論文(ICCV 2023):Scalable Diffusion Models with Transformers
代碼和工程網頁:https://www.wpeebles.com/DiT.html
DiTs(Diffusion Transformers)是首個基于Transformer架構的擴散模型!它在圖像的潛在空間上進行訓練,用transformer替換了常用的U-Net主干網絡;DiTs具備?可擴展性?,當增加Transformer的深度/寬度,或輸入token的數量時,計算復雜度變高(Gflops↑),生成質量往往更好(FID↓);在經典的ImageNet 256×256 和 512×512 的類別條件生成任務中,作者推出的DiT-XL/2模型在質量上打敗了當時其它所有的擴散模型(FID分別為3.04和2.27)。
當年Transformer架構的推出改變了NLP等領域的發展趨勢,在自回歸模型中被廣泛應用,但在其它生成建模框架中卻應用不多——比如擴散模型;擴散模型在圖像生成領域一直位于前列,當時普遍采用的是U-Net這類卷積網絡架構。
U-Net
2020年DDPM的這篇工作首次將U-Net作為擴散模型的核心架構,該網絡有以下幾點特性
1. 多特征提取:通過下采樣和上采樣結構,能捕捉圖像的全局和局部信息;
2. 跳躍連接:幫助保留低級特征(如邊緣、紋理),提升生成質量;
3. 計算高效:相比于純Transformer,卷積U-Net在圖像生成任務中更輕量。
其設計源于PixelCNN++和Conditional GANs,早期在生成模型中的應用包括逐像素生成圖像、用于圖像到圖像的轉換任務。在DDPM中用到的是其結合了ResNet和注意力機制的變體
1. 替換原始U-Net的普通卷積塊,改用殘差連接,緩解深層網絡梯度消失的問題;
2. 在低分辨率層(多次下采樣后)插入空間自注意力模塊,以捕捉長程依賴關系,算是受Transformer啟發在卷積架構中的局部使用;
3. 其他有用Group Normalization代替BatchNorm,對小批量更魯棒;采用自適應歸一化注入條件信息(如時間步、類別標簽)(代碼示例如下)
class adaLN_Zero_Block(nn.Module):def __init__(self, dim):super().__init__()self.norm = nn.LayerNorm(dim, elementwise_affine=False) # create a LayerNorm layer without learnable parameters, just for normalization (minus mean, divide by variance)self.adaLN = nn.Linear(dim, 6 * dim) # input condition c of shape [B, dim] -> 6 * dim parameters for AdaLNnn.init.zeros_(self.adaLN.weight) # zero initialization for the linear layer, so that it behaves like a standard LayerNorm at the beginningdef forward(self, x, c):gamma1, beta1, gamma2, beta2, alpha1, alpha2 = self.adaLN(c).chunk(6, dim=-1)x = alpha1 * x + gamma1 * self.norm(x) + beta1 # normalization + scaling and shifting (like residual connection)x = alpha2 * x + gamma2 * self.norm(x) + beta2return x因為DDPM的成功,故后續很多工作也一直沿用這種設計,而DiT的出現正反映了生成模型從卷積主導到注意力主導的趨勢。
動機
U-Net有一些歸納偏置(inductive bias),包括
1. 局部性:通過卷積核的局部感受野處理圖像,假設相鄰像素間強相關;
2. 平移等變性:卷積操作對于圖像平移具有不變性;
3. 層次化多尺度建模:通過上/下采樣結構可以捕捉不同尺度的特征。
傳統觀點認為這些是擴散模型高性能的關鍵,但作者認為這些偏置于擴散模型而言并不是必要的,完全可以用Tranformer替代。作者通過DiT證明,擴散模型的性能取決于計算資源和通用架構能力,而非特定的結構偏好。近年來深度學習不同任務和領域逐漸收斂到少數幾種通用架構,DiT的提出為擴散模型提供了更靈活的架構選擇,使其能受益于Transformer的擴展性和跨領域(NLP、CV……)技術積累。
ViT
20年提出的ViT(Vision Transformer)首次將純Transformer架構成功應用于圖像分類任務,核心是將圖像視為序列,用NLP中Transformer的方式處理圖像,打破傳統CNN在CV領域的主導地位。關鍵步驟為
1. 圖像分塊(patch embedding):將圖像分割為固定大小的path,每個patch展平為一個向量
2. 添加位置編碼(position embedding):由于Transformer本身不感知空間位置,需為每個patch添加可學習的位置編碼
3. 分類標記(class token):在序列開頭插入一個可學習的 [CLS] token,然后使用標準的Transformer編碼器(多頭注意力+MLP)處理patch序列,最后用 [CLS] token的輸出做分類
ViT無卷積操作,在中小規模數據集上表現可能不如CNN,但在超大數據集上顯著優于ResNet,且可擴展性強。
先驗知識
擴散方程
在高斯擴散模型中設定對真實數據的前向加噪過程為
,其中
是超參數,應用重參數化技巧,可通過下式直接對
進行采樣
,
擴散模型會學著如何去噪,的各式統計量
正是神經網絡要預測的東西,訓練損失是
的對數似然的變分下界,即
,再除以一個與訓練無關的附加項。
因為和
均為高斯分布,故可用它們的均值和協方差來評估DKL。將
重參數化為噪聲預測網絡
時,訓練損失可簡化為預測和實際噪聲之間的均方誤差,即
為了同時優化協方差矩陣,會用
訓練
的同時用完整損失
訓練
def training_losses(self, model, x_start, t, model_kwargs=None, noise=None):"""Compute training losses for a single timestep.:param model: the model to evaluate loss on.:param x_start: the [N x C x ...] tensor of inputs.:param t: a batch of timestep indices.:param model_kwargs: if not None, a dict of extra keyword arguments topass to the model. This can be used for conditioning.:param noise: if specified, the specific Gaussian noise to try to remove.:return: a dict with the key "loss" containing a tensor of shape [N].Some mean or variance settings may also have other keys."""# 前向計算if model_kwargs is None:model_kwargs = {}if noise is None:noise = th.randn_like(x_start)x_t = self.q_sample(x_start, t, noise=noise)terms = {}# 直接計算變分下界損失,適用于理論嚴格的訓練if self.loss_type == LossType.KL or self.loss_type == LossType.RESCALED_KL:# compute the variational lower-bound termterms["loss"] = self._vb_terms_bpd(model=model,x_start=x_start,x_t=x_t,t=t,clip_denoised=False,model_kwargs=model_kwargs,)["output"]if self.loss_type == LossType.RESCALED_KL:terms["loss"] *= self.num_timesteps# 簡化為均方誤差損失elif self.loss_type == LossType.MSE or self.loss_type == LossType.RESCALED_MSE:model_output = model(x_t, t, **model_kwargs)# 方差可學習時,也要為其計算變分下界if self.model_var_type in [ModelVarType.LEARNED,ModelVarType.LEARNED_RANGE,]:B, C = x_t.shape[:2]assert model_output.shape == (B, C * 2, *x_t.shape[2:])# 將模型輸出拆分為均值和方差model_output, model_var_values = th.split(model_output, C, dim=1)# 凍結均值部分的梯度,確保KL損失僅優化方差frozen_out = th.cat([model_output.detach(), model_var_values], dim=1)terms["vb"] = self._vb_terms_bpd(model=lambda *args, r=frozen_out: r,x_start=x_start,x_t=x_t,t=t,clip_denoised=False,)["output"]if self.loss_type == LossType.RESCALED_MSE:# Divide by 1000 for equivalence with initial implementation.# Without a factor of 1/1000, the VB term hurts the MSE term.(損失加權)terms["vb"] *= self.num_timesteps / 1000.0# 目標選擇 + 算MSEtarget = {ModelMeanType.PREVIOUS_X: self.q_posterior_mean_variance(x_start=x_start, x_t=x_t, t=t)[0],ModelMeanType.START_X: x_start,ModelMeanType.EPSILON: noise,}[self.model_mean_type]assert model_output.shape == target.shape == x_start.shapeterms["mse"] = mean_flat((target - model_output) ** 2)if "vb" in terms:terms["loss"] = terms["mse"] + terms["vb"]else:terms["loss"] = terms["mse"]else:raise NotImplementedError(self.loss_type)return terms
訓好后,初始化
,然后通過重參數化技巧采樣
。
免分類器指導CFG
條件擴散模型會拿額外信息作為輸入,比如類標簽c,如何讓生成的樣本既符合條件c又高質量呢?如分類器引導這類傳統方法會額外訓練一個分類器,而這里提出一種免分類器的方案,同樣可以幫助采樣過程找到最大化的
:
根據貝葉斯公式,有,故取梯度有
將模型輸出視作分數函數,、
,另外
不用分類器計算,而是視作條件修正項,通過條件預測
和無條件預測
的差進行估計
于是可通過下列式子引導采樣:
即對條件/無條件預測結果進行插值,其中s=1時,退化為普通條件采樣,s>1時增強條件控制,生成的樣本更符合c,但多樣性可能降低。在采樣過程中,會用引導后的
代替原始模型輸出
。
在訓練時,會隨機將條件c替換為“null”,讓模型同時學習條件生成和無條件生成
def forward_with_cfg(self, x, t, y, cfg_scale):"""實現帶免分類器指導(CFG)的模型前向傳播,同時處理條件/無條件預測y為條件標簽,形狀[2B],前B個為真實條件,后B個為空條件參考來自OpenAI的GLIDE項目"""half = x[: len(x) // 2]combined = torch.cat([half, half], dim=0) # 保證條件/無條件預測的噪聲完全一致model_out = self.forward(combined, t, y)# 將模型輸出分為兩部分,默認只對前3個通道(RGB)應用CFG# 當模型輸出通道數>3,或顯式配置了方差學習,或架構設計包含額外預測任務,rest都不為空eps, rest = model_out[:, :3], model_out[:, 3:]# 將噪聲預測eps分為條件/無條件兩部分,形狀均為[B, 3, H, W]cond_eps, uncond_eps = torch.split(eps, len(eps) // 2, dim=0)# 指導后輸出half_eps = uncond_eps + cfg_scale * (cond_eps - uncond_eps)eps = torch.cat([half_eps, half_eps], dim=0) # 保持形狀return torch.cat([eps, rest], dim=1)
...
# 在sample.py中的調用邏輯class_labels = [207, 360, 387, 974, 88, 979, 417, 279] # 條件化的類別索引列表
n = len(class_labels) # 要同時生成的圖像類別數n=8
z = torch.randn(n, 4, latent_size, latent_size, device=device) # 在淺空間標準正態分布采樣所得初始噪聲
y = torch.tensor(class_labels, device=device) # 打包成張量的條件信息# 設置免分類器引導
z = torch.cat([z, z], 0) # 用于條件/無條件生成的兩份數據
y_null = torch.tensor([1000] * n, device=device) # 將1000當作“null”
y = torch.cat([y, y_null], 0)
model_kwargs = dict(y=y, cfg_scale=args.cfg_scale) # 超參cfg_scale即s# 采樣
samples = diffusion.p_sample_loop(model.forward_with_cfg, z.shape, z, clip_denoised=False, model_kwargs=model_kwargs, progress=True, device=device
)
samples, _ = samples.chunk(2, dim=0)
samples = vae.decode(samples / 0.18215).sample # 0.18215是常見的尺度因子,潛在向量進入模型前乘以該值以匹配統計特性,故解碼時要移除save_image(samples, "sample.png", nrow=4, normalize=True, value_range=(-1, 1))作者將現成的VAEs混入基于Transformer的DDPMs
from diffusers.models import AutoencoderKL # 從Hugging Face上下載VAE
vae = AutoencoderKL.from_pretrained(f"stabilityai/sd-vae-ft-{args.vae}").to(device) # 拉取參數,兩類優化策略可選:均方誤差mse,指數移動平均ema
...
samples = vae.decode(samples / 0.18215).sample
...
# HF的庫中diffusers/models/autoencoders/vae.py,定義編碼器代碼如下
class Encoder(nn.Module):r"""The `Encoder` layer of a variational autoencoder that encodes its input into a latent representation.Args:in_channels (`int`, *optional*, defaults to 3):The number of input channels.out_channels (`int`, *optional*, defaults to 3):The number of output channels.down_block_types (`Tuple[str, ...]`, *optional*, defaults to `("DownEncoderBlock2D",)`):The types of down blocks to use. See `~diffusers.models.unet_2d_blocks.get_down_block` for available
卷積類(無注意力):DownBlock2D ResnetDownsampleBlock2D SkipDownBlock2D DownEncoderBlock2D KDownBlock2D
帶自注意力的(self-attention):AttnDownBlock2D AttnDownEncoderBlock2D AttnSkipDownBlock2D
帶跨注意力(cross-attention):CrossAttnDownBlock2D SimpleCrossAttnDownBlock2D KCrossAttnDownBlock2Doptions.block_out_channels (`Tuple[int, ...]`, *optional*, defaults to `(64,)`):The number of output channels for each block.layers_per_block (`int`, *optional*, defaults to 2):The number of layers per block.norm_num_groups (`int`, *optional*, defaults to 32):The number of groups for normalization.act_fn (`str`, *optional*, defaults to `"silu"`):The activation function to use. See `~diffusers.models.activations.get_activation` for available options.double_z (`bool`, *optional*, defaults to `True`):Whether to double the number of output channels for the last block."""def __init__(self,in_channels: int = 3,out_channels: int = 3,down_block_types: Tuple[str, ...] = ("DownEncoderBlock2D",),block_out_channels: Tuple[int, ...] = (64,),layers_per_block: int = 2,norm_num_groups: int = 32,act_fn: str = "silu",double_z: bool = True,mid_block_add_attention=True,):super().__init__()self.layers_per_block = layers_per_blockself.conv_in = nn.Conv2d(in_channels, block_out_channels[0], kernel_size=3, stride=1, padding=1,) # 將輸入通道數映射為第一個下采樣塊的通道數self.down_blocks = nn.ModuleList([])# down(逐步降低空間分辨率、增加通道數,提取高層語義特征)output_channel = block_out_channels[0]for i, down_block_type in enumerate(down_block_types):input_channel = output_channeloutput_channel = block_out_channels[i]is_final_block = i == len(block_out_channels) - 1down_block = get_down_block(down_block_type,num_layers=self.layers_per_block,in_channels=input_channel,out_channels=output_channel,add_downsample=not is_final_block, # 最后一層down_block不做下采樣resnet_eps=1e-6,downsample_padding=0,resnet_act_fn=act_fn,resnet_groups=norm_num_groups,attention_head_dim=output_channel,temb_channels=None,)self.down_blocks.append(down_block)# mid(保持空間分辨率不變,但可以增加感受野和特征交互)self.mid_block = UNetMidBlock2D(in_channels=block_out_channels[-1],resnet_eps=1e-6,resnet_act_fn=act_fn,output_scale_factor=1,resnet_time_scale_shift="default",attention_head_dim=block_out_channels[-1],resnet_groups=norm_num_groups,temb_channels=None,add_attention=mid_block_add_attention, # 加一個注意力層?)# outself.conv_norm_out = nn.GroupNorm(num_channels=block_out_channels[-1], num_groups=norm_num_groups, eps=1e-6)self.conv_act = nn.SiLU()conv_out_channels = 2 * out_channels if double_z else out_channels # 輸出通道數翻倍,分別表示均值和方差self.conv_out = nn.Conv2d(block_out_channels[-1], conv_out_channels, 3, padding=1)self.gradient_checkpointing = Falsedef forward(self, sample: torch.Tensor) -> torch.Tensor:r"""The forward method of the `Encoder` class."""sample = self.conv_in(sample)if torch.is_grad_enabled() and self.gradient_checkpointing: # 若啟用梯度計算,且開啟了梯度檢查點for down_block in self.down_blocks:sample = self._gradient_checkpointing_func(down_block, sample)sample = self._gradient_checkpointing_func(self.mid_block, sample)else:for down_block in self.down_blocks:sample = down_block(sample)sample = self.mid_block(sample)# post-processsample = self.conv_norm_out(sample)sample = self.conv_act(sample)sample = self.conv_out(sample)return sample
DiT的設計
整體架構如下圖
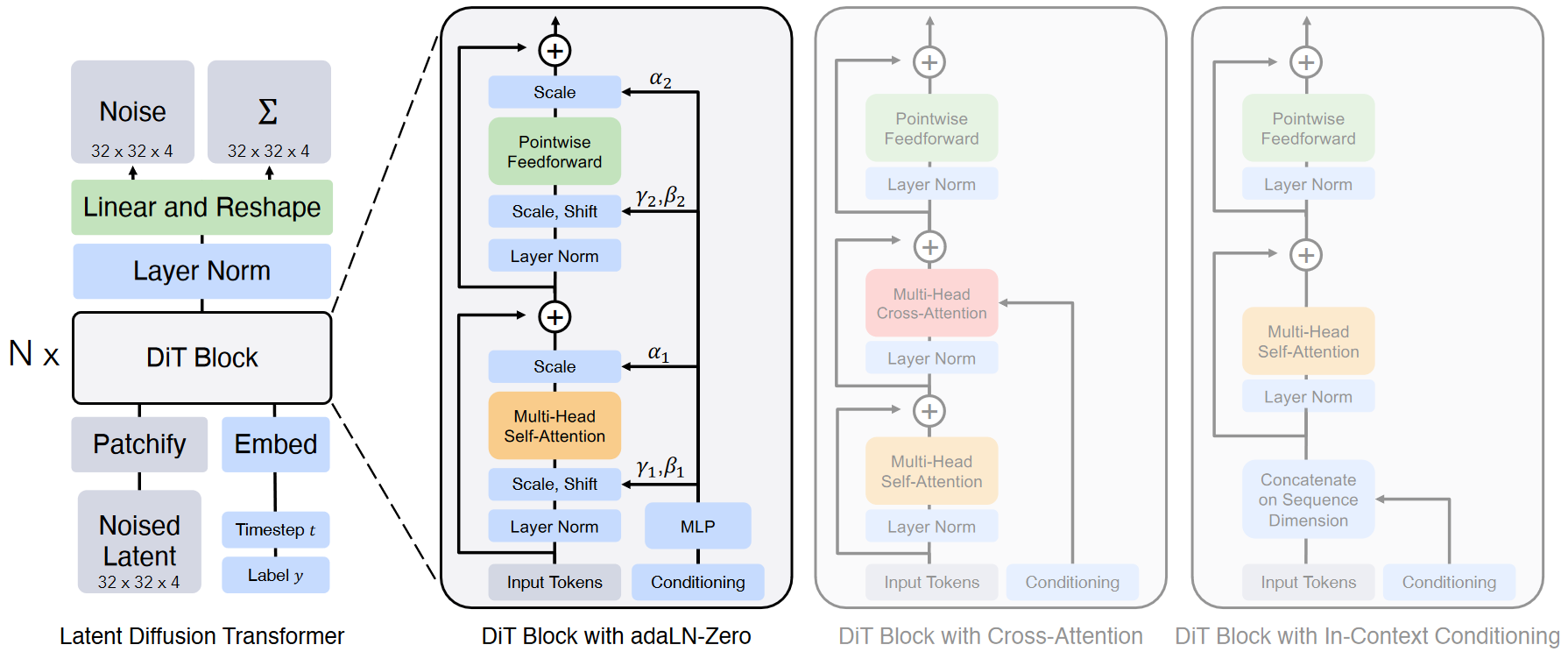
處理256×256×3的圖片,映射到潛空間,變成32×32×4的z,作為DiT的輸入。
DiT的第一層為“patchify”,對z進行分塊,線性嵌入每塊,將空間表征變成含T個維度為d的token的序列,然后將標準的正余弦版本的位置嵌入應用于所有token
def get_2d_sincos_pos_embed(embed_dim, grid_size, cls_token=False, extra_tokens=0):"""輸入一個 grid_size×grid_size 的網格輸出每個網格點的位置編碼向量,形為 (grid_size×grid_size, embed_dim)從后續兩個函數的“assert”語句來看,embed_dim需為4的倍數前/后一半列為x/y信息,再1/4列為正/余弦,即[x_sin_block, x_cos_block, y_sin_block, y_cos_block] 若存在cls_token,在編碼前補零MAE(帶掩碼的自編碼器)官方實現"""grid_h = np.arange(grid_size, dtype=np.float32)grid_w = np.arange(grid_size, dtype=np.float32)grid = np.meshgrid(grid_w, grid_h) # here w goes 列表grid含兩個形為(grid_size, grid_size)的數組[W, H],分別記錄每個網格點的w/h坐標grid = np.stack(grid, axis=0) # 堆疊成3維張量,形為(2, grid_size, grid_size)grid = grid.reshape([2, 1, grid_size, grid_size])pos_embed = get_2d_sincos_pos_embed_from_grid(embed_dim, grid)if cls_token and extra_tokens > 0:pos_embed = np.concatenate([np.zeros([extra_tokens, embed_dim]), pos_embed], axis=0)return pos_embeddef get_2d_sincos_pos_embed_from_grid(embed_dim, grid):assert embed_dim % 2 == 0 # 確保embed_dim是偶數# 將embed_dim分成兩半,分別用于編碼兩個維度的位置emb_h = get_1d_sincos_pos_embed_from_grid(embed_dim // 2, grid[0])emb_w = get_1d_sincos_pos_embed_from_grid(embed_dim // 2, grid[1])emb = np.concatenate([emb_h, emb_w], axis=1)return embdef get_1d_sincos_pos_embed_from_grid(embed_dim, pos):assert embed_dim % 2 == 0# 將embed_dim分成兩半,分別用于正/余弦編碼omega = np.arange(embed_dim // 2, dtype=np.float64)omega /= embed_dim / 2.omega = 1. / 10000**omega # 頻率衰減因子 (D/2,)pos = pos.reshape(-1) # 展平坐標 (M=1×grid_size×grid_size,)(-1為占位符)out = np.einsum('m,d->md', pos, omega) # 外積計算位置*頻率 (M, D/2)emb_sin = np.sin(out) # 正弦部分 (M, D/2)emb_cos = np.cos(out) # 余弦部分 (M, D/2)emb = np.concatenate([emb_sin, emb_cos], axis=1) # (M, D)return emb
看到這塊位置編碼時,我想到旋轉位置編碼RoPE,都是用正余弦函數來編碼位置信息,頻率都是按指數遞減(),但這里是加法
其中是該patch在網格中的絕對位置,在RoPE中則是通過“旋轉”將相對位置
編碼入嵌入向量
將query和key向量的每一對維度當作平面坐標,按角度旋轉一定角度(位置和頻率決定),將相對位置信息融入自注意力的內積計算中:。
T的大小由超參分塊大小p決定,p減半,T將呈平方增長,讓Transformer Gflops至少變成原來的平方,但對下游參數量并無顯著影響,因為模型的主要參數(Transformer層的權重)僅由隱藏維度d和層數N決定,與T無關。作者添加了p = 2, 4, 8多種設計。
而后輸入的tokens會被系列transformer塊處理。除了噪聲圖片,擴散模型有時還會處理額外的條件信息,比如時間步t、類標簽c、自然語言等。作者嘗試了4種用來處理的transformer塊變體,對標準ViT塊設計引入微小但重要的修改:
1. 上下文條件輸入(In-context conditioning)。將條件信息作為額外的token拼接到輸入序列中,與圖像token一起處理。類似于[CLS] token,無需修改標準的ViT塊,在最后一塊中將條件token移除即可。引入的Gflops微乎其微。
2. 交叉注意力塊(Cross-attention block)。將條件信息單獨做一個長為2的序列,在多頭自注意力塊后添加額外的多頭交叉注意力層,類似于原始Transformer中的編碼器-解碼器交叉注意力機制,或者淺空間擴散模型(LDMs)對類標簽進行條件化的方法。引入的Gflops最高,大致占總開銷的15%。
3. 自適應層歸一化塊(adaLN block)。adaLN在GANs和以UNet為主干的擴散模型中有廣泛應用,作者將其替換掉標準Transformer塊中的Layer Norm,從原本的直接學習逐維縮放和平移的參數和
,變成從條件信息(t和c的嵌入向量之和)回歸出來。在這3種塊中,引入的Gflops最少,計算效率最高,也是唯一能將條件信息影響所有token的方法。
4. 自適應歸一化層-零初始化塊(adaLN-Zero Block)。先前在ResNets上的工作發現,將殘差塊初始化為一個恒等函數是有益的,殘差塊的數學形式為,
為殘差函數,恒等映射即在初始狀態下使
,讓模型先學到全局結構,再逐漸利用殘差分支進行細化,這樣訓練會更穩定,收斂更快。例如在U-Net中將每個殘差塊最后一層卷積權重初始化為0,作者對adaLN的DiT塊做類似修改,讓其再回歸一個逐維縮放參數
用在殘差連接前。系數
、
和
都是由條件調制網絡——一個小型MLP(非線性+線性層)回歸出來的,就將該MLP最后一層的weight和bias初始化為0,所有輸出自然為0,如下
# initialization for AdaLN modulation
self.adaLN_modulation = nn.Sequential(nn.SiLU(),nn.Linear(dim, dim * 6)
)
nn.init.constant_(self.adaLN_modulation[-1].weight, 0)
nn.init.constant_(self.adaLN_modulation[-1].bias, 0)
...
# 從條件生成調制參數(多頭自注意力/多層感知機的平移和縮放參數、殘差分支門控系數)
shift_msa, scale_msa, gate_msa, shift_mlp, scale_mlp, gate_mlp = self.adaLN_modulation(c).chunk(6, dim=-1)和原始的adaLN塊一樣,adaLN-Zero引入的Gflops微乎其微。
依次堆疊N個DiT塊,每個塊的隱藏維度為d。參考ViT,采用標準Transformer配置,同時在N、d和注意力頭數上進行聯合縮放,具體為4種配置:DiT-S、DiT-B、DiT-L和DiT-XL,涵蓋從0.3到118.6Gflops的廣泛模型規模和計算量分配,以評估不同規模下的性能表現,詳細配置如下

在最后的DiT塊中,需將圖片token序列解碼成對噪聲和對角(不同像素/通道/特征之間的噪聲獨立)協方差的預測,這兩部分輸出需與原始空間輸入保持形狀一致,為此使用一個標準的線性解碼器:先對序列施加最終的(自適應)層歸一化,再將每個token線性映射成大小為p×p×2C的張量,其中C為DiT空間輸入的通道數,最后將得到的token重排列回其原始的空間布局,得到噪聲和協方差。
整個DiT設計空間包括了patch大小、Transformer塊結構和模型規模。
實驗
作者設計了積累模型,用以探索DiT設計空間,研究擴展性,模型根據其配置和潛在分片大小p進行命名,例如DiT-XL/2,就是XL版模型規模,同時p=2。
訓練設置
在ImageNet數據集(蠻有挑戰性的基準)的256×256和512×512的圖片上,訓練類條件潛在DiT模型。對最終的線性層要么進行零初始化,要么像ViT那樣初始化。訓練所有模型時均采用AdamW,固定學習率,無權重衰減,批量大小256,唯一用的數據增強是水平翻轉。
與先前ViTs的工作不同,作者沒發現學習率預熱和正則化的必要性,甚至不用時,所有模型配置下的訓練都高度穩定,也沒看到訓練Transformer時的任何常見損失尖峰。
按生成式建模文獻中的常用做法,在訓練DiT的過程中采用指數滑動平均EMA,衰減系數為0.9999
EMA權重的更新公式為
其中,表示每次更新只用到當前權重變化的0.01%,主要依賴于歷史權重。用這個“平滑版本”的參數
作為最終評估或采樣的模型權重/
在所有模型規模和分塊大小下采用相同的訓練參數,和ADM(U-Net作為骨干網絡,又比原始DDPM加入注意力層,即Attention-based Diffusion Model)幾乎完全一致。
擴散設置
對于擴散模型,作者采用現成的預訓練好的VAE作為圖像的編解碼器,VAE編碼器下采樣因子為8,假設給定RGB圖像x的形狀為256×256×3,那么的形狀就是32×32×4,實驗中所有擴散模型都在這個潛在空間中進行操作。在從擴散模型中采樣出一個新的潛在向量后,用VAE解碼器將其解碼成像素
。
所有實驗同樣沿用了ADM論文中擴散過程的超參數設置:1. 設置最大擴散步數,將噪聲方差
從
線性增加到
;2. 反向過程的高斯分布
中的協方差矩陣
也假設為對角形式,由模型預測(VS. 固定);3. 使用正余弦編碼+MLP得到時間步的嵌入向量,與標簽嵌入結合,用于調制網絡的中間層。
評價指標
和先前工作對齊,比較250步DDPM采樣后的FID-50K。FID是衡量生成圖像質量的常用指標,依賴于Inception網絡提取的特征統計(均值&協方差),任何圖像預處理細節的差異(如圖像尺寸、歸一化方式、插值方法)都會讓數值產生顯著變化,故為了避免計算流程差異,作者直接將生成樣本保存,然后用AMD論文提供的TensorFlow版評估工具統一計算FID,即可保證和ADM的結果完全可比(一樣的代碼、相同的預處理)。默認不使用CFG,除非特別注明。補充報告IS(圖像清晰度和多樣性)、sFID(更關注圖像的空間細節)、Precision/Recall(衡量生成圖像和真實分布的覆蓋率recall和質量)作為參考指標。
計算
所有DiT模型均用JAX框架實現,在TPU v3 prod上訓練,JAX是Google提出的一個高性能數值計算庫,支持自動微分、XLA編譯、TPU加速,非常適合大規模模型訓練,TPU v3是Google第三代張量處理硬件單元,每個pod是由多個TPU芯片組成的集群,可大規模并行訓練。DiT-L-2作為計算量最大的模型,在256個TPU芯片上協同訓練,全局批量大小為256時,每秒約5.7次迭代(一個批次數據完成一次前向+反向+參數更新)
DiT塊設計
4種:in-context(119.4Gflops)、cross-attention(137.6Gflops)、adaLN(118.6Gflops)、adaLN-zero(118.6Gflops)。FID結果如下
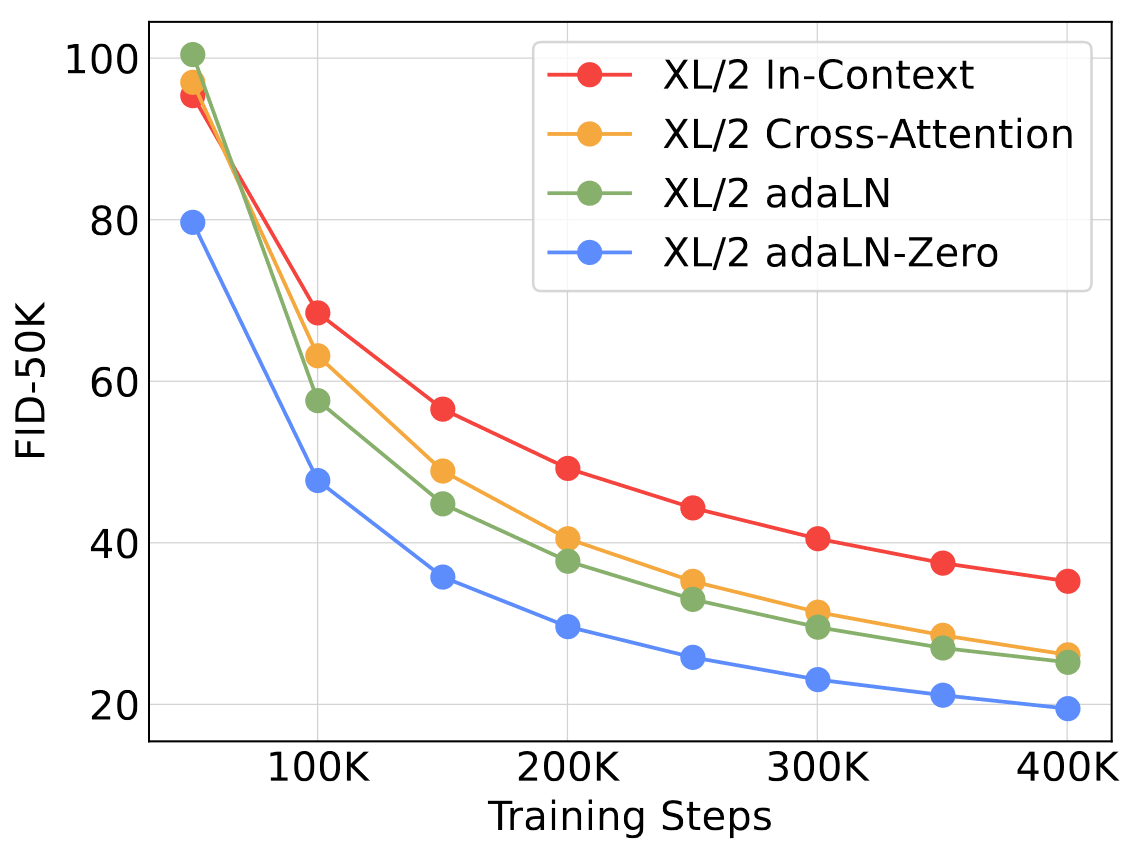
adaLN-Zero塊的FID最低,計算最高效,在400K訓練迭代后,近in-context模型的一半,說明該調節機制對模型質量有重要影響,相較于原始adaLN的性能提升也說明初始化方式的重要性,后續就采用adaLN-Zero了。
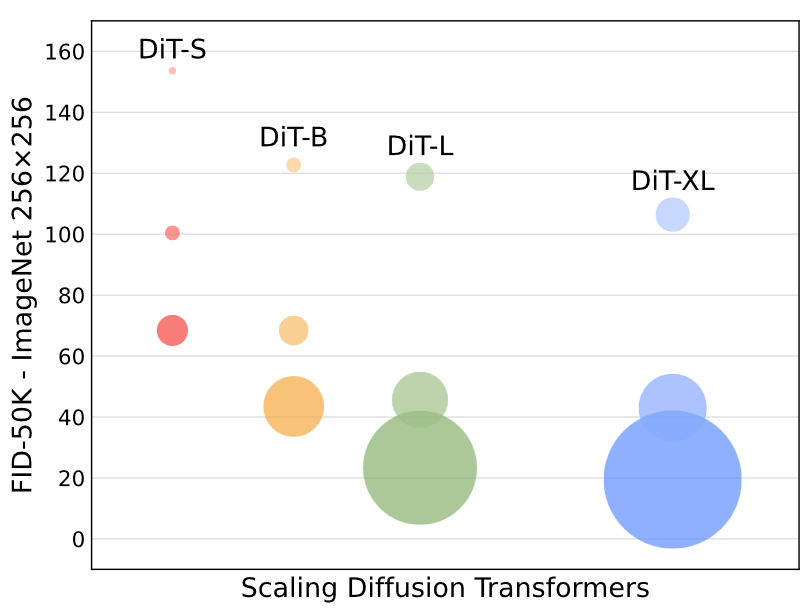
模型規模和分塊大小
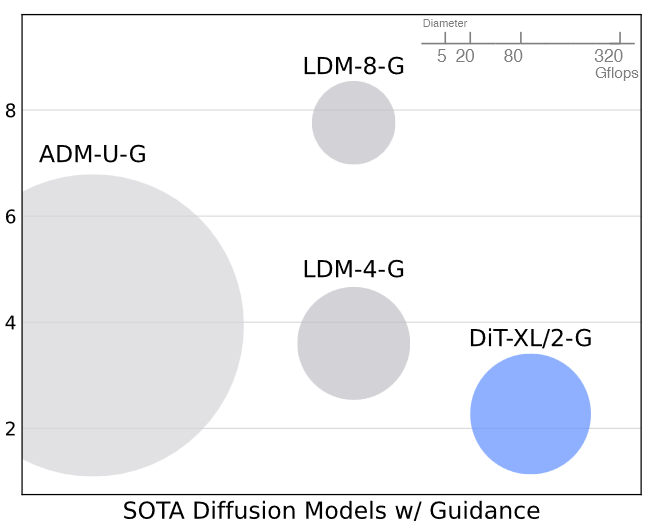
12個DiT模型,4種模型配置(S、B、L、XL),3種分塊大小(8、4、2),表現如下,圓圈面積表示擴散模型的flops,注意到DiT-L和DiT-XL在Gflops上相對較近。可以看出隨著計算量增大(增大模型尺寸、減少分塊大小),FID所反映出的性能還是穩步提升的
或者從下圖中可以更明顯地看出模型規模和分塊大小對性能的影響(迭代12次的結果),要想降低FID,可以讓transformer更深更寬,或分塊尺寸更小
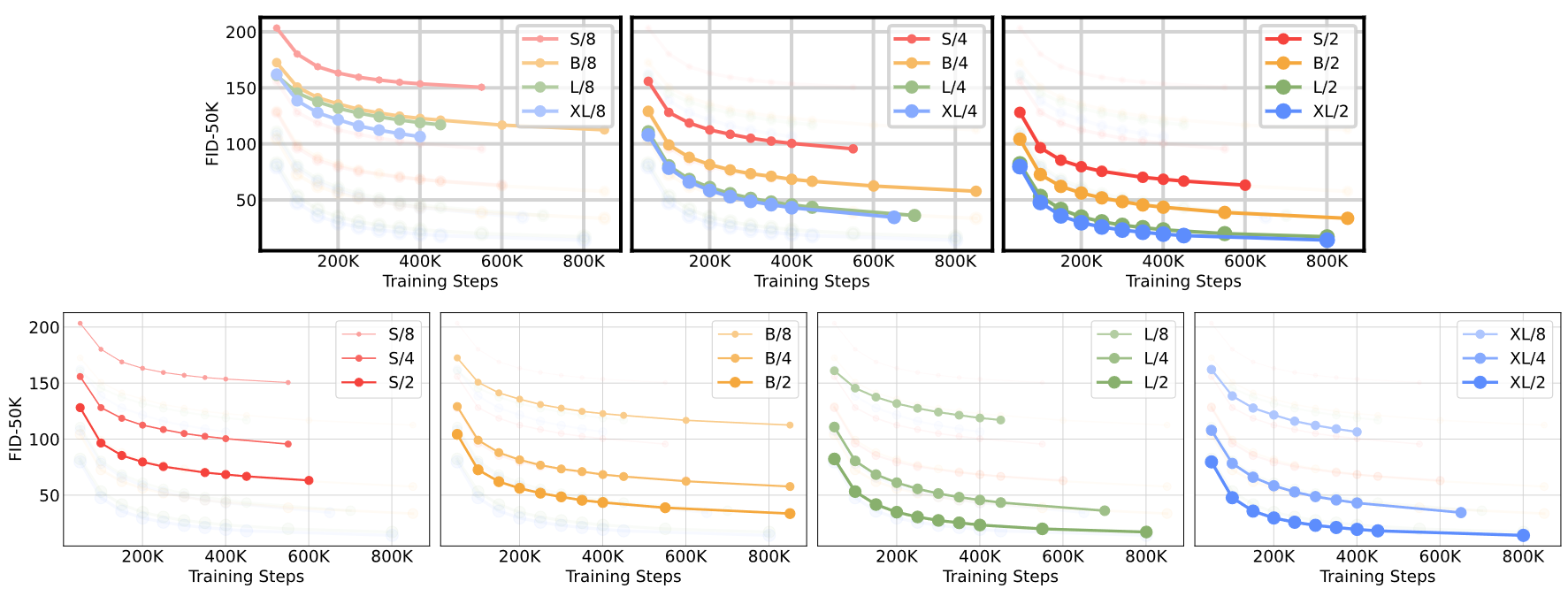
下圖進一步說明Gflops與FID間的強相關,顯示400K步訓練后的結果,總Gflops相近的,FID值就差不多,比如DiT-S/2和DiT-B/4
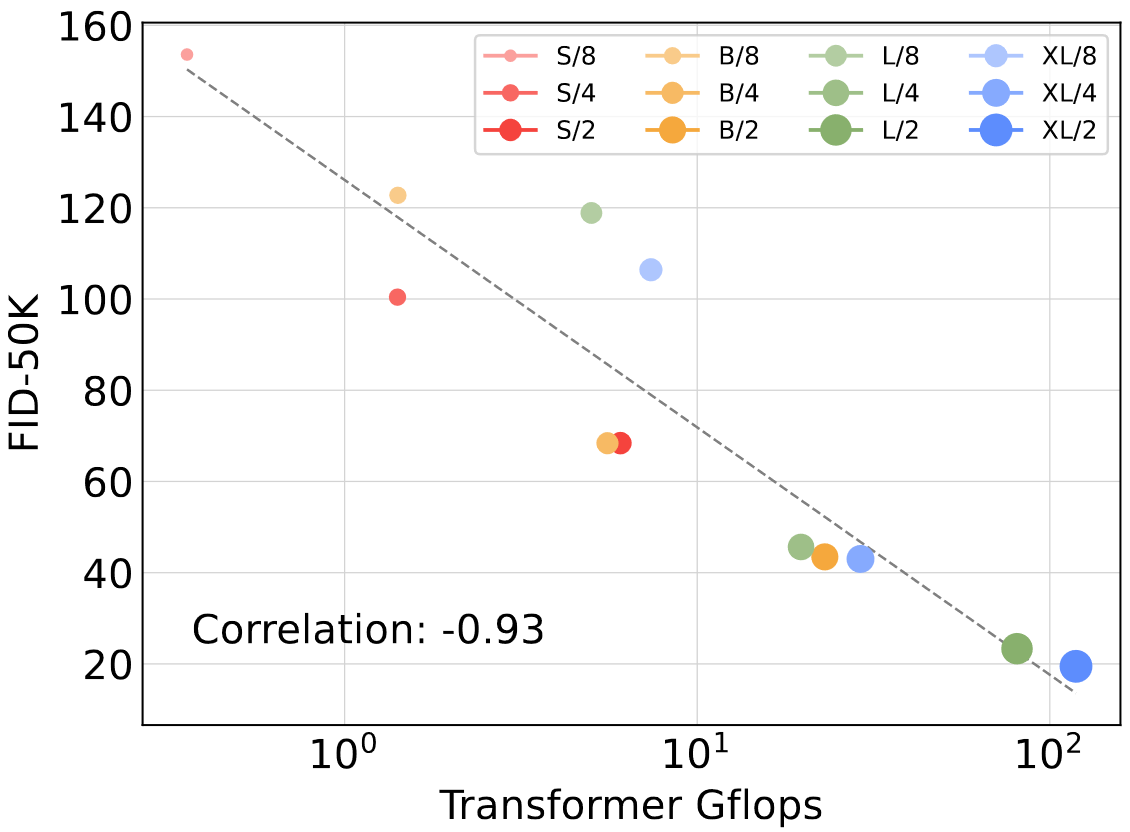
這種強相關性在其他指標上也有體現(采用MSE重建損失下微調的VAE解碼器,ft-MSE VAE decoder,更傾向于準確還原像素,而非追求主觀感知效果)
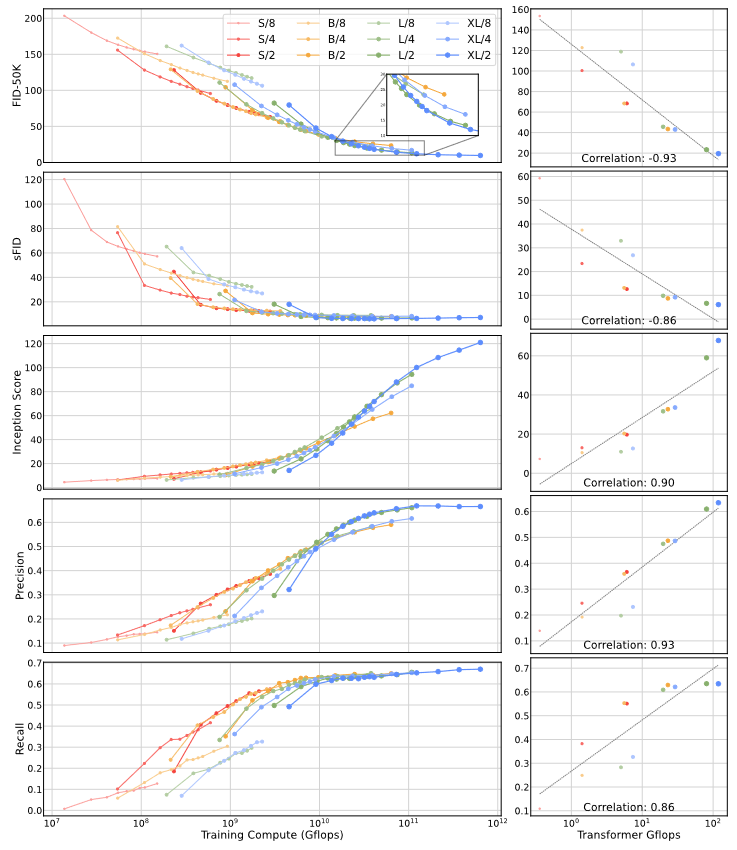
但是模型更大,訓練會更高效。下圖繪制不同模型的FID隨總訓練計算量的變化,其中訓練計算量估摸著為Gflops × 批量大小?× 訓練步數 × 3(反向傳遞的計算量算前向的兩倍)。可以看到,小模型即使訓練更久,FID也不見得比大模型低
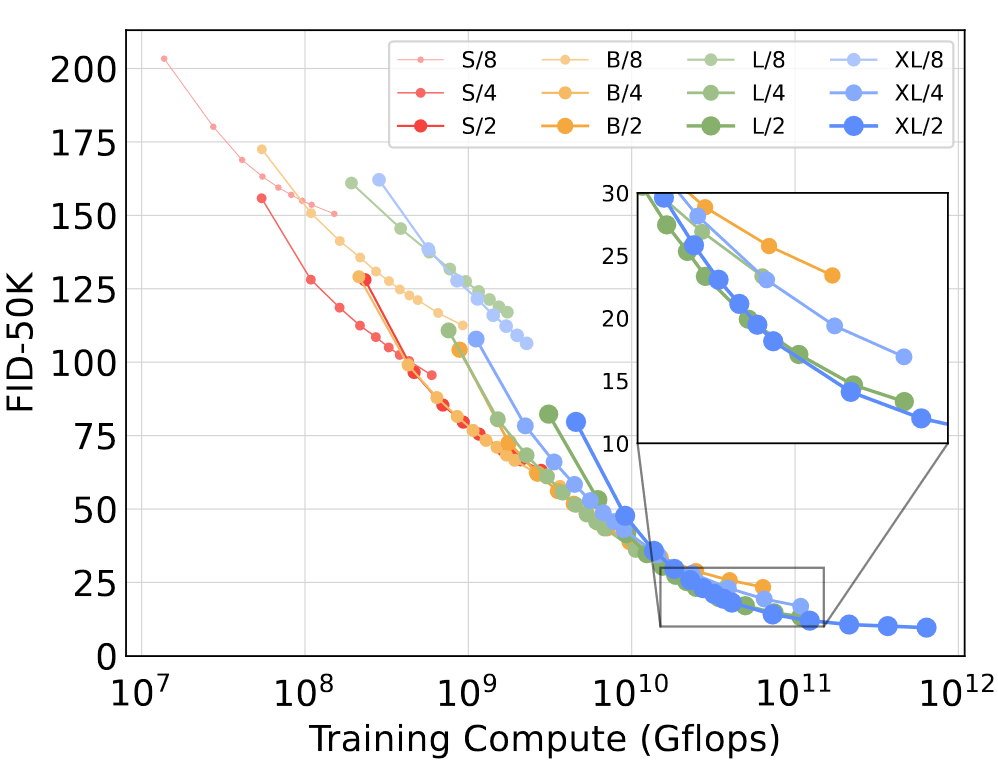
另外類似地,除分塊大小外其它條件均相同的情況下,模型在相同訓練Gflops下也會有不同表現,例如同樣是大致訓練Gflops,XL/4就比XL/2表現更好。
將可擴展性效果可視化,還是400K步訓練后,使用相同的起始噪聲、采樣噪聲和類別標簽,由12個DiT模型分別采樣出一張圖片,如下(差距還是蠻明顯的)

效果SOTA
最高Gflops的模型DiT-XL/2,在訓練7M步后,個別采樣效果圖如下(ImageNet 512×512和256×256)

在256×256分辨率下,和當時類條件生成模型相比,打敗了SOTA(StyleGAN-XL),同時將此前LDM達到的最好的FID-50K從3.60降到了2.27,在所有測試的cfg設置下,都取得了比LDM-4和LDM-8更高的召回值(Recall)
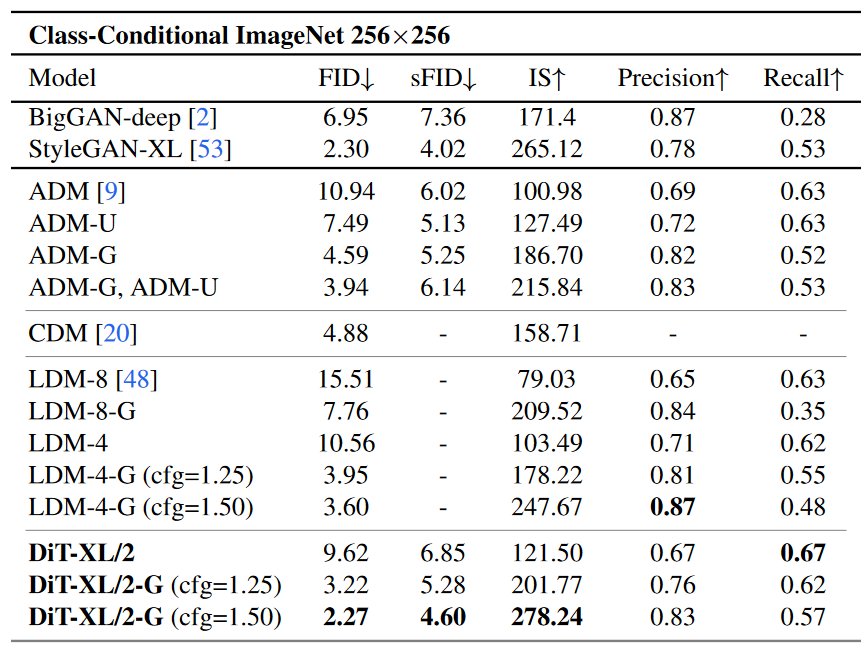
其計算(118.6Gflops)相較于潛空間的U-Net模型,例如LDM-4(103.6Gflops)更為高效,比像素空間U-Net模型,例如ADM(1120Gflops)或ADM-U(742Fflops)則要高效得多
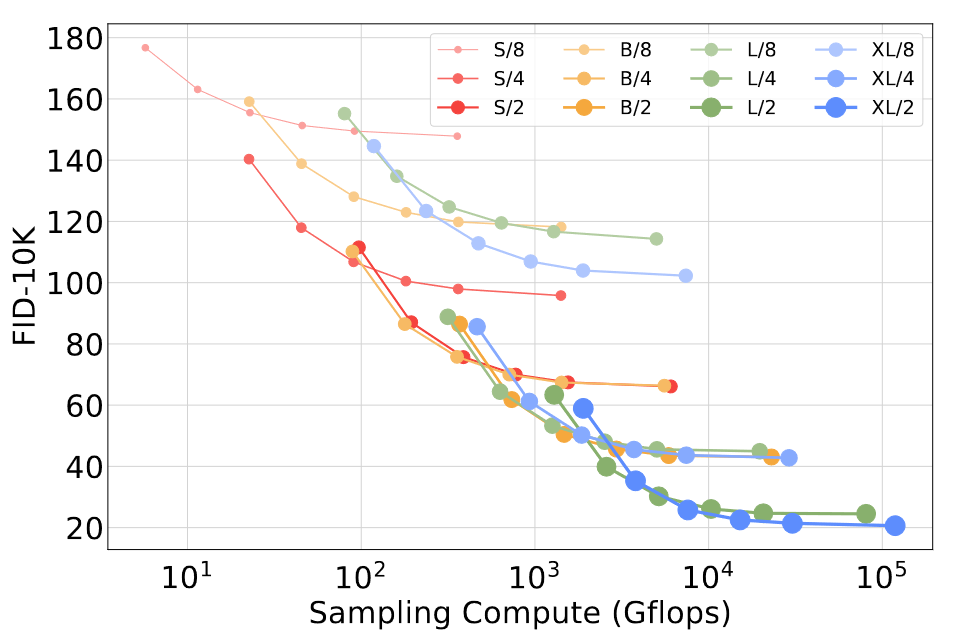
再思考一個問題,小模型能否憑借更多步采樣勝過大模型?從下圖可以看到,增大采樣步數并不能彌補模型Gflops的不足,都是訓練了400K步,采樣步數為[16, 32, 64, 128, 256, 1000],針對每個采樣步數的設置,繪制FID及采樣Gflops。DiT-L/2采樣1000步(80.7 Tflops),也比不過DiT-XL/2采樣128步(至少少了5倍,15.2 Tflops),fid-0K為25.9 VS. 23.7。
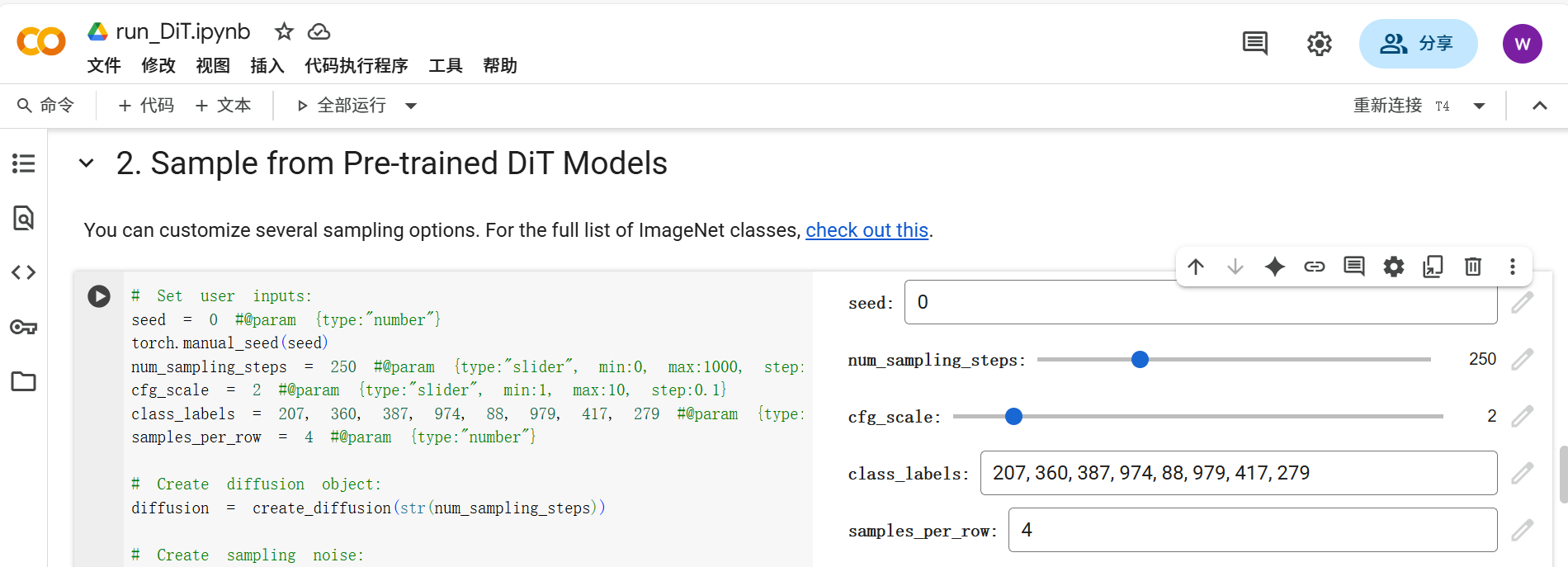
run_DiT.ipynb
也許有必要講一下代碼庫中這個用來演示的記事本文件,它用預訓練好的DiT模型進行采樣。也許你用Google Colab打開會好看一點,這個在線Jupyter Notebook環境網址為:https://colab.research.google.com/,因為文件中有些Colab的記事本參數化功能(#@param),例如下圖中顯示的交互面板
開頭簡要介紹了一下:DiTs是用ImageNet訓練出來的“class-conditional latent”擴散模型,將DDPM框架中的U-Nets替換為了transformer,也就是說DiTs將類別標簽作為條件輸入,由VAE編碼器將輸入映射到潛在空間后,再由Transformer在潛空間進行處理,輸出由VAE解碼器映射回圖像空間。DiT在ImageNet這個基準測試集上打敗了當時所有先進的擴散模型。
下面是工程頁、HuggingFace、論文、GitHub的網址。
1. Setup
建議用GPU來運行這個記事本,在Google Colab中的操作步驟就是依次點擊Runtime > Change runtime type > Hardware accelerator > GPU,這樣Colab就會分配一臺帶GPU的虛擬機,可能資源不是很充足或者要收費,可能比較慢,用自己的服務器可能快些,anyway,自己選擇
運行下列代碼單元,克隆DiT的GitHub倉庫(下載的文件存儲在Google Drive中),安裝并配置PyTorch和所需依賴,在當前會話(session)中只需執行一次,但虛擬機是臨時的,一旦斷開或閑置超時,所有安裝的東西都會丟失
!git clone https://github.com/facebookresearch/DiT.git
# 開頭的 ! 表示在 Notebook 的系統 Shell 里執行命令,Colab默認當前工作目錄/content
import DiT, os
os.chdir('DiT')
# 將當前工作目錄切換到剛克隆的倉庫中,相當于 Shell 中的 cd
os.environ['PYTHONPATH'] = '/env/python:/content/DiT'
# 設置環境變量PYTHONPATH,告訴后續子進程去哪些路徑找包
!pip install diffusers timm --upgrade
'''
安裝/升級兩大依賴
diffusers:HF的擴散模型庫
timm:PyTorch圖像模型庫,提供很多視覺backbone/工具
'''
# DiT imports:
import torch
from torchvision.utils import save_image # 將一批Tensor圖保存為網格圖
from diffusion import create_diffusion
from diffusers.models import AutoencoderKL
from download import find_model # 下載/定位預訓練權重
from models import DiT_XL_2
from PIL import Image
from IPython.display import display
torch.set_grad_enabled(False) # 推理模型,關閉梯度
device = "cuda" if torch.cuda.is_available() else "cpu"
if device == "cpu":print("GPU not found. Using CPU instead.")然后下載模型DiT-XL/2,你可以選分辨率為512×512還是256×256,也可以LDM VAE換掉
image_size = 256 #@param [256, 512]
# 下拉選擇框 256還是512
vae_model = "stabilityai/sd-vae-ft-ema" #@param ["stabilityai/sd-vae-ft-mse", "stabilityai/sd-vae-ft-ema"]
# 選哪個Stable Diffusion的VAE,EMA版穩定更常用,用MSE目標微調過的版本像素更保真
latent_size = int(image_size) // 8
# SD的VAE編碼器會將分辨率下采樣8倍
# Load model:
model = DiT_XL_2(input_size=latent_size).to(device)
# 網絡規模最大號,分塊大小2
state_dict = find_model(f"DiT-XL-2-{image_size}x{image_size}.pt")
model.load_state_dict(state_dict)
# 加載模型對應的預訓練權重
model.eval() # important!
vae = AutoencoderKL.from_pretrained(vae_model).to(device)
# 從HF拉取預訓練VAE(首次會下載到緩存,之后直接讀取)2. Sample from Pre-trained DiT Models
采樣時有多個可供用戶自定義的選項

文件中也提供了ImageNet中類別編號相應鏈接(the full list of ImageNet classes),點進去可以查到類別標簽“207”是“golden retriever”,即“金毛獵犬”
# Set user inputs:
seed = 0 #@param {type:"number"}
# 顯示數字框,由用戶選擇隨機種子
torch.manual_seed(seed)
# 使初始噪聲和每步采樣用到的隨機數可復現(相同用戶設置下,每次運行得到的圖片都一樣)
num_sampling_steps = 250 #@param {type:"slider", min:0, max:1000, step:1}
cfg_scale = 2 #@param {type:"slider", min:1, max:10, step:0.1}
class_labels = 207, 360, 387, 974, 88, 979, 417, 279 #@param {type:"raw"}
samples_per_row = 4 #@param {type:"number"}# Create diffusion object:
diffusion = create_diffusion(str(num_sampling_steps)) # 將步數作字符串傳入# Create sampling noise:
n = len(class_labels)
z = torch.randn(n, 4, latent_size, latent_size, device=device)
# 通道數為4來自Stable Diffusion的 VAE latent 約定
y = torch.tensor(class_labels, device=device)# Setup classifier-free guidance:
z = torch.cat([z, z], 0)
y_null = torch.tensor([1000] * n, device=device)
y = torch.cat([y, y_null], 0)
model_kwargs = dict(y=y, cfg_scale=cfg_scale)# Sample images(一次前向里同時跑“有條件”和“無條件”兩路):
samples = diffusion.p_sample_loop(model.forward_with_cfg, z.shape, z, clip_denoised=False,model_kwargs=model_kwargs, progress=True, device=device
)
'''
model.forward_with_cfg:模型的前向函數,內部將前/后半(有/無條件)分開前向,再按cfg公式混合
z.shape:告知采樣器目標形狀
clip_denoised=False:不裁剪預測值
model_kwargs=model_kwargs:附加傳給model.forward_with_cfg的字典(里面有y和cfg_scale)
progress=True:打開進度條
'''
samples, _ = samples.chunk(2, dim=0) # Remove null class samples(后半無條件結果用于cfg輔助)
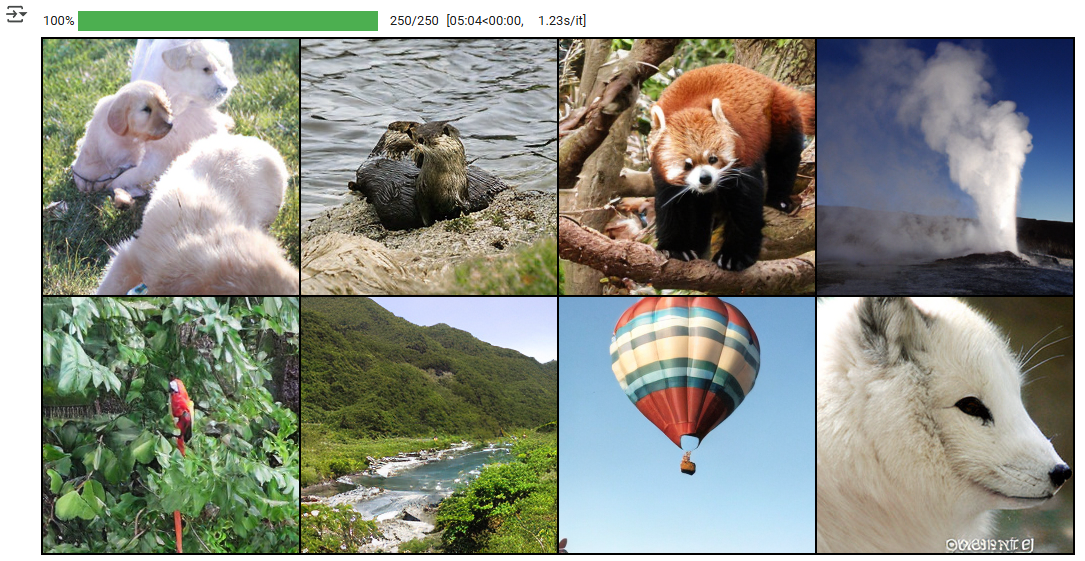
samples = vae.decode(samples / 0.18215).sample# Save and display images:
save_image(samples, "sample.png", nrow=int(samples_per_row),normalize=True, value_range=(-1, 1))
samples = Image.open("sample.png")
display(samples)采樣出的圖片
)


——右值引用和移動語義)








![[激光原理與應用-250]:理論 - 幾何光學 - 透鏡成像的優缺點,以及如克服缺點](http://pic.xiahunao.cn/[激光原理與應用-250]:理論 - 幾何光學 - 透鏡成像的優缺點,以及如克服缺點)



)


