參考鏈接:https://mp.weixin.qq.com/s/cscrUn7n_o6PdeQRzWpx8g
視頻教程:https://www.bilibili.com/video/BV1LGbozkEDY
模型代碼:https://github.com/boson-ai/higgs-audio
如果是兩個模型加在一起:一個語言模型,一個文本轉語音模型有問題
一個是耗時問題,另一個是語音轉文本再轉語音會丟失非語言信息,比如語氣和環境音
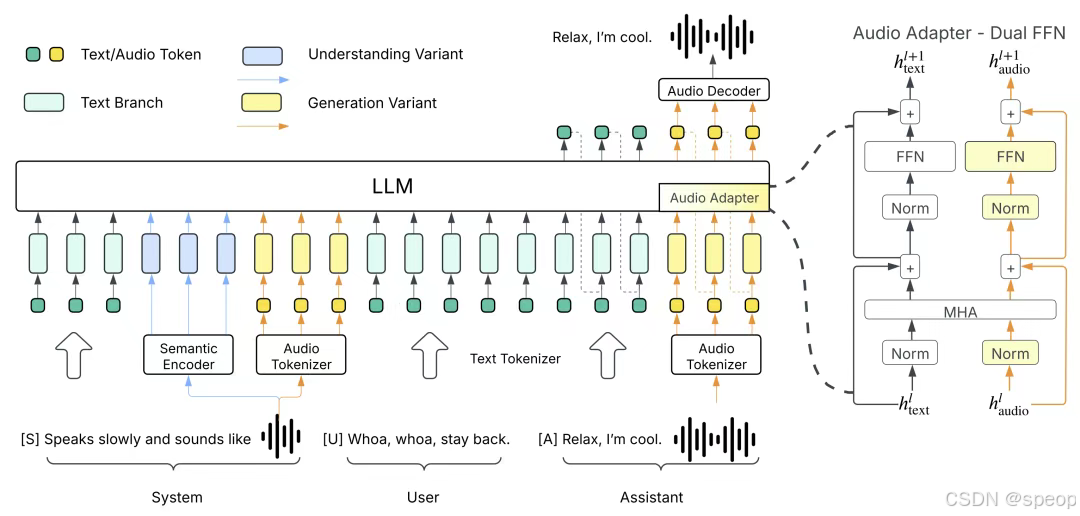
傳統的語音和文本模型之間相互獨立,李沐老師就想,欸,能不能將兩者結合起來,直接讓LLM用語音進行溝通。那么首先就要知道文本語言模型的本質是用給定的一段指令去生成預測結果,就是將任務先拆解為系統指令(system)、用戶輸入(user)、**模型回復(assistant)**三個部分。
system告訴模型,需要做什么事情,例如回答該問題、寫一段文字或者其他
user就是告知事情的詳細內容,例如問題具體是什么、文字要什么風格。所以如果要讓模型支持語音,就需要為模型增加一個系統命令,在user里輸入要轉錄為語音的文字,讓模型從system里輸出對應語音數據。這樣語音任務就能轉換成相同的處理格式,直接打通語音和文本之間的映射,通過追加更多的數據和算力,直接scaling law“大力出奇跡”。
中文的一個字:token
語言模型的輸出是一個softmax,本質上是一個多分類的問題
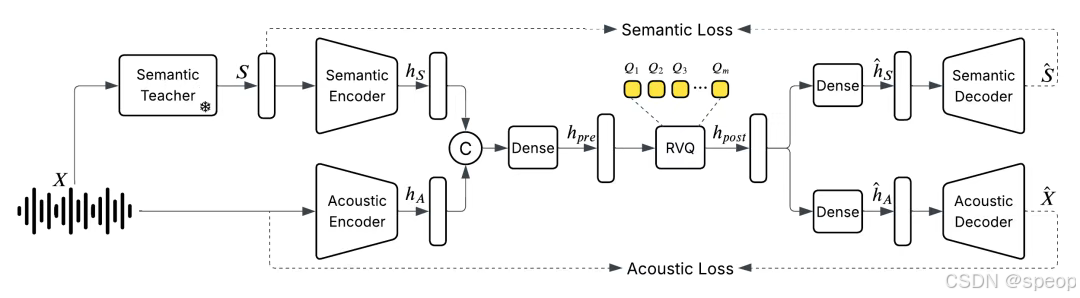
語音tokenizer:需要將語音這樣連續的信號變為離散的token
現有的方法是將一秒的語音信號裁切成多段(如100毫秒一段),為每一段匹配最相似的預定義模板(如45個模板),然后將其表示為長度為10的編號序列,也就是一個個token。
但這樣做,雖然可以將一小時的音頻從60兆壓縮到0.16兆,但質量相當糟糕,所以需要優先保留語音的語義信息,而聲學信號只保留少量部分,后續再通過其他手段還原。
于是他們訓練了一個統一的離散化音頻分詞器,以每秒25幀的速度運行,同時保持甚至提高音頻質量,以捕獲語義和聲學特征
常用壓縮:1小時 128kbps mp3 ~60MB
設64K audio tokens, 24 tokens per second
1秒audio:log2(64K)x24=384bit1小時audio ~0.16MB對比mp3,又壓縮了375x
優先應該保持語義的信號
語言模型能將一個東西的語音的表示和文字的表示能夠做一個映射
將語音的語義盡量映射回文本,使得能夠利用上文本語音模型
將語音對話表示為相應的system(場景描述、聲學特征、人物特征等)、user(對話文本)、assistant(對應音頻輸出)的形式。
同樣的模型架構訓練一個額外的語音理解模型
用戶給你一段語音,請你分析它的場景,它里面有哪些人,說什么東西,情緒,。
把生成模型出來的東西作為用戶的輸入
生成模型system prompt是對場景的描述
用戶給你的內容作為system的輸出
教第一個徒弟打拳
教第二個徒弟踢腿
然后讓兩個徒弟互相打,最后期望兩個徒弟都能夠學會拳腳功夫
文字作為上一輪用戶的輸入,語音作為上一輪系統的輸出,在給一段文字就能輸出和這個人聲音一致的語音。
1. 語音信號離散化表示(關鍵突破)
問題:語音是連續信號,傳統方法(如分段+模板匹配)壓縮后質量差。
解決方案:
- 統一音頻分詞器(Unified Audio Tokenizer)
- 分層離散化:將語音信號分解為兩類token:
- 語義token(高層):捕獲文本內容、意圖(映射到文本空間,類似ASR)。
- 聲學token(低層):保留音色、語調等特征(通過矢量量化/VQ-VAE壓縮)。
- 高幀率處理:以每秒25幀的速度編碼,平衡信息密度和連續性。
- 聯合訓練:語義和聲學token的編碼器/解碼器端到端優化,避免傳統模板匹配的信息丟失。
- 分層離散化:將語音信號分解為兩類token:
效果:
- 語音壓縮后仍能保留語義和情感信息(如“憤怒”語調的聲學特征)。
- 后續用LLM處理離散token時,類似處理文本,無需額外設計連續信號模塊。
2. 數據構建與清洗(質量保障)
問題:語音-文本對齊數據稀缺,公開數據質量差。
解決方案:
- 數據來源:購買版權數據+合規抓取,覆蓋多樣化場景(對話、音樂、環境音等)。
- 嚴格過濾:
- 通過ASR模型+人工規則剔除低質量音頻(如背景噪聲大、內容不連貫)。
- 僅保留10%數據(1000萬小時高質量數據)。
- 自生成標注:
- 用預訓練的AudioVerse模型(語音→文本/場景分析)自動標注語音的
system字段(場景、情緒等)。 - 形成
(system: 場景描述, user: 文本, assistant: 音頻)的三元組訓練數據。
- 用預訓練的AudioVerse模型(語音→文本/場景分析)自動標注語音的
效果:
- 數據多樣性高且對齊精準,模型能學習復雜語音-文本關聯(如“笑著回答問題”)。
3. 模型架構設計(性能核心)
核心思路:將語音任務轉化為LLM熟悉的“文本生成”格式。
具體實現:
- 多任務統一框架:
- 輸入:
system指令(如“生成憤怒的男聲”)+user文本 → 輸出:聲學token序列。 - 模型本質是條件式token預測(類似文本生成,但輸出是語音token)。
- 輸入:
- 雙模型協同訓練:
- AudioVerse:語音→文本/場景分析(提供
system標注)。 - 主模型:文本+場景→語音生成。
- 兩者互促,類似GAN的對抗訓練(但更溫和)。
- AudioVerse:語音→文本/場景分析(提供
優化點:
- 語義優先:模型優先學習語音的語義token,再細化聲學token(避免早期過擬合到音色細節)。
- 延遲優化:流式生成聲學token,實時拼接(類似文本模型的逐詞生成)。
4. 為什么性能顯著提升?
- 語義理解更強:
- 語音token與文本空間對齊,模型能利用文本預訓練知識(如GPT的推理能力)。
- 例:生成“悲傷的詩歌朗讀”時,模型先理解“悲傷”的文本語義,再匹配對應聲學特征。
- 端到端聯合訓練:
- 傳統TTS分模塊(文本→音素→聲學),而沐神模型統一優化,避免誤差累積。
- 數據規模效應:
- 1000萬小時數據遠超傳統TTS數據集(如LJSpeech僅24小時),覆蓋長尾場景。
5. 關鍵優化總結
| 模塊 | 傳統方法 | 沐神團隊的優化 | 提升點 |
|---|---|---|---|
| 語音表示 | 手工模板匹配 | 分層離散化token(語義+聲學) | 質量↑,兼容文本模型 |
| 數據構建 | 小規模純凈數據 | 海量數據+嚴格過濾+自生成標注 | 多樣性↑,對齊精度↑ |
| 模型訓練 | 獨立訓練ASR/TTS模塊 | 語音-文本聯合訓練,雙模型互促 | 語義和聲學協同優化 |
| 任務泛化 | 單一任務(如TTS) | 統一框架支持生成、分析、實時交互 | 多任務性能均衡 |
6. 可玩性功能示例
- 聲音克隆:輸入目標語音片段(5秒),模型提取聲學token后生成新內容。
- 實時情緒交互:檢測用戶語音情緒(如憤怒),生成共情的語音回復。
- 音樂生成:將歌詞+風格描述(
system)轉換為歌唱音頻。
若想深入技術細節,建議閱讀代碼中的tokenizer.py(音頻離散化)和trainer.py(多任務損失函數),關鍵是如何平衡語義和聲學token的損失權重。
音頻分詞器:https://github.com/boson-ai/higgs-audio/blob/main/tech_blogs/TOKENIZER_BLOG.md
提出的DualFFN架構:https://github.com/boson-ai/higgs-audio/blob/main/tech_blogs/ARCHITECTURE_BLOG.md

這里可以試用
from boson_multimodal.serve.serve_engine import HiggsAudioServeEngine, HiggsAudioResponse
from boson_multimodal.data_types import ChatMLSample, Message, AudioContentimport torch
import torchaudio
import time
import clickMODEL_PATH = "bosonai/higgs-audio-v2-generation-3B-base"
AUDIO_TOKENIZER_PATH = "bosonai/higgs-audio-v2-tokenizer"system_prompt = ("Generate audio following instruction.\n\n<|scene_desc_start|>\nAudio is recorded from a quiet room.\n<|scene_desc_end|>"
)messages = [Message(role="system",content=system_prompt,),Message(role="user",content="The sun rises in the east and sets in the west. This simple fact has been observed by humans for thousands of years.",),
]
device = "cuda" if torch.cuda.is_available() else "cpu"serve_engine = HiggsAudioServeEngine(MODEL_PATH, AUDIO_TOKENIZER_PATH, device=device)output: HiggsAudioResponse = serve_engine.generate(chat_ml_sample=ChatMLSample(messages=messages),max_new_tokens=1024,temperature=0.3,top_p=0.95,top_k=50,stop_strings=["<|end_of_text|>", "<|eot_id|>"],
)
torchaudio.save(f"output.wav", torch.from_numpy(output.audio)[None, :], output.sampling_rate)






)
![學習:JS[8]本地存儲+正則表達式](http://pic.xiahunao.cn/學習:JS[8]本地存儲+正則表達式)



![[學習] CORDIC算法詳解:從數學原理到反正切計算實戰](http://pic.xiahunao.cn/[學習] CORDIC算法詳解:從數學原理到反正切計算實戰)







