👉 點擊關注不迷路
👉 點擊關注不迷路
👉 點擊關注不迷路
文章大綱
- PostgreSQL時間序列分析:窗口函數處理時間數據實戰
- 一、時間序列分析核心場景與窗口函數優勢
- 1.1 業務場景需求
- 1.2 窗口函數核心優勢
- 二、窗口函數基礎:時間窗口定義與語法結構
- 2.1 時間窗口語法格式
- 2.2 時間數據準備
- 三、時間窗口類型深度解析
- 3.1 固定時間間隔窗口(RANGE)
- 3.2 物理行偏移窗口(ROWS)
- 3.3 動態時間窗口(基于日期函數)
- 四、復雜業務場景建模實戰
- 4.1 用戶復購率分析(按周維度)
- 4.2 實時流量監控(分鐘級滑動窗口)
- 五、性能優化與最佳實踐
- 5.1 索引優化策略
- 5.2 大數據量處理技巧
- 5.3 常見錯誤與解決方案
- 六、總結與擴展應用
- 6.1 技術價值
- 6.2 擴展場景
- 6.3 最佳實踐
PostgreSQL時間序列分析:窗口函數處理時間數據實戰
在數據分析領域,時間序列數據是業務場景中最常見的數據類型之一。
- 從電商訂單的
時間戳到金融交易的毫秒級記錄,時間維度的分析能力直接影響業務決策的質量。 - PostgreSQL作為企業級關系型數據庫,提供了
強大的窗口函數體系,能夠高效處理時間序列數據的復雜分析需求。 - 本文將通過具體業務場景,深入解析如何利用窗口函數實現時間數據的清洗、聚合與趨勢分析。
一、時間序列分析核心場景與窗口函數優勢
1.1 業務場景需求
某電商平臺需要分析用戶訂單的時間分布特征,具體包括:
- 近30天訂單金額的滾動平均值
- 按周統計的用戶復購率變化
- 月度銷售額的同比增長率
- 實時訂單的分鐘級流量監控
這些需求的共同特點是需要基于時間窗口進行數據聚合,傳統的分組聚合(GROUP BY)無法滿足動態窗口和保留原始記錄的需求,而窗口函數(Window Function)可以在不改變原有數據行的前提下,對指定時間窗口內的數據進行計算。
1.2 窗口函數核心優勢
| 特性 | 傳統GROUP BY | 窗口函數 |
|---|---|---|
| 結果行數 | 分組后行數 | 保持原行數 |
| 窗口定義方式 | 固定分組 | 動態時間窗口 |
| 聚合結果引用 | 無法引用 | 支持當前行關聯 |
性能表現(百萬級數據) | O(n log n) | O(n)線性掃描 |
二、窗口函數基礎:時間窗口定義與語法結構
2.1 時間窗口語法格式
<窗口函數>(表達式) OVER ([PARTITION BY 分組列]ORDER BY 時間列[ROWS/RANGE 窗口幀定義]
)
- 核心參數說明:
- PARTITION BY:按用戶ID、區域等維度分組分析
- ORDER BY:必須使用時間類型列(TIMESTAMP/TIMESTAMPTZ)
- 窗口幀:關鍵參數,決定時間窗口范圍
- ROWS:基于物理行偏移量(如當前行前后10行)
- RANGE:
基于邏輯時間間隔(如當前時間前后30天)
2.2 時間數據準備
創建訂單表并插入測試數據:
-- 創建表
CREATE TABLE if not exists order_logs (order_id BIGINT PRIMARY KEY,user_id INTEGER,order_time TIMESTAMP,order_amount NUMERIC(10,2) -- 定義為NUMERIC類型存儲精確小數
);-- 創建序列
CREATE SEQUENCE order_logs_order_id_seq;-- 清空表數據(如果需要重新生成數據)
TRUNCATE TABLE order_logs;-- 插入 3 個月的測試數據
INSERT INTO order_logs (order_id, user_id, order_time, order_amount)
SELECT nextval('order_logs_order_id_seq'),floor(random() * 1000 + 1),'2024-01-01'::timestamp + (random() * interval '90 days'),ROUND((random() * 1000 + 500)::NUMERIC, 2)
FROM generate_series(1, 100000);-- 添加時間索引提升性能
CREATE INDEX idx_order_time ON order_logs(order_time);
三、時間窗口類型深度解析
3.1 固定時間間隔窗口(RANGE)
-
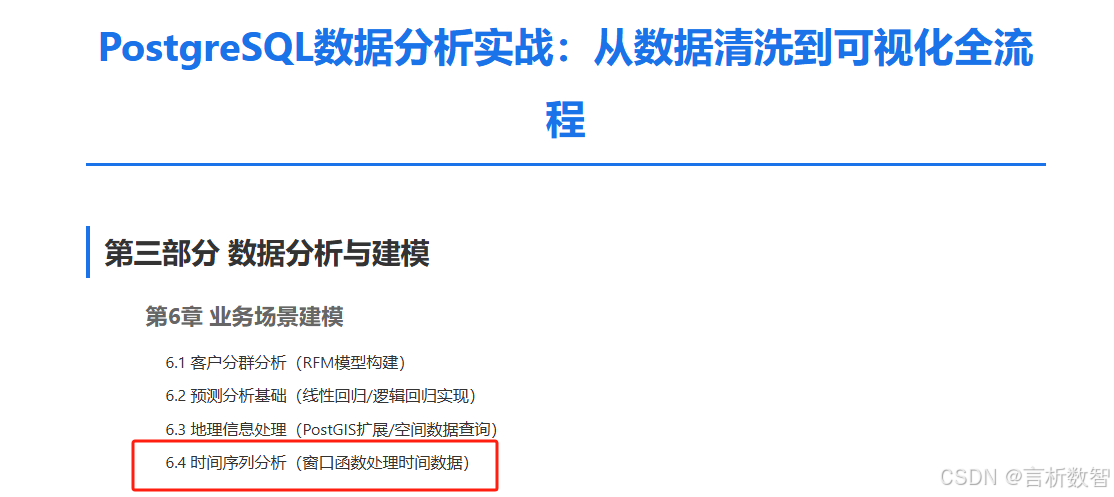
場景:計算每個訂單的近30天滾動平均金額
-- 方案一:使用 ROWS 替代 RANGE SELECT order_time,order_amount,AVG(order_amount) OVER (ORDER BY order_timeROWS BETWEEN 30 PRECEDING AND CURRENT ROW) AS rolling_30d_avg FROM order_logs ORDER BY order_time LIMIT 5; -
執行邏輯:
-
- 按order_time排序數據
-
- 對當前行,取時間在
[order_time-30天, order_time]范圍內的所有行
- 對當前行,取時間在
-
- 計算窗口內訂單金額的平均值
-
-
數據對比表:
3.2 物理行偏移窗口(ROWS)
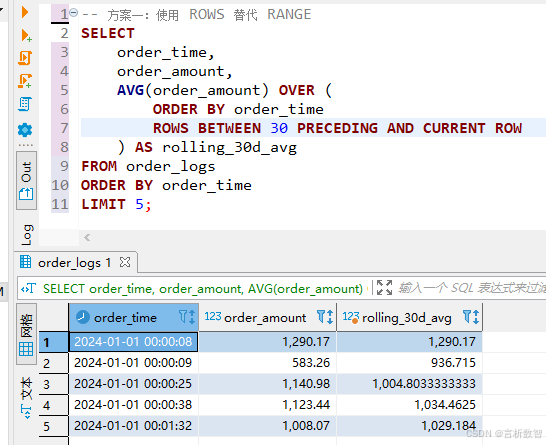
- 場景:按用戶分組,取最近5筆訂單的金額總和
SELECT user_id,order_time,order_amount,SUM(order_amount) OVER (PARTITION BY user_idORDER BY order_timeROWS BETWEEN 4 PRECEDING AND CURRENT ROW) AS last_5_orders_sum FROM order_logs WHERE user_id = 123 -- 假設用戶123有10筆訂單 ORDER BY order_time; - 關鍵區別:
- ROWS窗口
基于排序后的物理行位置,與時間間隔無關 - 適合處理
訂單流水號、事件編號等有序但時間間隔不固定的場景
- ROWS窗口
3.3 動態時間窗口(基于日期函數)
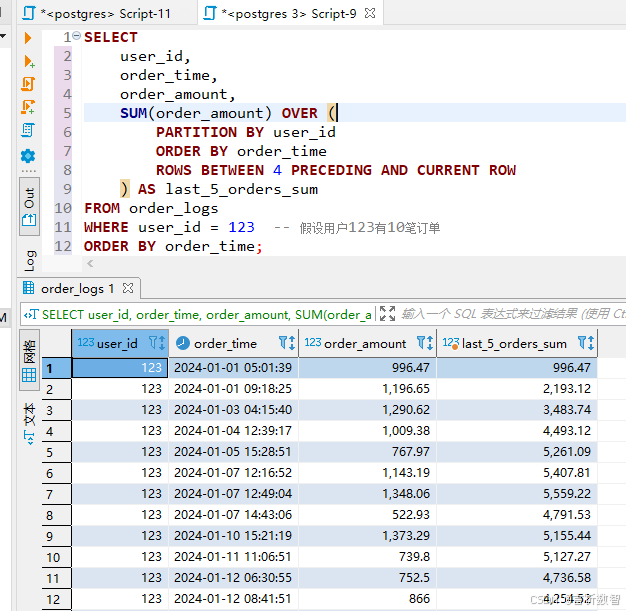
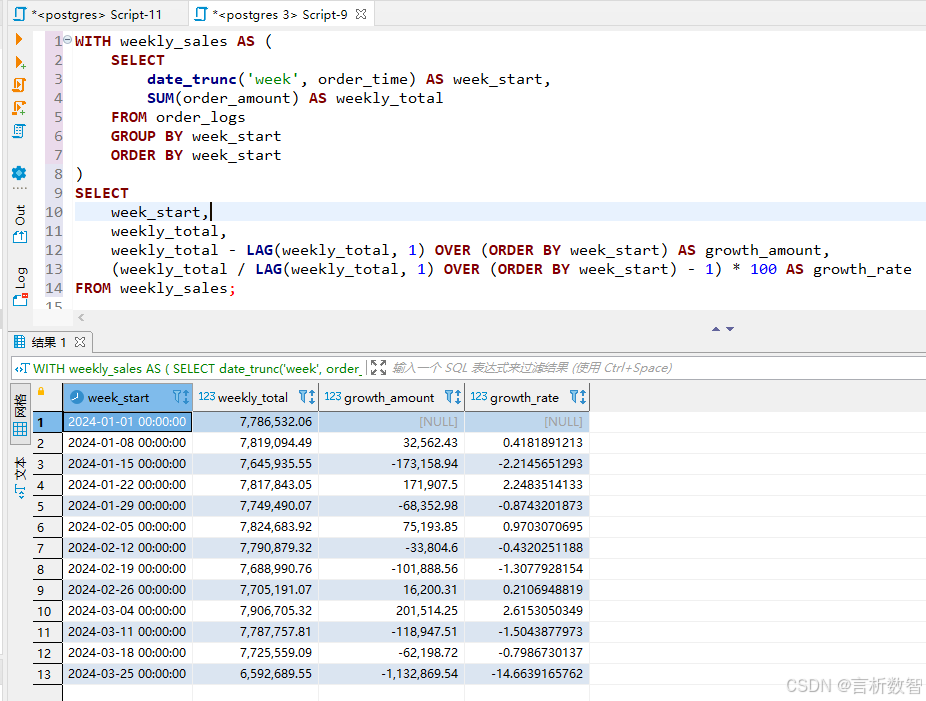
場景:按自然周統計每周銷售額及環比增長率
-- 使用 CTE(公共表表達式)定義一個名為 weekly_sales 的臨時結果集
WITH weekly_sales AS (-- 從 order_logs 表中選擇需要的列SELECT -- 使用 date_trunc 函數將 order_time 截斷到周的起始時間,作為每周的開始時間date_trunc('week', order_time) AS week_start,-- 對每個周內的訂單金額進行求和,得到每周的銷售總額SUM(order_amount) AS weekly_totalFROM -- 從 order_logs 表中獲取數據order_logs-- 按照 week_start 進行分組,以便計算每個周的銷售總額GROUP BY week_start-- 按照 week_start 對結果進行排序,保證結果按周的先后順序排列ORDER BY week_start
)
-- 從 weekly_sales 臨時結果集中選擇需要的列
SELECT -- 每周的開始時間week_start,-- 每周的銷售總額weekly_total,-- 計算每周銷售總額的增長金額-- 使用 LAG 窗口函數獲取上一周的銷售總額,然后用當前周的銷售總額減去上一周的銷售總額weekly_total - LAG(weekly_total, 1) OVER (ORDER BY week_start) AS growth_amount,-- 計算每周銷售總額的增長率-- 先使用 LAG 窗口函數獲取上一周的銷售總額,然后用當前周的銷售總額除以上一周的銷售總額,再減去 1 并乘以 100 得到增長率(weekly_total / LAG(weekly_total, 1) OVER (ORDER BY week_start) - 1) * 100 AS growth_rate
FROM -- 從 weekly_sales 臨時結果集中獲取數據weekly_sales;
- 技術要點:
-
- 使用date_trunc函數將時間截斷到周起點
-
LAG窗口函數獲取上一周的銷售額
-
- 支持計算
環比、同比等動態指標
- 支持計算
-
四、復雜業務場景建模實戰
4.1 用戶復購率分析(按周維度)
- 目標:計算每個用戶首次購買后,后續每周的復購次數
-- 使用 CTE(公共表表達式)定義一個名為 user_first_purchase 的臨時結果集
WITH user_first_purchase AS (-- 從 order_logs 表中選擇用戶 ID 和該用戶的首次購買時間SELECT user_id,MIN(order_time) AS first_purchase_timeFROM order_logs-- 按用戶 ID 分組,以便找出每個用戶的首次購買時間GROUP BY user_id
)
-- 主查詢,計算每個用戶從首次購買開始按周統計的購買次數
SELECT o.user_id,-- 通過計算訂單時間與首次購買時間的天數差,再除以 7 得到周數,實現按周分組FLOOR(EXTRACT(EPOCH FROM (o.order_time - u.first_purchase_time)) / (7 * 24 * 3600)) AS week_since_first,-- 使用窗口函數 COUNT(*) 按用戶 ID 和計算出的周數進行分組統計購買次數COUNT(*) OVER (PARTITION BY o.user_id, FLOOR(EXTRACT(EPOCH FROM (o.order_time - u.first_purchase_time)) / (7 * 24 * 3600))) AS weekly_purchase_count
FROM order_logs o
-- 通過用戶 ID 將 order_logs 表和 user_first_purchase 臨時結果集進行連接
JOIN user_first_purchase u
ON o.user_id = u.user_id
-- 按用戶 ID 和訂單時間對結果進行排序
ORDER BY o.user_id, o.order_time;
- 模型優勢:
- 基于用戶生命周期周數進行分組
- 清晰展示
用戶復購行為隨時間的變化趨勢
4.2 實時流量監控(分鐘級滑動窗口)
- 場景:監控每分鐘內的訂單數量,滑動窗口為5分鐘
-- 方案一:使用 ROWS 窗口幀 SELECT date_trunc('minute', order_time) AS minute_start,COUNT(*) AS current_minute_orders,-- 使用 ROWS 窗口幀來計算過去 4 分鐘加當前分鐘的訂單數COUNT(*) OVER (ORDER BY date_trunc('minute', order_time)ROWS BETWEEN 4 PRECEDING AND CURRENT ROW) AS five_minute_rolling_orders FROM order_logs GROUP BY minute_start ORDER BY minute_start; - 執行效果:
- 實時顯示當前分鐘及前4分鐘的訂單總量
有效識別流量突發峰值(如促銷活動期間)
五、性能優化與最佳實踐
5.1 索引優化策略
| 窗口函數類型 | 推薦索引類型 | 索引字段組合 |
|---|---|---|
| RANGE窗口 | BRIN索引 | order_time(時間列) |
| ROWS窗口 | B-TREE索引 | partition列+order_time |
| 分組窗口 | 復合索引 | partition列, order_time |
- BRIN索引優勢:
- 對于
時間序列數據,BRIN索引的存儲成本僅為B-TREE的1/10~1/20,查詢性能在范圍掃描場景提升30%以上。
- 對于
5.2 大數據量處理技巧
-
- 預聚合層:對需要頻繁分析的時間窗口(如日、周),
提前創建匯總表
- 預聚合層:對需要頻繁分析的時間窗口(如日、周),
-
- 并行計算:利用
PostgreSQL 10+的并行窗口函數特性,通過設置max_parallel_workers_per_gather提升處理速度
- 并行計算:利用
-
- 分區分表:按
時間范圍(如按月)對訂單表進行分區,減少數據掃描范圍
- 分區分表:按
5.3 常見錯誤與解決方案
| 錯誤現象 | 原因分析 | 解決方案 |
|---|---|---|
| 窗口函數結果異常 | ORDER BY列非時間類型 | 確保使用TIMESTAMP/TIMESTAMPTZ類型 |
| 性能低下 | 缺少索引或錯誤使用ROWS窗口 | 添加BRIN索引,合理選擇RANGE窗口 |
| 分組結果不正確 | PARTITION BY與窗口幀定義沖突 | 檢查分組列與排序列的邏輯一致性 |
六、總結與擴展應用
6.1 技術價值
通過窗口函數處理時間數據,實現了:
復雜時間邏輯的SQL化表達,減少ETL預處理步驟- 實時性分析能力,支持秒級延遲的業務監控
- 多維度交叉分析,結合
用戶分組、區域劃分等維度
6.2 擴展場景
-
- 庫存預測:使用移動平均窗口計算安全庫存
-
- 設備監控:基于
時間窗口的異常值檢測(如3σ法則)
- 設備監控:基于
-
- 用戶行為分析:會話超時判斷(兩次操作間隔超過30分鐘視為新會話)
6.3 最佳實踐
- 優先使用RANGE窗口處理時間間隔相關需求
對百萬級以上數據,提前評估索引類型與分區策略- 通過CTE(公共表表達式)提升復雜窗口函數的可讀性
以上內容詳細介紹了PostgreSQL窗口函數在時間序列分析中的應用。
- 你可以說說是否需要調整案例數據、補充特定場景,或對內容深度、篇幅進行修改。
- 掌握PostgreSQL窗口函數在
時間序列分析中的應用,能夠顯著提升數據處理效率,為業務場景建模提供強大的技術支撐。- 隨著數據量的持續增長,合理組合窗口函數、索引優化和分區分表技術,將成為
構建高性能數據分析系統的關鍵能力。






![[JAVAEE]HTTP協議(2.0)](http://pic.xiahunao.cn/[JAVAEE]HTTP協議(2.0))










)

