在分布式系統中,有效應對節點故障、網絡分區延遲和數據一致性等挑戰至關重要。本文將剖析保障分布式系統可靠性的核心機制:數據分片實現水平擴展,冗余副本保障數據高可用,租約(Lease)機制優化節點狀態共識與資源管理,多數派(Quorum)原則確保操作的一致性,Gossip等去中心化協議高效同步集群狀態。這些成熟機制為構建穩健、高效的分布式系統提供了方法論支撐。
分布式系統
任何計算機系統都需要完成兩項基本任務,即計算(Computation)和存儲(Storage)。問題始于處理規模的需要,大多數事情在小規模上都是微不足道的——一旦超過了一定的大小、體積或其他物理受限的東西,同樣的問題就會變得更加困難。 當數據量級攀升至億萬級別,并發請求激增時,單個計算或存儲節點的物理極限便會凸顯。此時,無論如何優化單點性能,也難以獨立承載如此巨大的處理需求。
假設擁有無限的資源(如資金、人員、研發時間等),那么理論上所有的計算和存儲任務都可以在一個單一的高性能、高可靠節點上完成。然而,現實世界中資源總是有限的,因此必須在成本與收益之間找到最佳平衡點。在小規模場景下,通過縱向擴展(Scale-up),即升級單個節點的硬件,是一種直接的策略。但隨著規模的持續增長,硬件升級會遭遇瓶頸:要么不存在滿足需求的單點硬件,要么其成本高昂到不切實際。
為突破單點瓶頸,分布式系統(Distributed System) 應運而生。它通過將龐大的計算或存儲任務分解,并將其分散到由網絡連接的多個獨立計算節點(通常是商用計算機)集群上協同處理。這種橫向擴展(Scale-out)的方式,通過聚合眾多節點的計算和存儲能力以應對大規模問題。
從本質上看,分布式系統可以視為操作系統中計算與存儲管理理論在多節點協作環境下的延伸和擴展。操作系統在單機內管理進程、線程、內存、文件系統等資源;而分布式系統則在此基礎上,引入了跨節點的數據分片、任務調度、一致性協議、容錯機制等復雜問題。
單機性能與整體性能的關系
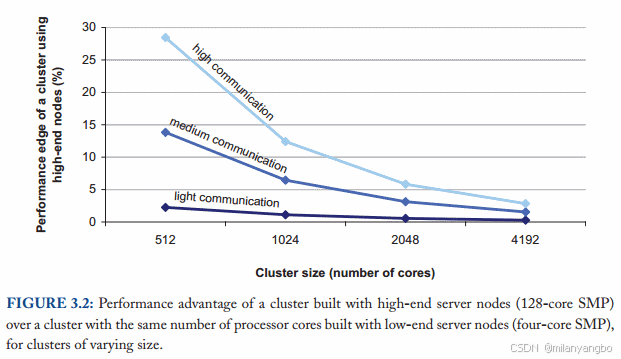
數據顯示,當集群規模較小時,采用高性能硬件能夠顯著提升系統的整體性能。然而,隨著集群規模的持續擴大,高端硬件帶來的邊際效益會逐漸遞減,其與普通商用級硬件在集群整體性能上的差距會縮小。
從理論上講,理想情況下,每增加一臺機器,分布式系統的計算和存儲能力應能夠線性增長。然而,實際情況遠非如此。
1)網絡開銷與協調開銷: 在大規模集群中,數據需要在不同節點間網絡傳輸,任務的執行需要跨節點協調。這些通信和同步的開銷往往成為新的瓶頸,而非單個節點的計算能力。即使計算和存儲在同一節點,進程間的協調也會引入開銷。
2)Amdahl定律的啟示: 系統整體性能的提升受限于系統中無法并行化部分的比例。在分布式系統中,串行部分(如某些一致性協議的決策階段、共享資源的爭用)會限制并行帶來的收益。
3)成本效益: 高端硬件成本高昂。采用性價比更高的中檔商用級硬件,結合精心設計的容錯機制,通常能以更低的總體擁有成本(Total Cost of Ownership,TCO)獲得理想的系統性能和可靠性。
因此,現代分布式系統設計傾向于使用大量相對廉價的商用硬件,依賴軟件層面的智能調度和容錯機制來保證系統的整體表現。
節點
在分布式系統中,節點是指一個能夠獨立執行特定邏輯功能的程序實體。在工程實踐中,一個節點通常對應一個操作系統上的進程,它承載一組明確定義的任務,如數據存儲、計算處理、元數據管理等。一個進程通常被視為一個邏輯上不可分割的節點單元。
然而,若一個進程內部包含多個高度獨立、可分別承擔不同角色的組件,從架構設計的角度,有時也會將其細化為多個邏輯節點,即使它們物理上運行在同一個進程或機器內。
拜占庭問題
拜占庭問題(Byzantine Problem)是分布式系統中的一個經典難題,由Leslie Lamport等人在1982年提出。其名稱源于一個比喻:拜占庭帝國的多位將軍率軍圍攻一座城市,需通過信使來協商進攻或撤退的策略。然而,將軍(節點)中可能存在叛徒,發送錯誤消息(甚至惡意信息)以破壞計劃。問題的核心在于,如何在存在叛徒的情況下,讓忠誠的將軍們達成一致并執行正確決策。
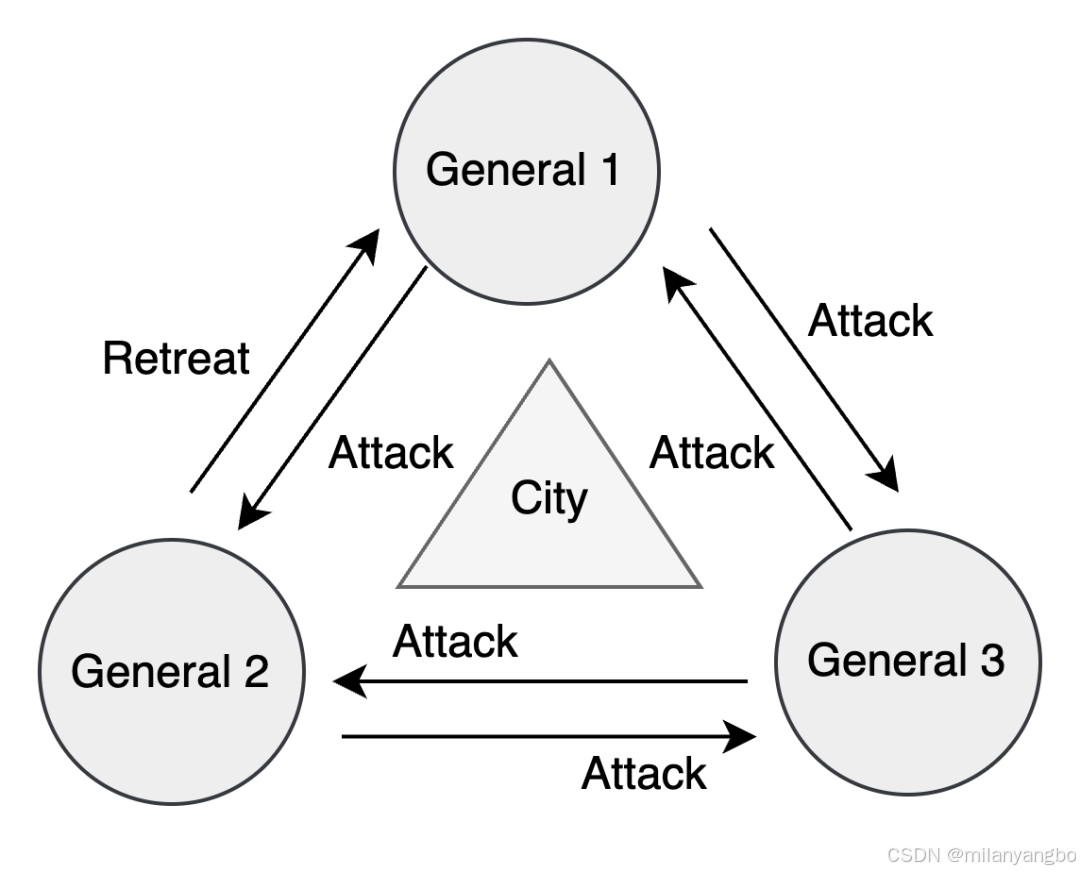
在分布式系統中,這種發送任意錯誤、不一致或惡意數據的節點故障被稱為拜占庭故障(Byzantine Fault)。解決此類問題的算法統稱為拜占庭容錯(Byzantine Fault Tolerance, BFT) 算法,其中最著名的實用算法是PBFT (Practical Byzantine Fault Tolerance)。BFT算法通常要求在總共 N 個節點中,惡意節點的數量 f 必須小于 N/3(即 N ≥ 3f+1),才能保證系統正確達成共識。這類算法因其高昂的通信開銷(通常需要多輪消息交換和數字簽名)和復雜性,性能相對較低。
拜占庭問題在對安全性要求極高的領域至關重要,例如航空航天、金融交易以及區塊鏈技術。比特幣的工作量證明(Proof of Work, PoW) 和以太坊等采用的權益證明(Proof of Stake, PoS) 等共識機制,其本質上都是為了在開放、無需信任的環境中解決拜占庭問題,確保全網對交易記錄的一致性和不可篡改性。
崩潰故障
在許多常見的分布式應用場景中,尤其是在受控的企業內部環境(如私有云、公司數據中心),節點通常被認為是“誠實但可能出錯”的。這意味著節點不會故意發送錯誤或矛盾的信息,它們可能發生的故障主要是崩潰故障(Crash Fault),即節點突然停止工作并不再響應。這種簡化的故障模型允許使用更高效的容錯機制。
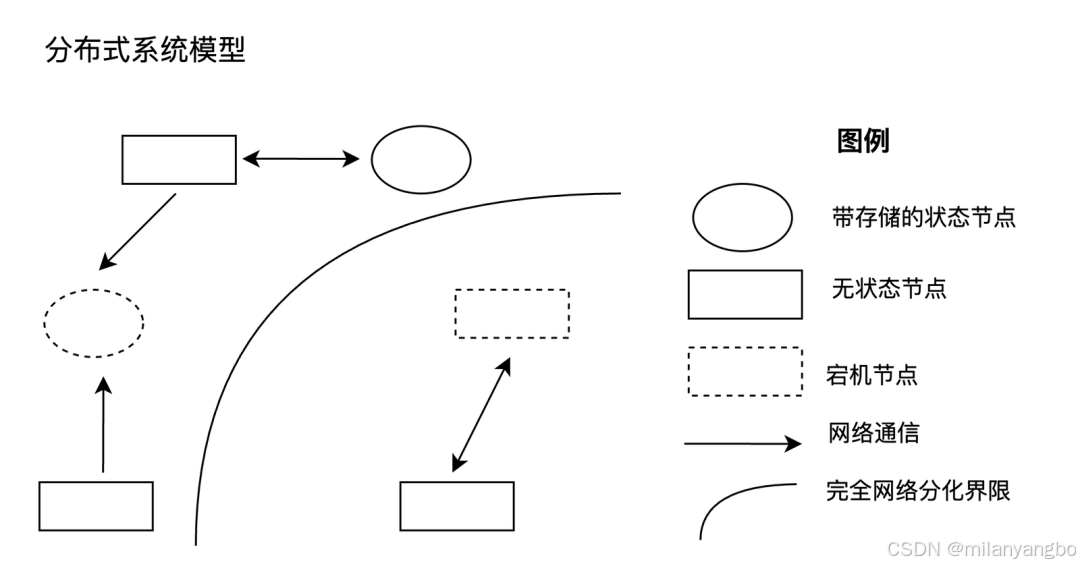
針對崩潰故障的容錯設計,即崩潰故障容錯(Crash Fault Tolerance, CFT),它涉及處理分布式系統的各種異常(Failure)情況。
1)不可靠網絡與分布式三態:當節點A向節點B發起遠程過程調用(RPC)后,在預設時間內未收到響應,節點A無法確定節點B是否已處理該請求。RPC的執行結果存在三種狀態:“成功”、“失敗”、“超時(未知)”,稱之為分布式系統的三種狀態。
這種不確定性是分布式編程的主要難點之一。最簡單的做法是,將執行步驟設計為可重試的,即具有所謂的冪等性(Idempotence)。冪等操作是指無論執行一次還是多次,其產生的效果都相同。例如,覆蓋寫(SET key = value)是冪等的;基于唯一ID的創建操作(CREATE IF NOT EXISTS item_id)也是冪等的。通過重試超時的冪等操作,可以簡化錯誤處理邏輯。
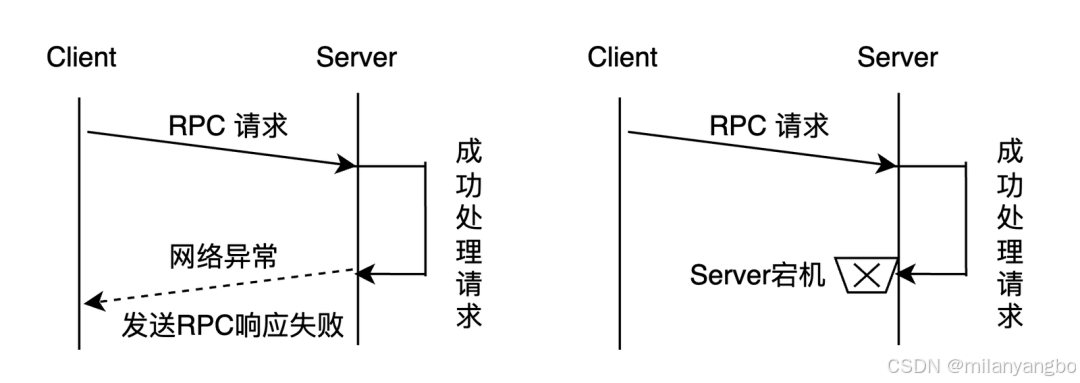
2)節點故障:雖然單個節點的平均無故障時間(Mean Time Between Failure,MTBF)可能較長,但在擁有成百上千個節點的集群中,節點故障成為常態事件(所謂“墨菲定律”的體現)。系統必須能夠自動檢測到故障節點,并將其負責的計算和存儲任務平滑地遷移到其他健康節點。
3)數據丟失:節點存儲的數據可能因硬件損壞(尤其是機械硬盤)、軟件缺陷或操作失誤而變得不可讀或數據錯誤。對于有狀態服務而言,數據丟失意味著狀態丟失。
4)時鐘偏移:分布式系統中的每個節點都擁有獨立的物理時鐘。由于硬件差異、溫度變化、網絡同步(Network Time Protocol,NTP)的精度限制等因素,這些本地時鐘之間難以完全同步,會產生時鐘偏移。這給確定跨節點事件的全局偏序關系帶來了挑戰,可能導致邏輯錯誤。
總而言之,分布式系統的核心挑戰源于各種異常帶來的不確定性,而系統的規模會顯著放大這種不確定性發生的概率和影響。研究和應用成熟的分布式算法與協議,不僅為具體問題提供了行之有效的解決方案,更重要的是,它們揭示了在特定約束條件下什么是可能實現的、正確實現的最小代價是什么,以及哪些目標是理論上不可達的。
未完待續
很高興與你相遇!如果你喜歡本文內容,記得關注哦!!!


)



![[光學原理與應用-418]:非線性光學 - 數學中的線性函數與非線性函數](http://pic.xiahunao.cn/[光學原理與應用-418]:非線性光學 - 數學中的線性函數與非線性函數)

:原理講透 + 最小可運行 GPT)
)







![[CISCN2019 華北賽區 Day1 Web1]Dropbox](http://pic.xiahunao.cn/[CISCN2019 華北賽區 Day1 Web1]Dropbox)

