sc-atac的基礎知識
**fragment**是ATAC-seq實驗中的一個重要概念,它指的是通過Tn5轉座酶對DNA分子進行酶切,然后經由雙端測序得到的序列。
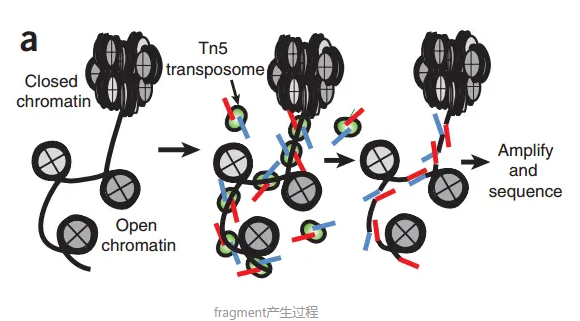
根據Tn5插入導致的偏移從read比對得到的位置推斷出fragment的起始和結束位置。根據之前的報道,Tn5轉座酶以同源二聚體的形式結合到DNA上,在兩個Tn5分子間隔著9-bp的DNA序列。根據這個情況,每個Tn5同源二聚體的結合事件會產生2個Insertions,中間隔著9bp。因此,真實的"開放"位置的中心在Tn5二聚體的正中間,而不是Tn5的插入位置。為了盡可能的還原真實情況,我們對Tn5的Insertions進行了校正,即正鏈的插入結果往右移動4bp(+4 bp), 負鏈的插入結果往左偏移5bp(-5 bp)。這個和最早提出的ATAC-seq里的描述是一致的。因此,在ArchR中,"fragment"指的是一個table或genomic ranges對象, 記錄在染色體上,經過偏移校正后的單堿基起始位置,以及經過偏移校正后單堿基結束位置,每個fragment都會對應唯一的細胞條形碼。類似的,"Insertions"這得是偏移校正后的單堿基位置,它位于開放位置的正中心。(https://www.jianshu.com/p/f7975da8e1e8)
- Tn5 轉座酶(綠色剪刀圖標)只能切割 開放染色質(Open chromatin,線條松散)。
- 在封閉染色質(Closed chromatin,線條緊密)處,Tn5 無法進入,因此不切割。
- Tn5 在開放區域切割后,插入測序接頭(adapters,灰色小條),形成 可測序的 DNA 片段。
- 這些片段經過 PCR 擴增 & 測序,最終得到 開放染色質信號峰。
“只有染色質松開的區域才會被 Tn5 切割并變成可測序的 ATAC 片段。”
Tn5 轉座酶是同源二聚體
什么是同源二聚體,組蛋白是八聚體嗎?兩者什么區別
一句話區分:
- 同源二聚體 = 2 個相同蛋白抱在一起;
- 組蛋白八聚體 = 8 個不同組蛋白(2×H2A、2×H2B、2×H3、2×H4)按固定比例拼成核小體核心。
1 同源二聚體(homo-dimer)
- 定義:由 兩條完全相同的肽鏈/蛋白 非共價結合而成的功能單位。
- ATAC-seq 場景:Tn5 轉座酶只有 兩條一模一樣的 Tn5 分子 同時結合 DNA,才能切割并插入接頭。
2 組蛋白八聚體(histone octamer)
- 組成:
(H2A-H2B) × 2 (H3-H4) × 2 共 8 條肽鏈 - 功能:繞成核小體核心,把 DNA 纏成“線軸”。
3 核心差異
| 維度 | 同源二聚體 | 組蛋白八聚體 |
|---|---|---|
| 鏈數 | 2 條相同蛋白 | 8 條不同蛋白 |
| 蛋白種類 | 1 種 | 4 種(H2A、H2B、H3、H4) |
| 生物學角色 | 酶活性單位(如 Tn5) | 染色質結構骨架 |
| 是否完全相同 | ? 是 | ? 否 |
根據之前的報道,Tn5轉座酶以同源二聚體的形式結合到DNA上,在兩個Tn5分子間隔著9-bp的DNA序列。什么意思
意思是:
Tn5 轉座酶只有兩條完全相同的酶鏈(同源二聚體)同時抓住 DNA,它們之間被 9 個堿基對(9 bp)的 DNA 片段隔開;
- 正鏈酶切在 +4 bp 處
- 負鏈酶切在 -5 bp 處
校正后,這兩個切點中間正好留下 9 bp 的“間隙”,真正的開放染色質中心就在這段間隙的正中間。
根據這個情況,每個Tn5同源二聚體的結合事件會產生2個Insertions,中間隔著9bp。什么是Insertions
在 ATAC-seq 里,Insertion 指的是 Tn5 轉座酶在 DNA 上實際切割并把測序接頭“插入”進去的那一個單堿基點。
- 一個 Tn5 同源二聚體結合事件會 同時切兩下,因此 產生 2 個這樣的插入點(兩條鏈各一個)。
- 這兩個插入點之間正好隔著 9 bp 的 DNA 片段。
Insertions與Fragment的區別
-
Insertions 是 單個堿基點(Tn5 二聚體中心),
例如 chr1:1000(正鏈 +4 校正后)。 -
Fragment 是 一條線段(起點—終點),
例如 chr1:1000–1001(起點 1000,終點 1001),長度 1 bp,正好以 Insertion 點為中心。
因此,Insertion 位于 Fragment 的正中間,兩者校正后的坐標只差一個“線段寬度”,方向相反的兩端各 1 bp。
為什么使用ArchR
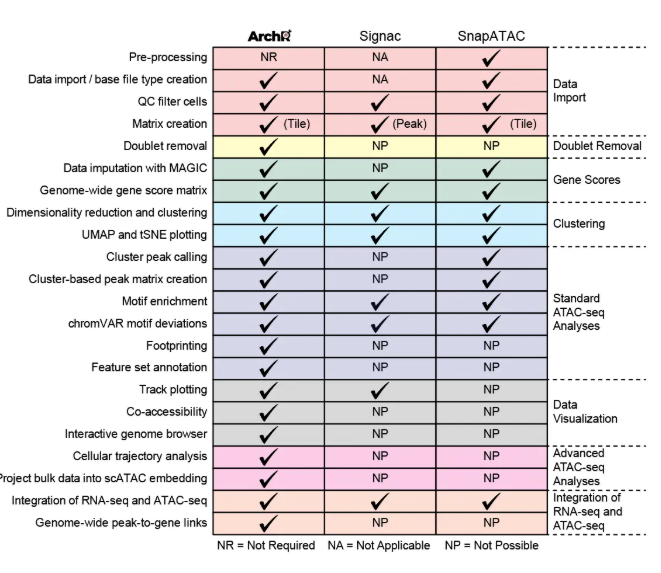
- 行標題:表示不同的功能模塊,如數據導入(Data import)、雙細胞去除(Doublet Removal)、基因得分(Gene Scores)、聚類(Clustering)、標準ATAC-seq分析(Standard ATAC-seq Analyses)、數據可視化(Data Visualization)和高級ATAC-seq分析(Advanced ATAC-seq Analyses)等。
ArchR通過優化數據結構降低了內存消耗,使用并行提高了運行速度,因此保證其性能優于其他同類型工具
什么是Arrow文件/ArchRProject
proj <- ArchRProject(ArrowFiles = ArrowFiles,genomeAnnotation = genomeAnnotation,geneAnnotation = geneAnnotation,copyArrows = TRUE
)
- Arrow 文件的作用
- Arrow 文件:是 ArchR 項目中用于存儲每個獨立樣本所有相關信息的文件格式。這些信息包括元數據(如樣本名稱、實驗條件等)、開放的染色質片段(fragments)以及數據矩陣等。
- 獨立樣本:每個 Arrow 文件對應一個獨立樣本,這個樣本最好是詳盡的分析單元,例如在特定實驗條件下的單個重復實驗。
- Arrow 文件的內容
- 文件內容:Arrow 文件記錄了每個樣本的所有相關信息,這些信息對于后續的分析至關重要。
- 文件路徑:Arrow 文件實際上是存儲在磁盤上的 HDF5 文件,而不是內存中的 R 對象。
·Arrow 文件:存儲在磁盤上的文件,使用 HDF5 格式,可以存儲大量數據,并且支持快速讀取和寫入。
·R 對象:存儲在內存中的數據結構,用于數據處理和分析,但不適合存儲大量數據,因為內存容量有限。
- ArchR 處理 Arrow 文件的方式
- 編輯和更新:在創建 Arrow 文件以及進行一些附加分析時,ArchR 會編輯和更新相應的 Arrow 文件,添加額外的信息層。
- 高效訪問:通過使用 ArchRProject 對象,ArchR 可以將多個 Arrow 文件關聯到一個分析框架中,從而確保在 R 中能高效訪問這些文件。
- ArchRProject 對象的作用
- 內存占用:ArchRProject 對象本身占用的內存不多,因為它主要負責關聯磁盤上的 Arrow 文件,而不是存儲文件內容本身。
- 分析框架:ArchRProject 對象將多個 Arrow 文件關聯到一個分析框架中,使得在 R 中可以高效地訪問和處理這些文件。
- 總結
- Arrow 文件:存儲每個樣本所有相關信息的 HDF5 文件,存儲在磁盤上。
- ArchRProject 對象:用于關聯多個 Arrow 文件,使其在 R 中高效訪問,占用內存少。
- 處理流程:在創建和分析過程中,ArchR 會更新 Arrow 文件,添加額外信息層,以支持復雜的數據分析。
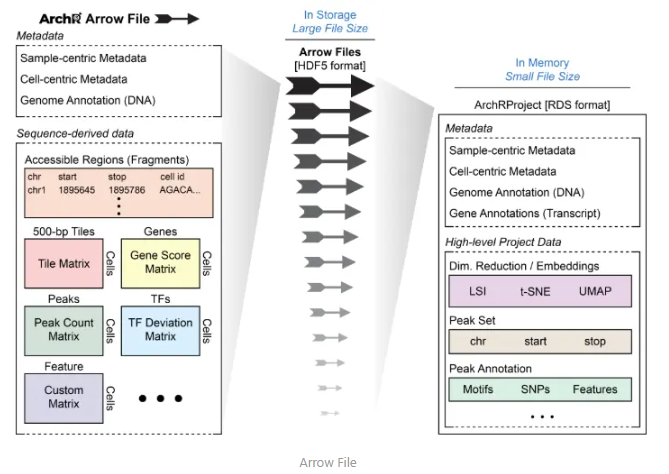
這張圖展示了 ArchR 項目中== Arrow 文件==和 ArchRProject 對象的結構和內容,以及它們在存儲和內存中的不同格式。
左側:Arrow 文件(存儲在磁盤上)
- 格式:HDF5 格式,文件體積較大。
- 內容:
- Metadata(元數據):
- 樣本中心元數據(Sample-centric Metadata)
- 細胞中心元數據(Cell-centric Metadata)
- 基因組注釋(Genome Annotation,DNA)
- Sequence-derived data(序列衍生數據):
- 可訪問區域(Accessible Regions,Fragments)
- 500 bp 的片段(Tiles)
- 基因得分矩陣(Gene Score Matrix)
- 峰值(Peaks)
- 峰值計數矩陣(Peak Count Matrix)
- 轉錄因子偏差矩陣(TF Deviation Matrix)
- 細胞類型矩陣(Cell Type Matrix)
- Metadata(元數據):
右側:ArchRProject 對象(加載到內存中)
- 格式:RDS 格式,文件體積較小。
- 內容:
- Metadata(元數據):
- 樣本中心元數據(Sample-centric Metadata)
- 細胞中心元數據(Cell-centric Metadata)
- 基因組注釋(Genome Annotation,DNA 和轉錄本)
- High-level Project Data(高級項目數據):
- 降維/嵌入(Dim. Reduction / Embeddings,如 LSI、t-SNE、UMAP)
- 峰值集合(Peak Set,包括染色體位置、起始、終止位置)
- 峰值注釋(Peak Annotation,包括 Motifs、SNPs、Features)
- Metadata(元數據):
總結
- Arrow 文件存儲了單細胞 ATAC-seq 數據的原始信息,包括元數據和序列衍生數據,文件體積較大,存儲在磁盤上。
- ArchRProject 對象是一個內存中的對象,包含了 Arrow 文件的索引和一些高級分析數據,文件體積較小,便于在內存中快速訪問和處理。
- 通過使用 ArchRProject 對象,可以高效地訪問和管理磁盤上的 Arrow 文件,同時利用內存中的對象進行快速分析。
有一些操作會直接修改Arrow文件,而一些操作會先作用于ArchRproject,接著反過來更新每個相關Arrow文件。因為Arrow文件是以非常大的HDF5格式存放,所以ArchR的get-er函數通過和ArchRProject進行交互獲取數據,而add-er函數既能直接在Arrow文件中添加數據,也能直接在ArchRpoject里添加數據,或者通過ArchRpoject向Arrow文件添加數據。




:記憶增強注意力機制在UNet中的創新應用-原理、實現與性能提升)













:TApplication窗體)
自定義相機渲染到Canvas(離屏渲染))