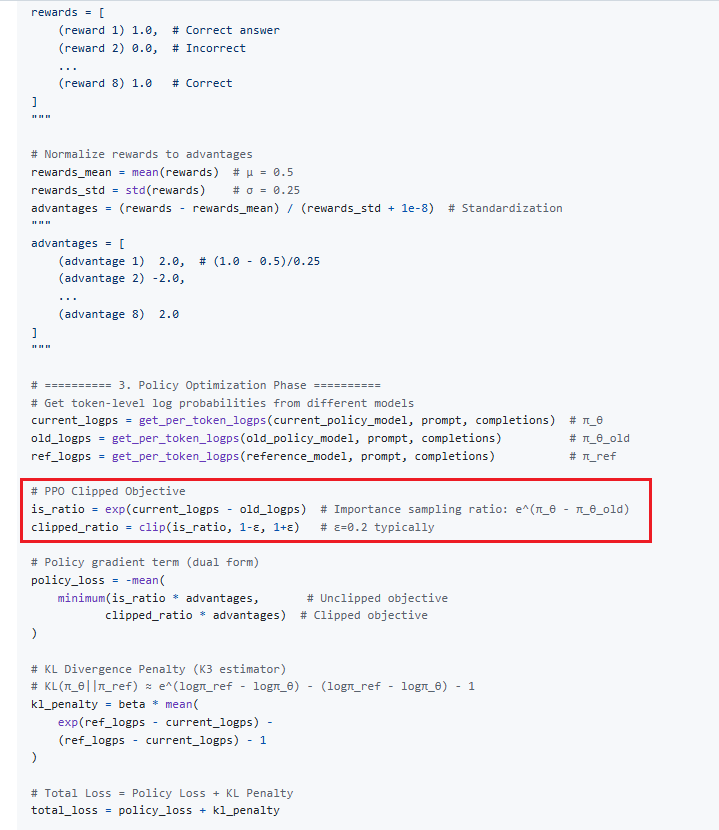
PPO 中重要性采樣
- https://github.com/modelscope/ms-swift/blob/main/docs/source/Instruction/GRPO/GetStarted/GRPO.md
- 樂,這個網頁中是的groundtruth是錯誤的(可能是為了防止抄襲)。
一些例子
0. 池塘養魚的一個例子
想象一下,你想知道一個湖里所有魚的平均重量(求期望)。
普通(均勻)采樣:你租一條小船,隨機在湖面上撒網。問題是,湖中心魚又多又大,但你隨機撒網,很可能大部分網都撒在了沒什么魚的岸邊。這樣你得撒非常多次網(采樣非常多),才能得到一個比較準確的平均值。效率低下。
重要性采樣:你是個聰明的漁夫。你知道湖中心的魚又多又大(重要區域)。所以你決定:別隨機撒網了,咱們就開著船專門去湖中心撒網!
新問題:這樣從湖中心撈上來的魚肯定比實際湖里的平均魚要重,直接算平均值會嚴重高估。
解決方案:加權(重要性權重)。當你從湖中心撈起一條大魚時,你在心里想:“這條魚確實重,但它來自一個我刻意選擇的‘高產區域’,所以它的代表性沒那么強。我得給它打個折。”
反之,如果你偶爾在岸邊撈到一條小魚,你會想:“這條魚雖然小,但它來自一個我幾乎不采樣的‘低產區域’,它能被撈上來非常難得,它的價值應該被放大。”
這個“打折”或“放大”的系數,就是 重要性權重 。通過這個權重,就能糾正你“刻意去湖中心采樣”所帶來的偏差,最終也能算出整個湖里魚的真實平均重量。
核心思想:重要性采樣允許我們故意從一個我們喜歡的、容易采樣的分布(去湖中心) 而不是從那個原始的、難以采樣的分布(整個湖面)進行抽樣。然后通過一個權重來修正兩個分布之間的差異,從而得到無偏的估計。
1. 強化學習
這是重要性采樣最經典的應用領域之一。
問題:一個機器人要用“舊策略” π_old 收集來的數據,來學習和評估一個“新策略” π_new 的好壞。如果新策略和舊策略差別很大,那么舊數據對于新策略來說就可能很不相關,直接用它訓練效果會很差甚至危險(比如新策略是“高速行駛”,而舊數據全是“低速行駛”的)。
重要性采樣的應用:我們仍然使用舊策略的數據,但在用這些數據計算新策略的收益時,給每一條數據都加上一個重要性權重:權重 = (新策略采取舊行動的概率) / (舊策略采取舊行動的概率)。
例子:舊策略 π_old 在紅燈時有 80% 的概率剎車,20% 的概率闖過去。新策略 π_new 更保守,在紅燈時有 99% 的概率剎車,1% 的概率闖過去。
如果一條舊數據是“紅燈->闖過去->發生車禍”,那么這條數據對于新策略的權重就是 (1%) / (20%) = 0.05。
這意味著,雖然“闖紅燈導致車禍”這件事本身代價很大,但因為新策略幾乎不會這么做(概率只有1%),所以這件事對新策略的影響會被大大折扣(權重0.05)。
反之,對于“紅燈->剎車->安全”的數據,權重是 (99%) / (80%) ≈ 1.24,其影響會被適當放大。
這樣,就能安全且高效地利用舊數據來優化新策略了。你提供的命令中的 --importance_sampling_level sequence 就是這個思想在 GRPO 算法中的應用。
2. 金融風險評估
問題:計算某種極端金融事件(如股市暴跌50%)發生的風險。這種事件概率極低,但后果極其嚴重。如果用普通的蒙特卡洛模擬,你可能要模擬成千上萬次甚至百萬次,才可能碰到一兩次這種極端情況,效率極低。
重要性采樣的應用:我們故意修改模擬的規則(采樣分布),讓極端事件更容易發生。比如,在模擬時故意讓股價的波動性變大。
然后,在計算風險時,為每一次模擬結果加上一個權重。這個權重就是:在真實模型下,這個結果發生的概率 / 在修改后的模型下,這個結果發生的概率。
對于那些被我們“人為放大”的暴跌事件,我們會給它一個很小的權重,因為雖然它在我們的模擬中經常發生,但在現實中其實很難發生。通過權重修正后,我們就能得到它在真實世界中的正確風險值。這樣,我們用幾千次模擬就可能達到普通蒙特卡洛需要幾百萬次模擬的精度。
3. 計算機圖形學(渲染)
問題:計算一個物體表面某一點的顏色(即它接收到的來自所有方向的光照積分)。來自光源方向的光線貢獻很大,而來自其他方向的光線貢獻很小。
重要性采樣的應用:與其均勻地向所有方向發射光線去探測,不如集中地向光源的方向發射更多光線(因為那里貢獻大)。
然后,在計算顏色時,為那些射向光源的光線賦予較低的權重(因為你發射了太多條了),為那些射向黑暗角落的光線賦予較高的權重(因為你發射的很少)。這樣就可以用更少的光線(更快的渲染速度)得到更清晰、噪聲更少的圖像。




——微調Transformer語言模型進行回歸分析)

——系統包管理)







)




)