1)
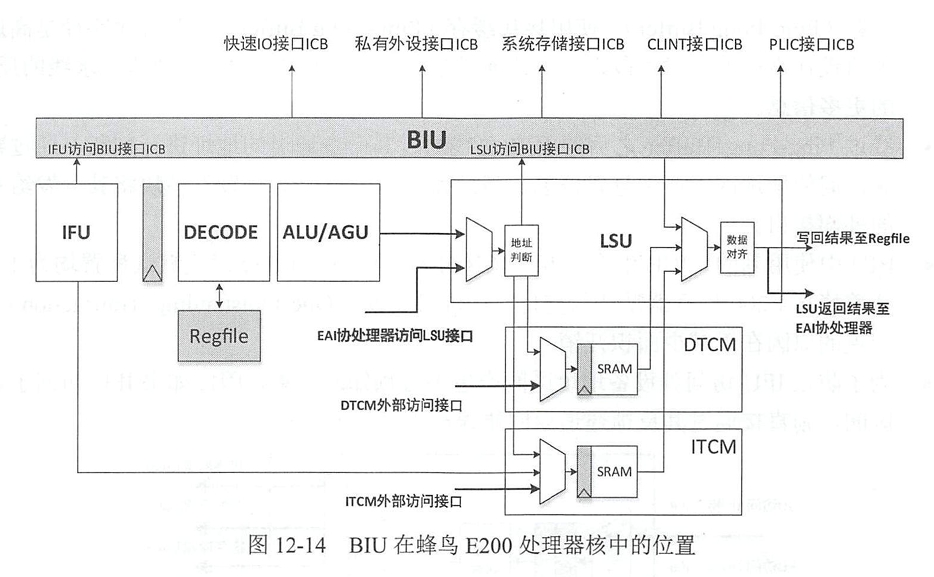
①BIU作為核心通信樞紐,主要承擔兩大功能:一是連接處理器核內的關鍵執行單元(包括IFU、LSU和EAI協處理器),統一管理指令和數據的內部傳輸路徑;二是作為"核內計算"與"核外資源"的唯一交互通道,負責對接外部存儲(如ITCM、DTCM、SRAM)及外設(包括快速IO、私有外設、CLINT和PLIC)。
②核內計算單元連接方式:
i)IFU通過專用的"IFU-BIU接口"與BIU相連;
ii)LSU通過"LSU-BIU接口"與BIU建立連接;
iii)ALU/AGU和LSU可直接將結果寫回寄存器文件。
③核心存儲單元配置:
i)ITCM經由BIU接口與IFU對接;
ii)DTCM通過BIU接口與LSU連接。
④核外擴展資源均采用標準化的ICB接口與BIU通信。ITCM/DTCM還額外提供外部訪問接口以支持容量擴展需求。
⑤EAI協處理器通過"LSU-EAI接口"間接接入BIU系統
→另一個視角
①指令流
i)取指:IFU通過專用接口向BIU發起指令請求,優先訪問ITCM獲取指令,若ITCM未命中,則通過ICB接口從外部SRAM加載指令;
ii)解碼:IFU將指令傳送至DECODE單元,解碼器將指令解析為操作碼和操作數地址;
iii)運算:ALU/AGU接收解碼結果,算術運算則直接執行計算,數據訪問則生成目標地址并傳遞給LSU;
iv)寫回:運算結果直接寫回寄存器堆,為后續指令執行提供數據支持。
②數據流
i)數據加載:LSU接收來自 ALU/AGU 的地址信息,通過"BIU-LSU接口"向BIU發起數據請求,優先訪問DTCM獲取目標數據,若DTCM未命中,則BIU通過ICB接口訪問外部SRAM;
ii)協處理輔助:當需要進行復雜運算時,EAI協處理器通過LSU接口獲取數據,完成運算后將結果數據返回至LSU;
iii)數據存儲 / 寫回:LSU將加載的數據傳送至ALU/AGU參與運算,或直接將數據寫入DTCM/SRAM存儲器,最終運算結果由LSU寫回Regfile,完成整個數據流處理過程。
2)
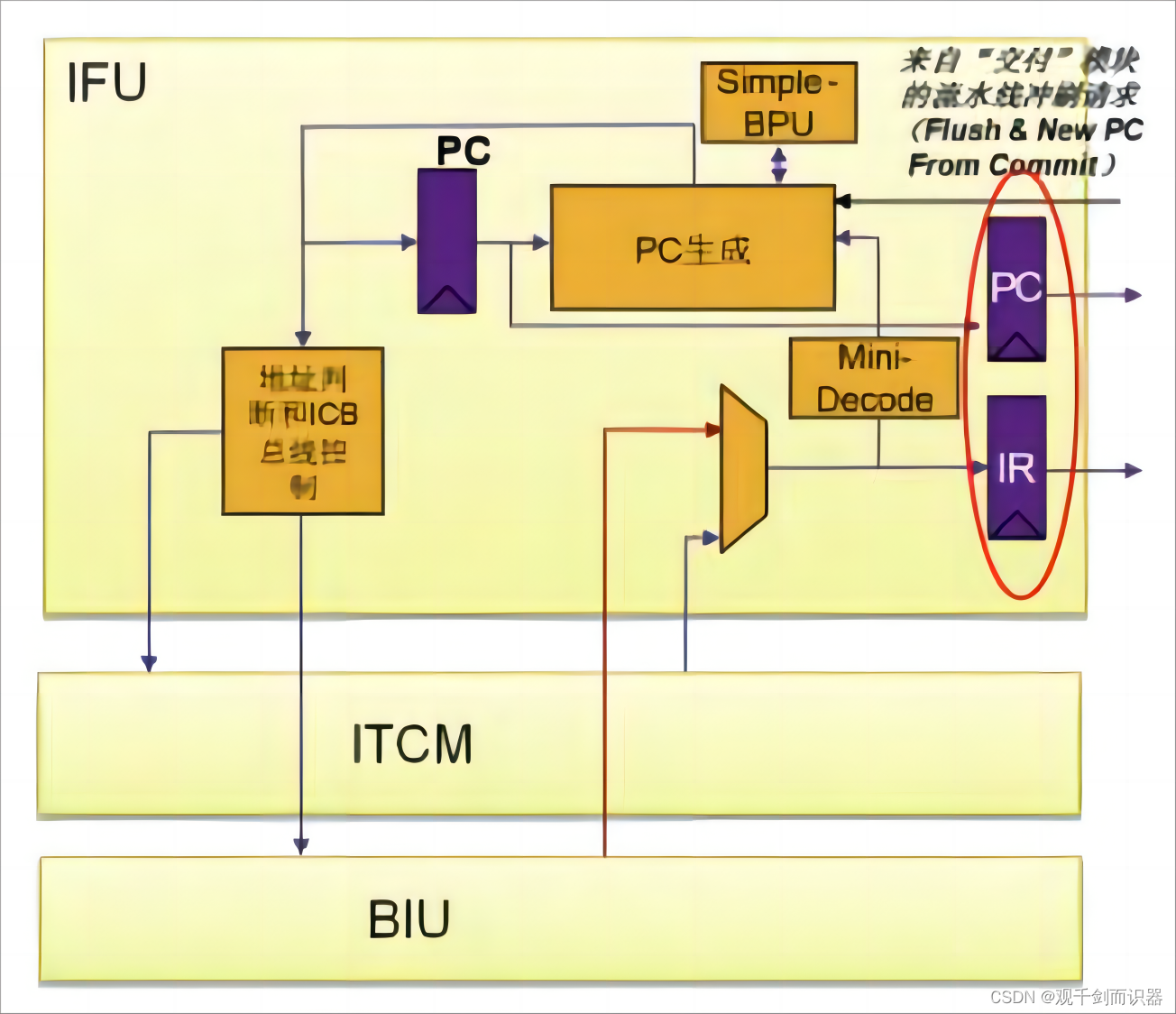
①
3)
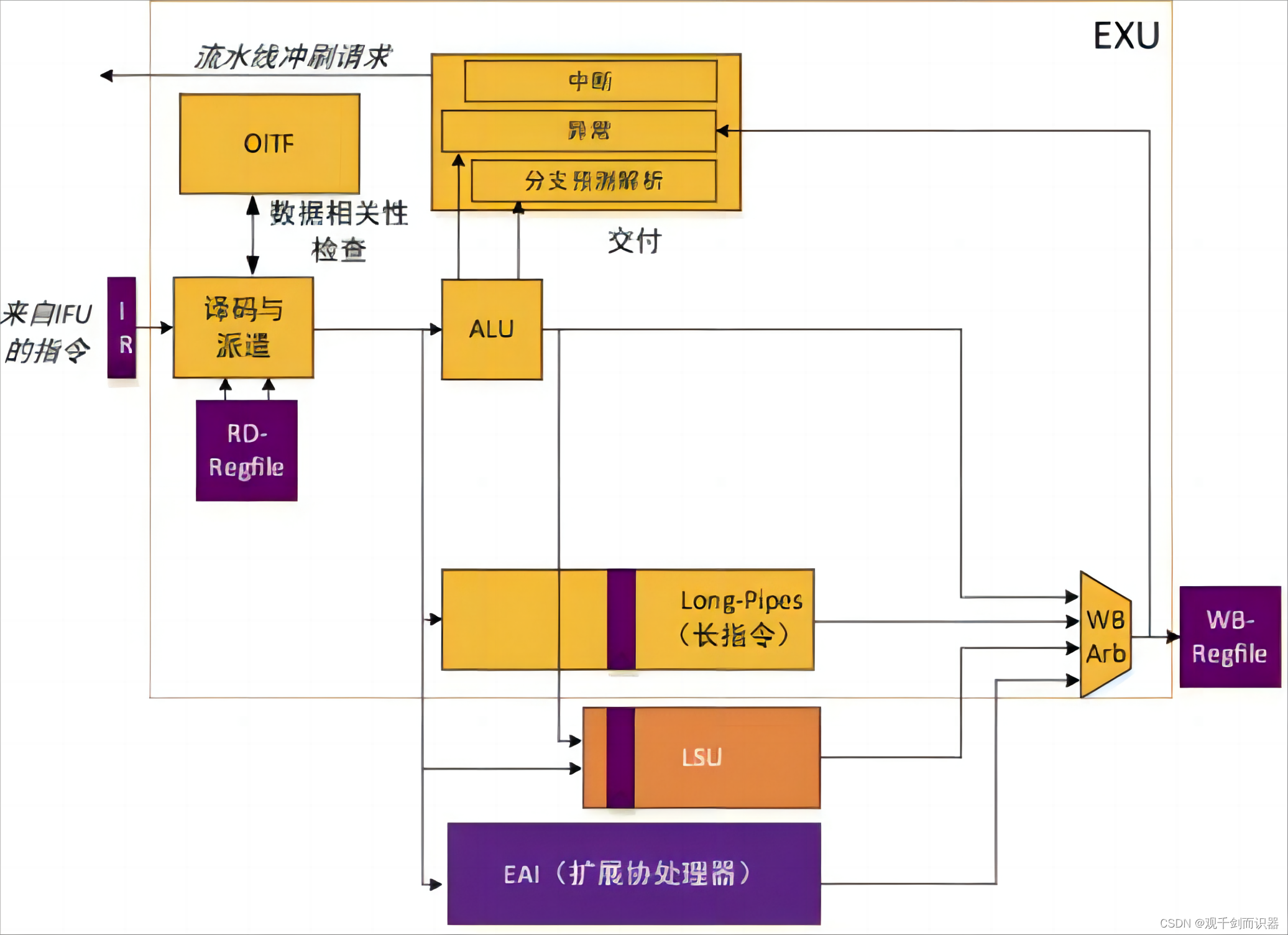
①
4)
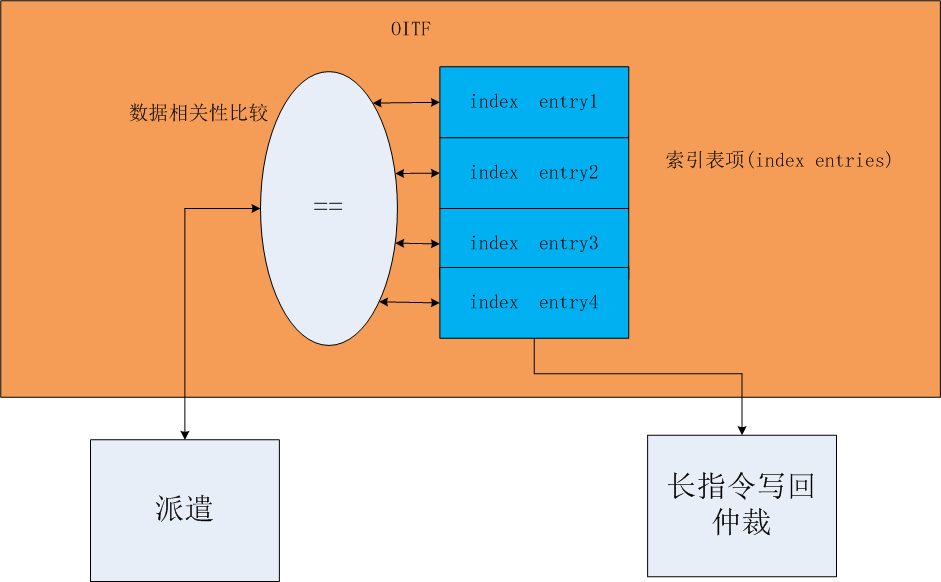
①
5)
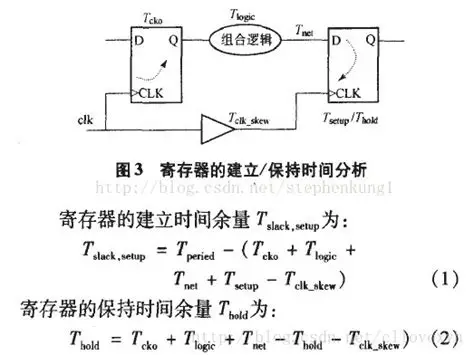
①
6)

①sret指令用于從S模式異常處理程序返回低特權級的核心指令.執行時,cpu退出異常處理流程,返回原執行流;
②mret指令用于從M模式的異常處理或中斷服務程序中退出,返回到陷入前的特權模式(如S模式或U模式).→在U/S模式下執行會觸發非法指令異常.
③WFI核心目的是讓處理器進入低功耗待機模式,直到一個不可屏蔽的中斷或可屏蔽中斷(當前已使能)發生.它是一種提示性hints指令,架構上它向硬件提供了一個明確提示,即程序目前沒有工作,具體的硬件實現可以自由決定如何響應這個提示.
→
如果在執行WFI時,中斷已經pending,則WFI指令的行為像一個NOP.CPU不會進入等待狀態,而是繼續執行下一條指令;
否則,CPU會暫停當前線程的執行,并開始進入一種架構性休眠狀態.此時,時鐘可能被門控,部分功能單元可能被斷電,從而顯著降低功耗.
→
WFI是本地的,在harts系統中,一個hart執行WFI只會讓該hart自己進入休眠狀態,不影響其他hart運行.
→
WFI不等于關機和深度睡眠,它只是一種淺睡眠狀態,喚醒延遲很低.更深的睡眠狀態通常需要通過PMU寄存器來配置.
7)
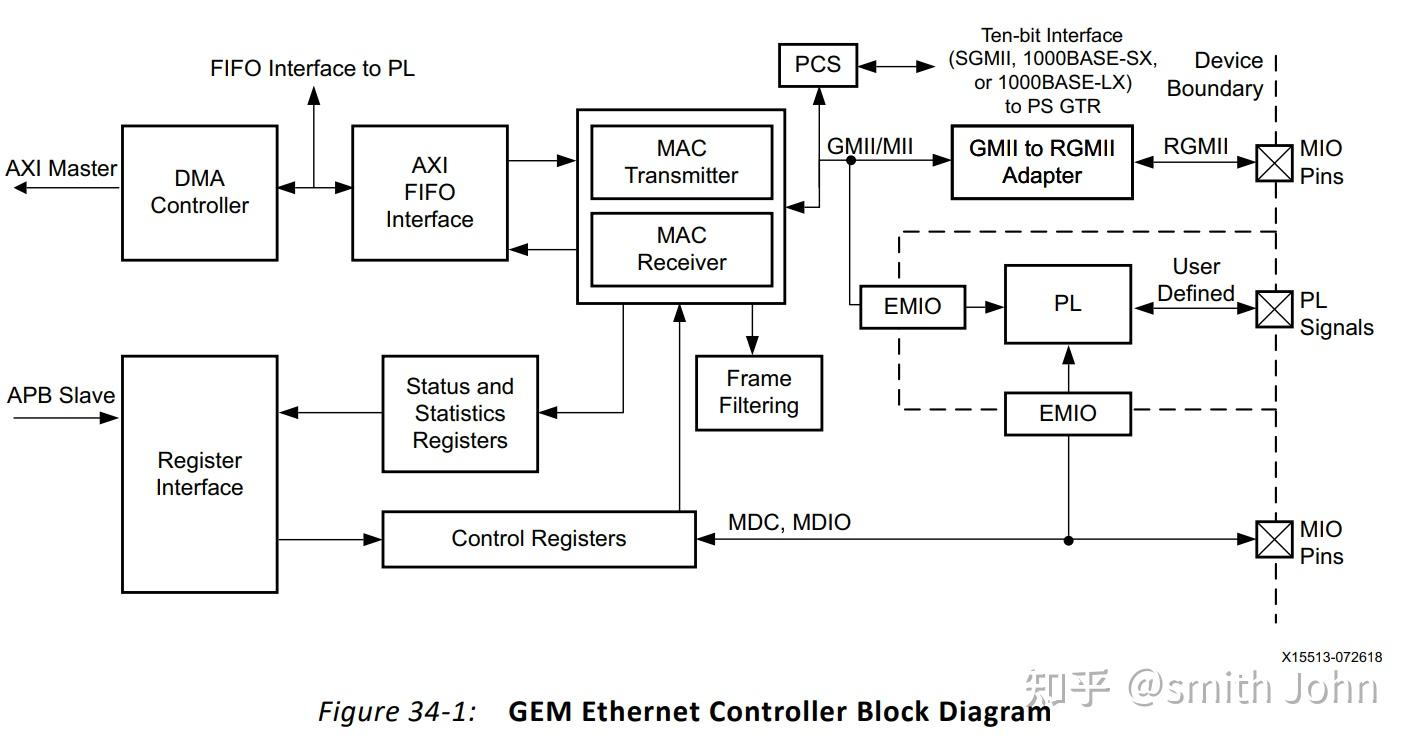
①
8)
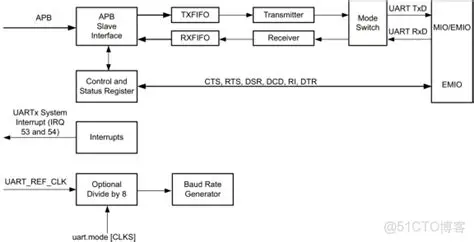
①
9)
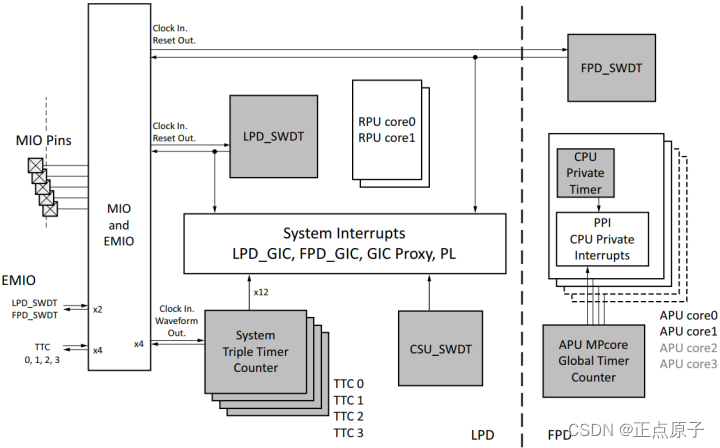
①
10)
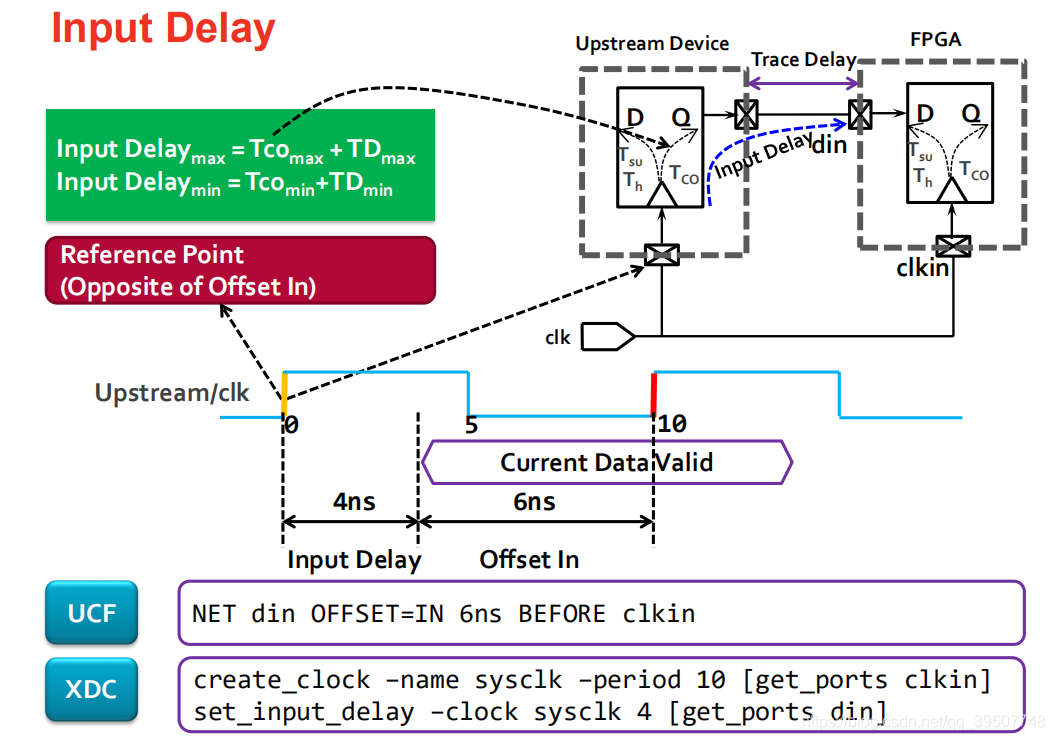
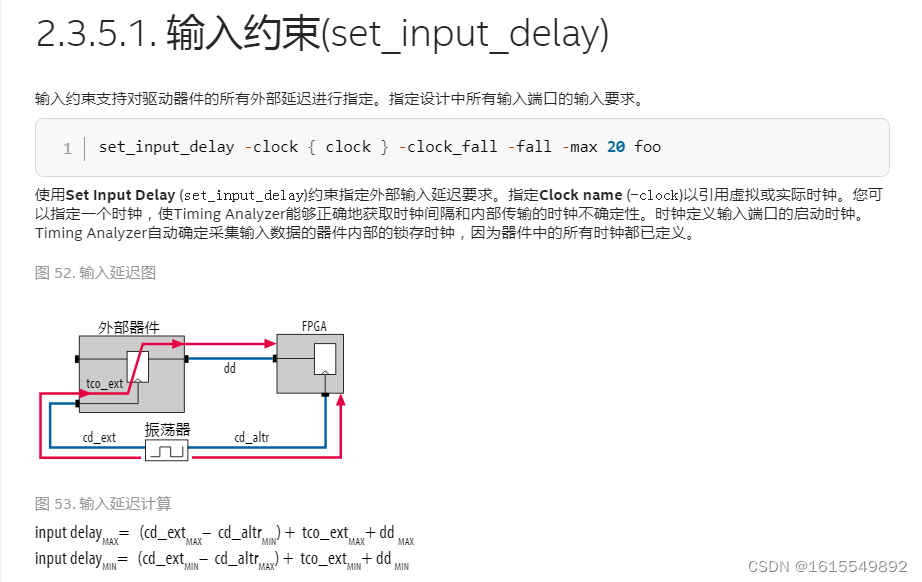 ①set_input_delay的根本目的,是告訴VIVADO時序分析器,FPGA芯片外部的信號,相對于其對應的外部時鐘,是何時到達FPGA輸入引腳的.(如果沒有這個約束,VIVADO會假設外部信號是完美的,與時鐘邊沿完美對齊);
①set_input_delay的根本目的,是告訴VIVADO時序分析器,FPGA芯片外部的信號,相對于其對應的外部時鐘,是何時到達FPGA輸入引腳的.(如果沒有這個約束,VIVADO會假設外部信號是完美的,與時鐘邊沿完美對齊);
②set_input_delay的工作原理基于一個標準的source-synchronous接口模型.時序分析器會為這條路徑計算兩個最壞情況;建立時間檢查(最慢路徑)和保持時間檢查(最快路徑).因此set_input_delay也需要指定-max和-min.
③對于建立時間檢查(set_input_delay -clock < clk_name > -max < value > [get_ports < name >]),分析器考慮最慢的數據路徑和最快的時鐘路徑.
④對于保持時間檢查,分析器考慮最快的數據路徑和最慢的時鐘路徑.
11)
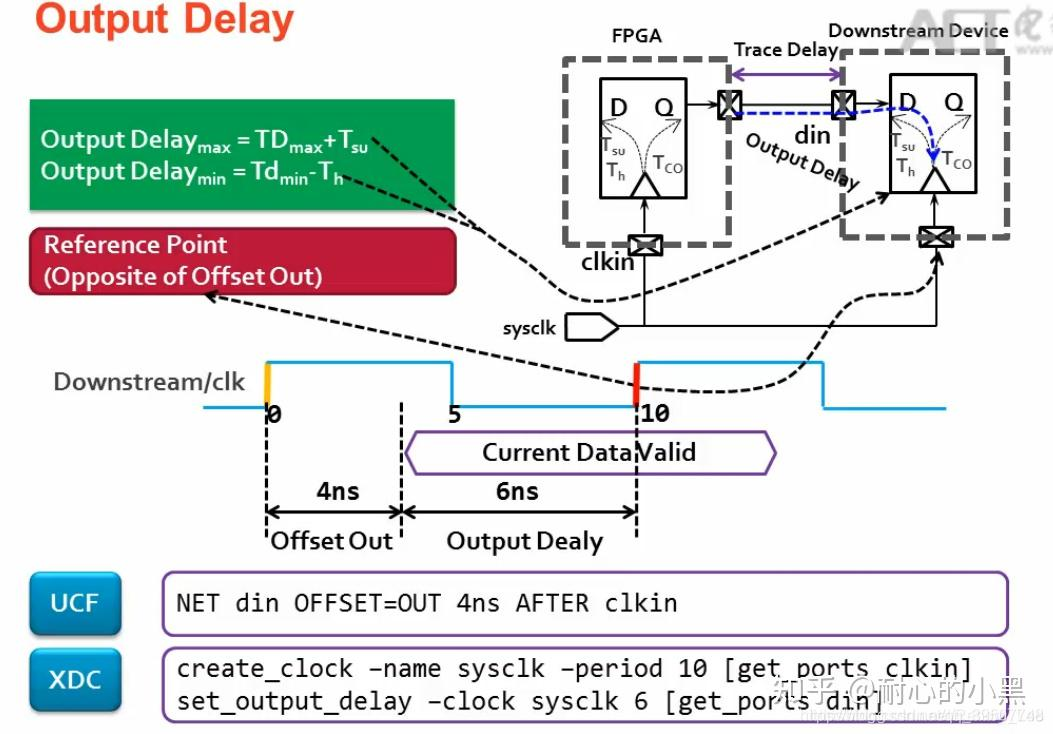
①set_output_delay約束的本質,就是告訴FPGA時序分析工具,外部接收芯片的時序要求.根據這個要求,工具反過來約束FPGA內部的邏輯和布線,確保數據在正確的時間出現在FPGA IO引腳.
②難點在于,數據的有效窗口,不僅取決于FPGA內部,還取決于整個系統的時鐘網絡.
③set_output_delay定義了,相對于參考時鐘,數據在FPGA引腳之后的有效時間是多少.
12)
①
①
☆)
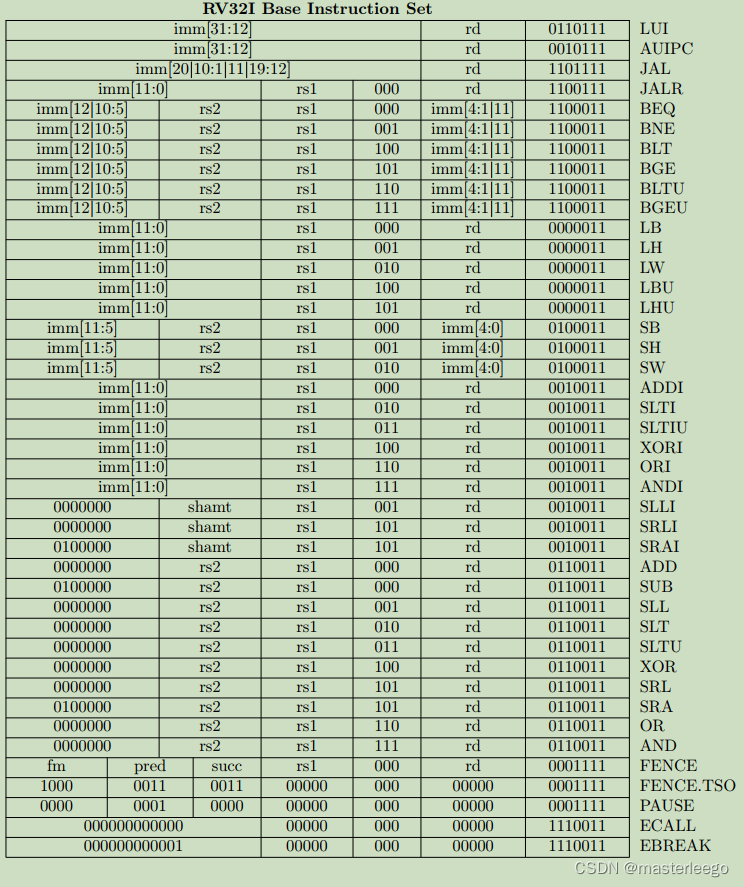
①B型指令其分支偏移量在指令中編碼為12位,且在計算目標地址時該偏移量會被硬件左移1位,以實現字節尋址下的指令地址對齊,因此相當于當前指令地址PC的跳轉范圍是±4KB.如需實現更大范圍的跳轉,需結合LUI指令(加載高位立即數)或AUIPC指令(PC相對加載高位立即數)來構造完整目標地址.
②JAL作為J型指令唯一用于實現帶鏈接直接跳轉指令,其功能是將下一條指令地址保存到指定寄存器中,同時跳轉到由20位立即數計算得出的目標地址處繼續執行程序.該指令支持相對于當前PC值±1MB的大地址范圍跳轉.
→
i)jal采用PC相對尋址,偏移范圍±1MB.適用于跳轉到固定偏移位置.
ii)jalr采用寄存器間接尋址,適用于動態目標地址(如函數返回/函數指針調用).
→
調用約定,函數調用jal固定使用ra保存返回地址;函數返回jalr通過ra間接跳轉.
③LUI(load upper immediate)指令用于將20位立即數加載到寄存器的高位,低12bit補零.
④在RV32I指令集中,B指令的立即數僅13位,跳轉范圍±4KB.若需長距離跳轉,需組合指令條件分支+JAL實現(多指令序列).(注意比較指令和條件跳轉指令的區別)
⑤lw指令用于從內存中讀取一個32位數據,通過基址加偏移量的方式計算內存地址,并要求地址對齊.→避免在訪問每次訪問不同地址時都需要修改基址寄存器,增加指令數量.→lh需要2字節對齊,lb無對齊要求.
⑥fence指令的pred前序操作集/succ后序操作集位域解析→i表示設備輸入(內存加載或外設寄存器讀),o表示設備輸出,r表示內存讀(普通內存加載操作),w表示內存寫.→
fence rw,w表示所有讀寫操作必須在該屏障前完成,之后才能執行寫操作.
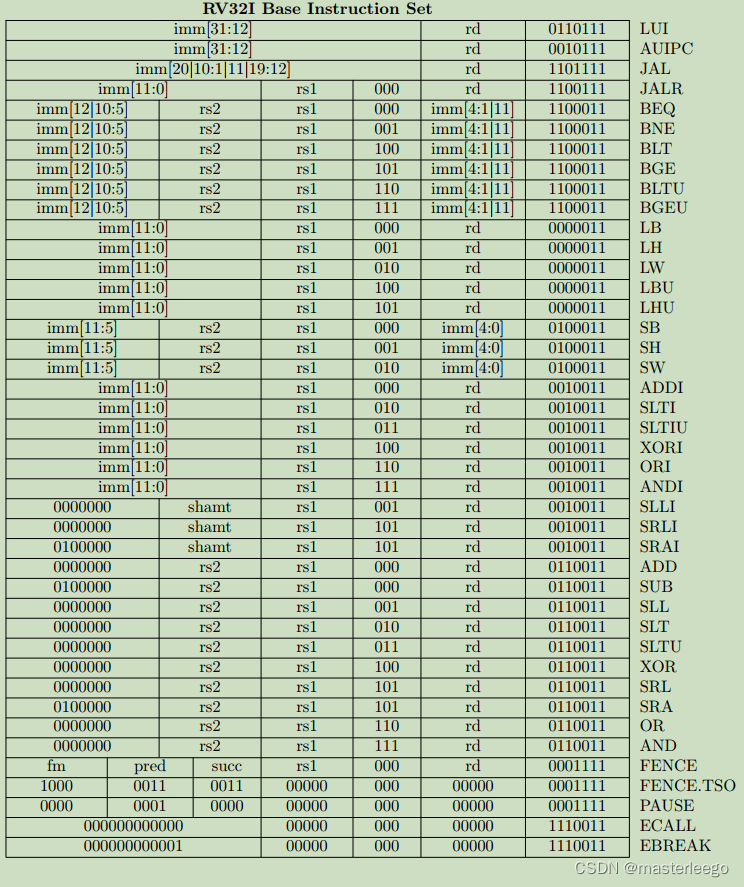
①fence指令用于控制內存訪問順序,確保其前后的特定內存操作滿足順序約束,避免因亂序執行導致的數據一致性問題.
②amo指令直接執行原子性讀-修改-寫操作(如原子加/交換/位操作等),在單條指令內保證操作的原子性,無需額外鎖機制,屬于可選的A擴展指令集.其通過硬件直接實現原子性.
③LR/SC指令通過lr.w(加載保留)和sc.w(條件存儲)的組合實現原子操作.屬于A擴展指令集.通過標記-檢查機制實現原子性
④fencei指令用于確保在該指令之前對指令存儲空間的所有寫入操作,在該指令之后對同一hart的取指操作可見.→程序可能修改自身正在執行或即將執行的代碼區域.如果沒有同步機制,處理器可能繼續執行舊的指令.→fencei強制硬件執行流水線沖刷、無效指令緩存、同步取指邏輯.→只保證當前執行它的hart能看到指令修改的效果.具體的沖刷和失效范圍(是整個i-cache還是僅相關區域)以及精確的硬件行為是implementation-defined.
⑤ecall(environment call)指令用于主動請求來自執行環境的服務,是用戶模式程序(u-mode)與更高特權級別(m-mode/s-mode)進行溝通的核心機制,主要用于實現系統調用.→當處理器執行ecall指令時,處理器會產生一個同步異常.處理器將當前pc保存到異常程序計數器mepc/sepc寄存器中,這個值指向ecall本身的地址或下一條指令的地址.→處理器將發生異常時的特權模式保存到異常狀態寄存器mstatus/sstatus中.→處理器將異常原因碼寫入異常狀態寄存器mcause/sstatus.→特權級別提升與跳轉.→軟件異常處理程序接管.→返回到用戶程序.
⑥ebreak(environment break)是RV32I指令集中重要調試指令.執行指令時,處理器會產生一個斷點異常.→異常進入時,處理器將當前pc存儲mepc,設置mcause為3,設置mtval(陷阱值寄存器)為0,跳轉到mtvec指定的異常處理程序.
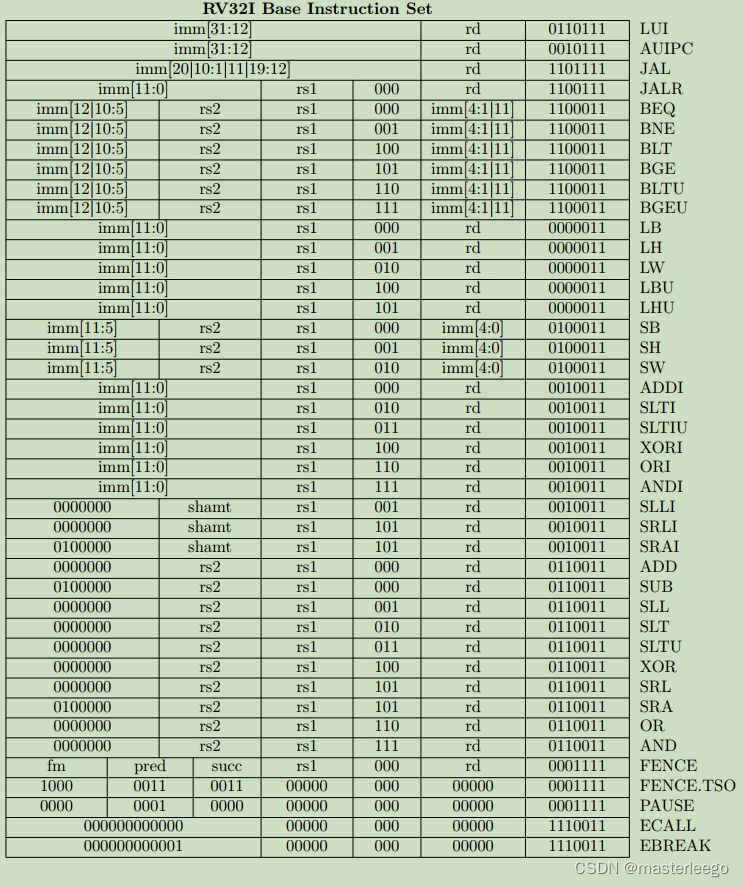
①csrrw用于原子性交換CSR和通用寄存器中的值,其行為是:讀取CSR舊值,零擴展至32位后寫入通用寄存器rd;將源通用寄存器rs1中的值寫入該CSR.注意,若rd=x0或rs1=x0,則跳過讀取操作或清零CSR.→csrrw提供原子操作,避免因中斷或上下文切換導致的數據不一致.
②csrrs用于原子化讀取并置位CSR,其原子化讀取目標CSR的當前值,并將其擴展至XLEN位,存入整數寄存器rd中.同時將源寄存器rs1的值視為bitmask,對CSR執行按位或,若rs1中某位為1,則CSR對應位置1,其他位保持不變.→讀取、修改、寫入三步操作在硬件層面原子完成,中間不會被中斷或上下文切換打斷.→注意!硬件確保CSR指令不會被異步異常打斷,但可能被同步異常打斷,比如指令執行中觸異常(如非法地址),此時終止執行并跳轉異常處理.此外還可能被調試中斷打斷.
③csrrc提供了一種原子方法來清除CSR中的特定位,同時不會影響其他位,并且能夠獲取修改前的狀態.
④fence指令→處理器和編譯器為了優化性能(亂序執行/緩存層次結構),可能會重排內存讀寫指令的執行順序.在單線程中這通常是安全的,但在并發多線程環境下,這種重排可能導致程序邏輯錯誤(違反內存一致性模型).→fence指令不提供任何原子性保證,它只強制特定類型指令執行的相對順序符合預期,例如,fence前的所有store必須在fence后的任何load/store之前對其他處理器可見.
⑤AMO指令在單個不可分割的步驟中,完成讀-修改-寫一個內存位置的操作.→當異步中斷在AMO執行過程到達時,此時立即凍結AMO操作(暫停在微操作的任意階段),并且保留關鍵狀態(內存鎖保持占用/寄存器值暫存),中斷返回后再重新執行AMO指令.
⑥LR/SC提供一種更復雜原子結構的底層原語.其提供了一種有條件的原子性.SC成功執行意味著從LR到SC這段時間內,目標內存位置沒有被干擾,因此整個序列(加載/計算/條件存儲)的效果是原子的.如果SC失敗,則需要重試整個序列.
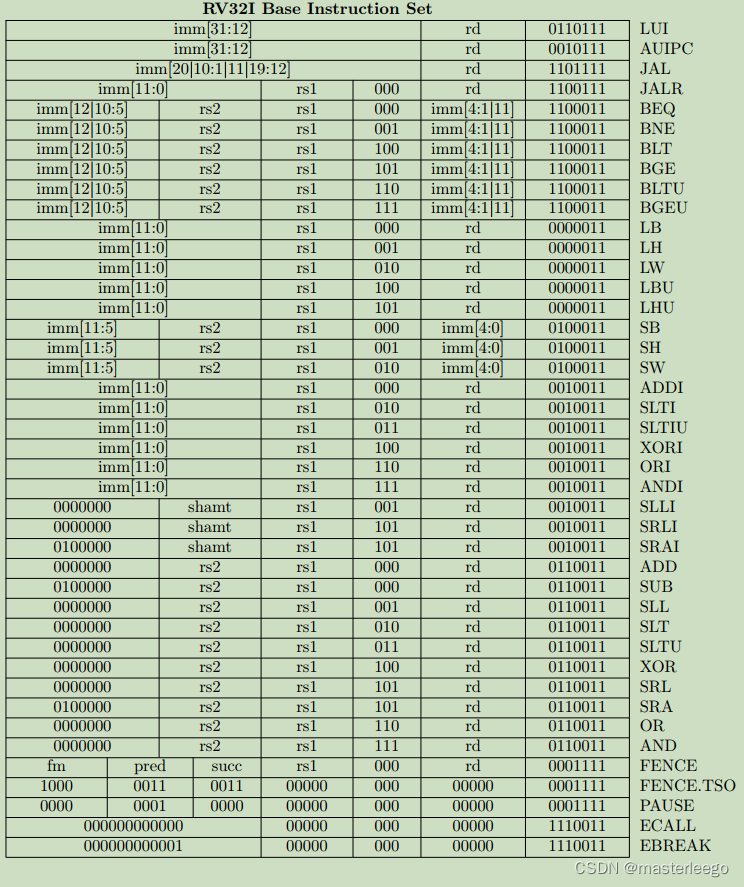
①ecall指令是risc-v架構中實現特權級躍遷的核心機制.其本質是觸發同步異常,強制將控制權從低特權級轉移到高特權級(通常是M/S模式).
→
執行ecall指令時,cpu立即停止當前指令流.硬件自動保存PC和原因寄存器,確保異常入口的狀態完整性.
②ebreak指令會立即引發一個斷點異常,強制暫停當前程序執行,并將控制權轉移給調試環境或異常處理程序執行,并將控制權轉移給調試環境或異常處理程序.→執行:返回地址保存/異常原因記錄/指令編碼獲取至mtval/跳轉至處理程序.→注意!軟件需修正mepc以避免死循環.
③add指令忽略算術溢出.其壓縮格式為c.add rd,rs2.
④amoadd指令會執行三個操作:i)從內存地址(由rs1指定)加載數據到臨時寄存器,將這個數據存入rd寄存器;ii)將加載的數據與rs2寄存器中的值進行加法;iii)將結果寫回原始內存地址.所有操作原子完成.→可以通過可選后綴aq/rl控制內存屏障行為.

】哈希表——242.有效的字母異位詞、349.兩個數組的交集、202.快樂數、1.兩數之和)



 用戶手冊)


)







![[手寫系列]Go手寫db — — 第三版(實現分組、排序、聚合函數等)](http://pic.xiahunao.cn/[手寫系列]Go手寫db — — 第三版(實現分組、排序、聚合函數等))


