目錄
- 前言
- 1. 基本知識
- 2. 在線URL
- 2.1 英文
- 2.2 混合
- 3. 實戰
前言
爬蟲神器,無代碼爬取,就來:bright.cn
Java基本知識:
- java框架 零基礎從入門到精通的學習路線 附開源項目面經等(超全)
- 【Java項目】實戰CRUD的功能整理(持續更新)
需要爬蟲相關的PDF,并統計對應PDF里頭的詞頻,其中某個功能需要如下知識點
1. 基本知識
Apache PDFBox 是一個開源的 Java PDF 操作庫,支持:
-
讀取 PDF 文件內容(包括文字、圖片、元數據)
-
創建和修改 PDF 文檔
-
提取文本內容用于搜索、分析等操作
Maven相關的依賴:
<dependency><groupId>org.apache.pdfbox</groupId><artifactId>pdfbox</artifactId><version>2.0.29</version>
</dependency>
需下載 在進行統計:
import org.apache.pdfbox.pdmodel.PDDocument;
import org.apache.pdfbox.text.PDFTextStripper;import java.io.File;
import java.io.IOException;public class PDFWordCounter {public static void main(String[] args) {String pdfPath = "sample.pdf"; // 替換為你的 PDF 文件路徑String keyword = "Java"; // 要統計的詞語try {// 加載 PDF 文檔PDDocument document = PDDocument.load(new File(pdfPath));// 使用 PDFTextStripper 提取文本PDFTextStripper stripper = new PDFTextStripper();String text = stripper.getText(document);document.close(); // 記得關閉文檔資源// 轉小寫處理,方便忽略大小寫String lowerText = text.toLowerCase();String lowerKeyword = keyword.toLowerCase();// 調用詞頻統計函數int count = countOccurrences(lowerText, lowerKeyword);System.out.println("詞語 \"" + keyword + "\" 出現次數: " + count);} catch (IOException e) {e.printStackTrace();}}// 使用 indexOf 遍歷匹配詞語出現次數private static int countOccurrences(String text, String word) {int count = 0;int index = 0;while ((index = text.indexOf(word, index)) != -1) {count++;index += word.length();}return count;}
}
上述的Demo詳細分析下核心知識:
-
PDDocument.load(File)
用于加載 PDF 文件到內存中
PDFBox 使用 PDDocument 表示整個 PDF 對象,使用完后必須調用 close() 釋放資源 -
PDFTextStripper
PDFBox 中用于提取文字的核心類,會盡可能“以閱讀順序”提取文本,適用于純文字 PDF 文件。對于圖像型掃描件則無效(需 OCR) -
大小寫不敏感統計
實際應用中搜索關鍵詞通常需要忽略大小寫,因此我們先統一將文本和關鍵詞轉換為小寫 -
indexOf 實現詞頻統計
這是最基礎也最直觀的統計方法,效率較高,但不夠精確
如果需要更精確(只統計完整單詞),可以使用正則:
Pattern pattern = Pattern.compile("\\b" + Pattern.quote(word) + "\\b", Pattern.CASE_INSENSITIVE);
Matcher matcher = pattern.matcher(text);
int count = 0;
while (matcher.find()) {count++;
}
2. 在線URL
2.1 英文
此處的Demo需要注意一個點:
| 注意點 | 說明 |
|---|---|
| PDF 文件是否公開訪問 | 不能訪問受密碼或登錄保護的 PDF |
| 文件大小 | 不建議下載和分析過大文件,可能導致內存問題 |
| 中文 PDF | 若是掃描圖片形式的中文 PDF,則 PDFBox 無法直接提取文本(需 OCR) |
| 編碼問題 | 若中文顯示為亂碼,可能是 PDF 沒有內嵌字體 |
🔧 思路:
-
通過 URL.openStream() 獲取在線 PDF 的輸入流
-
使用 PDFBox 的 PDDocument.load(InputStream) 讀取 PDF
-
用 PDFTextStripper 提取文本
-
用字符串方法或正則統計關鍵詞頻率
import org.apache.pdfbox.pdmodel.PDDocument;
import org.apache.pdfbox.text.PDFTextStripper;import java.io.InputStream;
import java.net.URL;
import java.util.regex.Matcher;
import java.util.regex.Pattern;public class OnlinePDFKeywordCounter {public static void main(String[] args) {String pdfUrl = "https://www.example.com/sample.pdf"; // 你的在線 PDF 鏈接String keyword = "Java"; // 需要統計的關鍵詞try (InputStream inputStream = new URL(pdfUrl).openStream();PDDocument document = PDDocument.load(inputStream)) {PDFTextStripper stripper = new PDFTextStripper();String text = stripper.getText(document);// 使用正則匹配單詞邊界(忽略大小寫)Pattern pattern = Pattern.compile("\\b" + Pattern.quote(keyword) + "\\b", Pattern.CASE_INSENSITIVE);Matcher matcher = pattern.matcher(text);int count = 0;while (matcher.find()) {count++;}System.out.println("詞語 \"" + keyword + "\" 出現在在線 PDF 中的次數為: " + count);} catch (Exception e) {System.err.println("處理 PDF 時出錯: " + e.getMessage());e.printStackTrace();}}
}
2.2 混合
| 方法 | 適用場景 | 是否支持中文 |
|---|---|---|
indexOf | 中英文都適用 | ? |
Pattern + \\b | 僅限英文單詞匹配 | ? 中文不支持 |
正則表達式 \\b...\\b(表示“單詞邊界”)并不適用于中文
統計在想的URL PDF的詞頻:
import org.apache.pdfbox.pdmodel.PDDocument;
import org.apache.pdfbox.text.PDFTextStripper;import java.io.InputStream;
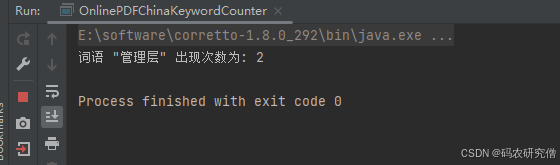
import java.net.URL;public class OnlinePDFKeywordCounter {public static void main(String[] args) {String pdfUrl = "https://www.xxxx.pdf";String keyword = "管理層"; // 要統計的中文關鍵詞try (InputStream inputStream = new URL(pdfUrl).openStream();PDDocument document = PDDocument.load(inputStream)) {PDFTextStripper stripper = new PDFTextStripper();String text = stripper.getText(document);// 直接用 indexOf 不區分大小寫(對于中文沒必要轉小寫)int count = countOccurrences(text, keyword);System.out.println("詞語 \"" + keyword + "\" 出現次數為: " + count);} catch (Exception e) {System.err.println("處理 PDF 時出錯: " + e.getMessage());e.printStackTrace();}}// 簡單統計子串出現次數(適用于中文)private static int countOccurrences(String text, String keyword) {int count = 0;int index = 0;while ((index = text.indexOf(keyword, index)) != -1) {count++;index += keyword.length();}return count;}
}
截圖如下:
3. 實戰
如果詞頻比較多,可以使用List
import org.apache.pdfbox.pdmodel.PDDocument;
import org.apache.pdfbox.text.PDFTextStripper;import java.io.InputStream;
import java.net.URL;
import java.util.Arrays;
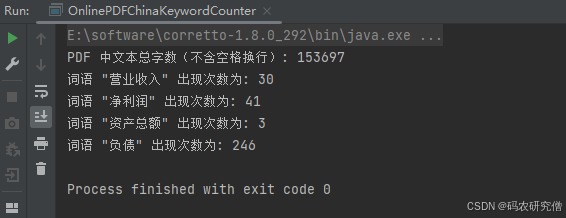
import java.util.List;public class OnlinePDFChinaKeywordCounter {public static void main(String[] args) {String pdfUrl = "https://www.pdf";// 多個中文關鍵詞List<String> keywords = Arrays.asList("營業收入", "凈利潤", "資產總額", "負債");try (InputStream inputStream = new URL(pdfUrl).openStream();PDDocument document = PDDocument.load(inputStream)) {PDFTextStripper stripper = new PDFTextStripper();String text = stripper.getText(document);// 統計 PDF 中的總文字長度(不含空格和換行)int totalCharacters = text.replaceAll("\\s+", "").length();System.out.println("PDF 中文本總字數(不含空格換行): " + totalCharacters);for (String keyword : keywords) {int count = countOccurrences(text, keyword);System.out.println("詞語 \"" + keyword + "\" 出現次數為: " + count);}} catch (Exception e) {System.err.println("處理 PDF 時出錯: " + e.getMessage());e.printStackTrace();}}// 統計某個關鍵詞出現次數private static int countOccurrences(String text, String keyword) {int count = 0;int index = 0;while ((index = text.indexOf(keyword, index)) != -1) {count++;index += keyword.length();}return count;}
}
截圖如下:




)






)







)