
文章概要
作為一名數據架構師,我經常被問到一個問題:在眾多數據庫選擇中,ClickHouse和PostgreSQL哪一個更適合我的項目?本文將深入探討這兩種數據庫系統的核心差異、性能對比、適用場景以及各自的優缺點,幫助您在技術選型時做出明智決策。我們將從架構設計、查詢性能、擴展能力、數據模型等多個維度進行全面分析,并結合實際案例展示它們在不同業務場景下的表現。
想象一下,你精心構建的數據分析系統,在關鍵時刻卻像一只蝸牛一樣緩慢爬行,用戶等待查詢結果的時間足夠喝完三杯咖啡——這不是科幻場景,而是許多企業在數據爆炸時代面臨的真實困境。在當今這個數據驅動的世界里,數據庫系統已經從默默無聞的"幕后英雄"變成了決定企業成敗的"關鍵先生"。它們就像是現代應用的心臟,負責泵送、處理和分析那些源源不斷的數據血液,為企業決策提供動力。
在這個數據庫的"武林大會"中,兩位"高手"格外引人注目。一位是ClickHouse,這位由俄羅斯互聯網巨頭Yandex打造的"列式存儲宗師",2016年"出山"后便以其驚人的分析速度震驚了數據界。它就像是數據分析界的"閃電俠",專為處理海量數據的在線分析處理(OLAP)而生,能夠將原本需要20分鐘的查詢縮短到毫秒級別,同時還能幫你省下一半的存儲空間——這簡直就是數據界的"減肥達人"!
另一位則是PostgreSQL,這位"老牌勁旅"已經馳騁數據庫江湖數十年,以其全面的能力和靈活的適應性贏得了無數開發者的心。作為行式存儲的代表,它就像是那個"全能型選手",在處理日常事務(OLTP)方面游刃有余,同時還能支持JSON等現代數據格式,堪稱數據庫界的"瑞士軍刀"。
那么,為什么要讓這兩位"高手"同臺競技呢?因為在這個數據量呈指數級增長的時代,選錯數據庫就像是給法拉利裝了拖拉機的引擎——不僅浪費資源,還會讓你的業務"寸步難行"。許多企業在成長過程中都會面臨這樣的"十字路口":是繼續使用熟悉的PostgreSQL,還是轉向專為分析而生的ClickHouse?這個選擇不僅關乎技術,更關乎企業的競爭力和未來發展。通過深入比較這兩種數據庫,我們可以幫助你在數據的海洋中找到最適合自己的那艘"船",而不是在選型的漩渦中迷失方向。
架構設計對比
ClickHouse的列式存儲架構
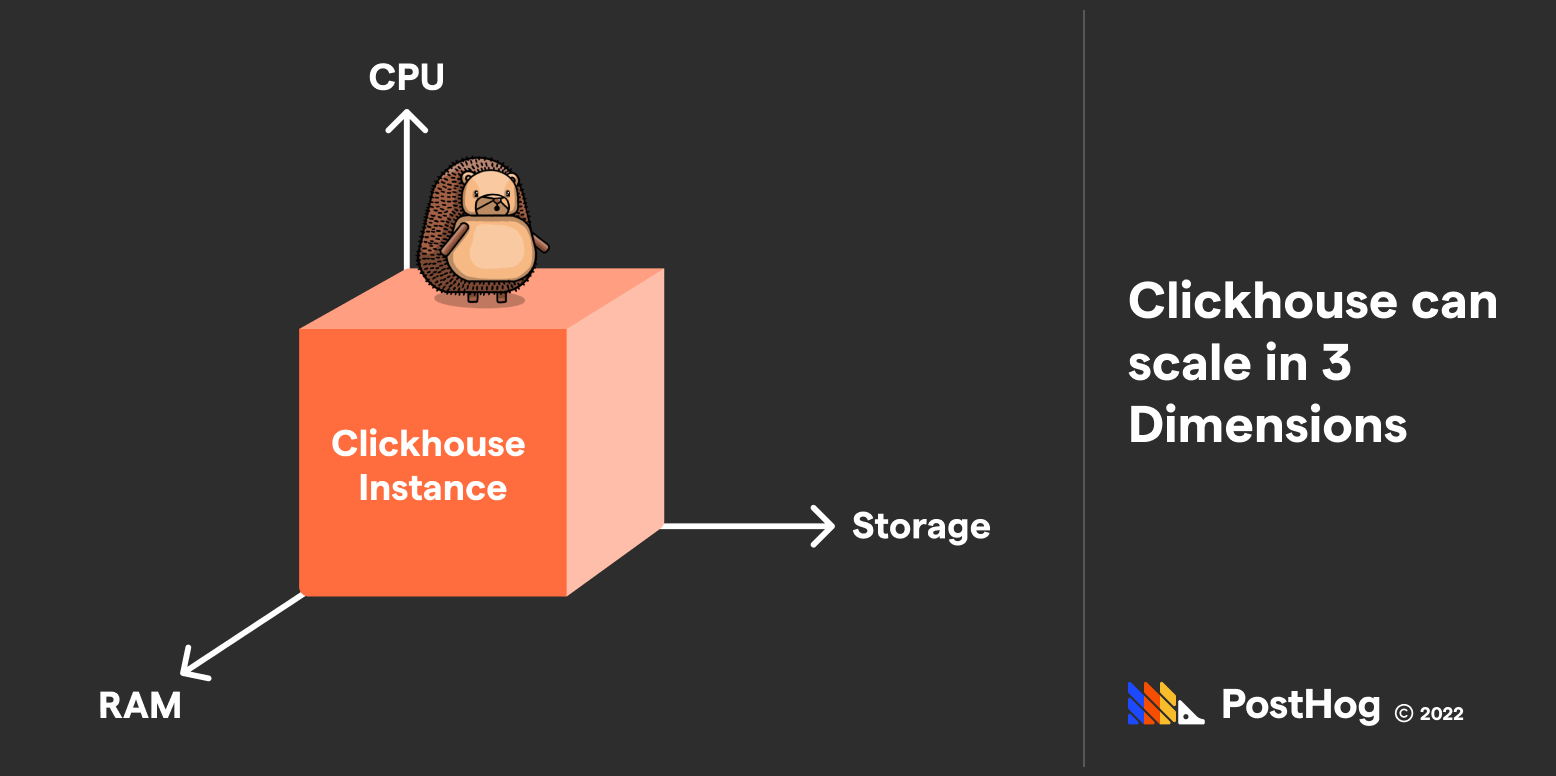
ClickHouse作為面向OLAP的列式數據庫,其架構設計堪稱數據分析領域的"特種部隊"。它采用了向量化執行引擎和列式存儲的完美結合,這種設計理念徹底顛覆了傳統數據庫的處理方式。
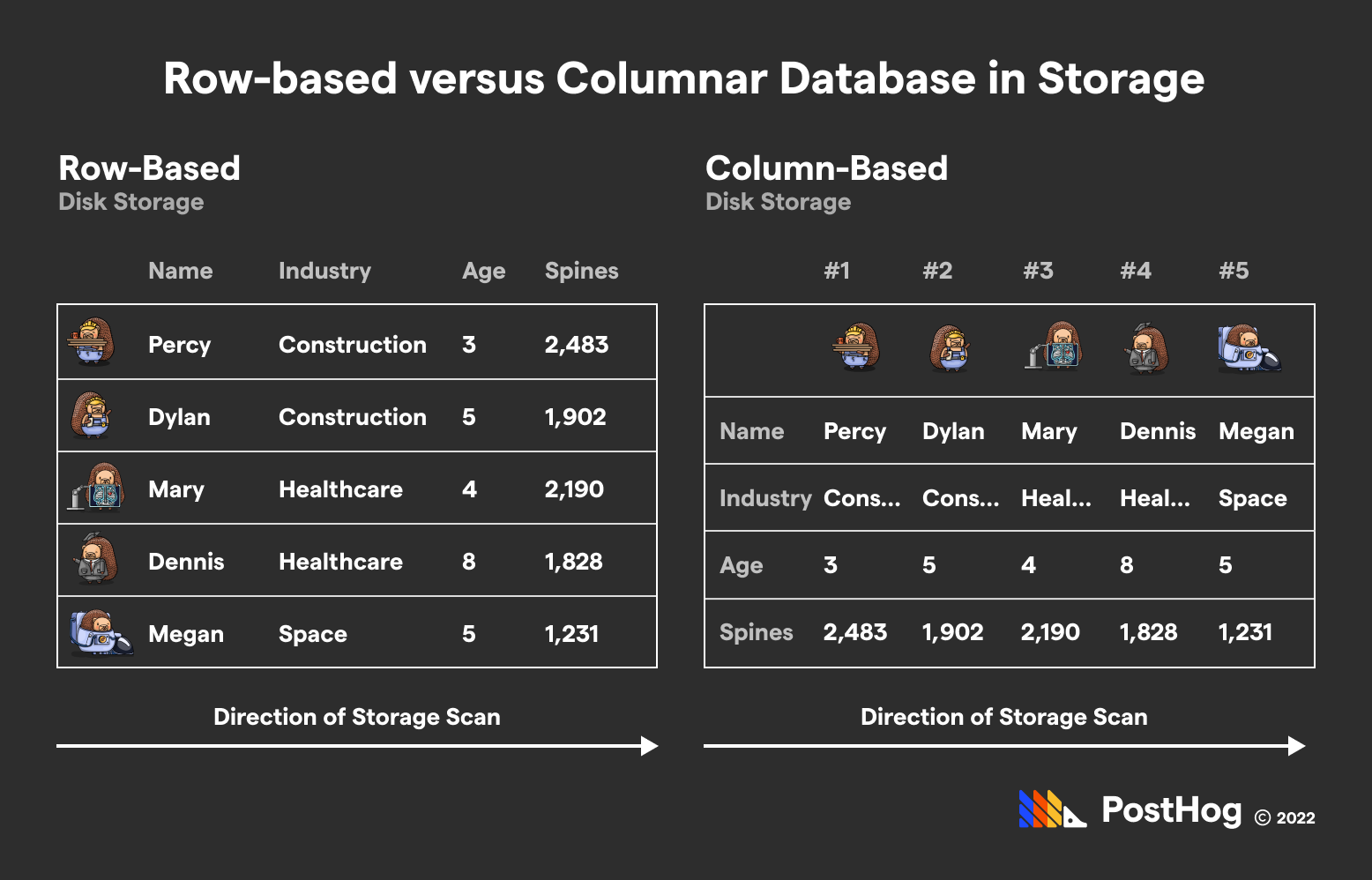
在ClickHouse的世界里,數據不是按我們熟悉的行方式存儲,而是按列組織。想象一下,如果傳統數據庫像是一本完整的通訊錄,每頁記錄一個人的所有信息;那么ClickHouse就像是把通訊錄拆成了多個獨立的小冊子——一個專門存放所有姓名,一個專門存放所有電話號碼,以此類推。
具體來說,ClickHouse的數據塊(Block)結構非常獨特:每個Block包含多行數據(默認為8192行),但數據在內存中是按列存儲的。這種設計使得單列數據在內存中是連續的,就像圖書館里同一類書籍被整齊地排列在一起,而不是按讀者借閱順序混合擺放。
有趣的事實:ClickHouse的列式存儲不僅優化了數據布局,還實現了驚人的壓縮率。在某些場景下,它可以將數據壓縮到原始大小的1/10甚至更小,這就像把一個裝滿空氣的袋子抽成真空,體積瞬間縮小!
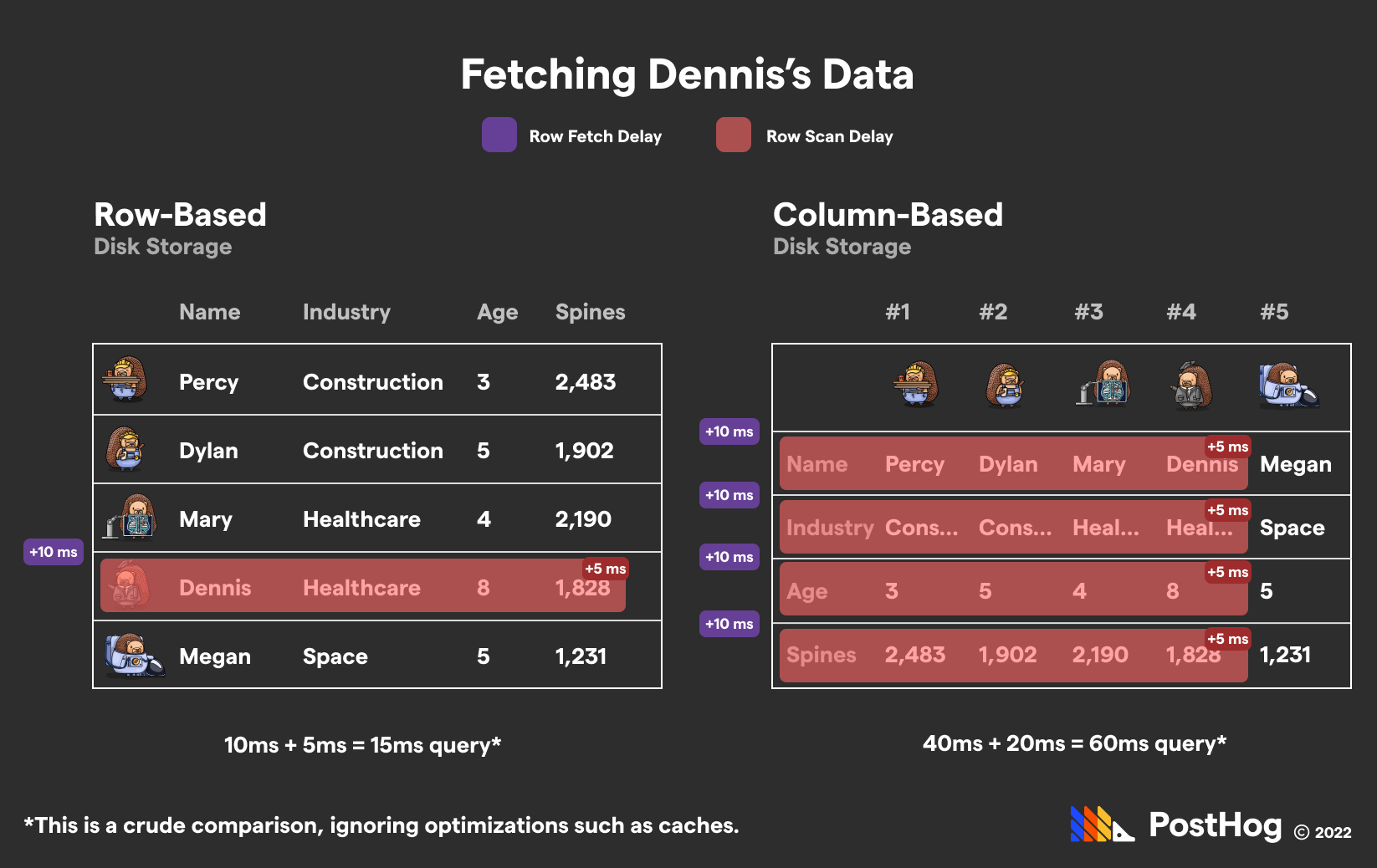
這種架構特別適合分析型查詢,因為大多數分析操作只涉及表中的少數幾列,而不是全部列。當您需要計算"所有用戶的平均年齡"時,ClickHouse只需讀取年齡列,而不必加載姓名、地址等其他無關數據,這大大提高了I/O效率。
PostgreSQL的行式存儲架構
與ClickHouse不同,PostgreSQL采用的是傳統的行式存儲架構,這種設計可以比作是一位經驗豐富的"多面手"。在PostgreSQL中,數據按行存儲,就像我們日常使用的表格,每一行代表一個完整的記錄,包含該記錄的所有字段。
PostgreSQL的行式存儲架構使其在處理事務性工作負載時表現出色。當您需要插入、更新或刪除單條記錄時,PostgreSQL只需操作包含該記錄的數據頁,而不必像列式存儲那樣可能需要修改多個列文件。這就像在通訊錄中更新一個人的聯系方式,只需找到那一頁修改即可,而不必翻遍多個分類冊子。
PostgreSQL還實現了流復制策略,采用主副本模型,數據被持續地從主節點復制到副本節點。這種設計確保了數據的一致性和高可用性,使其成為許多企業級應用的首選。
值得一提的是:PostgreSQL雖然采用行式存儲,但它也提供了一流的JSON支持,允許在關系型數據庫中靈活地處理半結構化數據。這就像一位西裝革履的商務人士,不僅精通傳統商務,還能玩轉最新潮的數字貨幣。
兩種架構對性能的影響
當我們將這兩種架構放在一起比較時,就像是對比一輛F1賽車和一輛全地形越野車——它們各自在不同的賽道上閃耀。
在分析型查詢方面,ClickHouse的列式存儲架構展現出壓倒性優勢。根據實際測試,ClickHouse在分析工作負載上的性能通常比PostgreSQL快5-10倍。在某些極端案例中,如OONI(開放網絡觀察站)的實踐經驗,他們將分析查詢時間從PostgreSQL的20分鐘縮短到了ClickHouse的毫秒級,同時還將存儲需求減半!
這種巨大差異源于列式存儲的幾個關鍵優勢:
- 更高的數據壓縮率:相似數據類型連續存儲使得壓縮算法更有效
- 更少的I/O操作:查詢只需讀取相關列,避免加載不必要的數據
- 更好的CPU緩存利用率:連續的數據布局提高了緩存命中率
- 向量化執行:ClickHouse可以批量處理數據,而不是逐行處理
然而,在事務處理場景下,PostgreSQL的行式存儲則占據上風。當需要頻繁插入、更新或刪除單條記錄時,PostgreSQL只需操作單個數據頁,而ClickHouse可能需要更新多個列文件,效率較低。
在擴展性方面,兩種數據庫也展現出不同的特點:
- PostgreSQL主要通過垂直擴展(增加更多CPU/RAM)和讀復制來提升性能,但在高吞吐量分析查詢方面可能會遇到瓶頸。
- ClickHouse則天然支持水平擴展,可以輕松跨多個節點分布數據和查詢,使其成為大規模分布式分析工作負載的理想選擇。
關鍵洞察:選擇哪種架構,最終取決于您的業務需求。如果您主要執行復雜的分析查詢處理大量數據,ClickHouse的列式存儲將是您的不二之選;如果您需要處理大量事務性操作,同時兼顧一些分析需求,PostgreSQL的行式存儲則更為適合。
架構決定命運,在數據庫世界尤其如此。了解這兩種數據庫的核心架構差異,將幫助您在技術選型時做出更明智的決策,為您的業務選擇最合適的數據基礎設施。

性能基準測試
在數據庫選型的世界里,性能往往是最關鍵的考量因素。今天,我們將見證一場精彩的對決:ClickHouse與PostgreSQL,兩位數據庫界的重量級選手,將在性能的擂臺上展開較量。誰能在數據分析的賽道上脫穎而出?讓我們拭目以待!
查詢速度對比:OLAP場景下的表現
當談到OLAP(在線分析處理)場景下的查詢速度,ClickHouse展現出了令人矚目的優勢,就像一輛專為賽道設計的跑車,而PostgreSQL則更像一輛全能型SUV。這種差距源于ClickHouse那革命性的列式存儲架構和向量化執行引擎。
ClickHouse在處理分析查詢時,采用了一種獨特的數據塊(Block)結構,每個Block包含多行數據(默認為8192行),并按列存儲在內存中。這種設計讓ClickHouse能夠:
- 高效利用CPU緩存:由于相關數據在內存中是連續存儲的,大大減少了緩存未命中的情況,就像廚師將常用調料放在手邊,減少了找調料的時間
- 實現向量化處理:一次性處理多行數據,大幅提升CPU指令執行效率,就像用一把大刀同時切多根菜絲,而不是一根一根地切
- 只讀取必要列:在分析查詢中,通常只需要訪問部分列,列式存儲避免了讀取不必要的數據,就像在圖書館只取需要的幾本書,而不是把整個書架都搬回家
相比之下,PostgreSQL作為傳統的行式存儲數據庫,在OLAP場景下面臨一些固有挑戰。雖然PostgreSQL可以通過垂直擴展(增加CPU/RAM)和讀復制來提升性能,但在處理大規模數據分析時,其性能瓶頸逐漸顯現,就像一輛SUV雖然能應對各種路況,但在專業賽道上很難超越跑車。
根據多項基準測試,在典型的OLAP工作負載下,ClickHouse的查詢性能通常比PostgreSQL快5-10倍。特別是在聚合計算、分組統計和復雜分析查詢方面,這種差距更為明顯。例如,在處理數十億行數據的聚合查詢時,ClickHouse可能只需幾秒鐘,而PostgreSQL可能需要幾分鐘甚至更長時間——這就像一個是即時響應,另一個則需要耐心等待。
數據壓縮效率比較
數據壓縮不僅影響存儲成本,還會對I/O性能產生直接影響,進而影響整體查詢性能。在這一方面,ClickHouse再次展現了其作為列式數據庫的卓越能力。
ClickHouse的列式存儲架構天然適合高壓縮率,這就像專業的收納師特別擅長將同類物品高效打包:
- 同類型數據:同一列中的數據類型相同,可以使用專門的壓縮算法,就像將所有襯衫疊在一起,所有褲子疊在一起,既整齊又節省空間
- 數據相似性:相鄰的數據值往往相似或重復,有利于壓縮算法發揮效果,就像同一系列的樂高積木可以緊密拼接
- 編碼優化:ClickHouse支持多種編碼方式,如字典編碼、增量編碼等,可根據數據特征自動選擇最優壓縮策略,就像擁有多種收納技巧的整理達人,能根據物品特點選擇最合適的收納方式
實際測試表明,ClickHouse通常可以實現5-10倍的數據壓縮率,這意味著原始數據為1TB,存儲在ClickHouse中可能只需要100-200GB。相比之下,PostgreSQL的行式存儲雖然也支持壓縮,但壓縮率通常較低,一般在2-3倍左右。
這種高壓縮率不僅節省了存儲空間,還減少了I/O操作,因為系統需要從磁盤讀取的數據量大幅減少,這也是ClickHouse查詢性能優異的重要原因之一——就像輕裝上陣的運動員,自然跑得更快。
實際案例分析:從20分鐘到毫秒的優化
理論上的性能優勢固然重要,但實際應用中的表現更能說明問題。讓我們來看一個真實案例:OONI(開放網絡觀察站)的數據庫遷移經驗。
OONI是一個全球性的網絡觀察項目,需要處理和分析大量的網絡測量數據。最初,他們使用PostgreSQL作為數據分析平臺,但隨著數據量的增長,遇到了嚴重的性能瓶頸:
- 分析查詢耗時:復雜的分析查詢需要約20分鐘才能完成,就像等待一鍋慢燉的湯
- 存儲壓力大:數據量快速增長,存儲成本不斷攀升,就像家里東西越來越多,空間卻不夠用
- 用戶體驗差:分析師需要等待很長時間才能獲取查詢結果,工作效率低下,就像在高峰期擠地鐵,既耗時又耗力
在遷移到ClickHouse后,結果令人震驚:
- 查詢性能提升:同樣的分析查詢,響應時間從20分鐘縮短到毫秒級別,性能提升數千倍,就像從騎自行車升級到了坐火箭
- 存儲效率提高:在存儲相同數據的情況下,存儲需求減少了一半,就像用真空袋收納衣物,瞬間騰出大量空間
- 用戶體驗改善:分析師可以實時交互式地探索數據,大大提高了工作效率,就像從撥號上網升級到了光纖寬帶
正如OONI團隊所言:“在ClickHouse中擁有所有數據意味著我們可以快速回答問題,而不必等待數小時查詢收斂,顯著提高了我們的內部數據分析能力。”
這個案例生動地展示了ClickHouse在處理大規模數據分析時的強大能力。當然,需要指出的是,這種性能提升主要適用于OLAP場景。在OLTP(在線事務處理)場景下,PostgreSQL仍然具有其獨特優勢,特別是在處理高并發的短事務方面,它就像是一個反應敏捷的拳擊手,快速而精準。
通過這些性能對比和實際案例,我們可以看到,在數據分析領域,ClickHouse憑借其列式存儲和向量化執行的優勢,確實提供了令人印象深刻的性能表現。但選擇哪種數據庫,還需要結合具體的業務需求、數據特征和使用場景來綜合考量——畢竟,沒有最好的數據庫,只有最適合的數據庫。
擴展能力分析
ClickHouse的水平擴展機制
在數據處理的"馬拉松"中,ClickHouse的水平擴展機制就像一支訓練有素的接力隊伍,能夠輕松應對PB級別的數據分析挑戰。它的擴展能力不是簡單的加法,而是近乎線性提升的乘法效應!
分片(Shard)機制是ClickHouse水平擴展的核心引擎。想象一下,你的數據就像一本巨大的百科全書,ClickHouse聰明地將其拆分成多個章節,每個章節(分片)由不同的節點負責管理。當數據量增長時,你只需添加更多"書架"(節點),系統就能自動平衡負載,這種設計讓擴展變得如此優雅。
在ClickHouse集群中,Keeper服務就像一位高效的圖書管理員,只負責管理"目錄"(元數據),記錄哪些數據存儲在哪個節點上,而不參與實際的"閱讀"(數據處理)。這種輕量級的元數據管理方式讓計算節點能夠專注于數據處理,大大提高了整體效率。
ClickHouse的副本(Replica)機制則是數據安全的"保險箱"。每個分片可以配置多個副本,就像為重要文件準備了多個備份。當某個節點"罷工"時,系統可以立即切換到其他副本,確保服務不中斷。這種設計不僅提高了系統的可用性,還能通過副本分布實現負載均衡,一舉兩得。
值得一提的是ClickHouse的向量化執行引擎,它就像一位高效的"批處理大師",以數據塊(Block)為基本處理單元(默認包含8192行數據),按列存儲在內存中。這種設計使得CPU緩存利用率更高,計算效率更優,為水平擴展提供了堅實基礎。
當執行查詢時,ClickHouse會智能地將查詢分發到相關節點,各節點并行處理自己的數據分片,最后將結果匯總返回。這種分布式查詢執行機制就像一支協作默契的交響樂團,每個樂手(節點)負責自己的部分,最終呈現出完美的和聲,讓ClickHouse能夠輕松應對PB級別的數據分析任務。
PostgreSQL的垂直擴展與讀復制
如果說ClickHouse是"水平擴展"的冠軍,那么PostgreSQL則是"垂直擴展"的健將。PostgreSQL傳統上更傾向于垂直擴展策略,就像是通過升級單臺超級計算機來提升性能,而不是組建一個計算機集群。這種策略通過增強單個服務器的硬件能力(如增加CPU、內存、更快的存儲)來提升性能,在數據量不大、并發請求有限的場景下非常有效,而且實現簡單,管理成本低。
PostgreSQL的讀復制功能是其水平擴展的主要手段。通過**流復制(Streaming Replication)**技術,PostgreSQL可以創建一個主節點(Master)和多個只讀副本(Replica)。主節點處理所有的寫操作,并將變更以流的形式同步到副本節點。讀操作則可以分發到主節點和所有副本節點,從而分散讀負載。這種設計就像一位主廚和多個幫手的關系,主廚負責創新菜品(寫操作),幫手們則負責為顧客提供現成的菜品(讀操作)。
PostgreSQL的復制機制基于預寫日志(WAL),主節點持續生成WAL記錄,副本節點通過應用這些WAL記錄來保持與主節點數據的一致性。這種機制確保了數據的強一致性,但也帶來了一些限制,就像同步錄音帶一樣,必須嚴格按照順序來。
近年來,PostgreSQL社區也開發了一些水平擴展解決方案,如Citus(現已成為PostgreSQL的擴展),它可以將PostgreSQL轉變為分布式數據庫,支持數據的分片存儲和并行查詢。但這些解決方案相比ClickHouse的原生分布式設計,在架構上更為復雜,配置和維護成本也更高,就像給一輛家用轎車加裝賽車引擎,雖然性能提升了,但維護難度也隨之增加。
PostgreSQL的擴展策略在面對高吞吐量的分析查詢時往往顯得力不從心。雖然可以通過增加更多的讀副本分散讀負載,但寫操作仍然受限于單個主節點的處理能力,這在處理大規模數據寫入時可能成為瓶頸,就像一條單行道,無論兩側有多少輔助道路,主干道的通行能力始終有限。
分布式環境下的表現對比
在分布式環境的"擂臺"上,ClickHouse和PostgreSQL展現出截然不同的"武功招式",這也決定了它們各自適用的"戰場"。
擴展效率方面,ClickHouse展現出明顯的優勢。根據實際測試數據,Aiven for ClickHouse數據庫的性能平均比Aiven for PostgreSQL高出5-10倍。在某些特定場景下,這種差距更為顯著。例如,OONI(網絡觀察站)的案例顯示,他們將分析查詢從PostgreSQL遷移到ClickHouse后,查詢時間從原來的20分鐘縮短到毫秒級別,同時存儲需求也減少了一半。這種提升就像從騎自行車升級到乘坐高鐵,差距不言而喻。
數據處理能力上,ClickHouse專為分布式環境設計,可以輕松處理PB級別的數據。其列式存儲和向量化執行引擎使得數據壓縮比更高,I/O效率更優。而PostgreSQL雖然通過擴展如Citus也能實現分布式處理,但在處理大規模數據分析時,性能和資源利用率通常不如ClickHouse,就像一輛普通轎車和一輛專門設計的越野車在崎嶇山路上的表現差異。
查詢復雜度方面,PostgreSQL在處理復雜的事務性查詢和關聯操作時更為靈活,支持完整的SQL標準和豐富的窗口函數。ClickHouse雖然也支持類SQL語言,但在某些復雜查詢場景下可能需要特殊的語法或變通方法,如使用LIMIT BY替代窗口函數,使用ANY JOIN減少Shuffle等。這就像比較一位全能型選手和一位專項選手,前者在各種項目上都有不錯的表現,后者則在特定項目上無人能及。
一致性保證上,PostgreSQL提供強一致性模型,所有副本節點最終都會與主節點保持完全一致。而ClickHouse在某些配置下可能采用最終一致性模型,優先保證查詢性能而非嚴格的一致性,這在某些對數據一致性要求極高的場景下可能需要特別注意。這就像比較一位嚴謹的會計師和一位快速估算師,前者追求精確到分,后者則追求快速得到大致結果。
運維復雜度方面,PostgreSQL的讀復制配置相對簡單,適合中小規模部署。ClickHouse的分布式集群雖然功能強大,但配置和維護更為復雜,需要專業的運維團隊支持。這就像比較一輛家用車和一架飛機,前者人人都能駕駛,后者則需要專業飛行員和地面支持團隊。
總的來說,在分布式環境下,ClickHouse更適合大規模數據分析場景,能夠提供卓越的查詢性能和良好的擴展性;而PostgreSQL則在事務處理和數據一致性方面表現更佳,適合對ACID特性要求高的應用。在實際應用中,許多組織選擇將兩者結合使用,用PostgreSQL處理事務性數據,用ClickHouse進行數據分析,通過數據同步機制實現優勢互補,就像一支球隊同時擁有出色的防守和進攻球員,根據不同情況派出最適合的陣容。
數據模型與查詢語言
ClickHouse的類SQL語言與擴展功能
ClickHouse采用了一種獨特的類SQL語言,它保留了傳統關系型數據庫的便利性,同時為分析型工作負載進行了專門優化。這種設計使得熟悉SQL的開發人員能夠快速上手,但又不失其強大的分析能力。
ClickHouse的SQL方言包含多項創新擴展,這些擴展專門針對大數據分析場景進行了優化:
-
LIMIT BY子句:這是ClickHouse的一大特色,可以用來替代傳統的窗口函數,在分組數據中獲取每組的前N條記錄,語法簡潔且執行高效。
SELECT * FROM table ORDER BY some_column LIMIT n BY group_column -
ANY JOIN:這是一種特殊的連接操作,旨在減少分布式環境下的數據Shuffle操作。當只需要匹配的任意一條記錄而非全部匹配時,ANY JOIN能顯著提升查詢性能。
-
分布式查詢優化:ClickHouse引入了GLOBAL修飾符,在處理小表與大表的右連接時特別有用。通過GLOBAL IN或GLOBAL JOIN,ClickHouse避免了在分布式環境中的重復計算,大幅提升了查詢效率。
有趣的是,ClickHouse的這些擴展功能雖然偏離了標準SQL,但卻完美契合了其"為分析而生"的設計理念,就像是為數據分析量身定制的一套"方言",讓復雜的大數據查詢變得簡單而高效。
PostgreSQL的標準SQL兼容性
PostgreSQL作為一款成熟的關系型數據庫管理系統,以其出色的標準SQL兼容性著稱。它嚴格遵循SQL標準,同時提供了豐富的擴展功能,使其成為OLTP工作負載的理想選擇。
PostgreSQL的SQL支持特點包括:
-
完整的SQL標準兼容:PostgreSQL支持大部分SQL:2011標準功能,包括復雜查詢、外鍵、觸發器、視圖等,使其能夠處理各種復雜的事務處理場景。
-
強大的JSON支持:PostgreSQL提供了一流的JSON支持,包括JSON和JSONB數據類型,以及豐富的JSON操作函數,使其在處理半結構化數據時表現出色。
-
高級索引功能:PostgreSQL支持多種索引類型,如B-tree、Hash、GiST、SP-GiST、GIN和BRIN,可以根據不同的查詢模式選擇最合適的索引策略。
-
豐富的數據類型:除了標準數據類型外,PostgreSQL還支持數組、hstore鍵值對、幾何類型、網絡地址類型等多種高級數據類型。
PostgreSQL的SQL實現就像一位"多才多藝的全能選手",在各種場景下都能表現出色,特別是在需要嚴格事務一致性的OLTP場景中,其標準SQL兼容性為開發人員提供了極大的便利和可靠性。
特殊查詢功能對比:窗口函數、連接操作等
當涉及到特殊查詢功能時,ClickHouse和PostgreSQL展現出了各自的設計哲學和優化方向。
窗口函數
-
PostgreSQL:提供了完整的窗口函數支持,包括ROW_NUMBER()、RANK()、DENSE_RANK()、LEAD()、LAG()等,符合SQL標準。這使得在PostgreSQL中進行復雜的分析計算變得直觀且強大。
-
ClickHouse:雖然不完全支持標準窗口函數,但通過LIMIT BY子句提供了類似的功能,專門優化了分組排序獲取前N條記錄的場景。這種設計雖然不夠通用,但在特定分析場景下性能更優。
連接操作
-
PostgreSQL:支持標準的JOIN操作,包括INNER JOIN、LEFT JOIN、RIGHT JOIN、FULL OUTER JOIN等,并提供了多種連接算法(如嵌套循環、哈希連接、歸并連接)以優化不同場景下的查詢性能。
-
ClickHouse:除了標準JOIN外,還提供了ANY JOIN這種特殊連接類型,特別適合分布式環境下的性能優化。在分布式查詢中,ClickHouse的GLOBAL修飾符可以有效減少數據傳輸和重復計算,提升查詢效率。
分布式查詢處理
-
PostgreSQL:通過流復制實現主從復制,主要采用主副本模型,數據在主節點上更新后流式傳輸到副本節點。這種模式適合讀多寫少的場景,但在處理大規模分布式分析查詢時可能面臨挑戰。
-
ClickHouse:原生設計為分布式系統,通過GLOBAL修飾符等優化機制,有效解決了分布式環境下的數據傾斜和重復計算問題。ClickHouse的查詢優化器專門針對列式存儲和向量化執行進行了優化,使其在復雜分析查詢中表現卓越。
從本質上說,PostgreSQL的查詢功能更像是一位"嚴謹的學者",遵循標準并提供全面的解決方案;而ClickHouse則像一位"創新的工程師",不拘泥于傳統,而是專注于解決特定問題并提供極致的性能。這兩種不同的哲學使得它們在各自的領域都能發揮最大的價值。

存儲引擎與數據管理
ClickHouse的多種存儲引擎解析
ClickHouse作為面向OLAP的列式數據庫,其存儲引擎(表引擎)是決定數據在操作系統層面文件系統讀寫、更新和刪除方式的核心技術。不同的存儲引擎提供了不同的存儲機制,以適應各種業務場景的需求。
ClickHouse最著名的存儲引擎家族是MergeTree系列,這是ClickHouse最強大和最常用的引擎類型。MergeTree引擎的主要特點是數據按主鍵排序存儲,支持數據分區、數據副本和數據采樣。在MergeTree家族中,又有多個變體:
-
ReplacingMergeTree:這種引擎在合并數據塊時會刪除具有相同排序鍵的重復行,只保留最后一行。它適用于需要去重的場景,如用戶行為日志分析。
-
CollapsingMergeTree:它通過"折疊"標記為1和-1的行來刪除數據。這種引擎設計用于處理需要頻繁更新和刪除的場景,如實時庫存管理。
-
VersionedCollapsingMergeTree:這是CollapsingMergeTree的增強版,它使用版本號來處理數據更新,解決了CollapsingMergeTree在數據插入順序不確定時可能產生的問題。
-
SummingMergeTree:這種引擎在合并數據塊時會對具有相同排序鍵的數值列進行求和,適用于預聚合場景,如流量統計。
-
AggregatingMergeTree:它允許在合并過程中使用聚合函數,適用于需要中間狀態聚合的復雜分析場景。
除了MergeTree系列,ClickHouse還提供了其他專用引擎:
- Log系列引擎:如TinyLog、StripeLog和Log,適用于小表數據快速寫入的場景。
- 分布式引擎:如Distributed,用于在多個服務器上執行查詢。
- 內存引擎:如Memory,將數據存儲在RAM中,提供極快的查詢速度,但重啟后數據會丟失。
- 集成引擎:如MySQL、PostgreSQL、HDFS等,用于直接查詢外部數據源。
ClickHouse的存儲引擎設計體現了其向量化執行的特點。數據在ClickHouse中以**數據塊(Block)**的形式組織,每個Block默認包含8192行數據,按列存儲。這種列式存儲方式使得單列數據在內存中是連續的,極大地提高了CPU緩存命中率,從而加速了查詢處理。
PostgreSQL的存儲機制
與ClickHouse不同,PostgreSQL采用傳統的行式存儲架構,這是大多數關系型數據庫的標準做法。在PostgreSQL中,數據按行存儲,每行的所有列值連續存儲在一起。這種設計非常適合OLTP(在線事務處理)工作負載,其中通常需要訪問或操作整行數據。
PostgreSQL的存儲機制基于堆表(Heap Table)結構,數據在物理文件中無特定順序存儲。當插入新數據時,PostgreSQL會將其放在第一個有足夠空間的位置,這可能導致數據在磁盤上分散存儲。為了提高查詢性能,PostgreSQL使用索引來加速數據檢索,最常用的是B-tree索引,此外還支持GiST、SP-GiST、GIN和BRIN等多種索引類型。
PostgreSQL的存儲管理還包括以下幾個關鍵組件:
-
WAL(Write-Ahead Logging):這是PostgreSQL的預寫日志機制,確保數據持久性和崩潰恢復。所有數據修改首先記錄到WAL日志,然后再應用到實際數據文件中。
-
MVCC(多版本并發控制):PostgreSQL使用MVCC來管理并發訪問,每個事務看到的是數據庫的一個快照。這意味著讀操作不會阻塞寫操作,反之亦然,大大提高了并發性能。
-
TOAST(The Oversized-Attribute Storage Technique):用于存儲大字段(如大文本或二進制數據)的技術。當行數據超過一定大小時,PostgreSQL會自動將大字段壓縮并存儲到單獨的表中,而在原表中保留指針。
-
表空間(Tablespaces):允許將數據庫對象(如表和索引)存儲在文件系統的不同位置,有助于I/O負載均衡和管理存儲資源。
PostgreSQL的**流復制(Streaming Replication)**機制是其高可用性的核心。在這種模式下,一個主服務器(Primary)持續將WAL記錄流式傳輸到一個或多個備用服務器(Standby),備用服務器可以處理只讀查詢,從而實現讀擴展和負載均衡。
與ClickHouse專注于分析查詢不同,PostgreSQL的存儲機制設計考慮了事務完整性和數據一致性,使其成為需要ACID特性的OLTP工作負載的理想選擇。
數據更新與刪除策略比較
ClickHouse和PostgreSQL在數據更新和刪除策略上存在顯著差異,這反映了它們不同的設計目標和工作負載定位。
ClickHouse的數據更新與刪除策略:
ClickHouse最初被設計為主要用于數據插入和查詢的系統,而不是頻繁更新和刪除。因此,它的數據更新和刪除機制與傳統關系型數據庫有很大不同。
-
MUTATION操作:ClickHouse提供了特殊的
ALTER TABLE ... UPDATE和ALTER TABLE ... DELETE語句,這些操作被稱為MUTATION。它們不是立即執行的,而是在后臺異步進行,這可能會影響查詢性能,特別是在大型表上。 -
MergeTree引擎的特殊處理:ClickHouse的MergeTree系列引擎通過特殊的合并策略來處理數據更新和刪除:
- ReplacingMergeTree:在合并過程中刪除重復行,只保留最后一行,實現"更新"效果。
- CollapsingMergeTree:通過插入符號相反的行(標記為1和-1)來"刪除"數據,在合并時折疊這些行。
- VersionedCollapsingMergeTree:使用版本號來確保正確的更新順序,避免CollapsingMergeTree可能出現的順序問題。
-
輕量級刪除:較新版本的ClickHouse引入了輕量級刪除操作
DELETE FROM table WHERE ...,它比傳統的MUTATION操作更高效,但仍然是異步執行的。
ClickHouse的這些策略表明,它更適合追加寫入的工作負載,而不是頻繁更新的場景。數據更新和刪除在ClickHouse中被視為特殊操作,而不是常規操作。
PostgreSQL的數據更新與刪除策略:
PostgreSQL作為傳統的RDBMS,提供了標準且高效的數據更新和刪除機制:
-
即時更新與刪除:PostgreSQL的
UPDATE和DELETE語句是立即執行的,符合ACID特性。當執行這些操作時,PostgreSQL會:- 找到受影響的行
- 對行加鎖(如果需要)
- 創建新版本的數據行(對于UPDATE)或標記行為已刪除(對于DELETE)
- 將更改寫入WAL日志以確保持久性
-
MVCC機制:PostgreSQL使用MVCC來處理并發更新。當一行被更新時,PostgreSQL不會修改原始行,而是創建一個新版本,并標記舊行為"過期"。其他事務仍可以看到舊版本,直到它們結束。這提供了高并發性,但也意味著需要定期清理過期行(通過VACUUM過程)。
-
事務支持:PostgreSQL提供完整的事務支持,允許將多個更新和刪除操作組合到原子事務中,確保數據一致性。
策略比較與適用場景:
-
性能考慮:
- ClickHouse的更新和刪除操作通常比PostgreSQL慢,因為它們是異步的,并且可能涉及大量數據重組。
- PostgreSQL提供即時、事務性的更新和刪除,適合需要快速響應的OLTP場景。
-
數據一致性:
- PostgreSQL提供強一致性和ACID保證,更新和刪除操作是立即可見且持久的。
- ClickHouse的更新和刪除操作最終是一致的,可能需要一段時間才能完全生效。
-
適用場景:
- ClickHouse適合分析型工作負載,其中數據主要是批量插入,更新和刪除操作較少。例如,日志分析、監控數據、業務智能等場景。
- PostgreSQL適合事務型工作負載,其中數據頻繁更新和刪除,需要強一致性保證。例如,電子商務系統、銀行交易、用戶管理等場景。
-
混合策略:
- 在實際應用中,一些組織采用混合策略:使用PostgreSQL處理事務性數據,然后將數據定期導入ClickHouse進行分析。這種架構結合了兩種數據庫的優勢。
總結來說,ClickHouse和PostgreSQL在數據更新和刪除策略上的差異反映了它們不同的設計哲學:ClickHouse專注于高性能分析,而PostgreSQL專注于事務完整性和通用性。選擇哪種數據庫應取決于您的具體工作負載和業務需求。

適用場景分析
ClickHouse最適合的業務場景
ClickHouse作為面向OLAP的列式數據庫,在特定業務場景下簡直就是數據分析的"超級跑車",其性能優勢令人嘆為觀止。以下場景中,ClickHouse能夠充分發揮其威力:
大規模數據分析與商業智能:當企業需要處理TB甚至PB級別的數據時,ClickHouse的列式存儲架構和高壓縮率能夠顯著提高查詢性能。想象一下,在傳統數據庫中需要20分鐘才能完成的復雜聚合查詢,在ClickHouse中可能只需要毫秒級響應,這種性能差距對于需要實時決策的業務來說簡直是天壤之別。正如OONI的案例所示,他們成功將分析查詢時間從PostgreSQL的20分鐘縮短到ClickHouse的毫秒級,同時還將存儲需求減半。
實時監控與儀表板:ClickHouse擅長處理高并發查詢,使其成為構建實時監控系統和業務儀表板的理想選擇。無論是IT基礎設施監控、用戶行為分析還是業務KPI跟蹤,ClickHouse都能提供近乎實時的數據洞察,讓決策者能夠及時把握業務動態,不再因為"數據正在加載"而錯失良機。
日志分析與安全審計:隨著系統規模擴大,日志數據量呈指數級增長,ClickHouse的高壓縮率和快速查詢能力使其成為日志分析的"利器"。特別是在安全審計場景下,需要從海量日志中快速識別異常模式,ClickHouse的性能優勢能夠大大提高安全團隊的響應效率,讓潛在威脅無處遁形。
用戶行為分析:對于互聯網企業而言,分析用戶行為數據以優化產品體驗至關重要。ClickHouse能夠高效處理大量用戶事件數據,支持復雜的漏斗分析、留存分析等,幫助產品團隊深入理解用戶需求,做出數據驅動的產品決策。
時序數據分析:雖然ClickHouse不是專門的時序數據庫,但其高效的存儲和查詢能力使其在處理時序數據方面也表現出色。特別是在需要長期存儲大量歷史數據并進行復雜分析的場景,如IoT設備數據分析、金融交易分析等,ClickHouse都能游刃有余。
PostgreSQL的優勢應用領域
PostgreSQL作為一款成熟的關系型數據庫,被譽為"數據庫界的瑞士軍刀",憑借其強大的功能和靈活性,在眾多應用場景中占據重要地位:
事務處理系統(OLTP):PostgreSQL的行式存儲架構和ACID特性使其成為處理高頻次、小規模事務的理想選擇。無論是電商平臺訂單處理、銀行交易系統還是企業資源規劃(ERP)系統,PostgreSQL都能提供穩定可靠的事務支持,確保數據的一致性和完整性,讓業務運轉如絲般順滑。
復雜數據模型管理:當應用需要處理復雜的數據關系和約束時,PostgreSQL的豐富數據類型支持和強大的外鍵、約束機制能夠有效維護數據完整性。特別是在需要管理復雜業務邏輯的企業應用中,PostgreSQL的優勢尤為明顯,就像一位嚴謹的圖書管理員,確保每本書都在正確的位置。
地理信息系統(GIS):PostgreSQL通過PostGIS擴展提供了強大的地理空間數據處理能力,使其成為GIS應用的首選數據庫。無論是位置服務、路線規劃還是空間分析,PostgreSQL都能提供專業級的支持,讓地圖應用不再"迷路"。
混合負載應用:對于既需要事務處理又需要一定分析能力的應用,PostgreSQL提供了一個平衡的解決方案。雖然其分析性能不及專門的OLAP數據庫,但對于中小規模的分析需求,PostgreSQL已經足夠應對,避免了維護多套系統的復雜性,可謂"一專多能"。
JSON文檔存儲:PostgreSQL對JSON的出色支持使其成為需要同時處理關系數據和文檔數據的應用的理想選擇。特別是在現代Web應用中,PostgreSQL能夠靈活應對半結構化數據存儲需求,無需引入專門的文檔數據庫,簡化了技術棧。
數據一致性要求高的場景:在金融、醫療等對數據一致性要求極高的行業,PostgreSQL成熟的事務機制和嚴格的ACID合規性提供了可靠保障。這些場景下,性能往往不是首要考慮因素,數據的準確性和一致性更為關鍵,PostgreSQL就像一位一絲不茍的會計師,確保每一分錢都準確無誤。
混合使用策略與最佳實踐
在實際業務中,ClickHouse和PostgreSQL往往不是非此即彼的選擇,而是可以根據業務需求巧妙結合,就像一對默契的搭檔,各自發揮所長。以下是一些混合使用的策略和最佳實踐:
OLTP+OLAP架構:將PostgreSQL作為事務處理系統,負責日常業務操作和數據錄入;同時將數據同步到ClickHouse中用于分析查詢。這種架構模式能夠兼顧事務處理的可靠性和分析查詢的高性能,是許多企業的標準做法。數據同步可以通過ETL工具、變更數據捕獲(CDC)或應用層雙寫等方式實現,就像兩個專業運動員各自在擅長的賽道上奔跑。
數據同步策略是混合架構成功的關鍵。建議采用增量同步機制,并設置合理的同步頻率,在實時性和系統負載之間找到平衡點。
數據分層存儲:根據數據訪問頻率和價值,采用分層存儲策略。熱數據(頻繁訪問)存儲在PostgreSQL中,溫數據和冷數據(較少訪問)存儲在ClickHouse中。這種策略既能保證高頻數據的快速訪問,又能降低整體存儲成本,特別適用于用戶行為分析、日志分析等場景,就像將常用的物品放在手邊,不常用的物品整齊收納在柜子里。
實時數據管道:構建以PostgreSQL為源頭、ClickHouse為終點的實時數據管道。PostgreSQL負責處理實時業務數據,通過流處理系統(如Kafka)將數據實時傳輸到ClickHouse進行分析。這種架構適用于需要實時數據分析的場景,如實時推薦系統、實時風控等,讓數據像水流一樣順暢地在系統間流動。
查詢路由層:在應用層和數據庫之間引入查詢路由層,根據查詢類型自動將請求路由到合適的數據庫系統。事務性查詢路由到PostgreSQL,分析性查詢路由到ClickHouse。這種方式對應用層透明,簡化了開發復雜度,就像一位智能交通警察,將車輛引導到最合適的道路上。
數據生命周期管理:制定明確的數據生命周期策略,規定數據何時從PostgreSQL遷移到ClickHouse,以及何時歸檔或刪除。例如,可以將最近30天的詳細交易數據保留在PostgreSQL中,而將歷史數據聚合后存儲在ClickHouse中用于長期趨勢分析,讓數據在適當的"生命周期階段"發揮最大價值。
在實際實施混合策略時,需要注意以下幾點:
-
數據一致性:確保兩個系統之間的數據同步策略能夠滿足業務一致性要求,特別是在關鍵業務場景下。
-
同步延遲:評估數據同步的延遲對業務的影響,對于實時性要求高的場景,需要選擇低延遲的同步方案。
-
運維復雜度:混合架構會增加系統復雜度和運維成本,需要權衡性能提升與運維負擔之間的關系。
-
團隊技能:確保團隊同時具備兩種數據庫的專業知識,或者有明確的分工負責不同系統的維護。
-
成本控制:混合架構可能意味著更高的硬件和軟件許可成本,需要進行全面的成本效益分析。
總之,ClickHouse和PostgreSQL各有其獨特的優勢和適用場景。在實際項目中,明智的做法不是簡單選擇其中一種,而是根據業務需求,靈活運用各自優勢,構建高效、可靠的數據架構。通過合理的混合使用策略,企業可以在保證業務穩定運行的同時,最大化數據價值,為業務決策提供強有力的支持。
選型建議與總結
根據業務需求選擇合適的數據庫
在ClickHouse與PostgreSQL之間做出選擇,就像選擇一位專業的運動員——關鍵是要看比賽項目!這兩種數據庫系統各有其獨特優勢,適用于截然不同的"賽場"。
如果您的應用主要涉及大規模數據分析、復雜聚合查詢和實時報表生成,那么ClickHouse無疑是您的"數據分析冠軍"。它的列式存儲架構、向量化執行引擎和高效的數據壓縮能力,使其在處理分析型工作負載時表現卓越。特別是當您需要處理海量數據(TB級甚至PB級)并要求亞秒級響應時,ClickHouse能夠提供令人印象深刻的性能提升。正如OONI的案例所示,從PostgreSQL遷移到ClickHouse后,他們的分析查詢時間從20分鐘縮短到毫秒級,同時存儲需求減半——這簡直是從馬車到火箭的跨越!
如果您的應用主要是事務處理、CRUD操作和需要強一致性的業務系統,那么PostgreSQL將是您的"事務處理大師"。作為一款成熟的關系型數據庫,PostgreSQL在OLTP場景下表現出色,提供了完善的事務支持、豐富的數據類型和強大的擴展能力。它特別適合需要頻繁更新、刪除單條記錄的業務系統,如電子商務平臺、ERP系統等。就像一位可靠的管家,PostgreSQL能夠精確、高效地處理每一筆"家務"。
值得注意的是,在某些情況下,混合使用策略可能是最佳選擇。許多企業采用PostgreSQL處理日常事務性工作負載,同時將數據同步到ClickHouse中進行復雜分析,這種架構就像是一支配備不同專長隊員的球隊,能夠兼顧兩方面的優勢。
最終建議與決策框架
為了幫助您在ClickHouse和PostgreSQL之間做出明智選擇,我們提供以下決策框架——這就像是為您的技術選型之旅準備的"導航地圖":
-
工作負載評估
- 分析型為主(大量聚合、分組、復雜查詢):選擇ClickHouse
- 事務型為主(頻繁點查、插入、更新、刪除):選擇PostgreSQL
- 混合負載:考慮雙數據庫架構或使用PostgreSQL的擴展(如Citus)
-
性能需求分析
- 查詢響應時間要求亞秒級,特別是對大數據集:ClickHouse有明顯優勢
- 高并發短事務處理:PostgreSQL更適合
- 數據壓縮比和存儲效率:ClickHouse的列式存儲通常能提供更好的壓縮率
-
擴展性考量
- 需要水平擴展到多節點:ClickHouse的分布式架構更具優勢
- 主要通過垂直擴展提升性能:PostgreSQL是合適選擇
- 讀寫分離需求:PostgreSQL的讀復制方案成熟穩定
-
數據特征評估
- 數據量大但更新頻率低:ClickHouse是理想選擇
- 數據頻繁更新:PostgreSQL提供更好的支持
- 數據模式經常變更:PostgreSQL的靈活性更高
-
團隊能力匹配
- 團隊熟悉傳統SQL和關系型數據庫:PostgreSQL上手更快
- 團隊有大數據分析背景:ClickHouse的學習曲線更平緩
-
生態系統整合
- 需要與現有PostgreSQL工具鏈集成:選擇PostgreSQL
- 需要與大數據生態系統(如Hadoop、Spark)集成:ClickHouse更合適
最終,數據庫選型不應僅僅關注技術指標,還需要綜合考慮業務需求、團隊能力、維護成本和長期發展。在許多情況下,最佳解決方案可能是組合使用這兩種數據庫,讓它們各自處理自己擅長的工作負載,通過數據同步機制保持數據一致性,從而構建一個既高效又靈活的數據架構。
記住,沒有最好的數據庫,只有最適合您業務需求的數據庫。就像選擇交通工具一樣,有時需要跑車,有時需要貨車,有時則需要兩者兼備。希望本文的分析能夠幫助您在技術選型時做出更加明智的決策。

系統及知識準備)
內存和內存地址、數組的查找算法和排序算法;)
場:河南農業大學(補題))

以pinia為中心的開發模板(監聽watch))








 :使用 Milvus 實現高效圖片查重功能)
的自述)



