最近在做個類似的項目,有用到這方面的知識,順便做一些記錄和筆記吧,希望能幫到大家了解智能體應用開發
目錄
引言
AI原生應用的興起
智能體在AI中的角色
實現原理詳解
機器學習基礎
數據管理與關聯數據庫
數據結構
Embedding
檢索方案
部分實踐代碼
強化學習與決策制定
首先,我們需要定義MDP的幾個關鍵元素:
智能體的設計與開發
需求分析與場景定義
智能體架構設計
開發工具與平臺
零代碼/低代碼開發平臺
開源框架與庫
引言
AI原生應用的興起
隨著人工智能技術的飛速發展,AI原生應用逐漸成為創新的前沿。這些應用從設計之初就將AI技術作為核心,與傳統的應用程序相比,它們能夠提供更加智能化、個性化的服務。AI原生應用正在改變我們與技術的互動方式,從簡單的工具使用轉變為與智能助手的協作,這些助手能夠理解我們的需求,預測我們的行動,并提供定制化的解決方案。
智能體在AI中的角色
智能體(Agent)是AI領域中一個關鍵的概念,它指的是能夠在特定環境中自主運作并執行任務的軟件實體。智能體不僅可以感知其環境,還能做出決策并采取行動以達成目標。在AI原生應用中,智能體充當著用戶與復雜AI系統之間的橋梁,它們使得AI技術更加易于訪問和使用。
實現原理詳解
機器學習基礎
機器學習是智能體實現智能行為的關鍵技術之一。它使智能體能夠從數據中學習并改進其性能。
- 監督學習:智能體通過已標記的訓練數據學習預測或決策任務。
- 非監督學習:智能體在沒有明確標記的數據中尋找模式和結構。
- 強化學習:智能體通過與環境的交互學習最優行為策略以最大化某種累積獎勵。
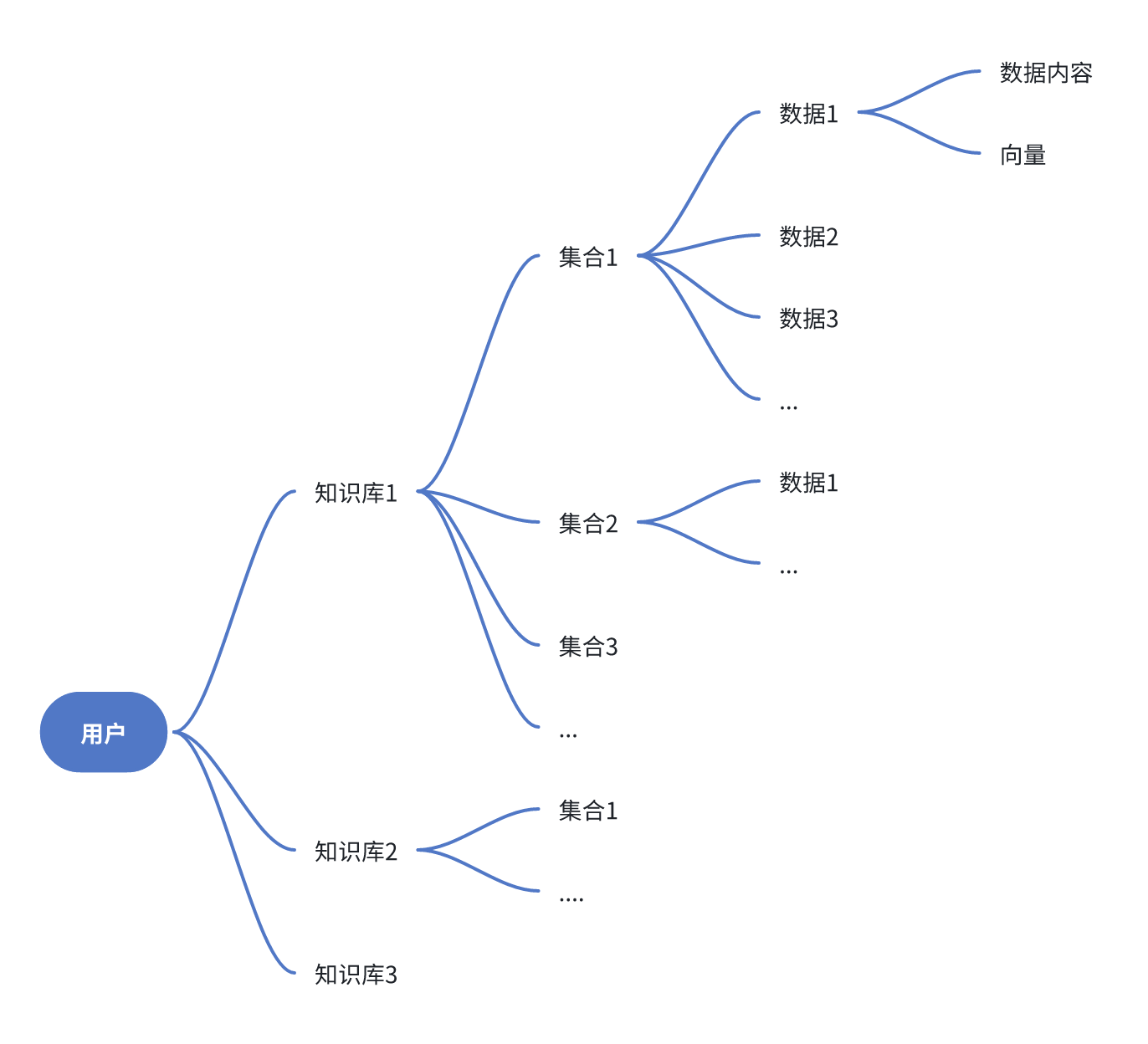
數據管理與關聯數據庫
智能體需要有效的數據管理來支持其學習和決策過程。
- 數據庫的類型與選擇:根據智能體的需求選擇合適的數據庫系統,如關系型數據庫、NoSQL數據庫等。
? - 關聯規則與數據挖掘:使用數據挖掘技術發現數據中的關聯規則,幫助智能體做出更好的決策。

數據結構
Embedding
人類的文字、圖片、視頻等媒介是無法直接被計算機理解的,要想讓計算機理解兩段文字是否有相似性、相關性,通常需要將它們轉成計算機可以理解的語言,向量是其中的一種方式。
向量可以簡單理解為一個數字數組,兩個向量之間可以通過數學公式得出一個距離,距離越小代表兩個向量的相似度越大。從而映射到文字、圖片、視頻等媒介上,可以用來判斷兩個媒介之間的相似度。向量搜索便是利用了這個原理。
而由于文字是有多種類型,并且擁有成千上萬種組合方式,因此在轉成向量進行相似度匹配時,很難保障其精確性。在向量方案構建的知識庫中,通常使用topk召回的方式,也就是查找前k個最相似的內容,丟給大模型去做更進一步的語義判斷、邏輯推理和歸納總結,從而實現知識庫問答。因此,在知識庫問答中,向量搜索的環節是最為重要的。
影響向量搜索精度的因素非常多,主要包括:向量模型的質量、數據的質量(長度,完整性,多樣性)、檢索器的精度(速度與精度之間的取舍)。與數據質量對應的就是檢索詞的質量。
檢索器的精度比較容易解決,向量模型的訓練略復雜,因此數據和檢索詞質量優化成了一個重要的環節。
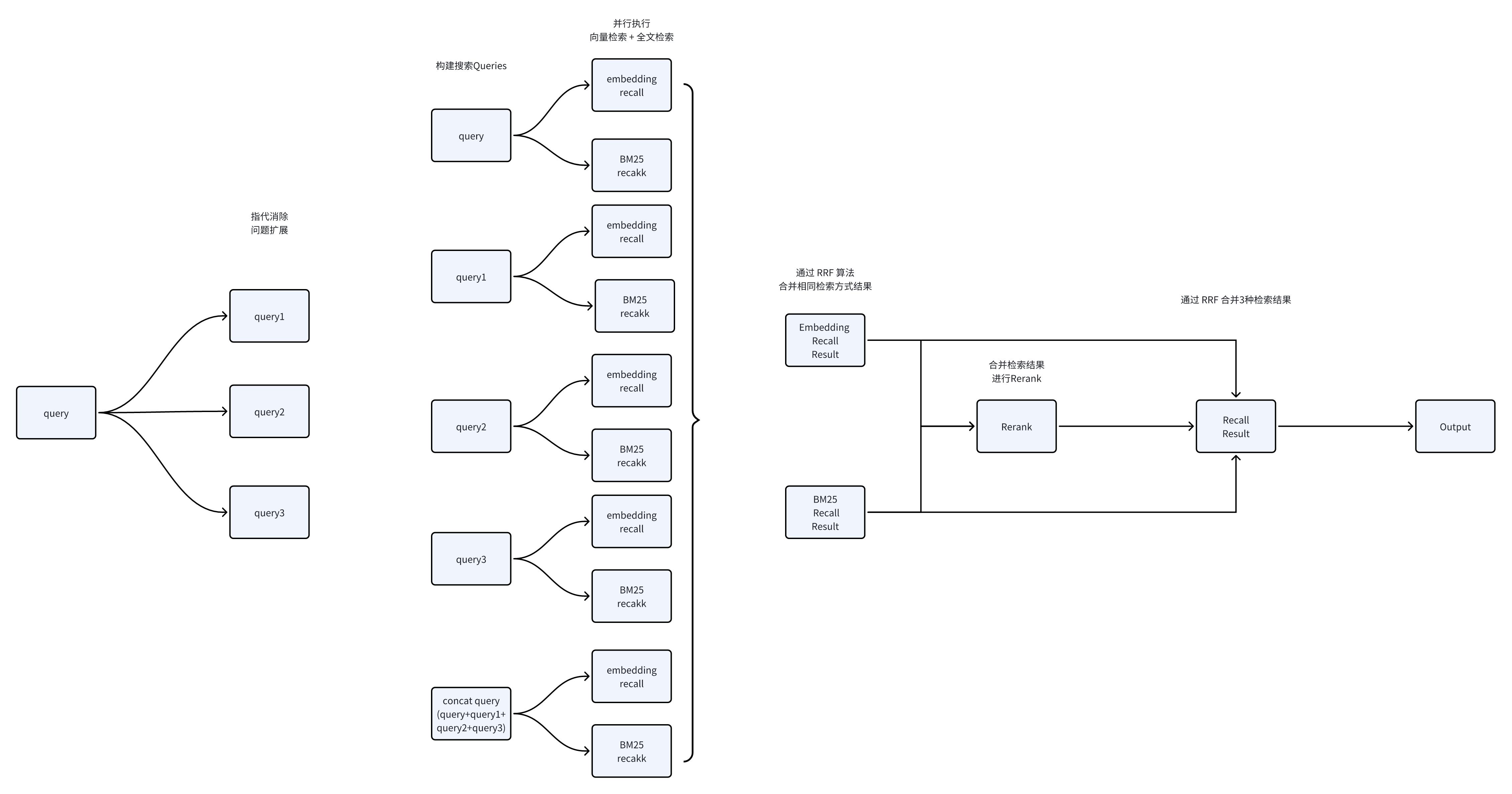
檢索方案
- 通過改進問題處理來實現消除指代和擴展問題,這將增強對話的連貫性以及語義的深度。
- 使用Concat查詢技術來提升連續對話的重排序過程,從而提高排序的準確性。
- 利用RRF合并策略,整合多個來源的搜索結果,以提升整體的搜索效果。
- 通過重排序機制,對結果進行再次排序,以提升搜索結果的精確度。
部分實踐代碼
import re# 假設我們有以下對話歷史和問題
dialog_history = ["今天天氣怎么樣?", "明天會下雨嗎?", "北京的天氣如何?"]
current_question = "北京明天的天氣怎么樣?"# 指代消除和問題擴展
def expand_question(question, history):# 這里簡單用正則表達式匹配和替換,實際情況可能需要更復雜的NLP處理for q in history:question = re.sub(r"\b北京\b", q, question, flags=re.IGNORECASE)return questionexpanded_question = expand_question(current_question, dialog_history)# Concat查詢,假設我們有兩個不同的搜索引擎返回的結果
def concat_query(expanded_question):# 這里假設search_engine_1和search_engine_2是兩個搜索函數results_1 = search_engine_1(expanded_question)results_2 = search_engine_2(expanded_question)# 合并結果return results_1 + results_2concatenated_results = concat_query(expanded_question)# RRF合并方式,這里我們簡單地使用取并集的方式
def rrf_merge(results):# 假設result是一個包含多個搜索結果的列表merged_results = list(set(results)) # 使用set去重return merged_resultsrrf_results = rrf_merge(concatenated_results)# Rerank二次排序,這里我們簡單地根據結果的相關性進行排序
def rerank(results):# 這里假設我們有一個函數來評估結果的相關性ranked_results = sorted(results, key=lambda x: relevance_score(x), reverse=True)return ranked_resultsreranked_results = rerank(rrf_results)# 假設的搜索函數和相關性評分函數
def search_engine_1(question):# 這里只是一個示例,實際中會調用搜索引擎APIreturn ["晴", "多云", "有雨"]def search_engine_2(question):# 這里只是一個示例,實際中會調用另一個搜索引擎APIreturn ["有雨", "晴轉多云"]def relevance_score(result):# 這里只是一個示例,實際中會根據結果的相關性進行評分return len(result)# 輸出最終結果
print("Expanded Question:", expanded_question)
print("Reranked Results:", reranked_results)強化學習與決策制定
強化學習是智能體在動態環境中做出決策的關鍵。
- 馬爾可夫決策過程(MDP):提供了一種數學框架來分析決策過程。
首先,我們需要定義MDP的幾個關鍵元素:
- 狀態(States): 對話系統的狀態可以是當前對話的歷史和當前問題。
- 動作(Actions): 在重排序的上下文中,動作可能是選擇不同的排序策略或調整排序參數。
- 獎勵(Rewards): 獎勵可以是基于用戶滿意度的反饋,或者是排序后結果的相關性得分。
- 轉移概率(Transition Probabilities): 這表示在給定狀態下,采取某個動作后轉移到新狀態的概率。
import numpy as np# 假設我們有一組候選答案和它們的初始相關性得分
candidates = ["答案1", "答案2", "答案3"]
initial_scores = np.array([0.7, 0.6, 0.8])# 定義狀態轉移矩陣,這里簡化為隨機選擇動作
transition_matrix = np.random.rand(len(candidates), len(candidates))# 定義獎勵函數,這里簡化為基于初始得分的隨機獎勵
def reward_function(state, action):# 假設獎勵與初始得分成正比return initial_scores[action]# 定義MDP模型
class MDP:def __init__(self, states, actions, transition_probabilities, reward_function):self.states = statesself.actions = actionsself.transition_probabilities = transition_probabilitiesself.reward_function = reward_functiondef step(self, state, action):# 執行動作并返回獎勵和下一個狀態next_state = np.random.choice(self.states, p=self.transition_probabilities[state][action])reward = self.reward_function(state, action)return reward, next_state# 初始化MDP
mdp = MDP(states=candidates, actions=range(len(candidates)), transition_probabilities=transition_matrix, reward_function=reward_function)# 簡單的策略迭代算法
def policy_iteration(mdp, gamma=0.9, theta=1e-6):policy = {s: np.random.choice(mdp.actions) for s in mdp.states}V = {s: 0 for s in mdp.states}while True:delta = 0for s in mdp.states:v = V[s]V[s] = max([sum([mdp.transition_probabilities[s][a][i] * (mdp.reward_function(s, a) + gamma * V[i]) for i in mdp.states]) for a in mdp.actions])delta = max(delta, abs(v - V[s]))if delta < theta:breakpolicy = {s: np.argmax([sum([mdp.transition_probabilities[s][a][i] * (mdp.reward_function(s, a) + gamma * V[i]) for i in mdp.states]) for a in mdp.actions]) for s in mdp.states}return policy, V# 執行策略迭代
policy, value_function = policy_iteration(mdp)# 輸出最優策略
print("最優策略:", policy)智能體的設計與開發
需求分析與場景定義
設計和開發智能體的第一步是進行需求分析和場景定義。這一階段的目標是明確智能體需要解決的問題、它將如何與用戶或其他系統交互,以及它需要滿足的性能標準。需求分析包括但不限于:
- 用戶需求調研:了解目標用戶群體的需求和期望。
- 功能定義:列出智能體需要實現的具體功能。
- 場景模擬:設想智能體在不同情境下的應用案例。
- 性能指標:確定智能體的性能標準,如響應時間、準確性等。
智能體架構設計
智能體的架構設計是構建其內部結構和組件的過程。一個良好的架構設計能夠確保智能體的靈活性、可擴展性和可維護性。架構設計的關鍵要素包括:
- 感知模塊:負責收集環境信息。
- 決策模塊:基于感知信息和內部知識庫做出決策。
- 行動模塊:執行決策模塊的指令,與外部環境交互。
- 學習模塊:使智能體能夠從經驗中學習并優化行為。
- 通信模塊:如果需要與其他系統或智能體交互,設計通信接口。
開發工具與平臺
選擇合適的開發工具和平臺對于智能體的開發至關重要。這些工具和平臺能夠提供必要的支持,幫助開發者快速構建和測試智能體。
- 開發環境:選擇支持智能體開發的語言和開發環境,如Python、Java等。
- API和SDK:利用現有的API和SDK來加速開發過程,如語音識別、圖像處理等。
- 版本控制:使用版本控制系統,如Git,來管理代碼和協作。
零代碼/低代碼開發平臺
零代碼/低代碼開發平臺使得非技術用戶也能夠參與到智能體的開發中來。這些平臺通過可視化的拖拽界面和預定義的模板簡化了開發流程:
- 可視化編程:通過圖形界面進行編程,無需編寫代碼。
- 模板和組件:提供可重用的模板和組件,加速開發過程。
- 自動化部署:一鍵部署智能體到不同的平臺和設備。
開源框架與庫
利用開源框架和庫可以減少開發工作量,同時利用社區的力量來改進和維護智能體:
- 機器學習框架:如TensorFlow、PyTorch等,用于構建和訓練智能體的模型。
- 自然語言處理庫:如NLTK、spaCy等,提供語言處理的工具和算法。
- 強化學習庫:如OpenAI Gym、DeepMind Lab等,提供強化學習的環境和算法。
函數的用法詳解)



)

![[C/C++]_[初級]_[在Windows和macOS平臺上導出動態庫的一些思考]](http://pic.xiahunao.cn/[C/C++]_[初級]_[在Windows和macOS平臺上導出動態庫的一些思考])



)

】技巧)






