目錄
一、從代碼看 CNN 的核心組件
二、準備工作:庫導入與數據加載
三、核心:用代碼實現 CNN 并理解各層作用
1.網絡層結構
2.重點理解:卷積層參數與輸出尺寸計算
四、訓練 CNN
五、結果分析
卷積神經網絡(CNN)是計算機視覺領域的核心模型,相比全連接網絡,它能更高效地提取圖像特征。本文不空談理論,而是通過 PyTorch 代碼實現一個完整的 CNN 模型,帶你在實戰中理解卷積、池化等核心概念,掌握 CNN 的工作原理。
一、從代碼看 CNN 的核心組件
在實現模型前,先明確 CNN 的三個核心層 —— 這些是區別于全連接網絡的關鍵,后續代碼會逐一對應:
- 卷積層(Conv2d):通過滑動窗口提取局部特征(如邊緣、紋理);
- 激活層(ReLU):引入非線性,讓模型學習復雜模式;
- 池化層(MaxPool2d):降低特征圖尺寸,減少計算量,增強魯棒性。
我們將用這些組件構建一個識別 MNIST 手寫數字的 CNN 模型,邊寫代碼邊解釋原理。
二、準備工作:庫導入與數據加載
首先導入必要的庫,加載 MNIST 數據集(28×28 的手寫數字圖片):
import torch
from torch import nn
from torch.utils.data import DataLoader
from torchvision import datasets
from torchvision.transforms import ToTensor# 加載MNIST數據集
training_data = datasets.MNIST(root="data",train=True,download=True,transform=ToTensor() # 轉為張量,形狀為[1,28,28]
)
test_data = datasets.MNIST(root="data",train=False,download=True,transform=ToTensor()
)# 按批次加載數據(每批64張圖)
batch_size = 64
train_dataloader = DataLoader(training_data, batch_size=batch_size)
test_dataloader = DataLoader(test_data, batch_size=batch_size)# 查看數據形狀([批次, 通道, 高度, 寬度])
for X, y in test_dataloader:print(f"數據形狀: {X.shape}") # 輸出:torch.Size([64, 1, 28, 28])break
關鍵說明:MNIST 圖片是單通道(灰度圖),所以輸入形狀為[N,1,28,28](N 為批次大小),這會影響后續卷積層的參數設置。
三、核心:用代碼實現 CNN 并理解各層作用
1.網絡層結構
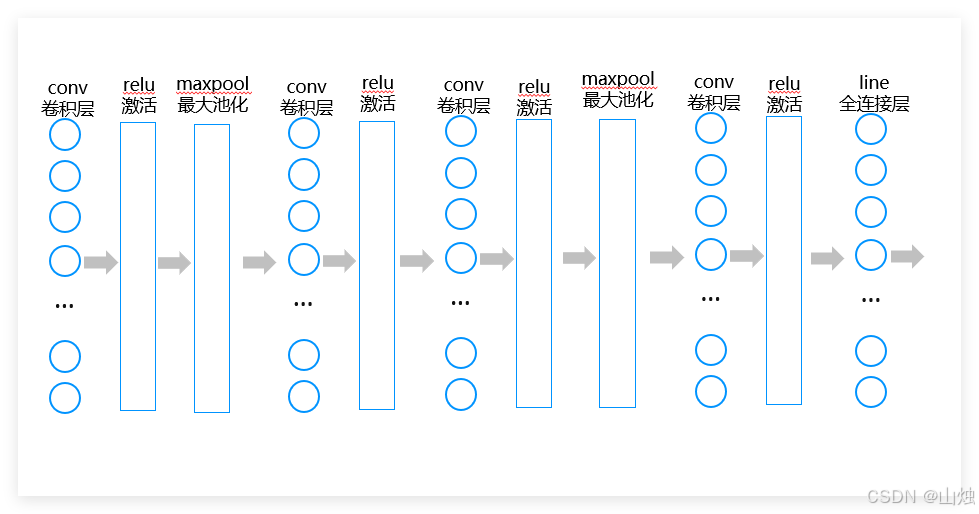
我們構建一個包含 4 個卷積塊的 CNN 模型,每個卷積塊由 “卷積層 + 激活層” 組成,部分塊后添加池化層。通過代碼注釋詳細說明每層的作用和參數含義。
# 自動選擇設備(優先GPU)
device = "cuda" if torch.cuda.is_available() else "cpu"
print(f"使用設備: {device}")class CNN(nn.Module):def __init__(self):super(CNN, self).__init__()# 第一個卷積塊:卷積層+激活層+池化層self.conv1 = nn.Sequential(# 卷積層:輸入1通道,輸出16通道,卷積核5×5,步長1,填充2nn.Conv2d(in_channels=1, # 輸入通道數(灰度圖為1)out_channels=16, # 輸出通道數(16個不同的卷積核)kernel_size=5, # 卷積核大小5×5stride=1, # 步長1(每次滑動1個像素)padding=2 # 填充2(保持輸出尺寸與輸入一致:28→28)),nn.ReLU(), # 激活層:引入非線性,過濾負值# 池化層:2×2窗口,步長2,輸出尺寸變為14×14(28/2)nn.MaxPool2d(kernel_size=2, stride=2))# 第二個卷積塊:卷積層+激活層(無池化)self.conv2 = nn.Sequential(# 輸入16通道(上一層輸出),輸出32通道,卷積核3×3nn.Conv2d(16, 32, kernel_size=3, stride=1, padding=1),nn.ReLU() # 輸出尺寸保持14×14)# 第三個卷積塊:卷積層+激活層+池化層self.conv3 = nn.Sequential(nn.Conv2d(32, 64, kernel_size=3, stride=1, padding=1),nn.ReLU(),nn.MaxPool2d(2, 2) # 輸出尺寸變為7×7(14/2))# 第四個卷積塊:卷積層+激活層(無池化)self.conv4 = nn.Sequential(nn.Conv2d(64, 128, kernel_size=3, stride=1, padding=1),nn.ReLU() # 輸出尺寸保持7×7)# 全連接層:將特征圖轉為10個類別(0-9)self.fc = nn.Linear(128 * 7 * 7, 10) # 128通道×7×7尺寸def forward(self, x):# 前向傳播:數據依次經過各層x = self.conv1(x) # 輸出形狀:[N,16,14,14]x = self.conv2(x) # 輸出形狀:[N,32,14,14]x = self.conv3(x) # 輸出形狀:[N,64,7,7]x = self.conv4(x) # 輸出形狀:[N,128,7,7]x = x.view(x.size(0), -1) # 展平:[N,128×7×7]x = self.fc(x) # 輸出形狀:[N,10](10個類別分數)return x# 創建模型并移動到設備
model = CNN().to(device)
print("CNN模型結構:")
print(model)
2.重點理解:卷積層參數與輸出尺寸計算
以第一個卷積層為例,輸入是[64,1,28,28](64 張圖,1 通道,28×28),經過kernel_size=5, padding=2, stride=1的卷積后,輸出尺寸計算公式:
輸出尺寸 = (輸入尺寸 - 卷積核大小 + 2×填充) / 步長 + 1
即:(28 - 5 + 2×2)/1 + 1 = 28
所以輸出仍為 28×28,再經 2×2 池化后變為 14×14—— 這就是卷積層如何在保留特征的同時控制尺寸的核心邏輯。
四、訓練 CNN
CNN 的訓練流程和全連接網絡類似,我們將訓練輪次調整為 10 輪,既能保證模型收斂,又能節省訓練時間。定義訓練和測試函數如下:
# 損失函數(多分類用交叉熵)
loss_fn = nn.CrossEntropyLoss()
# 優化器(Adam,學習率0.0001)
optimizer = torch.optim.Adam(model.parameters(), lr=0.0001)# 訓練函數
def train(dataloader, model, loss_fn, optimizer):model.train() # 開啟訓練模式batch_num = 1for X, y in dataloader:X, y = X.to(device), y.to(device)# 前向傳播:計算預測pred = model(X)loss = loss_fn(pred, y)# 反向傳播:更新參數optimizer.zero_grad() # 梯度清零loss.backward() # 計算梯度optimizer.step() # 更新參數# 每100批次打印一次損失if batch_num % 100 == 1:print(f"批次 {batch_num} | 損失: {loss.item():.4f}")batch_num += 1# 測試函數
def test(dataloader, model, loss_fn):model.eval() # 開啟測試模式size = len(dataloader.dataset)num_batches = len(dataloader)correct = 0test_loss = 0with torch.no_grad(): # 禁用梯度計算for X, y in dataloader:X, y = X.to(device), y.to(device)pred = model(X)test_loss += loss_fn(pred, y).item()correct += (pred.argmax(1) == y).type(torch.float).sum().item()# 計算準確率和平均損失test_loss /= num_batchescorrect /= sizeprint(f"\n測試集:準確率 {100*correct:.2f}% | 平均損失 {test_loss:.4f}\n")# 開始訓練(10輪)
print("="*50)
print("開始訓練CNN模型(10輪)")
print("="*50)
for epoch in range(10):print(f"輪次 {epoch+1}/10")print("-"*30)train(train_dataloader, model, loss_fn, optimizer)# 每2輪測試一次if (epoch+1) % 2 == 0:test(test_dataloader, model, loss_fn)
print("="*50)
print("訓練結束")五、結果分析
輪次 10/10
------------------------------
批次 1 | 損失: 0.0002
批次 101 | 損失: 0.0000
批次 201 | 損失: 0.0015
批次 301 | 損失: 0.0190
批次 401 | 損失: 0.0003
批次 501 | 損失: 0.0008
批次 601 | 損失: 0.0001
批次 701 | 損失: 0.0065
批次 801 | 損失: 0.0019
批次 901 | 損失: 0.0310測試集:準確率 99.17% | 平均損失 0.0355==================================================
訓練結束即使只訓練 10 輪,CNN 在測試集上的準確率通常也能達到99% 以上,明顯高于同輪次的全連接網絡。這體現了 CNN 的高效性,原因在于:
- 局部感受野:卷積層通過滑動窗口只關注局部像素,更符合圖像的局部相關性;
- 權值共享:同一通道的卷積核參數共享,大幅減少參數數量(全連接層 784→128 需要近 10 萬個參數,而 5×5 的卷積層 1→16 僅需 400 個參數);
- 池化層:通過下采樣保留關鍵特征,增強模型對圖像位移、縮放的魯棒性。
這些特性讓 CNN 在較少的訓練輪次下就能達到較好的性能。







顯著提升一次性穿刺器產品合格率)

)



![c語言中的數組可以用int a[3]來創建。寫一次int就可以了,而java中要聲明兩次int類型像這樣:int[] arr = new int[3];](http://pic.xiahunao.cn/c語言中的數組可以用int a[3]來創建。寫一次int就可以了,而java中要聲明兩次int類型像這樣:int[] arr = new int[3];)
)

)

)
