今天講講如何在GEE中做最后的精度評價。主要是因為在和許多讀者或通過交流群,或通過私聊溝通過程中,發現很多人還不是很理解在GEE中分類后精度評價的問題。
在進行評價之前,需要明晰在GEE中精度評價分為哪幾種情況。我們這里說的是兩種情況。
第一種,構建好了分類模型后,將分類模型應用于驗證樣本集,然后計算混淆矩陣;
第二種,沒有分類模型,只有分類結果圖,那么應該是將分類結果圖應用于樣本集,最后計算混淆矩陣。
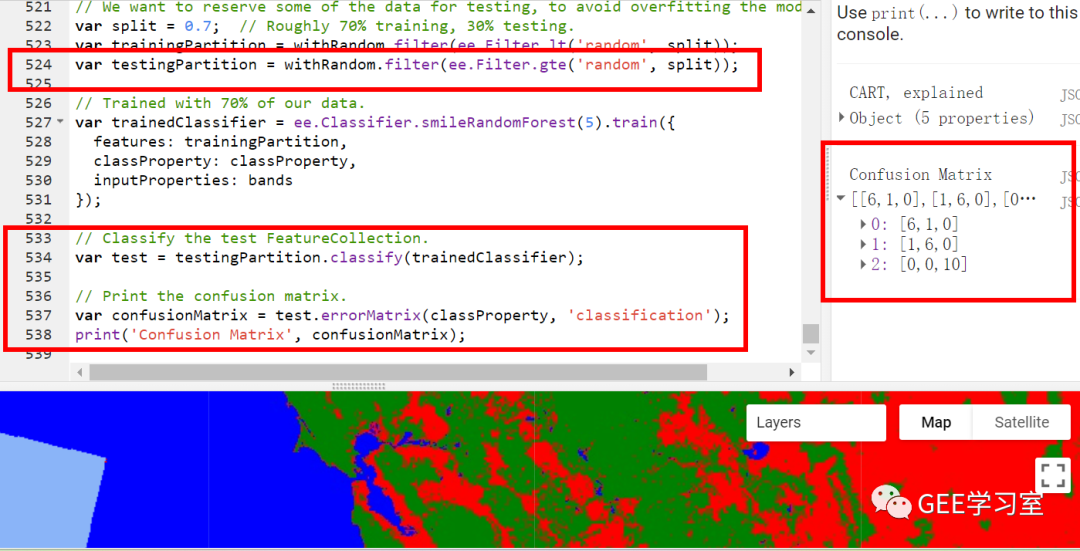
對于第一種情況,由于官方給出了有關代碼,所以大家都比較好理解,也正是這么做的,具體參見下圖。(參見代碼:https://code.earthengine.google.com/e145a3f0e88cc272c6541f4514bb3093)
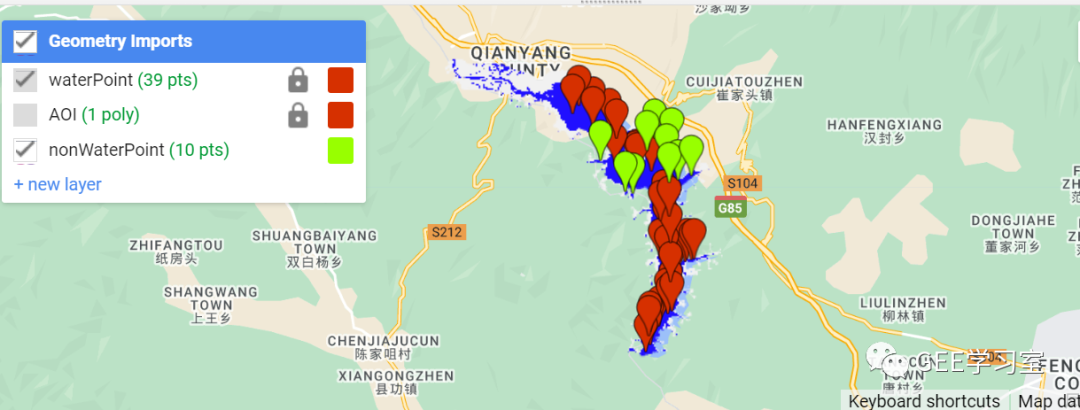
對于第二種情況,則有很多人不理解,或者還沒有完全掌握。舉個例子,下面有一張水體分類圖和驗證樣本,需要計算水體精度,該如何做呢?其實也是可以做的,最后的結果見下圖:
那么兩種方法的區別或者一致性是什么呢?這地方有個概念需要理解清楚,即精度評價針對的是測試樣本本身,而不是模型。也就是說,對于測試樣本集,我們已經構建好了標簽信息,那么接下來要做的只是找到每個樣本對應的分類標記就行。而分類標簽的獲取,可以是來源于模型,而更多的應該是直接來源于分類圖結果。
那么,對應到GEE中,測試樣本集最后會是一個FeatureCollection類,在FeatureCollection類中可以計算混淆矩陣等指標,其輸入只需要兩個不同的字段(比如樣本的屬性字段“class”和分類結果圖字段“classification”)。那么,如何獲取這兩個字段,以及成功獲取這兩個字段,就可以計算精度。
對應于第一種情況,因為模型已經構建好了,當然可以用于分類每個樣本的分類屬性,所以可以構建這兩個字段以及計算混淆矩陣的,也就是直接使用:

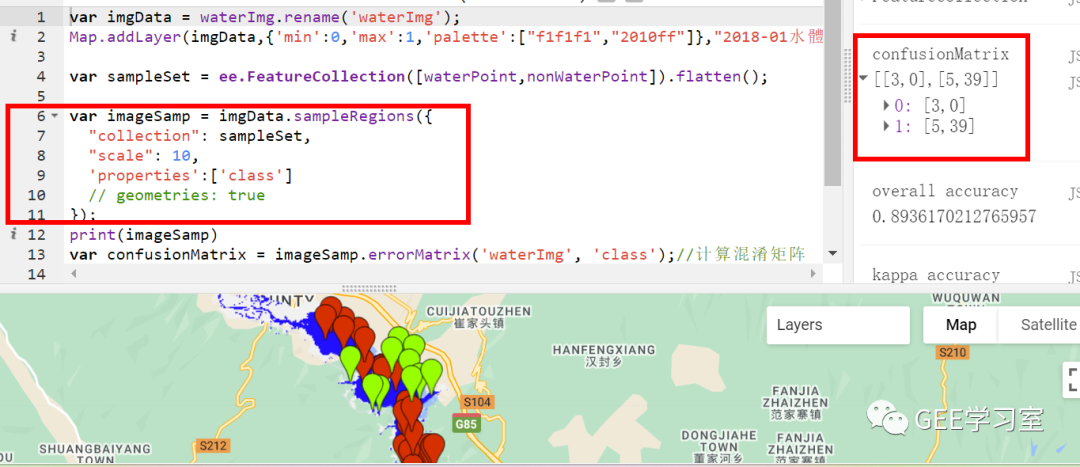
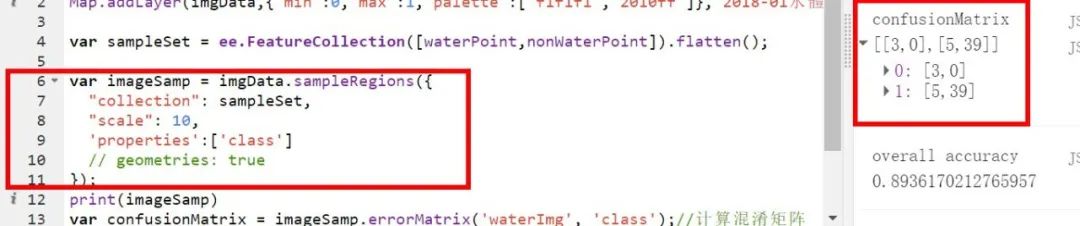
對應于第二種情況,由于沒有模型而只有分類結果圖,所以需要做的就是獲取測試樣本集對應位置的分類結果,那么在GEE中自然想到sampleRegions函數,或者類似于能夠替換sampleRegions的函數,效果如下圖:
那么,第二種方式較第一種方式有什么好處呢?
1)第二種方式使用范圍更廣泛,本質上更好,因為不再設計推理的過程;
2)第二種方案非常適合在分塊情況下的精度評價。我們知道分塊后,每一塊的測試樣本集都是不同的,但是又需要給出一個總的整體的精度評價,那么此時需要將每一塊內的測試樣本集整合起來,最后利用全局分類圖進行評價,那么此時就需要使用我們今天介紹的方法了。
今天的水體精度評價代碼如下,大家有需要的自取:
https://code.earthengine.google.com/6d2ed19fb3917832c8883ad8ab0d77e6
var imgData = waterImg.rename('waterImg');Map.addLayer(imgData,{'min':0,'max':1,'palette':["f1f1f1","2010ff"]},"2018-01水體分佈圖")var sampleSet = ee.FeatureCollection([waterPoint,nonWaterPoint]).flatten();var imageSamp = imgData.sampleRegions({"collection": sampleSet,"scale": 10,'properties':['class']// geometries: true});print(imageSamp)var confusionMatrix = imageSamp.errorMatrix('waterImg', 'class');//計算混淆矩陣print('confusionMatrix',confusionMatrix);//面板上顯示混淆矩陣print('overall accuracy', confusionMatrix.accuracy());//面板上顯示總體精度print('kappa accuracy', confusionMatrix.kappa());//面板上顯示kappa值

)

】技巧)











)



