1. 背景
在大模型對齊(alignment)里,常見的兩類方法是:
PPO:強化學習經典算法,OpenAI 在 RLHF 里用它來“用獎勵模型更新策略”。
DPO:2023 年提出的新方法(參考論文《Direct Preference Optimization: Your Language Model is Secretly a Reward Model》),繞過了獎勵模型,直接用偏好對 (chosen/rejected) 來優化。
2. PPO(Proximal Policy Optimization)
2.1 核心思想
來自強化學習領域,是一種 on-policy 策略梯度方法。
用獎勵模型(Reward Model)給生成的文本打分。
目標是最大化期望獎勵,同時用 KL 懲罰 約束策略不要偏離初始模型太遠。
2.2 損失函數(簡化)
LPPO(θ)=Et[min?(rt(θ)A^t,??clip(rt(θ),1??,1+?)A^t)]L^{PPO}(\theta) = \mathbb{E}_t \Big[ \min( r_t(\theta) \hat{A}_t, \; \text{clip}(r_t(\theta), 1-\epsilon, 1+\epsilon)\hat{A}_t ) \Big]
其中:
rt(θ)=πθ(at∣st)πθold(at∣st)r_t(\theta) = \frac{\pi_\theta(a_t|s_t)}{\pi_{\theta_\text{old}}(a_t|s_t)}(策略比值)
A^t\hat{A}_t:優勢函數(由獎勵模型給出)
clip:限制更新幅度,避免策略崩潰。
2.3 特點
優點:穩定性較好;能處理連續更新。
缺點:需要訓練一個獨立的獎勵模型,流程復雜;計算成本大。
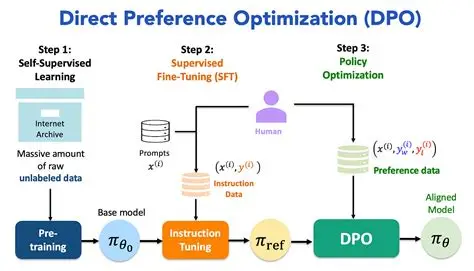
3. DPO(Direct Preference Optimization)
3.1 核心思想
用人類/自我博弈生成的偏好對:
chosen= 更好的回答rejected= 更差的回答
不需要顯式訓練獎勵模型,而是把“獎勵隱含在概率分布里”。
直接優化策略模型,使得它更偏向
chosen。
3.2 損失函數(簡化)
LDPO(θ)=?E(x,y+,y?)[log?σ(β?(log?πθ(y+∣x)?log?πθ(y?∣x)?log?πref(y+∣x)+log?πref(y?∣x)))]L^{DPO}(\theta) = - \mathbb{E}_{(x, y^+, y^-)} \Big[ \log \sigma\big(\beta \cdot (\log \pi_\theta(y^+|x) - \log \pi_\theta(y^-|x) - \log \pi_{\text{ref}}(y^+|x) + \log \pi_{\text{ref}}(y^-|x)) \big) \Big]
其中:
y+y^+:chosen
y?y^-:rejected
πref\pi_{\text{ref}}:參考模型(通常是初始 SFT 模型)
β\beta:溫度參數,調節強度
本質上是一個 對比學習(contrastive learning) 的形式。
3.3 特點
優點:
不需要獎勵模型,流程更簡單。
樣本利用率高,對訓練穩定。
缺點:
需要偏好對 (chosen/rejected),不能直接用單個答案 + 分數。
不適合在線優化,更適合離線批量訓練。
4. 對比總結
| 特點 | PPO | DPO |
|---|---|---|
| 提出時間 | 2017(RL 算法)→ RLHF | 2023(斯坦福團隊) |
| 是否需要獎勵模型 | ? 需要 | ? 不需要 |
| 輸入形式 | 答案 + 獎勵分數 | 偏好對 (chosen, rejected) |
| 優化方式 | 強化學習(on-policy) | 直接偏好對比(對比學習) |
| 訓練穩定性 | 相對復雜,易發散 | 更穩定,收斂快 |
| 適合場景 | 在線訓練,獎勵函數明確(數學/代碼/對話安全性) | 離線批量微調,數據是偏好對(人類標注/自我博弈) |
| 代表案例 | OpenAI GPT-4 RLHF | DeepSeek R1(自博弈 + DPO) |
5. 與 RLHF、自我博弈的關系
RLHF + PPO = 經典路線(GPT-4、Claude):人類標注 → 獎勵模型 → PPO 優化。
自我博弈 + DPO = 新興路線(DeepSeek R1):模型自己對弈 → 偏好對 → DPO 微調。
混合范式:
有人類數據時用 PPO 強化價值觀對齊;
有大規模自生成數據時用 DPO 提升推理/邏輯能力。
6. 一句話理解
PPO:模型像在健身,獎勵模型是教練,不斷糾正姿勢。
DPO:模型像在辯論,直接看“好答案 vs 壞答案”,學會站在勝方。



)




——個人筆記)










