特征,常與通道注意力結合(如CBAM),輕量級且計算高效,適用于各類CNN架構以提升空間特征表征能力。

八、其他改進與性能對比
1. 測試階段優化
- 多尺度測試(Multi-Scale Testing, MST):輸入圖像縮放至不同尺寸進行推理,提升小目標檢測精度(犧牲速度)。
- 自適應錨框機制:根據輸入圖像尺寸動態調整錨框比例,適配不同分辨率。
2. 輕量化變體:YOLOv4-tiny
- 主干網絡:使用CSPDarknet53的輕量化版本,減少卷積層和通道數(如僅保留前13層)。
- 頸部網絡:移除SPP和PAN,僅用簡單FPN。
- 檢測頭:僅保留兩個尺度(13×13和26×26),適合移動端或嵌入式設備。
3. 性能對比(COCO數據集)
| 模型 | Backbone | mAP@0.5 | FPS (Tesla V100) |
|---|---|---|---|
| YOLOv3 | Darknet53 | 57.9 | 40 |
| YOLOv4 | CSPDarknet53 | 65.7 | 65 |
| YOLOv4-tiny | CSPDarknet53-tiny | 40.2 | 448 |
- 結論:YOLOv4相比YOLOv3,mAP提升約7.8%,FPS提升62.5%,實現“精度與速度雙突破”。
八、總結:YOLOv4的技術突破點
| 模塊 | YOLOv3 | YOLOv4 | 改進收益 |
|---|---|---|---|
| 主干網絡 | Darknet53 | CSPDarknet53 + SPP | 輕量化、更強特征表達 |
| 頸部網絡 | FPN | FPN + PAN | 底層細節與高層語義雙向融合 |
| 數據增強 | 基礎增強 | Mosaic + MixUp + SAT | 小目標檢測與魯棒性提升 |
| 損失函數 | Smooth L1 + BCE | CIoU Loss | 定位更精準,收斂更快 |
| 正則化 | 普通BN + Dropout | CmBN + 標簽平滑 | 訓練穩定性與泛化能力提升 |
| 激活函數 | LeakyReLU | Mish(主干) | 非線性表達增強 |
| 檢測頭 | Softmax(單標簽) | Logistic(多標簽) | 支持多標簽分類 |
九、常見誤區與注意事項
-
YOLOv4與YOLOv5的關系:
- YOLOv4是官方版本,由原團隊開發;YOLOv5由Ultralytics公司基于PyTorch重構,非官方但更易部署,兩者技術路線不同(如YOLOv5使用Focus結構和不同的CSP變體)。
-
Mish的適用場景:
- 算力充足時使用Mish可提升精度;嵌入式設備建議用LeakyReLU或Swish優化版。
-
錨框的必要性:
- YOLOv4仍依賴手工設計的錨框,而后續YOLOv5s/YOLOX嘗試無錨框(Anchor-Free)設計,需注意技術演進趨勢。
朝飲花上露,夜臥松下風。
云英化為水,光采與我同。 —王昌齡
)


)





)
最小棧)
)
 技術指南)
)
 貪心算法)




