一、Linux中的buffer與cache的區別
Linux的內存管理與監控_linux服務器虛假內存和真實內存怎么區分-CSDN博客文章瀏覽閱讀66次。本文主要是關于【Linux系統的物理內存與虛擬內存講解】【重點對虛擬內存的作用與用法進行了講解說明】【最后還對如何新增擴展、優化、刪除內存交換空間swap進行了詳細的操作流程講解】_linux服務器虛假內存和真實內存怎么區分https://coffeemilk.blog.csdn.net/article/details/149689342
| 序號 | buffer與cache的區別 |
| buffer與cache都是存放在物理內存中的數據。 正常情況下至于何時回收,怎么回收buffer與cache的數據是不用我們管的,操作系統的內核會自行調度處理。 不建議自己手動回收處理
| |
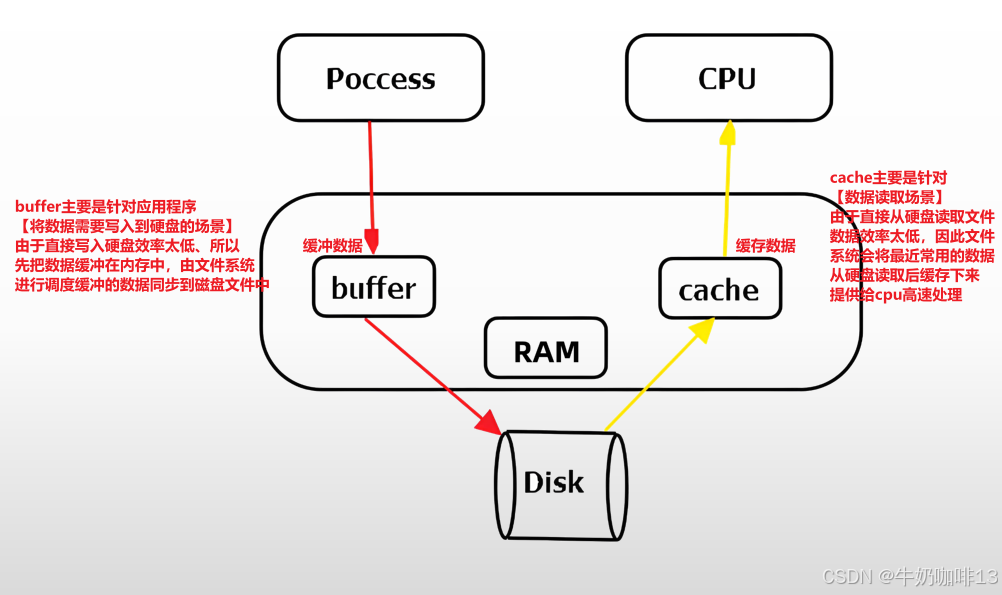
| 1 | buffer主要是針對應用程序將【數據寫入硬盤】的場景(即:由于直接將應用程序的數據直接寫入到硬盤時,硬盤的寫入速度效率太低,因此buffer又稱為硬盤的緩沖區。而將buffer緩存區的數據寫入到硬盤的操作是由操作系統的文件系統來調度完成的)【Buffer(緩沖)為了提高內存和硬盤之間的寫操作】(buffer把分散的寫操作集中進行,減少磁盤碎片和硬盤的反復尋道,從而提高系統性能。更細的說是針對內存和硬盤之間的寫操作來設計的,目的是將寫的操作集中起來進行,減少磁盤碎片和硬盤反復尋址過程,提高性能。在Linux系統內部有一個守護進程,會定期清空Buffer中的內容,將其寫入硬盤內,當手動執行sync命令時也會觸發上述操作)。 注意:buffer里面存儲的數據雖然不是很多,但是數據都很關鍵(如:Linux系統正在寫數據,但是突然斷電,等電恢復后,系統重啟時會提示你進行數據恢復【這就是由于buffer里面的數據沒有寫入到硬盤導致的】好消息是文件系統的日志記錄功能可以幫助你進行數據的恢復【前提是文件系統擁有日志記錄功能且已經開啟】)。 buffer里面一般存儲的數據都不是很大,一般都在幾十兆到幾百兆。 |
| 2 | cache主要是針對【CPU讀取硬盤文件數據】的場景(即:首次將硬盤的數據讀取后緩存在內存中,下次再使用的時候就直接從cache中獲取,讀取效率就提升了,方便CPU快速處理;一般cache中緩存的是最近經常使用的數據,長時間不使用的數據就會被文件系統清除掉)【Cache(緩存)是為了調高CPU和內存之間數據交換而設計的】。 一般cache里面會存在大量的緩存數據,多達幾G到幾十G,可以清除出大量的內存。 |
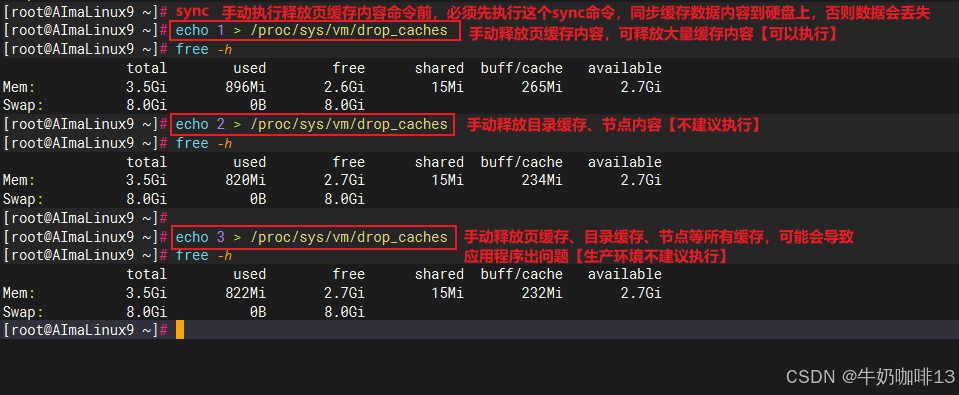
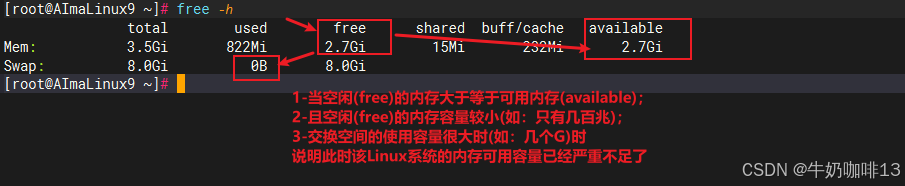
#查看Linux系統的內存使用情況命令
free -h#查看系統實時運行情況命令
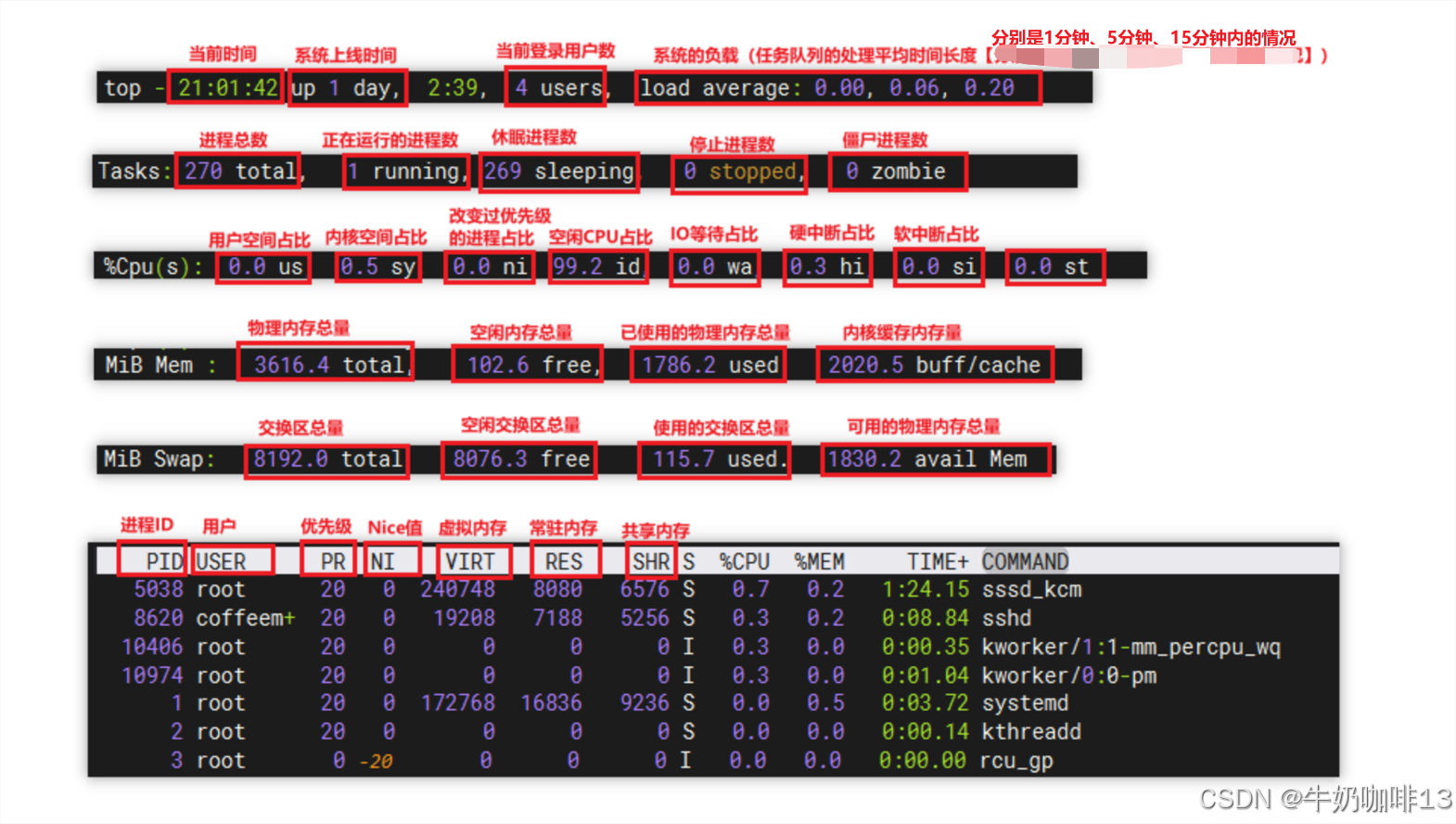
top

Linux系統必學的基礎操作命令——快速上手Linux(上)-CSDN博客![]() https://coffeemilk.blog.csdn.net/article/details/148987685
https://coffeemilk.blog.csdn.net/article/details/148987685
二、Linux內存不足時系統回收內存的步驟
| 序號 | 內存不足時系統回收內存的步驟 | 說明 |
| 1 | 臟頁面(DirtyPages)寫回 | 臟頁面是指:內存中已被修改但尚未寫入磁盤的數據 |
| vm.dirty ratio:控制臟頁面占用系統內存的最大比例(可手動配置比例) | ||
| vm.dirty background ratio:當臟頁面達到這個比例時,系統自動觸發臟數據寫回操作(可手動配置比例) | ||
| 在內存緊張時,內核會加速將臟頁面寫回磁盤以釋放內存 | ||
| 2 | 頁面緩存(Page Cache)清理 | Page Cache會占用很大物理內存,它主要作用是加快文件讀取速度 |
| 當內存不足時,系統首先會嘗試清理不再頻繁訪問的頁面緩存,以釋放內存 | ||
| 內核通過LRU(Least Recently Used,最近最少使用)算法清理不常使用的緩存頁面 | ||
| 3 | 使用交換分區(Swap) | Page Cache釋放還是不夠時,Linux系統內核會將不常用的內存頁交換到swap分區 |
| 頻繁的swap操作會導致性能下降,尤其是在涉及大量硬盤I/O的情況下 | ||
| 通過vm.swappiness來控制內存交換的頻率 | ||
| 4 | OOM Killer (Out Of Memory Killer) | 當內核無法通過上述步驟回收足夠的內存時,OOM Killer啟動 |
| OOM Killer 會基于進程的OOM分數選擇占用內存較多的進程進行終止? | ||
| OOM Killer 通常優先殺死占用內存過多的后臺進程 | ||
| 注意:一旦運行到這一步OOM Killer回收內存空間則對于我們的應用程序來說就很危險了!!!很容易被OOM Killer殺掉,會導致業務中斷情況發生(且這里殺掉的應用一般是占用內存較多的應用,且不確定是哪個) | ||
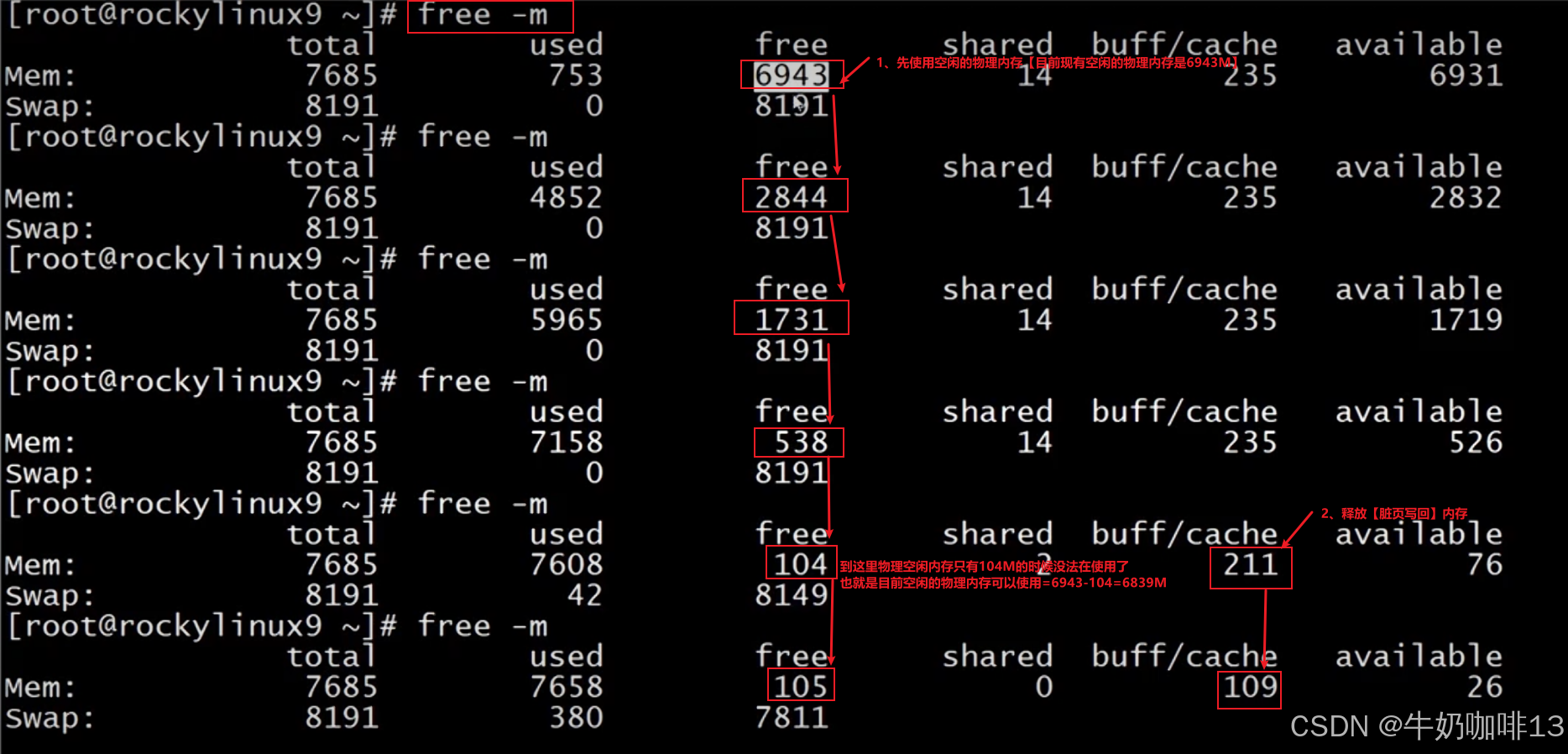
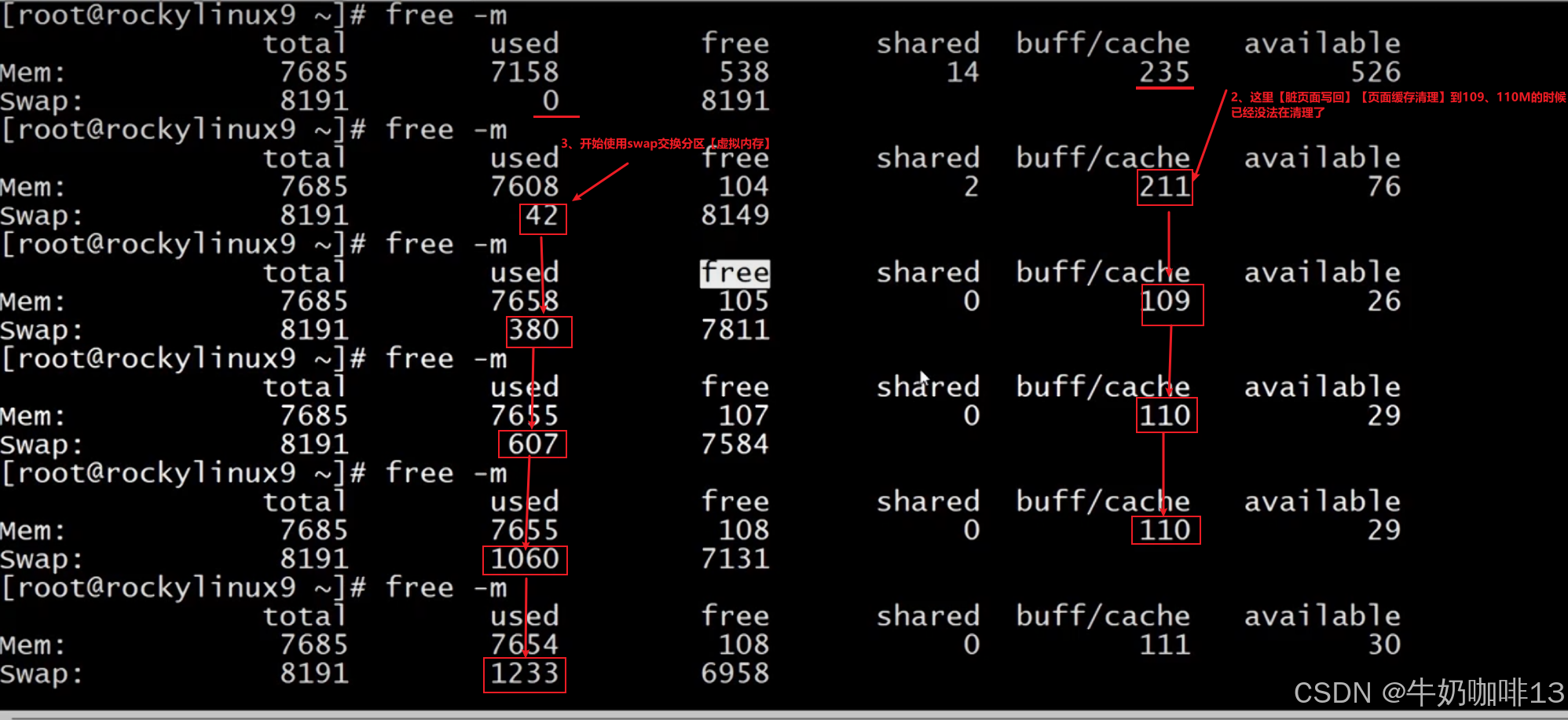
示例:如下圖Linux系統的物理內存是3.5G+內存交換空間8G=11.5G的總內存空間;假如現在有一個應用程序需要11G的內存運行空間,現在空閑的物理內存是2.7G不足11G,系統回收內存的步驟如下:
????????1、臟頁面寫回(即釋放臟頁面占用的內存,一般也不能釋放多少空間【大概幾十兆到幾百兆】)假設這里釋放了0.1G;
????????2、頁面緩存清理(按照LRU【最近最少使用算法】將不常使用的緩存頁面移動到交換分區中【即虛擬內存中】)假設這里釋放了0.5G;
????????3、目前的可用的空間=空閑的物理內存2.7G+臟頁面寫回釋放的內存0.1G+頁面緩存清理釋放的內存0.5G=3.3G,還是不夠應用程序所需的12G;此時交換分區(虛擬內存)提供了7G的內存空間,目前可用內存為=3.3G+7G=10.3G還是不足11G(這里可供使用的物理內存只占到不足一半的空間,應用程序運行響應會非常緩慢).
????????4、OOM Killer就會啟動對運行的程序進行打分,然后將打分最高的程序殺掉釋放空間比如這里釋放0.8G空間,此時可用的空間=10.3G+0.8G=11.1G滿足程序運行,程序就可以正常運行了(但是OOM Killer根據打分情況將我們正在運行的應用程序殺掉,十分危險)。

比如當我們使用自己編寫的memload程序申請16g內存啟動后,可以不斷的運行【free -h】或【free -m】命令查看內存空間的使用情況(可以看到由于我們Linux系統無法提供該程序所需的16g內存導致該程序無法成功運行被殺掉,可以使用【dmesg】命令查看被殺死程序的詳細信息日志),如下圖所示:?
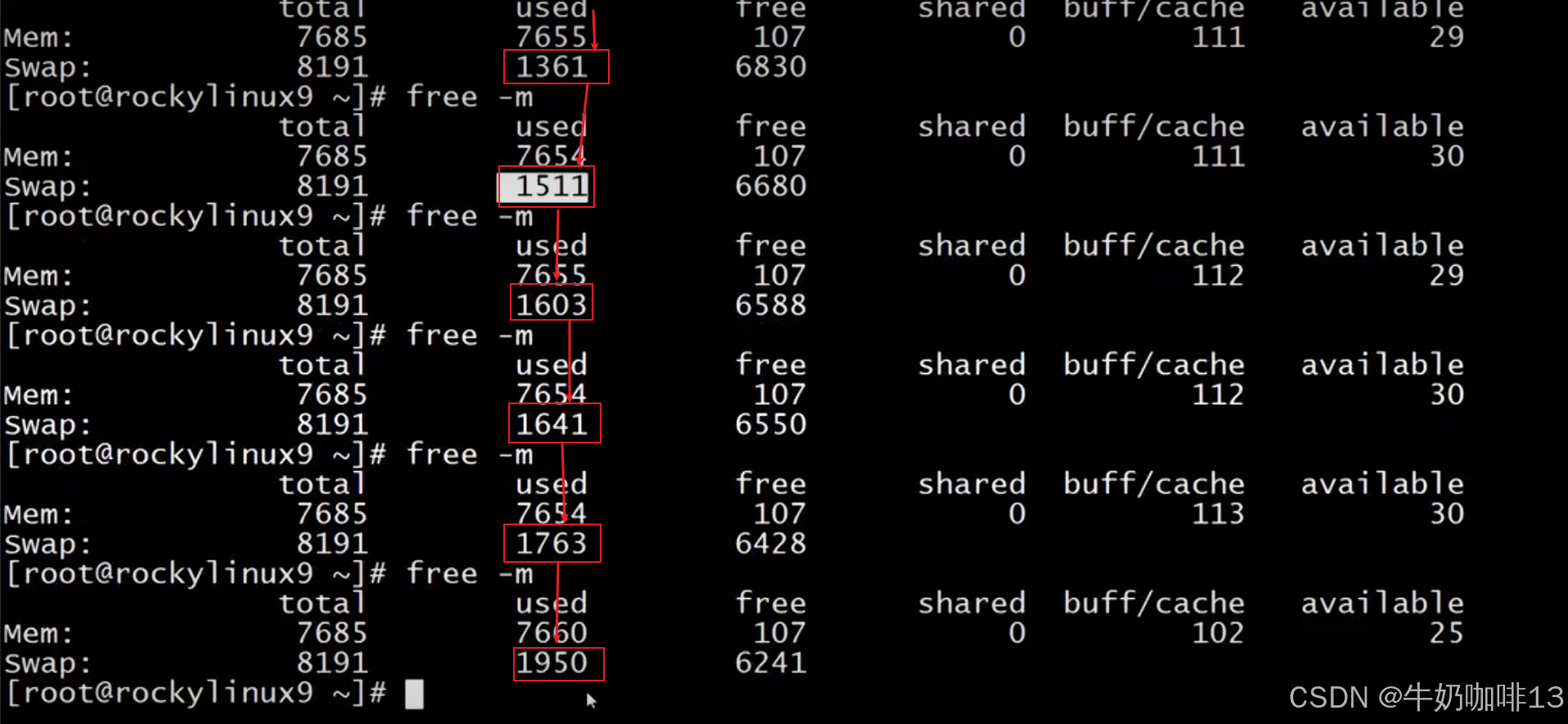

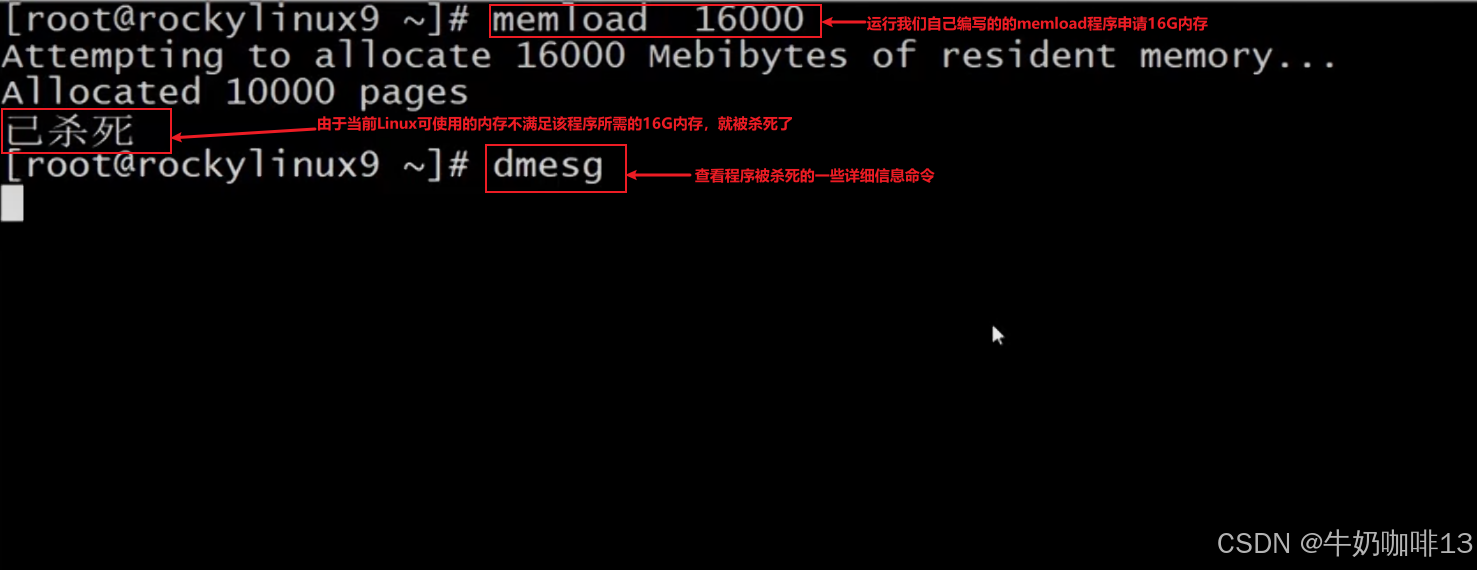
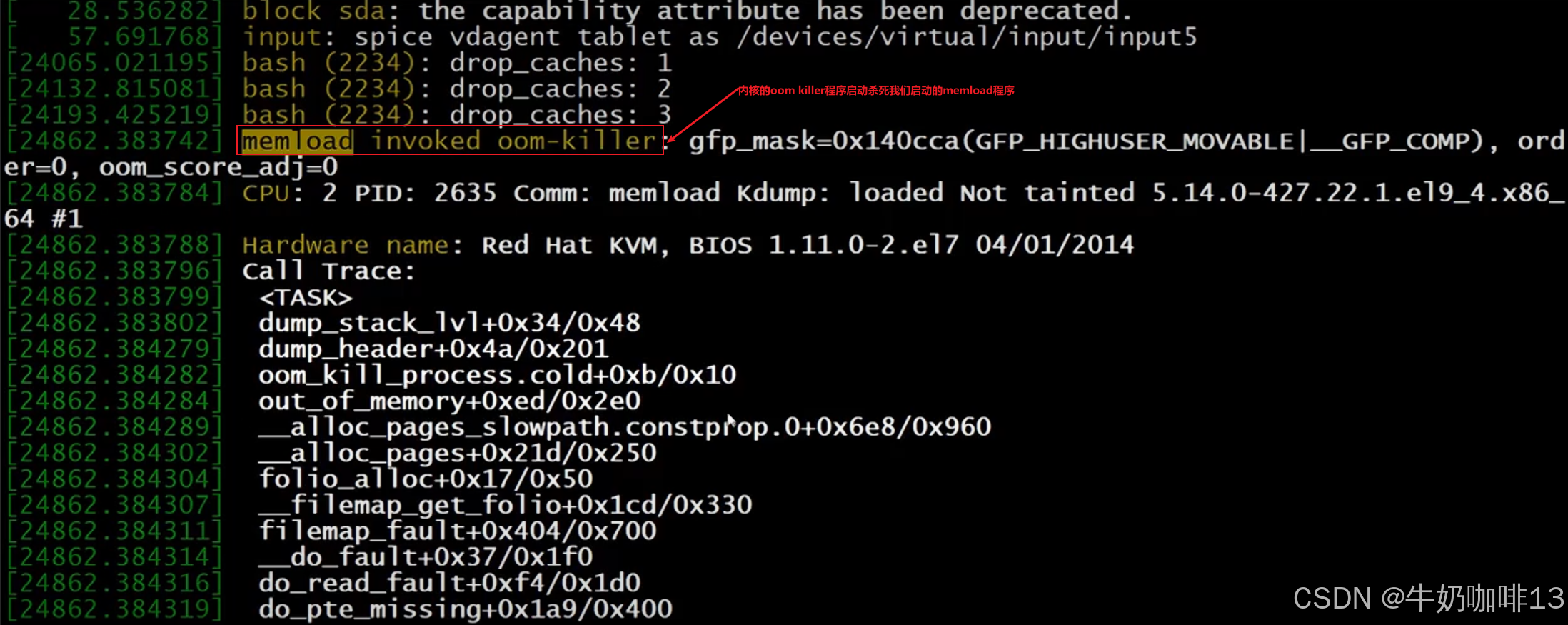
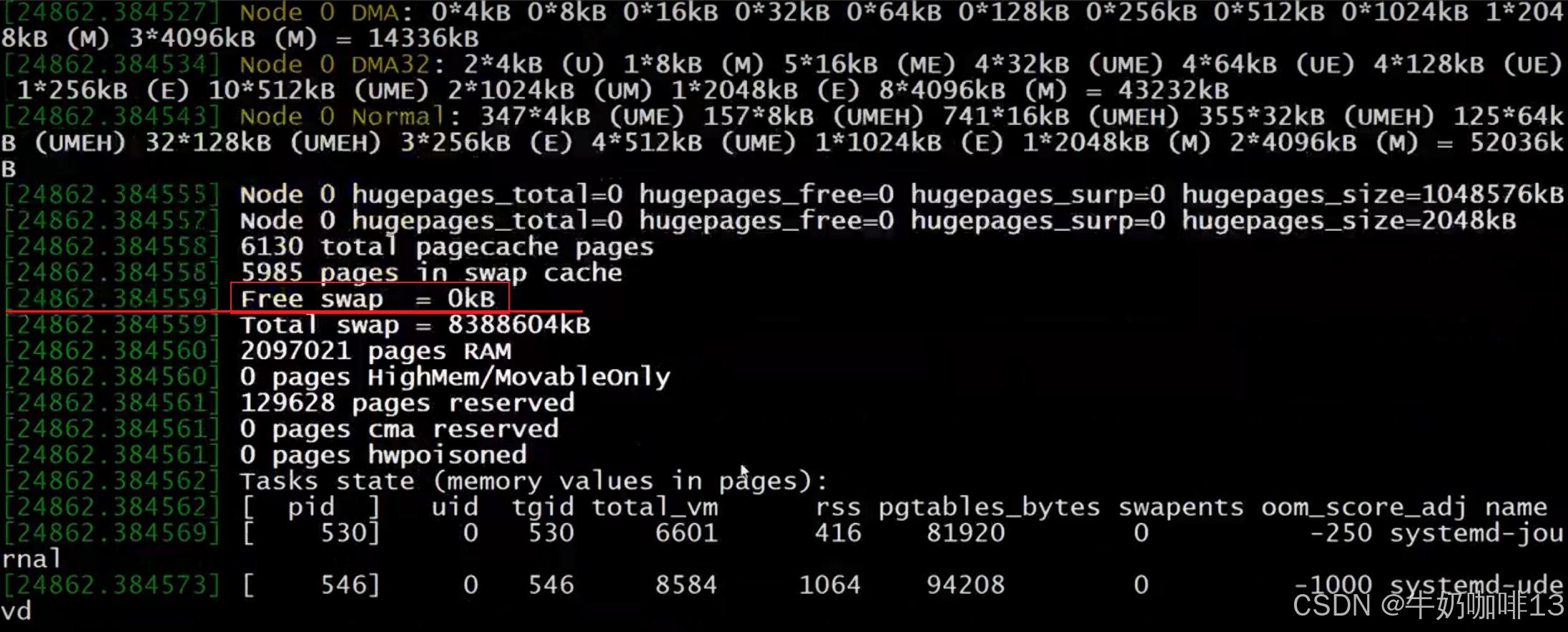
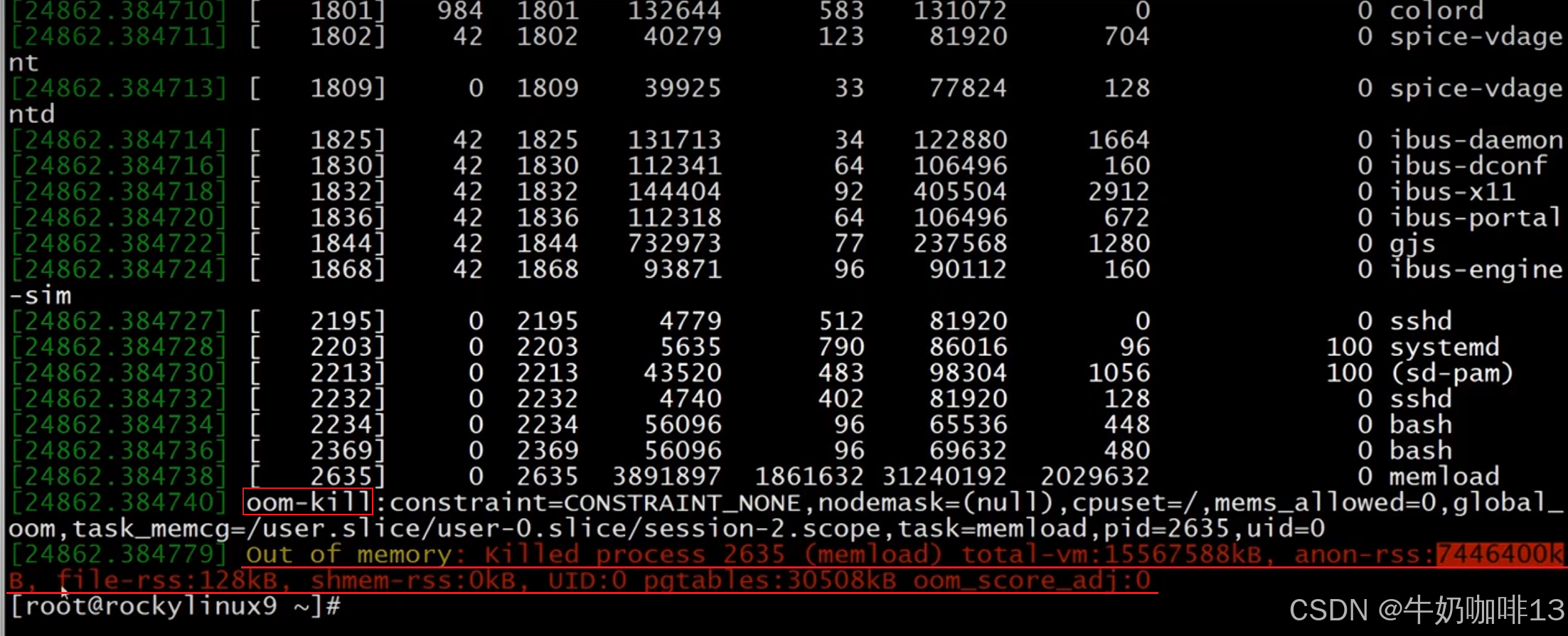
????????從上面的示例我們可以看到,其實Linux系統的內核會自己調度系統的內存資源進行處理,效果也是很好的,根本不用我們自己手動釋放內存資源(特別是生產環境一般不建議自己手動釋放資源和重啟系統,這樣造成的風險會比較高)。
三、swappiness
????????swappiness值的大小對如何使用swap分區是有著很大的聯系的。swappiness=0的時候表示最大限度使用物理內存,然后才是 swap空間,swappiness=100的時候表示積極的使用swap分區,并且把內存上的數據及時的搬運到swap空間里面。linux的基本默認設置為60。
? ? ? ? 請注意:swap交換內存性能遠比不上物理內存,且過多使用swap反而會降低系統整體性能,這違背了創建swap交換內存的初衷。我們希望在物理內存即將到達滿荷時再使用交換內存swap,因此swappiness的值建議范圍在10-60的區間,而固態硬盤可以將這個值設置的偏高一些。
3.1、手動優化swap操作命令
#查看系統當前設置的swap值(值為60表示你的物理內存在使用到100-60=40%的時候,就開始使用swap交換了)
cat /proc/sys/vm/swappiness
#從操作系統層面來說,要盡可能使用物理內存(因為物理內存是比swap內存快很多的)我們這里臨時設置物理內存到70%的時候才使用swap交換
sysctl vm.swappiness=30
#設置vm.swappiness=30永久生效,則需要修改/etc/sysctl.conf配置文件在這個配置文件末尾添加上【vm.swappiness = 30】系統重啟后生效
vi /etc/sysctl.conf
3.2、手動刪除swap文件命令
#1-先停用內存交換空間文件
swapoff /data/swapfile1
#2-再直接移除這個內存空間交換文件
rm -rf /data/swapfile1
#3-注釋或直接刪除掉之前在/etc/fstab文件里追加的開機自動掛載配置內容
#/data/swapfile1 swap swap defaults 0 0







)


)




:記憶增強注意力機制在UNet中的創新應用-原理、實現與性能提升)


