scrapy 庫復習
scrapy的概念:Scrapy是一個為了爬取網站數據,提取結構性數據而編寫的應用框架
scrapy框架的運行流程以及數據傳遞過程:
- 爬蟲中起始的url構造成request對象–>爬蟲中間件–>引擎–>調度器
- 調度器把request–>引擎–>下載中間件—>下載器
- 下載器發送請求,獲取response響應---->下載中間件---->引擎—>爬蟲中間件—>爬蟲
- 爬蟲提取url地址,組裝成request對象---->爬蟲中間件—>引擎—>調度器,重復步驟2
- 爬蟲提取數據—>引擎—>管道處理和保存數據
創建項目和爬蟲
scrapy startproject <項目名稱>
scrapy genspider <爬蟲名字> <允許爬取的域名>
網上找的簡單實例
import scrapyclass ItcastSpider(scrapy.Spider):# 爬蟲名字name = 'itcast'# 允許爬取的范圍allowed_domains = ['itcast.cn']# 開始爬取的url地址start_urls = ['http://www.itcast.cn/channel/teacher.shtml']# 數據提取的方法,接受下載中間件傳過來的responsedef parse(self, response):# scrapy的response對象可以直接進行xpathnames = response.xpath('//div[@class="tea_con"]//li/div/h3/text()')print(names)# 獲取具體數據文本的方式如下# 分組li_list = response.xpath('//div[@class="tea_con"]//li')for li in li_list:# 創建一個數據字典item = {}# 利用scrapy封裝好的xpath選擇器定位元素,并通過extract()或extract_first()來獲取結果item['name'] = li.xpath('.//h3/text()').extract_first() # 老師的名字item['level'] = li.xpath('.//h4/text()').extract_first() # 老師的級別item['text'] = li.xpath('.//p/text()').extract_first() # 老師的介紹print(item)
運行方式,在文件所在目錄內運行 scrapy crawl <爬蟲名>
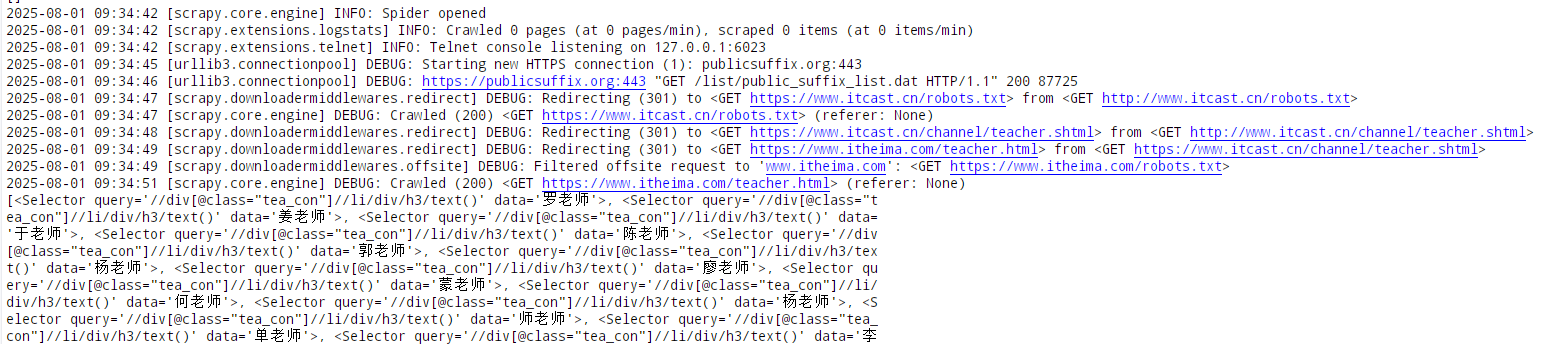
注意:
- scrapy.Spider爬蟲類中必須有名為parse的解析
- 如果網站結構層次比較復雜,也可以自定義其他解析函數
- 在解析函數中提取的url地址如果要發送請求,則必須屬于allowed_domains范圍內,但是start_urls中的url地址不受這個限制,我們會在后續的課程中學習如何在解析函數中構造發送請求
- 啟動爬蟲的時候注意啟動的位置,是在項目路徑下啟動
- parse()函數中使用yield返回數據,注意:解析函數中的yield能夠傳遞的對象只能是:BaseItem, Request, dict, None
解析并獲取scrapy爬蟲中的數據: 利用xpath規則字符串進行定位和提取
- response.xpath方法的返回結果是一個類似list的類型,其中包含的是selector對象,操作和列表一樣,但是有一些額外的方法
- 額外方法extract():返回一個包含有字符串的列表
- 額外方法extract_first():返回列表中的第一個字符串,列表為空沒有返回None
利用管道pipeline來處理(保存)數據
在pipelines.py文件中定義對數據的操作
- 定義一個管道類
- 重寫管道類的process_item方法
- process_item方法處理完item之后必須返回給引擎
import json
class ItcastPipeline():# 爬蟲文件中提取數據的方法每yield一次item,就會運行一次# 該方法為固定名稱函數def process_item(self, item, spider):print(item)return item
在settings.py配置啟用管道
ITEM_PIPELINES = {'myspider.pipelines.ItcastPipeline': 400
}
配置項中鍵為使用的管道類,管道類使用.進行分割,第一個為項目目錄,第二個為文件,第三個為定義的管道類。
配置項中值為管道的使用順序,設置的數值約小越優先執行,該值一般設置為1000以內。
scrapy 構造并發送請求
數據建模
通常在做項目的過程中,在 items.py 中進行數據建模
1、為什么建模
- 定義item即提前規劃好哪些字段需要抓,防止手誤,因為定義好之后,在運行過程中,系統會自動檢查
- 配合注釋一起可以清晰的知道要抓取哪些字段,沒有定義的字段不能抓取,在目標字段少的時候可以使用字典代替
- 使用scrapy的一些特定組件需要Item做支持,如scrapy的ImagesPipeline管道類,百度搜索了解更多
2、如何建模
在 item.py 文件中定義要提取的字段:
class MyspiderItem(scrapy.Item):name = scrapy.Field() #名字title = scrapy.Field() #職稱desc = scrapy.Field() #介紹
3、如何使用建好的模板
模板類定義以后需要在爬蟲中導入并且實例化,之后的使用方法和使用字典相同
from mySpider.mySpider.items import MyspiderItem #導入itemclass ItcastSpider(scrapy.Spider):……# 數據提取的方法,接受下載中間件傳過來的responsedef parse(self, response):……for li in li_list:# 創建一個數據字典item = MyspiderItem()# 利用scrapy封裝好的xpath選擇器定位元素,并通過extract()或extract_first()來獲取結果item['name'] = li.xpath('.//h3/text()').extract_first() # 老師的名字item['level'] = li.xpath('.//h4/text()').extract_first() # 老師的級別item['text'] = li.xpath('.//p/text()').extract_first() # 老師的介紹yield item
注意:
- from myspider.items import MyspiderItem這一行代碼中 注意item的正確導入路徑,忽略pycharm標記的錯誤
- python中的導入路徑要訣:從哪里開始運行,就從哪里開始導入
翻頁請求
requests模塊是如何實現翻頁請求的:
- 找到下一頁的URL地址
- 調用requests.get(url)
scrapy實現翻頁的思路:
- 找到下一頁的url地址
- 構造url地址的請求對象,傳遞給引擎
構造 Request 對象,并發送請求
1、 實現方法
- 確定url地址
- 構造請求,scrapy.Request(url,callback)
- callback:指定解析函數名稱,表示該請求返回的響應使用哪一個函數進行解析
- 把請求交給引擎:yield scrapy.Request(url,callback)
2、招聘爬蟲實例
通過網易招聘頁面爬取招聘信息,并實現翻頁請求
步驟:
1、獲取首頁的數據
2、尋找下一頁的地址,進行翻頁,獲取數據
spider 文件
import scrapyclass mySpider(scrapy.Spider):name = "joblistspider"allowed_domains = ["gz.gov.cn"]start_urls = ["https://www.gz.gov.cn/zwgk/zcjd/zcjd/index.html"]base_url = "https://www.gz.gov.cn/zwgk/zcjd/zcjd/index_"offset = 1end = '.html'def parse(self, response):#提取下一頁的hrefnex_url = response.xpath("//ul[@class='news_list']/li")for url in nex_url:item = {}item['name'] = url.xpath("./a/text()").extract_first()item['time'] = url.xpath("./span/text()").extract_first()item['link'] = url.xpath("./a/@href").extract_first()yield itemif self.offset <=40:self.offset += 1url = self.base_url+str(self.offset)+self.endyield scrapy.Request(url, callback=self.parse)
pipelines.py
import jsonclass JoblistspiderPipeline:def __init__(self):#self.f = open('joblist.json','w')self.f = open('joblist.csv','w',encoding='utf-8')def process_item(self, item, spider):content = json.dumps(dict(item), ensure_ascii=False) + ',\n'self.f.write(content)return itemdef close_spider(self, spider):self.f.close()
setting.py
ITEM_PIPELINES = {'Gzgov.pipelines.GzgovPipeline': 300,
}ROBOTSTXT_OBEY = False
scrapy.Request的更多參數
scrapy.Request(url[,callback,method="GET",headers,body,cookies,meta,dont_filter=False])
參數解釋:
- 中括號里的參數為可選參數
- callback:表示當前的url的響應交給哪個函數去處理
- meta:實現數據在不同的解析函數中傳遞,meta默認帶有部分數據,比如下載延遲,請求深度等
- dont_filter:默認為False,會過濾請求的url地址,即請求過的url地址不會繼續被請求,對需要重復請求的url地址可以把它設置為Ture,比如貼吧的翻頁請求,頁面的數據總是在變化;start_urls中的地址會被反復請求,否則程序不會啟動
- method:指定POST或GET請求
- headers:接收一個字典,其中不包括cookies
- cookies:接收一個字典,專門放置cookies
- body:接收json字符串,為POST的數據,發送payload_post請求時使用(在下一章節中會介紹post請求)
meta 參數使用
meta可以實現數據在不同的解析函數中的傳遞
……yield scrapy.Request(url, callback=self.parse,meta={"item":item})
特別注意
meta參數是一個字典
meta字典中有一個固定的鍵proxy,表示代理ip



)


)




:記憶增強注意力機制在UNet中的創新應用-原理、實現與性能提升)







