本文深入解析 SQLMesh 中的增量時間范圍模型,介紹其核心原理、配置方法及高級特性。通過實際案例說明如何利用該模型提升數據加載效率,降低計算資源消耗,并提供配置示例與最佳實踐建議,幫助讀者在實際項目中有效應用這一強大功能。

一、增量時間范圍模型概述
在數據倉庫和數據分析領域,高效的數據加載策略至關重要。SQLMesh 提供的"增量時間范圍"模型(Incremental by Time Range)正是為此而生。與傳統的全量刷新模型相比,增量模型通過僅加載新數據,大幅提升了數據處理效率。
核心優勢:
- 減少重復數據加載,節省計算資源
- 降低存儲成本
- 提高數據處理速度
- 保證數據一致性
二、工作原理詳解
1. 時間范圍計算機制
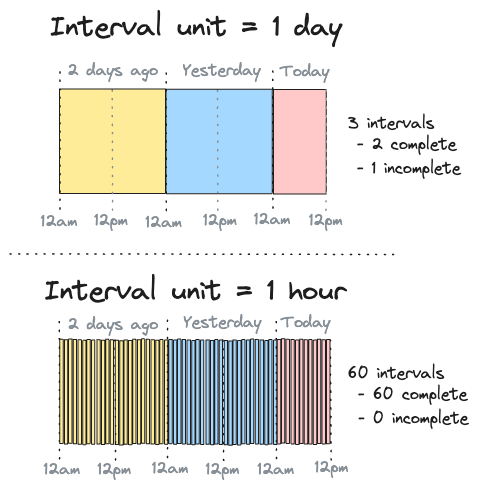
SQLMesh 采用獨特的時間間隔計算方法,而非簡單的基于最新記錄時間戳的方式。這種方法更加健壯,避免了數據間隙和單次查詢限制帶來的問題。
時間間隔計算示例:
假設模型開始時間為兩天前的午夜(00:00),當前時間為中午12:00(12:00 PM):
| 間隔單位 | 兩天前 | 昨天 | 今天 | 總計 |
|---|---|---|---|---|
| 1天 | 1 | 1 | 1(未完成) | 3 |
| 1小時 | 24 | 24 | 12 | 60 |
關鍵點:
- 第一次運行會標記所有間隔為已處理
- 后續運行只處理新增的間隔
- 系統自動跟蹤已處理的時間范圍
2. 模型執行方式
SQLMesh 提供兩種主要執行命令:
- sqlmesh plan - 當模型結構變更時使用
- sqlmesh run - 定期執行模型時使用
調度優化:
通過為不同模型設置不同的 cron 表達式,可以按需控制執行頻率,避免資源浪費。例如:
- 高頻模型每小時運行一次
- 低頻模型每天運行一次
三、模型配置實戰
1. 基礎配置模板
MODEL (name sqlmesh_example.new_model,kind INCREMENTAL_BY_TIME_RANGE(time_column(model_time_column, '%Y-%m-%d') -- 時間列格式)
);SELECT * FROM sqlmesh_example.incremental_model
WHERE model_time_column BETWEEN @start_ds AND @end_ds
配置要點:
time_column必須使用 UTC 時區- 宏變量
@start_ds和@end_ds由系統自動填充 - 時間格式必須與配置一致
2. 前向變更配置
對于大型數據模型,可啟用前向變更模式:
MODEL (name sqlmesh_example.new_model,kind INCREMENTAL_BY_TIME_RANGE(time_column(model_time_column, '%Y-%m-%d'),forward_only true -- 所有變更僅向前應用)
)
使用場景:
- 數據量過大,無法承受全表刷新
- 需要保持歷史數據完整性
- 變更不涉及結構性修改
執行方式:
sqlmesh plan --forward-only # 單次前向變更
或在模型配置中永久設置:
forward_only true
四、高級特性與安全機制
1. 雙重時間過濾
SQLMesh 實施兩層時間過濾機制:
- 輸入過濾 - 在模型查詢中通過 WHERE 子句實現
- 輸出過濾 - 由 SQLMesh 自動添加的安全過濾器
為什么需要雙層過濾?
- 輸入過濾優化性能,減少處理數據量
- 輸出過濾確保數據安全,防止意外數據泄露
- 適應不同上游模型的時間列差異
最佳實踐:
- 始終在模型查詢中包含時間過濾條件
- 不要依賴單一過濾層
- 理解兩者作用差異
2. 破壞性變更處理
SQLMesh 對可能破壞數據的變更采取保守策略:
-
默認情況下會阻止可能導致數據丟失的變更
-
可通過配置調整行為:
MODEL (name sqlmesh_example.new_model,kind INCREMENTAL_BY_TIME_RANGE(time_column model_time_column,forward_only true,on_destructive_change allow -- 允許破壞性變更) )
變更控制層級:
- 模型級別配置
- 全局默認設置
- 命令行覆蓋選項
五、配置示例與技巧
案例1:電商訂單分析模型
MODEL (name ecommerce.order_analysis,kind INCREMENTAL_BY_TIME_RANGE(time_column(order_timestamp, '%Y-%m-%d %H:%i:%s'),forward_only false)
);SELECT order_id,customer_id,order_amount,order_timestamp
FROM ecommerce.orders
WHERE order_timestamp BETWEEN @start_ds AND @end_ds
配置建議:
- 時間列選擇最細粒度的時間戳
- 根據業務需求平衡前向變更和全量刷新
- 對關鍵業務表保留破壞性變更保護
案例2:用戶行為日志模型(大容量)
MODEL (name user_behavior.logs,kind INCREMENTAL_BY_TIME_RANGE(time_column(event_time, '%Y-%m-%d %H:%i:%s'),forward_only true)
);SELECT user_id,event_type,event_time,page_url
FROM user_behavior.events
WHERE event_time BETWEEN @start_ds AND @end_ds
優化技巧:
- 設置較大的 batch_size 處理海量數據
- 定期評估前向變更的適用性
- 監控數據延遲情況
總結
SQLMesh 的增量時間范圍模型為現代數據工程提供了強大的工具,能夠顯著提升數據處理效率并降低資源消耗。通過合理配置時間列、巧妙運用前向變更機制以及理解雙層時間過濾的工作原理,數據工程師可以構建既高效又安全的數據管道。
關鍵收獲:
- 增量模型是處理大規模數據的利器
- 時間間隔計算比簡單時間戳更可靠
- 雙重時間過濾確保性能與安全
- 前向變更平衡了靈活性與安全性
- 破壞性變更保護機制防止數據丟失
建議在實際項目中逐步采用增量模型,從非關鍵表開始測試,積累經驗后再推廣到核心業務表。同時,定期審查模型配置,根據數據增長和業務需求調整策略。
通過掌握這些技術,您將能夠構建更高效、更可靠的數據基礎設施,為業務決策提供有力支持。





)

:安裝部署Docker Deskpot之后啟動出現Docker Engine Stopped!)

![[模型部署] 3. 性能優化](http://pic.xiahunao.cn/[模型部署] 3. 性能優化)








 解題報告 | 珂學家)
