事務和鎖(進階)
- 一.回顧事務
- 1.什么是事務
- 2 為什么要使用事務
- 3 怎么使用事務
- 二.InnoDB和ACID模型
- 三. 如何實現原子性
- 四.如何實現持久性
- 五.隔離性實現原理
- 1.事務的隔離性
- 2.事務的隔離級別
- 3.鎖
- 1)鎖信息
- 2) 共享鎖和獨占鎖-Shared and Exclusive Locks
- 3) 意向鎖-Intention Locks
- 4) 索引記錄鎖 - Record Locks
- 5) 間隙鎖 - Gap Locks
- 6) 臨鍵鎖 - Next-Key Locks
- 7) 插?意向鎖 - Insert Intention Locks
- 8)AUTO-INC Locks
- 9)死鎖
- (1)示例
- (2)死鎖產生的條件
- (3)InnoDB對死鎖的檢測
- (4)如何避免死鎖
- 4.查看并設置隔離級別
- 5. READ UNCOMMITTED - 讀未提交與臟讀
- 1) 實現方式
- 2) 存在問題
- 3) 問題重現
- 6. READ COMMITTED - 讀已提交與不可重復讀
- 1) 實現方式
- 2) 存在問題
- 3) 問題重現
- 7. REPEATABLE READ - 可重復讀與幻讀
- 1)實現方式
- 2 )存在問題
- 3) 問題重現
- 8 SERIALIZABLE - 串行化
- 1) 實現方式
- 2) 存在問題
- 9 不同隔離級別的性能與安全
- 10.多版本控制(MVCC)
- 1)實現原理
- (1)版本鏈
- (2) ReadView
- 2)MVCC是否可以解決不可重復讀與幻讀
一.回顧事務
1.什么是事務
事務是把?組SQL語句打包成為一個整體,在這組SQL的執行過程中,要么全部成功,要么全部失
敗,這組SQL語句可以是?條也可以是多條。再來看?下轉賬的例子,如圖: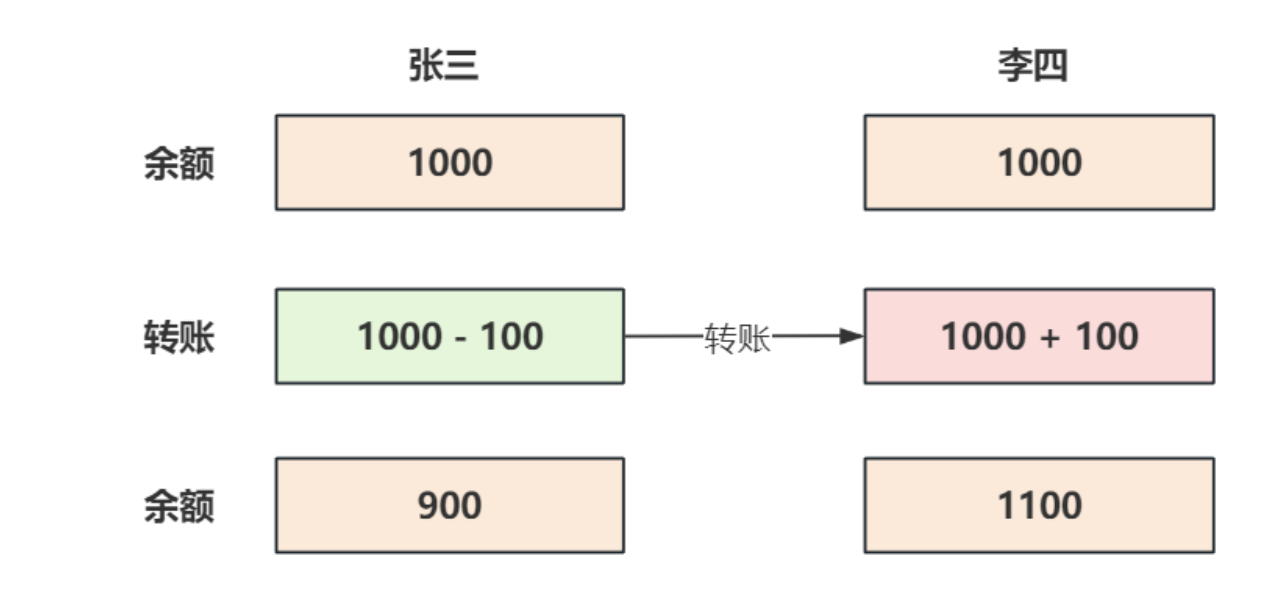
在這個例?中,涉及了兩條更新語句:
如果轉賬成功,應該有以下結果:
- 張三的賬戶余額減少 100 ,變成 900 ,李四的賬?余額增加了 100 ,變成 1100 ,不能出現張三的余額減少?李四的余額沒有增加的情況;
- 張三和李四在發?轉賬前后的總額不變,也就是說轉賬前張三和李四的余額總數為1000+1000=2000 ,轉賬后他們的余額總數為 900+1100=2000 ;
- 轉賬后的余額結果應當保存到存儲介質中,以便以后讀取;
- 還有?點需要要注意,在轉賬的處理過程中張三和李四的余額不能因其他的轉賬事件而受到干擾;
以上這四點在事務的整個執行過程中必須要得到保證,這也就是事務的 ACID 特性,即:
- Atomicity (原子性):一個事務中的所有操作,要么全部成功,要么全部失敗,不會出現只執行了一半的情況,如果事務在執行過程中發生錯誤,會回滾( Rollback )到事務開始前的狀態,就像這個事務從來沒有執行過一樣;
- Consistency (一致性):在事務開始之前和事務結束以后,數據庫的完整性不會被破壞。這表示寫?的數據必須完全符合所有的預設規則,包括數據的精度、關聯性以及關于事務執行過程中服務器崩潰后如何恢復;
- Isolation (隔離性):數據庫允許多個并發事務同時對數據進?讀寫和修改,隔離性可以防止多個事務并發執行時由于交叉執行而導致數據的不?致。事務可以指定不同的隔離級別,以權衡在不同的應用場景下數據庫性能和安全。
- Durability (持久性):事務處理結束后,對數據的修改將永久的寫?存儲介質,即便系統故障也不會丟失。
2 為什么要使用事務
事務具備的ACID特性,也是我們使?事務的原因,在我們日常的業務場景中有?量的需求要用事務來保證。?持事務的數據庫能夠簡化我們的編程模型,不需要我們去考慮各種各樣的潛在錯誤和并發問題,在使?事務過程中,要么提交,要么回滾,不用去考慮網絡異常,服務器宕機等其他因素,因此我們經常接觸的事務本質上是數據庫對 ACID 模型的?個實現,是為應?層服務的。
3 怎么使用事務
-
要使用事務那么數據庫就要?持事務,在MySQL中支持事務的存儲引擎是InnoDB,可以通過
show engines; 語句查看: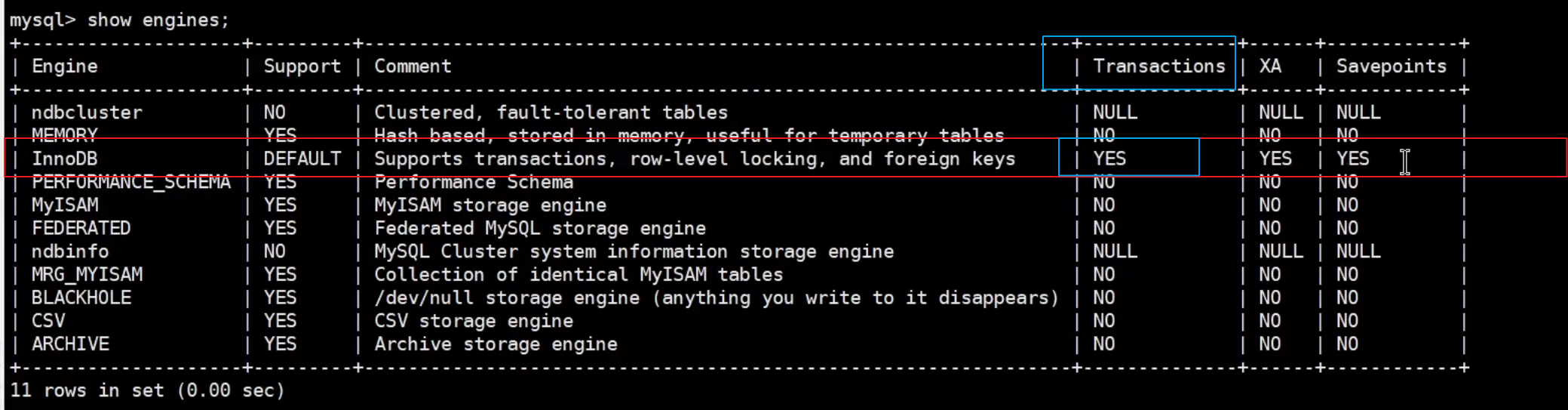
-
通過以下語句可以完成對事務的控制:
- START TRANSACTION 或 BEGIN 開始?個新的事務;
- COMMIT 提交當前事務,并對更改持久化保存;
-ROLLBACK 回滾當前事務,取消其更改;
-SET autocommit 禁?或啟?當前會話的默認?動提交模式, autocommit 是?個系統變量可以通過選項指定也可以通過命令行設置 --autocommit[={OFF|ON}]
-
演示開啟一個事務,執行修改后并回滾
# 開啟事務
mysql> START TRANSACTION;
Query OK, 0 rows affected (0.00 sec)
# 在修改之前查看表中的數據
mysql> select * from account;
+----+------+---------+
| id | name | balance |
+----+------+---------+
| 1 | 張三 | 1000.00 |
| 2 | 李四 | 1000.00 |
+----+------+---------+
2 rows in set (0.00 sec)
# 張三余額減少100
mysql> UPDATE account set balance = balance - 100 where name = '張三';
Query OK, 1 row affected (0.00 sec)
Rows matched: 1 Changed: 1 Warnings: 0
# 李四余額增加100
mysql> UPDATE account set balance = balance + 100 where name = '李四';
Query OK, 1 row affected (0.00 sec)
Rows matched: 1 Changed: 1 Warnings: 0
# 在修改之后,提交之前查看表中的數據,余額已經被修改
mysql> select * from account;
+----+------+---------+
| id | name | balance |
+----+------+---------+
| 1 | 張三 | 900.00 |
| 2 | 李四 | 1100.00 |
+----+------+---------+
2 rows in set (0.00 sec)
# 回滾事務
mysql> rollback;
Query OK, 0 rows affected (0.00 sec)
# 再查詢發現修改沒有?效
mysql> select * from account;
+----+------+---------+
| id | name | balance |
+----+------+---------+
| 1 | 張三 | 1000.00 |
| 2 | 李四 | 1000.00 |
+----+------+---------+
2 rows in set (0.00 sec)
- 演示開啟一個事務,執行修改后并回提交:
# 開啟事務
mysql> START TRANSACTION;
Query OK, 0 rows affected (0.00 sec)
# 在修改之前查看表中的數據
mysql> select * from account;
+----+------+---------+
| id | name | balance |
+----+------+---------+
| 1 | 張三 | 1000.00 |
| 2 | 李四 | 1000.00 |
+----+------+---------+
2 rows in set (0.00 sec)
# 張三余額減少100
mysql> UPDATE account set balance = balance - 100 where name = '張三';
Query OK, 1 row affected (0.00 sec)
Rows matched: 1 Changed: 1 Warnings: 0
# 李四余額增加100
mysql> UPDATE account set balance = balance + 100 where name = '李四';
Query OK, 1 row affected (0.00 sec)
Rows matched: 1 Changed: 1 Warnings: 0
# 在修改之后,提交之前查看表中的數據,余額已經被修改
mysql> select * from account;
+----+------+---------+
| id | name | balance |
+----+------+---------+
| 1 | 張三 | 900.00 |
| 2 | 李四 | 1100.00 |
+----+------+---------+
2 rows in set (0.00 sec)
# 提交事務
mysql> commit;
Query OK, 0 rows affected (0.01 sec)
# 再查詢發現數據已被修改,說明數據已經持久化到磁盤
mysql> select * from account;
+----+------+---------+
| id | name | balance |
+----+------+---------+
| 1 | 張三 | 900.00 |
| 2 | 李四 | 1100.00 |
+----+------+---------+
2 rows in set (0.00 sec)
- 默認情況下MySQL啟?事務自動提交,也就是說每個語句都是一個事務,就像被 START TRANSACTION 和 COMMIT 包裹一樣,不能使用 ROLLBACK 來撤銷執行結果;但是如果在語句執行期間發生錯誤,則自動回滾;
- 通過 SET autocommit 設置自動與手動提交
# 查看當前的事務提交模式
mysql> show variables like 'autocommit';
+---------------+-------+
| Variable_name | Value |
+---------------+-------+
| autocommit | ON | # ON表??動提交模式
+---------------+-------+
1 row in set, 1 warning (0.02 sec)
# 設置為?動提交(禁??動提交)
mysql> SET AUTOCOMMIT=0; # ?式?
mysql> SET AUTOCOMMIT=OFF; # ?式?
Query OK, 0 rows affected (0.00 sec)
# 再次查看事務提交模式
mysql> show variables like 'autocommit';
+---------------+-------+
| Variable_name | Value |
+---------------+-------+
| autocommit | OFF | # OFF表?關閉?動提交,此時轉為?動提交
+---------------+-------+
1 row in set, 1 warning (0.00 sec)
- 手動提交模式下,提交或回滾事務時直接使用 commit 或 rollback
# 查看事務提交模式,確定?動提交已關閉
mysql> show variables like 'autocommit';
+---------------+-------+
| Variable_name | Value |
+---------------+-------+
| autocommit | OFF | # OFF表?關閉?動提交,此時轉為?動提交
+---------------+-------+
1 row in set, 1 warning (0.00 sec)
# 查詢表中現在的數據
mysql> select * from account;
+----+------+---------+
| id | name | balance |
+----+------+---------+
| 1 | 張三 | 900.00 |
| 2 | 李四 | 1100.00 |
+----+------+---------+
2 rows in set (0.00 sec)
# 張三余額減少100
mysql> UPDATE account set balance = balance - 100 where name = '張三';
Query OK, 1 row affected (0.00 sec)
Rows matched: 1 Changed: 1 Warnings: 0
# 在修改之后查看表中的數據,余額已經被修改
mysql> select * from account;
+----+------+---------+
| id | name | balance |
+----+------+---------+
| 1 | 張三 | 800.00 | # ?原來的減少了100
| 2 | 李四 | 1100.00 |
+----+------+---------+
2 rows in set (0.00 sec)
# 回滾事務
mysql> rollback;
Query OK, 0 rows affected (0.00 sec)
# 再查詢是被修改之后的值,發現修改沒有?效
mysql> select * from account;
+----+------+---------+
| id | name | balance |
+----+------+---------+
| 1 | 張三 | 900.00 |
| 2 | 李四 | 1100.00 |
+----+------+---------+
2 rows in set (0.00 sec)
# 上?個事務已回滾,接下來重新執?更新操作,讓張三余額減少100
mysql> UPDATE account set balance = balance - 100 where name = '張三';
Query OK, 1 row affected (0.00 sec)
Rows matched: 1 Changed: 1 Warnings: 0
# 在修改之后查看表中的數據,余額已經被修改
mysql> select * from account;
+----+------+---------+
| id | name | balance |
+----+------+---------+
| 1 | 張三 | 800.00 | # ?原來的減少了100
| 2 | 李四 | 1100.00 |
+----+------+---------+
2 rows in set (0.00 sec)
# 提交事務
mysql> commit;
Query OK, 0 rows affected (0.00 sec)
# 再查詢是被修改之后的值,說明數據已經持久化到磁盤
mysql> select * from account;
+----+------+---------+
| id | name | balance |
+----+------+---------+
| 1 | 張三 | 800.00 |
| 2 | 李四 | 1100.00 |
+----+------+---------+
2 rows in set (0.00 sec)
- 通過 SET autocommit 設置自動與自動提交
# 查看當前的事務提交模式
mysql> show variables like 'autocommit';
+---------------+-------+
| Variable_name | Value |
+---------------+-------+
| autocommit | OFF | # ?動提交模式
+---------------+-------+
1 row in set, 1 warning (0.00 sec)
mysql> SET AUTOCOMMIT=1; # ?式?
mysql> SET AUTOCOMMIT=ON; # ?式?
Query OK, 0 rows affected (0.00 sec)
# 再次查看事務提交模式
mysql> show variables like 'autocommit';
+---------------+-------+
| Variable_name | Value |
+---------------+-------+
| autocommit | ON | # ON表??動提交模式
+---------------+-------+
1 row in set, 1 warning (0.00 sec)
- 注意:只要使用 START TRANSACTION 或 BEGIN 開啟事務,必須要通過 COMMIT 提交才會持久化,與是否設置 SET autocommit 無關。
二.InnoDB和ACID模型
-
ACID模型是?組數據庫設計原則,強調業務數據的可靠性,MySQL的InnoDB存儲引擎嚴格遵循ACID模型,不會因為軟件崩潰和硬件故障等異常導致數據的不完整。
-
Atomicity(原子性):原子性方面主要涉及InnoDB的事務開啟與提交,我們之前做過詳細講解與回顧
- 設置 autocommit[={OFF|ON}] 系統變量,開啟和禁?事務是否自動提交.
- 使用 START TRANSACTION 或 BEGIN TRANSACTION 語句開啟事務;
- 使用 COMMIT 語句提交事務;
- 使用 ROLLBACK 語句回滾事務。
-
Consistency(?致性):?致性主要涉及InnoDB內部對于崩潰時數據保護的相關處理,相關特性包括:
- InnoDB 存儲引擎的雙寫緩沖區 doublewrite buffer ;
- InnoDB 存儲引擎的崩潰恢復
-
Isolation(隔離性):隔離方面主要涉及應用于每個事務的隔離級別,相關特性包括:
- 通過 SET TRANSACTION 語句設置事務的隔離級別;
- InnoDB 存儲引擎的鎖,鎖可以在 INFORMATION_SCHEMA 系統庫和 Performance Schema 系統庫中的 data_locks 和 data_lock_waits 表查看
-
Durability(持久性):持久性涉及MySQL與特定硬件配置的交互,可能性取決于CPU、?絡和存儲設備的性能,由于硬件環境比較復雜,所以無法提供固定的操作指南,只能根據實際環境進行測試得到最佳的性能,相關特性包括:
- InnoDB 存儲引擎的雙寫緩沖區 doublewrite buffer ;
- innodb_flush_log_at_trx_commit 系統變量的設置;
- sync_binlog 系統變量的設置;
- innodb_file_per_table 系統變量的設置;
- 存儲設備(如磁盤驅動器、SSD或RAID磁盤陣列)中的寫緩沖區;
- 存儲設備中由電池?持的緩存。
- 運行MySQL的操作系統,特別是對 fsync() 系統調?的?持;
- 不間斷電源UPS (uninterruptible power supply),保護所有運行MySQL服務器和數據存儲設備的電力供應;
- 備份策略,例如備份的頻率和類型,以及備份保留周期;
- 分布式環境中數據中心之間的網絡連接。
-
需要重點說明的是,事務最終要保證數據的可靠和?致,也就是說 ACID 中的Consistency(?致性)是最終的?的,那么當事務同時滿?了Atomicity(原?性),Isolation(隔離性)和Durability(持久性)時,也就實現了?致性。
-
接下來我們分別討論MySQL是如何實現原子性,持久性和隔離性
三. 如何實現原子性
- 在?個事務的執行過程中,如果多條DML語句順利執行,那么結果最終會寫入數據庫;如果在事務
的執行過程中,其中?條DML語句出現異常,導致后?的語句無法繼續執行或即使繼續執行也會導致數據不完整、不?致,這時前?執行的語句已經對數據做了修改,如果要保證?致性,就需要對之前的修改做撤銷操作,這個撤銷操作稱為回滾 rollback ,如下圖所示: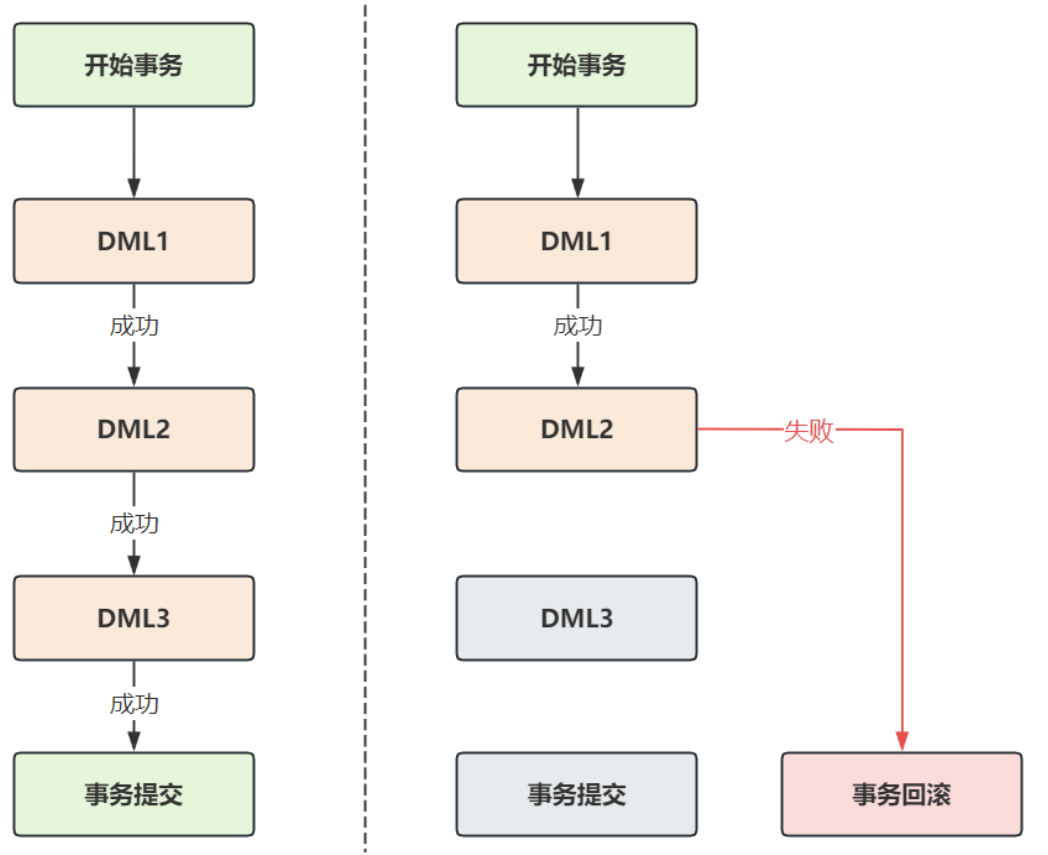
- 那么回滾操作是如何實現的呢?回滾過程中依據的是什么呢?在InnoDB專題中介紹過UndoLog的作用和原理,我們大致回顧?下,在事務執行每個DML之前,把原始數據記錄在?個日志?,做為回滾的依據,這個日志稱為 Undo Log (回滾日志或撤銷日志),在不考慮緩存和刷盤的條件下,執行過程如下所示:
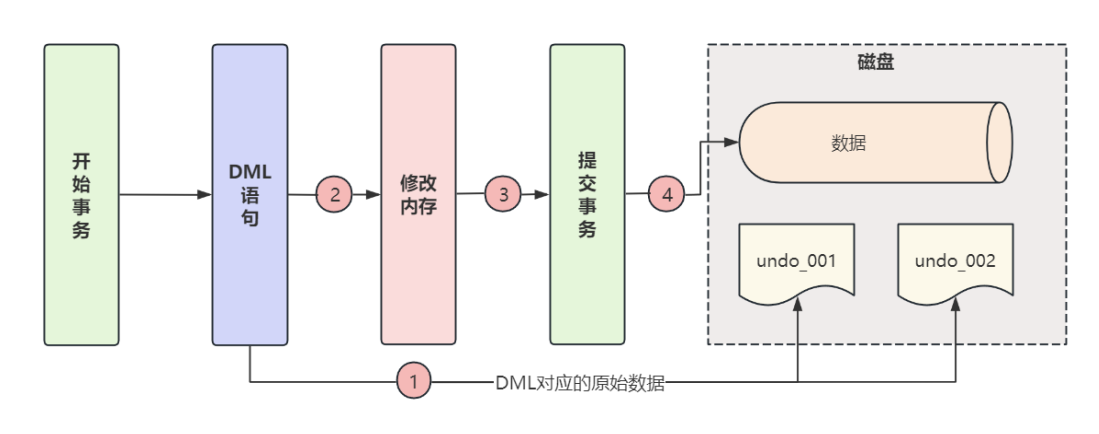
- 當需要回滾操作時,MySQL根據操作類型,在Insert Undo鏈或Update Undo鏈中讀取相應的日志記錄,并反向執行修改,使數據還原,完成回滾。
- 通過 Undo Log 實現了數據的回滾操作,這時就可以保證在事務成功的時候全部的SQL語句都執
行成功,在事務失敗的時候全部的SQL語句都執行失敗,實現在原子性。
四.如何實現持久性
- 提交的事務要把數據寫入(持久化到)存儲介質,比如磁盤。在正常情況下大多沒有問題,可是在服務器崩潰或突然斷電的情況下,?個事務中的多個修改操作,只有?部分寫?了數據文件,而另?部分沒有寫入,如果不做針對處理的話,就會造成數據的丟失,從而導致數據不完整,也就不能保證?致性。
- 在真正寫入數據文件之前,MySQL會把事務中的所有DML操作以日志的形式記錄下來,以便在服務器下次啟動的時候進行恢復操作,恢復操作的過程就是把日志中沒有寫到數據文件的記錄重新執行?遍,保證所有的需要保存的數據都持久化到存儲介質中,我們把這個日志稱為 Redo Log (重做日志);生成重做日志是保證數據?致性的重要環節。在持久化的處理過程中,還包括緩沖池、
Doublewrite Buffer (雙寫緩沖區)、 Binary Log (二進制日志) 等知識點,關于InnoDB的日志生成機制以及崩潰恢復機制我們在InnoDB 存儲引擎專題進行了詳細講解。
五.隔離性實現原理
1.事務的隔離性
MySQL服務可以同時被多個客?端訪問,每個客戶端執行的DML語句以事務為基本單位,那么不同的客戶端在對同一張表中的同?條數據進行修改的時候就可能出現相互影響的情況,為了保證不同的事務之間在執行的過程中不受影響,那么事務之間就需要要相互隔離,這種特性就是隔離性。
2.事務的隔離級別
學習過多線程技術,都知道在并發執行的過程中,多個線程對同一個共享變量進行修改時,在不加限制的情況下會出現線程安全問題,我們解決線程安全問題時,?般的做法是通過對修改操作進行加鎖;同理,多個事務在對同?個表中的同?條數據進行修改時,如果要實現事務間的隔離也可以通過鎖來完成,在MySQL中常見的鎖包括:讀鎖,寫鎖,行鎖,間隙鎖,Next-Key鎖等,不同的鎖策略聯合多版本并發控制可以實現事務間不同程度的隔離,稱為事務的隔離級別;
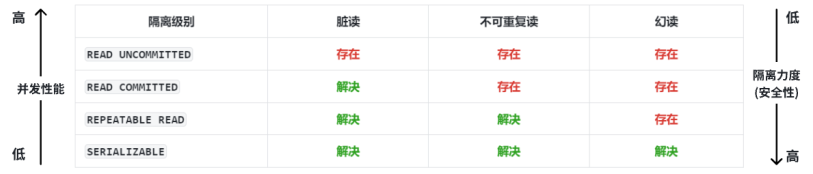
不同的隔離級別在性能和安全方面做了取舍,有的隔離級別注重并發性,有的注重安全性,有的則是并發和安全適中;在MySQL的InnoDB引擎中事務的隔離級別有四種,分別是:
- READ UNCOMMITTED ,讀未提交
- READ COMMITTED ,讀已提交
- REPEATABLE READ ,可重復讀(默認)
- SERIALIZABLE ,串行化
3.鎖
實現事務隔離級別的過程中用到了鎖,所謂鎖就是在事務A修改某些數據時,對這些數據加?把鎖,防?其他事務同時對這些數據執行修改操作;當事務A完成修改操作后,釋放當前持有的鎖,以便其他事務再次上鎖執行對應的操作。不同存儲引擎中的鎖功能并不相同,這?我們重點介紹InnoDB存儲引擎中的鎖。
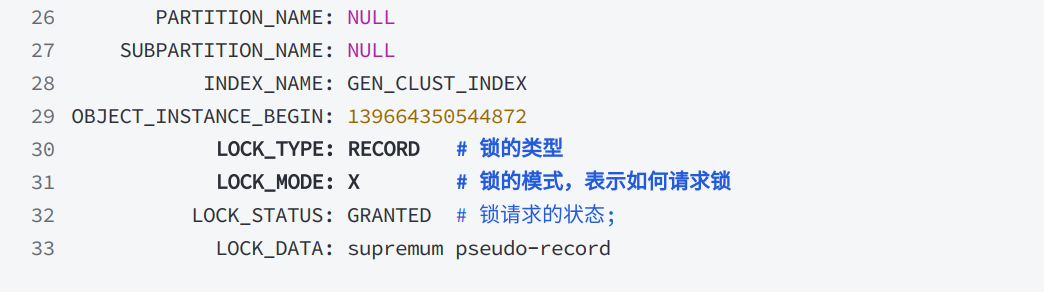
1)鎖信息
-
鎖的信息包括鎖的請求(申請),鎖的持有以及阻塞狀態等等,都保存在 performance_schema 庫的 data_locks 表中,可以通過以下方式查看:

-
鎖類型
鎖類型依賴于存儲引擎,在InnoDB存儲引擎中按照鎖的粒度分為,行級鎖 RECORD 和表級鎖
TABLE :- 行級鎖也叫行鎖,是對表中的某些具體的數據行進行加鎖;
- 表級鎖也叫表鎖,是對整個數據表進行加鎖。
在之前版本的BDB存儲引擎中還支持頁級鎖,鎖定的是?個數據頁,MySQL8中沒有頁級鎖
- 鎖模式
鎖模式,?來描述如何請求(申請)鎖,分為共享鎖(S)、獨占鎖(X)、意向共享鎖(IS)、意向獨占鎖
(IX)、記錄鎖、間隙鎖、Next-Key鎖、AUTO-INC 鎖、空間索引的謂詞鎖等
這?介紹的鎖類型和鎖模式,也就是?家經常聽過的鎖分類
2) 共享鎖和獨占鎖-Shared and Exclusive Locks
InnoDB實現了標準的行級鎖,分為兩種分別是共享鎖(S鎖)和獨占鎖(X鎖),獨占鎖也稱為排他鎖。
- 共享鎖(S鎖):允許持有該鎖的事務讀取表中的一行記錄,同時允許其他事務在鎖定行上加另?個
共享鎖并讀取被鎖定的對象,但不能對其進行寫操作; - 獨占鎖(X鎖):允許持有該鎖的事務對數據行進行更新或刪除,同時不論其他事務對鎖定行進行讀
取或修改都不允許對鎖定行進行加鎖;
- 如果事務T1持有R行上的共享鎖(S),那么事務T2請求R行上的鎖時會有如下處理:
- T2請求S鎖會立即被授予,此時T1和T2都對R行持有S鎖;
- T2請求X鎖不能立即被授予,阻塞到T1釋放持有的鎖
- 如果事務T1持有R行上的獨占鎖(X),那么T2請求R?上的任意類型鎖都不能?即被授予,事務T2必須等待事務T1釋放R行上的鎖。
TIPS:
讀鎖是共享鎖的?種實現,寫鎖是排他鎖的?種實現。
3) 意向鎖-Intention Locks
- InnoDB?持多粒度鎖,允許行鎖和表鎖共存;
- InnoDB使?意向鎖實現多粒度級別的鎖,意向鎖是表級別的鎖,它并不是真正意義上的加鎖,而只是在 data_locks 中記錄事務以后要對表中的哪?行加哪種類型的鎖(共享鎖或排他鎖),意向鎖分為兩種:
- 意向共享鎖(IS):表示事務打算對表中的單個行設置共享鎖。
- 意向排他鎖(IX):表示事務打算對表中的單個行設置排他鎖。
- 在獲取意向鎖時有如下協議:
- 在事務獲得表中某一行的共享鎖(S)之前,它必須?先獲得該表上的IS鎖或更強的鎖。
- 在事務獲得表中某一行的排他鎖(X)之前,它必須?先獲得該表上的IX鎖。
- 意向鎖可以提?加鎖的性能,在真正加鎖之前不需要遍歷表中的?是否加鎖,只需要查看?下表中
的意向鎖即可; - 在請求鎖的過程中,如果將要請求的鎖與現有鎖兼容,則將鎖授予請求的事務,如果與現有鎖沖
突,則不會授予;事務將阻塞等待,直到沖突的鎖被釋放;意向鎖與行級鎖的兼容性如下表: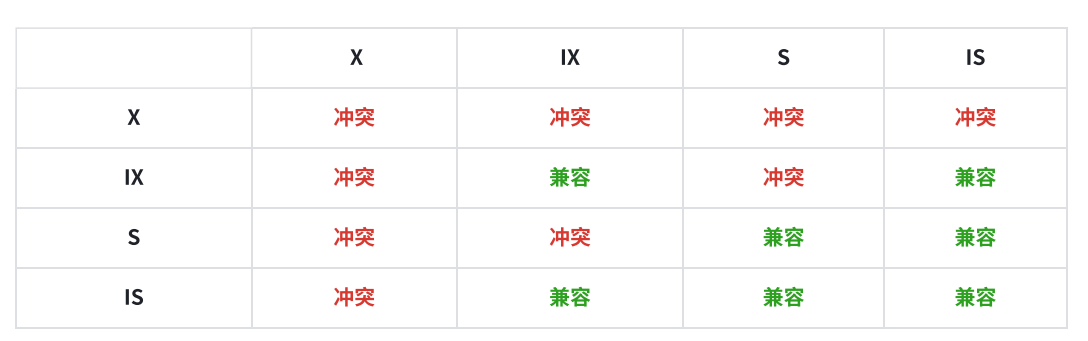
- 除了全表鎖定請求之外,意向鎖不會阻止任何鎖請求;意向鎖的主要目的是表示事務正在鎖定某行或者正在意圖鎖定某行。
4) 索引記錄鎖 - Record Locks
- 索引記錄鎖或稱為精準行鎖,顧名思意是指索引記錄上的鎖,如下SQL鎖住的是指定的一行:

- 索引記錄鎖總是鎖定索引行,在表沒有定義索引的情況下,InnoDB創建?個隱藏的聚集索引,并
使用該索引進行記錄鎖定,當使用索引進行查找時,鎖定的只是滿足條件的行,如圖所示: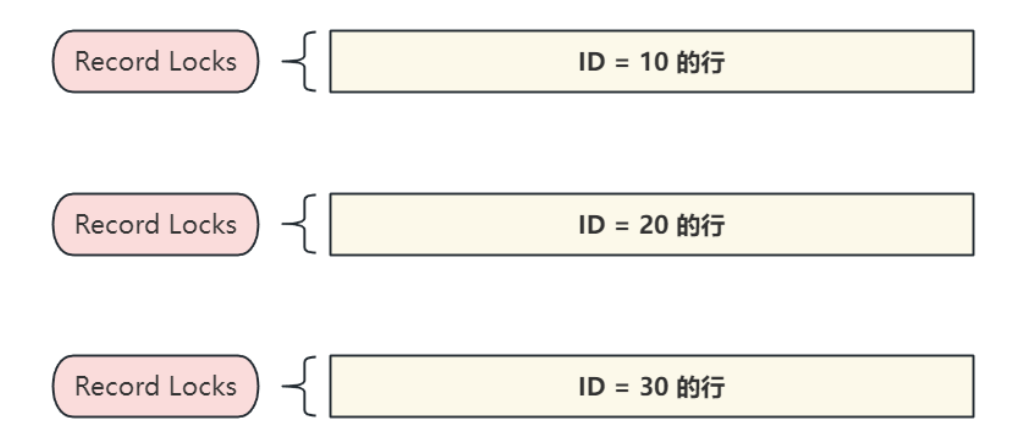
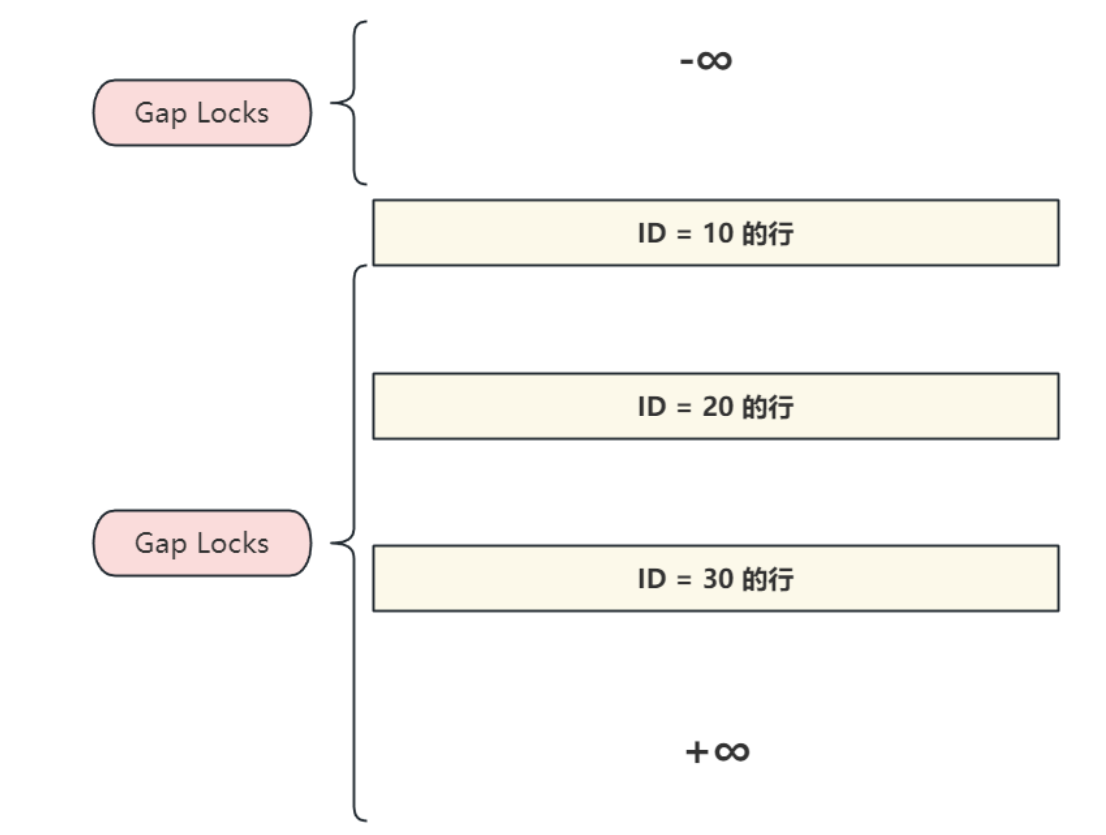
5) 間隙鎖 - Gap Locks
- 間隙鎖鎖定的是索引記錄之間的間隙,或者第?個索引記錄之前,再或者最后?個索引記錄之后的
間隙。如圖所示位置,根據不同的查詢條件都可能會加間隙鎖: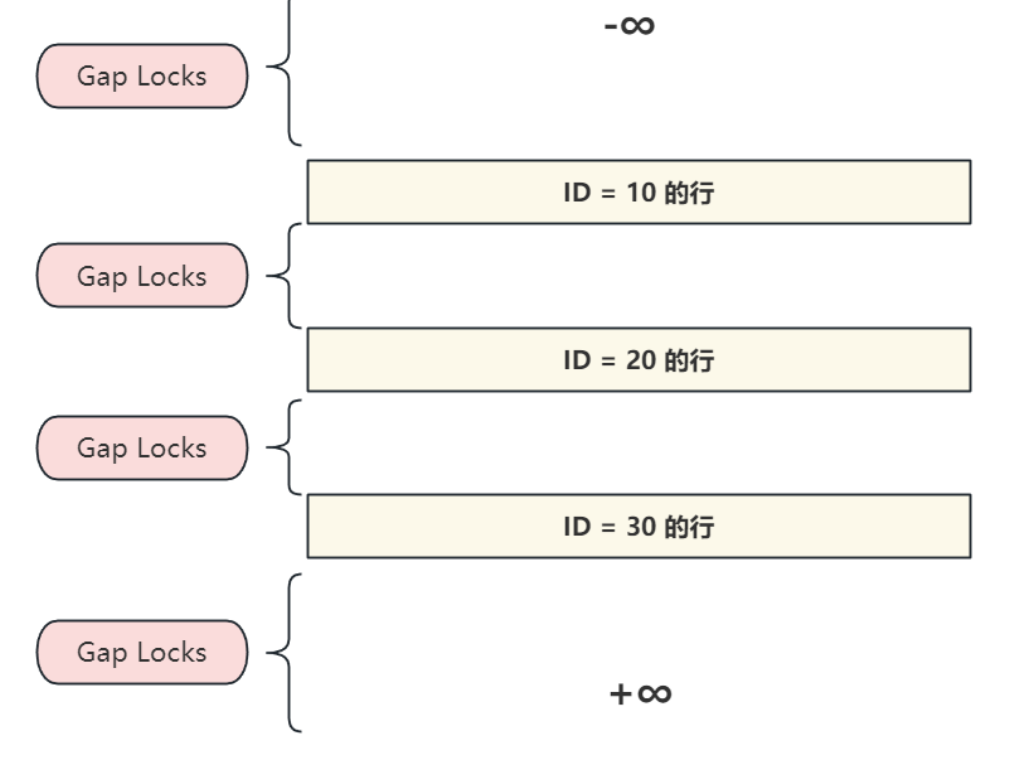
- 例如有如下SQL,鎖定的是ID (10,20)之間的間隙,注意不包括10和20的行,目的是防止其他事務將ID值為15的列插?到列 account 表中(無論是否已經存在要插入的數據列),因為指定范圍值之間的間隙被鎖定了;

- 間隙可以跨越單個或多個索引值;
- 對于使?唯?索引查詢到的唯一行,不使?間隙鎖,如下語句,id列有唯一的索引,只對id值為100的行使用索引記錄鎖:
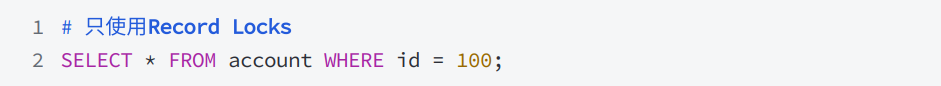
- 如果id沒有被索引,或者是一個非唯一的索引,以上語句將鎖定對應記錄前?的間隙;
- 不同事務的間隙鎖可以共存, 一個事務的間隙鎖不會阻止另一個事務在相同的間隙上使?間隙鎖;共享間隙鎖和獨占間隙鎖之間沒有區別。
- 當事務隔離級別設置為 READ COMMITTED 時間隙鎖會被禁?,對于搜索和索引掃描不再使?間
隙鎖定。
6) 臨鍵鎖 - Next-Key Locks
- Next-key 鎖是索引記錄鎖和索引記錄之前間隙上間隙鎖的組合,如圖所示;
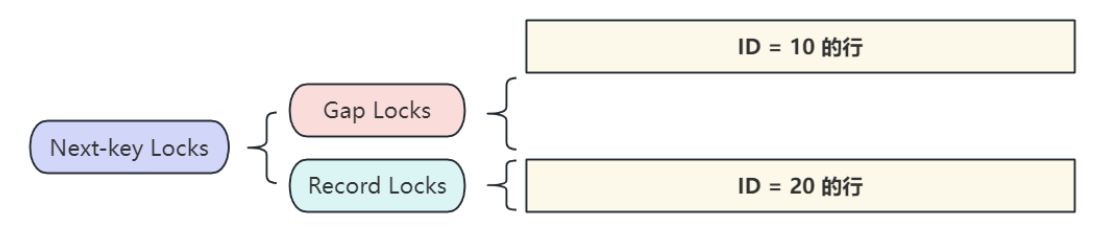
- InnoDB搜索或掃描?個表的索引時,執行行級鎖策略,具體方式是:在掃描過程中遇到的索引記錄上設置共享鎖或排他鎖,因此,行級鎖策略實際上應用的是索引記錄鎖。索引記錄上的 nextkey 鎖也會影響該索引記錄之前的"間隙",也就是說, next-key 鎖是索引記錄鎖加上索引記錄前?的間隙鎖。如果?個會話對索引中的?條記錄R具有共享鎖或排他鎖,則另?個會話不能在索引記錄R之前的空?中插?新的索引記錄行。
- 假設索引包含值10、11、13和20,這些索引可能的 next-key 鎖覆蓋以下區間,其中圓括號表示不包含區間端點,方括號表示包含端點:

- 默認情況下, REPEATABLE READ 事務隔離級別開啟 next-key 鎖并進行搜索和索引掃描,可
以防止幻象行,從而解決幻讀問題。
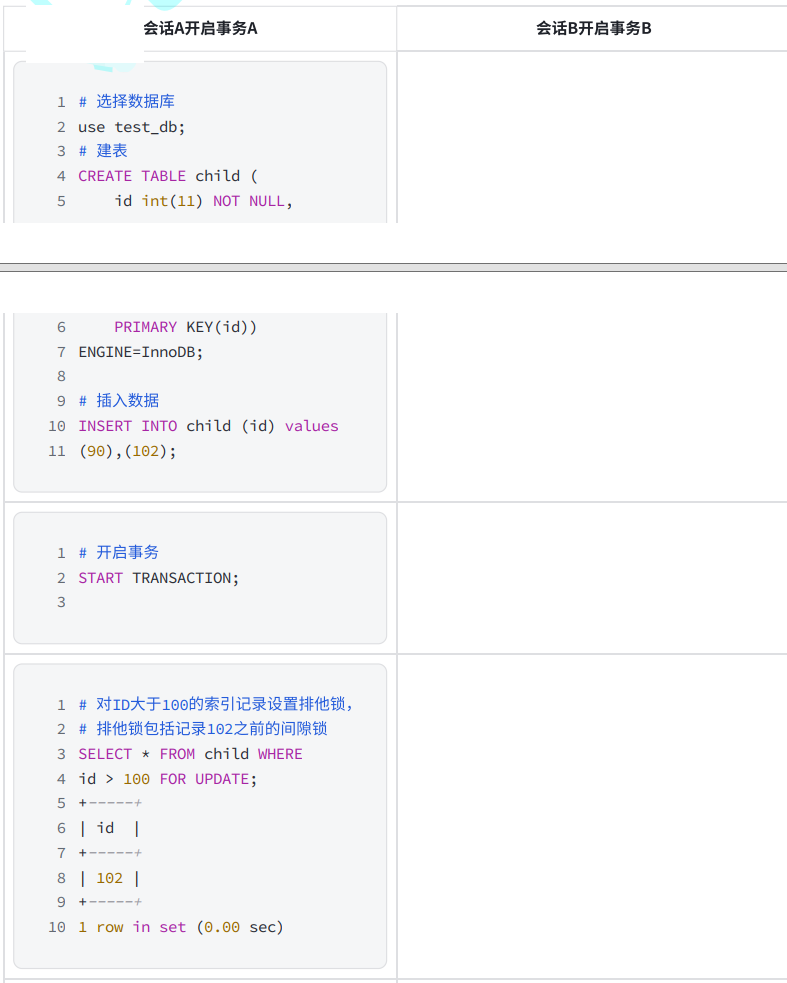
7) 插?意向鎖 - Insert Intention Locks
- 插?意向鎖是一個特殊的間隙鎖,在向索引記錄之前的間隙進行insert操作插?數據時使?,如果多個事務向相同索引間隙中不同位置插入記錄,則不需要彼此等待。假設已經存在值為10和20的索引記錄,兩個事務分別嘗試插入索引值為15和16的行,在獲得插入行上的排他鎖之前,每個事務都用插?意向鎖鎖住10到20之間的間隙,但不會相互阻塞,因為他們所操作的行并不沖突;
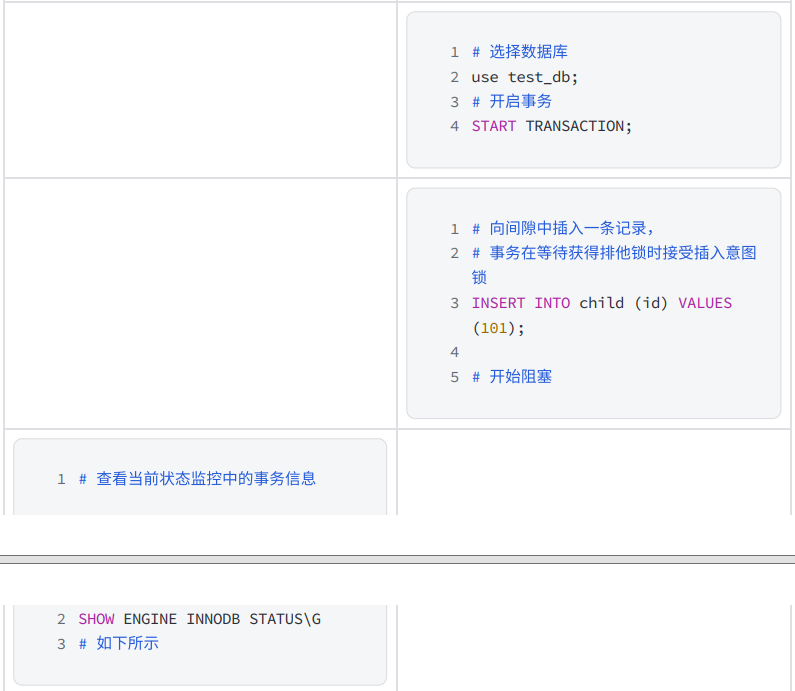
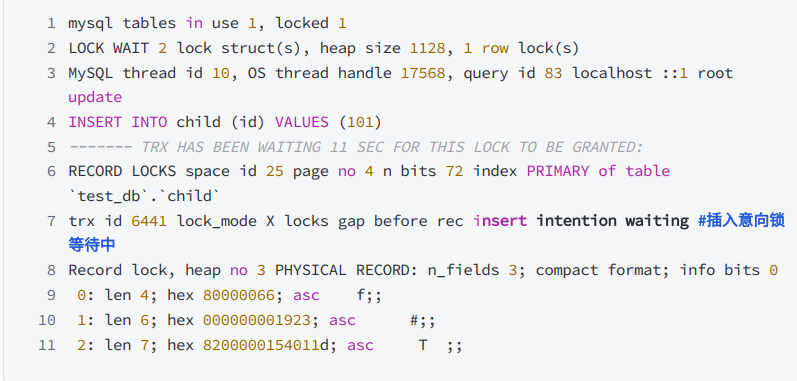
- 下面的示例演示一個事務在獲得插?記錄的排他鎖之前,使用了插入意向鎖:
8)AUTO-INC Locks
AUTO-INC鎖也叫自增鎖是?個表級鎖,服務于配置了 AUTO_INCREMENT ?增列的表。在插入數據時會在表上加自增鎖,并生成自增值,同時阻塞其他的事務操作,以保證值的唯一性。需要注意的
是,當?個事務執行新增操作已生成自增值,但是事務回滾了,申請到的主鍵值不會回退,這意味著
在表中會出現自增值不連續的情況。
9)死鎖
(1)示例
-
由于每個事務都持有另一個事務所需的鎖,導致事務無法繼續進行的情況稱為死鎖。以下圖為例,
兩個事務都不會主動釋放自己持有的鎖,并且都在等待對方持有的資源變得可用。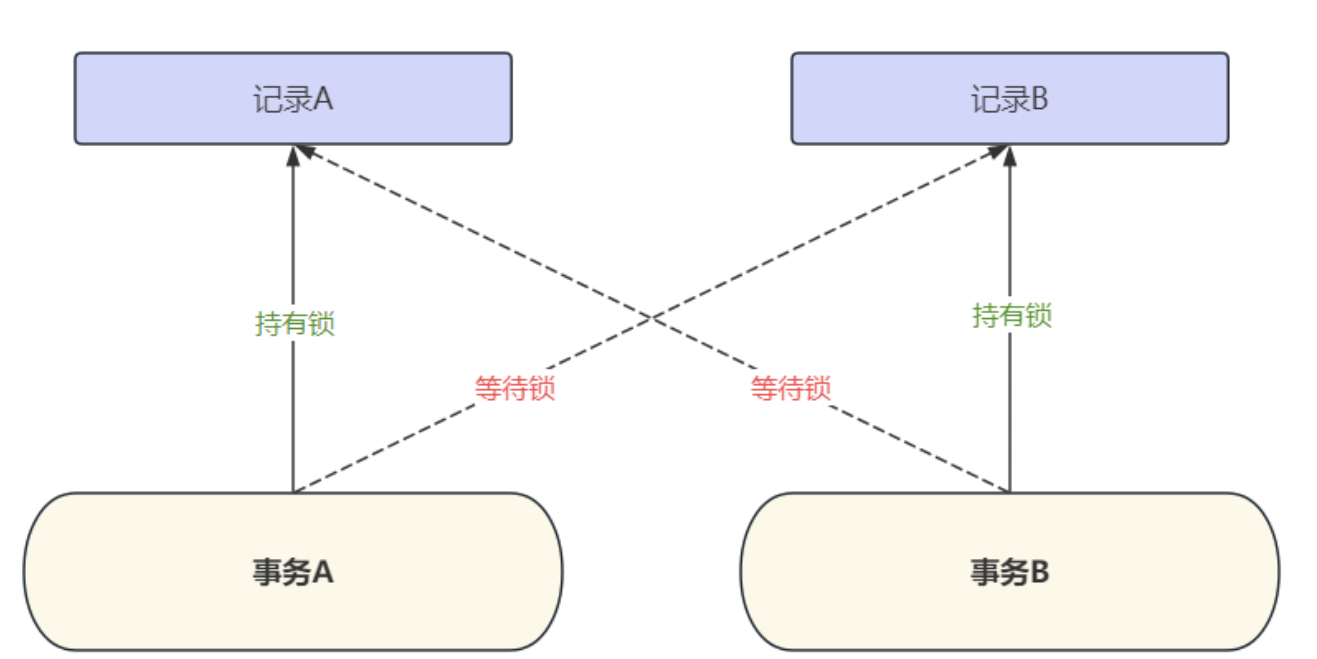
-
下?通過?個示例演示?下死鎖的發生過程,其中涉及兩個客戶端A和B,并通過啟用全局變量
innodb_print_all_deadlocks 來查看死鎖的信息,同時死鎖信息也會保存到錯誤日志中 -
?先打開?個客戶端A,并執行以下操作

-
接下來,打開客戶端B并執行以下操作
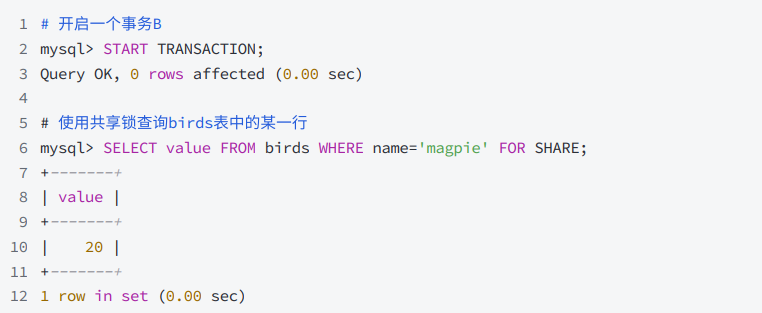
-
在另?個客戶端中查看兩個select操作持有的鎖信息
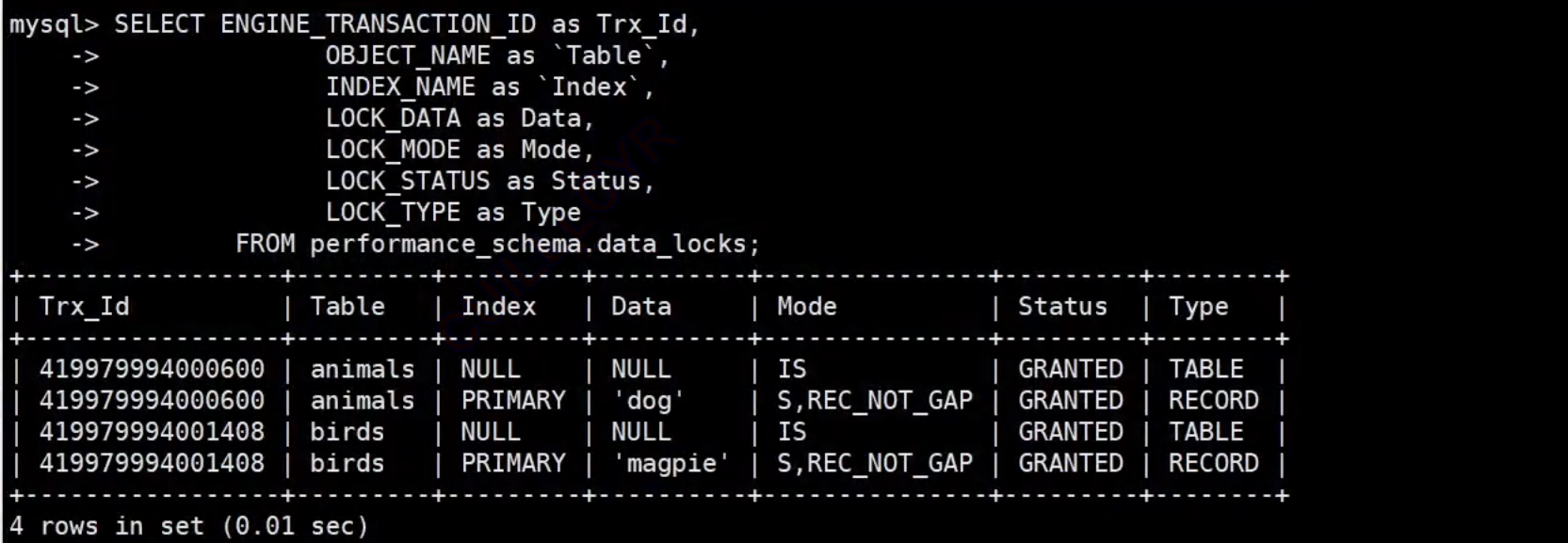
-
在客戶端B中更新animals表中的行

-
客戶B開始等待,可以查看鎖的等待信息:
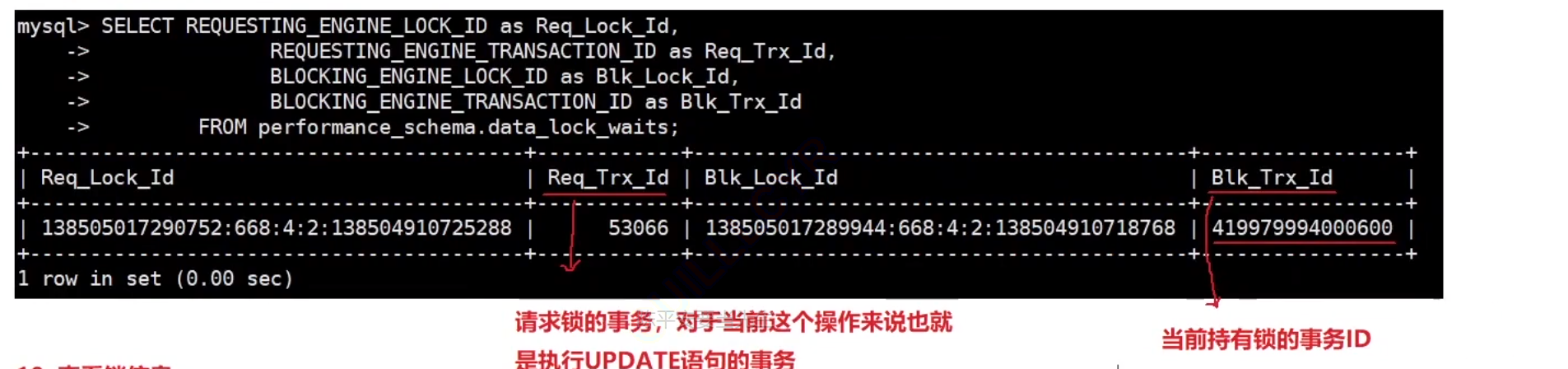
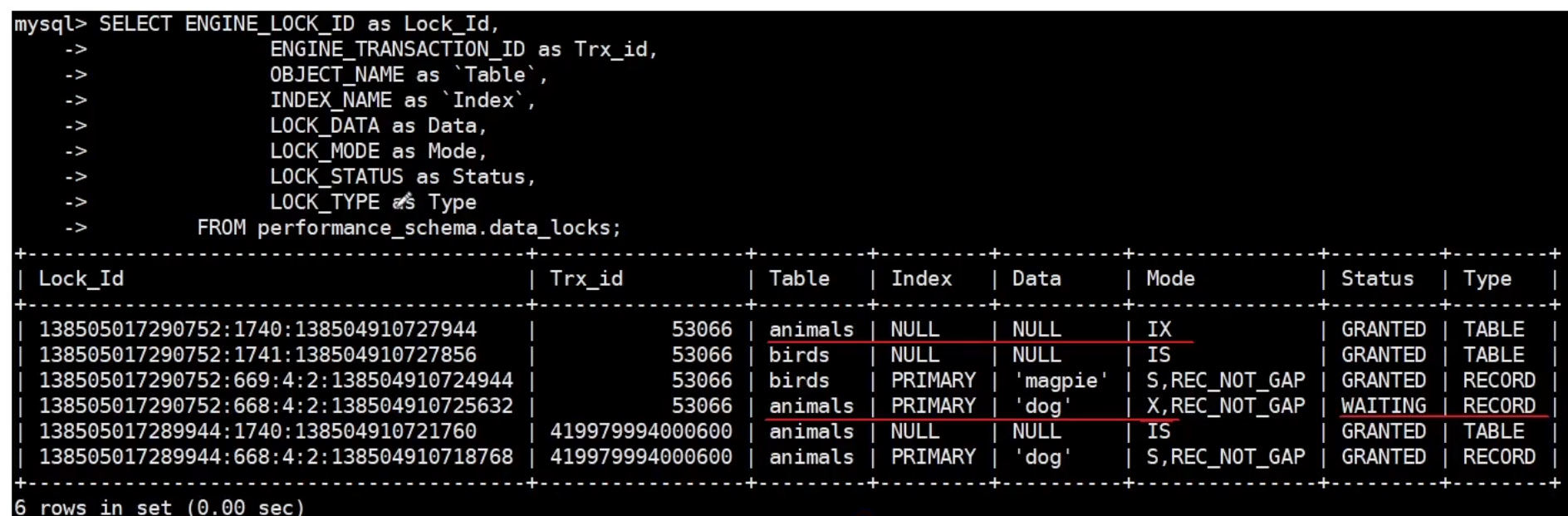
-
InnoDB只有在事務試圖修改數據時才使?順序事務id,之前的只讀事務id由411549995855872變為52005
-
如果客戶端A試圖同時更新birds中的一行,將導致死鎖

-
死鎖發?時,InnoDB主動回滾導致死鎖的事務,此時可以看到客戶端B的更新執行成功。

-
可以通過以下方式查看當前服務器發生死鎖的次數

-
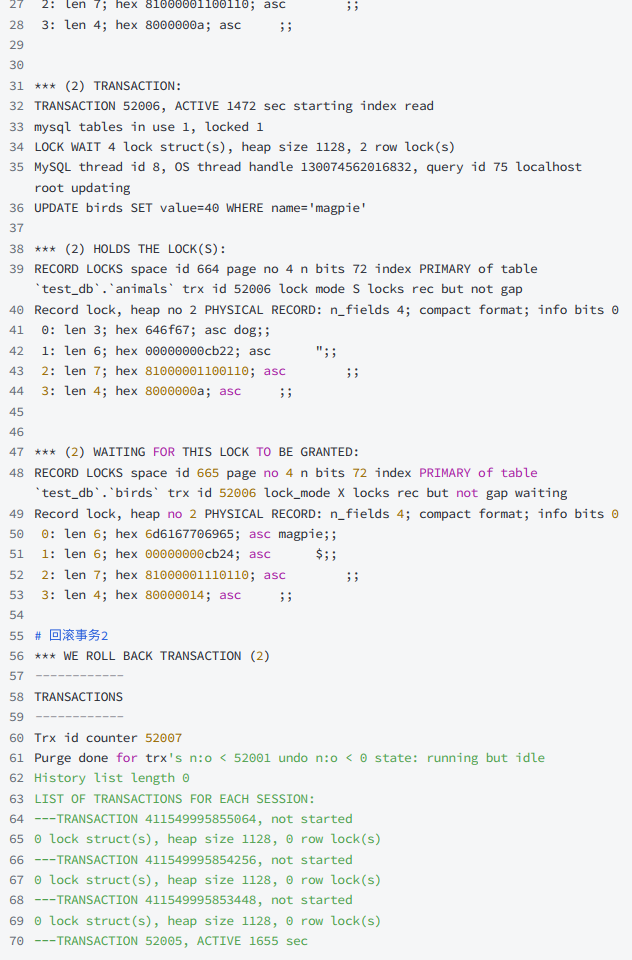
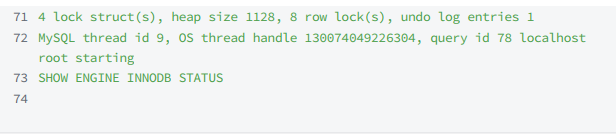
InnoDB的j監視器包含了關于死鎖和事務的相關信息,可以通過 SHOW ENGINE INNODB
STATUS; 查看 LATEST DETECTED DEADLOCK 節點的內容
-
錯誤?志中也記錄了死鎖相關的信息
(2)死鎖產生的條件
- 互斥訪問:如果線程1獲取到了鎖A,那么線程2就不能同時得到鎖A
- 不可搶占:獲取到鎖的線程,只能??主動釋放鎖,別的線程不能從他的?中搶占鎖
- 保持與請求:線程1已經獲得了鎖A,還要在這個基礎上再去獲了鎖B
- 循環等待:線程1等待線程2釋放鎖,線程2也等待線程1釋放鎖,死鎖發?時系統中?定有由兩個或兩個以上的線程組成的?條環路,該環路中的每個線程都在等待著下?個進程釋放鎖以上四條是造成死鎖的必要條件,必須同時滿?,所以如果想要打破死鎖,可以破壞以上四個條件之?,最常見的方式就是打破循環等待
(3)InnoDB對死鎖的檢測
- InnoDB在運行時會對死鎖進行檢測,當死鎖檢測啟?時(默認),InnoDB?動檢測事務死鎖,并回
滾?個或多個事務來打破死鎖。InnoDB嘗試選擇?事務進?回滾,其中事務的大小由插入、更新
或刪除的行數決定。 - 如果系統變量 innodb_table_locks = 1 (默認) 和 autocommit = 0 ,InnoDB可以檢測到表級鎖和?級鎖級別發?的死鎖;否則,?法檢測到由 lock TABLES 語句設置的表鎖或由?InnoDB存儲引擎設置的鎖,對于?法檢測到的死鎖,可以通過設置系統變量innodb_lock_wait_timeout 的值來指定鎖的超時時間來解決死鎖問題- 當超過 200 個事務等待鎖資源或等待的鎖個數超過 1,000,000 個時也會被視為死鎖,并嘗試將等待列表的事務回滾。
- 在?并發系統中,多個線程等待相同的鎖時,死鎖檢測可能會導致性能降性變慢,此時禁?死鎖檢
測并依賴 innodb_lock_wait_timeout 設置進行事務回滾可能性能更?。可以通過設置系統變量 innodb_deadlock_detect[={OFF|ON}] 禁?死鎖檢測。
(4)如何避免死鎖
- MySQL是?個多線程程序,死鎖的情況?概率會發?,但他并不可怕,除?頻繁出現,導致無法運行某些事務
- InnoDB使用自動行級鎖,即使在只插入或刪除單行的事務中,也可能出現死鎖。這是因為插?或
刪除行并不是真正的"原?"操作,同時會對索引記錄進行修改并設置鎖 - 使?以下技術來處理死鎖并降低發生死鎖的可能性:
- 使?事務?不是使? LOCK TABLES 語句?動加鎖,并使用innodb_lock_wait_timeout 變量設置鎖的超時時間,保證任何情況下鎖都可以?動釋放
- 經常使? SHOW ENGINE INNODB STATUS 命令來確定最近?次死鎖的原因。這可以幫助我
們修改應?程序以避免死鎖 - 如果出現頻繁的死鎖警告,可以通過啟? innodb_print_all_deadlocks 變量來收集調試信息。對于死鎖的信息,都記錄在MySQL錯誤?志中,調試完成后記得禁?此選項
- 如果事務由于死鎖而失敗,記得重新發起事務,再執行?次
- 盡量避免大事務,保持事務粒度小且持續時間短,這樣事務之間就不容易發?沖突,從?降低
發?死鎖的概率 - 修改完成后立即提交事務也可以降低死鎖發?的概率。特別注意的是,不要在?個交互式會話
中?時間打開?個未提交的事務 - 當事務中要修改多個表或同?表中的不同?時,每次都要以?致的順序執行這些操作,使事務中的修改操作形成定義良好的隊列,可以避免死鎖。?不是在不同的位置編寫多個類似的INSERT、UPDATE和DELETE語句。我們寫的程序其實就是把?系列操作組織成?個方法或函數
- 向表中添加適當的索引,以便查詢時掃描更少的索引并設置更少的鎖,可以使用EXPLAIN SELECT來確定哪些索引用于當前的查詢
- 使用表級鎖防止對表進行并發更新,可以避免死鎖,但代價是系統的并發性降低
- 如果在查詢時加鎖,比如 SELECT…FOR UPDATE 或 SELECT…FOR SHARE ,嘗試使?較低的隔離級別,比如 READ COMMITTED
4.查看并設置隔離級別
-
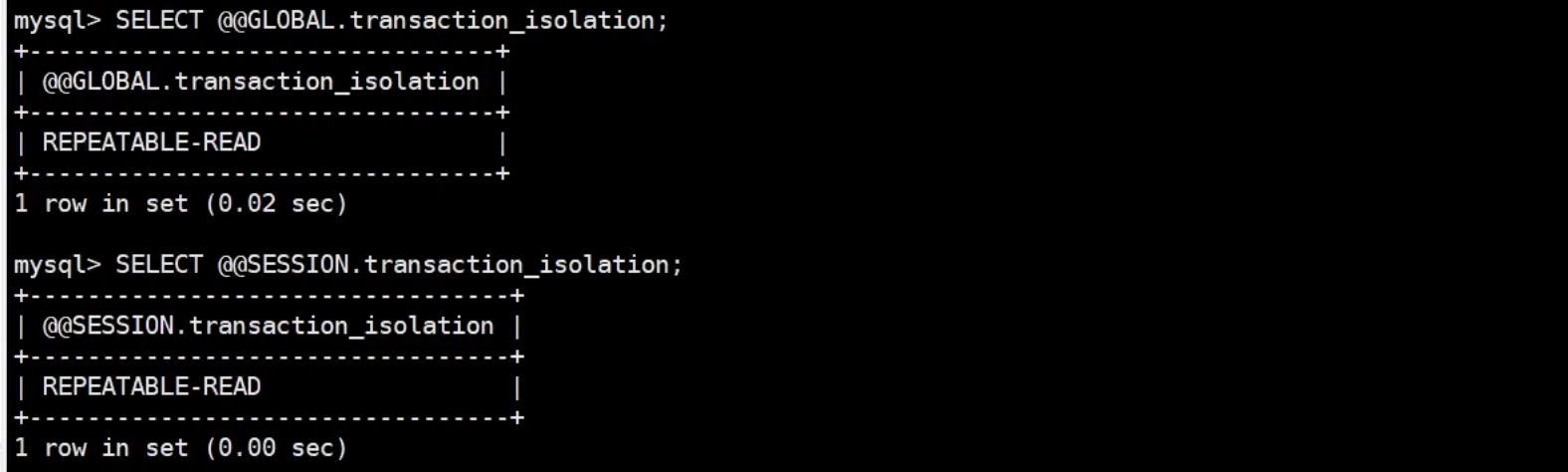
事務的隔離級別分為全局作?域和會話作?域,查看不同作?域事務的隔離級別,可以使用以下的
方式:

-
設置事務的隔離級別和訪問模式,可以使?以下語法:

-
通過選項?件指定事務的隔離級別,以便MySQL啟動的時候讀取并設置

TIPS:
官?MySQL8.0更新描述:The tx_isolation and tx_read_only system variables have been removed. Use transaction_isolation and transaction_read_only instead.所以在MySQL5.7及以前的版本中使用 tx_isolation 和 tx_read_only 來設置事務的隔離級別和訪問模式
- 通過SET語法設置系統變量的?式設置事務的隔離級別

- 設置事務隔離級別的語句不能在已開啟的事務中執?,否則將會報錯:

5. READ UNCOMMITTED - 讀未提交與臟讀
1) 實現方式
- 讀取時:不加任何鎖,直接讀取版本鏈中的最新版本,也就是當前讀,可能會出現臟讀,不可重復讀、幻讀問題;
- 更新時:加共享行鎖(S鎖),事務結束時釋放,在數據修改完成之前,其他事務不能修改當前數據,但可以被其他事務讀取。
2) 存在問題
事務的 READ UNCOMMITTED 隔離級別不使?獨占鎖,所以并發性能很高,但是會出現大量的數
據安全問題,比如在事務A中執行了?條 INSERT 語句,在沒有執行 COMMIT 的情況下,會在事務B
中被讀取到,此時如果事務A執行回滾操作,那么事務B中讀取到事務A寫?的數據將沒有意義,我們
把這個理象叫做 “臟讀” 。
3) 問題重現
- 在一個客戶端A中先設置全局事務隔離級別為 READ UNCOMMITTED 讀未提交:

- 打開另?個客?端B并確認隔離級別

- 在不同的客戶端中執行事務

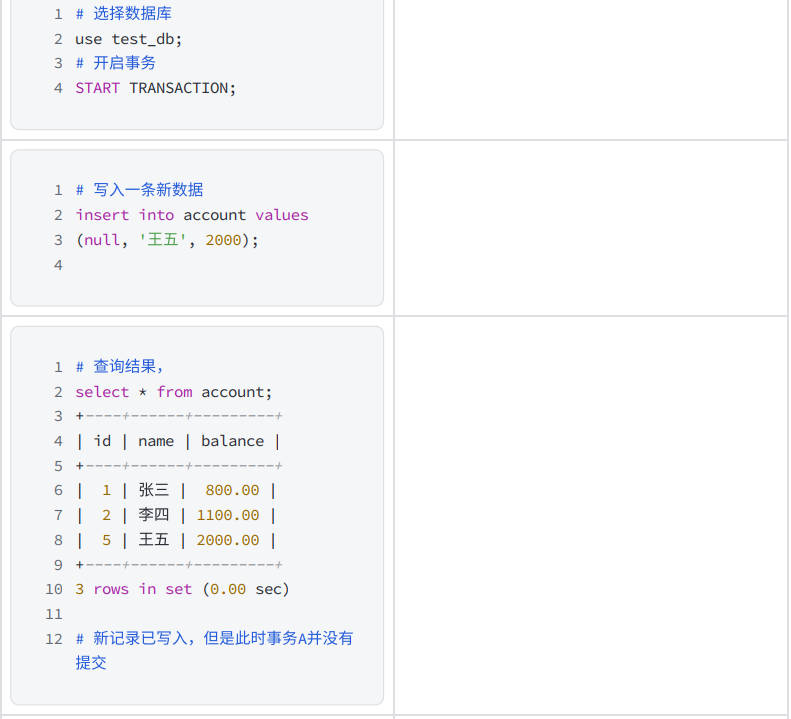

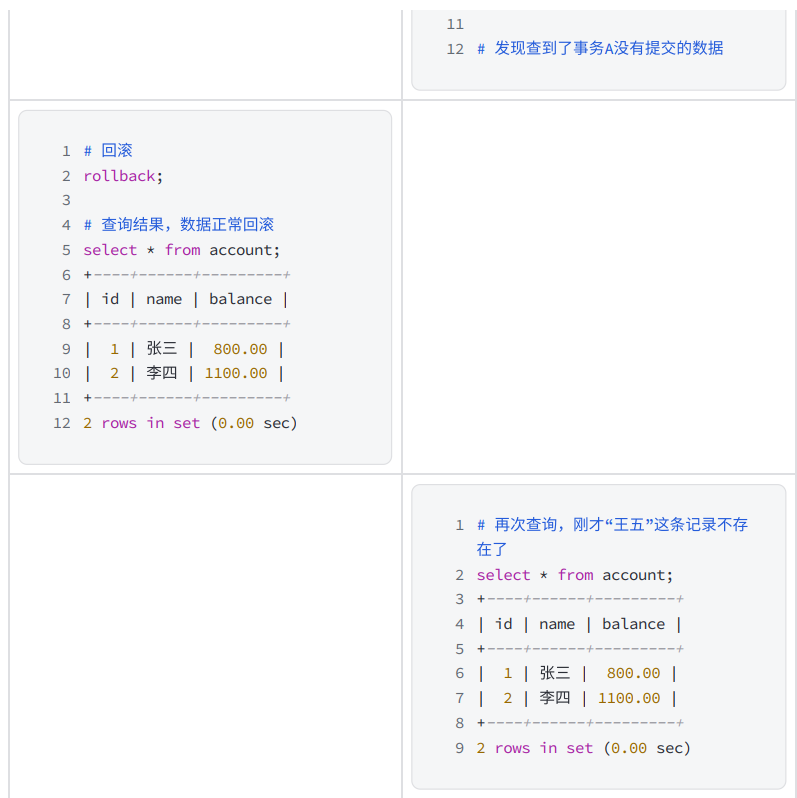
- 由于 READ UNCOMMITTED 讀未提交會出現"臟讀"現象,在正常的業務中出現這種問題會產?非
常危重后果,所以正常情況下應該避免使? READ UNCOMMITTED 讀未提交這種的隔離級別。
6. READ COMMITTED - 讀已提交與不可重復讀
1) 實現方式
- 讀取時:不加鎖,但使?快照讀,即按照 MVCC 機制讀取符合 ReadView 要求的版本數據,每次
查詢都會構造?個新的 ReadView ,可以解決臟讀,但?法解決不可重復讀和幻讀問題; - 更新時:加獨占?鎖(X),事務結束時釋放,數據在修改完畢之前,其他事務不能修改也不能讀取
這?數據。
2) 存在問題
為了解決臟讀問題,可以把事務的隔離級別設置為 READ COMMITTED ,這時事務只能讀到了其
他事務提交之后的數據,但會出現不可重復讀的問題,比如事務A先對某條數據進行了查詢,之后事務
B對這條數據進行了修改,并且提交( COMMIT )事務,事務A再對這條數據進行查詢時,得到了事務B
修改之后的結果,這導致了事務A在同?個事務中以相同的條件查詢得到了不同的值,這個現象要"不
可重復讀"。
3) 問題重現
-
在?個客戶端A中先設置全局事務隔離級別為 READ COMMITTED 讀未提交:

-
打開另?個客?端B并確認隔離級別

-
在不同的客戶端中執行事務

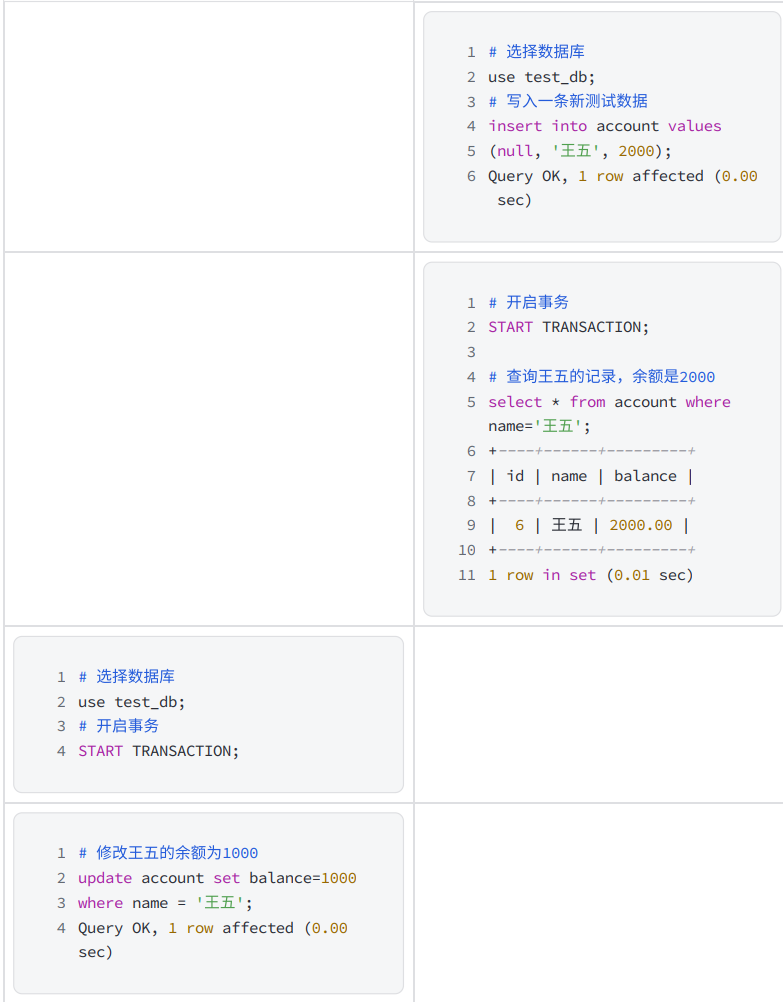
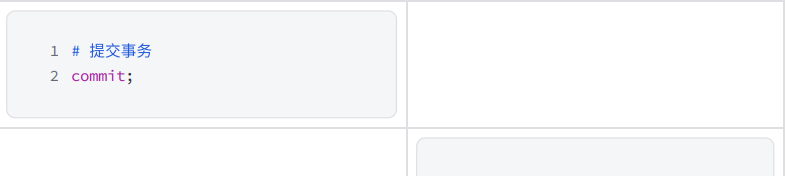
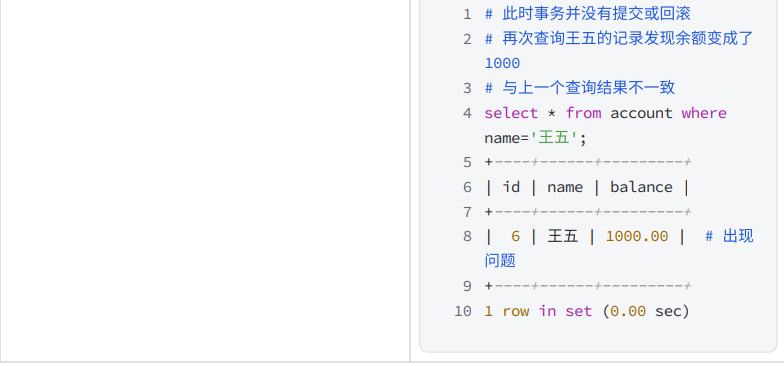
7. REPEATABLE READ - 可重復讀與幻讀
1)實現方式
- 讀取時:不加鎖,也使?快照讀,按照MVCC機制讀取符合ReadView要求的版本數據,但無論事務中有幾次查詢,只會在?次查詢時?成?個ReadView,可以解決臟讀、不可重復讀,配合Next-Key行鎖可以解決?部分幻讀問題;
- 更新時:加Next-Key行鎖,事務結束時釋放,在?個范圍內的數據修改完成之前,其他事務不能對這個范圍內的數據進行修改、插入和刪除操作,同時也不能被查詢。
2 )存在問題
事務的 REPEATABLE READ 隔離級別是會出現幻讀問題的,在 InnoDB 中使?了Next-Key行鎖來解決?部分場景下的幻讀問題,那么在不加 Next-Key ?鎖的情況下會出現什么問題嗎?
我們知道 Next-Key 鎖,鎖住的是當前索引記錄以及索引記錄前?的間隙,那么在不加 NextKey 鎖的情況下,也就是只對當前修改?加了獨占?鎖(X),這時記錄前的間隙沒有被鎖定,其他的事務就可以向這個間隙中插?記錄。
就會導致?個問題:事務A查詢了?個區間的記錄得到結果集A,事務B向這個區間的間隙中寫?了?條記錄,事務A再查詢這個區間的結果集時會查到事務B新寫?的記錄得到結果集B,兩次查詢的結果集不?致,這個現象就是"幻讀"。
3) 問題重現
-
由于 REPEATABLE READ 隔離級別默認使?了 Next-Key 鎖,為了重現幻讀問量,我們把隔離
級回退到更新時只加了排他鎖的 READ COMMITTED .

-
在不同的客戶端中執行事務

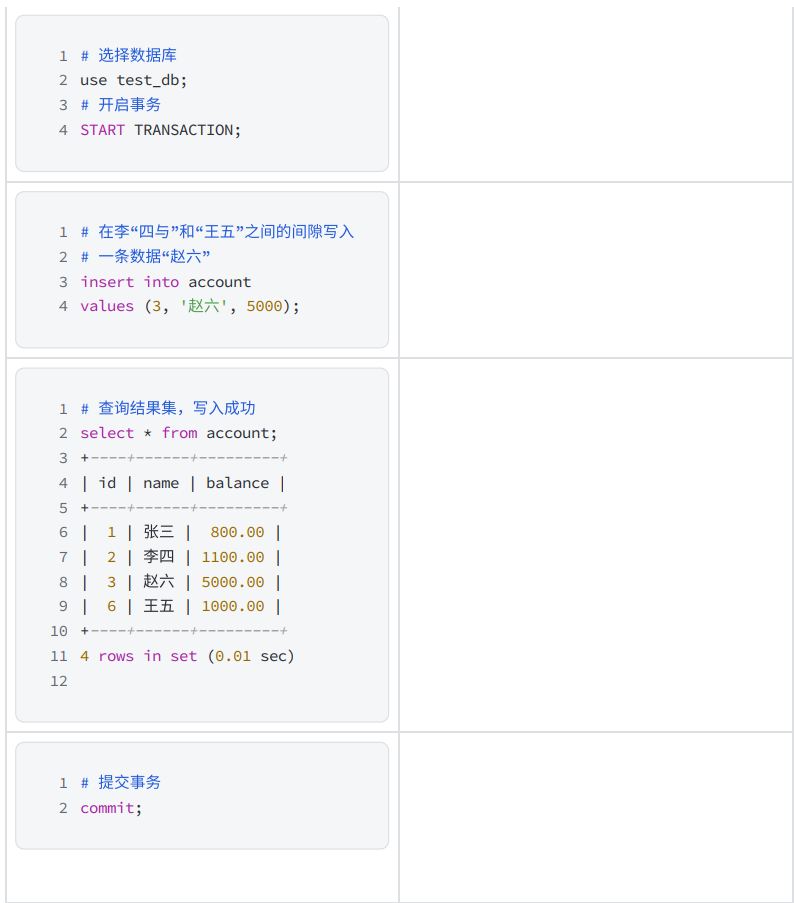

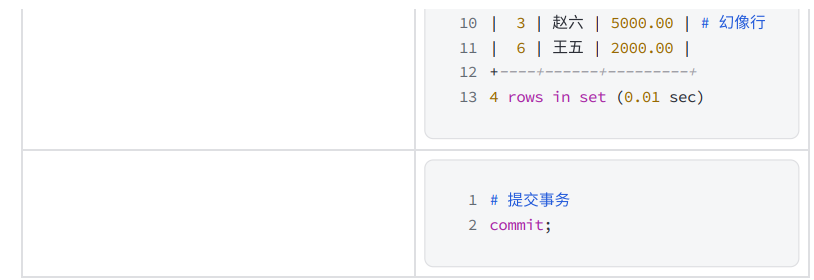
8 SERIALIZABLE - 串行化
1) 實現方式
- 讀取時:加共享表鎖,讀取版本鏈中的最新版本,事務結束時釋放;
- 更新時:加獨占表鎖,事務結束時釋放,完全串行操作,可以解決所有事務問題。
2) 存在問題
所有的更新都是串行操作,效率極低。
9 不同隔離級別的性能與安全
10.多版本控制(MVCC)
上?個小節介紹了實現事務隔離性的鎖機制,但是頻繁加鎖與釋放鎖會對性能產生比較大的影響,為了提高性能,InnoDB與鎖配合,同時采用另?種事務隔離性的實現機制 MVCC ,即 MultiVersioned Concurrency Control 多版本并發控制,?來解決臟讀、不可重復讀等事務之間讀寫問題,MVCC 在某些場景中替代了低效的鎖,在保證了隔離性的基礎上,提升了讀取效率和并發性。
1)實現原理
(1)版本鏈
- MVCC的實現是基于 Undo Log 版本鏈和 ReadView 來完成的,Undo Log做為回滾的基礎,在執行Update或Delete操作時,會將每次操作的上?個版本記錄在Undo Log中,每條Undo Log中都記錄?個叫做 roll_pointer 的引用信息,通過 roll_pointer 就可以將某條數據對應的Undo Log組織成?個Undo鏈,在數據行的頭部通過數據行中的 roll_pointer 與Undo Log中的第一條?志進?關聯,這樣就構成?條完整的數據版本鏈,如下圖所示:
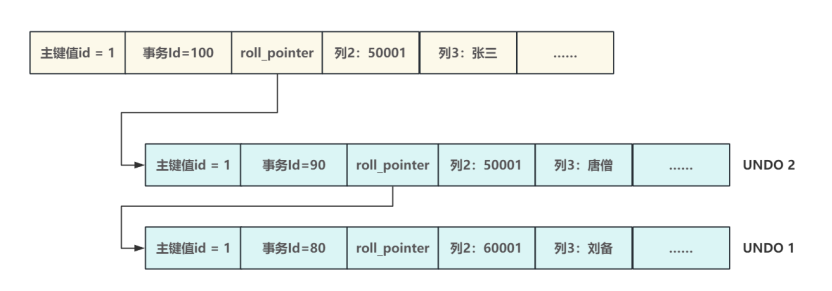
- 每?條被修改的記錄都會有?條版本鏈,體現了這條記錄的所有變更,當有事務對這條數據進行修
改時,將修改后的數據鏈接到版本鏈接的頭部,如下圖中 UNDO3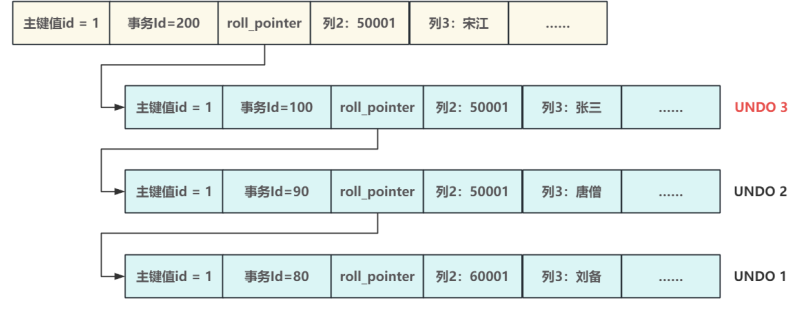
(2) ReadView
- 每條數據的版本鏈都構造好之后,在查詢時具體選擇哪個版本呢?這?就需要使? ReadView 結
構來實現了,所謂 ReadView 是?個內存結構,顧名思義是?個視圖,在事務使? select 查詢
數據時就會構造?個ReadView,??記錄了該版本鏈的?些統計值,這樣在后續查詢處理時就不
?遍歷所有版本鏈了,這些統計值具體包括:- m_ids :當前所有活躍事務的集合
- m_low_limit_id :活躍事務集合中最?事務Id
- m_up_limit_id :下?個將被分配的事務Id,也就是 最大的事務Id + 1
- m_creator_trx_id :創建當前 ReadView 的事務Id
- 對應的源碼如下
/*****************************************************************************
/** @file include/read0types.h
Cursor read
Created 2/16/1997 Heikki Tuuri
*******************************************************/
// ... 省略
// Friend declaration
class MVCC;
/** Read view lists the trx ids of those transactions for which a consistent
read should not see the modifications to the database. */
class ReadView {
// ... 省略
private:
/** The read should not see any transaction with trx id >= this
value. In other words, this is the "high water mark". */
trx_id_t m_low_limit_id; // ?于等于此值的是未開啟的事務,不可?
/** The read should see all trx ids which are strictly
smaller (<) than this value. In other words, this is the
low water mark". */
trx_id_t m_up_limit_id; // ?于此值的是已提交事務,可?
/** trx id of creating transaction, set to TRX_ID_MAX for free
views. */
trx_id_t m_creator_trx_id; // 創建當前ReadView的事務Id
/** Set of RW transactions that was active when this snapshot
was taken */
ids_t m_ids; // 當前所有活躍事務的集合
/** The view does not need to see the undo logs for transactions
whose transaction number is strictly smaller (<) than this value:
they can be removed in purge if not needed by other views */
// 如果當前ReadView和其他ReadView不需要事務Id?于此值的Undo?志,可以在purge階段刪
除
trx_id_t m_low_limit_no;
/** AC-NL-RO transaction view that has been "closed". */
bool m_closed; // 是否關閉標識
// ... 省略
};
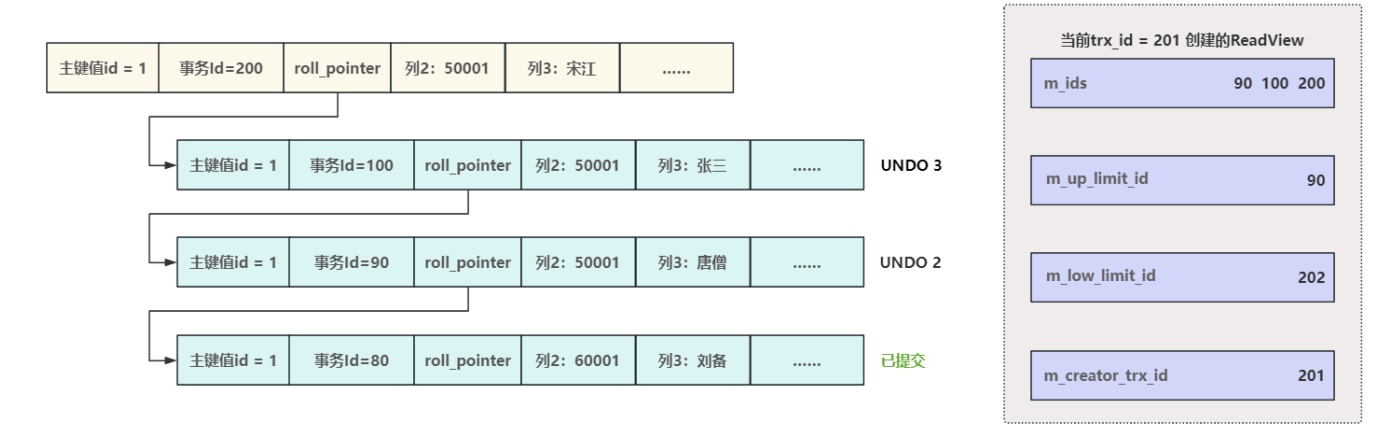
- 構造好 ReadView 之后需要根據?定的查詢規則找到唯?的可?版本,這個查找規則比較簡單,以下圖的版本鏈為例,在 m_creator_trx_id=201 的事務執行select 時,會構造?個ReadView 同時對相應的變量賦值
- m_ids :活躍事務集合為 [90, 100, 200]
- m_up_limit_id :活躍事務最小事務Id= 90
- m_low_limit_id :預分配事務ID= 202 ,最?事務Id=預分配事務ID-1= 201
- m_creator_trx_id :當前創建 ReadView 的事務Id= 201
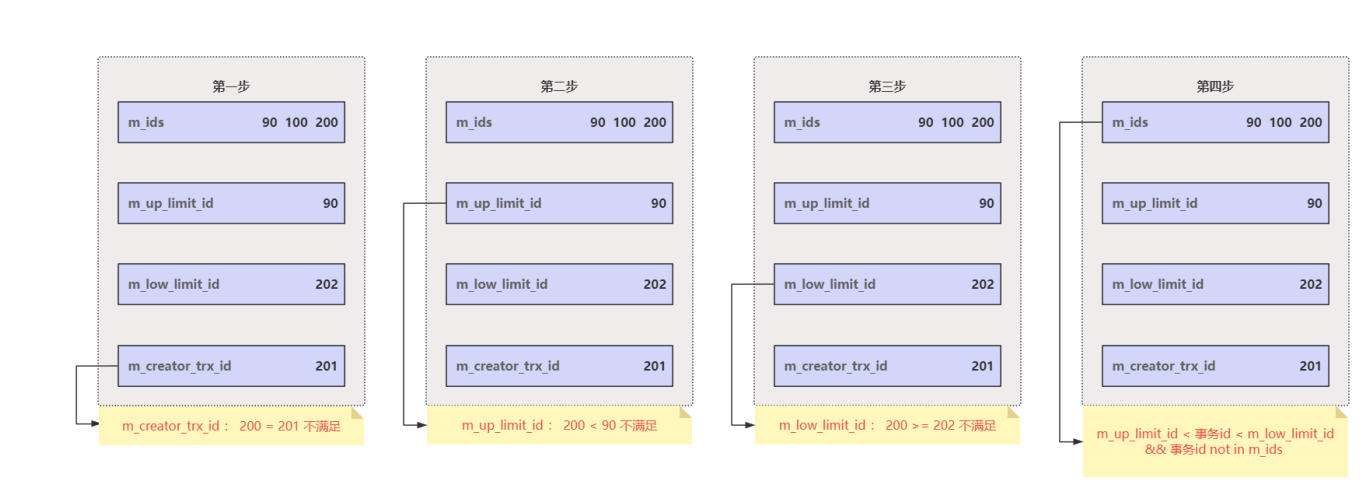
- 接下來找到版本鏈頭,從鏈頭開始遍歷所有版本,根據四步查找規則,判斷每個版本:
- 第?步:判斷該版本是否為當前事務創建,若 m_creator_trx_id 等于該版本事務id,意味
著讀取自己修改的數據,可以直接訪問,如果不等則到第?步 - 第?步:若該版本事務Id< m_up_limit_id (最?事務Id),意味著該版本在ReadView?成之前已經提交,可以直接訪問,如果不是則到第三步
- 第三步:若該版本事務Id>= m_low_limit_id (最?事務Id),意味著該版本在ReadView?成之后才創建,所以肯定不能被當前事務訪問,所以?需第四步判斷,直接遍歷下?個版本,如果不是則到第四步
- 第四步:若該版本事務Id在 m_up_limit_id (最?事務Id)和 m_low_limit_id (最?事務Id)之間,同時該版本不在活躍事務列表中,意味著創建ReadView時該版本已經提交,可以直接訪問,如果不是則遍歷并判斷下?個版本
- 第?步:判斷該版本是否為當前事務創建,若 m_creator_trx_id 等于該版本事務id,意味
- 這樣從版本鏈頭遍歷判斷到版本鏈尾,找到?個符合要求的版本即可,就可以實現查詢到的結果都
是已經提交事務的數據,解決了臟讀問題。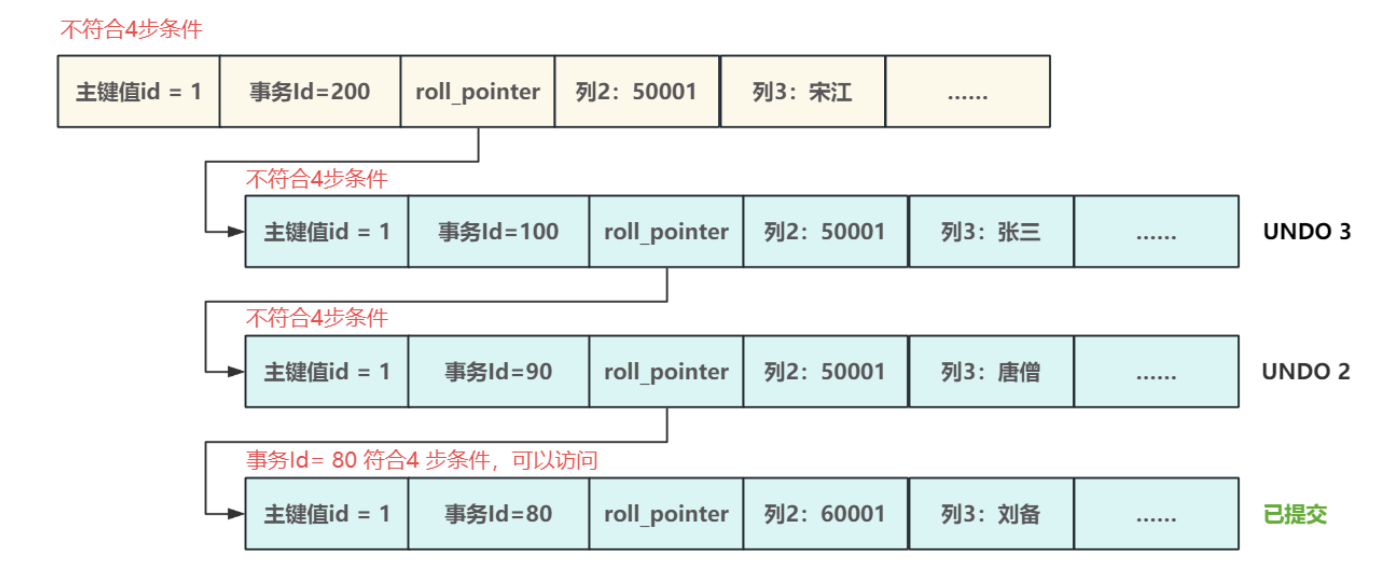
2)MVCC是否可以解決不可重復讀與幻讀
- ?先幻讀?法通過MVCC單獨解決
- 對于不可重復讀問題,在事務中的第?個查詢時創建?個ReadView,后續查詢都是?這個ReadView進?判斷,所以每次的查詢結果都是?樣的,從而解決不可重復讀問題,在REPEATABLE READ 可重復讀,隔離級別下就采?的這種方式
- 如果事務每次查詢都創建?個新的ReadView,這樣就會出現不可重復讀問題,在 READ
COMMITTED 讀已提交的隔離級別下就是這種實現方式









顯著提升一次性穿刺器產品合格率)

)



![c語言中的數組可以用int a[3]來創建。寫一次int就可以了,而java中要聲明兩次int類型像這樣:int[] arr = new int[3];](http://pic.xiahunao.cn/c語言中的數組可以用int a[3]來創建。寫一次int就可以了,而java中要聲明兩次int類型像這樣:int[] arr = new int[3];)
)

)
