目錄
一、概述
二、實例詳解
1)問題描述與分析
2)初始化種群
3)計算種群適應度
4)遺傳操作
5)基因交叉操作
6)變異操作
三、計算結果
四、總結?
一、概述
? ? ? ?遺傳算法在求解最優解的問題中最為常用,不論是在線性還是非線性問題中都得到廣泛運用。本文主要介紹對遺傳算法思想的個人理解,并結合一個簡單實例進行說明,以便在后續實際問題中能夠借助遺傳算法思想解決問題。首先需要明白的是,遺傳算法只是一種求解最優近似解的算法之一,它不是用于求解精確解的方法。當然,如果我們能得到精確解,自然也沒必要去研究最優近似解。
? ? ? ?從遺傳算法的名字我們也可知道,這個算法的思想借助了生物學上生物進化與基因遺傳的思想。生物個體在進化過程中,基因代代相傳,并在傳遞過程中出現基因混合、突變等現象,然后適應環境的基因被保存下來,不適應環境的基因被淘汰出局,如此生物基因逐步達到與環境的最佳適配。遺傳算法的迭代過程正式基于生物進化過程來構建,并用相應的數學概念來對應生物進化過程的個體、基因、遺傳、混合(雜交)、淘汰等,其過程完全按照生物進化過程進行迭代演進。
? ? ? ?我們知道,生物進化中基因傳遞、自然淘汰等都是不可預測的概率事件。因此,遺傳算法迭代過程也充滿了不可預測性。雖然總體趨勢是向最優方向發展,但是我們并不能準確給出何時算法能得到我們認為的最優近似結果。也或許在某些問題中,我們根本不知道得到的結果是否就是最好的解。
二、實例詳解
1)問題描述與分析
? ? ? 使用遺傳算法計算函數result = x + 10 * sin(4*x) + 7 * cos(3*x)在自變量[0,10]以內的最大值。這是一個非常簡單的求極值問題,我們通過解析法也可以得到精確解,但是此處我們需要借助這個問題來詳細說明遺傳算法的實現。通過前面的概述,我們可以知道遺傳算法的實現應該依次有以下步驟:創建一個初始種群—>計算種群的適應度—>種群遺傳—>新種群雜交—>新種群變異—>計算新種群適應度,如此循環進行上述操作,直到我們得到合適的結果或迭代步數完成為止。下面借助MATLAB逐一說明每一步的實現過程。
2)初始化種群
? ? ? ?從生物學角度來講,一個種群包含若干個體,一個個體包含若干基因。因此,初始化種群前我們需要確定這個種群的個體數量和每個個體包含多少基因。在實際操作中,種群的大小和基因數量都應根據實際問題來分析設置,因為它們直接影響算法的收斂速度和求解精度。在此問題中,我們可以選擇種群數量為50個個體,這個值盡量大一點,在計算機性能允許的條件下。每個個體的基因數量設置為20。
? ? ? ?此處作進一步說明,個體其實就是我們預設的一組方程x的解,這里我們隨機預設了50個解,當然我們并不知道其中是否包含了最優解,這50個解我們將使用程序自動隨機生成。個體的基因其實就是對每個解使用二進制編碼時需要使用的二進制位數,這個位數越長,解的精度越高,當然對計算機性能的要求也越高,如果實際問題對求解精度要求很高,需要編碼長度越長。在遺傳算法中,使用二進制對個體(解)進行編碼是最常用,且最直觀的方式,因此此處就直接采用二進制編碼形式。初始化種群的具體實現如下段MATLAB代碼所示。
? ? ? ? 此段代碼已逐行解釋,核心是initial_group = randi([0,1],NP, L),randi函數實現了一個隨機初始化種群,并將該種群放入矩陣initial_group中。randi函數的作用是生成一個NP行,L列的整數矩陣,該矩陣中的元素在0和1之間隨機取值。由此我們可以知道,initial_group矩陣中,每一行表示一個個體,共有50個,每個個體包含20個基因,而基因是由0和1組成的。至于每個個體和解的對應關系,后面詳述。
NP = 50;%種群個體數量
L = 20;%個體編碼長度
PC = 0.8;%交叉概率
PB = 0.1;%變異概率
G = 100;%最大迭代次數
up = 10;%上限
down = 0;%下限
initial_group = randi([0,1],NP, L);%初始化種群3)計算種群適應度
? ? ? ? 計算種群適應度,就是要得到在當代的種群中,每個個體對環境的適應度,環境適應度高的個體我們保留并遺傳至下一代,適應度低的個體我們就淘汰。在此問題中我們要做的就是得到每個個體接近最大值的程度,因此我們要分析如何來設計這個適應度函數。從某種程度上說,適應度函數的設計是影響遺傳算法解決實際問題效果的核心環節。某些地方也將適應度函數稱為評價函數,即用于評價群體中個體的優劣。適應度函數也是實際問題與遺傳算法相關聯的關鍵數學模型,在此問題中,我們直接給出了一個數學模型,分析時比較簡單,但在許多實際問題中需要我們自己去建立一個合理的數學模型,這也是用遺傳算法解決實際問題的難點所在。
? ? ? ?在本問題中,我們的目的是求函數的最大值(x,y),并給出了函數公式,因此我們可以直接采用原函數作為適應度函數,將個體帶入函數中,得到的值越大,說明個體適應度越高,簡單且直觀。
function result = fitnessFun(x)
result = x + 10 * sin(4*x) + 7 * cos(3*x);
end? ? ? ?而我們在具體實現時還需要做一些處理。 首先是將群體中的個體轉換為適應度函數的輸入值,我們初始化得到的群體是一群使用二進制編碼的個體,并不是直觀的函數輸入值,所以我們首先需要將二進制編碼的個體轉換為十進制數,并將這群個體限制在給定的求值范圍內,這樣就得到了適應度函數可用的輸入值,具體代碼如下:
U = initial_group(i,:);
value = 0;
for j = 1:Lvalue = U(j)*2^(j-1) + value;
end
x(i) = down + value * (up - down)/(2^L - 1);%將編碼轉換為函數輸入值? ? ? ?然后,我們將轉換后的個體帶入適應度函數中,就可以得到每個個體的適應度值。此處對適應度值進行了歸一化處理,將適應度控制在0到1之間,便于后續處理。
Fit = fitnessFun(x);maxFit = max(Fit);%最大適應度值minFit = min(Fit);%最小適應度值inde_maxFit = find(Fit == maxFit);%適應度最大的個體所在位置,可能有多個值best_unit = initial_group(inde_maxFit(1,1),:);%當代中最優個體best_unitV = x(inde_maxFit(1,1));%該最優個體對應的值Fit = (Fit - minFit)/(maxFit - minFit);%歸一化適應度值,限制在0到1之間4)遺傳操作
? ? ? ?以下開始進行進化操作,首先是進行遺傳,即根據當代種群的適應度值選擇哪些個體可以被遺傳到下一代。常用的遺傳操作方法是輪盤賭方式,具體實現代碼如下所示。輪盤賭方式就是將個體的概率按大小成比例按順序分布在圓盤上,圓盤扇形區域的大小反映了個體概率大小。當轉動輪盤時,指針最后指向的區域對應個體就是選中的個體。由此可知,個體概率越大,被選中的概率就越大。
? ? ? ?下述代碼中,前兩行是將適應度值轉化為概率值。cumsum函數將概率值進行逐項連續累加,作為輪盤賭的概率值。while循環中執行了輪盤賭操作,總共執行了NP(50)次。采用輪盤賭操作后,適應度高的個體被遺傳到下一代的概率大,且同一個個體存在被多次遺傳到下一代的可能。通過遺傳操作后,新的種群數量與上一代個體數量保持一致。
sum_fit = sum(Fit);
fitvalue = Fit./sum_fit;
fitvalue = cumsum(fitvalue);%對向量fitvalue進行逐項累加,返回一個向量如:1 2 3,返回1 3 6
ms = sort(rand(NP,1));%生成一組隨機向量,并按從小到大排序
inde_fit = 1;
inde_newUnit = 1;
while inde_newUnit <= NP%執行輪盤賭操作,上一代中同一個個體存在被多次遺傳至下一代的可能if(ms(inde_newUnit)) < fitvalue(inde_fit)new_group(inde_newUnit,:) = initial_group(inde_fit,:);%復制個體,直接遺傳至下一代inde_newUnit = inde_newUnit + 1;elseinde_fit = inde_fit +1;end
end5)基因交叉操作
? ? ? ?交叉操作是指在上述新產生的子代群體中,選擇兩個個體,對這兩個個體對應位置的基因進行交換。具體實現代碼如下,我們直接依次選取相鄰兩個個體進行交叉操作。p是隨機生成的一個隨機數,通過與PC比較用于判斷是否要執行交叉操作。q是隨機生成的一個長度為L的0和1的向量。這個向量的作用是用于實現隨機選擇需要交叉的位置。此處我們將元素1對應的位置進行交叉。向量q保證了我們執行交叉時,交叉的位置和基因數量的隨機性。
for i = 1:2:NP%在相鄰兩個個體之間執行交叉操作p = rand;%產生一個隨機數if p < PCq = randi([0,1],1,L);for j = 1:Lif q(j) == 1temp = new_group(i+1, j);new_group(i+1, j) = new_group(i, j);new_group(i, j) = temp;endendendend6)變異操作
? ? ? ? 變異就是將一個個體中某些位置的基因進行修改,對于二進制編碼的個體而言,就是將部分位置的編碼元素取反。具體實現如下,while循環表征了執行變異次數的隨機性,inde_varUnit表征了執行變異個體的隨機性,for循環表征了執行變異基因的位置和數量的隨機性。
i = 1;while i <= round(NP*PB)inde_varUnit = randi([1,NP]);%隨機指定需要變異的個體for j = 1:round(L*PB)inde_varD = randi([1,L]);%隨機指定需要變異的基因位置new_group(inde_varUnit, inde_varD) = ~new_group(inde_varUnit, inde_varD);%取反即可endi= i + 1;end三、計算結果
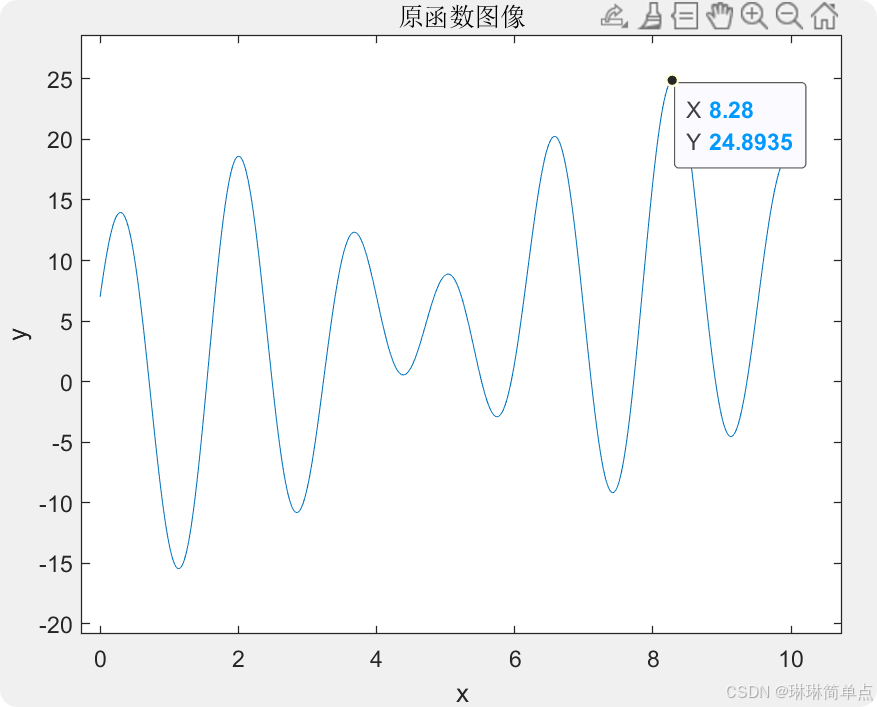
在本實例中,函數的實際圖像如下,函數的最大值約為(8.28,24.8935)。
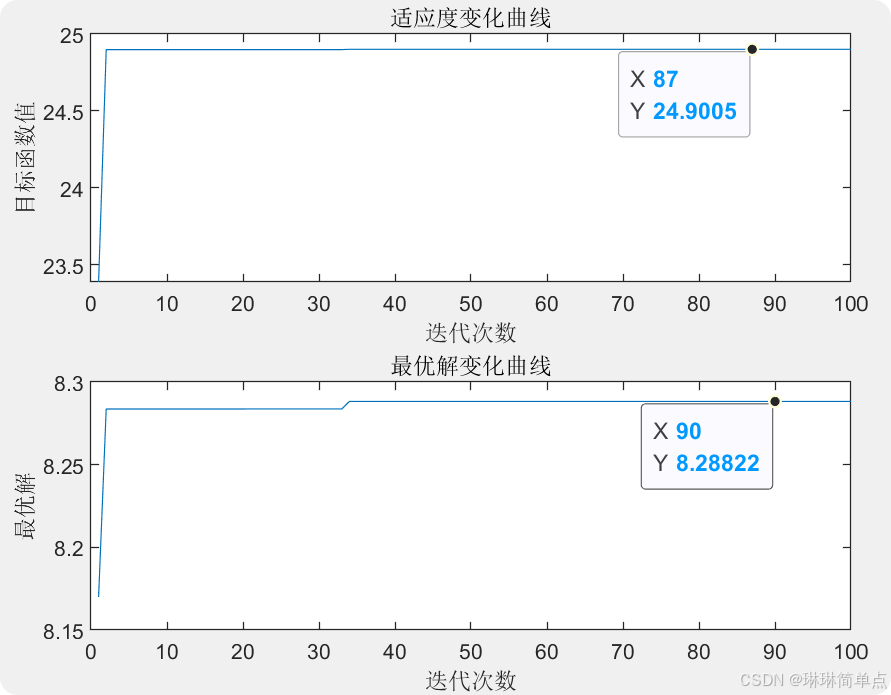
采用遺傳算法求解過程如下,得到的最優解為(8.28822,24.9005),相差很小。?參考源代碼實現。
四、總結?
? ? ? ? 本文詳細講述了經典遺傳算法的思想和典型案例實現思路。遺傳算法從一群初始解中去尋找最優解,并在迭代過程中不斷優化這個解群,其優化方法是大概率繼承前一代中最優的解,并對新的解群進行交叉、變異操作,以產生出新的解。在此過程中有兩個關鍵環節,一是解的適應度函數模型,這個是連接遺傳算法和實際問題的紐帶,是我們分析實際問題是否適用遺傳算法的關鍵;二是解的優化,從上述過程中我們可知,解的優化在交叉和變異,只有這兩步才會在原有解的基礎上產生出新的解,而這兩步操作充滿了隨機性。其中交叉的概率我們設置得比較大,因為交叉后產生的新解大概率不會與原解存在較大的差異,避免新的解呈現大幅度雜亂無序的變化。而變異操作我們設置的概率很小,且在執行次數、變異位置和數量上都引入了變異概率。這是因為變異操作針對單個個體,一個編碼位置的突變可能會導致出現一個異常偏離群體的個體,我們自然不能允許這樣的個體在群體中大量出現,但是我們又不能杜絕這樣的個體出現,因為沒有異常偏離群體的個體,我們可能會丟失可能存在的其他最優解,而陷入局部最優中,變異操作在一定程度上可以避免這樣的情況。
? ? ? ? 從本文實例中我們還可知,遺傳算法的初始解群體對算法收斂影響很大。本例中,我們限定了所有解的范圍,算法收斂速度很快,如果我們不限定范圍,或者我們將初始解群體限制在[0,5],可想而知我們可能得不到最優解,或陷入局部最優中。遺傳算法提供的是一種求解最優解的思想,而不是一種固定的模式方法,套用模式只會限制它的應用。因此具體問題要具體分析,我們要盡可能在初始化群體時確保最優解在群體囊括的包絡內,輪盤賭的遺傳方式是否合適,是否需要繼承一些適應度小的個體,變異的概率是否需要大一些,以確保群體的多樣性等,這些都是在分析實際問題時需要考慮的。通常情況下,如果我們無法限定解的范圍,也無法確定適應度函數的趨勢,那么使用遺傳算法求解也是不合適的。比如在此例中,不限定解的范圍,在整個實數域我們是無法求解的。
(第2版) 學習筆記 07.光照)

)






![[JAVAEE]HTTP協議(2.0)](http://pic.xiahunao.cn/[JAVAEE]HTTP協議(2.0))









