一、人類反饋的強化學習(RLHF)
微調的目標是通過指令,包括路徑方法,進一步訓練你的模型,使他們更好地理解人類的提示,并生成更像人類的回應。
RLHF:使用人類反饋微調型語言模型,使用強化學習,使用人類反饋微調LLM,從而得到一個更符合人類偏好的模型。
Reinforcement Learning(強化學習):是一種機器學習類型,智能體在環境中采取行動,以達到最大化某種累積獎勵的目標,從而學習做出與特定目標相關的決策。
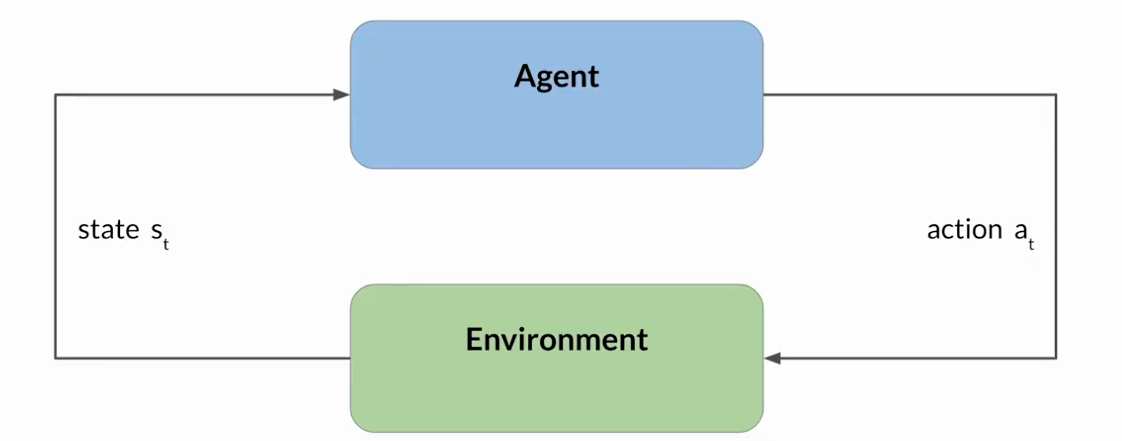
智能體通過采取行動,觀察環境中的變化,并根據其行動的結果接收獎勵或者懲罰,不斷從其經驗中學習,迭代這一過程。
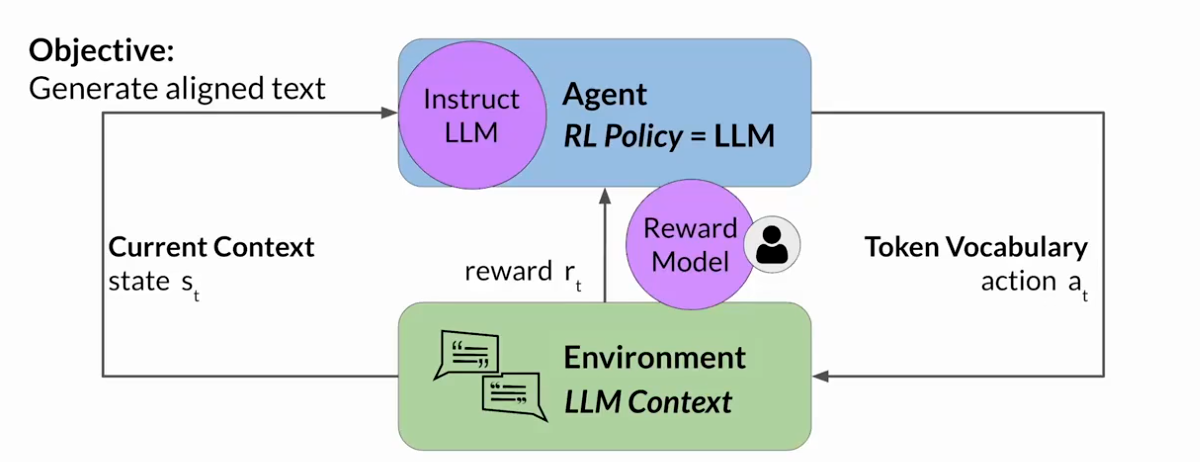
RLHF:獲取人類反饋的信息
首先,必須決定你希望人類根據什么標準來評估LLM的生成結果
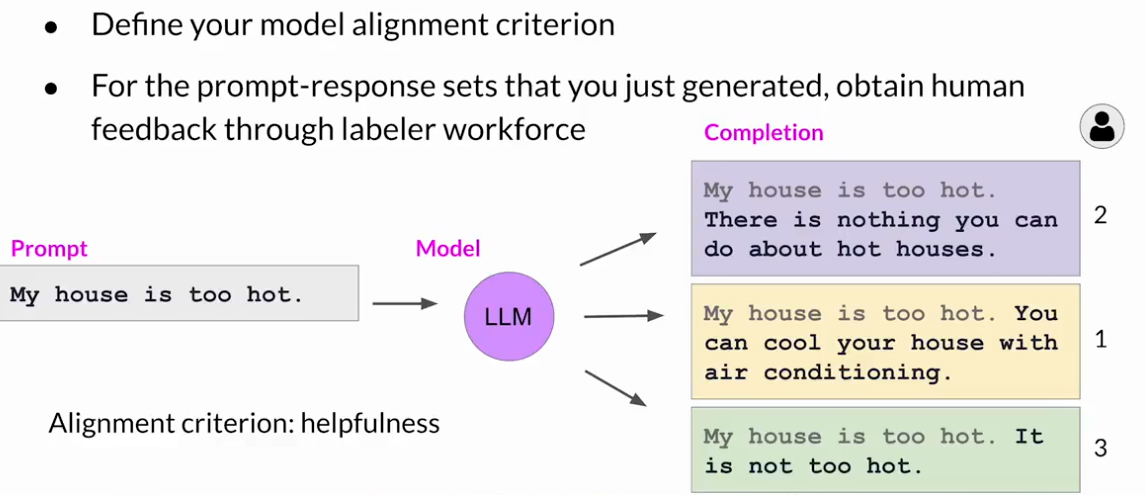
RLHF:獎勵模式
獎勵模型將有效地取代人類的數據標注員并自動選擇在RLHF過程中自動挑選最佳的結果
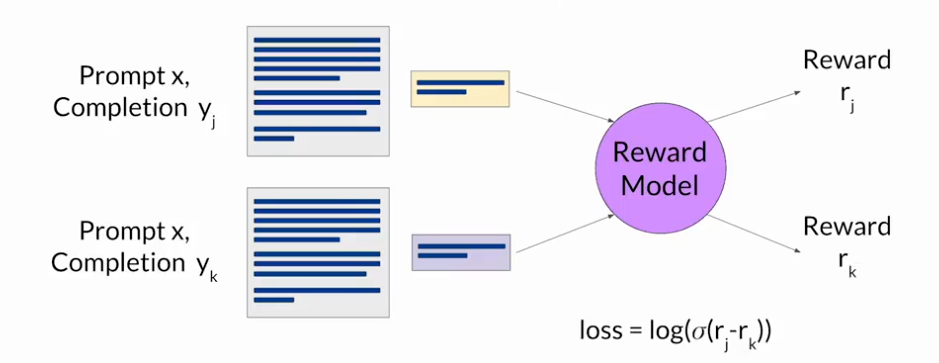
RLHF:利用強化學習進行微調
優先選擇一個在所關注的任務上已經做的很好的模型
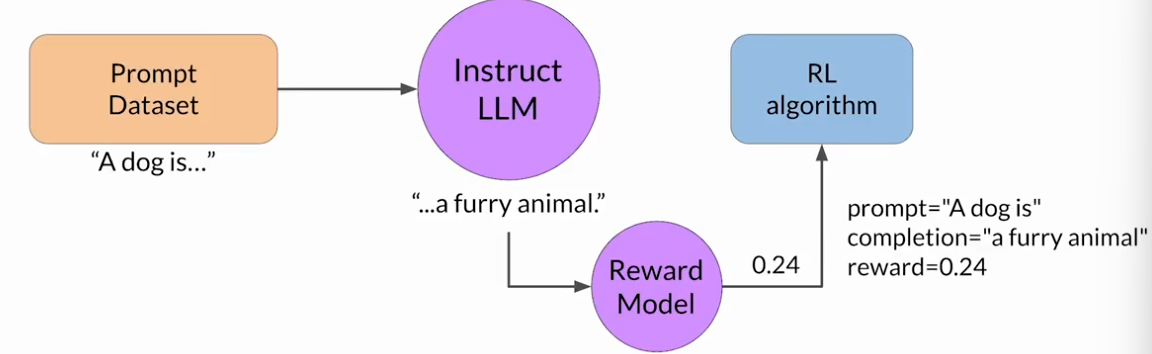
首先,從提示詞數據集中選擇一個提示詞,使用LLM進行補全,反饋至獎勵模型得到一個獎勵值,將這個提示詞-補全對于獎勵值反饋至強化學習算法,來更新LLM的權重
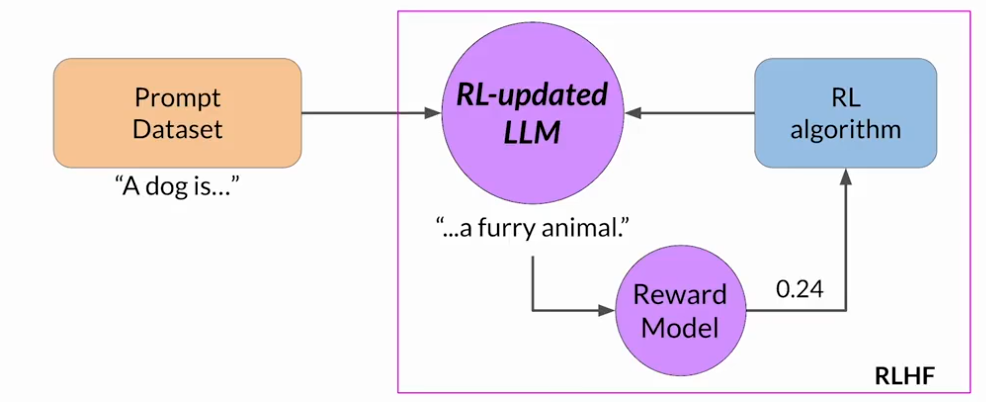
把微調過的模型成為人類對齊的LLM
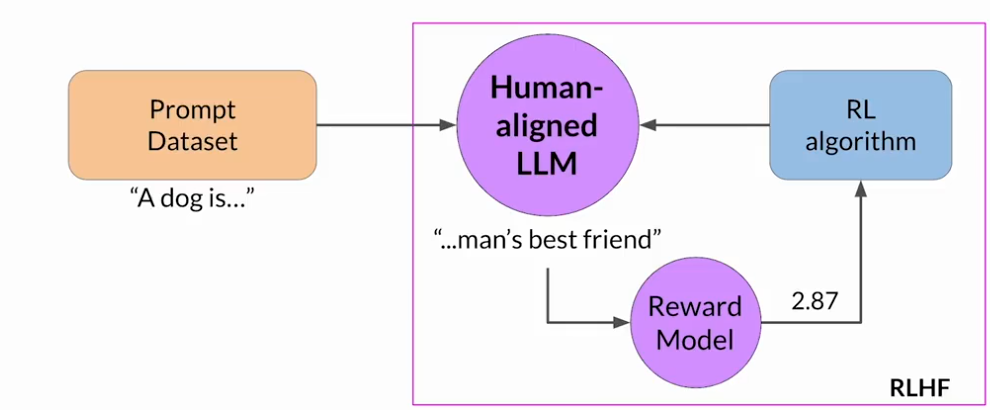
RLHF:獎勵黑客行為
代理通過選擇那些使其獲得最大獎勵的行為來欺騙系統,即使這些行動并不符合原始的目標
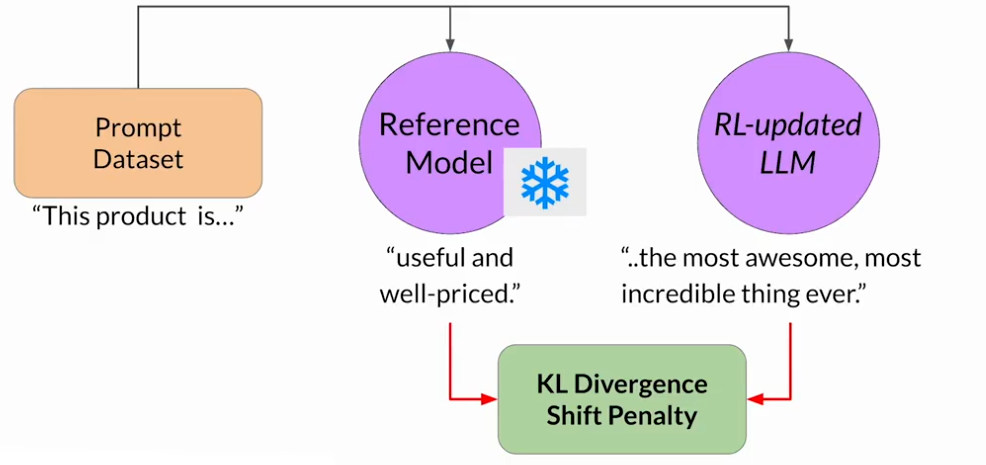
KL散度是一個統計度量,用來衡量兩個概率分布有多不同,可以用它來比較兩個模型的生成結果,來確定RL更新模型已經偏離了多少參考。
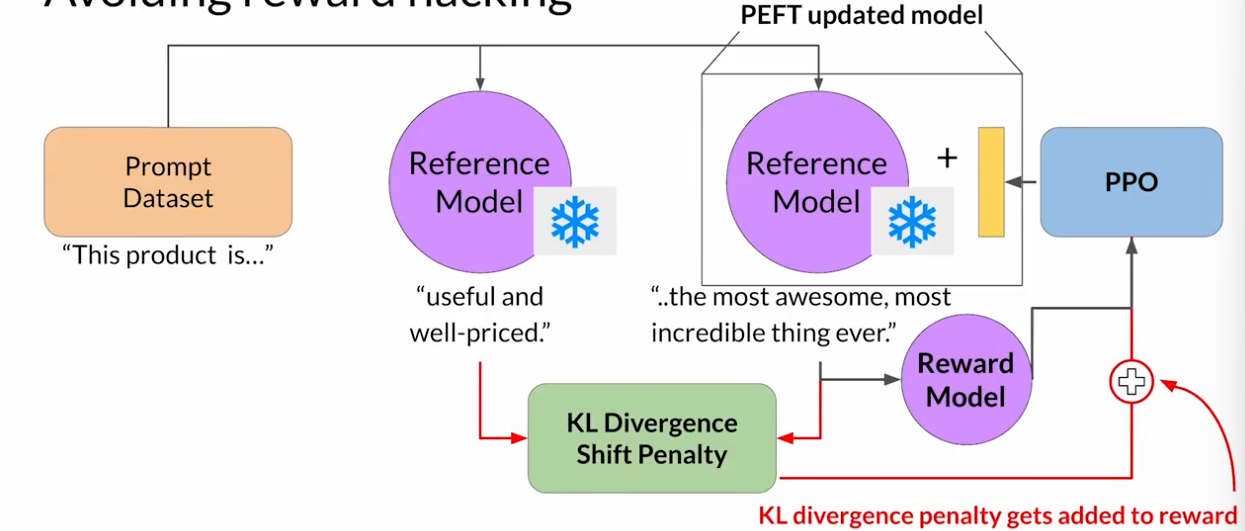




)




——個人筆記)









