哈嘍!我是我不是小upper~之前和大家聊過各類算法的優缺點,還有回歸算法的總結,今天咱們來深入聊聊正則化算法!這可是解決機器學習里 “過擬合” 難題的關鍵技術 —— 想象一下,模型就像個死記硬背的學生,把訓練題的答案全背下來了,但遇到新題目就傻眼,這就是過擬合。正則化就像給模型請了個 “家教”,教會它 “舉一反三”,而不是死記硬背~
為什么需要正則化?
當模型在訓練數據上表現得 “過于優秀”,甚至能記住所有噪音時,就會陷入過擬合。這時候,它在新數據上的表現會暴跌。正則化的核心思路很簡單:給模型的 “學習能力” 設個限制,通過在損失函數里加一個 “懲罰項”,讓模型參數不能隨心所欲地變大,從而降低復雜度,提升泛化能力。
先來簡單介紹一下7種正則化方法
1. L1 正則化(Lasso 回歸)
- 原理:在損失函數中加入模型參數的絕對值之和作為懲罰項(公式:
)。
- 效果:
- 強制讓部分參數變成 0,就像給特征做 “斷舍離”,自動篩選出重要特征(比如 100 個特征里,可能只剩 10 個非零參數)。
- 適合特征多但冗余大的場景,比如基因數據、文本分類,能直接簡化模型結構。
- 缺點:參數更新時可能不夠平滑,極端情況下容易漏掉一些相關特征。
2. L2 正則化(Ridge 回歸)
- 原理:懲罰項是參數的平方和(公式:
)。
- 效果:
- 讓所有參數都趨近于 0,但不會完全為 0,就像給參數 “瘦身”,避免某個特征 “一家獨大”。
- 對異常值更魯棒,比如房價預測中,個別極端高價樣本不會讓模型過度傾斜。
- 應用:線性回歸、神經網絡中最常用的 “標配” 正則化,簡單有效。
3. 彈性網絡正則化(Elastic Net)
- 原理:L1 和 L2 的 “混血兒”,懲罰項是兩者的加權和(公式:
)。
- 效果:
- 結合了 L1 的特征選擇能力和 L2 的穩定性,比如當多個特征高度相關時(如股票價格的不同指標),L1 可能隨機選一個,而彈性網絡會保留多個。
- 適合特征間有復雜關聯的數據集,比如金融數據、生物醫學數據。
4. Dropout 正則化(神經網絡專屬)
- 原理:在訓練過程中,隨機 “丟棄” 一部分神經元(讓其輸出為 0),就像讓模型 “閉目養神”,每次只用部分神經元學習。
- 效果:
- 迫使模型不能依賴任何一個神經元,增強泛化能力,就像學生用不同的知識點組合解題,而不是死記某一種思路。
- 計算成本低,不需要修改損失函數,在 CNN、Transformer 等網絡中廣泛使用。
- 注意:測試時所有神經元都正常工作,但會按比例縮放輸出,保證結果無偏。
5. 貝葉斯 Ridge 和 Lasso 回歸
- 原理:從貝葉斯視角看,正則化等價于給參數添加先驗分布。
- 貝葉斯 Ridge:假設參數服從高斯分布(對應 L2 正則化),認為參數值越小越合理。
- 貝葉斯 Lasso:假設參數服從拉普拉斯分布(對應 L1 正則化),更容易產生稀疏解。
- 效果:不僅能正則化,還能給出參數的不確定性估計(比如 “這個特征的影響有 95% 的概率在 0.1-0.3 之間”),適合需要概率輸出的場景(如醫療診斷)。
6. 早停法(Early Stopping)
- 原理:訓練時監控驗證集誤差,當誤差不再下降時提前終止訓練,避免模型在訓練集上 “鉆牛角尖”。
- 效果:
- 簡單粗暴的 “止損” 策略,不需要修改模型結構,計算成本低。
- 尤其適合深度學習,比如訓練神經網絡時,防止過擬合的同時節省算力。
- 注意:需要預留驗證集,且終止時機需要調參(比如連續 10 輪誤差上升就停)。
7. 數據增強(Data Augmentation)
- 原理:通過人工擴展訓練數據(如圖像旋轉、文本同義詞替換),讓模型接觸更多 “新樣本”,被迫學習更通用的特征。
- 效果:
- 從源頭解決數據不足的問題,比如圖像分類中,翻轉、裁剪圖片能讓模型學會 “不變性”(貓不管怎么轉都是貓)。
- 對小數據集效果顯著,比如用 1 萬張照片通過增強變成 10 萬張,提升模型魯棒性。
- 應用:CV(計算機視覺)、NLP(自然語言處理)領域的 “必選技能”,如 ResNet 用數據增強提升 ImageNet 準確率。
咱今天要探究的是這7各部分,大家請看:
-
L1 正則化
-
L2 正則化
-
彈性網絡正則化
-
Dropout 正則化
-
貝葉斯Ridge和Lasso回歸
-
早停法
-
數據增強
1、L1 正則化(Lasso 正則化)
L1 正則化(又稱 Lasso 正則化)是機器學習中控制模型復雜度、防止過擬合的重要技術。它的核心思想是在模型原有的損失函數中加入一個懲罰項,通過約束模型參數的大小,迫使模型優先選擇簡單的參數組合,從而提升模型在新數據上的泛化能力。
核心原理與公式
L1 正則化通過向損失函數中添加L1 范數項(即模型參數的絕對值之和)來實現約束。以線性回歸為例,其完整的損失函數表達式為:

-
各符號含義:
- (
:第?i?個樣本的真實值;
:模型對第?i?個樣本的預測值(
);
:第?j?個特征的權重(參數);
:正則化超參數,用于控制懲罰項的強度(
- m:特征數量。
- (
-
關鍵作用:
- 稀疏性誘導:L1 正則化項中的絕對值運算會使部分參數?\(w_j\)?被強制壓縮至 0,從而實現特征選擇—— 自動剔除無關或冗余的特征,僅保留對目標最具影響的特征。
- 模型簡化:參數稀疏化意味著模型僅依賴少數關鍵特征,復雜度降低,過擬合風險隨之減小。
優化特性與求解方法
-
非光滑性帶來的挑戰: 由于 L1 正則化項包含絕對值(如?
),損失函數在?
?處不可導,傳統的梯度下降法無法直接使用。因此,L1 正則化模型通常采用以下優化方法:
- 坐標下降法:逐維更新參數,每次固定其他維度,僅優化當前維度的參數,直至收斂。
- 近端梯度下降法:在梯度下降過程中引入近端算子,處理非光滑的正則化項。
-
稀疏性的幾何解釋: 在二維參數空間中(假設模型僅有兩個特征?
?和?
),L1 正則化項的約束形狀為菱形。當損失函數的等高線與菱形邊界相切時,切點往往出現在坐標軸上(即?
?或?
),從而迫使其中一個參數為 0,實現稀疏性。
Python 實現與案例解析
以下通過 Python 代碼演示 L1 正則化在簡單線性回歸中的應用,并結合可視化分析其效果。
代碼步驟解析
import numpy as np
import matplotlib.pyplot as plt
from sklearn.linear_model import Lasso# 1. 生成示例數據
np.random.seed(42) # 固定隨機種子,確保結果可復現
X = np.linspace(-5, 5, num=100).reshape(-1, 1) # 生成100個一維特征數據
y = 2 * X + np.random.normal(0, 1, size=(100, 1)) # 真實模型為y=2X+噪聲# 2. 創建Lasso模型并訓練
lasso = Lasso(alpha=0.1) # alpha對應正則化強度λ,值越大,參數越易稀疏化
lasso.fit(X, y) # 擬合數據# 3. 可視化擬合結果與正則化效應
fig, ax = plt.subplots(figsize=(8, 5))# 繪制原始數據與擬合線
ax.scatter(X, y, color="blue", label="原始數據點")
ax.plot(X, lasso.predict(X), color="red", linewidth=2, label="L1正則化擬合線")# 繪制L1正則化項的等高線圖(展示參數約束效果)
beta_0 = np.linspace(-10, 10, 100) # 假設截距β0的取值范圍
beta_1 = np.linspace(-10, 10, 100) # 假設權重β1的取值范圍
B0, B1 = np.meshgrid(beta_0, beta_1) # 生成網格點
Z = np.zeros_like(B0)# 計算每個網格點對應的L1正則化項值(|β0| + |β1|)
for i in range(len(beta_0)):for j in range(len(beta_1)):Z[i, j] = np.abs(B0[i, j]) + np.abs(B1[i, j]) # L1范數=絕對值之和# 繪制等高線(代表正則化項的大小,層級越多,懲罰越嚴格)
ax.contour(B0, B1, Z, levels=20, colors="black", alpha=0.5, linestyles='dashed')# 添加坐標軸標簽與標題
ax.set_xlabel("截距 β0", fontsize=12)
ax.set_ylabel("權重 β1", fontsize=12)
ax.set_title("L1正則化的等高線約束與擬合效果", fontsize=14)
ax.legend()
plt.show()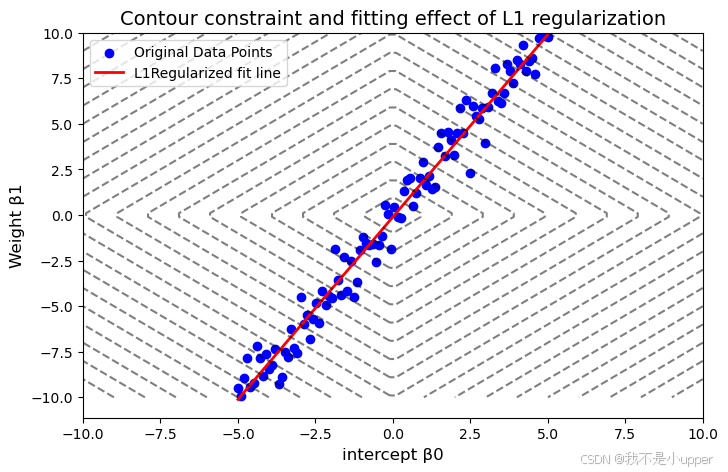
上述可視化結果解讀
-
數據與擬合線: 藍色散點為帶噪聲的原始數據,紅色直線為 L1 正則化后的擬合結果。由于 L1 正則化的約束,模型參數被簡化,擬合線不會過度貼近噪聲點,體現出抗過擬合能力。
-
等高線圖的意義:
- 黑色虛線為 L1 正則化項的等高線,每一條線上的點對應相同的正則化項值(如最內層菱形對應?
,外層對應更大的值)。
- 損失函數的等高線(未顯式繪制)與菱形等高線的切點即為最優參數解。從圖中可見,切點可能位于坐標軸上(如?β0=0)?或?β1=0),直觀展示了 L1 正則化如何通過幾何約束迫使參數稀疏化。
- 黑色虛線為 L1 正則化項的等高線,每一條線上的點對應相同的正則化項值(如最內層菱形對應?
適用場景與注意事項
-
適用場景:
- 特征數量遠大于樣本量(如基因表達數據、文本數據),需通過稀疏性篩選關鍵特征。
- 模型需要具備可解釋性(僅保留少數非零參數,便于理解特征重要性)。
-
調參建議:
- 通過交叉驗證(Cross-Validation)選擇最優?
- 若特征間存在強相關性,L1 正則化可能隨機選擇其中一個特征,此時可考慮彈性網絡(Elastic Net)等結合 L1/L2 的正則化方法。
- 通過交叉驗證(Cross-Validation)選擇最優?
通過 L1 正則化,模型在擬合能力與復雜度之間取得平衡,尤其在特征選擇和模型解釋性方面表現突出,是機器學習中處理高維數據的重要工具。
2、L2 正則化(嶺正則化)
L2 正則化,也被稱為嶺正則化,是機器學習中控制模型復雜度、防止過擬合的重要技術。它的核心思想是通過向模型的損失函數中添加L2 范數項(即模型參數的平方和),迫使模型的權重參數盡可能縮小,從而讓模型的預測結果更加平滑、泛化能力更強。
核心原理與公式
假設我們的基礎損失函數是均方誤差(MSE),用于衡量模型預測值與真實值的差異。引入 L2 正則化后,完整的損失函數表達式為:
- 第一部分:
?是均方誤差損失,衡量模型對訓練數據的擬合程度(n為樣本數,
- 第二部分:
?是 L2 正則化項,由所有特征權重的平方和乘以正則化強度參數?
關鍵作用:
- 通過懲罰較大的權重,L2 正則化迫使模型避免過度依賴任何單一特征,從而降低過擬合風險。
優化過程的兩大特點
-
可導性與優化算法兼容性 由于正則化項包含平方運算(
),整個損失函數是連續可導的。這意味著我們可以使用常見的梯度下降、牛頓法等優化算法求解損失函數的最小值。以梯度下降為例,權重的更新公式為:? ? ? ? ? ? ? ?
? ? ? ? ? ? ? ? ? ? ? ? ? ? ? 其中?
?是學習率,
?是第i個樣本的第j個特征值。可以看到,正則化項的梯度為?
,會促使權重?
-
權重收縮與模型平滑 L2 正則化不會讓權重完全變為 0(這是與 L1 正則化的重要區別),但會將所有權重調整到較小的數值,使模型對輸入特征的變化不敏感,從而產生更平滑的預測結果。例如,在多項式回歸中,高次項的權重會被顯著縮小,避免模型擬合訓練數據中的噪聲。
案例:用 Python 實現 L2 正則化
下面通過一個簡單的線性回歸案例,演示 L2 正則化的效果,并通過等高線圖直觀展示正則化項對權重的約束。
代碼解析:
import numpy as np
import matplotlib.pyplot as plt
from sklearn.linear_model import Ridge# 生成示例數據(線性關系+隨機噪聲)
np.random.seed(42) # 固定隨機種子,確保結果可復現
X = np.linspace(-5, 5, num=100).reshape(-1, 1) # 生成100個樣本,特征X為一維數據
y = 2 * X + np.random.normal(0, 1, size=(100, 1)) # 真實模型為y=2X+噪聲# 創建Ridge模型(L2正則化)
ridge = Ridge(alpha=0.1) # alpha對應公式中的λ,控制正則化強度
ridge.fit(X, y) # 擬合數據# 繪制數據點與擬合線
fig, ax = plt.subplots()
ax.scatter(X, y, color="blue", label="Data") # 原始數據點
ax.plot(X, ridge.predict(X), color="red", linewidth=2, label="L2 Regularization") # 擬合曲線
ax.set_xlabel("X")
ax.set_ylabel("y")
ax.set_title("L2正則化擬合結果")
ax.legend()# 繪制L2正則化項的等高線圖(展示權重空間的懲罰效果)
beta_0 = np.linspace(-10, 10, 100) # 假設截距β0的取值范圍
beta_1 = np.linspace(-10, 10, 100) # 權重β1的取值范圍
B0, B1 = np.meshgrid(beta_0, beta_1) # 生成網格點
Z = np.zeros_like(B0)# 計算每個網格點對應的L2正則化項值(β02 + β12)
for i in range(len(beta_0)):for j in range(len(beta_1)):Z[i, j] = beta_0[i]**2 + beta_1[j]**2 # 假設截距β0也參與正則化(實際Ridge默認對權重β1正則化)# 繪制等高線(越內層的等高線,正則化項值越小,權重越接近0)
ax.contour(B0, B1, Z, levels=20, colors="black", alpha=0.5)
ax.set_title("L2正則化項等高線圖")
plt.show()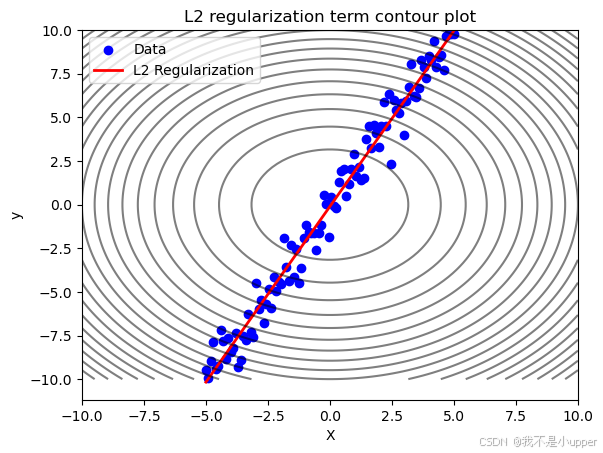
結果解讀:
- 擬合曲線:紅色曲線是經過 L2 正則化的線性模型,較好地捕捉了數據的整體趨勢(接近真實模型
),避免了過擬合噪聲。
- 等高線圖:黑色等高線表示正則化項
的值,中心(權重接近 0)的值最小。模型在優化時,需要同時最小化原始損失和正則化項,因此權重會被 “拉向” 等高線的中心區域,即趨向較小的值。
L2 正則化通過懲罰權重的平方和,迫使模型參數保持較小值,從而降低復雜度、提升泛化能力。它適用于大多數線性模型(如線性回歸、邏輯回歸)和神經網絡,是機器學習中最常用的正則化方法之一。實際應用中,可通過交叉驗證調整的取值,平衡模型的偏差與方差。
3、彈性網絡正則化(Elastic Net 正則化)
彈性網絡正則化是一種專門為線性回歸模型設計的正則化方法,它巧妙地融合了 L1 正則化和 L2 正則化的核心優勢,就像是把兩種 “武器” 的特點合二為一,讓模型在處理復雜數據時更加靈活高效。
核心思想與應用場景
在實際數據中,經常會遇到兩種棘手的問題:
- 特征數量龐大:比如基因測序數據可能包含上萬個特征,但其中很多特征與目標無關,需要篩選出真正重要的特征(類似 L1 正則化的 “特征選擇” 能力)。
- 特征間多重共線性:例如房價預測中,“房屋面積” 和 “房間數量” 可能高度相關,此時 L1 正則化可能會隨機剔除其中一個特征,而保留另一個,但實際上兩者可能都對房價有影響(L2 正則化更擅長處理這種相關性)。
彈性網絡正則化正是為解決這類問題而生。它通過同時引入 L1 范數(絕對值之和)和 L2 范數(平方和)作為正則化項,既能像 L1 一樣篩選特征(讓部分系數變為 0),又能像 L2 一樣保持系數的平滑性(避免極端值),尤其適合處理高維數據和特征間存在強相關性的場景。
損失函數與公式解析
彈性網絡正則化的損失函數公式為:\(\text{Loss} = \frac{1}{n} \sum_{i=1}^{n} (y_i - \hat{y}_i)^2 + \alpha \left( \rho \sum_{j=1}^{m} |w_j| + (1-\rho) \sum_{j=1}^{m} w_j^2 \right)\)
- 各部分含義:
- 第一部分是均方誤差(MSE),衡量模型預測值?\(\hat{y}_i\)?與真實值?\(y_i\)?的差異。
- 第二部分是正則化項,由兩部分組成:
- \(\rho \sum|w_j|\):L1 范數項(\(\rho\)?是 L1 范數的比例參數)。
- \((1-\rho) \sum w_j^2\):L2 范數項。
- \(\alpha\):正則化強度參數,控制對模型復雜度的懲罰力度(\(\alpha\)?越大,模型越簡單)。
- 參數關系:
- 當?\(\rho = 0\)?時,正則化項只剩 L2 范數,模型退化為嶺回歸(Ridge Regression)。
- 當?\(\rho = 1\)?時,正則化項只剩 L1 范數,模型退化為Lasso 回歸。
- 當?\(0 < \rho < 1\)?時,模型同時具備 L1 和 L2 正則化的特性,比如:
- 特征選擇:部分特征的系數會被壓縮至 0(類似 L1)。
- 處理共線性:對高度相關的特征,系數會被均勻壓縮(類似 L2),避免隨機剔除重要特征。
Python 實現與案例解析
下面通過一個簡單的回歸案例,演示彈性網絡正則化的應用過程:
代碼步驟解析
import numpy as np
import matplotlib.pyplot as plt
from sklearn.linear_model import ElasticNet# 1. 生成帶噪聲的線性數據
np.random.seed(42) # 固定隨機種子,確保結果可復現
n_samples = 100 # 樣本數量
X = np.linspace(-3, 3, n_samples) # 特征X:在-3到3之間均勻生成100個點
y = 0.5 * X + np.random.normal(scale=0.5, size=n_samples) # 真實模型:y=0.5X + 噪聲# 2. 創建并訓練彈性網絡模型
enet = ElasticNet(alpha=0.5, l1_ratio=0.7) # alpha=正則化強度,l1_ratio=ρ參數(L1占比70%)
enet.fit(X.reshape(-1, 1), y) # 輸入需為二維數組,reshape(-1,1)將X轉為100×1的矩陣# 3. 繪制結果
plt.scatter(X, y, color='b', label='Original data') # 原始數據點
plt.plot(X, enet.predict(X.reshape(-1, 1)), color='r', linewidth=2, label='Elastic Net') # 模型擬合曲線
plt.xlabel('X')
plt.ylabel('y')
plt.legend()
plt.title('Elastic Net Regression')
plt.show()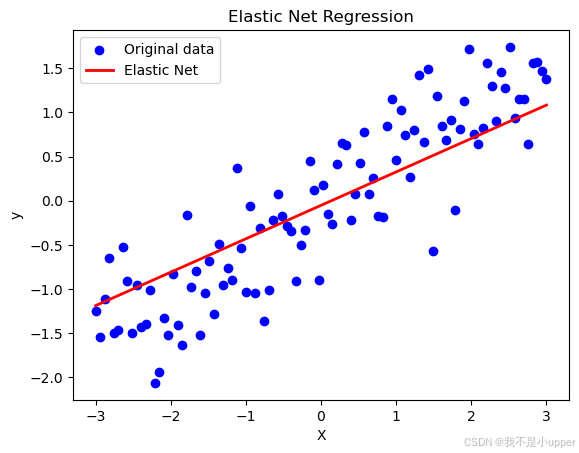
關鍵參數說明
- alpha=0.5:正則化強度適中,若 alpha 過大,模型可能過于平滑(欠擬合);若過小,正則化效果不明顯。
- l1_ratio=0.7:L1 范數占正則化項的 70%,L2 范數占 30%,此時模型會嘗試將部分特征系數置零,同時保留共線性特征的影響。
結果解讀
- 圖中藍色散點是帶噪聲的原始數據,紅色曲線是彈性網絡模型的擬合結果。
- 盡管數據中存在噪聲,但模型通過正則化抑制了過擬合,較好地捕捉了 X 和 y 之間的線性關系(接近真實模型?y=0.5X)。
實際應用建議
- 參數調優:
- 通過交叉驗證(如 GridSearchCV)同時調整
alpha和l1_ratio,找到最優組合。 - 若數據特征間存在共線性,優先嘗試
l1_ratio在 0.3-0.7 之間的值。
- 通過交叉驗證(如 GridSearchCV)同時調整
- 特征預處理:
- 對數據進行標準化(如使用 StandardScaler),確保不同量綱的特征在正則化中被公平對待。
- 適用場景:
- 醫學數據分析(特征多且可能存在共線性,如基因表達數據)。
- 金融建模(如股票收益率預測,特征間常高度相關)。
彈性網絡正則化通過結合 L1 和 L2 的優勢,在特征選擇和處理共線性之間找到了平衡,是線性回歸中應對復雜數據的有效工具。
4、Dropout 正則化(用于神經網絡)
Dropout 正則化是神經網絡中一種簡單有效的防過擬合技術,特別適用于隱藏層較多的復雜模型。它的核心思路是在訓練過程中,通過隨機 “丟棄” 部分神經元的輸出,打破神經元之間的固定依賴關系,迫使模型學習更魯棒、更通用的特征表達。
原理與數學表達
在神經網絡的訓練階段,Dropout 的具體操作如下:
-
隨機丟棄神經元:對于每一層神經元,按照預設的概率?p(稱為丟棄率)隨機決定是否保留該神經元的輸出。
- 引入二進制隨機變量?
(取值為 0 或 1),若?
,則第?j?個神經元的輸出被置為 0(即 “丟棄”);若?
,則保留輸出。
- 每個神經元的丟棄是獨立隨機的,例如當?p = 0.5?時,每層約有一半的神經元會被隨機丟棄。
- 引入二進制隨機變量?
-
前向傳播與反向傳播:
- 被丟棄的神經元在本次迭代中不參與前向傳播,其連接權重也不參與反向傳播的梯度更新。
- 這相當于在每次訓練時,模型的結構都是一個 “精簡版” 的子網絡,不同迭代中丟棄的神經元不同,從而形成多個子網絡的集成效果。
-
損失函數與訓練目標: 在帶有 Dropout 的神經網絡中,損失函數仍基于原始任務目標(如回歸的均方誤差、分類的交叉熵),但模型參數?
?的優化需考慮隨機丟棄的影響。損失函數形式為:
? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ?其中:
- m?是訓練樣本數量,
?是第?i?個輸入樣本,
?是具體的損失函數(如均方誤差?
?或交叉熵)。
- m?是訓練樣本數量,
-
測試階段的補償機制: 在測試或推理時,為保持訓練與測試階段的輸出期望一致,需要將所有神經元的輸出乘以訓練階段的保留概率?1 - p。例如,若訓練時丟棄率為?p = 0.5,則測試時每個神經元的輸出需乘以?0.5。這一步通常由框架自動實現(如 TensorFlow 會在模型導出時自動處理)。
代碼實現與詳細過程
以下通過一個簡單的回歸任務,演示如何在 TensorFlow 中使用 Dropout 正則化:
1. 生成帶噪聲的樣本數據
import numpy as np
import matplotlib.pyplot as plt
import tensorflow as tf# 生成一些樣本數據
np.random.seed(42)
n_samples = 100
X = np.linspace(-3, 3, n_samples)
y = 0.5 * X + np.random.normal(scale=0.5, size=n_samples)- 數據分布:輸入?X?是區間?[-3, 3]?內的均勻分布,輸出?y?是線性函數?y = 0.5X?疊加標準差為 0.5 的噪聲,模擬真實場景中的不完美數據。
2. 構建含 Dropout 的神經網絡模型?
model = tf.keras.models.Sequential([tf.keras.layers.Dense(16, activation='relu', input_shape=(1,)), # 第1層:16個神經元,ReLU激活tf.keras.layers.Dropout(0.5), # Dropout層:丟棄率50%tf.keras.layers.Dense(1) # 輸出層:1個神經元(回歸任務)
])- 網絡結構:
- 輸入層:接收形狀為?
?的單特征數據。
- 隱藏層:16 個神經元,使用 ReLU 激活函數引入非線性。
- Dropout 層:在隱藏層之后,以 50% 的概率隨機丟棄神經元輸出,防止隱藏層過度依賴某些特定神經元。
- 輸出層:單神經元,直接輸出連續值(適用于回歸任務)。
- 輸入層:接收形狀為?
3. 編譯與訓練模型
model.compile(optimizer='adam', loss='mean_squared_error') # 使用均方誤差損失和Adam優化器
model.fit(X, y, epochs=50, batch_size=16, verbose=0) # 訓練50輪,批量大小16- 優化目標:最小化預測值與真實值的均方誤差(MSE)。
- Dropout 的作用:在每輪訓練中,隱藏層的 16 個神經元會隨機保留 8 個(丟棄率 50%),迫使模型學習更魯棒的特征組合,避免過擬合噪聲。
4. 可視化結果?
import matplotlib.pyplot as plt
plt.scatter(X, y, color='b', label='Original data') # 繪制原始數據點
plt.plot(X, model.predict(X), color='r', linewidth=2, label='Dropout Regularization') # 繪制擬合曲線
plt.xlabel('X')
plt.ylabel('y')
plt.legend()
plt.title('Neural Network with Dropout Regularization')
plt.show()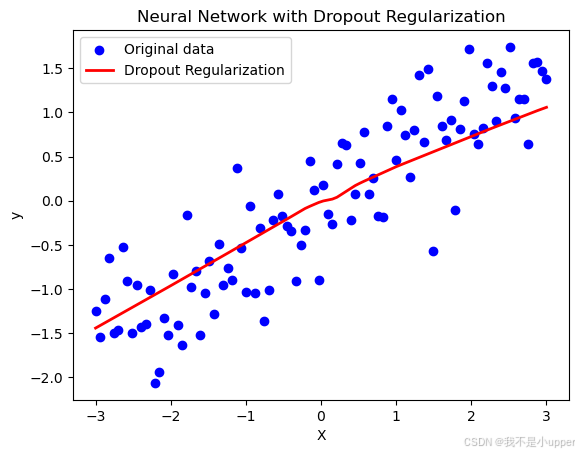
- 結果解讀:
- 藍色散點為帶噪聲的原始數據,紅色曲線為模型預測值。
- 由于 Dropout 的正則化作用,模型未過度擬合噪聲,而是學習到了數據的整體線性趨勢(接近真實函數?y = 0.5X),體現了泛化能力的提升。
關鍵要點總結
- 丟棄率?p?的選擇:通常在?
?之間,過大可能導致模型欠擬合(神經元丟棄過多,信息丟失嚴重),過小則正則化效果不足。
- 適用場景:Dropout 對全連接層效果顯著,在卷積神經網絡(CNN)或 Transformer 中也常作為標配組件,但需結合層特性調整丟棄率(如 CNN 中丟棄率可更低,因卷積層本身具有稀疏性)。
- 與其他正則化的結合:可與 L2 正則化、早停法等結合使用,進一步提升模型性能。
通過 Dropout,神經網絡在訓練中通過 “隨機瘦身” 強制學習更通用的特征,有效緩解了過擬合問題,是深度學習中簡單且高效的正則化手段。
5、貝葉斯 Ridge 和 Lasso 回歸
貝葉斯 Ridge 回歸與貝葉斯 Lasso 回歸是基于貝葉斯統計理論的回歸模型,它們在經典線性回歸的基礎上引入概率視角,不僅能擬合數據,還能通過參數的概率分布刻畫模型的不確定性。以下從原理、公式、特點及代碼實現展開說明。
貝葉斯 Ridge 回歸
核心思想: 貝葉斯 Ridge 回歸通過在損失函數中加入L2 正則化項(即權重向量的平方和)控制模型復雜度,同時將模型權重參數視為隨機變量,利用貝葉斯推斷估計參數的概率分布,而非單一確定值。這種方法不僅能緩解過擬合,還能給出預測結果的置信區間,體現模型對預測的 “不確定性判斷”。
目標函數:
- n:樣本數量;
:第i個樣本的特征向量;
:模型權重向量;
:L2 范數的平方(權重平方和);
貝葉斯推斷過程:
- 先驗分布:假設權重
,其中
是先驗方差,體現對 “權重應較小” 的先驗知識。
- 似然函數:在給定
為均值的高斯分布,即:? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ?
,其中
是噪聲方差。
- 后驗分布:根據貝葉斯定理,結合先驗和似然得到權重的后驗分布?
,其中?
?是權重的點估計,
?是協方差矩陣,描述參數的不確定性。
- 預測分布:對新樣本
,預測值
的分布為:? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ??
,包含數據噪聲和參數不確定性。
特點:
- 優點:能處理不同類型數據和噪聲,通過后驗分布提供預測的置信區間,適合需要不確定性評估的場景(如醫療診斷、金融風險分析)。
- 缺點:需進行概率推斷(如馬爾可夫鏈蒙特卡羅采樣),計算復雜度高于傳統 Ridge 回歸。
貝葉斯 Lasso 回歸
核心思想: 與貝葉斯 Ridge 回歸類似,但將正則化項改為L1 范數(權重絕對值之和),對應權重參數的先驗分布為拉普拉斯分布。L1 范數的特性使模型傾向于將部分權重置零,從而實現特征選擇,即自動識別對預測無關的特征并剔除。
目標函數:
:L1 范數(權重絕對值之和);
- 其他符號含義與貝葉斯 Ridge 回歸一致。
貝葉斯推斷過程:
- 先驗分布:權重
,該分布在零點附近概率密度較高,促使權重向零收縮,甚至精確為零。
- 后驗分布:通過貝葉斯定理結合拉普拉斯先驗和高斯似然,后驗分布傾向于產生稀疏解(大量權重為零),從而篩選出關鍵特征。
特點:
- 優點:自動進行特征選擇,適合高維數據(如基因表達數據、文本數據),模型解釋性更強(僅保留非零權重的特征)。
- 缺點:計算復雜度高,需高效算法(如變分貝葉斯推斷)求解后驗分布。
Python 代碼實現(貝葉斯 Ridge 回歸)
import numpy as np
import matplotlib.pyplot as plt
from sklearn.linear_model import BayesianRidge# 生成示例數據集(一維線性關系+噪聲)
np.random.seed(42) # 固定隨機種子確保可復現
X = np.random.rand(100, 1) * 10 # 生成100個0-10之間的隨機特征值
y = 2 * X[:, 0] + np.random.randn(100) # 真實模型為y=2x+噪聲(噪聲服從標準正態分布)# 創建貝葉斯Ridge回歸模型對象
model = BayesianRidge() # 采用默認超參數,自動估計正則化參數和噪聲方差# 擬合模型(基于訓練數據學習權重參數)
model.fit(X, y)# 生成用于預測的新樣本點(0到10之間均勻分布的100個點)
x_new = np.linspace(0, 10, 100).reshape(-1, 1)# 預測新樣本點的輸出值及標準差(return_std=True返回預測標準差)
y_pred, y_std = model.predict(x_new, return_std=True)# 繪制原始數據、擬合曲線及置信區間
fig, ax = plt.subplots(figsize=(8, 5))
ax.scatter(X, y, color='blue', label='原始數據', alpha=0.6) # 繪制散點圖展示原始數據分布
ax.plot(x_new, y_pred, color='red', label='擬合曲線', linewidth=2) # 繪制模型擬合的線性曲線
ax.fill_between(x_new.flatten(), # x軸坐標(展平為一維數組)y_pred - y_std, # 置信區間下界(預測值減去標準差)y_pred + y_std, # 置信區間上界(預測值加上標準差)color='pink', alpha=0.3, label='95%置信區間'
) # 填充區域表示預測的不確定性范圍ax.set_xlabel('特征X', fontsize=12)
ax.set_ylabel('目標y', fontsize=12)
ax.set_title('貝葉斯Ridge回歸擬合效果', fontsize=14)
ax.legend()
plt.show()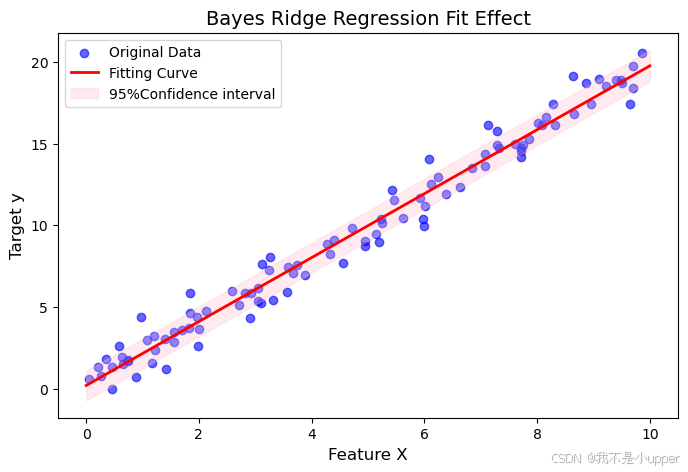
代碼解析:
- 數據生成:通過
np.random.rand生成特征X,真實模型為(
為高斯噪聲),模擬線性回歸場景。
- 模型初始化:
BayesianRidge默認使用經驗貝葉斯方法(Empirical Bayes)自動估計超參數(如正則化強度、噪聲方差),無需手動調參。 - 擬合與預測:
model.fit學習權重參數,model.predict返回預測均值()和標準差(
),后者反映預測的不確定性(標準差越小,預測越可靠)。
- 結果可視化:
- 藍色散點為原始數據,紅色曲線為模型擬合的均值預測。
- 粉色陰影區域為預測值的置信區間(均值 ± 標準差),體現模型對不同x值的預測不確定性(如數據稀疏區域的置信區間更寬)。
?6、早停法(Early Stopping)
早停法是一種直觀且有效的防止模型過擬合的正則化技術,核心思想是在模型訓練過程中實時監控其在驗證集上的表現,避免模型對訓練數據過度擬合。它不需要修改損失函數或模型結構,而是通過控制訓練的終止時機來平衡模型的偏差與方差。
早停法的核心步驟
- 數據劃分:將原始數據集劃分為訓練集和驗證集。訓練集用于模型參數更新,驗證集用于評估模型在未見過數據上的泛化能力。
- 初始化模型:設定模型的初始參數(如神經網絡的權重)。
- 迭代訓練與監控:
- 在每一輪訓練迭代中,使用訓練集更新模型參數,并計算訓練誤差(衡量模型對訓練數據的擬合程度)。
- 每輪迭代后,立即用驗證集計算驗證誤差(衡量模型的泛化能力)。
- 終止條件判斷:當驗證誤差連續多輪不再下降(或開始上升)時,停止訓練,并保留此時的模型參數作為最終結果。
關鍵公式與原理
早停法的核心是通過監控驗證誤差來找到模型的最佳訓練平衡點。假設損失函數為均方誤差(MSE),則:
- 訓練誤差:
?其中,
為訓練樣本數,
?為模型在訓練集上的預測值。
- 驗證誤差:
?其中,
為驗證樣本數,
為模型在驗證集上的預測值。
目標:在訓練過程中,當驗證誤差從下降轉為上升時(即出現過擬合跡象),及時終止訓練,選擇驗證誤差最小的模型參數。
Python 實現與代碼解析
以下是一個基于線性回歸的早停法示例,通過逐步增加訓練樣本量模擬迭代過程,并直觀展示誤差變化:
import numpy as np
import matplotlib.pyplot as plt
from sklearn.model_selection import train_test_split
from sklearn.linear_model import LinearRegression# 生成示例數據(線性關系+隨機噪聲)
np.random.seed(42) # 固定隨機種子確保可復現
X = np.linspace(-5, 5, num=100).reshape(-1, 1) # 特征數據(100個樣本,單維度)
y = 2 * X + np.random.normal(0, 1, size=(100, 1)) # 真實標簽:y=2X+噪聲# 劃分訓練集(80樣本)和驗證集(20樣本)
X_train, X_val, y_train, y_val = train_test_split(X, y, test_size=0.2, random_state=42
)# 初始化線性回歸模型
model = LinearRegression()# 存儲每輪迭代的訓練誤差和驗證誤差
train_errors = []
val_errors = []# 模擬迭代訓練:逐步增加訓練樣本量(從1到80樣本)
for i in range(1, len(X_train) + 1):# 使用前i個樣本訓練模型model.fit(X_train[:i], y_train[:i])# 計算訓練誤差:僅用已訓練的i個樣本預測y_train_pred = model.predict(X_train[:i])train_error = np.mean((y_train_pred - y_train[:i]) ** 2)train_errors.append(train_error)# 計算驗證誤差:用整個驗證集預測y_val_pred = model.predict(X_val)val_error = np.mean((y_val_pred - y_val) ** 2)val_errors.append(val_error)# 繪制誤差曲線
fig, ax = plt.subplots(figsize=(8, 4))
ax.plot(train_errors, label="訓練誤差", linestyle="-", color="blue")
ax.plot(val_errors, label="驗證誤差", linestyle="-", color="orange")
# 找到驗證誤差最小的位置(早停點)
best_epoch = np.argmin(val_errors)
ax.axvline(x=best_epoch, linestyle="--", color="red", label=f"早停點(第{best_epoch+1}輪)"
) # +1是因為索引從0開始
ax.set_xlabel("訓練輪數(樣本量遞增)")
ax.set_ylabel("均方誤差(MSE)")
ax.set_title("早停法效果可視化")
ax.legend()
plt.grid(True)
plt.show()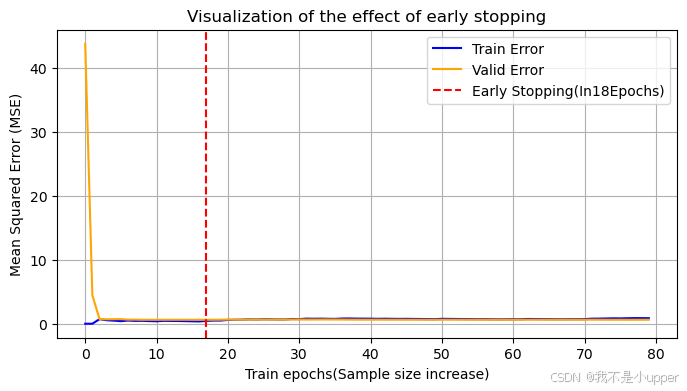
代碼詳解與可視化分析
- 數據生成:創建一維特征X和線性標簽y=2X+噪聲,模擬真實場景中的數據分布。
- 數據劃分:將數據按 8:2 劃分為訓練集和驗證集,驗證集用于監控泛化能力。
- 迭代訓練:
- 從 1 個樣本開始,逐步增加到 80 個樣本(每輪多訓練 1 個樣本),模擬模型從簡單到復雜的過程。
- 每輪訓練后,同時計算訓練誤差(僅用已訓練的樣本評估)和驗證誤差(用獨立驗證集評估)。
- 可視化結果:
- 訓練誤差:隨訓練樣本增加持續下降(模型對訓練數據擬合越來越好)。
- 驗證誤差:先下降后上升(當模型開始過擬合時,驗證誤差回升)。
- 早停點:驗證誤差最小的位置(圖中紅色虛線),此時模型在泛化能力和擬合能力間達到平衡。
早停法的優缺點
- 優點:
- 無需修改模型結構或超參數,實現簡單。
- 計算成本低,尤其適合深度學習中避免過度訓練。
- 缺點:
- 需預留驗證集,可能減少訓練數據量。
- 終止時機依賴經驗(如連續多少輪誤差上升才停),需調參。
早停法通過 “監控 - 止損” 的邏輯,為模型訓練提供了一種動態平衡的解決方案,是實際應用中防止過擬合的常用技術之一。
7、數據增強
數據增強是一種通過擴充和變換訓練數據來提升模型泛化能力的正則化技術。其核心邏輯是:當模型見過的數據越多、越多樣,就越不容易被訓練集中的特定噪聲或局部模式 “帶偏”,從而在新數據上表現得更穩健。
數據增強的核心步驟
-
隨機變換操作:
對原始訓練數據應用各類隨機變換,常見的包括:- 幾何變換:旋轉(如將圖像順時針旋轉 30 度)、平移(將圖像向左移動 10 像素)、縮放(將圖像放大 1.2 倍)、裁剪(隨機截取圖像的一部分)等。
- 像素變換:調整亮度(調暗 20%)、對比度(增強對比度)、添加高斯噪聲(模擬圖像模糊)等。
- 空間變換:在自然語言處理中,可隨機替換同義詞(如將 “高興” 換成 “開心”)、打亂句子順序等。
-
擴充數據集:
將變換后的樣本與原始數據合并,形成更大的訓練集。例如,原始數據有 1000 張圖片,經過 5 種變換后,可擴充為 6000 張圖片(原始 + 5 倍變換數據)。 -
模型訓練:
使用增強后的數據集訓練模型,讓模型在學習過程中接觸更多樣化的輸入模式,從而提升對不同場景的適應能力。
數據增強的目標
通過增加數據的多樣性,迫使模型學習更本質的特征,而非記憶訓練集中的表面規律。例如:
- 在圖像分類中,對貓的圖像進行旋轉、縮放等變換后,模型需要學會 “無論貓怎么擺姿勢都是貓”,而不是記住某個特定角度的貓。
- 在語音識別中,對音頻添加背景噪聲,模型需學會從嘈雜環境中提取關鍵語音特征。
代碼示例解析
import numpy as np
import matplotlib.pyplot as plt
from sklearn.datasets import make_moons
from sklearn.linear_model import LogisticRegression# 生成示例數據集(月亮形狀的二分類數據)
np.random.seed(42) # 固定隨機種子確保結果可復現
X, y = make_moons(n_samples=200, noise=0.1) # 生成200個帶噪聲的樣本# 創建邏輯回歸模型
model = LogisticRegression()# 繪制原始數據分布(兩類樣本呈月牙狀分布)
fig, ax = plt.subplots()
ax.scatter(X[:, 0], X[:, 1], c=y, cmap="bwr", edgecolors='k')
ax.set_xlabel("X1")
ax.set_ylabel("X2")
ax.set_title("Original Data Distribution")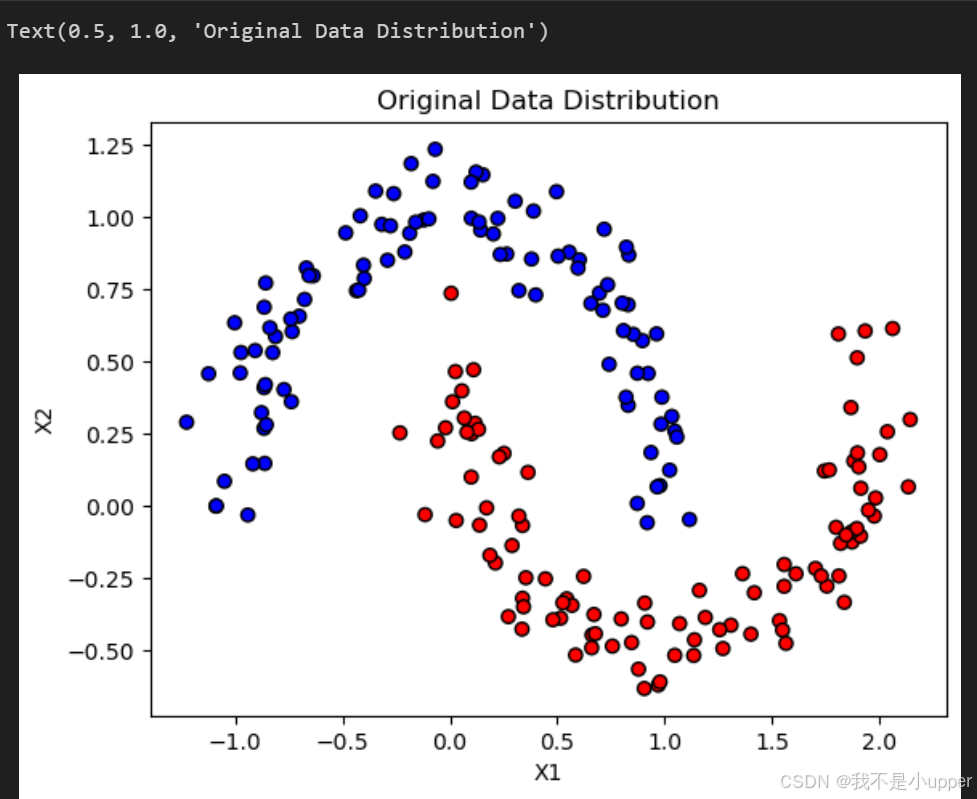
數據增強過程:?
n_transforms = 50 # 生成50倍增強數據
augmented_X = []
augmented_y = []
for i in range(n_transforms):# 對原始數據添加隨機高斯擾動(噪聲均值0,標準差0.05)transformed_X = X + np.random.normal(0, 0.05, size=X.shape)augmented_X.append(transformed_X)augmented_y.append(y) # 標簽與原始數據一致# 合并原始數據與增強數據
augmented_X = np.concatenate(augmented_X, axis=0) # 縱向拼接,shape從(200,2)變為(200*50,2)
augmented_y = np.concatenate(augmented_y, axis=0)可視化增強后的數據:
fig, ax = plt.subplots()
ax.scatter(augmented_X[:, 0], augmented_X[:, 1], c=augmented_y, cmap="bwr", edgecolors='k')
ax.set_xlabel("X1")
ax.set_ylabel("X2")
ax.set_title("Data Distribution after Augmentation")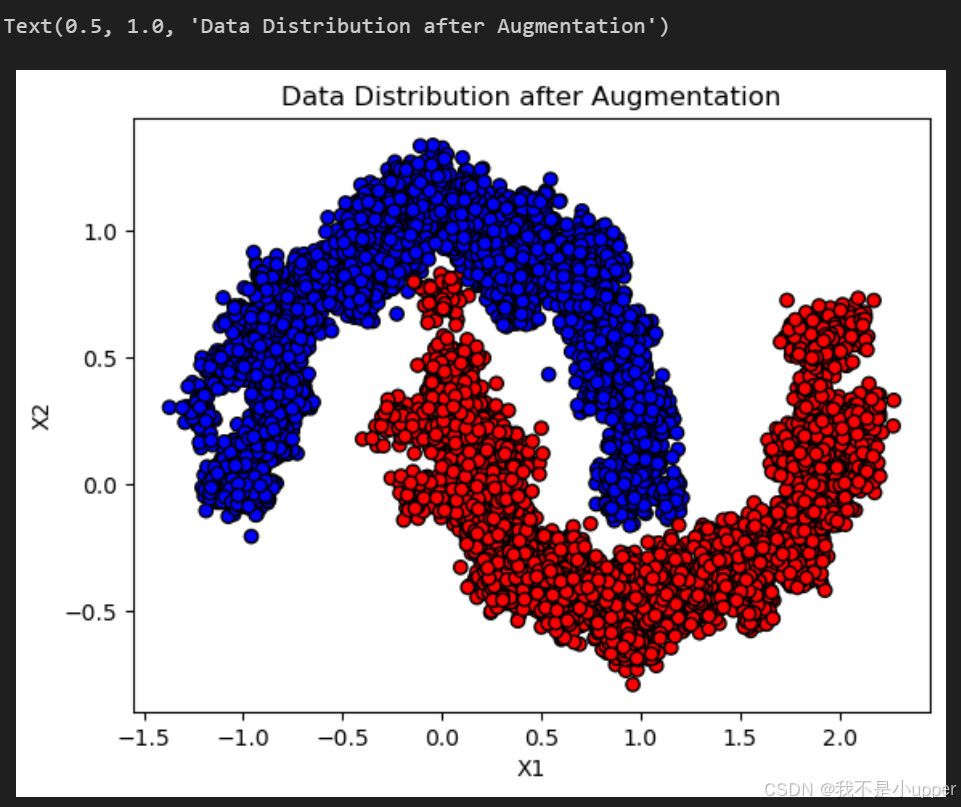
- 變化:原始數據集中的每個樣本(如某個月牙點)周圍生成了許多 “近鄰點”(通過高斯噪聲擾動),數據集的密度顯著增加,覆蓋了更廣泛的空間區域。
模型訓練與決策邊界繪制:
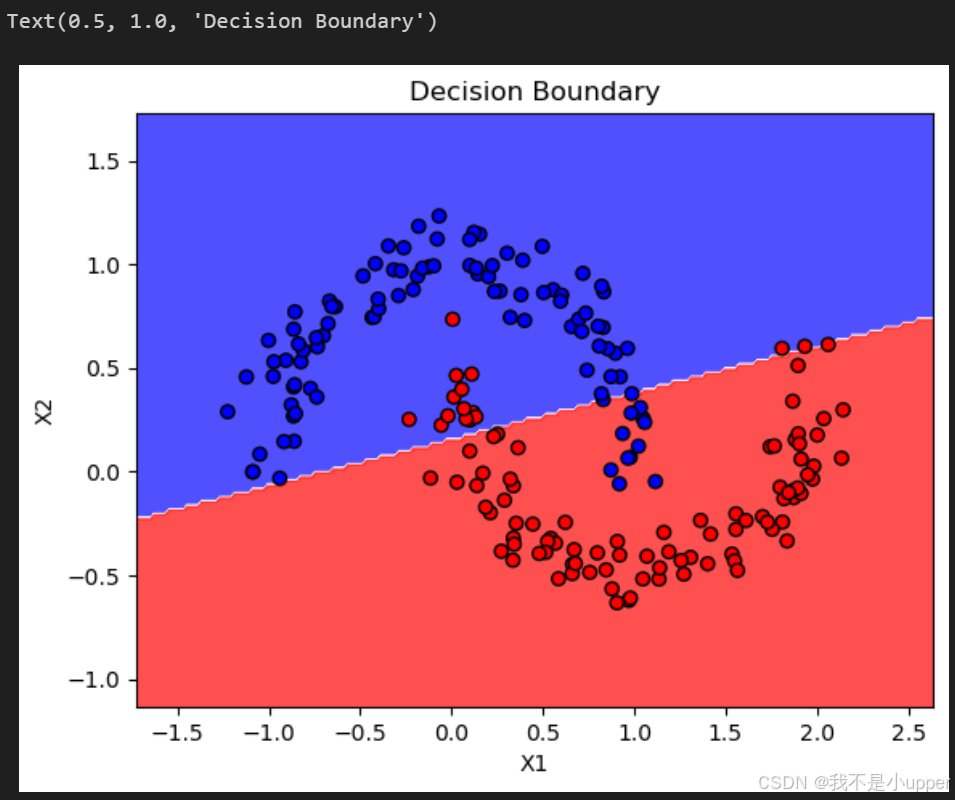
- 結果分析:
- 增強前:模型可能因訓練數據有限,決策邊界過度擬合原始月牙的局部形狀。
- 增強后:數據點分布更密集,模型學到的決策邊界更平滑,能更好地泛化到未見過的新樣本(如原始數據點周圍的區域)。
關鍵要點
-
無顯式公式但有統計規律:
數據增強沒有統一的數學公式,但其本質是對數據分布進行平滑擴展—— 通過隨機變換生成符合原始數據分布規律的新樣本(如高斯擾動保持數據的局部相關性)。 -
任務特異性:
- 圖像領域:常用旋轉、裁剪、顏色抖動等變換。
- 文本領域:常用同義詞替換、句子截斷、段落打亂等。
- 時序數據(如股票價格):常用時間平移、幅度縮放等。
-
平衡多樣性與真實性:
變換需合理(如不能將貓的圖像旋轉 180 度后標簽仍標為 “貓”),確保增強數據與原始數據屬于同一分布,避免引入誤導性樣本。
通過數據增強,模型能在不增加真實數據采集成本的前提下,“虛擬” 擴充數據集,是應對小數據過擬合問題的核心技術之一。
最后
今天介紹了7個機器學習中正則化算法的總結,以及不同情況使用的情況。
喜歡的朋友可以收藏、點贊、轉發起來!





)




)






)

