【終極指南】吃透機器學習環境配置:從Conda、CUDA到Docker容器化
大家好!在機器學習的旅程中,一個穩定、可復現的環境是成功的基石。
第一部分:核心理念——為何環境配置如此重要?
任何機器學習模型的運行,都離不開一個精確配置的環境 。一個好的環境配置實踐,能為您帶來以下核心優勢:
-
隔離性:確保不同項目間的依賴庫互不干擾,避免版本沖突 。
-
可復現性:讓您的代碼在任何機器上都能得到相同的結果,這在學術研究和工業生產中至關重要 。
-
易于遷移:方便地將整個工作環境打包、遷移,實現快速部署 。
第二部分:入門必備——包管理工具 (Conda & Pipenv)
包管理工具是環境配置的第一步,它們幫助我們創建獨立的虛擬環境并管理項目所需的各種軟件包。
1. Conda
Conda是一個開源、跨平臺的包和環境管理系統,功能強大且社區支持廣泛 。
-
創建環境:
conda create -n test_env -
安裝包 (以PyTorch為例):
conda install -n test_env pytorch torchvision torchaudio cudatoolkit=11.3 -c pytorch -
激活與退出:
conda activate test_env和conda deactivate
2. Pipenv
Pipenv旨在將
pip(包安裝)和virtualenv(虛擬環境)的功能合二為一,讓依賴管理更自動化 。
-
安裝包:
pipenv install numpy torch -
激活與退出:
pipenv shell和Ctrl + D
第三部分:進階核心——深入理解GPU、驅動與CUDA
僅僅安裝好軟件包是不夠的,要讓代碼在GPU上跑起來,我們必須理解硬件、驅動和CUDA之間的關系。
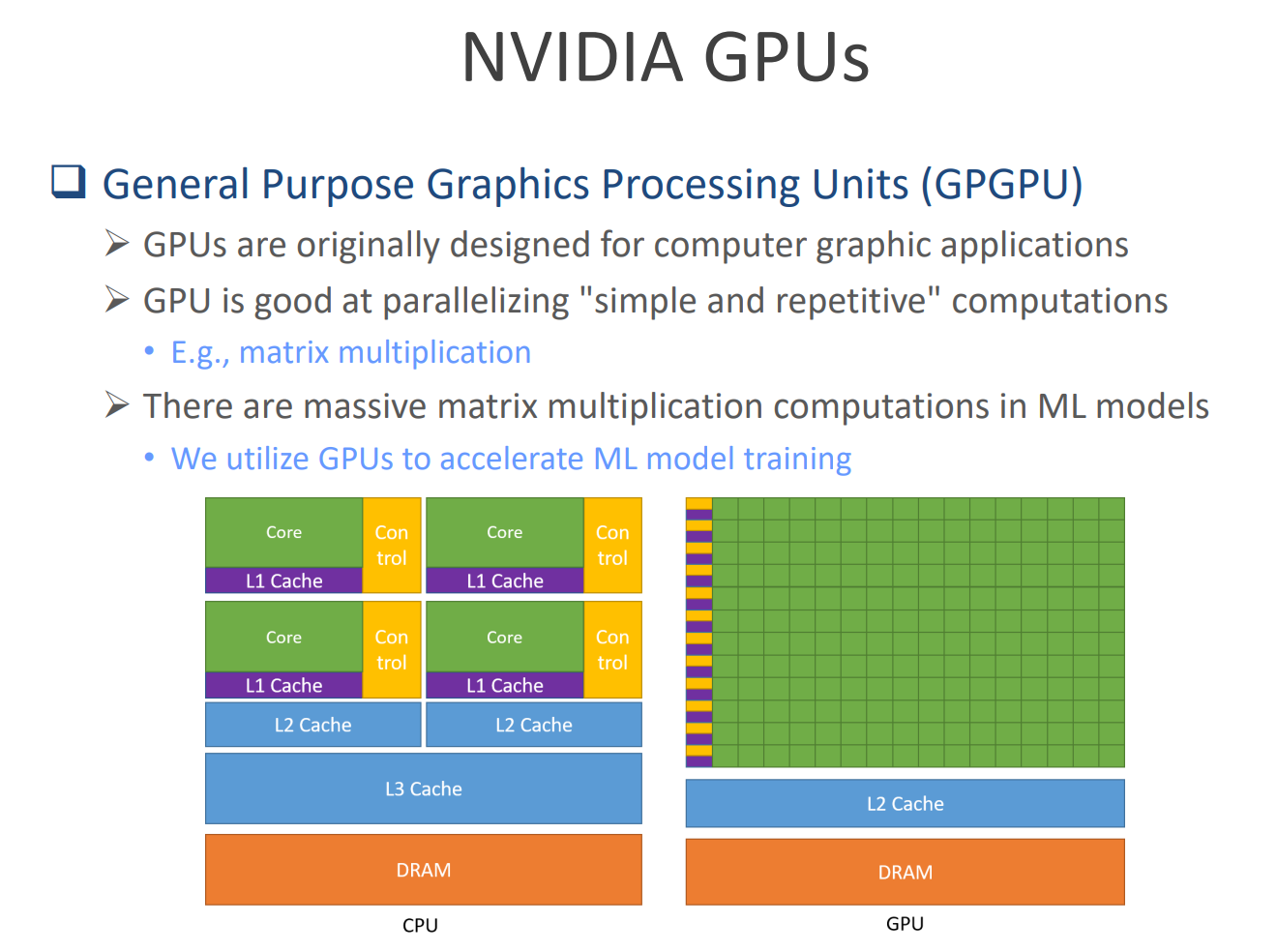
Q1:NVIDIA驅動和CUDA有什么區別?
這是一個非常關鍵的問題。簡單來說,驅動是基礎,CUDA是建立在該基礎之上的應用開發平臺。
-
NVIDIA驅動 (NVIDIA Driver):它是連接操作系統和GPU硬件的“橋梁” 。沒有驅動,您的電腦根本無法識別GPU 。驅動程序本身包含一個版本的CUDA API,稱為
驅動CUDA版本 (Driver CUDA Version),您可以通過在終端運行
nvidia-smi命令查看。這個版本代表了該驅動最高能夠支持的CUDA功能 。 -
CUDA運行時 (CUDA Runtime):當我們說“為PyTorch安裝CUDA”時,通常指的是安裝CUDA運行時 。它是一個并行的計算平臺和編程接口(API),允許像PyTorch這樣的框架利用GPU強大的并行計算能力(如矩陣運算)來加速模型訓練 。
最重要的兼容性法則:驅動的CUDA版本必須大于或等于運行時的CUDA版本 。例如,如果
nvidia-smi顯示CUDA版本是11.6,那么您為項目安裝的運行時CUDA版本(如11.3)不能超過11.6 。
第四部分:高手之路——擁抱容器化 (Docker)
當環境變得異常復雜時(例如,需要在最新的GPU上運行依賴舊版CUDA的舊項目),容器化技術就成了我們的終極武器。
Q2:虛擬機和容器有什么區別?我應該用哪個?
-
虛擬機 (Virtual Machine, VM):它虛擬化了整個操作系統 。就像在Windows上安裝一個軟件,運行一個完整的Linux系統。這使得它非常“重”,但隔離性極強 。
-
容器 (Container):它運行在同一個主機操作系統之上,共享系統內核 。它虛擬的不是操作系統,而是
應用程序及其所有依賴項的運行環境。這使得容器非常“輕量”,啟動極快 。
對于機器學習開發,容器通常是更好的選擇,因為它在提供了足夠隔離性的同時,性能開銷更小。
Q3:為什么要使用容器?它解決了什么問題?
使用容器的核心原因是為了解決環境的復雜性、可移植性和兼容性難題。
-
處理復雜依賴:當您需要特定版本的庫(如cuDNN、NCCL)來進行分布式訓練時,容器可以將這一切完美打包 。
-
解決兼容性噩夢:您可以在容器里打包舊版的PyTorch和它依賴的舊版CUDA,然后在安裝了最新驅動和GPU的機器上無縫運行 。
-
行業標準:無論是工業界的Kubernetes還是學術界的Slurm,都廣泛采用容器作為應用部署的標準單元 。
Q4:為什么文件推薦使用NVIDIA自己的容器?
因為標準的Docker容器無法很好地適配GPU。如果在普通容器里使用GPU,會要求容器內的驅動版本必須和主機的驅動版本
完全一致,這極大地破壞了容器的“可移植性” 。
NVIDIA Docker是完美的解決方案 。
-
核心優勢:您無需在容器內安裝任何NVIDIA驅動 。NVIDIA Docker會自動將主機的驅動和GPU設備安全地映射到容器中。
-
帶來的好處:這讓在容器中使用GPU變得極其簡單,并且讓您的容器鏡像具有了真正的可移植性,可以在任何安裝了NVIDIA Docker的機器上運行 。
使用NVIDIA Docker的流程:
-
在主機上安裝好NVIDIA驅動和NVIDIA Docker 。
-
從Docker Hub拉取官方預構建的鏡像 (如
docker pull pytorch/pytorch:1.9.1-cuda11.1-cudnn8-runtime) 。 -
使用
--gpus all參數啟動容器,即可在容器內訪問GPU 。
最終總結
-
驅動先行:無論采用何種方案,必須在主機上正確安裝NVIDIA驅動 。
-
版本兼容:牢記,運行時的CUDA版本不能高于驅動支持的CUDA版本 。
-
擁抱容器:對于復雜的GPU環境,強烈推薦使用NVIDIA Docker。它能為您免去無數環境配置的煩惱,讓您專注于算法和模型本身。
什么意思?有什么用?bmpData.Scan0;什么意思?有什么用?)


)


:自定義實現一個自增的StatefulWidget組件)
![[AI8051U入門第十三步]W5500實現MQTT通信](http://pic.xiahunao.cn/[AI8051U入門第十三步]W5500實現MQTT通信)


![linux81 shell通配符:[list],‘‘ ``““](http://pic.xiahunao.cn/linux81 shell通配符:[list],‘‘ ``““)








